
Top 10 des commandes Hadoop [avec utilisations]
Publié: 2021-01-29À notre époque, avec d'énormes blocs de données, il devient essentiel de les traiter. Les données provenant d'organisations dont la clientèle est en croissance sont bien plus volumineuses que tout outil de gestion de données traditionnel ne peut stocker. Cela nous laisse avec la question de la gestion d'ensembles de données plus importants, qui peuvent aller de gigaoctets à pétaoctets, sans utiliser un seul gros ordinateur ou un outil de gestion de données traditionnel.
C'est là que le framework Apache Hadoop attire l'attention. Avant de plonger dans l'implémentation de la commande Hadoop, comprenons brièvement le framework Hadoop et son importance.
Table des matières
Qu'est-ce qu'Hadoop ?
Hadoop est couramment utilisé par les grandes entreprises pour résoudre divers problèmes, du stockage quotidien de gros Go (gigaoctets) de données aux opérations informatiques sur les données.
Traditionnellement défini comme un framework logiciel open source utilisé pour stocker des données et des applications de traitement, Hadoop se démarque assez fortement de la majorité des outils de gestion de données traditionnels. Il améliore la puissance de calcul et étend la limite de stockage des données en ajoutant quelques nœuds dans le framework, ce qui le rend hautement évolutif. De plus, vos données et vos processus applicatifs sont protégés contre diverses pannes matérielles.
Hadoop suit une architecture maître-esclave pour distribuer et stocker des données à l'aide de MapReduce et HDFS. Comme illustré dans la figure ci-dessous, l'architecture est adaptée de manière définie pour effectuer des opérations de gestion de données à l'aide de quatre nœuds principaux, à savoir Nom, Données, Maître et Esclave. Les composants de base de Hadoop sont construits directement au-dessus du framework. D'autres composants s'intègrent directement aux segments.
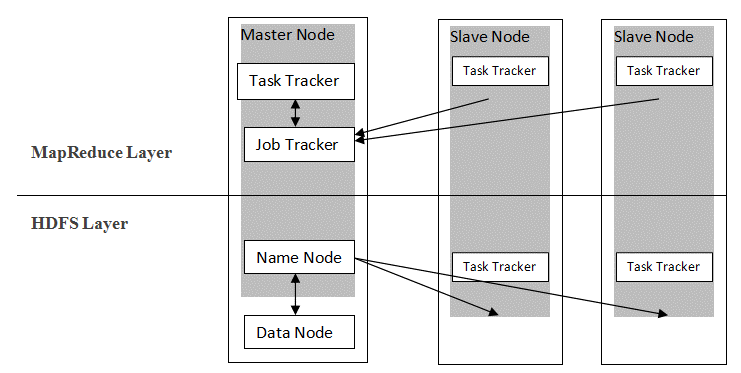 La source
La source

Commandes Hadoop
Les principales fonctionnalités du framework Hadoop montrent une nature cohérente, et il devient plus convivial lorsqu'il s'agit de gérer le Big Data avec l'apprentissage des commandes Hadoop. Vous trouverez ci-dessous quelques commandes Hadoop pratiques qui permettent d'effectuer diverses opérations, telles que la gestion et le traitement des fichiers des clusters HDFS. Cette liste de commandes est fréquemment requise pour obtenir certains résultats de processus.
1. Hadoop Touchz
hadoop fs -touchz /répertoire/nom de fichier
Cette commande permet à l'utilisateur de créer un nouveau fichier dans le cluster HDFS. Le «répertoire» dans la commande fait référence au nom du répertoire dans lequel l'utilisateur souhaite créer le nouveau fichier, et le «nom de fichier» signifie le nom du nouveau fichier qui sera créé à la fin de la commande.
2. Commande de test Hadoop
hadoop fs -test -[defsz] <chemin>
Cette commande particulière remplit l'objectif de tester l'existence d'un fichier dans le cluster HDFS. Les caractères de "[defsz]" dans la commande doivent être modifiés si nécessaire. Voici une brève description de ces personnages :
- d -> Vérifie s'il s'agit d'un répertoire ou non
- e -> Vérifie s'il s'agit d'un chemin ou non
- f -> Vérifie s'il s'agit d'un fichier ou non
- s -> Vérifie s'il s'agit d'un chemin vide ou non
- r -> Vérifie l'existence du chemin et l'autorisation de lecture
- w -> Vérifie l'existence du chemin et l'autorisation d'écriture
- z -> Vérifie la taille du fichier
3. Commande de texte Hadoop
hadoop fs -texte <src>
La commande text est particulièrement utile pour afficher le fichier zip alloué au format texte. Il fonctionne en traitant les fichiers source et en fournissant son contenu dans un format texte décodé brut.
4. Commande de recherche Hadoop
hadoop fs -find <chemin> … <expression>

Cette commande est généralement utilisée dans le but de rechercher des fichiers dans le cluster HDFS. Il analyse l'expression donnée dans la commande avec tous les fichiers du cluster et affiche les fichiers qui correspondent à l'expression définie.
Lire : Les meilleurs outils Hadoop
5. Commande Hadoop Getmerge
hadoop fs -getmerge <src> <localdest>
La commande Getmerge permet de fusionner un ou plusieurs fichiers dans un répertoire désigné sur le cluster de système de fichiers HDFS. Il accumule les fichiers dans un seul fichier situé dans le système de fichiers local. Le « src » et « localdest » représentent la signification de source-destination et de destination locale.
6. Commande de comptage Hadoop
hadoop fs -count [options] <chemin>
Aussi évident que son nom, la commande Hadoop count compte le nombre de fichiers et d'octets dans un répertoire donné. Il existe différentes options disponibles qui modifient la sortie selon les besoins. Ceux-ci sont les suivants :
- q -> quota affiche la limite du nombre total de noms et de l'utilisation de l'espace
- u -> affiche uniquement le quota et l'utilisation
- h -> donne la taille d'un fichier
- v -> affiche l'en-tête
7. Commande Hadoop AppendToFile
hadoop fs -appendToFile <localsrc> <dest>
Il permet à l'utilisateur d'ajouter le contenu d'un ou plusieurs fichiers dans un seul fichier sur le fichier de destination spécifié dans le cluster de système de fichiers HDFS. Lors de l'exécution de cette commande, les fichiers source donnés sont ajoutés à la source de destination selon le nom de fichier donné dans la commande.
8. Commande Hadoop ls
hadoop fs -ls /chemin
La commande ls dans Hadoop affiche la liste des fichiers/contenus dans un répertoire spécifié, c'est-à-dire un chemin. En ajoutant "R" avant /path, la sortie affichera les détails du contenu, tels que les noms, la taille, le propriétaire, etc. pour chaque fichier spécifié dans le répertoire donné.
9. Commande Hadoop mkdir
hadoop fs -mkdir /chemin/nom_répertoire
La caractéristique unique de cette commande est la création d'un répertoire dans le cluster de système de fichiers HDFS si le répertoire n'existe pas. De plus, si le répertoire spécifié est présent, le message de sortie affichera une erreur indiquant l'existence du répertoire.
10. Commande chmod Hadoop
hadoop fs -chmod [-R] <mode> <chemin>
Cette commande est utilisée lorsqu'il est nécessaire de modifier les autorisations d'accès à un fichier particulier. En donnant la commande chmod, la permission du fichier spécifié est modifiée. Cependant, il est important de se rappeler que l'autorisation sera modifiée lorsque le propriétaire du fichier exécutera cette commande.
Lisez aussi: Tutoriel Impala Hadoop
Conclusion
Commençant par le problème important du stockage des données auquel sont confrontées les grandes organisations dans le monde d'aujourd'hui, cet article a discuté de la solution pour le stockage limité des données en introduisant Hadoop et son impact sur la réalisation des opérations de gestion des données à l'aide des commandes Hadoop. Pour les débutants dans Hadoop, un aperçu du framework est décrit avec ses composants et son architecture.

Après avoir lu cet article, on peut facilement se sentir confiant quant à ses connaissances sur l'aspect du framework Hadoop et ses commandes appliquées. Certification PG exclusive d'upGrad en Big Data : upGrad propose un programme de 7,5 mois spécifique à l'industrie pour la certification PG en Big Data où vous organiserez, analyserez et interpréterez le Big Data avec IIIT-Bangalore.
Conçu avec soin pour les professionnels en activité, il aidera les étudiants à acquérir des connaissances pratiques et favorisera leur entrée dans des rôles liés au Big Data.
Faits saillants du programme :
- Apprendre des langues et des outils pertinents
- Apprentissage des concepts avancés de la programmation distribuée, des plates-formes Big Data, des bases de données, des algorithmes et de l'exploration Web
- Un certificat accrédité de l'IIIT Bangalore
- Aide au placement pour être absorbé par les meilleures multinationales
- Mentorat 1: 1 pour suivre vos progrès et vous aider à chaque étape
- Travailler sur des projets et des missions en direct
Admissibilité : formation en mathématiques/génie logiciel/statistiques/analyse
Consultez nos autres cours de génie logiciel sur upGrad.