
A GraphQL Primer : pourquoi nous avons besoin d'un nouveau type d'API (Partie 1)
Publié: 2022-03-10Dans cette série, je veux vous présenter GraphQL. À la fin, vous devez comprendre non seulement de quoi il s'agit, mais également ses origines, ses inconvénients et les bases de son utilisation. Dans ce premier article, plutôt que de sauter dans l'implémentation, je souhaite expliquer comment et pourquoi nous sommes arrivés à GraphQL (et à des outils similaires) en examinant les leçons tirées des 60 dernières années de développement d'API, de RPC à aujourd'hui. Après tout, comme Mark Twain l'a décrit de manière colorée, il n'y a pas de nouvelles idées.
"Il n'y a pas de nouvelle idée. C'est impossible. Nous prenons simplement beaucoup d'idées anciennes et les mettons dans une sorte de kaléidoscope mental."
- Mark Twain dans "La propre autobiographie de Mark Twain: les chapitres de la revue nord-américaine"
Mais d'abord, je dois m'adresser à l'éléphant dans la pièce. Les nouvelles choses sont toujours excitantes, mais elles peuvent aussi sembler épuisantes. Vous avez peut-être entendu parler de GraphQL et vous vous êtes simplement dit : "Pourquoi..." Alternativement, vous avez peut-être pensé à quelque chose comme : "Pourquoi est-ce que je me soucie d'une nouvelle tendance de conception d'API ? Le REPOS c'est… bien. Ce sont des questions légitimes, alors laissez-moi vous expliquer pourquoi vous devriez prêter attention à celle-ci.
introduction
Les avantages d'apporter de nouveaux outils à votre équipe doivent être mis en balance avec ses coûts. Il y a beaucoup de choses à mesurer. Il y a le temps qu'il faut pour apprendre, le temps que la conversion enlève au développement de fonctionnalités, les frais généraux liés à la maintenance de deux systèmes. Avec des coûts aussi élevés, toute nouvelle technologie doit être meilleure, plus rapide ou plus productive de manière considérable. Les améliorations progressives, bien qu'excitantes, ne valent tout simplement pas l'investissement. Les types d'API dont je veux parler, GraphQL en particulier, sont à mon avis un énorme pas en avant et offrent plus que suffisamment d'avantages pour justifier le coût.
Plutôt que d'explorer d'abord les fonctionnalités, il est utile de les mettre en contexte et de comprendre comment elles ont vu le jour. Pour ce faire, je vais commencer par un petit rappel de l'histoire des API.
RPC
RPC était sans doute le premier modèle d'API majeur et ses origines remontent aux débuts de l'informatique au milieu des années 60. À l'époque, les ordinateurs étaient encore si gros et si chers que la notion de développement d'applications pilotées par API, telle que nous la concevons, n'était pour la plupart que théorique. Des contraintes telles que la bande passante/latence, la puissance de calcul, le temps de calcul partagé et la proximité physique ont obligé les ingénieurs à penser en termes de systèmes distribués plutôt qu'en termes de services qui exposent les données. De ARPANET dans les années 60, jusqu'au milieu des années 90 avec des choses comme CORBA et RMI de Java, la plupart des ordinateurs ont interagi les uns avec les autres en utilisant des appels de procédure à distance (RPC) qui est un modèle d'interaction client-serveur où un client provoque une procédure (ou méthode) à exécuter sur un serveur distant.
Il y a beaucoup de bonnes choses à propos de RPC. Son principe principal est de permettre à un développeur de traiter le code dans un environnement distant comme s'il se trouvait dans un environnement local, bien que beaucoup plus lent et moins fiable, ce qui crée une continuité dans des systèmes autrement distincts et disparates. Comme beaucoup de choses qui sont sorties d'ARPANET, il était en avance sur son temps car ce type de continuité est quelque chose que nous recherchons toujours lorsque nous travaillons avec des actions non fiables et asynchrones comme l'accès à la base de données et les appels de service externes.
Au fil des décennies, de nombreuses recherches ont été menées sur la manière de permettre aux développeurs d'intégrer un comportement asynchrone comme celui-ci dans le flux typique d'un programme. s'il y avait eu des choses comme Promises, Futures et ScheduledTasks disponibles à l'époque, il est possible que notre paysage d'API serait différent.
Un autre avantage de RPC est que, puisqu'il n'est pas contraint par la structure des données, des méthodes hautement spécialisées peuvent être écrites pour les clients qui demandent et récupèrent exactement les informations nécessaires, ce qui peut entraîner une surcharge réseau minimale et des charges utiles plus petites.
Il y a, cependant, des choses qui rendent le RPC difficile. Premièrement, la continuité nécessite un contexte . RPC, de par sa conception, crée beaucoup de couplage entre les systèmes locaux et distants - vous perdez les frontières entre votre code local et votre code distant. Pour certains domaines, c'est correct ou même préféré comme dans les SDK clients, mais pour les API où le code client n'est pas bien compris, cela peut être considérablement moins flexible que quelque chose de plus orienté données.
Plus important cependant, est le potentiel de prolifération des méthodes API . En théorie, un service RPC expose une petite API réfléchie qui peut gérer n'importe quelle tâche. En pratique, un grand nombre de terminaux externes peuvent s'accréter sans trop de structure. Il faut énormément de discipline pour éviter le chevauchement des API et la duplication au fil du temps lorsque les membres de l'équipe vont et viennent et que les projets pivotent.
Il est vrai qu'avec des outils et des documents appropriés, les changements, comme ceux que j'ai mentionnés, peuvent être gérés, mais pendant mon temps d'écriture de logiciels, j'ai rencontré peu de services d'auto-documentation et disciplinés, donc, pour moi, c'est un peu un hareng rouge.
SAVON
Le prochain type d'API majeur à venir était SOAP, qui est né à la fin des années 90 chez Microsoft Research. SOAP (Simple O bject A ccess Protocol) est une spécification de protocole ambitieuse pour la communication basée sur XML entre les applications. L'ambition déclarée de SOAP était de remédier à certains des inconvénients pratiques de RPC, XML-RPC en particulier, en créant une base bien structurée pour les services Web complexes. En effet, cela signifiait simplement ajouter un système de type comportemental à XML. Malheureusement, il a créé plus d'obstacles qu'il n'en a résolu, comme en témoigne le fait que très peu de nouveaux points de terminaison SOAP sont écrits aujourd'hui.
"SOAP est ce que la plupart des gens considéreraient comme un succès modéré."
— Boîte à dons
SOAP avait de bonnes choses à faire malgré sa verbosité insupportable et ses noms terribles. Les contrats exécutoires dans le WSDL et le WADL (prononcez « wizdle » et « waddle ») entre le client et le serveur garantissent des résultats prévisibles et sûrs, et le WSDL pourrait être utilisé pour générer de la documentation ou pour créer des intégrations avec des IDE et d'autres outils.
La grande révélation de SOAP concernant l'évolution des API a été son introduction progressive et peut-être involontaire d'appels plus orientés ressources. Les points de terminaison SOAP vous permettent de demander des données avec une structure prédéterminée plutôt que de penser aux méthodes requises pour générer les données (en supposant qu'elles soient écrites de cette façon).
L'inconvénient le plus important de SOAP est qu'il est si verbeux ; il est presque impossible à utiliser sans beaucoup d'outils . Vous avez besoin d'outils pour écrire des tests, d'outils pour inspecter les réponses d'un serveur et d'outils pour analyser toutes les données. De nombreux systèmes plus anciens utilisent encore SOAP, mais l'exigence d'outils le rend trop lourd pour la plupart des nouveaux projets, et le nombre d'octets nécessaires à la structure XML en fait un mauvais choix pour servir les appareils mobiles ou les systèmes distribués bavards.
Pour plus d'informations, il vaut la peine de lire la spécification SOAP ainsi que l'histoire étonnamment intéressante de SOAP de Don Box, l'un des membres de l'équipe d'origine.
DU REPOS
Enfin, nous en sommes arrivés au design pattern API du moment : REST. REST, introduit dans une thèse de doctorat de Roy Fielding en 2000, a fait basculer le pendule dans une direction totalement différente. REST est, à bien des égards, l'antithèse de SOAP et les regarder côte à côte donne l'impression que sa thèse était un peu rageuse.
SOAP utilise HTTP comme transport muet et construit sa structure dans le corps de la requête et de la réponse. REST, d'autre part, supprime les contrats client-serveur, les outils, les en-têtes XML et sur mesure, les remplaçant par la sémantique HTTPs car c'est la structure qui choisit à la place d'utiliser des verbes HTTP pour interagir avec les données et les URI qui référencent une ressource dans une hiérarchie de Les données.
| SAVON | DU REPOS | |
|---|---|---|
| Verbes HTTP | OBTENIR, METTRE, POSTER, CORRIGER, SUPPRIMER | |
| Format de données | XML | Tout ce que vous voulez |
| Contrats client/serveur | Toute la journée ! | Qui a besoin de ces |
| Système de types | JavaScript a un raccourci non signé, n'est-ce pas ? | |
| URL | Décrire les opérations | Ressources nommées |
REST change complètement et explicitement la conception de l'API de la modélisation des interactions à la simple modélisation des données d'un domaine. Étant entièrement orienté ressources lorsque vous travaillez avec une API REST, vous n'avez plus besoin de savoir ou de vous soucier de ce qu'il faut pour récupérer une donnée donnée ; vous n'êtes pas non plus tenu de savoir quoi que ce soit sur la mise en œuvre des services backend.

Non seulement la simplicité était une aubaine pour les développeurs, mais comme les URL représentent des informations stables, elles sont facilement mises en cache, son apatridie facilite la mise à l'échelle horizontale et, puisqu'elle modélise les données plutôt que d'anticiper les besoins des consommateurs, elle peut réduire considérablement la surface des API. .
REST est génial, et son ubiquité est un succès étonnant mais, comme toutes les solutions qui l'ont précédé, REST n'est pas sans défauts. Pour parler concrètement de certaines de ses lacunes, passons en revue un exemple de base. Imaginons que nous devons créer la page de destination d'un blog qui affiche une liste d'articles de blog et le nom de leur auteur.
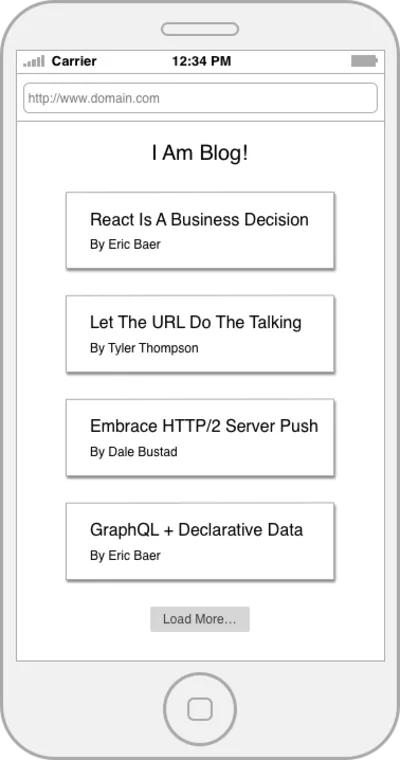
Écrivons le code qui peut récupérer les données de la page d'accueil à partir d'une API REST simple. Nous allons commencer par quelques fonctions qui enveloppent nos ressources.
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/posts/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/authors/${authorId}`);Maintenant, orchestrons !
const getPostWithAuthor = postId => { return getPost(postId) .then(post => getAuthor(post.author)) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(postIds => { const postDetails = postIds.map(getPostWithAuthor); return Promise.all(postDetails); }) };Donc, notre code fera ce qui suit :
- Récupérer tous les messages ;
- Récupérez les détails de chaque publication ;
- Récupérer la ressource Auteur pour chaque publication.
La bonne chose est qu'il est assez facile de raisonner, bien organisé et que les limites conceptuelles de chaque ressource sont bien tracées. La déception ici est que nous venons de faire huit requêtes réseau, dont beaucoup se produisent en série.
GET /posts GET /posts/234 GET /posts/456 GET /posts/17 GET /posts/156 GET /author/9 GET /author/4 GET /author/7 GET /author/2 Oui, vous pourriez critiquer cet exemple en suggérant que l'API pourrait avoir un point de terminaison paginé /posts mais cela coupe les cheveux. Il n'en reste pas moins que vous avez souvent une collection d'appels d'API à faire qui dépendent les uns des autres pour rendre une application ou une page complète.
Développer des clients et des serveurs REST est certainement meilleur que ce qui l'a précédé, ou du moins plus à l'épreuve des idiots, mais beaucoup de choses ont changé au cours des deux décennies qui ont suivi l'article de Fielding. A l'époque, tous les ordinateurs étaient en plastique beige ; maintenant ils sont en aluminium ! Sérieusement, 2000 était proche du pic de l'explosion de l'informatique personnelle. Chaque année, les processeurs doublaient de vitesse et les réseaux devenaient plus rapides à un rythme incroyable. La pénétration d'Internet sur le marché était d'environ 45 % avec nulle part où aller mais en hausse.
Puis, vers 2008, l'informatique mobile s'est généralisée. Avec le mobile, nous avons effectivement régressé d'une décennie en termes de vitesse/performance du jour au lendemain. En 2017, nous avons près de 80 % de pénétration des smartphones au niveau national et plus de 50 % au niveau mondial, et il est temps de repenser certaines de nos hypothèses sur la conception des API.
Les faiblesses de REST
Ce qui suit est un regard critique sur REST du point de vue d'un développeur d'applications client, en particulier celui qui travaille dans le mobile. Les API de style GraphQL et GraphQL ne sont pas nouvelles et ne résolvent pas les problèmes hors de portée des développeurs REST. La contribution la plus importante de GraphQL est sa capacité à résoudre ces problèmes de manière systématique et avec un niveau d'intégration qui n'est pas facilement disponible ailleurs. En d'autres termes, il s'agit d'une solution "piles incluses".
Les principaux auteurs de REST, dont Fielding, ont publié un article fin 2017 (Reflections on the REST Architectural Style and "Principled Design of the Modern Web Architecture") réfléchissant sur deux décennies de REST et les nombreux modèles qu'il a inspirés. Il est court et vaut vraiment la peine d'être lu pour quiconque s'intéresse à la conception d'API.
Avec un contexte historique et une application de référence, examinons les trois principales faiblesses de REST.
Le repos est bavard
Les services REST ont tendance à être au moins quelque peu « bavards », car il faut plusieurs allers-retours entre le client et le serveur pour obtenir suffisamment de données pour rendre une application. Cette cascade de requêtes a des impacts dévastateurs sur les performances, en particulier sur mobile. Pour en revenir à l'exemple du blog, même dans le meilleur des cas avec un nouveau téléphone et un réseau fiable avec une connexion 4G, vous avez passé près de 0,5 seconde en temps de latence avant le téléchargement du premier octet de données.
Latence 4G de 55 ms * 8 requêtes = surcharge de 440 ms
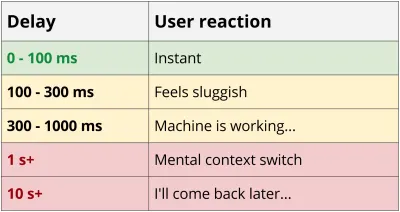
Un autre problème avec les services bavards est que dans de nombreux cas, il faut moins de temps pour télécharger une grande demande que plusieurs petites. La réduction des performances des petites requêtes est vraie pour de nombreuses raisons, notamment TCP Slow Start, le manque de compression des en-têtes et l'efficacité de gzip. Si vous êtes curieux à ce sujet, je vous recommande vivement de lire le réseau de navigateur haute performance d'Ilya Grigorik. Le blog MaxCDN a également un excellent aperçu.
Ce problème n'est pas techniquement lié à REST mais à HTTP, en particulier HTTP/1. HTTP/2 résout pratiquement le problème du bavardage, quel que soit le style de l'API, et il est largement pris en charge par les clients tels que les navigateurs et les SDK natifs. Malheureusement, le déploiement a été lent du côté de l'API. Parmi les 10 000 meilleurs sites Web, l'adoption est d'environ 20 % (et en augmentation) à la fin de 2017. Même Node.js, à ma grande surprise, a obtenu le support HTTP/2 dans sa version 8.x. Si vous en avez la capacité, veuillez mettre à jour votre infrastructure ! En attendant, ne nous attardons pas puisque ce n'est qu'une partie de l'équation.
HTTP mis à part, le dernier élément expliquant pourquoi le bavardage est important concerne le fonctionnement des appareils mobiles, et en particulier de leurs radios. En bref, le fonctionnement de la radio est l'une des parties les plus gourmandes en batterie d'un téléphone, de sorte que le système d'exploitation l'éteint à chaque occasion. Non seulement le démarrage de la radio vide la batterie, mais cela ajoute encore plus de surcharge à chaque demande.
TMI (surextraction)
Le problème suivant avec les services de style REST est qu'ils envoient beaucoup plus d'informations que nécessaire. Dans notre exemple de blog, tout ce dont nous avons besoin est le titre de chaque article et le nom de son auteur, ce qui ne représente qu'environ 17% de ce qui a été renvoyé. C'est une perte de 6x pour une charge utile très simple. Dans une API du monde réel, ce type de surcharge peut être énorme. Les sites de commerce électronique, par exemple, représentent souvent un seul produit sous forme de milliers de lignes de JSON. Comme le problème du bavardage, les services REST peuvent gérer ce scénario aujourd'hui en utilisant des « ensembles de champs clairsemés » pour inclure ou exclure conditionnellement des parties des données. Malheureusement, la prise en charge de cela est inégale, incomplète ou problématique pour la mise en cache réseau.
Outillage et introspection
La dernière chose qui manque aux API REST, ce sont les mécanismes d'introspection. Sans aucun contrat avec des informations sur les types de retour ou la structure d'un point de terminaison, il n'y a aucun moyen de générer de manière fiable de la documentation, de créer des outils ou d'interagir avec les données. Il est possible de travailler dans REST pour résoudre ce problème à des degrés divers. Les projets qui implémentent entièrement l'API OpenAPI, OData ou JSON sont souvent propres, bien spécifiés et, à des degrés divers, bien documentés, mais les backends comme celui-ci sont rares. Même l'hypermédia, un fruit à portée de main relativement bas, bien qu'il ait été vanté lors de conférences pendant des décennies, n'est toujours pas bien fait, voire pas du tout.
Conclusion
Chacun des types d'API est défectueux, mais chaque modèle l'est. Cet écrit n'est pas un jugement sur le travail de base phénoménal que les géants du logiciel ont posé, mais seulement une évaluation sobre de chacun de ces modèles, appliqués dans leur forme «pure» du point de vue d'un développeur client. J'espère qu'au lieu de penser qu'un modèle comme REST ou RPC est rompu, vous pourrez repartir en pensant à la façon dont chacun a fait des compromis et aux domaines dans lesquels une organisation d'ingénierie pourrait concentrer ses efforts pour améliorer ses propres API .
Dans le prochain article, j'explorerai GraphQL et comment il vise à résoudre certains des problèmes que j'ai mentionnés ci-dessus. L'innovation dans GraphQL et les outils similaires réside dans leur niveau d'intégration et non dans leur mise en œuvre. S'il vous plaît, si vous ou votre équipe ne recherchez pas une API "piles incluses", envisagez d'examiner quelque chose comme la nouvelle spécification OpenAPI qui peut aider à construire une base plus solide aujourd'hui !
Si vous avez aimé cet article (ou si vous l'avez détesté) et que vous souhaitez me faire part de vos commentaires, retrouvez-moi sur Twitter en tant que @ebaerbaerbaer ou sur LinkedIn à ericjbaer.