
Performances frontales 2021 : planification et métriques
Publié: 2022-03-10Ce guide a été aimablement soutenu par nos amis de LogRocket, un service qui combine la surveillance des performances frontales, la relecture de session et l'analyse des produits pour vous aider à créer de meilleures expériences client. LogRocket suit les mesures clés, y compris. DOM complet, temps jusqu'au premier octet, premier délai d'entrée, CPU client et utilisation de la mémoire. Obtenez un essai gratuit de LogRocket dès aujourd'hui.

Table des matières
- Se préparer : planification et métriques
Culture de la performance, Core Web Vitals, profils de performance, CrUX, Lighthouse, FID, TTI, CLS, appareils. - Fixer des objectifs réalistes
Budgets de performance, objectifs de performance, framework RAIL, budgets 170Ko/30Ko. - Définir l'environnement
Choix d'un framework, coût de performance de base, Webpack, dépendances, CDN, architecture frontale, CSR, SSR, CSR + SSR, rendu statique, prérendu, modèle PRPL. - Optimisations des actifs
Brotli, AVIF, WebP, images réactives, AV1, chargement multimédia adaptatif, compression vidéo, polices Web, polices Google. - Construire des optimisations
Modules JavaScript, modèle module/nomodule, tree-shaking, code-splitting, scope-hoisting, Webpack, service différentiel, web worker, WebAssembly, bundles JavaScript, React, SPA, hydratation partielle, importation sur interaction, tiers, cache. - Optimisations de livraison
Chargement paresseux, observateur d'intersection, report du rendu et du décodage, CSS critique, streaming, conseils de ressources, changements de mise en page, service worker. - Mise en réseau, HTTP/2, HTTP/3
Agrafage OCSP, certificats EV/DV, packaging, IPv6, QUIC, HTTP/3. - Test et surveillance
Flux de travail d'audit, navigateurs proxy, page 404, invites de consentement aux cookies GDPR, diagnostics de performance CSS, accessibilité. - Victoires rapides
- Tout sur une seule page
- Télécharger la liste de contrôle (PDF, pages Apple, MS Word)
- Abonnez-vous à notre newsletter par e-mail pour ne pas manquer les prochains guides.
Se préparer : planification et métriques
Les micro-optimisations sont idéales pour maintenir les performances sur la bonne voie, mais il est essentiel d'avoir des objectifs clairement définis à l'esprit - des objectifs mesurables qui influenceraient toutes les décisions prises tout au long du processus. Il existe plusieurs modèles différents, et ceux discutés ci-dessous sont assez opiniâtres - assurez-vous simplement de définir vos propres priorités dès le début.
- Instaurer une culture de la performance.
Dans de nombreuses organisations, les développeurs front-end savent exactement quels sont les problèmes sous-jacents courants et quelles stratégies doivent être utilisées pour les résoudre. Cependant, tant qu'il n'y aura pas d'approbation établie de la culture de la performance, chaque décision se transformera en un champ de bataille de départements, divisant l'organisation en silos. Vous avez besoin de l'adhésion des parties prenantes de l'entreprise, et pour l'obtenir, vous devez établir une étude de cas ou une preuve de concept sur la façon dont la vitesse - en particulier Core Web Vitals que nous aborderons en détail plus tard - bénéficie des mesures et des indicateurs de performance clés. ( KPI ) dont ils se soucient.Par exemple, pour rendre les performances plus tangibles, vous pouvez exposer l'impact sur les performances des revenus en montrant la corrélation entre le taux de conversion et le temps de chargement de l'application, ainsi que les performances de rendu. Ou le taux d'exploration du robot de recherche (PDF, pages 27 à 50).
Sans un alignement solide entre les équipes de développement/conception et les équipes commerciales/marketing, les performances ne se maintiendront pas à long terme. Étudiez les plaintes courantes qui parviennent au service client et à l'équipe de vente, étudiez les analyses pour les taux de rebond élevés et les baisses de conversion. Découvrez comment l'amélioration des performances peut aider à résoudre certains de ces problèmes courants. Ajustez l'argument en fonction du groupe d'intervenants auquel vous vous adressez.
Exécutez des expériences de performances et mesurez les résultats, à la fois sur mobile et sur ordinateur (par exemple, avec Google Analytics). Cela vous aidera à construire une étude de cas adaptée à l'entreprise avec des données réelles. De plus, l'utilisation des données d'études de cas et d'expériences publiées sur WPO Stats aidera à accroître la sensibilité des entreprises quant à l'importance des performances et à leur impact sur l'expérience utilisateur et les mesures commerciales. Dire que la performance compte à elle seule ne suffit cependant pas - vous devez également établir des objectifs mesurables et traçables et les observer au fil du temps.
Comment aller là? Dans son exposé sur la création de performances à long terme, Allison McKnight partage une étude de cas complète sur la manière dont elle a contribué à établir une culture de la performance chez Etsy (diapos). Plus récemment, Tammy Everts a parlé des habitudes des équipes de performance très efficaces dans les petites et les grandes organisations.
Tout en ayant ces conversations dans les organisations, il est important de garder à l'esprit que, tout comme l'UX est un éventail d'expériences, la performance Web est une distribution. Comme l'a noté Karolina Szczur, "s'attendre à ce qu'un seul chiffre puisse fournir une note à laquelle aspirer est une hypothèse erronée". Par conséquent, les objectifs de performance doivent être granulaires, traçables et tangibles.
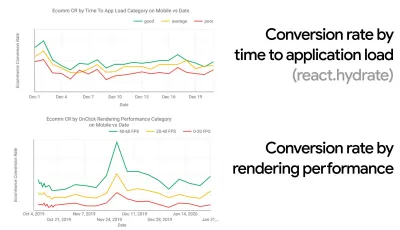
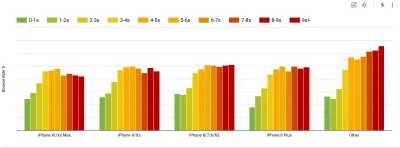
- Objectif : être au moins 20 % plus rapide que votre concurrent le plus rapide.
Selon des recherches psychologiques, si vous voulez que les utilisateurs aient l'impression que votre site Web est plus rapide que celui de votre concurrent, vous devez être au moins 20 % plus rapide. Étudiez vos principaux concurrents, collectez des mesures sur leurs performances sur mobile et sur ordinateur et définissez des seuils qui vous aideraient à les dépasser. Pour obtenir des résultats et des objectifs précis, assurez-vous d'abord d'avoir une image complète de l'expérience de vos utilisateurs en étudiant vos analyses. Vous pouvez ensuite imiter l'expérience du 90e centile pour les tests.Pour avoir une bonne première impression des performances de vos concurrents, vous pouvez utiliser Chrome UX Report ( CrUX , un ensemble de données RUM prêt à l'emploi, introduction vidéo par Ilya Grigorik et guide détaillé par Rick Viscomi), ou Treo, un outil de surveillance RUM qui est alimenté par Chrome UX Report. Les données sont recueillies auprès des utilisateurs du navigateur Chrome, de sorte que les rapports seront spécifiques à Chrome, mais ils vous donneront une distribution assez complète des performances, surtout des scores Core Web Vitals, sur un large éventail de vos visiteurs. Notez que les nouveaux ensembles de données CrUX sont publiés le deuxième mardi de chaque mois .
Alternativement, vous pouvez également utiliser :
- Outil de comparaison de rapports Chrome UX d'Addy Osmani,
- Speed Scorecard (fournit également un estimateur d'impact sur les revenus),
- Comparaison de test d'expérience utilisateur réelle ou
- SiteSpeed CI (basé sur des tests synthétiques).
Remarque : Si vous utilisez Page Speed Insights ou l'API Page Speed Insights (non, ce n'est pas obsolète !), vous pouvez obtenir des données de performances CrUX pour des pages spécifiques au lieu de simplement les agrégats. Ces données peuvent être beaucoup plus utiles pour définir des objectifs de performance pour des actifs tels que "page de destination" ou "liste de produits". Et si vous utilisez CI pour tester les budgets, vous devez vous assurer que votre environnement testé correspond à CrUX si vous avez utilisé CrUX pour définir la cible ( merci Patrick Meenan ! ).
Si vous avez besoin d'aide pour montrer le raisonnement derrière la priorisation de la vitesse, ou si vous souhaitez visualiser la baisse du taux de conversion ou l'augmentation du taux de rebond avec des performances plus lentes, ou peut-être que vous auriez besoin de plaider en faveur d'une solution RUM dans votre organisation, Sergey Chernyshev a construit un calculateur de vitesse UX, un outil open source qui vous aide à simuler des données et à les visualiser pour faire passer votre message.
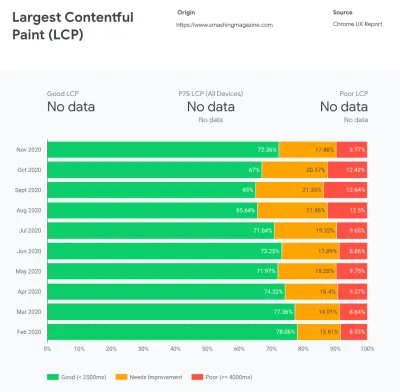
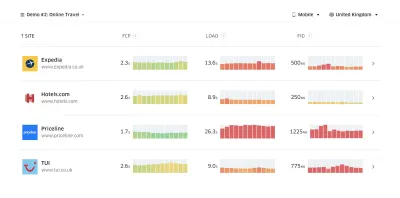
CrUX génère un aperçu des distributions de performances au fil du temps, avec le trafic collecté auprès des utilisateurs de Google Chrome. Vous pouvez créer le vôtre sur le tableau de bord Chrome UX. ( Grand aperçu ) 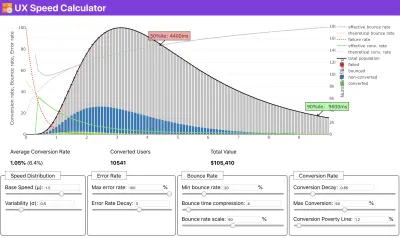
Juste au moment où vous avez besoin de justifier les performances pour faire passer votre message : le calculateur de vitesse UX visualise l'impact des performances sur les taux de rebond, la conversion et le revenu total, sur la base de données réelles. ( Grand aperçu ) Parfois, vous voudrez peut-être aller un peu plus loin, en combinant les données provenant de CrUX avec toutes les autres données dont vous disposez déjà pour déterminer rapidement où se situent les ralentissements, les angles morts et les inefficacités - pour vos concurrents ou pour votre projet. Dans son travail, Harry Roberts a utilisé une feuille de calcul de topographie de vitesse de site qu'il utilise pour décomposer les performances par types de pages clés et suivre les différentes métriques clés entre elles. Vous pouvez télécharger la feuille de calcul au format Google Sheets, Excel, document OpenOffice ou CSV.
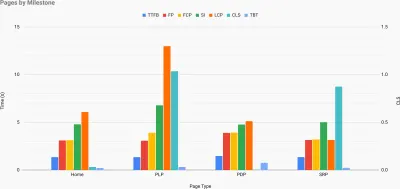
Topographie de la vitesse du site, avec des mesures clés représentées pour les pages clés du site. ( Grand aperçu ) Et si vous voulez aller jusqu'au bout, vous pouvez exécuter un audit de performance Lighthouse sur chaque page d'un site (via Lightouse Parade), avec une sortie enregistrée au format CSV. Cela vous aidera à identifier les pages spécifiques (ou les types de pages) de vos concurrents qui fonctionnent moins bien ou mieux, et sur quoi vous voudrez peut-être concentrer vos efforts. (Pour votre propre site, il est probablement préférable d'envoyer des données à un point de terminaison d'analyse !).

Avec Lighthouse Parade, vous pouvez exécuter un audit de performance Lighthouse sur chaque page d'un site, avec une sortie enregistrée au format CSV. ( Grand aperçu ) Collectez des données, configurez une feuille de calcul, réduisez 20 % et définissez vos objectifs ( budgets de performance ) de cette façon. Vous avez maintenant quelque chose de mesurable à tester. Si vous gardez le budget à l'esprit et essayez de n'expédier que la charge utile minimale pour obtenir un temps d'interactivité rapide, alors vous êtes sur une voie raisonnable.
Besoin de ressources pour démarrer ?
- Addy Osmani a écrit un article très détaillé sur la façon de commencer la budgétisation des performances, comment quantifier l'impact des nouvelles fonctionnalités et par où commencer lorsque vous dépassez votre budget.
- Le guide de Lara Hogan sur la façon d'aborder les conceptions avec un budget de performance peut fournir des indications utiles aux concepteurs.
- Harry Roberts a publié un guide sur la configuration d'une feuille de calcul Google pour afficher l'impact des scripts tiers sur les performances, à l'aide de Request Map,
- Le calculateur de budget de performance de Jonathan Fielding, le calculateur de budget de performance de Katie Hempenius et les calories du navigateur peuvent aider à créer des budgets (merci à Karolina Szczur pour l'avertissement).
- Dans de nombreuses entreprises, les budgets de performance ne doivent pas être ambitieux, mais plutôt pragmatiques, servant de signe de maintien pour éviter de dépasser un certain point. Dans ce cas, vous pouvez choisir votre pire point de données au cours des deux dernières semaines comme seuil et partir de là. Budgets de performance, vous montre pragmatiquement une stratégie pour y parvenir.
- En outre, rendez visible à la fois le budget de performances et les performances actuelles en configurant des tableaux de bord avec des graphiques indiquant les tailles de build. Il existe de nombreux outils vous permettant d'y parvenir : le tableau de bord SiteSpeed.io (open source), SpeedCurve et Caliber ne sont que quelques-uns d'entre eux, et vous pouvez trouver d'autres outils sur perf.rocks.

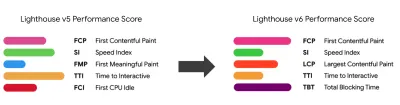
Les calories du navigateur vous aident à définir un budget de performances et à mesurer si une page dépasse ces chiffres ou non. ( Grand aperçu ) Une fois que vous avez un budget en place, intégrez-les dans votre processus de construction avec Webpack Performance Hints et Bundlesize, Lighthouse CI, PWMetrics ou Sitespeed CI pour appliquer les budgets sur les demandes d'extraction et fournir un historique des scores dans les commentaires des relations publiques.
Pour exposer les budgets de performance à toute l'équipe, intégrez les budgets de performance dans Lighthouse via Lightwallet ou utilisez LHCI Action pour une intégration rapide des actions Github. Et si vous avez besoin de quelque chose de personnalisé, vous pouvez utiliser webpagetest-charts-api, une API de points de terminaison pour créer des graphiques à partir des résultats de WebPagetest.
Cependant, la sensibilisation aux performances ne doit pas provenir uniquement des budgets de performance. Tout comme Pinterest, vous pouvez créer une règle eslint personnalisée qui interdit l'importation à partir de fichiers et de répertoires connus pour être très dépendants et gonfler le bundle. Créez une liste de packages "sûrs" pouvant être partagés par toute l'équipe.
Pensez également aux tâches critiques des clients qui sont les plus bénéfiques pour votre entreprise. Étudiez, discutez et définissez des seuils de temps acceptables pour les actions critiques et établissez des repères de chronométrage utilisateur "UX ready" que l'ensemble de l'organisation a approuvés. Dans de nombreux cas, les parcours des utilisateurs toucheront au travail de nombreux départements différents, de sorte que l'alignement en termes de délais acceptables aidera à soutenir ou à empêcher les discussions sur les performances plus tard. Assurez-vous que les coûts supplémentaires des ressources et fonctionnalités ajoutées sont visibles et compris.
Alignez les efforts de performance avec d'autres initiatives technologiques, allant des nouvelles fonctionnalités du produit en cours de construction à la refactorisation pour atteindre de nouveaux publics mondiaux. Ainsi, chaque fois qu'une conversation sur le développement ultérieur a lieu, la performance fait également partie de cette conversation. Il est beaucoup plus facile d'atteindre les objectifs de performances lorsque la base de code est fraîche ou vient d'être refactorisée.
De plus, comme l'a suggéré Patrick Meenan, il vaut la peine de planifier une séquence de chargement et des compromis pendant le processus de conception. Si vous priorisez dès le début les pièces les plus critiques et définissez l'ordre dans lequel elles doivent apparaître, vous saurez également ce qui peut être retardé. Idéalement, cet ordre reflétera également la séquence de vos importations CSS et JavaScript, de sorte qu'il sera plus facile de les gérer pendant le processus de construction. Pensez également à ce que devrait être l'expérience visuelle dans les états "intermédiaires", pendant le chargement de la page (par exemple, lorsque les polices Web ne sont pas encore chargées).
Une fois que vous avez établi une solide culture de la performance dans votre organisation, visez à être 20 % plus rapide que vous-même pour garder les priorités intactes au fil du temps ( merci, Guy Podjarny ! ). Mais tenez compte des différents types et comportements d'utilisation de vos clients (ce que Tobias Baldauf a appelé cadence et cohortes), ainsi que du trafic des bots et des effets de saisonnalité.
Planification, planification, planification. Il pourrait être tentant de se lancer rapidement dans des optimisations rapides "à portée de main" - et cela pourrait être une bonne stratégie pour des gains rapides - mais il sera très difficile de faire de la performance une priorité sans planifier et définir des objectifs réalistes. - des objectifs de performance adaptés.
- Choisissez les bonnes métriques.
Tous les indicateurs n'ont pas la même importance. Étudiez les métriques les plus importantes pour votre application : généralement, elles seront définies par la rapidité avec laquelle vous pouvez commencer à rendre les pixels les plus importants de votre interface et la rapidité avec laquelle vous pouvez fournir une réactivité d'entrée pour ces pixels rendus. Cette connaissance vous donnera la meilleure cible d'optimisation pour les efforts en cours. En fin de compte, ce ne sont pas les événements de chargement ou les temps de réponse du serveur qui définissent l'expérience, mais la perception de la vivacité de l' interface .Qu'est-ce que ça veut dire? Plutôt que de vous concentrer sur le temps de chargement complet de la page (via les délais onLoad et DOMContentLoaded , par exemple), donnez la priorité au chargement de la page tel qu'il est perçu par vos clients. Cela signifie se concentrer sur un ensemble de mesures légèrement différent. En fait, choisir la bonne métrique est un processus sans gagnants évidents.
Sur la base des recherches de Tim Kadlec et des notes de Marcos Iglesias dans son discours, les mesures traditionnelles pourraient être regroupées en quelques ensembles. Habituellement, nous aurons besoin de tous pour obtenir une image complète des performances, et dans votre cas particulier, certains d'entre eux seront plus importants que d'autres.
- Les métriques basées sur la quantité mesurent le nombre de demandes, le poids et un score de performance. Bon pour déclencher des alarmes et surveiller les changements au fil du temps, pas si bon pour comprendre l'expérience utilisateur.
- Les métriques de jalon utilisent des états dans la durée de vie du processus de chargement, par exemple Time To First Byte et Time To Interactive . Bon pour décrire l'expérience utilisateur et le suivi, moins bon pour savoir ce qui se passe entre les jalons.
- Les métriques de rendu fournissent une estimation de la vitesse de rendu du contenu (par exemple, le temps de démarrage du rendu , l' indice de vitesse ). Bon pour mesurer et ajuster les performances de rendu, mais pas si bon pour mesurer quand un contenu important apparaît et peut être interagi avec.
- Les métriques personnalisées mesurent un événement particulier et personnalisé pour l'utilisateur, par exemple le temps du premier tweet de Twitter et PinnerWaitTime de Pinterest. Bon pour décrire précisément l'expérience utilisateur, pas si bon pour mettre à l'échelle les métriques et comparer avec les concurrents.
Pour compléter le tableau, nous recherchons généralement des mesures utiles parmi tous ces groupes. Généralement, les plus spécifiques et les plus pertinentes sont :
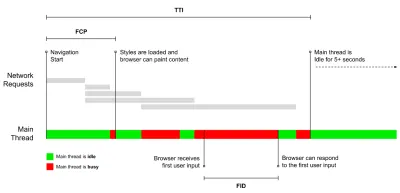
- Temps d'interactivité (TTI)
Au moment où la mise en page s'est stabilisée , les polices Web clés sont visibles et le fil principal est suffisamment disponible pour gérer les entrées de l'utilisateur - essentiellement le moment où un utilisateur peut interagir avec l'interface utilisateur. Les indicateurs clés pour comprendre combien d' attente un utilisateur doit attendre pour utiliser le site sans décalage. Boris Schapira a écrit un article détaillé sur la façon de mesurer le TTI de manière fiable. - Premier délai d'entrée (FID) ou réactivité d'entrée
Le moment entre le moment où un utilisateur interagit pour la première fois avec votre site et le moment où le navigateur est réellement en mesure de répondre à cette interaction. Complète très bien TTI car il décrit la partie manquante de l'image : ce qui se passe lorsqu'un utilisateur interagit réellement avec le site. Conçu comme une métrique RUM uniquement. Il existe une bibliothèque JavaScript pour mesurer le FID dans le navigateur. - La plus grande peinture de contenu (LCP)
Marque le point dans la chronologie de chargement de la page où le contenu important de la page a probablement été chargé. L'hypothèse est que l'élément le plus important de la page est le plus grand visible dans la fenêtre d'affichage de l'utilisateur. Si les éléments sont rendus à la fois au-dessus et au-dessous du pli, seule la partie visible est considérée comme pertinente. - Temps de blocage total ( TBT )
Une métrique qui aide à quantifier la gravité de la non-interactivité d'une page avant qu'elle ne devienne interactive de manière fiable (c'est-à-dire que le fil principal a été exempt de toute tâche s'exécutant sur 50 ms ( tâches longues ) pendant au moins 5 s). La métrique mesure le temps total entre la première peinture et le temps d'interaction (TTI) où le thread principal a été bloqué suffisamment longtemps pour empêcher la réactivité des entrées. Il n'est donc pas étonnant qu'un TBT faible soit un bon indicateur de bonnes performances. (merci, Artem, Phil) - Décalage de mise en page cumulatif ( CLS )
La métrique met en évidence la fréquence à laquelle les utilisateurs subissent des changements de mise en page inattendus ( refusions ) lorsqu'ils accèdent au site. Il examine les éléments instables et leur impact sur l'expérience globale. Plus le score est bas, mieux c'est. - Indice de vitesse
Mesure la rapidité avec laquelle le contenu de la page est rempli visuellement ; plus le score est bas, mieux c'est. Le score de l'indice de vitesse est calculé en fonction de la vitesse de progression visuelle , mais il ne s'agit que d'une valeur calculée. Il est également sensible à la taille de la fenêtre d'affichage, vous devez donc définir une gamme de configurations de test qui correspondent à votre public cible. Notez qu'il devient moins important avec LCP devenant une métrique plus pertinente ( merci, Boris, Artem ! ). - Temps CPU passé
Une métrique qui montre combien de fois et combien de temps le thread principal est bloqué, travaillant sur la peinture, le rendu, les scripts et le chargement. Un temps CPU élevé est un indicateur clair d'une expérience janky , c'est-à-dire lorsque l'utilisateur subit un décalage notable entre son action et une réponse. Avec WebPageTest, vous pouvez sélectionner "Capture Dev Tools Timeline" dans l'onglet "Chrome" pour exposer la répartition du fil principal lorsqu'il s'exécute sur n'importe quel appareil utilisant WebPageTest. - Coûts CPU au niveau des composants
Tout comme avec le temps CPU dépensé , cette métrique, proposée par Stoyan Stefanov, explore l' impact de JavaScript sur le CPU . L'idée est d'utiliser le nombre d'instructions CPU par composant pour comprendre son impact sur l'expérience globale, de manière isolée. Pourrait être implémenté en utilisant Puppeteer et Chrome. - Indice de frustration
Alors que de nombreuses métriques présentées ci-dessus expliquent quand un événement particulier se produit, FrustrationIndex de Tim Vereecke examine les écarts entre les métriques au lieu de les regarder individuellement. Il examine les étapes clés perçues par l'utilisateur final, telles que le titre est visible, le premier contenu est visible, visuellement prêt et la page semble prête et calcule un score indiquant le niveau de frustration lors du chargement d'une page. Plus l'écart est grand, plus le risque qu'un utilisateur soit frustré est grand. Potentiellement un bon KPI pour l'expérience utilisateur. Tim a publié un article détaillé sur FrustrationIndex et son fonctionnement. - Impact du poids de l'annonce
Si votre site dépend des revenus générés par la publicité, il est utile de suivre le poids du code lié à la publicité. Le script de Paddy Ganti construit deux URL (une normale et une bloquant les publicités), invite la génération d'une comparaison vidéo via WebPageTest et signale un delta. - Métriques de déviation
Comme l'ont noté les ingénieurs de Wikipédia, les données sur la variance de vos résultats pourraient vous informer sur la fiabilité de vos instruments et sur l'attention que vous devez accorder aux écarts et aux valeurs aberrantes. Un écart important est un indicateur des ajustements nécessaires dans la configuration. Cela permet également de comprendre si certaines pages sont plus difficiles à mesurer de manière fiable, par exemple en raison de scripts tiers provoquant des variations importantes. Il peut également être judicieux de suivre la version du navigateur pour comprendre les baisses de performances lorsqu'une nouvelle version du navigateur est déployée. - Métriques personnalisées
Les métriques personnalisées sont définies par les besoins de votre entreprise et l'expérience client. Cela vous oblige à identifier les pixels importants , les scripts critiques , le CSS nécessaire et les actifs pertinents et à mesurer la rapidité avec laquelle ils sont livrés à l'utilisateur. Pour celui-ci, vous pouvez surveiller les temps de rendu des héros ou utiliser l'API de performance, en marquant des horodatages particuliers pour les événements importants pour votre entreprise. En outre, vous pouvez collecter des métriques personnalisées avec WebPagetest en exécutant du JavaScript arbitraire à la fin d'un test.
Notez que la première peinture significative (FMP) n'apparaît pas dans l'aperçu ci-dessus. Il fournissait un aperçu de la rapidité avec laquelle le serveur produit des données. Un FMP long indiquait généralement que JavaScript bloquait le thread principal, mais pouvait également être lié à des problèmes de back-end/serveur. Cependant, la métrique a été obsolète récemment car elle semble ne pas être précise dans environ 20 % des cas. Il a été effectivement remplacé par LCP qui est à la fois plus fiable et plus facile à raisonner. Il n'est plus pris en charge dans Lighthouse. Vérifiez les dernières mesures et recommandations de performances centrées sur l'utilisateur pour vous assurer que vous êtes sur la page de sécurité ( merci, Patrick Meenan ).

Steve Souders a une explication détaillée de bon nombre de ces mesures. Il est important de noter que tandis que le Time-To-Interactive est mesuré en exécutant des audits automatisés dans ce que l'on appelle l'environnement de laboratoire , le premier délai d'entrée représente l'expérience utilisateur réelle , les utilisateurs réels subissant un décalage notable. En général, c'est probablement une bonne idée de toujours mesurer et suivre les deux.
Selon le contexte de votre application, les métriques préférées peuvent différer : par exemple, pour l'interface utilisateur de Netflix TV, la réactivité des touches, l'utilisation de la mémoire et le TTI sont plus critiques, et pour Wikipedia, les premières/dernières modifications visuelles et les métriques de temps CPU dépensé sont plus importantes.
Remarque : le FID et le TTI ne tiennent pas compte du comportement de défilement ; le défilement peut se produire indépendamment car il est hors fil principal, donc pour de nombreux sites de consommation de contenu, ces mesures peuvent être beaucoup moins importantes ( merci, Patrick ! ).
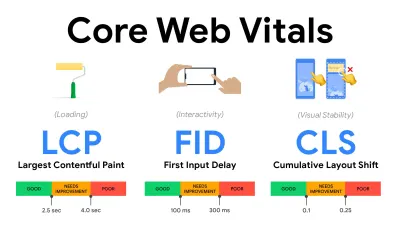
- Mesurer et optimiser les Core Web Vitals .
Pendant longtemps, les mesures de performances étaient assez techniques, se concentrant sur la vision technique de la rapidité de réponse des serveurs et de la rapidité de chargement des navigateurs. Les mesures ont changé au fil des ans - essayant de trouver un moyen de capturer l'expérience utilisateur réelle , plutôt que les horaires du serveur. En mai 2020, Google a annoncé Core Web Vitals, un ensemble de nouvelles mesures de performances axées sur l'utilisateur, chacune représentant une facette distincte de l'expérience utilisateur.Pour chacun d'eux, Google recommande une gamme d'objectifs de vitesse acceptables. Au moins 75 % de toutes les pages vues doivent dépasser la plage Bon pour réussir cette évaluation. Ces mesures ont rapidement gagné du terrain, et avec Core Web Vitals devenant des signaux de classement pour la recherche Google en mai 2021 ( mise à jour de l'algorithme de classement Page Experience ), de nombreuses entreprises ont tourné leur attention vers leurs scores de performance.
Décomposons chacun des Core Web Vitals, un par un, ainsi que des techniques et des outils utiles pour optimiser vos expériences avec ces mesures à l'esprit. (Il convient de noter que vous obtiendrez de meilleurs scores Core Web Vitals en suivant un conseil général dans cet article.)
- Plus grande peinture de contenu ( LCP ) < 2,5 sec.
Mesure le chargement d'une page et signale le temps de rendu de la plus grande image ou du bloc de texte visible dans la fenêtre d'affichage. Par conséquent, LCP est affecté par tout ce qui retarde le rendu d'informations importantes - qu'il s'agisse de temps de réponse lents du serveur, de blocage de CSS, de JavaScript en vol (première ou tierce partie), de chargement de polices Web, d'opérations de rendu ou de peinture coûteuses, d'opérations paresseuses -images chargées, écrans squelettes ou rendu côté client.
Pour une bonne expérience, LCP doit se produire dans les 2,5 secondes suivant le premier chargement de la page. Cela signifie que nous devons rendre la première partie visible de la page le plus tôt possible. Cela nécessitera un CSS critique personnalisé pour chaque modèle, l'orchestration de l'ordre<head>et la prélecture des actifs critiques (nous les aborderons plus tard).La principale raison d'un faible score LCP est généralement les images. Délivrer un LCP en <2,5s sur Fast 3G — hébergé sur un serveur bien optimisé, le tout statique sans rendu côté client et avec une image provenant d'un CDN image dédié — signifie que la taille théorique maximale de l'image n'est que d'environ 144Ko . C'est pourquoi les images réactives sont importantes, ainsi que le préchargement précoce des images critiques (avec
preload).Petite astuce : pour découvrir ce qui est considéré comme LCP sur une page, dans DevTools, vous pouvez survoler le badge LCP sous "Timings" dans le panneau de performances ( merci, Tim Kadlec !).
- Premier délai d'entrée ( FID ) < 100 ms.
Mesure la réactivité de l'interface utilisateur, c'est-à-dire la durée pendant laquelle le navigateur a été occupé par d'autres tâches avant de pouvoir réagir à un événement d'entrée discret de l'utilisateur comme un appui ou un clic. Il est conçu pour capturer les retards résultant de l'occupation du thread principal, en particulier lors du chargement de la page.
L'objectif est de rester dans les 50 à 100 ms pour chaque interaction. Pour y arriver, nous devons identifier les tâches longues (bloquer le thread principal pendant plus de 50 ms) et les décomposer, diviser le code d'un paquet en plusieurs morceaux, réduire le temps d'exécution de JavaScript, optimiser la récupération des données, différer l'exécution des scripts de tiers. , déplacez JavaScript vers le thread d'arrière-plan avec les agents Web et utilisez l'hydratation progressive pour réduire les coûts de réhydratation dans les SPA.Petit conseil : en général, une stratégie fiable pour obtenir un meilleur score FID consiste à minimiser le travail sur le thread principal en divisant les groupes plus grands en groupes plus petits et en servant ce dont l'utilisateur a besoin quand il en a besoin, afin que les interactions de l'utilisateur ne soient pas retardées. . Nous en parlerons plus en détail ci-dessous.
- Décalage de mise en page cumulé ( CLS ) < 0,1.
Mesure la stabilité visuelle de l'interface utilisateur pour garantir des interactions fluides et naturelles, c'est-à-dire la somme totale de tous les scores de changement de mise en page individuels pour chaque changement de mise en page inattendu qui se produit pendant la durée de vie de la page. Un changement de mise en page individuel se produit chaque fois qu'un élément qui était déjà visible change de position sur la page. Il est noté en fonction de la taille du contenu et de la distance parcourue.
Ainsi, chaque fois qu'un décalage apparaît - par exemple, lorsque les polices de secours et les polices Web ont des métriques de police différentes, ou que des publicités, des intégrations ou des iframes arrivent en retard, ou que les dimensions d'image/vidéo ne sont pas réservées, ou que le CSS en retard oblige à repeindre, ou que des modifications sont injectées par JavaScript tardif — il a un impact sur le score CLS. La valeur recommandée pour une bonne expérience est un CLS < 0,1.
Il convient de noter que les Core Web Vitals sont censés évoluer dans le temps, avec un cycle annuel prévisible . Pour la mise à jour de la première année, nous pourrions nous attendre à ce que First Contentful Paint soit promu à Core Web Vitals, à un seuil FID réduit et à une meilleure prise en charge des applications d'une seule page. Nous pourrions également voir la réponse aux entrées de l'utilisateur après le chargement prendre plus de poids, ainsi que des considérations de sécurité, de confidentialité et d'accessibilité (!).
En relation avec Core Web Vitals, il existe de nombreuses ressources et articles utiles qui valent la peine d'être examinés :
- Web Vitals Leaderboard vous permet de comparer vos scores par rapport à la concurrence sur mobile, tablette, ordinateur de bureau et sur 3G et 4G.
- Core SERP Vitals, une extension Chrome qui affiche les Core Web Vitals de CrUX dans les résultats de recherche Google.
- Layout Shift GIF Generator qui visualise CLS avec un simple GIF (également disponible depuis la ligne de commande).
- La bibliothèque web-vitals peut collecter et envoyer des Core Web Vitals à Google Analytics, Google Tag Manager ou tout autre point de terminaison d'analyse.
- Analyzing Web Vitals with WebPageTest, dans lequel Patrick Meenan explore comment WebPageTest expose les données sur Core Web Vitals.
- Optimisation avec Core Web Vitals, une vidéo de 50 minutes avec Addy Osmani, dans laquelle il explique comment améliorer Core Web Vitals dans une étude de cas sur le commerce électronique.
- Cumulative Layout Shift in Practice et Cumulative Layout Shift in the Real World sont des articles complets de Nic Jansma, qui couvrent à peu près tout sur CLS et sa corrélation avec des mesures clés telles que le taux de rebond, le temps de session ou les clics de rage.
- What Forces Reflow, avec un aperçu des propriétés ou des méthodes, lorsqu'elles sont demandées/appelées en JavaScript, qui déclencheront le navigateur pour calculer de manière synchrone le style et la mise en page.
- CSS Triggers montre quelles propriétés CSS déclenchent Layout, Paint et Composite.
- Correction de l'instabilité de la mise en page est une procédure pas à pas d'utilisation de WebPageTest pour identifier et résoudre les problèmes d'instabilité de la mise en page.
- Cumulative Layout Shift, The Layout Instability Metric, un autre guide très détaillé de Boris Schapira sur CLS, comment il est calculé, comment le mesurer et comment l'optimiser.
- How To Improve Core Web Vitals, un guide détaillé de Simon Hearne sur chacune des mesures (y compris d'autres Web Vitals, telles que FCP, TTI, TBT), quand elles se produisent et comment elles sont mesurées.
Alors, les Core Web Vitals sont-ils les métriques ultimes à suivre ? Pas assez. Ils sont en effet déjà exposés dans la plupart des solutions et plates-formes RUM, notamment Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (déjà dans la vue pellicule), Newrelic, Shopify, Next.js, tous les outils Google (PageSpeed Insights, Lighthouse + CI, Search Console etc.) et bien d'autres.
Cependant, comme l'explique Katie Sylor-Miller, certains des principaux problèmes avec Core Web Vitals sont le manque de support multi-navigateur, nous ne mesurons pas vraiment le cycle de vie complet de l'expérience d'un utilisateur, et il est difficile de corréler les changements dans FID et CLS avec des résultats commerciaux.
Comme nous devrions nous attendre à ce que Core Web Vitals évolue, il semble tout à fait raisonnable de toujours combiner Web Vitals avec vos métriques personnalisées pour mieux comprendre où vous en êtes en termes de performances.
- Plus grande peinture de contenu ( LCP ) < 2,5 sec.
- Collectez des données sur un appareil représentatif de votre audience.
Pour recueillir des données précises, nous devons soigneusement choisir les appareils sur lesquels effectuer les tests. Dans la plupart des entreprises, cela signifie examiner les analyses et créer des profils d'utilisateurs basés sur les types d'appareils les plus courants. Pourtant, souvent, l'analyse seule ne fournit pas une image complète. Une partie importante du public cible peut abandonner le site (et ne pas y revenir) simplement parce que son expérience est trop lente et que ses appareils sont peu susceptibles d'apparaître comme les appareils les plus populaires dans l'analyse pour cette raison. Ainsi, mener en plus des recherches sur les appareils courants dans votre groupe cible pourrait être une bonne idée.À l'échelle mondiale en 2020, selon l'IDC, 84,8 % de tous les téléphones mobiles expédiés sont des appareils Android. Un consommateur moyen met à niveau son téléphone tous les 2 ans, et aux États-Unis, le cycle de remplacement du téléphone est de 33 mois. Les téléphones les plus vendus dans le monde coûteront en moyenne moins de 200 $.
Un appareil représentatif est donc un appareil Android âgé d' au moins 24 mois , coûtant 200 $ ou moins, fonctionnant en 3G lente, RTT 400 ms et transfert 400 kbps, juste pour être un peu plus pessimiste. Cela peut être très différent pour votre entreprise, bien sûr, mais c'est une approximation assez proche de la majorité des clients. En fait, il peut être judicieux de se pencher sur les meilleures ventes Amazon actuelles pour votre marché cible. ( Merci à Tim Kadlec, Henri Helvetica et Alex Russell pour les pointeurs ! ).
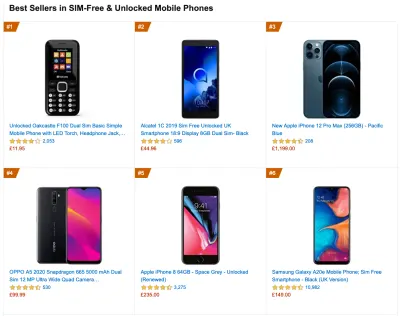
Lors de la création d'un nouveau site ou d'une nouvelle application, vérifiez toujours d'abord les meilleures ventes Amazon actuelles pour votre marché cible. ( Grand aperçu ) Quels appareils de test choisir alors ? Ceux qui correspondent bien au profil décrit ci-dessus. C'est une bonne option de choisir un Moto G4/G5 Plus légèrement plus ancien, un appareil Samsung de milieu de gamme (Galaxy A50, S8), un bon appareil de milieu de gamme comme un Nexus 5X, Xiaomi Mi A3 ou Xiaomi Redmi Note 7 et un appareil lent comme Alcatel 1X ou Cubot X19, peut-être dans un laboratoire d'appareils ouverts. Pour les tests sur des appareils à limitation thermique plus lents, vous pouvez également obtenir un Nexus 4, qui coûte environ 100 $.
Vérifiez également les chipsets utilisés dans chaque appareil et ne sur-représentez pas un chipset : quelques générations de Snapdragon et d'Apple ainsi que des Rockchip bas de gamme, Mediatek suffiraient (merci Patrick !) .
Si vous n'avez pas d'appareil à portée de main, émulez l'expérience mobile sur ordinateur en testant sur un réseau 3G étranglé (par exemple, 300 ms RTT, 1,6 Mbps en baisse, 0,8 Mbps en hausse) avec un processeur étranglé (ralentissement 5×). Basculez éventuellement vers la 3G normale, la 4G lente (par exemple, 170 ms RTT, 9 Mbps vers le bas, 9 Mbps vers le haut) et le Wi-Fi. Pour rendre l'impact sur les performances plus visible, vous pouvez même introduire les mardis 2G ou configurer un réseau 3G/4G limité dans votre bureau pour des tests plus rapides.
Gardez à l'esprit que sur un appareil mobile, nous devrions nous attendre à un ralentissement de 4 × à 5 × par rapport aux ordinateurs de bureau. Les appareils mobiles ont différents GPU, CPU, mémoire et différentes caractéristiques de batterie. C'est pourquoi il est important d'avoir un bon profil d'un appareil moyen et de toujours tester sur un tel appareil.
- Des outils de test synthétiques collectent des données de laboratoire dans un environnement reproductible avec des paramètres d'appareil et de réseau prédéfinis (par exemple, Lighthouse , Caliber , WebPageTest ) et
- Les outils de surveillance des utilisateurs réels ( RUM ) évaluent en permanence les interactions des utilisateurs et collectent des données de terrain (par exemple, SpeedCurve , New Relic - les outils fournissent également des tests synthétiques).
- utiliser Lighthouse CI pour suivre les scores de Lighthouse dans le temps (c'est assez impressionnant),
- exécutez Lighthouse dans GitHub Actions pour obtenir un rapport Lighthouse avec chaque PR,
- exécuter un audit de performance Lighthouse sur chaque page d'un site (via Lightouse Parade), avec une sortie enregistrée au format CSV,
- utilisez le calculateur de scores Lighthouse et les poids métriques Lighthouse si vous avez besoin d'approfondir vos connaissances.
- Lighthouse est également disponible pour Firefox, mais sous le capot, il utilise l'API PageSpeed Insights et génère un rapport basé sur un agent utilisateur Chrome 79 sans tête.

Heureusement, il existe de nombreuses options intéressantes qui vous aident à automatiser la collecte de données et à mesurer les performances de votre site Web au fil du temps en fonction de ces mesures. Gardez à l'esprit qu'une bonne image des performances couvre un ensemble de mesures de performances, de données de laboratoire et de données de terrain :
Le premier est particulièrement utile pendant le développement car il vous aidera à identifier, isoler et résoudre les problèmes de performances tout en travaillant sur le produit. Ce dernier est utile pour la maintenance à long terme car il vous aidera à comprendre vos goulots d'étranglement de performances au fur et à mesure qu'ils se produisent en direct - lorsque les utilisateurs accèdent réellement au site.
En exploitant les API RUM intégrées telles que la synchronisation de la navigation, la synchronisation des ressources, la synchronisation de la peinture, les tâches longues, etc., les outils de test synthétiques et RUM fournissent ensemble une image complète des performances de votre application. Vous pouvez utiliser Calibre, Treo, SpeedCurve, mPulse et Boomerang, Sitespeed.io, qui sont tous d'excellentes options pour la surveillance des performances. De plus, avec l'en-tête Server Timing, vous pouvez même surveiller les performances back-end et front-end en un seul endroit.
Note : Il est toujours plus prudent de choisir des régulateurs au niveau du réseau, externes au navigateur, car, par exemple, DevTools a des problèmes d'interaction avec HTTP/2 push, en raison de la façon dont il est implémenté ( merci, Yoav, Patrick !). Pour Mac OS, nous pouvons utiliser Network Link Conditioner, pour Windows Windows Traffic Shaper, pour Linux netem et pour FreeBSD dummynet.
Comme il est probable que vous effectuerez des tests dans Lighthouse, n'oubliez pas que vous pouvez :
- Configurez des profils "propre" et "client" pour les tests.
Lors de l'exécution de tests dans des outils de surveillance passifs, il est courant de désactiver les tâches antivirus et CPU en arrière-plan, de supprimer les transferts de bande passante en arrière-plan et de tester avec un profil utilisateur propre sans extensions de navigateur pour éviter les résultats faussés (dans Firefox et dans Chrome).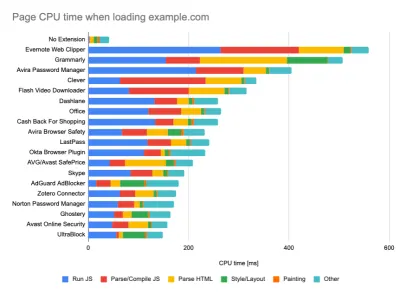
Le rapport de DebugBear met en évidence les 20 extensions les plus lentes, y compris les gestionnaires de mots de passe, les bloqueurs de publicités et les applications populaires comme Evernote et Grammarly. ( Grand aperçu ) Cependant, c'est aussi une bonne idée d'étudier les extensions de navigateur que vos clients utilisent fréquemment et de tester également avec des profils "clients" dédiés. En fait, certaines extensions peuvent avoir un impact profond sur les performances (rapport sur les performances des extensions Chrome 2020) sur votre application, et si vos utilisateurs les utilisent beaucoup, vous voudrez peut-être en tenir compte dès le départ. Par conséquent, les résultats de profil "propres" seuls sont trop optimistes et peuvent être écrasés dans des scénarios réels.
- Partagez les objectifs de performance avec vos collègues.
Assurez-vous que les objectifs de performance sont familiers à tous les membres de votre équipe pour éviter les malentendus sur toute la ligne. Chaque décision - qu'il s'agisse de conception, de marketing ou de quelque chose entre les deux - a des implications sur les performances , et la répartition des responsabilités et de la propriété sur l'ensemble de l'équipe rationaliserait ultérieurement les décisions axées sur les performances. Mapper les décisions de conception par rapport au budget de performance et aux priorités définies dès le début.
Table des matières
- Se préparer : planification et métriques
- Fixer des objectifs réalistes
- Définir l'environnement
- Optimisations des actifs
- Construire des optimisations
- Optimisations de livraison
- Mise en réseau, HTTP/2, HTTP/3
- Test et surveillance
- Victoires rapides
- Tout sur une seule page
- Télécharger la liste de contrôle (PDF, pages Apple, MS Word)
- Abonnez-vous à notre newsletter par e-mail pour ne pas manquer les prochains guides.