
Descente de gradient dans l'apprentissage automatique : comment ça marche ?
Publié: 2021-01-28Table des matières
introduction
L'optimisation de ses algorithmes est l'une des parties les plus cruciales du Machine Learning. Presque tous les algorithmes de Machine Learning ont un algorithme d'optimisation à leur base qui agit comme le cœur de l'algorithme. Comme nous le savons tous, l'optimisation est l'objectif ultime de tout algorithme, même avec des événements réels ou lorsqu'il s'agit d'un produit basé sur la technologie sur le marché.
Il existe actuellement de nombreux algorithmes d'optimisation qui sont utilisés dans plusieurs applications telles que la reconnaissance faciale, les voitures autonomes, l'analyse basée sur le marché, etc. De même, dans l'apprentissage automatique, ces algorithmes d'optimisation jouent un rôle important. Un de ces algorithmes d'optimisation largement utilisé est l'algorithme de descente de gradient que nous allons parcourir dans cet article.
Qu'est-ce que la descente de gradient ?
En Machine Learning, l'algorithme Gradient Descent est l'un des algorithmes les plus utilisés et pourtant il stupéfie la plupart des nouveaux venus. Mathématiquement, Gradient Descent est un algorithme d'optimisation itératif du premier ordre qui est utilisé pour trouver le minimum local d'une fonction différentiable. En termes simples, cet algorithme Gradient Descent est utilisé pour trouver les valeurs des paramètres (ou coefficients) d'une fonction qui sont utilisés pour minimiser une fonction de coût aussi bas que possible. La fonction de coût est utilisée pour quantifier l'erreur entre les valeurs prédites et les valeurs réelles d'un modèle de Machine Learning construit.
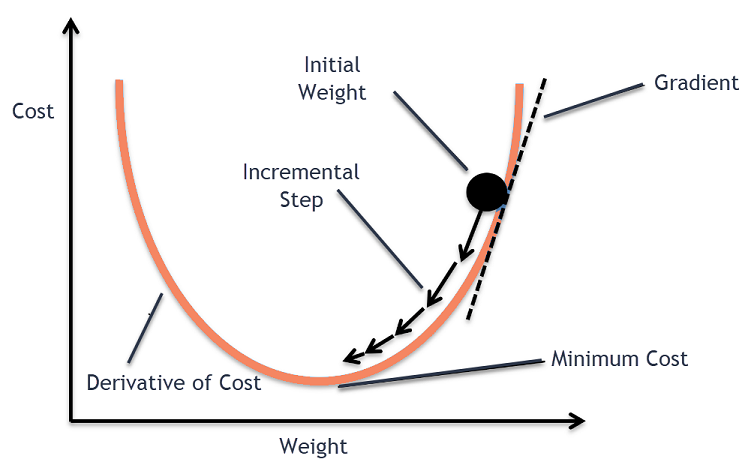
Intuition de descente de gradient
Considérez un grand bol avec lequel vous conserveriez normalement des fruits ou mangeriez des céréales. Ce bol sera la fonction de coût (f).
Maintenant, une coordonnée aléatoire sur n'importe quelle partie de la surface du bol sera les valeurs actuelles des coefficients de la fonction de coût. Le fond du bol est le meilleur ensemble de coefficients et c'est le minimum de la fonction.
Ici, le but est de calculer les différentes valeurs des coefficients à chaque itération, d'évaluer le coût et de choisir les coefficients qui ont une meilleure valeur de fonction de coût (valeur inférieure). Sur plusieurs itérations, on trouverait que le fond du bol a les meilleurs coefficients pour minimiser la fonction de coût.

De cette manière, l'algorithme Gradient Descent fonctionne pour aboutir à un coût minimum.
Rejoignez le cours d'apprentissage automatique en ligne des meilleures universités du monde - Masters, programmes de troisième cycle pour cadres et programme de certificat avancé en ML et IA pour accélérer votre carrière.
Procédure de descente de gradient
Ce processus de descente de gradient commence par l'attribution initiale de valeurs aux coefficients de la fonction de coût. Il peut s'agir soit d'une valeur proche de 0, soit d'une petite valeur aléatoire.
coefficient = 0,0
Ensuite, le coût des coefficients est obtenu en l'appliquant à la fonction de coût et en calculant le coût.
coût = f(coefficient)
Ensuite, la dérivée de la fonction de coût est calculée. Cette dérivée de la fonction de coût est obtenue par le concept mathématique du calcul différentiel. Il nous donne la pente de la fonction au point donné où sa dérivée est calculée. Cette pente est nécessaire pour savoir dans quelle direction le coefficient doit être déplacé à l'itération suivante pour obtenir une valeur de coût inférieure. Cela se fait en observant le signe de la dérivée calculée.
delta = dérivée (coût)
Une fois que nous savons quelle direction est en aval de la dérivée calculée, nous devons mettre à jour les valeurs des coefficients. Pour cela, un paramètre est appelé paramètre d'apprentissage, alpha (α) est utilisé. Ceci est utilisé pour contrôler dans quelle mesure les coefficients peuvent changer à chaque mise à jour.
coefficient = coefficient – (alpha * delta)
La source
De cette manière, ce processus est répété jusqu'à ce que le coût des coefficients soit égal à 0,0 ou suffisamment proche de zéro. C'est la procédure de l'algorithme de descente de gradient.
Types d'algorithmes de descente de gradient
À l'époque moderne, il existe trois types de base de descente de gradient qui sont utilisés dans les algorithmes modernes d'apprentissage automatique et d'apprentissage en profondeur. La principale différence entre chacun de ces 3 types est son coût de calcul et son efficacité. En fonction de la quantité de données utilisées, de la complexité temporelle et de la précision, voici les trois types.
- Descente de dégradé par lots
- Descente de gradient stochastique
- Descente de dégradé en mini lot
Descente de dégradé par lots
Il s'agit de la première version de base des algorithmes de descente de gradient dans laquelle l'ensemble de données est utilisé en même temps pour calculer la fonction de coût et son gradient. Comme l'ensemble de données est utilisé en une seule fois pour une seule mise à jour, le calcul du gradient dans ce type peut être très lent et n'est pas possible avec les ensembles de données qui dépassent la capacité de mémoire de l'appareil.
Ainsi, cet algorithme de descente de gradient par lots n'est utilisé que pour des ensembles de données plus petits et lorsque le nombre d'exemples d'apprentissage est important, la descente de gradient par lots n'est pas préférée. Au lieu de cela, les algorithmes Stochastic et Mini Batch Gradient Descent sont utilisés.
Descente de gradient stochastique
Il s'agit d'un autre type d'algorithme de descente de gradient dans lequel un seul exemple d'apprentissage est traité par itération. Dans ce cas, la première étape consiste à randomiser l'ensemble des données d'apprentissage. Ensuite, un seul exemple d'apprentissage est utilisé pour mettre à jour les coefficients. Cela contraste avec la descente de gradient par lots dans laquelle les paramètres (coefficients) ne sont mis à jour que lorsque tous les exemples d'apprentissage sont évalués.

La descente de gradient stochastique (SGD) a l'avantage que ce type de mise à jour fréquente donne un taux d'amélioration détaillé. Cependant, dans certains cas, cela peut s'avérer coûteux en termes de calcul car il ne traite qu'un seul exemple à chaque itération, ce qui peut entraîner un nombre d'itérations très élevé.
Descente de dégradé en mini lot
Il s'agit d'un algorithme récemment développé qui est plus rapide que les algorithmes Batch et Stochastic Gradient Descent. Il est généralement préféré car il s'agit d'une combinaison des deux algorithmes mentionnés précédemment. En cela, il sépare l'ensemble d'apprentissage en plusieurs mini-lots et effectue une mise à jour pour chacun de ces lots après avoir calculé le gradient de ce lot (comme dans SGD).
Généralement, la taille du lot varie entre 30 et 500, mais il n'y a pas de taille fixe car elle varie selon les applications. Par conséquent, même s'il existe un énorme ensemble de données d'apprentissage, cet algorithme le traite en mini-lots "b". Ainsi, il convient aux grands ensembles de données avec un nombre moindre d'itérations.
Si 'm' est le nombre d'exemples d'apprentissage, alors si b==m, la descente de gradient par lots sera similaire à l'algorithme de descente de gradient par lots.
Variantes de descente de gradient dans l'apprentissage automatique
Avec cette base pour Gradient Descent, plusieurs autres algorithmes ont été développés à partir de cela. Quelques-uns d'entre eux sont résumés ci-dessous.
Descente Dégradée Vanille
C'est l'une des formes les plus simples de la technique de descente de gradient. Le nom vanille signifie pur ou sans aucune falsification. En cela, de petits pas sont faits dans la direction des minima en calculant le gradient de la fonction de coût. Semblable à l'algorithme mentionné ci-dessus, la règle de mise à jour est donnée par,
coefficient = coefficient – (alpha * delta)
Descente de gradient avec Momentum
Dans ce cas, l'algorithme est tel que l'on connaît les étapes précédentes avant de passer à l'étape suivante. Cela se fait en introduisant un nouveau terme qui est le produit de la mise à jour précédente et d'une constante connue sous le nom de momentum. En cela, la règle de mise à jour du poids est donnée par,
mise à jour = alpha * delta
vélocité = mise_à_jour_précédente * élan
coefficient = coefficient + vitesse – mise à jour
ADAGRAD
Le terme ADAGRAD signifie Adaptive Gradient Algorithm. Comme son nom l'indique, il utilise une technique adaptative pour mettre à jour les poids. Cet algorithme est plus adapté aux données rares. Cette optimisation modifie ses taux d'apprentissage en fonction de la fréquence des mises à jour des paramètres pendant l'entraînement. Par exemple, les paramètres qui ont des gradients plus élevés sont conçus pour avoir un taux d'apprentissage plus lent afin que nous ne finissions pas par dépasser la valeur minimale. De même, les gradients inférieurs ont un taux d'apprentissage plus rapide pour s'entraîner plus rapidement.
ADAM
Un autre algorithme d'optimisation adaptative qui a ses racines dans l'algorithme Gradient Descent est l'ADAM qui signifie Adaptive Moment Estimation. Il s'agit d'une combinaison des algorithmes ADAGRAD et SGD avec Momentum. Il est construit à partir de l'algorithme ADAGRAD et est construit plus bas. En termes simples ADAM = ADAGRAD + Momentum.
De cette manière, il existe plusieurs autres variantes d'algorithmes de descente de gradient qui ont été développés et sont en cours de développement dans le monde tels que AMSGrad, ADAMax.
Conclusion
Dans cet article, nous avons vu l'algorithme derrière l'un des algorithmes d'optimisation les plus couramment utilisés en Machine Learning, les algorithmes de descente de gradient, ainsi que ses types et variantes qui ont été développés.
upGrad propose un programme exécutif PG en apprentissage automatique et IA et une maîtrise ès sciences en apprentissage automatique et IA qui peuvent vous guider vers la construction d'une carrière. Ces cours expliqueront la nécessité de l'apprentissage automatique et d'autres étapes pour acquérir des connaissances dans ce domaine couvrant des concepts variés allant de la descente de gradient à l'apprentissage automatique.
Où l'algorithme de descente de gradient peut-il contribuer au maximum ?
L'optimisation au sein de tout algorithme d'apprentissage automatique s'ajoute à la pureté de l'algorithme. L'algorithme de descente de gradient aide à minimiser les erreurs de fonction de coût et à améliorer les paramètres de l'algorithme. Bien que l'algorithme Gradient Descent soit largement utilisé dans l'apprentissage automatique et l'apprentissage profond, son efficacité peut être déterminée par la quantité de données, la quantité d'itérations et la précision préférées, ainsi que le temps disponible. Pour les ensembles de données à petite échelle, la descente de gradient par lot est optimale. La descente de gradient stochastique (SGD) s'avère plus efficace pour des ensembles de données détaillés et plus étendus. En revanche, Mini Batch Gradient Descent est utilisé pour une optimisation plus rapide.
Quels sont les défis rencontrés dans la descente de gradient ?
Gradient Descent est préféré pour optimiser les modèles d'apprentissage automatique afin de réduire la fonction de coût. Cependant, il a aussi ses défauts. Supposons que le dégradé soit diminué en raison des fonctions de sortie minimales des couches de modèle. Dans ce cas, les itérations ne seront pas aussi efficaces car le modèle ne se recyclera pas complètement, mettant à jour ses poids et ses biais. Parfois, un gradient d'erreur accumule des charges de poids et de biais pour maintenir les itérations à jour. Cependant, ce gradient devient trop important pour être géré et s'appelle un gradient explosif. Les besoins en infrastructure, l'équilibre du taux d'apprentissage, l'élan doivent être pris en compte.
La descente de gradient converge-t-elle toujours ?
La convergence se produit lorsque l'algorithme de descente de gradient minimise avec succès sa fonction de coût à un niveau optimal. Gradient Descent Algorithm essaie de minimiser la fonction de coût à travers les paramètres de l'algorithme. Cependant, il peut atterrir sur n'importe lequel des points optimaux et pas nécessairement sur celui qui a un point optimal global ou local. L'une des raisons pour lesquelles la convergence n'est pas optimale est la taille du pas. Une taille de pas plus importante entraîne plus d'oscillations et peut s'écarter de l'optimum global. Par conséquent, la descente de gradient peut ne pas toujours converger vers la meilleure caractéristique, mais elle atterrit toujours sur le point caractéristique le plus proche.