
A GraphQL Primer : L'évolution de la conception d'API (Partie 2)
Publié: 2022-03-10Dans la partie 1, nous avons examiné comment les API ont évolué au cours des dernières décennies et comment chacune a cédé la place à la suivante. Nous avons également parlé de certains des inconvénients particuliers de l'utilisation de REST pour le développement de clients mobiles. Dans cet article, je veux voir où la conception de l'API du client mobile semble se diriger - avec un accent particulier sur GraphQL.
Il y a, bien sûr, beaucoup de personnes, d'entreprises et de projets qui ont essayé de combler les lacunes de REST au fil des ans : HAL, Swagger/OpenAPI, OData JSON API et des dizaines d'autres projets plus petits ou internes ont tous cherché à mettre de l'ordre dans le monde sans spécifications de REST. Plutôt que de prendre le monde pour ce qu'il est et de proposer des améliorations progressives, ou d'essayer d'assembler suffisamment de pièces disparates pour faire de REST ce dont j'ai besoin, j'aimerais tenter une expérience de pensée. Étant donné une compréhension des techniques qui ont fonctionné et qui n'ont pas fonctionné dans le passé, j'aimerais prendre les contraintes d'aujourd'hui et nos langages immensément plus expressifs pour essayer d'esquisser l'API que nous voulons. Travaillons à partir de l'expérience du développeur vers l'arrière plutôt que l'implémentation vers l'avant (je vous regarde SQL).
Trafic HTTP minimal
Nous savons que le coût de chaque requête réseau (HTTP/1) est élevé sur plusieurs mesures, de la latence à la durée de vie de la batterie. Idéalement, les clients de notre nouvelle API auront besoin d'un moyen de demander toutes les données dont ils ont besoin en aussi peu d'allers-retours que possible.
Charges utiles minimales
Nous savons également que le client moyen est limité en ressources, en bande passante, en CPU et en mémoire, notre objectif devrait donc être de n'envoyer que les informations dont notre client a besoin. Pour ce faire, nous aurons probablement besoin d'un moyen pour le client de demander des données spécifiques.
Lisible par l'homme
Nous avons appris de l'époque SOAP qu'il n'est pas facile d'interagir avec une API, les gens grimaceront à sa mention. Les équipes d'ingénierie veulent utiliser les mêmes outils sur lesquels nous comptons depuis des années comme curl , wget et Charles et l'onglet réseau de nos navigateurs.
Riche en outillage
Une autre chose que nous avons apprise de XML-RPC et de SOAP est que les contrats client/serveur et les systèmes de type, en particulier, sont incroyablement utiles. Si possible, toute nouvelle API aurait la légèreté d'un format comme JSON ou YAML avec la capacité d'introspection de contrats plus structurés et de type sécurisé.
Préservation du raisonnement local
Au fil des ans, nous sommes parvenus à nous mettre d'accord sur certains principes directeurs sur la manière d'organiser de grandes bases de code - le principal étant la "séparation des préoccupations". Malheureusement pour la plupart des projets, cela a tendance à se décomposer sous la forme d'une couche d'accès aux données centralisée. Si possible, les différentes parties d'une application doivent avoir la possibilité de gérer leurs propres besoins en données ainsi que ses autres fonctionnalités.
Puisque nous concevons une API centrée sur le client, commençons par ce à quoi cela pourrait ressembler de récupérer des données dans une API comme celle-ci. Si nous savons que nous devons à la fois faire un minimum d'allers-retours et que nous devons pouvoir filtrer les champs dont nous ne voulons pas, nous avons besoin d'un moyen à la fois de parcourir de grands ensembles de données et de n'en demander que les parties qui sont utile pour nous. Un langage de requête semble bien convenir ici.
Nous n'avons pas besoin de poser des questions sur nos données de la même manière que vous le feriez avec une base de données, donc un langage impératif comme SQL semble être le mauvais outil. En fait, nos principaux objectifs sont de traverser des relations préexistantes et de limiter les champs, ce que nous devrions pouvoir faire avec quelque chose de relativement simple et déclaratif. L'industrie a plutôt bien opté pour JSON pour les données non binaires, alors commençons par un langage de requête déclaratif de type JSON. Nous devrions être en mesure de décrire les données dont nous avons besoin, et le serveur devrait retourner JSON contenant ces champs.

Un langage de requête déclaratif répond à l'exigence de charges utiles minimales et de trafic HTTP minimal, mais il existe un autre avantage qui nous aidera à atteindre un autre de nos objectifs de conception. De nombreux langages déclaratifs, de requête et autres, peuvent être efficacement manipulés comme s'il s'agissait de données. Si nous concevons avec soin, notre langage de requête permettra aux développeurs de séparer les requêtes volumineuses et de les recombiner de la manière qui a du sens pour leur projet. L'utilisation d'un langage de requête comme celui-ci nous aiderait à atteindre notre objectif ultime de préservation du raisonnement local.
Il y a beaucoup de choses passionnantes que vous pouvez faire une fois que vos requêtes deviennent des « données ». Par exemple, vous pouvez intercepter toutes les requêtes et les regrouper de la même manière qu'un DOM virtuel regroupe les mises à jour du DOM, vous pouvez également utiliser un compilateur pour extraire les petites requêtes au moment de la construction afin de pré-cacher les données ou vous pouvez créer un système de cache sophistiqué. comme Apollo Cache.
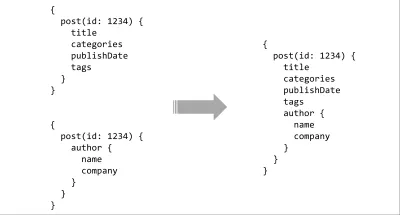
Le dernier élément de la liste de souhaits de l'API est l'outillage. Nous obtenons déjà une partie de cela en utilisant un langage de requête, mais le véritable pouvoir vient lorsque vous le couplez avec un système de type. Avec un schéma typé simple sur le serveur, il existe des possibilités presque infinies d'outils riches. Les requêtes peuvent être analysées statiquement et validées par rapport au contrat, les intégrations IDE peuvent fournir des conseils ou une auto-complétion, les compilateurs peuvent apporter des optimisations au moment de la construction aux requêtes, ou plusieurs schémas peuvent être assemblés pour former une surface d'API contiguë.

Concevoir une API qui associe un langage de requête et un système de type peut sembler une proposition dramatique, mais les gens l'expérimentent, sous diverses formes, depuis des années. XML-RPC a poussé pour les réponses typées au milieu des années 90 et son successeur, SOAP, a dominé pendant des années ! Plus récemment, il y a des choses comme l'abstraction MongoDB de Meteor, l'horizon (RIP) de RethinkDB, l'incroyable Falcor de Netflix qu'ils utilisent pour Netflix.com depuis des années et le dernier est GraphQL de Facebook. Pour le reste de cet essai, je me concentrerai sur GraphQL car, alors que d'autres projets comme Falcor font des choses similaires, l'esprit de la communauté semble le favoriser massivement.
Qu'est-ce que GraphQL ?
Tout d'abord, je dois dire que j'ai un peu menti. L'API que nous avons construite ci-dessus était GraphQL. GraphQL n'est qu'un système de type pour vos données, un langage de requête pour les parcourir - le reste n'est que détail. Dans GraphQL, vous décrivez vos données comme un graphique d'interconnexions, et votre client demande spécifiquement le sous-ensemble de données dont il a besoin. Il y a beaucoup de paroles et d'écritures sur toutes les choses incroyables que GraphQL permet, mais les concepts de base sont très gérables et simples.
Pour rendre ces concepts plus concrets et pour aider à illustrer comment GraphQL tente de résoudre certains des problèmes de la partie 1, le reste de cet article construira une API GraphQL qui peut alimenter le blog de la partie 1 de cette série. Avant de vous lancer dans le code, il y a quelques points à garder à l'esprit à propos de GraphQL.
GraphQL est une spécification (pas une implémentation)
GraphQL n'est qu'une spécification. Il définit un système de type avec un langage de requête simple, et c'est tout. La première chose qui en ressort est que GraphQL n'est en aucun cas lié à un langage particulier. Il existe plus de deux douzaines d'implémentations dans tout, de Haskell à C++, dont JavaScript n'est qu'une. Peu de temps après l'annonce de la spécification, Facebook a publié une implémentation de référence en JavaScript mais, comme ils ne l'utilisent pas en interne, les implémentations dans des langages comme Go et Clojure peuvent être encore meilleures ou plus rapides.
La spécification de GraphQL ne mentionne ni les clients ni les données
Si vous lisez la spécification, vous remarquerez que deux choses sont manifestement absentes. Tout d'abord, au-delà du langage de requête, il n'y a aucune mention des intégrations client. Des outils tels qu'Apollo, Relay, Loka et autres sont possibles grâce à la conception de GraphQL, mais ils ne font en aucun cas partie de son utilisation ni ne sont nécessaires à son utilisation. Deuxièmement, il n'y a aucune mention d'une couche de données particulière. Le même serveur GraphQL peut, et le fait fréquemment, récupérer des données à partir d'un ensemble hétérogène de sources. Il peut demander des données mises en cache à Redis, effectuer une recherche d'adresse à partir de l'API USPS et appeler des microservices basés sur protobuff et le client ne saura jamais la différence.
Divulgation progressive de la complexité
GraphQL a, pour beaucoup de gens, atteint une rare intersection de puissance et de simplicité. Il fait un travail fantastique en rendant les choses simples simples et les choses difficiles possibles. Faire fonctionner un serveur et servir des données typées via HTTP peut ne prendre que quelques lignes de code dans à peu près n'importe quel langage imaginable.
Par exemple, un serveur GraphQL peut encapsuler une API REST existante et ses clients peuvent obtenir des données avec des requêtes GET régulières, tout comme vous interagissez avec d'autres services. Vous pouvez voir une démo ici. Ou, si le projet a besoin d'un ensemble d'outils plus sophistiqués, il est possible d'utiliser GraphQL pour faire des choses comme l'authentification au niveau du champ, les abonnements pub/sub ou les requêtes pré-compilées/mises en cache.
Un exemple d'application
Le but de cet exemple est de démontrer la puissance et la simplicité de GraphQL dans ~70 lignes de JavaScript, pas d'écrire un tutoriel détaillé. Je n'entrerai pas dans trop de détails sur la syntaxe et la sémantique, mais tout le code ici est exécutable, et il y a un lien vers une version téléchargeable du projet à la fin de l'article. Si après avoir traversé cela, vous souhaitez creuser un peu plus, j'ai une collection de ressources sur mon blog qui vous aideront à créer des services plus gros et plus robustes.
Pour la démo, j'utiliserai JavaScript, mais les étapes sont très similaires dans toutes les langues. Commençons par quelques exemples de données en utilisant l'incroyable Mocky.io.
Auteurs
{ 9: { id: 9, name: "Eric Baer", company: "Formidable" }, ... }Des postes
[ { id: 17, author: "author/7", categories: [ "software engineering" ], publishdate: "2016/03/27 14:00", summary: "...", tags: [ "http/2", "interlock" ], title: "http/2 server push" }, ... ] La première étape consiste à créer un nouveau projet avec express et le middleware express-graphql .

bash npm init -y && npm install --save graphql express express-graphql Et pour créer un fichier index.js avec un serveur express.
const app = require("express")(); const PORT = 5000; app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); Pour commencer à travailler avec GraphQL, nous pouvons commencer par modéliser les données dans l'API REST. Dans un nouveau fichier appelé schema.js ajoutez ce qui suit :
const { GraphQLInt, GraphQLList, GraphQLObjectType, GraphQLSchema, GraphQLString } = require("graphql"); const Author = new GraphQLObjectType({ name: "Author", fields: { id: { type: GraphQLInt }, name: { type: GraphQLString }, company: { type: GraphQLString }, } }); const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author }, categories: { type: new GraphQLList(GraphQLString) }, publishDate: { type: GraphQLString }, summary: { type: GraphQLString }, tags: { type: new GraphQLList(GraphQLString) }, title: { type: GraphQLString } } }); const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post) } } }); module.exports = new GraphQLSchema({ query: Blog }); Le code ci-dessus mappe les types dans les réponses JSON de notre API aux types de GraphQL. Un GraphQLObjectType correspond à un JavaScript Object , un GraphQLString correspond à un JavaScript String et ainsi de suite. Le seul type spécial auquel il faut prêter attention est le GraphQLSchema sur les dernières lignes. Le GraphQLSchema est l'exportation au niveau racine d'un GraphQL - le point de départ des requêtes pour parcourir le graphique. Dans cet exemple de base, nous ne définissons que la query ; c'est là que vous définiriez les mutations (écritures) et les abonnements.
Ensuite, nous allons ajouter le schéma à notre serveur express dans le fichier index.js . Pour ce faire, nous allons ajouter le middleware express-graphql et lui passer le schéma.
const graphqlHttp = require("express-graphql"); const schema = require("./schema.js"); const app = require("express")(); const PORT = 5000; app.use(graphqlHttp({ schema, // Pretty Print the JSON response pretty: true, // Enable the GraphiQL dev tool graphiql: true })); app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); À ce stade, bien que nous ne retournions aucune donnée, nous avons un serveur GraphQL fonctionnel qui fournit son schéma aux clients. Pour faciliter le démarrage de l'application, nous ajouterons également un script de démarrage au package.json .
"scripts": { "start": "nodemon index.js" }, L'exécution du projet et l'accès à https://localhost:5000/ devraient afficher un explorateur de données appelé GraphiQL. GraphiQL se chargera par défaut tant que l'en-tête HTTP Accept n'est pas défini sur application/json . Appeler cette même URL avec fetch ou cURL en utilisant application/json renverra un résultat JSON. N'hésitez pas à jouer avec la documentation intégrée et à écrire une requête.

La seule chose qui reste à faire pour terminer le serveur est de câbler les données sous-jacentes dans le schéma. Pour ce faire, nous devons définir des fonctions de resolve . Dans GraphQL, une requête est exécutée de haut en bas en appelant une fonction de resolve lorsqu'elle parcourt l'arbre. Par exemple, pour la requête suivante :
query homepage { posts { title } } GraphQL appellera d'abord posts.resolve(parentData) puis posts.title.resolve(parentData) . Commençons par définir le résolveur sur notre liste d'articles de blog.
const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post), resolve: () => { return fetch('https://www.mocky.io/v2/594a3ac810000053021aa3a7') .then((response) => response.json()) } } } }); J'utilise ici le package isomorphic-fetch pour faire une requête HTTP car il montre bien comment renvoyer une promesse à partir d'un résolveur, mais vous pouvez utiliser tout ce que vous voulez. Cette fonction renverra un tableau de messages au type Blog. La fonction de résolution par défaut pour l'implémentation JavaScript de GraphQL est parentData.<fieldName> . Par exemple, le résolveur par défaut pour le champ Nom de l'auteur serait :
rawAuthorObject => rawAuthorObject.nameCe résolveur de remplacement unique doit fournir les données pour l'ensemble de l'objet de publication. Nous devons encore définir le résolveur pour l'auteur, mais si vous exécutez une requête pour récupérer les données nécessaires à la page d'accueil, vous devriez la voir fonctionner.
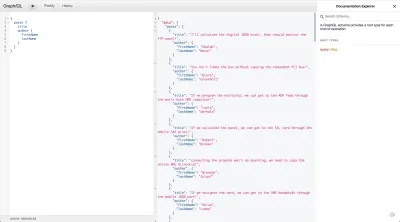
Étant donné que l'attribut author dans notre API de publications n'est que l'identifiant de l'auteur, lorsque GraphQL recherche un objet qui définit le nom et la société et trouve une chaîne, il renvoie simplement null . Pour câbler l'auteur, nous devons modifier notre schéma Post pour qu'il ressemble à ce qui suit :
const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author, resolve: (subTree) => { // Get the AuthorId from the post data const authorId = subTree.author.split("/")[1]; return fetch('https://www.mocky.io/v2/594a3bd21000006d021aa3ac') .then((response) => response.json()) .then(authors => authors[authorId]); } }, ... } });Maintenant, nous avons un serveur GraphQL entièrement fonctionnel qui encapsule une API REST. La source complète peut être téléchargée à partir de ce lien Github ou exécutée à partir de ce tableau de bord GraphQL.
Vous vous interrogez peut-être sur les outils dont vous aurez besoin pour consommer un point de terminaison GraphQL comme celui-ci. Il y a beaucoup d'options comme Relay et Apollo mais pour commencer, je pense que l'approche simple est la meilleure. Si vous avez beaucoup joué avec GraphiQL, vous avez peut-être remarqué qu'il a une longue URL. Cette URL n'est qu'une version encodée en URI de votre requête. Pour créer une requête GraphQL en JavaScript, vous pouvez faire quelque chose comme ceci :
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);Ou, si vous le souhaitez, vous pouvez copier coller l'URL directement depuis GraphiQL comme ceci :
https://localhost:5000/?query=query%20homepage%20%7B%0A%20%20posts%20%7B%0A%20%20%20%20title%0A%20%20%20%20author%20%7B%0A%20%20%20%20%20%20name%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D&operationName=homepagePuisque nous avons un point de terminaison GraphQL et une façon de l'utiliser, nous pouvons le comparer à notre API RESTish. Le code que nous devions écrire pour récupérer nos données à l'aide d'une API RESTish ressemblait à ceci :
Utilisation d'une API RESTish
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/post/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/author/${postId}`); const getPostWithAuthor = post => { return getAuthor(post.author) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(posts => { const postDetails = posts.map(getPostWithAuthor); return Promise.all(postDetails); }) };Utilisation d'une API GraphQL
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);En résumé, nous avons utilisé GraphQL pour :
- Réduisez neuf requêtes (liste des articles, quatre articles de blog et l'auteur de chaque article).
- Réduisez la quantité de données envoyées d'un pourcentage significatif.
- Utilisez des outils de développement incroyables pour créer nos requêtes.
- Écrivez un code beaucoup plus propre dans notre client.
Défauts dans GraphQL
Bien que je pense que le battage médiatique est justifié, il n'y a pas de solution miracle, et aussi génial que soit GraphQL, il n'est pas sans défauts.
Intégrité des données
GraphQL semble parfois être un outil spécialement conçu pour de bonnes données. Il fonctionne souvent mieux comme une sorte de passerelle, rassemblant des services disparates ou des tables hautement normalisées. Si les données qui reviennent des services que vous consommez sont désordonnées et non structurées, l'ajout d'un pipeline de transformation de données sous GraphQL peut être un véritable défi. La portée d'une fonction de résolution GraphQL est uniquement ses propres données et celles de ses enfants. Si une tâche d'orchestration a besoin d'accéder aux données d'un frère ou d'un parent dans l'arborescence, cela peut être particulièrement difficile.
Gestion des erreurs complexes
Une requête GraphQL peut exécuter un nombre arbitraire de requêtes, et chaque requête peut atteindre un nombre arbitraire de services. Si une partie de la requête échoue, plutôt que la totalité de la requête, GraphQL, par défaut, renvoie des données partielles. Les données partielles sont probablement le bon choix techniquement, et elles peuvent être incroyablement utiles et efficaces. L'inconvénient est que la gestion des erreurs n'est plus aussi simple que de vérifier le code d'état HTTP. Ce comportement peut être désactivé, mais le plus souvent, les clients se retrouvent avec des cas d'erreur plus sophistiqués.
Mise en cache
Bien que ce soit souvent une bonne idée d'utiliser des requêtes statiques GraphQL, pour des organisations comme Github qui autorisent des requêtes arbitraires, la mise en cache réseau avec des outils standard comme Varnish ou Fastly ne sera plus possible.
Coût CPU élevé
L'analyse, la validation et la vérification de type d'une requête est un processus lié au processeur qui peut entraîner des problèmes de performances dans les langages à thread unique comme JavaScript.
Il s'agit uniquement d'un problème pour l'évaluation des requêtes d'exécution.
Réflexions finales
Les fonctionnalités de GraphQL ne sont pas une révolution - certaines d'entre elles existent depuis près de 30 ans. Ce qui rend GraphQL puissant, c'est que le niveau de finition, d'intégration et de facilité d'utilisation en fait plus que la somme de ses parties.
Beaucoup de choses accomplies par GraphQL peuvent, avec effort et discipline, être réalisées en utilisant REST ou RPC, mais GraphQL apporte des API de pointe à l'énorme nombre de projets qui n'ont peut-être pas le temps, les ressources ou les outils pour le faire eux-mêmes. Il est également vrai que GraphQL n'est pas une solution miracle, mais ses défauts ont tendance à être mineurs et bien compris. En tant que personne qui a construit un serveur GraphQL raisonnablement compliqué, je peux facilement dire que les avantages l'emportent facilement sur le coût.
Cet essai se concentre presque entièrement sur la raison d'être de GraphQL et les problèmes qu'il résout. Si cela a piqué votre intérêt à en savoir plus sur sa sémantique et comment l'utiliser, je vous encourage à apprendre de la manière qui vous convient le mieux, qu'il s'agisse de blogs, de youtube ou simplement de la lecture de la source (How To GraphQL est particulièrement bon).
Si vous avez aimé cet article (ou si vous l'avez détesté) et que vous souhaitez me faire part de vos commentaires, retrouvez-moi sur Twitter en tant que @ebaerbaerbaer ou sur LinkedIn à ericjbaer.