
Liste de contrôle des performances frontales 2021 (PDF, pages Apple, MS Word)
Publié: 2022-03-10Ce guide a été aimablement soutenu par nos amis de LogRocket, un service qui combine la surveillance des performances frontales, la relecture de session et l'analyse des produits pour vous aider à créer de meilleures expériences client. LogRocket suit les mesures clés, y compris. DOM complet, temps jusqu'au premier octet, premier délai d'entrée, CPU client et utilisation de la mémoire. Obtenez un essai gratuit de LogRocket dès aujourd'hui.

La performance Web est une bête délicate, n'est-ce pas ? Comment savons-nous réellement où nous en sommes en termes de performances et quels sont exactement nos goulots d'étranglement ? Est-ce un JavaScript coûteux, une livraison lente des polices Web, des images lourdes ou un rendu lent ? Avons-nous suffisamment optimisé avec le secouage d'arbres, le levage de portée, le fractionnement de code et tous les modèles de chargement fantaisistes avec observateur d'intersection, hydratation progressive, conseils clients, HTTP/3, service workers et - oh my - edge workers ? Et, plus important encore, par où commencer à améliorer les performances et comment établir une culture de la performance à long terme ?
À l'époque, la performance n'était souvent qu'une réflexion après coup . Souvent reporté jusqu'à la toute fin du projet, cela se résumait à la minification, la concaténation, l'optimisation des actifs et éventuellement quelques ajustements fins sur le fichier de config du serveur. Avec le recul, les choses semblent avoir changé de manière assez significative.
Les performances ne sont pas seulement une préoccupation technique : elles affectent tout, de l'accessibilité à la convivialité en passant par l'optimisation des moteurs de recherche, et lors de leur intégration dans le flux de travail, les décisions de conception doivent être éclairées par leurs implications en termes de performances. Les performances doivent être mesurées, surveillées et affinées en permanence , et la complexité croissante du Web pose de nouveaux défis qui rendent difficile le suivi des métriques, car les données varient considérablement en fonction de l'appareil, du navigateur, du protocole, du type de réseau et de la latence ( Les CDN, les FAI, les caches, les proxys, les pare-feu, les équilibreurs de charge et les serveurs jouent tous un rôle dans les performances).
Donc, si nous créions un aperçu de toutes les choses que nous devons garder à l'esprit lors de l'amélioration des performances - du tout début du projet jusqu'à la version finale du site Web - à quoi cela ressemblerait-il ? Vous trouverez ci-dessous une liste de contrôle des performances frontales (espérons-le impartiale et objective) pour 2021 - un aperçu mis à jour des problèmes que vous devrez peut-être prendre en compte pour vous assurer que vos temps de réponse sont rapides, que l'interaction de l'utilisateur est fluide et que vos sites ne le font pas. drainer la bande passante de l'utilisateur.
Table des matières
- Le tout sur des pages séparées
- Se préparer : planification et métriques
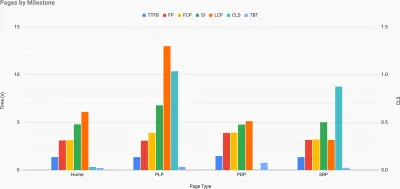
Culture de la performance, Core Web Vitals, profils de performance, CrUX, Lighthouse, FID, TTI, CLS, appareils. - Fixer des objectifs réalistes
Budgets de performance, objectifs de performance, framework RAIL, budgets 170Ko/30Ko. - Définir l'environnement
Choix d'un framework, coût de performance de base, Webpack, dépendances, CDN, architecture frontale, CSR, SSR, CSR + SSR, rendu statique, prérendu, modèle PRPL. - Optimisations des actifs
Brotli, AVIF, WebP, images réactives, AV1, chargement multimédia adaptatif, compression vidéo, polices Web, polices Google. - Construire des optimisations
Modules JavaScript, modèle module/nomodule, tree-shaking, code-splitting, scope-hoisting, Webpack, service différentiel, web worker, WebAssembly, bundles JavaScript, React, SPA, hydratation partielle, importation sur interaction, tiers, cache. - Optimisations de livraison
Chargement paresseux, observateur d'intersection, report du rendu et du décodage, CSS critique, streaming, conseils de ressources, changements de mise en page, service worker. - Mise en réseau, HTTP/2, HTTP/3
Agrafage OCSP, certificats EV/DV, packaging, IPv6, QUIC, HTTP/3. - Test et surveillance
Flux de travail d'audit, navigateurs proxy, page 404, invites de consentement aux cookies GDPR, diagnostics de performance CSS, accessibilité. - Victoires rapides
- Télécharger la liste de contrôle (PDF, pages Apple, MS Word)
- C'est parti !
(Vous pouvez également simplement télécharger la liste de contrôle PDF (166 Ko) ou télécharger le fichier Apple Pages modifiable (275 Ko) ou le fichier .docx (151 Ko). Bonne optimisation à tous !)
Se préparer : planification et métriques
Les micro-optimisations sont idéales pour maintenir les performances sur la bonne voie, mais il est essentiel d'avoir des objectifs clairement définis à l'esprit - des objectifs mesurables qui influenceraient toutes les décisions prises tout au long du processus. Il existe plusieurs modèles différents, et ceux discutés ci-dessous sont assez opiniâtres - assurez-vous simplement de définir vos propres priorités dès le début.
- Instaurer une culture de la performance.
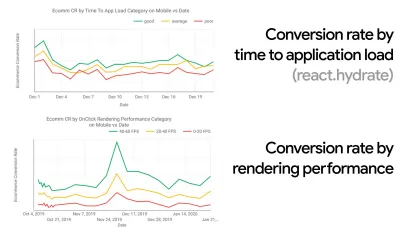
Dans de nombreuses organisations, les développeurs front-end savent exactement quels sont les problèmes sous-jacents courants et quelles stratégies doivent être utilisées pour les résoudre. Cependant, tant qu'il n'y aura pas d'approbation établie de la culture de la performance, chaque décision se transformera en un champ de bataille de départements, divisant l'organisation en silos. Vous avez besoin de l'adhésion des parties prenantes de l'entreprise, et pour l'obtenir, vous devez établir une étude de cas ou une preuve de concept sur la façon dont la vitesse - en particulier Core Web Vitals que nous aborderons en détail plus tard - bénéficie des mesures et des indicateurs de performance clés. ( KPI ) dont ils se soucient.Par exemple, pour rendre les performances plus tangibles, vous pouvez exposer l'impact sur les performances des revenus en montrant la corrélation entre le taux de conversion et le temps de chargement de l'application, ainsi que les performances de rendu. Ou le taux d'exploration du robot de recherche (PDF, pages 27 à 50).
Sans un alignement solide entre les équipes de développement/conception et les équipes commerciales/marketing, les performances ne se maintiendront pas à long terme. Étudiez les plaintes courantes qui parviennent au service client et à l'équipe de vente, étudiez les analyses pour les taux de rebond élevés et les baisses de conversion. Découvrez comment l'amélioration des performances peut aider à résoudre certains de ces problèmes courants. Ajustez l'argument en fonction du groupe d'intervenants auquel vous vous adressez.
Exécutez des expériences de performances et mesurez les résultats, à la fois sur mobile et sur ordinateur (par exemple, avec Google Analytics). Cela vous aidera à construire une étude de cas adaptée à l'entreprise avec des données réelles. De plus, l'utilisation des données d'études de cas et d'expériences publiées sur WPO Stats aidera à accroître la sensibilité des entreprises quant à l'importance des performances et à leur impact sur l'expérience utilisateur et les mesures commerciales. Dire que la performance compte à elle seule ne suffit cependant pas - vous devez également établir des objectifs mesurables et traçables et les observer au fil du temps.
Comment aller là? Dans son exposé sur la création de performances à long terme, Allison McKnight partage une étude de cas complète sur la manière dont elle a contribué à établir une culture de la performance chez Etsy (diapos). Plus récemment, Tammy Everts a parlé des habitudes des équipes de performance très efficaces dans les petites et les grandes organisations.
Tout en ayant ces conversations dans les organisations, il est important de garder à l'esprit que, tout comme l'UX est un éventail d'expériences, la performance Web est une distribution. Comme l'a noté Karolina Szczur, "s'attendre à ce qu'un seul chiffre puisse fournir une note à laquelle aspirer est une hypothèse erronée". Par conséquent, les objectifs de performance doivent être granulaires, traçables et tangibles.
- Objectif : être au moins 20 % plus rapide que votre concurrent le plus rapide.
Selon des recherches psychologiques, si vous voulez que les utilisateurs aient l'impression que votre site Web est plus rapide que celui de votre concurrent, vous devez être au moins 20 % plus rapide. Étudiez vos principaux concurrents, collectez des mesures sur leurs performances sur mobile et sur ordinateur et définissez des seuils qui vous aideraient à les dépasser. Pour obtenir des résultats et des objectifs précis, assurez-vous d'abord d'avoir une image complète de l'expérience de vos utilisateurs en étudiant vos analyses. Vous pouvez ensuite imiter l'expérience du 90e centile pour les tests.Pour avoir une bonne première impression des performances de vos concurrents, vous pouvez utiliser Chrome UX Report ( CrUX , un ensemble de données RUM prêt à l'emploi, introduction vidéo par Ilya Grigorik et guide détaillé par Rick Viscomi), ou Treo, un outil de surveillance RUM qui est alimenté par Chrome UX Report. Les données sont recueillies auprès des utilisateurs du navigateur Chrome, de sorte que les rapports seront spécifiques à Chrome, mais ils vous donneront une distribution assez complète des performances, surtout des scores Core Web Vitals, sur un large éventail de vos visiteurs. Notez que les nouveaux ensembles de données CrUX sont publiés le deuxième mardi de chaque mois .
Alternativement, vous pouvez également utiliser :
- Outil de comparaison de rapports Chrome UX d'Addy Osmani,
- Speed Scorecard (fournit également un estimateur d'impact sur les revenus),
- Comparaison de test d'expérience utilisateur réelle ou
- SiteSpeed CI (basé sur des tests synthétiques).
Remarque : Si vous utilisez Page Speed Insights ou l'API Page Speed Insights (non, ce n'est pas obsolète !), vous pouvez obtenir des données de performances CrUX pour des pages spécifiques au lieu de simplement les agrégats. Ces données peuvent être beaucoup plus utiles pour définir des objectifs de performance pour des actifs tels que "page de destination" ou "liste de produits". Et si vous utilisez CI pour tester les budgets, vous devez vous assurer que votre environnement testé correspond à CrUX si vous avez utilisé CrUX pour définir la cible ( merci Patrick Meenan ! ).
Si vous avez besoin d'aide pour montrer le raisonnement derrière la priorisation de la vitesse, ou si vous souhaitez visualiser la baisse du taux de conversion ou l'augmentation du taux de rebond avec des performances plus lentes, ou peut-être que vous auriez besoin de plaider en faveur d'une solution RUM dans votre organisation, Sergey Chernyshev a construit un calculateur de vitesse UX, un outil open source qui vous aide à simuler des données et à les visualiser pour faire passer votre message.
CrUX génère un aperçu des distributions de performances au fil du temps, avec le trafic collecté auprès des utilisateurs de Google Chrome. Vous pouvez créer le vôtre sur le tableau de bord Chrome UX. ( Grand aperçu ) 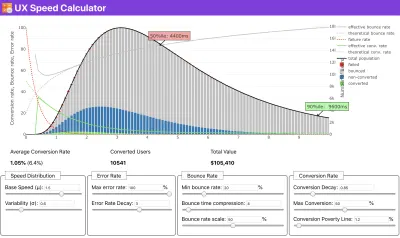
Juste au moment où vous avez besoin de justifier les performances pour faire passer votre message : le calculateur de vitesse UX visualise l'impact des performances sur les taux de rebond, la conversion et le revenu total, sur la base de données réelles. ( Grand aperçu ) Parfois, vous voudrez peut-être aller un peu plus loin, en combinant les données provenant de CrUX avec toutes les autres données dont vous disposez déjà pour déterminer rapidement où se situent les ralentissements, les angles morts et les inefficacités - pour vos concurrents ou pour votre projet. Dans son travail, Harry Roberts a utilisé une feuille de calcul de topographie de vitesse de site qu'il utilise pour décomposer les performances par types de pages clés et suivre les différentes métriques clés entre elles. Vous pouvez télécharger la feuille de calcul au format Google Sheets, Excel, document OpenOffice ou CSV.
Topographie de la vitesse du site, avec des mesures clés représentées pour les pages clés du site. ( Grand aperçu ) Et si vous voulez aller jusqu'au bout, vous pouvez exécuter un audit de performance Lighthouse sur chaque page d'un site (via Lightouse Parade), avec une sortie enregistrée au format CSV. Cela vous aidera à identifier les pages spécifiques (ou les types de pages) de vos concurrents qui fonctionnent moins bien ou mieux, et sur quoi vous voudrez peut-être concentrer vos efforts. (Pour votre propre site, il est probablement préférable d'envoyer des données à un point de terminaison d'analyse !).

Avec Lighthouse Parade, vous pouvez exécuter un audit de performance Lighthouse sur chaque page d'un site, avec une sortie enregistrée au format CSV. ( Grand aperçu ) Collectez des données, configurez une feuille de calcul, réduisez 20 % et définissez vos objectifs ( budgets de performance ) de cette façon. Vous avez maintenant quelque chose de mesurable à tester. Si vous gardez le budget à l'esprit et essayez de n'expédier que la charge utile minimale pour obtenir un temps d'interactivité rapide, alors vous êtes sur une voie raisonnable.
Besoin de ressources pour démarrer ?
- Addy Osmani a écrit un article très détaillé sur la façon de commencer la budgétisation des performances, comment quantifier l'impact des nouvelles fonctionnalités et par où commencer lorsque vous dépassez votre budget.
- Le guide de Lara Hogan sur la façon d'aborder les conceptions avec un budget de performance peut fournir des indications utiles aux concepteurs.
- Harry Roberts a publié un guide sur la configuration d'une feuille de calcul Google pour afficher l'impact des scripts tiers sur les performances, à l'aide de Request Map,
- Le calculateur de budget de performance de Jonathan Fielding, le calculateur de budget de performance de Katie Hempenius et les calories du navigateur peuvent aider à créer des budgets (merci à Karolina Szczur pour l'avertissement).
- Dans de nombreuses entreprises, les budgets de performance ne doivent pas être ambitieux, mais plutôt pragmatiques, servant de signe de maintien pour éviter de dépasser un certain point. Dans ce cas, vous pouvez choisir votre pire point de données au cours des deux dernières semaines comme seuil et partir de là. Budgets de performance, vous montre pragmatiquement une stratégie pour y parvenir.
- En outre, rendez visible à la fois le budget de performances et les performances actuelles en configurant des tableaux de bord avec des graphiques indiquant les tailles de build. Il existe de nombreux outils vous permettant d'y parvenir : le tableau de bord SiteSpeed.io (open source), SpeedCurve et Caliber ne sont que quelques-uns d'entre eux, et vous pouvez trouver d'autres outils sur perf.rocks.

Les calories du navigateur vous aident à définir un budget de performances et à mesurer si une page dépasse ces chiffres ou non. ( Grand aperçu ) Une fois que vous avez un budget en place, intégrez-les dans votre processus de construction avec Webpack Performance Hints et Bundlesize, Lighthouse CI, PWMetrics ou Sitespeed CI pour appliquer les budgets sur les demandes d'extraction et fournir un historique des scores dans les commentaires des relations publiques.
Pour exposer les budgets de performance à toute l'équipe, intégrez les budgets de performance dans Lighthouse via Lightwallet ou utilisez LHCI Action pour une intégration rapide des actions Github. Et si vous avez besoin de quelque chose de personnalisé, vous pouvez utiliser webpagetest-charts-api, une API de points de terminaison pour créer des graphiques à partir des résultats de WebPagetest.
Cependant, la sensibilisation aux performances ne doit pas provenir uniquement des budgets de performance. Tout comme Pinterest, vous pouvez créer une règle eslint personnalisée qui interdit l'importation à partir de fichiers et de répertoires connus pour être très dépendants et gonfler le bundle. Créez une liste de packages "sûrs" pouvant être partagés par toute l'équipe.
Pensez également aux tâches critiques des clients qui sont les plus bénéfiques pour votre entreprise. Étudiez, discutez et définissez des seuils de temps acceptables pour les actions critiques et établissez des repères de chronométrage utilisateur "UX ready" que l'ensemble de l'organisation a approuvés. Dans de nombreux cas, les parcours des utilisateurs toucheront au travail de nombreux départements différents, de sorte que l'alignement en termes de délais acceptables aidera à soutenir ou à empêcher les discussions sur les performances plus tard. Assurez-vous que les coûts supplémentaires des ressources et fonctionnalités ajoutées sont visibles et compris.
Alignez les efforts de performance avec d'autres initiatives technologiques, allant des nouvelles fonctionnalités du produit en cours de construction à la refactorisation pour atteindre de nouveaux publics mondiaux. Ainsi, chaque fois qu'une conversation sur le développement ultérieur a lieu, la performance fait également partie de cette conversation. Il est beaucoup plus facile d'atteindre les objectifs de performances lorsque la base de code est fraîche ou vient d'être refactorisée.
De plus, comme l'a suggéré Patrick Meenan, il vaut la peine de planifier une séquence de chargement et des compromis pendant le processus de conception. Si vous priorisez dès le début les pièces les plus critiques et définissez l'ordre dans lequel elles doivent apparaître, vous saurez également ce qui peut être retardé. Idéalement, cet ordre reflétera également la séquence de vos importations CSS et JavaScript, de sorte qu'il sera plus facile de les gérer pendant le processus de construction. Pensez également à ce que devrait être l'expérience visuelle dans les états "intermédiaires", pendant le chargement de la page (par exemple, lorsque les polices Web ne sont pas encore chargées).
Une fois que vous avez établi une solide culture de la performance dans votre organisation, visez à être 20 % plus rapide que vous-même pour garder les priorités intactes au fil du temps ( merci, Guy Podjarny ! ). Mais tenez compte des différents types et comportements d'utilisation de vos clients (ce que Tobias Baldauf a appelé cadence et cohortes), ainsi que du trafic des bots et des effets de saisonnalité.
Planification, planification, planification. Il pourrait être tentant de se lancer rapidement dans des optimisations rapides "à portée de main" - et cela pourrait être une bonne stratégie pour des gains rapides - mais il sera très difficile de faire de la performance une priorité sans planifier et définir des objectifs réalistes. - des objectifs de performance adaptés.
- Choisissez les bonnes métriques.
Tous les indicateurs n'ont pas la même importance. Étudiez les métriques les plus importantes pour votre application : généralement, elles seront définies par la rapidité avec laquelle vous pouvez commencer à rendre les pixels les plus importants de votre interface et la rapidité avec laquelle vous pouvez fournir une réactivité d'entrée pour ces pixels rendus. Cette connaissance vous donnera la meilleure cible d'optimisation pour les efforts en cours. En fin de compte, ce ne sont pas les événements de chargement ou les temps de réponse du serveur qui définissent l'expérience, mais la perception de la vivacité de l' interface .Qu'est-ce que ça veut dire? Plutôt que de vous concentrer sur le temps de chargement complet de la page (via les délais onLoad et DOMContentLoaded , par exemple), donnez la priorité au chargement de la page tel qu'il est perçu par vos clients. Cela signifie se concentrer sur un ensemble de mesures légèrement différent. En fait, choisir la bonne métrique est un processus sans gagnants évidents.
Sur la base des recherches de Tim Kadlec et des notes de Marcos Iglesias dans son discours, les mesures traditionnelles pourraient être regroupées en quelques ensembles. Habituellement, nous aurons besoin de tous pour obtenir une image complète des performances, et dans votre cas particulier, certains d'entre eux seront plus importants que d'autres.
- Les métriques basées sur la quantité mesurent le nombre de demandes, le poids et un score de performance. Bon pour déclencher des alarmes et surveiller les changements au fil du temps, pas si bon pour comprendre l'expérience utilisateur.
- Les métriques de jalon utilisent des états dans la durée de vie du processus de chargement, par exemple Time To First Byte et Time To Interactive . Bon pour décrire l'expérience utilisateur et le suivi, moins bon pour savoir ce qui se passe entre les jalons.
- Les métriques de rendu fournissent une estimation de la vitesse de rendu du contenu (par exemple, le temps de démarrage du rendu , l' indice de vitesse ). Bon pour mesurer et ajuster les performances de rendu, mais pas si bon pour mesurer quand un contenu important apparaît et peut être interagi avec.
- Les métriques personnalisées mesurent un événement particulier et personnalisé pour l'utilisateur, par exemple le temps du premier tweet de Twitter et PinnerWaitTime de Pinterest. Bon pour décrire précisément l'expérience utilisateur, pas si bon pour mettre à l'échelle les métriques et comparer avec les concurrents.
Pour compléter le tableau, nous recherchons généralement des mesures utiles parmi tous ces groupes. Généralement, les plus spécifiques et les plus pertinentes sont :
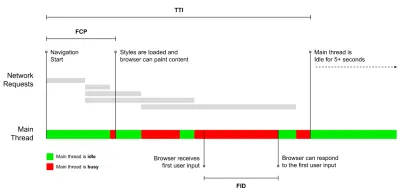
- Temps d'interactivité (TTI)
Au moment où la mise en page s'est stabilisée , les polices Web clés sont visibles et le fil principal est suffisamment disponible pour gérer les entrées de l'utilisateur - essentiellement le moment où un utilisateur peut interagir avec l'interface utilisateur. Les indicateurs clés pour comprendre combien d' attente un utilisateur doit attendre pour utiliser le site sans décalage. Boris Schapira a écrit un article détaillé sur la façon de mesurer le TTI de manière fiable. - Premier délai d'entrée (FID) ou réactivité d'entrée
Le moment entre le moment où un utilisateur interagit pour la première fois avec votre site et le moment où le navigateur est réellement en mesure de répondre à cette interaction. Complète très bien TTI car il décrit la partie manquante de l'image : ce qui se passe lorsqu'un utilisateur interagit réellement avec le site. Conçu comme une métrique RUM uniquement. Il existe une bibliothèque JavaScript pour mesurer le FID dans le navigateur. - La plus grande peinture de contenu (LCP)
Marque le point dans la chronologie de chargement de la page où le contenu important de la page a probablement été chargé. L'hypothèse est que l'élément le plus important de la page est le plus grand visible dans la fenêtre d'affichage de l'utilisateur. Si les éléments sont rendus à la fois au-dessus et au-dessous du pli, seule la partie visible est considérée comme pertinente. - Temps de blocage total ( TBT )
Une métrique qui aide à quantifier la gravité de la non-interactivité d'une page avant qu'elle ne devienne interactive de manière fiable (c'est-à-dire que le fil principal a été exempt de toute tâche s'exécutant sur 50 ms ( tâches longues ) pendant au moins 5 s). La métrique mesure le temps total entre la première peinture et le temps d'interaction (TTI) où le thread principal a été bloqué suffisamment longtemps pour empêcher la réactivité des entrées. Il n'est donc pas étonnant qu'un TBT faible soit un bon indicateur de bonnes performances. (merci, Artem, Phil) - Décalage de mise en page cumulatif ( CLS )
La métrique met en évidence la fréquence à laquelle les utilisateurs subissent des changements de mise en page inattendus ( refusions ) lorsqu'ils accèdent au site. Il examine les éléments instables et leur impact sur l'expérience globale. Plus le score est bas, mieux c'est. - Indice de vitesse
Mesure la rapidité avec laquelle le contenu de la page est rempli visuellement ; plus le score est bas, mieux c'est. Le score de l'indice de vitesse est calculé en fonction de la vitesse de progression visuelle , mais il ne s'agit que d'une valeur calculée. Il est également sensible à la taille de la fenêtre d'affichage, vous devez donc définir une gamme de configurations de test qui correspondent à votre public cible. Notez qu'il devient moins important avec LCP devenant une métrique plus pertinente ( merci, Boris, Artem ! ). - Temps CPU passé
Une métrique qui montre combien de fois et combien de temps le thread principal est bloqué, travaillant sur la peinture, le rendu, les scripts et le chargement. Un temps CPU élevé est un indicateur clair d'une expérience janky , c'est-à-dire lorsque l'utilisateur subit un décalage notable entre son action et une réponse. Avec WebPageTest, vous pouvez sélectionner "Capture Dev Tools Timeline" dans l'onglet "Chrome" pour exposer la répartition du fil principal lorsqu'il s'exécute sur n'importe quel appareil utilisant WebPageTest. - Coûts CPU au niveau des composants
Tout comme avec le temps CPU dépensé , cette métrique, proposée par Stoyan Stefanov, explore l' impact de JavaScript sur le CPU . L'idée est d'utiliser le nombre d'instructions CPU par composant pour comprendre son impact sur l'expérience globale, de manière isolée. Pourrait être implémenté en utilisant Puppeteer et Chrome. - Indice de frustration
Alors que de nombreuses métriques présentées ci-dessus expliquent quand un événement particulier se produit, FrustrationIndex de Tim Vereecke examine les écarts entre les métriques au lieu de les regarder individuellement. Il examine les étapes clés perçues par l'utilisateur final, telles que le titre est visible, le premier contenu est visible, visuellement prêt et la page semble prête et calcule un score indiquant le niveau de frustration lors du chargement d'une page. Plus l'écart est grand, plus le risque qu'un utilisateur soit frustré est grand. Potentiellement un bon KPI pour l'expérience utilisateur. Tim a publié un article détaillé sur FrustrationIndex et son fonctionnement. - Impact du poids de l'annonce
Si votre site dépend des revenus générés par la publicité, il est utile de suivre le poids du code lié à la publicité. Le script de Paddy Ganti construit deux URL (une normale et une bloquant les publicités), invite la génération d'une comparaison vidéo via WebPageTest et signale un delta. - Métriques de déviation
Comme l'ont noté les ingénieurs de Wikipédia, les données sur la variance de vos résultats pourraient vous informer sur la fiabilité de vos instruments et sur l'attention que vous devez accorder aux écarts et aux valeurs aberrantes. Un écart important est un indicateur des ajustements nécessaires dans la configuration. Cela permet également de comprendre si certaines pages sont plus difficiles à mesurer de manière fiable, par exemple en raison de scripts tiers provoquant des variations importantes. Il peut également être judicieux de suivre la version du navigateur pour comprendre les baisses de performances lorsqu'une nouvelle version du navigateur est déployée. - Métriques personnalisées
Les métriques personnalisées sont définies par les besoins de votre entreprise et l'expérience client. Cela vous oblige à identifier les pixels importants , les scripts critiques , le CSS nécessaire et les actifs pertinents et à mesurer la rapidité avec laquelle ils sont livrés à l'utilisateur. Pour celui-ci, vous pouvez surveiller les temps de rendu des héros ou utiliser l'API de performance, en marquant des horodatages particuliers pour les événements importants pour votre entreprise. En outre, vous pouvez collecter des métriques personnalisées avec WebPagetest en exécutant du JavaScript arbitraire à la fin d'un test.
Notez que la première peinture significative (FMP) n'apparaît pas dans l'aperçu ci-dessus. Il fournissait un aperçu de la rapidité avec laquelle le serveur produit des données. Un FMP long indiquait généralement que JavaScript bloquait le thread principal, mais pouvait également être lié à des problèmes de back-end/serveur. Cependant, la métrique a été obsolète récemment car elle semble ne pas être précise dans environ 20 % des cas. Il a été effectivement remplacé par LCP qui est à la fois plus fiable et plus facile à raisonner. Il n'est plus pris en charge dans Lighthouse. Vérifiez les dernières mesures et recommandations de performances centrées sur l'utilisateur pour vous assurer que vous êtes sur la page de sécurité ( merci, Patrick Meenan ).
Steve Souders a une explication détaillée de bon nombre de ces mesures. Il est important de noter que tandis que le Time-To-Interactive est mesuré en exécutant des audits automatisés dans ce que l'on appelle l'environnement de laboratoire , le premier délai d'entrée représente l'expérience utilisateur réelle , les utilisateurs réels subissant un décalage notable. En général, c'est probablement une bonne idée de toujours mesurer et suivre les deux.
Selon le contexte de votre application, les métriques préférées peuvent différer : par exemple, pour l'interface utilisateur de Netflix TV, la réactivité des touches, l'utilisation de la mémoire et le TTI sont plus critiques, et pour Wikipedia, les premières/dernières modifications visuelles et les métriques de temps CPU dépensé sont plus importantes.
Remarque : le FID et le TTI ne tiennent pas compte du comportement de défilement ; le défilement peut se produire indépendamment car il est hors fil principal, donc pour de nombreux sites de consommation de contenu, ces mesures peuvent être beaucoup moins importantes ( merci, Patrick ! ).
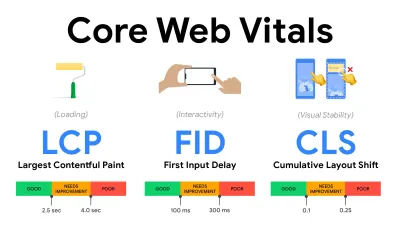
- Mesurer et optimiser les Core Web Vitals .
Pendant longtemps, les mesures de performances étaient assez techniques, se concentrant sur la vision technique de la rapidité de réponse des serveurs et de la rapidité de chargement des navigateurs. Les mesures ont changé au fil des ans - essayant de trouver un moyen de capturer l'expérience utilisateur réelle , plutôt que les horaires du serveur. En mai 2020, Google a annoncé Core Web Vitals, un ensemble de nouvelles mesures de performances axées sur l'utilisateur, chacune représentant une facette distincte de l'expérience utilisateur.Pour chacun d'eux, Google recommande une gamme d'objectifs de vitesse acceptables. Au moins 75 % de toutes les pages vues doivent dépasser la plage Bon pour réussir cette évaluation. Ces mesures ont rapidement gagné du terrain, et avec Core Web Vitals devenant des signaux de classement pour la recherche Google en mai 2021 ( mise à jour de l'algorithme de classement Page Experience ), de nombreuses entreprises ont tourné leur attention vers leurs scores de performance.
Décomposons chacun des Core Web Vitals, un par un, ainsi que des techniques et des outils utiles pour optimiser vos expériences avec ces mesures à l'esprit. (Il convient de noter que vous obtiendrez de meilleurs scores Core Web Vitals en suivant un conseil général dans cet article.)
- Plus grande peinture de contenu ( LCP ) < 2,5 sec.
Mesure le chargement d'une page et signale le temps de rendu de la plus grande image ou du bloc de texte visible dans la fenêtre d'affichage. Par conséquent, LCP est affecté par tout ce qui retarde le rendu d'informations importantes - qu'il s'agisse de temps de réponse lents du serveur, de blocage de CSS, de JavaScript en vol (première ou tierce partie), de chargement de polices Web, d'opérations de rendu ou de peinture coûteuses, d'opérations paresseuses -images chargées, écrans squelettes ou rendu côté client.
Pour une bonne expérience, LCP doit se produire dans les 2,5 secondes suivant le premier chargement de la page. Cela signifie que nous devons rendre la première partie visible de la page le plus tôt possible. Cela nécessitera un CSS critique personnalisé pour chaque modèle, l'orchestration de l'ordre<head>et la prélecture des actifs critiques (nous les aborderons plus tard).La principale raison d'un faible score LCP est généralement les images. Délivrer un LCP en <2,5s sur Fast 3G — hébergé sur un serveur bien optimisé, le tout statique sans rendu côté client et avec une image provenant d'un CDN image dédié — signifie que la taille théorique maximale de l'image n'est que d'environ 144Ko . C'est pourquoi les images réactives sont importantes, ainsi que le préchargement précoce des images critiques (avec
preload).Petite astuce : pour découvrir ce qui est considéré comme LCP sur une page, dans DevTools, vous pouvez survoler le badge LCP sous "Timings" dans le panneau de performances ( merci, Tim Kadlec !).
- Premier délai d'entrée ( FID ) < 100 ms.
Mesure la réactivité de l'interface utilisateur, c'est-à-dire la durée pendant laquelle le navigateur a été occupé par d'autres tâches avant de pouvoir réagir à un événement d'entrée discret de l'utilisateur comme un appui ou un clic. Il est conçu pour capturer les retards résultant de l'occupation du thread principal, en particulier lors du chargement de la page.
L'objectif est de rester dans les 50 à 100 ms pour chaque interaction. Pour y arriver, nous devons identifier les tâches longues (bloquer le thread principal pendant plus de 50 ms) et les décomposer, diviser le code d'un paquet en plusieurs morceaux, réduire le temps d'exécution de JavaScript, optimiser la récupération des données, différer l'exécution des scripts de tiers. , déplacez JavaScript vers le thread d'arrière-plan avec les agents Web et utilisez l'hydratation progressive pour réduire les coûts de réhydratation dans les SPA.Petit conseil : en général, une stratégie fiable pour obtenir un meilleur score FID consiste à minimiser le travail sur le thread principal en divisant les groupes plus grands en groupes plus petits et en servant ce dont l'utilisateur a besoin quand il en a besoin, afin que les interactions de l'utilisateur ne soient pas retardées. . Nous en parlerons plus en détail ci-dessous.
- Décalage de mise en page cumulé ( CLS ) < 0,1.
Mesure la stabilité visuelle de l'interface utilisateur pour garantir des interactions fluides et naturelles, c'est-à-dire la somme totale de tous les scores de changement de mise en page individuels pour chaque changement de mise en page inattendu qui se produit pendant la durée de vie de la page. Un changement de mise en page individuel se produit chaque fois qu'un élément qui était déjà visible change de position sur la page. Il est noté en fonction de la taille du contenu et de la distance parcourue.
Ainsi, chaque fois qu'un décalage apparaît - par exemple, lorsque les polices de secours et les polices Web ont des métriques de police différentes, ou que des publicités, des intégrations ou des iframes arrivent en retard, ou que les dimensions d'image/vidéo ne sont pas réservées, ou que le CSS en retard oblige à repeindre, ou que des modifications sont injectées par JavaScript tardif — il a un impact sur le score CLS. La valeur recommandée pour une bonne expérience est un CLS < 0,1.
Il convient de noter que les Core Web Vitals sont censés évoluer dans le temps, avec un cycle annuel prévisible . Pour la mise à jour de la première année, nous pourrions nous attendre à ce que First Contentful Paint soit promu à Core Web Vitals, à un seuil FID réduit et à une meilleure prise en charge des applications d'une seule page. We might also see the responding to user inputs after load gaining more weight, along with security, privacy and accessibility (!) considerations.
Related to Core Web Vitals, there are plenty of useful resources and articles that are worth looking into:
- Web Vitals Leaderboard allows you to compare your scores against competition on mobile, tablet, desktop, and on 3G and 4G.
- Core SERP Vitals, a Chrome extension that shows the Core Web Vitals from CrUX in the Google Search Results.
- Layout Shift GIF Generator that visualizes CLS with a simple GIF (also available from the command line).
- web-vitals library can collect and send Core Web Vitals to Google Analytics, Google Tag Manager or any other analytics endpoint.
- Analyzing Web Vitals with WebPageTest, in which Patrick Meenan explores how WebPageTest exposes data about Core Web Vitals.
- Optimizing with Core Web Vitals, a 50-min video with Addy Osmani, in which he highlights how to improve Core Web Vitals in an eCommerce case-study.
- Cumulative Layout Shift in Practice and Cumulative Layout Shift in the Real World are comprehensive articles by Nic Jansma, which cover pretty much everything about CLS and how it correlates with key metrics such as Bounce Rate, Session Time or Rage Clicks.
- What Forces Reflow, with an overview of properties or methods, when requested/called in JavaScript, that will trigger the browser to synchronously calculate the style and layout.
- CSS Triggers shows which CSS properties trigger Layout, Paint and Composite.
- Fixing Layout Instability is a walkthrough of using WebPageTest to identify and fix layout instability issues.
- Cumulative Layout Shift, The Layout Instability Metric, another very detailed guide by Boris Schapira on CLS, how it's calcualted, how to measure and how to optimize for it.
- How To Improve Core Web Vitals, a detailed guide by Simon Hearne on each of the metrics (including other Web Vitals, such as FCP, TTI, TBT), when they occur and how they are measured.
So, are Core Web Vitals the ultimate metrics to follow ? Not quite. They are indeed exposed in most RUM solutions and platforms already, including Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (in the filmstrip view already), Newrelic, Shopify, Next.js, all Google tools (PageSpeed Insights, Lighthouse + CI, Search Console etc.) and many others.
However, as Katie Sylor-Miller explains, some of the main problems with Core Web Vitals are the lack of cross-browser support, we don't really measure the full lifecycle of a user's experience, plus it's difficult to correlate changes in FID and CLS with business outcomes.
As we should be expecting Core Web Vitals to evolve, it seems only reasonable to always combine Web Vitals with your custom-tailored metrics to get a better understanding of where you stand in terms of performance.
- Plus grande peinture de contenu ( LCP ) < 2,5 sec.
- Gather data on a device representative of your audience.
To gather accurate data, we need to thoroughly choose devices to test on. In most companies, that means looking into analytics and creating user profiles based on most common device types. Yet often, analytics alone doesn't provide a complete picture. A significant portion of the target audience might be abandoning the site (and not returning back) just because their experience is too slow, and their devices are unlikely to show up as the most popular devices in analytics for that reason. So, additionally conducting research on common devices in your target group might be a good idea.Globally in 2020, according to the IDC, 84.8% of all shipped mobile phones are Android devices. An average consumer upgrades their phone every 2 years, and in the US phone replacement cycle is 33 months. Average bestselling phones around the world will cost under $200.
A representative device, then, is an Android device that is at least 24 months old , costing $200 or less, running on slow 3G, 400ms RTT and 400kbps transfer, just to be slightly more pessimistic. This might be very different for your company, of course, but that's a close enough approximation of a majority of customers out there. In fact, it might be a good idea to look into current Amazon Best Sellers for your target market. ( Thanks to Tim Kadlec, Henri Helvetica and Alex Russell for the pointers! ).
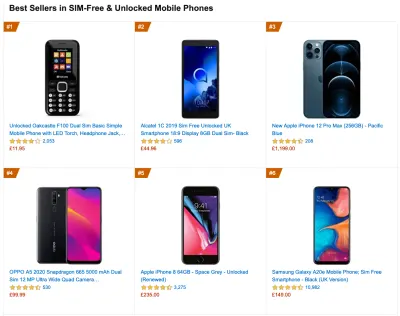
When building a new site or app, always check current Amazon Best Sellers for your target market first. ( Grand aperçu ) What test devices to choose then? The ones that fit well with the profile outlined above. It's a good option to choose a slightly older Moto G4/G5 Plus, a mid-range Samsung device (Galaxy A50, S8), a good middle-of-the-road device like a Nexus 5X, Xiaomi Mi A3 or Xiaomi Redmi Note 7 and a slow device like Alcatel 1X or Cubot X19, perhaps in an open device lab. For testing on slower thermal-throttled devices, you could also get a Nexus 4, which costs just around $100.
Also, check the chipsets used in each device and do not over-represent one chipset : a few generations of Snapdragon and Apple as well as low-end Rockchip, Mediatek would be enough (thanks, Patrick!) .
If you don't have a device at hand, emulate mobile experience on desktop by testing on a throttled 3G network (eg 300ms RTT, 1.6 Mbps down, 0.8 Mbps up) with a throttled CPU (5× slowdown). Eventually switch over to regular 3G, slow 4G (eg 170ms RTT, 9 Mbps down, 9Mbps up), and Wi-Fi. To make the performance impact more visible, you could even introduce 2G Tuesdays or set up a throttled 3G/4G network in your office for faster testing.
Keep in mind that on a mobile device, we should be expecting a 4×–5× slowdown compared to desktop machines. Mobile devices have different GPUs, CPU, memory and different battery characteristics. That's why it's important to have a good profile of an average device and always test on such a device.
- Synthetic testing tools collect lab data in a reproducible environment with predefined device and network settings (eg Lighthouse , Calibre , WebPageTest ) and
- Real User Monitoring ( RUM ) tools evaluate user interactions continuously and collect field data (eg SpeedCurve , New Relic — the tools provide synthetic testing, too).
- use Lighthouse CI to track Lighthouse scores over time (it's quite impressive),
- run Lighthouse in GitHub Actions to get a Lighthouse report alongside every PR,
- run a Lighthouse performance audit on every page of a site (via Lightouse Parade), with an output saved as CSV,
- use Lighthouse Scores Calculator and Lighthouse metric weights if you need to dive into more detail.
- Lighthouse is available for Firefox as well, but under the hood it uses the PageSpeed Insights API and generates a report based on a headless Chrome 79 User-Agent.

Luckily, there are many great options that help you automate the collection of data and measure how your website performs over time according to these metrics. Keep in mind that a good performance picture covers a set of performance metrics, lab data and field data:
The former is particularly useful during development as it will help you identify, isolate and fix performance issues while working on the product. The latter is useful for long-term maintenance as it will help you understand your performance bottlenecks as they are happening live — when users actually access the site.
By tapping into built-in RUM APIs such as Navigation Timing, Resource Timing, Paint Timing, Long Tasks, etc., synthetic testing tools and RUM together provide a complete picture of performance in your application. You could use Calibre, Treo, SpeedCurve, mPulse and Boomerang, Sitespeed.io, which all are great options for performance monitoring. Furthermore, with Server Timing header, you could even monitor back-end and front-end performance all in one place.
Note : It's always a safer bet to choose network-level throttlers, external to the browser, as, for example, DevTools has issues interacting with HTTP/2 push, due to the way it's implemented ( thanks, Yoav, Patrick !). For Mac OS, we can use Network Link Conditioner, for Windows Windows Traffic Shaper, for Linux netem, and for FreeBSD dummynet.
As it's likely that you'll be testing in Lighthouse, keep in mind that you can:
- Set up "clean" and "customer" profiles for testing.
While running tests in passive monitoring tools, it's a common strategy to turn off anti-virus and background CPU tasks, remove background bandwidth transfers and test with a clean user profile without browser extensions to avoid skewed results (in Firefox, and in Chrome).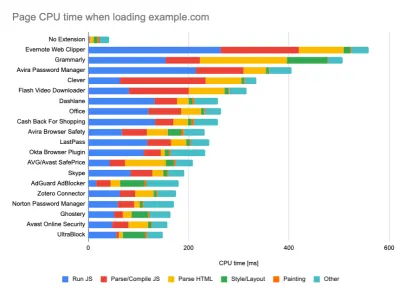
DebugBear's report highlights 20 slowest extensions, including password managers, ad-blockers and popular applications like Evernote and Grammarly. ( Grand aperçu ) However, it's also a good idea to study which browser extensions your customers use frequently, and test with dedicated "customer" profiles as well. In fact, some extensions might have a profound performance impact (2020 Chrome Extension Performance Report) on your application, and if your users use them a lot, you might want to account for it up front. Hence, "clean" profile results alone are overly optimistic and can be crushed in real-life scenarios.
- Partagez les objectifs de performance avec vos collègues.
Assurez-vous que les objectifs de performance sont familiers à tous les membres de votre équipe pour éviter les malentendus sur toute la ligne. Chaque décision - qu'il s'agisse de conception, de marketing ou de quelque chose entre les deux - a des implications sur les performances , et la répartition des responsabilités et de la propriété sur l'ensemble de l'équipe rationaliserait ultérieurement les décisions axées sur les performances. Mapper les décisions de conception par rapport au budget de performance et aux priorités définies dès le début.
Fixer des objectifs réalistes
- Temps de réponse de 100 millisecondes, 60 ips.
Pour qu'une interaction soit fluide, l'interface dispose de 100 ms pour répondre à l'entrée de l'utilisateur. Plus longtemps que cela, et l'utilisateur perçoit l'application comme lente. Le RAIL, un modèle de performance centré sur l'utilisateur, vous donne des objectifs sains : pour permettre une réponse <100 millisecondes, la page doit rendre le contrôle au thread principal au plus tard toutes les <50 millisecondes. La latence d'entrée estimée nous indique si nous atteignons ce seuil, et idéalement, il devrait être inférieur à 50 ms. Pour les points à haute pression comme l'animation, il est préférable de ne rien faire d'autre là où vous le pouvez et le minimum absolu là où vous ne le pouvez pas.
RAIL, un modèle de performance centré sur l'utilisateur. De plus, chaque image d'animation doit être terminée en moins de 16 millisecondes, atteignant ainsi 60 images par seconde (1 seconde ÷ 60 = 16,6 millisecondes) - de préférence en moins de 10 millisecondes. Étant donné que le navigateur a besoin de temps pour peindre le nouveau cadre à l'écran, votre code doit terminer son exécution avant d'atteindre la barre des 16,6 millisecondes. Nous commençons à avoir des conversations sur 120 ips (par exemple, les écrans de l'iPad Pro fonctionnent à 120 Hz) et Surma a couvert certaines solutions de performances de rendu pour 120 ips, mais ce n'est probablement pas une cible que nous envisageons pour l'instant .
Soyez pessimiste dans les attentes en matière de performances, mais soyez optimiste dans la conception de l'interface et utilisez judicieusement le temps d'inactivité (cochez idlize, idle-until-urgent et react-idle). De toute évidence, ces objectifs s'appliquent aux performances d'exécution plutôt qu'aux performances de chargement.
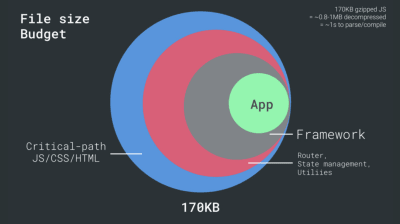
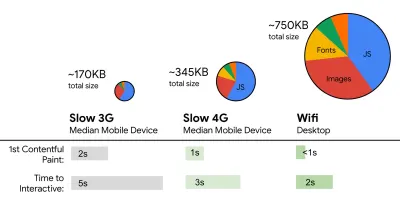
- FID < 100 ms, LCP < 2,5 s, TTI < 5 s sur 3G, budget de taille de fichier critique < 170 Ko (gzippé).
Bien que cela puisse être très difficile à atteindre, un bon objectif ultime serait le temps d'interaction de moins de 5 ans, et pour les visites répétées, visez moins de 2 ans (réalisable uniquement avec un travailleur de service). Visez la plus grande peinture de contenu de moins de 2,5 secondes et minimisez le temps de blocage total et le décalage de mise en page cumulé . Un délai de première entrée acceptable est inférieur à 100 ms–70 ms. Comme mentionné ci-dessus, nous envisageons comme référence un téléphone Android à 200 $ (par exemple Moto G4) sur un réseau 3G lent, émulé à 400 ms RTT et une vitesse de transfert de 400 kbps.Nous avons deux contraintes majeures qui façonnent effectivement un objectif raisonnable pour une livraison rapide du contenu sur le Web. D'une part, nous avons des contraintes de livraison réseau dues à TCP Slow Start. Les 14 premiers Ko du HTML — 10 paquets TCP, chacun de 1460 octets, faisant environ 14,25 Ko, bien qu'il ne faut pas les prendre au pied de la lettre — est le morceau de charge utile le plus critique, et la seule partie du budget qui peut être livrée dans le premier aller-retour ( c'est tout ce que vous obtenez en 1 seconde à 400 ms RTT en raison des temps de réveil mobiles).

Avec les connexions TCP, nous commençons avec une petite fenêtre de congestion et la doublons à chaque aller-retour. Dans le tout premier aller-retour, nous pouvons mettre 14 Ko. Tiré de : Réseaux de navigateur haute performance par Ilya Grigorik. ( Grand aperçu ) ( Remarque : étant donné que TCP sous-utilise généralement la connexion réseau de manière significative, Google a développé TCP Bottleneck Bandwidth and RRT ( BBR ), un algorithme de contrôle de flux TCP à retard TCP. Conçu pour le Web moderne, il répond à la congestion réelle, plutôt que la perte de paquets comme le fait TCP, il est nettement plus rapide, avec un débit plus élevé et une latence plus faible - et l'algorithme fonctionne différemment ( merci, Victor, Barry ! )
D'autre part, nous avons des contraintes matérielles sur la mémoire et le processeur en raison de l'analyse JavaScript et des temps d'exécution (nous en reparlerons en détail plus tard). Pour atteindre les objectifs énoncés dans le premier paragraphe, nous devons tenir compte du budget de taille de fichier critique pour JavaScript. Les opinions varient sur ce que devrait être ce budget (et cela dépend fortement de la nature de votre projet), mais un budget de 170 Ko JavaScript gzippé prendrait déjà jusqu'à 1 seconde pour être analysé et compilé sur un téléphone de milieu de gamme. En supposant que 170 Ko s'agrandissent à 3 fois cette taille lorsqu'ils sont décompressés (0,7 Mo), cela pourrait déjà sonner le glas d'une expérience utilisateur "décente" sur un Moto G4/G5 Plus.
Dans le cas du site Web de Wikipédia, en 2020, à l'échelle mondiale, l'exécution du code a été 19 % plus rapide pour les utilisateurs de Wikipédia. Ainsi, si vos mesures de performance Web d'une année sur l'autre restent stables, c'est généralement un signe d'avertissement car vous régressez en fait à mesure que l'environnement s'améliore (détails dans un article de blog de Gilles Dubuc).
Si vous souhaitez cibler des marchés en croissance tels que l'Asie du Sud-Est, l'Afrique ou l'Inde, vous devrez vous pencher sur un ensemble de contraintes très différent. Addy Osmani couvre les principales contraintes des téléphones multifonctions, telles que le peu d'appareils bon marché et de haute qualité, l'indisponibilité de réseaux de haute qualité et les données mobiles coûteuses, ainsi que le budget PRPL-30 et les directives de développement pour ces environnements.
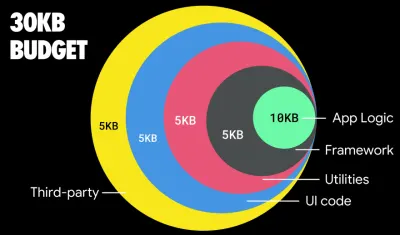
Selon Addy Osmani, une taille recommandée pour les routes à chargement différé est également inférieure à 35 Ko. ( Grand aperçu ) 
Addy Osmani suggère un budget de performances PRPL-30 (30 Ko gzippé + pack initial minifié) si vous ciblez un téléphone polyvalent. ( Grand aperçu ) En fait, Alex Russell de Google recommande de viser 130 à 170 Ko gzippés comme limite supérieure raisonnable. Dans des scénarios réels, la plupart des produits ne sont même pas proches : la taille médiane d'un bundle est aujourd'hui d'environ 452 Ko, ce qui représente une augmentation de 53,6 % par rapport au début de 2015. Sur un appareil mobile de classe moyenne, cela représente 12 à 20 secondes pour Time -À-Interactif .
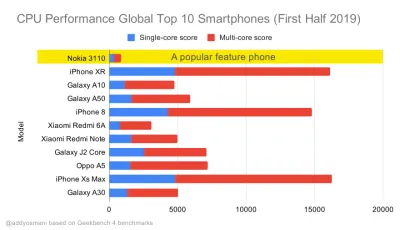
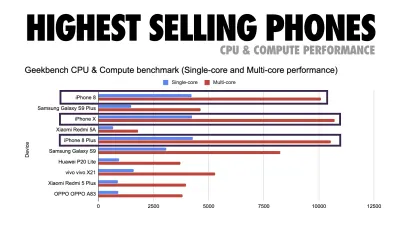
Références de performance du processeur Geekbench pour les smartphones les plus vendus dans le monde en 2019. JavaScript met l'accent sur les performances monocœur (rappelez-vous, il est intrinsèquement plus monothread que le reste de la plate-forme Web) et est lié au processeur. De l'article d'Addy "Chargement rapide des pages Web sur un téléphone à 20 $". ( Grand aperçu ) Nous pourrions également aller au-delà du budget de la taille du forfait. Par exemple, nous pourrions définir des budgets de performances basés sur les activités du thread principal du navigateur, c'est-à-dire le temps de peinture avant le démarrage du rendu, ou traquer les porcs CPU frontaux. Des outils tels que Calibre, SpeedCurve et Bundlesize peuvent vous aider à contrôler vos budgets et peuvent être intégrés à votre processus de construction.
Enfin, un budget de performance ne devrait probablement pas être une valeur fixe . En fonction de la connexion réseau, les budgets de performances doivent s'adapter, mais la charge utile sur une connexion plus lente est beaucoup plus "coûteuse", quelle que soit la façon dont elle est utilisée.
Remarque : Il peut sembler étrange de définir des budgets aussi rigides à une époque où le HTTP/2 est généralisé, les 5G et HTTP/3 à venir, les téléphones mobiles en évolution rapide et les SPA en plein essor. Cependant, ils semblent raisonnables lorsque nous traitons de la nature imprévisible du réseau et du matériel, y compris tout, des réseaux encombrés à l'infrastructure en développement lent, aux plafonds de données, aux navigateurs proxy, au mode de sauvegarde des données et aux frais d'itinérance sournois.
Définir l'environnement
- Choisissez et configurez vos outils de construction.
Ne faites pas trop attention à ce qui est censé être cool de nos jours. Tenez-vous en à votre environnement de construction, que ce soit Grunt, Gulp, Webpack, Parcel ou une combinaison d'outils. Tant que vous obtenez les résultats dont vous avez besoin et que vous n'avez aucun problème à maintenir votre processus de construction, tout va bien.Parmi les outils de build, Rollup continue de gagner du terrain, tout comme Snowpack, mais Webpack semble être le plus établi, avec littéralement des centaines de plugins disponibles pour optimiser la taille de vos builds. Attention à la feuille de route Webpack 2021.
L'une des stratégies les plus notables apparues récemment est la segmentation granulaire avec Webpack dans Next.js et Gatsby pour minimiser le code en double. Par défaut, les modules qui ne sont pas partagés dans chaque point d'entrée peuvent être demandés pour les routes qui ne l'utilisent pas. Cela finit par devenir une surcharge car plus de code est téléchargé que nécessaire. Avec la segmentation granulaire dans Next.js, nous pouvons utiliser un fichier manifeste de construction côté serveur pour déterminer quels segments de sortie sont utilisés par différents points d'entrée.
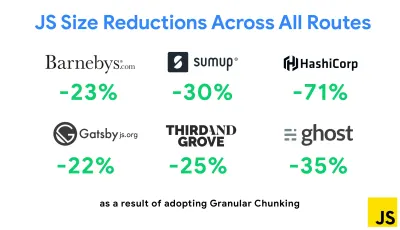
Pour réduire le code en double dans les projets Webpack, nous pouvons utiliser la segmentation granulaire, activée par défaut dans Next.js et Gatsby. Crédit photo : Addy Osmani. ( Grand aperçu ) Avec SplitChunksPlugin, plusieurs fragments fractionnés sont créés en fonction d'un certain nombre de conditions pour empêcher la récupération de code dupliqué sur plusieurs routes. Cela améliore le temps de chargement des pages et la mise en cache lors des navigations. Livré dans Next.js 9.2 et dans Gatsby v2.20.7.
Démarrer avec Webpack peut cependant être difficile. Donc, si vous voulez vous plonger dans Webpack, il existe d'excellentes ressources :
- La documentation Webpack - évidemment - est un bon point de départ, tout comme Webpack - The Confusing Bits de Raja Rao et An Annotated Webpack Config d'Andrew Welch.
- Sean Larkin a un cours gratuit sur Webpack : The Core Concepts et Jeffrey Way a publié un fantastique cours gratuit sur Webpack pour tout le monde. Les deux sont d'excellentes introductions pour plonger dans Webpack.
- Webpack Fundamentals est un cours très complet de 4h avec Sean Larkin, publié par FrontendMasters.
- Les exemples Webpack contiennent des centaines de configurations Webpack prêtes à l'emploi, classées par sujet et par objectif. Bonus : il existe également un configurateur de configuration Webpack qui génère un fichier de configuration de base.
- awesome-webpack est une liste organisée de ressources, bibliothèques et outils Webpack utiles, y compris des articles, des vidéos, des cours, des livres et des exemples pour les projets Angular, React et indépendants du framework.
- Le voyage vers des builds rapides d'assets de production avec Webpack est l'étude de cas d'Etsy sur la façon dont l'équipe est passée d'un système de build JavaScript basé sur RequireJS à Webpack et comment elle a optimisé ses builds, gérant plus de 13 200 assets en 4 minutes en moyenne.
- Les conseils de performance Webpack sont un fil de discussion d'Ivan Akulov, contenant de nombreux conseils axés sur les performances, y compris ceux axés spécifiquement sur Webpack.
- awesome-webpack-perf est un dépôt Goldmine GitHub avec des outils Webpack et des plugins utiles pour les performances. Également entretenu par Ivan Akulov.
- Utilisez l'amélioration progressive par défaut.
Pourtant, après toutes ces années, conserver l'amélioration progressive comme principe directeur de votre architecture frontale et de votre déploiement est une valeur sûre. Concevez et construisez d'abord l'expérience de base, puis améliorez l'expérience avec des fonctionnalités avancées pour les navigateurs capables, en créant des expériences résilientes. Si votre site Web fonctionne rapidement sur une machine lente avec un écran médiocre dans un navigateur médiocre sur un réseau sous-optimal, il ne fonctionnera que plus rapidement sur une machine rapide avec un bon navigateur sur un réseau décent.En fait, avec le service de module adaptatif, nous semblons porter l'amélioration progressive à un autre niveau, en servant des expériences de base "légères" aux appareils bas de gamme et en améliorant avec des fonctionnalités plus sophistiquées pour les appareils haut de gamme. L'amélioration progressive n'est pas susceptible de s'estomper de si tôt.
- Choisissez une base de performance solide.
Avec autant d'inconnues ayant un impact sur le chargement - le réseau, la limitation thermique, l'éviction du cache, les scripts tiers, les modèles de blocage de l'analyseur, les E/S de disque, la latence IPC, les extensions installées, les logiciels antivirus et les pare-feu, les tâches du processeur en arrière-plan, les contraintes matérielles et de mémoire, différences dans la mise en cache L2/L3, RTTS — JavaScript a le coût le plus élevé de l'expérience, à côté des polices Web bloquant le rendu par défaut et des images consommant souvent trop de mémoire. Avec les goulots d'étranglement des performances qui s'éloignent du serveur vers le client, en tant que développeurs, nous devons considérer toutes ces inconnues de manière beaucoup plus détaillée.Avec un budget de 170 Ko qui contient déjà le chemin critique HTML/CSS/JavaScript, le routeur, la gestion de l'état, les utilitaires, le framework et la logique d'application, nous devons examiner en profondeur le coût de transfert réseau, le temps d'analyse/compilation et le coût d'exécution. du cadre de notre choix. Heureusement, nous avons constaté une énorme amélioration au cours des dernières années dans la vitesse à laquelle les navigateurs peuvent analyser et compiler les scripts. Pourtant, l'exécution de JavaScript reste le principal goulot d'étranglement, donc prêter une attention particulière au temps d'exécution du script et au réseau peut avoir un impact.
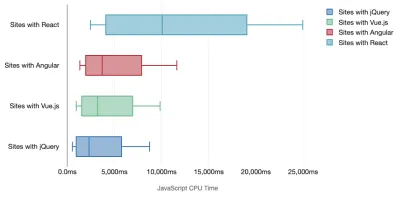
Tim Kadlec a mené une recherche fantastique sur les performances des frameworks modernes, et les a résumés dans l'article "Les frameworks JavaScript ont un coût". Nous parlons souvent de l'impact des frameworks autonomes, mais comme le note Tim, dans la pratique, il n'est pas rare d'utiliser plusieurs frameworks . Peut-être une ancienne version de jQuery qui migre lentement vers un framework moderne, ainsi que quelques applications héritées utilisant une ancienne version d'Angular. Il est donc plus raisonnable d'explorer le coût cumulé des octets JavaScript et du temps d'exécution du processeur qui peuvent facilement rendre les expériences utilisateur à peine utilisables, même sur des appareils haut de gamme.
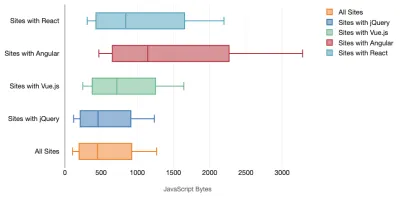
En général, les frameworks modernes ne donnent pas la priorité aux appareils moins puissants , de sorte que les expériences sur un téléphone et sur un ordinateur de bureau seront souvent radicalement différentes en termes de performances. Selon les recherches, les sites avec React ou Angular passent plus de temps sur le CPU que les autres (ce qui bien sûr ne veut pas nécessairement dire que React est plus cher sur le CPU que Vue.js).
Selon Tim, une chose est évidente : "si vous utilisez un framework pour créer votre site, vous faites un compromis en termes de performances initiales , même dans le meilleur des scénarios".
- Évaluer les frameworks et les dépendances.
Maintenant, tous les projets n'ont pas besoin d'un framework et toutes les pages d'une application à page unique n'ont pas besoin de charger un framework. Dans le cas de Netflix, "la suppression de React, de plusieurs bibliothèques et du code d'application correspondant du côté client a réduit la quantité totale de JavaScript de plus de 200 Ko, entraînant une réduction de plus de 50 % du temps d'interactivité de Netflix pour la page d'accueil déconnectée. ." L'équipe a ensuite utilisé le temps passé par les utilisateurs sur la page de destination pour prérécupérer React pour les pages suivantes sur lesquelles les utilisateurs étaient susceptibles d'atterrir (lisez la suite pour plus de détails).Et si vous supprimiez complètement un framework existant sur les pages critiques ? Avec Gatsby, vous pouvez vérifier gatsby-plugin-no-javascript qui supprime tous les fichiers JavaScript créés par Gatsby à partir des fichiers HTML statiques. Sur Vercel, vous pouvez également autoriser la désactivation du runtime JavaScript en production pour certaines pages (expérimental).
Une fois qu'un cadre est choisi, nous allons rester avec lui pendant au moins quelques années, donc si nous devons en utiliser un, nous devons nous assurer que notre choix est éclairé et bien réfléchi - et cela vaut en particulier pour les mesures de performance clés que nous s'en soucier.
Les données montrent que, par défaut, les frameworks sont assez chers : 58,6 % des pages React expédient plus de 1 Mo de JavaScript, et 36 % des chargements de pages Vue.js ont un First Contentful Paint de <1,5s. Selon une étude d'Ankur Sethi, "votre application React ne se chargera jamais plus rapidement qu'environ 1,1 seconde sur un téléphone moyen en Inde, peu importe à quel point vous l'optimisez. Votre application Angular prendra toujours au moins 2,7 secondes pour démarrer. les utilisateurs de votre application Vue devront attendre au moins 1 seconde avant de pouvoir commencer à l'utiliser." De toute façon, vous ne ciblez peut-être pas l'Inde comme marché principal, mais les utilisateurs accédant à votre site avec des conditions de réseau sous-optimales auront une expérience comparable.
Bien sûr, il est possible de créer des SPA rapidement, mais ils ne sont pas rapides prêts à l'emploi, nous devons donc tenir compte du temps et des efforts nécessaires pour les créer et les maintenir rapides. Ce sera probablement plus facile en choisissant très tôt un coût de performance de base léger.
Alors comment choisit-on un cadre ? C'est une bonne idée de considérer au moins le coût total sur la taille + les temps d'exécution initiaux avant de choisir une option ; des options légères telles que Preact, Inferno, Vue, Svelte, Alpine ou Polymer peuvent très bien faire le travail. La taille de votre ligne de base définira les contraintes du code de votre application.
Comme l'a noté Seb Markbage, un bon moyen de mesurer les coûts de démarrage des frameworks consiste à restituer d'abord une vue, puis à la supprimer, puis à restituer car elle peut vous indiquer comment le framework évolue. Le premier rendu a tendance à réchauffer un tas de code compilé paresseusement, dont un arbre plus grand peut bénéficier lorsqu'il évolue. Le deuxième rendu est essentiellement une émulation de la façon dont la réutilisation du code sur une page affecte les caractéristiques de performance à mesure que la page devient plus complexe.
Vous pouvez aller jusqu'à évaluer vos candidats (ou toute bibliothèque JavaScript en général) sur le système de notation à 12 points de Sacha Greif en explorant les fonctionnalités, l'accessibilité, la stabilité, les performances, l' écosystème de packages , la communauté, la courbe d'apprentissage, la documentation, l'outillage, les antécédents. , équipe, compatibilité, sécurité par exemple.
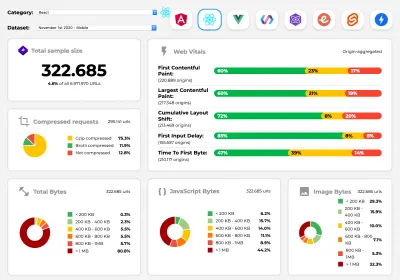
Perf Track suit les performances du framework à grande échelle. ( Grand aperçu ) Vous pouvez également vous fier aux données collectées sur le Web sur une période plus longue. Par exemple, Perf Track suit les performances du framework à grande échelle, en affichant les scores Core Web Vitals agrégés par origine pour les sites Web construits dans Angular, React, Vue, Polymer, Preact, Ember, Svelte et AMP. Vous pouvez même spécifier et comparer des sites Web construits avec Gatsby, Next.js ou Create React App, ainsi que des sites Web construits avec Nuxt.js (Vue) ou Sapper (Svelte).
Un bon point de départ consiste à choisir une bonne pile par défaut pour votre application. Gatsby (React), Next.js (React), Vuepress (Vue), Preact CLI et PWA Starter Kit fournissent des valeurs par défaut raisonnables pour un chargement rapide et prêt à l'emploi sur du matériel mobile moyen. Jetez également un coup d'œil aux conseils de performance spécifiques au framework web.dev pour React et Angular ( merci, Phillip ! ).
Et peut-être pourriez-vous adopter une approche légèrement plus rafraîchissante pour créer des applications d'une seule page - Turbolinks, une bibliothèque JavaScript de 15 Ko qui utilise HTML au lieu de JSON pour afficher les vues. Ainsi, lorsque vous suivez un lien, Turbolinks récupère automatiquement la page, échange son
<body>et fusionne son<head>, le tout sans encourir le coût d'un chargement complet de la page. Vous pouvez consulter les détails rapides et la documentation complète sur la pile (Hotwire).
- Rendu côté client ou rendu côté serveur ? Tous les deux!
C'est une conversation assez animée à avoir. L'approche ultime consisterait à mettre en place une sorte de démarrage progressif : utilisez le rendu côté serveur pour obtenir un First Contentful Paint rapide, mais incluez également un minimum de JavaScript nécessaire pour maintenir le temps d'interactivité proche du First Contentful Paint. Si JavaScript arrive trop tard après le FCP, le navigateur verrouillera le thread principal lors de l'analyse, de la compilation et de l'exécution de JavaScript découvert tardivement, ce qui entravera l'interactivité du site ou de l'application.Pour l'éviter, divisez toujours l'exécution des fonctions en tâches distinctes et asynchrones et, si possible, utilisez
requestIdleCallback. Envisagez de charger paresseusement des parties de l'interface utilisateur à l'aide de la prise en charge dynamiqueimport()de WebPack, en évitant les coûts de chargement, d'analyse et de compilation jusqu'à ce que les utilisateurs en aient vraiment besoin ( merci Addy ! ).Comme mentionné ci-dessus, Time to Interactive (TTI) nous indique le temps entre la navigation et l'interactivité. En détail, la métrique est définie en regardant la première fenêtre de cinq secondes après le rendu du contenu initial, dans laquelle aucune tâche JavaScript ne prend plus de 50 ms ( Long Tasks ). Si une tâche de plus de 50 ms se produit, la recherche d'une fenêtre de cinq secondes recommence. En conséquence, le navigateur supposera d'abord qu'il a atteint Interactive , juste pour passer à Frozen , juste pour finalement revenir à Interactive .
Une fois que nous avons atteint Interactive , nous pouvons ensuite, à la demande ou si le temps le permet, démarrer les parties non essentielles de l'application. Malheureusement, comme l'a remarqué Paul Lewis, les frameworks n'ont généralement pas de concept simple de priorité qui puisse être présenté aux développeurs, et donc le démarrage progressif n'est pas facile à mettre en œuvre avec la plupart des bibliothèques et des frameworks.
Pourtant, nous y arrivons. Ces jours-ci, il y a quelques choix que nous pouvons explorer, et Houssein Djirdeh et Jason Miller fournissent un excellent aperçu de ces options dans leur exposé sur le rendu sur le Web et l'article de Jason et Addy sur les architectures frontales modernes. L'aperçu ci-dessous est basé sur leur travail stellaire.
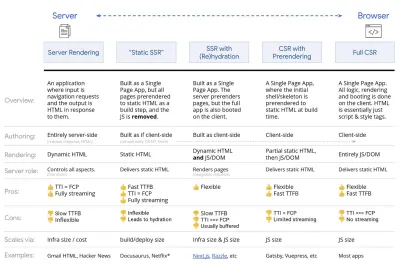
- Rendu complet côté serveur (SSR)
Dans les SSR classiques, comme WordPress, toutes les requêtes sont entièrement traitées sur le serveur. Le contenu demandé est renvoyé sous la forme d'une page HTML finie et les navigateurs peuvent le restituer immédiatement. Par conséquent, les applications SSR ne peuvent pas vraiment utiliser les API DOM, par exemple. L'écart entre First Contentful Paint et Time to Interactive est généralement faible, et la page peut être rendue immédiatement lorsque le code HTML est diffusé sur le navigateur.Cela évite des allers-retours supplémentaires pour la récupération de données et la création de modèles sur le client, car il est géré avant que le navigateur n'obtienne une réponse. Cependant, nous nous retrouvons avec un temps de réflexion du serveur plus long et par conséquent le temps jusqu'au premier octet et nous n'utilisons pas les fonctionnalités réactives et riches des applications modernes.
- Rendu statique
Nous construisons le produit comme une application d'une seule page, mais toutes les pages sont pré-rendues en HTML statique avec un minimum de JavaScript comme étape de construction. Cela signifie qu'avec le rendu statique, nous produisons à l'avance des fichiers HTML individuels pour chaque URL possible , ce que peu d'applications peuvent se permettre. Mais comme le code HTML d'une page n'a pas besoin d'être généré à la volée, nous pouvons obtenir un délai d'obtention du premier octet toujours rapide. Ainsi, nous pouvons afficher rapidement une page de destination, puis prérécupérer un cadre SPA pour les pages suivantes. Netflix a adopté cette approche en réduisant le chargement et le temps d'interaction de 50 %. - Rendu côté serveur avec (ré)hydratation (rendu universel, SSR + CSR)
Nous pouvons essayer d'utiliser le meilleur des deux mondes - les approches SSR et RSE. Avec l'hydratation dans le mélange, la page HTML renvoyée par le serveur contient également un script qui charge une application côté client à part entière. Idéalement, cela permet d'obtenir une First Contentful Paint rapide (comme SSR) puis de continuer le rendu avec (ré)hydratation. Malheureusement, c'est rarement le cas. Le plus souvent, la page semble prête mais elle ne peut pas répondre aux entrées de l'utilisateur, produisant des clics et des abandons de rage.Avec React, nous pouvons utiliser le module
ReactDOMServersur un serveur Node comme Express, puis appeler la méthoderenderToStringpour restituer les composants de niveau supérieur sous forme de chaîne HTML statique.Avec Vue.js, nous pouvons utiliser le vue-server-renderer pour rendre une instance Vue en HTML en utilisant
renderToString. Dans Angular, nous pouvons utiliser@nguniversalpour transformer les demandes des clients en pages HTML entièrement rendues par le serveur. Une expérience entièrement rendue par le serveur peut également être réalisée prête à l'emploi avec Next.js (React) ou Nuxt.js (Vue).L'approche a ses inconvénients. En conséquence, nous bénéficions d'une flexibilité totale des applications côté client tout en offrant un rendu plus rapide côté serveur, mais nous nous retrouvons également avec un écart plus long entre First Contentful Paint et Time To Interactive et un délai de première entrée accru. La réhydratation est très coûteuse, et généralement cette stratégie seule ne sera pas suffisante car elle retarde considérablement le Time To Interactive.
- Rendu côté serveur en streaming avec hydratation progressive (SSR + CSR)
Pour minimiser l'écart entre Time To Interactive et First Contentful Paint, nous rendons plusieurs requêtes à la fois et envoyons le contenu par blocs au fur et à mesure qu'ils sont générés. Nous n'avons donc pas besoin d'attendre la chaîne complète de HTML avant d'envoyer du contenu au navigateur, et donc d'améliorer Time To First Byte.Dans React, au lieu de
renderToString(), nous pouvons utiliser renderToNodeStream() pour diriger la réponse et envoyer le HTML en morceaux. Dans Vue, nous pouvons utiliser renderToStream() qui peut être canalisé et diffusé. Avec React Suspense, nous pourrions également utiliser le rendu asynchrone à cette fin.Côté client, plutôt que de démarrer l'ensemble de l'application en une seule fois, nous démarrons les composants progressivement . Les sections des applications sont d'abord décomposées en scripts autonomes avec découpage du code, puis hydratées progressivement (dans l'ordre de nos priorités). En fait, nous pouvons d'abord hydrater les composants critiques, tandis que le reste pourrait être hydraté plus tard. Le rôle du rendu côté client et côté serveur peut alors être défini différemment par composant. Nous pouvons alors également différer l'hydratation de certains composants jusqu'à ce qu'ils apparaissent, ou soient nécessaires pour l'interaction de l'utilisateur, ou lorsque le navigateur est inactif.
Pour Vue, Markus Oberlehner a publié un guide sur la réduction du temps d'interaction des applications SSR en utilisant l'hydratation sur l'interaction de l'utilisateur ainsi que vue-lazy-hydration, un plugin de stade précoce qui permet l'hydratation des composants sur la visibilité ou l'interaction spécifique de l'utilisateur. L'équipe Angular travaille sur l'hydratation progressive avec Ivy Universal. Vous pouvez également implémenter une hydratation partielle avec Preact et Next.js.
- Rendu trisomorphe
Avec les techniciens de service en place, nous pouvons utiliser le rendu du serveur de streaming pour les navigations initiales/non-JS, puis demander au technicien de service de prendre en charge le rendu du HTML pour les navigations après son installation. Dans ce cas, le technicien de service préaffiche le contenu et active les navigations de style SPA pour afficher de nouvelles vues dans la même session. Fonctionne bien lorsque vous pouvez partager le même code de modèle et de routage entre le serveur, la page client et le service worker.
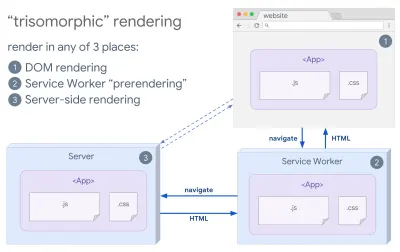
Rendu trisomorphe, avec le même rendu de code à 3 endroits quelconques : sur le serveur, dans le DOM ou dans un service worker. (Source de l'image : Google Developers) ( Grand aperçu ) - RSE avec prérendu
Le prérendu est similaire au rendu côté serveur, mais plutôt que de rendre les pages sur le serveur de manière dynamique, nous rendons l'application en HTML statique au moment de la construction. Alors que les pages statiques sont entièrement interactives sans beaucoup de JavaScript côté client, le prérendu fonctionne différemment . Fondamentalement, il capture l'état initial d'une application côté client sous forme de HTML statique au moment de la construction, tandis qu'avec le prérendu, l'application doit être démarrée sur le client pour que les pages soient interactives.Avec Next.js, nous pouvons utiliser l'exportation HTML statique en pré-affichant une application en HTML statique. Dans Gatsby, un générateur de site statique open source qui utilise React, utilise la méthode
renderToStaticMarkupau lieu de la méthoderenderToStringpendant les constructions, le bloc JS principal étant préchargé et les routes futures sont prérécupérées, sans les attributs DOM qui ne sont pas nécessaires pour les pages statiques simples.Pour Vue, nous pouvons utiliser Vuepress pour atteindre le même objectif. Vous pouvez également utiliser prerender-loader avec Webpack. Navi fournit également un rendu statique.
Le résultat est un meilleur Time To First Byte et First Contentful Paint, et nous réduisons l'écart entre Time To Interactive et First Contentful Paint. Nous ne pouvons pas utiliser l'approche si l'on s'attend à ce que le contenu change beaucoup. De plus, toutes les URL doivent être connues à l'avance pour générer toutes les pages. Ainsi, certains composants peuvent être rendus à l'aide du prérendu, mais si nous avons besoin de quelque chose de dynamique, nous devons compter sur l'application pour récupérer le contenu.
- Rendu complet côté client (CSR)
Toute la logique, le rendu et le démarrage sont effectués sur le client. Le résultat est généralement un écart énorme entre Time To Interactive et First Contentful Paint. En conséquence, les applications semblent souvent lentes car l'intégralité de l'application doit être démarrée sur le client pour rendre quoi que ce soit.Comme JavaScript a un coût de performance, à mesure que la quantité de JavaScript augmente avec une application, un fractionnement de code agressif et un report de JavaScript seront absolument nécessaires pour apprivoiser l'impact de JavaScript. Dans de tels cas, un rendu côté serveur sera généralement une meilleure approche au cas où peu d'interactivité serait requise. Si ce n'est pas une option, envisagez d'utiliser le modèle App Shell.
En général, SSR est plus rapide que CSR. Pourtant, c'est une implémentation assez fréquente pour de nombreuses applications.
Alors, côté client ou côté serveur ? En général, c'est une bonne idée de limiter l'utilisation de frameworks entièrement côté client aux pages qui en ont absolument besoin. Pour les applications avancées, ce n'est pas non plus une bonne idée de s'appuyer uniquement sur le rendu côté serveur. Le rendu serveur et le rendu client sont tous deux désastreux s'ils sont mal exécutés.
Que vous penchiez vers CSR ou SSR, assurez-vous de rendre les pixels importants dès que possible et de minimiser l'écart entre ce rendu et Time To Interactive. Envisagez de pré-rendre si vos pages ne changent pas beaucoup et différez le démarrage des frameworks si vous le pouvez. Diffusez du HTML en morceaux avec un rendu côté serveur et mettez en œuvre une hydratation progressive pour le rendu côté client - et hydratez-vous sur la visibilité, l'interaction ou pendant les temps d'inactivité pour tirer le meilleur parti des deux mondes.
- Rendu complet côté serveur (SSR)

- Combien pouvons-nous servir statiquement ?
Que vous travailliez sur une grande application ou sur un petit site, il vaut la peine de considérer quel contenu pourrait être servi statiquement à partir d'un CDN (c'est-à-dire JAM Stack), plutôt que d'être généré dynamiquement à la volée. Même si vous avez des milliers de produits et des centaines de filtres avec de nombreuses options de personnalisation, vous souhaiterez peut-être toujours servir vos pages de destination critiques de manière statique et dissocier ces pages du cadre de votre choix.Il existe de nombreux générateurs de sites statiques et les pages qu'ils génèrent sont souvent très rapides. The more content we can pre-build ahead of time instead of generating page views on a server or client at request time, the better performance we will achieve.
In Building Partially Hydrated, Progressively Enhanced Static Websites, Markus Oberlehner shows how to build out websites with a static site generator and an SPA, while achieving progressive enhancement and a minimal JavaScript bundle size. Markus uses Eleventy and Preact as his tools, and shows how to set up the tools, add partial hydration, lazy hydration, client entry file, configure Babel for Preact and bundle Preact with Rollup — from start to finish.
With JAMStack used on large sites these days, a new performance consideration appeared: the build time . In fact, building out even thousands of pages with every new deploy can take minutes, so it's promising to see incremental builds in Gatsby which improve build times by 60 times , with an integration into popular CMS solutions like WordPress, Contentful, Drupal, Netlify CMS and others.
Incremental static regeneration with Next.js. (Image credit: Prisma.io) (Large preview) Also, Next.js announced ahead-of-time and incremental static generation, which allows us to add new static pages at runtime and update existing pages after they've been already built, by re-rendering them in the background as traffic comes in.
Need an even more lightweight approach? In his talk on Eleventy, Alpine and Tailwind: towards a lightweight Jamstack, Nicola Goutay explains the differences between CSR, SSR and everything-in-between, and shows how to use a more lightweight approach — along with a GitHub repo that shows the approach in practice.
- Consider using PRPL pattern and app shell architecture.
Different frameworks will have different effects on performance and will require different strategies of optimization, so you have to clearly understand all of the nuts and bolts of the framework you'll be relying on. When building a web app, look into the PRPL pattern and application shell architecture. The idea is quite straightforward: Push the minimal code needed to get interactive for the initial route to render quickly, then use service worker for caching and pre-caching resources and then lazy-load routes that you need, asynchronously.
- Have you optimized the performance of your APIs?
APIs are communication channels for an application to expose data to internal and third-party applications via endpoints . When designing and building an API, we need a reasonable protocol to enable the communication between the server and third-party requests. Representational State Transfer ( REST ) is a well-established, logical choice: it defines a set of constraints that developers follow to make content accessible in a performant, reliable and scalable fashion. Web services that conform to the REST constraints, are called RESTful web services .As with good ol' HTTP requests, when data is retrieved from an API, any delay in server response will propagate to the end user, hence delaying rendering . When a resource wants to retrieve some data from an API, it will need to request the data from the corresponding endpoint. A component that renders data from several resources, such as an article with comments and author photos in each comment, may need several roundtrips to the server to fetch all the data before it can be rendered. Furthermore, the amount of data returned through REST is often more than what is needed to render that component.
If many resources require data from an API, the API might become a performance bottleneck. GraphQL provides a performant solution to these issues. Per se, GraphQL is a query language for your API, and a server-side runtime for executing queries by using a type system you define for your data. Unlike REST, GraphQL can retrieve all data in a single request , and the response will be exactly what is required, without over or under -fetching data as it typically happens with REST.
In addition, because GraphQL is using schema (metadata that tells how the data is structured), it can already organize data into the preferred structure, so, for example, with GraphQL, we could remove JavaScript code used for dealing with state management, producing a cleaner application code that runs faster on the client.
If you want to get started with GraphQL or encounter performance issues, these articles might be quite helpful:
- A GraphQL Primer: Why We Need A New Kind Of API by Eric Baer,
- A GraphQL Primer: The Evolution Of API Design by Eric Baer,
- Designing a GraphQL server for optimal performance by Leonardo Losoviz,
- GraphQL performance explained by Wojciech Trocki.
- Will you be using AMP or Instant Articles?
Depending on the priorities and strategy of your organization, you might want to consider using Google's AMP or Facebook's Instant Articles or Apple's Apple News. You can achieve good performance without them, but AMP does provide a solid performance framework with a free content delivery network (CDN), while Instant Articles will boost your visibility and performance on Facebook.The seemingly obvious benefit of these technologies for users is guaranteed performance , so at times they might even prefer AMP-/Apple News/Instant Pages-links over "regular" and potentially bloated pages. For content-heavy websites that are dealing with a lot of third-party content, these options could potentially help speed up render times dramatically.
Unless they don't. According to Tim Kadlec, for example, "AMP documents tend to be faster than their counterparts, but they don't necessarily mean a page is performant. AMP is not what makes the biggest difference from a performance perspective."
A benefit for the website owner is obvious: discoverability of these formats on their respective platforms and increased visibility in search engines.
Well, at least that's how it used to be. As AMP is no longer a requirement for Top Stories , publishers might be moving away from AMP to a traditional stack instead ( thanks, Barry! ).
Still, you could build progressive web AMPs, too, by reusing AMPs as a data source for your PWA. Downside? Obviously, a presence in a walled garden places developers in a position to produce and maintain a separate version of their content, and in case of Instant Articles and Apple News without actual URLs (thanks Addy, Jeremy!) .
- Choose your CDN wisely.
As mentioned above, depending on how much dynamic data you have, you might be able to "outsource" some part of the content to a static site generator, pushing it to a CDN and serving a static version from it, thus avoiding requests to the server. In fact, some of those generators are actually website compilers with many automated optimizations provided out of the box. As compilers add optimizations over time, the compiled output gets smaller and faster over time.Notice that CDNs can serve (and offload) dynamic content as well. So, restricting your CDN to static assets is not necessary. Double-check whether your CDN performs compression and conversion (eg image optimization and resizing at the edge), whether they provide support for servers workers, A/B testing, as well as edge-side includes, which assemble static and dynamic parts of pages at the CDN's edge (ie the server closest to the user), and other tasks. Also, check if your CDN supports HTTP over QUIC (HTTP/3).
Katie Hempenius has written a fantastic guide to CDNs that provides insights on how to choose a good CDN , how to finetune it and all the little things to keep in mind when evaluating one. In general, it's a good idea to cache content as aggressively as possible and enable CDN performance features like Brotli, TLS 1.3, HTTP/2, and HTTP/3.
Note : based on research by Patrick Meenan and Andy Davies, HTTP/2 prioritization is effectively broken on many CDNs, so be careful when choosing a CDN. Patrick has more details in his talk on HTTP/2 Prioritization ( thanks, Barry! ).
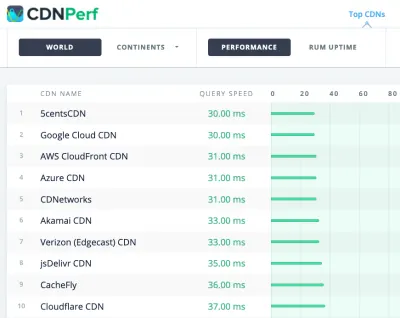
CDNPerf measures query speed for CDNs by gathering and analyzing 300 million tests every day. ( Grand aperçu ) When choosing a CDN, you can use these comparison sites with a detailed overview of their features:
- Comparaison CDN, une matrice de comparaison CDN pour Cloudfront, Aazure, KeyCDN, Fastly, Verizon, Stackpach, Akamai et bien d'autres.
- CDN Perf mesure la vitesse des requêtes pour les CDN en rassemblant et en analysant 300 millions de tests chaque jour, avec tous les résultats basés sur les données RUM des utilisateurs du monde entier. Vérifiez également la comparaison des performances DNS et la comparaison des performances du cloud.
- CDN Planet Guides fournit une vue d'ensemble des CDN pour des sujets spécifiques, tels que Serve Stale, Purge, Origin Shield, Prefetch et Compression.
- Web Almanac : CDN Adoption and Usage fournit des informations sur les principaux fournisseurs de CDN, leur gestion RTT et TLS, le temps de négociation TLS, l'adoption HTTP/2 et autres. (Malheureusement, les données ne datent que de 2019).
Optimisations des actifs
- Utilisez Brotli pour la compression de texte brut.
En 2015, Google a introduit Brotli, un nouveau format de données open source sans perte, désormais pris en charge par tous les navigateurs modernes. La bibliothèque Brotli open source, qui implémente un encodeur et un décodeur pour Brotli, a 11 niveaux de qualité prédéfinis pour l'encodeur, avec un niveau de qualité supérieur exigeant plus de CPU en échange d'un meilleur taux de compression. Une compression plus lente conduira finalement à des taux de compression plus élevés, mais Brotli décompresse rapidement. Il convient de noter cependant que Brotli avec le niveau de compression 4 est à la fois plus petit et se comprime plus rapidement que Gzip.En pratique, Brotli semble être beaucoup plus efficace que Gzip. Les opinions et les expériences diffèrent, mais si votre site est déjà optimisé avec Gzip, vous pouvez vous attendre à des améliorations au moins à un chiffre et au mieux à deux chiffres en matière de réduction de taille et de délais FCP. Vous pouvez également estimer les économies de compression Brotli pour votre site.
Les navigateurs n'accepteront Brotli que si l'utilisateur visite un site Web via HTTPS. Brotli est largement pris en charge et de nombreux CDN le prennent en charge (Akamai, Netlify Edge, AWS, KeyCDN, Fastly (actuellement uniquement en tant que pass-through), Cloudflare, CDN77) et vous pouvez activer Brotli même sur les CDN qui ne le prennent pas encore en charge. (avec un agent de service).
Le hic, c'est que la compression de tous les actifs avec Brotli à un niveau de compression élevé coûte cher, de nombreux hébergeurs ne peuvent pas l'utiliser à grande échelle simplement à cause des énormes frais généraux qu'il génère. En fait, au niveau de compression le plus élevé, Brotli est si lent que tout gain potentiel de taille de fichier pourrait être annulé par le temps nécessaire au serveur pour commencer à envoyer la réponse en attendant de compresser dynamiquement l'actif. (Mais si vous avez le temps pendant le temps de construction avec la compression statique, bien sûr, des paramètres de compression plus élevés sont préférés.)
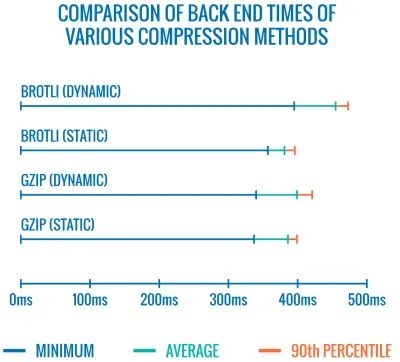
Comparaison des temps de back-end de diverses méthodes de compression. Sans surprise, Brotli est plus lent que gzip (pour l'instant). ( Grand aperçu ) Cela pourrait changer cependant. Le format de fichier Brotli comprend un dictionnaire statique intégré et, en plus de contenir diverses chaînes dans plusieurs langues, il prend également en charge la possibilité d'appliquer plusieurs transformations à ces mots, ce qui augmente sa polyvalence. Dans ses recherches, Felix Hanau a découvert un moyen d'améliorer la compression aux niveaux 5 à 9 en utilisant "un sous-ensemble plus spécialisé du dictionnaire que celui par défaut" et en s'appuyant sur l'en-tête
Content-Typepour dire au compresseur s'il doit utiliser un dictionnaire pour HTML, JavaScript ou CSS. Le résultat a été un "impact négligeable sur les performances (1% à 3% de CPU en plus contre 12% normalement) lors de la compression de contenu Web à des niveaux de compression élevés, en utilisant une approche d'utilisation limitée du dictionnaire".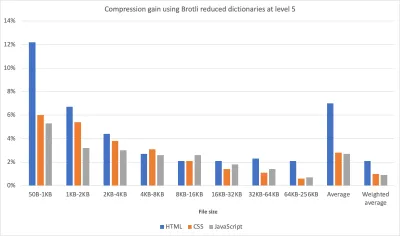
Grâce à l'approche améliorée du dictionnaire, nous pouvons compresser les actifs plus rapidement à des niveaux de compression plus élevés, tout en utilisant seulement 1 % à 3 % de CPU en plus. Normalement, le niveau de compression 6 sur 5 augmenterait l'utilisation du processeur jusqu'à 12 %. ( Grand aperçu ) De plus, grâce aux recherches d'Elena Kirilenko, nous pouvons obtenir une recompression Brotli rapide et efficace en utilisant les artefacts de compression précédents. Selon Elena, "une fois que nous avons un actif compressé via Brotli, et que nous essayons de compresser le contenu dynamique à la volée, où le contenu ressemble au contenu disponible à l'avance, nous pouvons obtenir des améliorations significatives des temps de compression. "
Combien de fois est-ce le cas? Par exemple, avec la livraison de sous- ensembles de bundles JavaScript (par exemple, lorsque des parties du code sont déjà mises en cache sur le client ou avec un bundle dynamique servant avec WebBundles). Ou avec du HTML dynamique basé sur des modèles connus à l'avance ou des polices WOFF2 dynamiquement sous-ensembles . Selon Elena, nous pouvons obtenir une amélioration de 5,3 % de la compression et de 39 % de la vitesse de compression en supprimant 10 % du contenu, et des taux de compression 3,2 % meilleurs et une compression 26 % plus rapide en supprimant 50 % du contenu.
La compression Brotli s'améliore, donc si vous pouvez contourner le coût de la compression dynamique des actifs statiques, cela en vaut vraiment la peine. Il va sans dire que Brotli peut être utilisé pour n'importe quelle charge utile en texte brut - HTML, CSS, SVG, JavaScript, JSON, etc.
Remarque : début 2021, environ 60 % des réponses HTTP sont livrées sans compression textuelle, dont 30,82 % avec Gzip et 9,1 % avec Brotli (à la fois sur mobile et sur ordinateur). Par exemple, 23,4% des pages Angular ne sont pas compressées (via gzip ou Brotli). Pourtant, l'activation de la compression est souvent l'une des victoires les plus faciles pour améliorer les performances en appuyant simplement sur un interrupteur.
La stratégie? Pré-compressez les ressources statiques avec Brotli+Gzip au niveau le plus élevé et compressez le HTML (dynamique) à la volée avec Brotli au niveau 4-6. Assurez-vous que le serveur gère correctement la négociation de contenu pour Brotli ou Gzip.
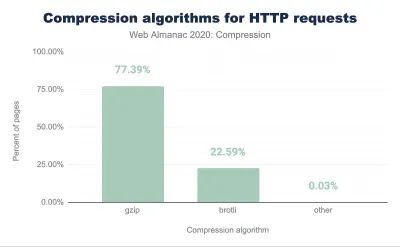
- Utilisons-nous le chargement multimédia adaptatif et les conseils client ?
Cela vient du pays des vieilles nouvelles, mais c'est toujours un bon rappel d'utiliser des images réactives avecsrcset,sizeset l'élément<picture>. En particulier pour les sites à forte empreinte multimédia, nous pouvons aller plus loin avec le chargement multimédia adaptatif (dans cet exemple, React + Next.js), offrant une expérience légère aux réseaux lents et aux appareils à faible mémoire et une expérience complète au réseau rapide et haute -dispositifs de mémoire. Dans le contexte de React, nous pouvons y parvenir avec des conseils client sur le serveur et des crochets réactifs adaptatifs sur le client.L'avenir des images réactives pourrait changer radicalement avec l'adoption plus large des conseils aux clients. Les indications client sont des champs d'en-tête de requête HTTP, par exemple
DPR,Viewport-Width,Width,Save-Data,Accept(pour spécifier les préférences de format d'image) et autres. Ils sont censés informer le serveur des spécificités du navigateur, de l'écran, de la connexion, etc. de l'utilisateur.En conséquence, le serveur peut décider comment remplir la mise en page avec des images de taille appropriée et ne servir que ces images dans les formats souhaités. Avec les conseils client, nous déplaçons la sélection des ressources du balisage HTML vers la négociation requête-réponse entre le client et le serveur.
Média adaptatif servant en cours d'utilisation. Nous envoyons un espace réservé avec du texte aux utilisateurs hors ligne, une image basse résolution aux utilisateurs 2G, une image haute résolution aux utilisateurs 3G et une vidéo HD aux utilisateurs 4G. Via Chargement rapide des pages Web sur un téléphone polyvalent à 20 $. ( Grand aperçu ) Comme Ilya Grigorik l'a noté il y a quelque temps, les conseils du client complètent le tableau - ils ne sont pas une alternative aux images réactives. "L'élément
<picture>fournit le contrôle de direction artistique nécessaire dans le balisage HTML. Les conseils du client fournissent des annotations sur les demandes d'image résultantes qui permettent l'automatisation de la sélection des ressources. Service Worker fournit des fonctionnalités complètes de gestion des demandes et des réponses sur le client."Un travailleur de service pourrait, par exemple, ajouter de nouvelles valeurs d'en-têtes d'indications client à la demande, réécrire l'URL et faire pointer la demande d'image vers un CDN, adapter la réponse en fonction de la connectivité et des préférences de l'utilisateur, etc. pour presque toutes les autres demandes également.
Pour les clients qui prennent en charge les conseils client, on peut mesurer 42 % d'économies d'octets sur les images et 1 Mo+ d'octets en moins pour le 70e centile+. Sur Smashing Magazine, nous avons également pu mesurer une amélioration de 19 à 32 %. Les conseils client sont pris en charge dans les navigateurs basés sur Chromium, mais ils sont toujours à l'étude dans Firefox.
Toutefois, si vous fournissez à la fois le balisage des images réactives normales et la
<meta>pour les conseils client, un navigateur prenant en charge évaluera le balisage des images réactives et demandera la source d'image appropriée à l'aide des en-têtes HTTP Client Hints. - Utilisons-nous des images réactives pour les images d'arrière-plan ?
Nous devrions sûrement ! Avecimage-set, désormais pris en charge dans Safari 14 et dans la plupart des navigateurs modernes à l'exception de Firefox, nous pouvons également proposer des images d'arrière-plan réactives :background-image: url("fallback.jpg"); background-image: image-set( "photo-small.jpg" 1x, "photo-large.jpg" 2x, "photo-print.jpg" 600dpi);Fondamentalement, nous pouvons conditionnellement servir des images d'arrière-plan basse résolution avec un descripteur
1x, et des images haute résolution avec un descripteur2x, et même une image de qualité d'impression avec un descripteur600dpi. Attention cependant : les navigateurs ne fournissent aucune information spéciale sur les images d'arrière-plan aux technologies d'assistance, donc idéalement, ces photos ne seraient qu'une décoration. - Utilisons-nous WebP ?
La compression d'image est souvent considérée comme un gain rapide, mais elle est encore largement sous-utilisée dans la pratique. Bien sûr, les images ne bloquent pas le rendu, mais elles contribuent fortement aux mauvais scores LCP, et très souvent, elles sont tout simplement trop lourdes et trop volumineuses pour l'appareil sur lequel elles sont consommées.Donc, à tout le moins, nous pourrions explorer l'utilisation du format WebP pour nos images. En fait, la saga WebP touche à sa fin l'année dernière avec Apple ajoutant la prise en charge de WebP dans Safari 14. Ainsi, après de nombreuses années de discussions et de débats, à partir d'aujourd'hui, WebP est pris en charge dans tous les navigateurs modernes. Nous pouvons donc servir des images WebP avec l'élément
<picture>et un repli JPEG si nécessaire (voir l'extrait de code d'Andreas Bovens) ou en utilisant la négociation de contenu (en utilisant les en-têtesAccept).WebP n'est cependant pas sans inconvénients . Bien que la taille des fichiers d'image WebP soit comparée à Guetzli et Zopfli équivalents, le format ne prend pas en charge le rendu progressif comme JPEG, c'est pourquoi les utilisateurs peuvent voir l'image finale plus rapidement avec un bon vieux JPEG, bien que les images WebP puissent devenir plus rapides via le réseau. Avec JPEG, nous pouvons servir une expérience utilisateur "décente" avec la moitié ou même le quart des données et charger le reste plus tard, plutôt que d'avoir une image à moitié vide comme c'est le cas avec WebP.
Votre décision dépendra de ce que vous recherchez : avec WebP, vous réduirez la charge utile, et avec JPEG, vous améliorerez les performances perçues. Vous pouvez en savoir plus sur WebP dans la conférence WebP Rewind de Pascal Massimino de Google.
Pour la conversion en WebP, vous pouvez utiliser WebP Converter, cwebp ou libwebp. Ire Aderinokun propose également un didacticiel très détaillé sur la conversion d'images en WebP, tout comme Josh Comeau dans son article sur l'adoption des formats d'image modernes.

Un exposé approfondi sur WebP : WebP Rewind par Pascal Massimino. ( Grand aperçu ) Sketch prend nativement en charge WebP et les images WebP peuvent être exportées depuis Photoshop à l'aide d'un plug-in WebP pour Photoshop. Mais d'autres options sont également disponibles.
Si vous utilisez WordPress ou Joomla, il existe des extensions pour vous aider à implémenter facilement la prise en charge de WebP, comme Optimus et Cache Enabler pour WordPress et la propre extension prise en charge par Joomla (via Cody Arsenault). Vous pouvez également faire abstraction de l'élément
<picture>avec React, des composants stylés ou gatsby-image.Ah - prise éhontée ! - Jeremy Wagner a même publié un livre Smashing sur WebP que vous voudrez peut-être consulter si vous êtes intéressé par tout ce qui concerne WebP.
- Utilisons-nous AVIF ?
Vous avez peut-être entendu la grande nouvelle : AVIF est arrivé. C'est un nouveau format d'image dérivé des images clés de la vidéo AV1. Il s'agit d'un format ouvert et libre de droits qui prend en charge la compression avec et sans perte, l'animation, le canal alpha avec perte et peut gérer des lignes nettes et des couleurs unies (ce qui était un problème avec JPEG), tout en offrant de meilleurs résultats dans les deux cas.En fait, par rapport à WebP et JPEG, AVIF est nettement plus performant , permettant d'économiser jusqu'à 50 % de la taille médiane des fichiers pour le même DSSIM ((dis)similarité entre deux images ou plus à l'aide d'un algorithme se rapprochant de la vision humaine). En fait, dans son article approfondi sur l'optimisation du chargement des images, Malte Ubl note qu'AVIF "surclasse très régulièrement JPEG de manière très significative. Ceci est différent de WebP qui ne produit pas toujours des images plus petites que JPEG et peut en fait être un net- perte due au manque de support pour le chargement progressif."

Nous pouvons utiliser AVIF comme une amélioration progressive, fournissant WebP ou JPEG ou PNG aux anciens navigateurs. (Grand aperçu). Voir la vue en texte brut ci-dessous. Ironiquement, AVIF peut être encore plus performant que les grands SVG, même s'il ne doit bien sûr pas être considéré comme un substitut aux SVG. C'est également l'un des premiers formats d'image à prendre en charge la prise en charge des couleurs HDR ; offrant une luminosité, une profondeur de couleur et des gammes de couleurs plus élevées. Le seul inconvénient est qu'actuellement, AVIF ne prend pas en charge le décodage progressif des images (encore ?) et, comme Brotli, un encodage à taux de compression élevé est actuellement assez lent, bien que le décodage soit rapide.
AVIF est actuellement pris en charge dans Chrome, Firefox et Opera, et le support dans Safari devrait arriver bientôt (car Apple est membre du groupe qui a créé AV1).
Quelle est la meilleure façon de diffuser des images de nos jours ? Pour les illustrations et les images vectorielles, le SVG (compressé) est sans aucun doute le meilleur choix. Pour les photos, nous utilisons des méthodes de négociation de contenu avec l'élément
picture. Si AVIF est pris en charge, nous envoyons une image AVIF ; si ce n'est pas le cas, nous revenons d'abord à WebP, et si WebP n'est pas pris en charge non plus, nous passons à JPEG ou PNG comme solution de secours (en appliquant les conditions@mediasi nécessaire) :<picture> <source type="image/avif"> <source type="image/webp"> <img src="image.jpg" alt="Photo" width="450" height="350"> </picture>Franchement, il est plus probable que nous utilisions certaines conditions dans l'élément
picture:<picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture><picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture>Vous pouvez aller encore plus loin en échangeant des images animées avec des images statiques pour les clients qui optent pour moins de mouvement avec
prefers-reduced-motion:<picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture><picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture>Au cours des quelques mois, AVIF a gagné en popularité :
- Nous pouvons tester les solutions de repli WebP/AVIF dans le panneau Rendu de DevTools.
- Nous pouvons utiliser Squoosh, AVIF.io et libavif pour encoder, décoder, compresser et convertir des fichiers AVIF.
- Nous pouvons utiliser le composant AVIF Preact de Jake Archibald qui décode un fichier AVIF dans un worker et affiche le résultat sur un canevas,
- Pour fournir AVIF uniquement aux navigateurs compatibles, nous pouvons utiliser un plugin PostCSS avec un script 315B pour utiliser AVIF dans vos déclarations CSS.
- Nous pouvons progressivement fournir de nouveaux formats d'image avec CSS et Cloudlare Workers pour modifier dynamiquement le document HTML renvoyé, en déduisant les informations de l'en-tête d'
accept, puis ajouter leswebp/avif, etc., le cas échéant. - AVIF est déjà disponible dans Cloudinary (avec des limites d'utilisation), Cloudflare prend en charge AVIF dans le redimensionnement d'image et vous pouvez activer AVIF avec des en-têtes AVIF personnalisés dans Netlify.
- En ce qui concerne l'animation, AVIF fonctionne aussi bien que
<img src=mp4>de Safari, surpassant GIF et WebP dans son ensemble, mais MP4 fonctionne toujours mieux. - En général, pour les animations, AVC1 (h264) > HVC1 > WebP > AVIF > GIF, en supposant que les navigateurs basés sur Chromium prendront toujours en charge
<img src=mp4>. - Vous pouvez trouver plus de détails sur AVIF dans AVIF for Next Generation Image Coding talk par Aditya Mavlankar de Netflix, et The AVIF Image Format talk par Kornel Lesinski de Cloudflare.
- Une excellente référence pour tout AVIF : le post complet de Jake Archibald sur AVIF est arrivé.
Alors, le futur AVIF, alors ? Jon Sneyers n'est pas d'accord : AVIF est 60 % moins performant que JPEG XL, un autre format libre et ouvert développé par Google et Cloudinary. En fait, JPEG XL semble bien mieux fonctionner dans tous les domaines. Cependant, JPEG XL n'est encore qu'au stade final de la normalisation et ne fonctionne pas encore dans aucun navigateur. (À ne pas confondre avec le JPEG-XR de Microsoft provenant du bon vieux Internet Explorer 9 fois).
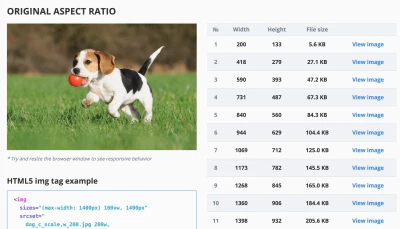
- Les JPEG/PNG/SVG sont-ils correctement optimisés ?
Lorsque vous travaillez sur une page de destination sur laquelle il est essentiel qu'une image de héros se charge à une vitesse fulgurante, assurez-vous que les fichiers JPEG sont progressifs et compressés avec mozJPEG (qui améliore le temps de rendu de démarrage en manipulant les niveaux de numérisation) ou Guetzli, l'open-source de Google encodeur se concentrant sur les performances perceptuelles et utilisant les enseignements de Zopfli et WebP. Seul bémol : des temps de traitement lents (une minute de CPU par mégapixel).Pour PNG, nous pouvons utiliser Pingo, et pour SVG, nous pouvons utiliser SVGO ou SVGOMG. Et si vous avez besoin de prévisualiser et de copier ou de télécharger rapidement tous les éléments SVG d'un site Web, svg-grabber peut également le faire pour vous.
Chaque article d'optimisation d'image l'indiquerait, mais garder les actifs vectoriels propres et serrés vaut toujours la peine d'être mentionné. Assurez-vous de nettoyer les ressources inutilisées, de supprimer les métadonnées inutiles et de réduire le nombre de points de chemin dans l'illustration (et donc le code SVG). ( Merci, Jérémie ! )
Il existe également des outils en ligne utiles :
- Utilisez Squoosh pour compresser, redimensionner et manipuler les images aux niveaux de compression optimaux (avec ou sans perte),
- Utilisez Guetzli.it pour compresser et optimiser les images JPEG avec Guetzli, qui fonctionne bien pour les images avec des bords nets et des couleurs unies (mais peut être un peu plus lent)).
- Utilisez le Responsive Image Breakpoints Generator ou un service tel que Cloudinary ou Imgix pour automatiser l'optimisation des images. De plus, dans de nombreux cas, l'utilisation
srcsetet desizesseules apportera des avantages significatifs. - Pour vérifier l'efficacité de votre balisage réactif, vous pouvez utiliser Imaging-heap, un outil de ligne de commande qui mesure l'efficacité des tailles de fenêtres et des ratios de pixels de l'appareil.
- Vous pouvez ajouter une compression d'image automatique à vos flux de travail GitHub, afin qu'aucune image ne puisse atteindre la production sans être compressée. L'action utilise mozjpeg et libvips qui fonctionnent avec les PNG et les JPG.
- Pour optimiser le stockage en interne, vous pouvez utiliser le nouveau format Lepton de Dropbox pour compresser sans perte les fichiers JPEG de 22 % en moyenne.
- Utilisez BlurHash si vous souhaitez afficher une image d'espace réservé plus tôt. BlurHash prend une image et vous donne une courte chaîne (seulement 20-30 caractères !) qui représente l'espace réservé pour cette image. La chaîne est suffisamment courte pour pouvoir être facilement ajoutée en tant que champ dans un objet JSON.
BlurHash est une petite représentation compacte d'un espace réservé pour une image. ( Grand aperçu ) Parfois, l'optimisation des images seule ne suffira pas. Pour améliorer le temps nécessaire pour démarrer le rendu d'une image critique, chargez paresseusement les images moins importantes et différez le chargement des scripts une fois que les images critiques ont déjà été rendues. Le moyen le plus à l'épreuve des balles est le chargement paresseux hybride, lorsque nous utilisons le chargement paresseux natif et le chargement paresseux, une bibliothèque qui détecte tout changement de visibilité déclenché par l'interaction de l'utilisateur (avec IntersectionObserver que nous explorerons plus tard). Aditionellement:
- Envisagez de précharger les images critiques, afin qu'un navigateur ne les découvre pas trop tard. Pour les images d'arrière-plan, si vous voulez être encore plus agressif que cela, vous pouvez ajouter l'image en tant qu'image normale avec
<img src>, puis la masquer hors de l'écran. - Envisagez d'échanger des images avec l'attribut Sizes en spécifiant différentes dimensions d'affichage d'image en fonction des requêtes multimédias, par exemple pour manipuler les
sizespour échanger les sources dans un composant de loupe. - Examinez les incohérences de téléchargement d'images pour éviter les téléchargements inattendus d'images de premier plan et d'arrière-plan. Méfiez-vous des images chargées par défaut, mais susceptibles de ne jamais être affichées, par exemple dans les carrousels, les accordéons et les galeries d'images.
- Assurez-vous de toujours définir la
widthet laheightdes images. Faites attention à la propriétéaspect-ratiodans CSS et à l'attributintrinsicsizequi nous permettra de définir les proportions et les dimensions des images, afin que le navigateur puisse réserver tôt un emplacement de mise en page prédéfini pour éviter les sauts de mise en page lors du chargement de la page.
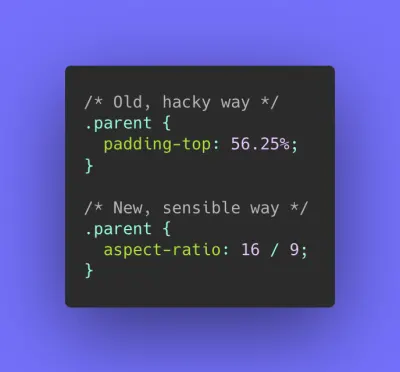
Cela ne devrait plus être qu'une question de semaines ou de mois maintenant, avec l'atterrissage du rapport d'aspect dans les navigateurs. Dans Safari Technical Preview 118 déjà. Actuellement derrière le drapeau dans Firefox et Chrome. ( Grand aperçu ) Si vous vous sentez aventureux, vous pouvez couper et réorganiser les flux HTTP/2 à l'aide des travailleurs Edge, essentiellement un filtre en temps réel vivant sur le CDN, pour envoyer des images plus rapidement via le réseau. Les travailleurs Edge utilisent des flux JavaScript qui utilisent des blocs que vous pouvez contrôler (essentiellement, il s'agit de JavaScript qui s'exécute sur la périphérie CDN qui peut modifier les réponses en streaming), afin que vous puissiez contrôler la livraison des images.
Avec un travailleur de service, il est trop tard car vous ne pouvez pas contrôler ce qui se passe sur le fil, mais cela fonctionne avec les travailleurs Edge. Vous pouvez donc les utiliser en plus des fichiers JPEG statiques enregistrés progressivement pour une page de destination particulière.
Un exemple de sortie par Imaging-heap, un outil de ligne de commande qui mesure l'efficacité entre les tailles de fenêtres et les ratios de pixels de l'appareil. (Source de l'image) ( Grand aperçu ) Pas assez bon? Eh bien, vous pouvez également améliorer les performances perçues pour les images avec la technique des images d'arrière-plan multiples. Gardez à l'esprit que jouer avec le contraste et brouiller les détails inutiles (ou supprimer les couleurs) peut également réduire la taille du fichier. Ah, vous avez besoin d' agrandir une petite photo sans perdre en qualité ? Pensez à utiliser Letsenhance.io.
Jusqu'à présent, ces optimisations ne couvrent que les bases. Addy Osmani a publié un guide très détaillé sur Essential Image Optimization qui va très loin dans les détails de la compression d'image et de la gestion des couleurs. Par exemple, vous pouvez flouter des parties inutiles de l'image (en leur appliquant un filtre de flou gaussien) pour réduire la taille du fichier, et éventuellement vous pouvez même commencer à supprimer des couleurs ou transformer l'image en noir et blanc pour réduire encore plus la taille. . Pour les images d'arrière-plan, l'exportation de photos depuis Photoshop avec une qualité de 0 à 10 % peut également être tout à fait acceptable.
Sur Smashing Magazine, nous utilisons le suffixe
-optpour les noms d'images — par exemple,brotli-compression-opt.png; chaque fois qu'une image contient ce suffixe, tout le monde dans l'équipe sait que l'image a déjà été optimisée.Ah, et n'utilisez pas JPEG-XR sur le Web - "le traitement du décodage côté logiciel des JPEG-XR sur le processeur annule et même compense l'impact potentiellement positif des économies de taille d'octet, en particulier dans le contexte des SPA" (pas à confondre avec le JPEG XL de Cloudinary/Google).

- Les vidéos sont-elles correctement optimisées ?
Nous avons couvert les images jusqu'à présent, mais nous avons évité une conversation sur les bons vieux GIF. Malgré notre amour pour les GIF, c'est vraiment le moment de les abandonner pour de bon (au moins dans nos sites Web et nos applications). Au lieu de charger des GIF animés lourds qui ont un impact à la fois sur les performances de rendu et sur la bande passante, c'est une bonne idée de passer soit au WebP animé (le GIF étant une solution de repli), soit de les remplacer par des vidéos HTML5 en boucle.Contrairement aux images, les navigateurs ne préchargent pas le contenu
<video>, mais les vidéos HTML5 ont tendance à être beaucoup plus légères et plus petites que les GIF. Pas une option? Eh bien, au moins, nous pouvons ajouter une compression avec perte aux GIF avec Lossy GIF, gifsicle ou giflossy.Les tests de Colin Bendell montrent que les vidéos intégrées dans les balises
imgde Safari Technology Preview s'affichent au moins 20 fois plus vite et décodent 7 fois plus vite que l'équivalent GIF, en plus d'être une fraction de la taille du fichier. Cependant, il n'est pas pris en charge dans d'autres navigateurs.Au pays des bonnes nouvelles, les formats vidéo ont énormément progressé au fil des ans. Pendant longtemps, nous avions espéré que WebM deviendrait le format pour les gouverner tous, et WebP (qui est essentiellement une image fixe à l'intérieur du conteneur vidéo WebM) remplacerait les formats d'image obsolètes. En effet, Safari prend désormais en charge WebP, mais malgré le soutien de WebP et WebM ces jours-ci, la percée ne s'est pas vraiment produite.
Pourtant, nous pourrions utiliser WebM pour la plupart des navigateurs modernes :
<!-- By Houssein Djirdeh. https://web.dev/replace-gifs-with-videos/ --> <!-- A common scenartio: MP4 with a WEBM fallback. --> <video autoplay loop muted playsinline> <source src="my-animation.webm" type="video/webm"> <source src="my-animation.mp4" type="video/mp4"> </video>Mais peut-être pourrions-nous le revoir complètement. En 2018, l'Alliance of Open Media a publié un nouveau format vidéo prometteur appelé AV1 . AV1 a une compression similaire au codec H.265 (l'évolution de H.264) mais contrairement à ce dernier, AV1 est gratuit. Le prix de la licence H.265 a poussé les fournisseurs de navigateurs à adopter à la place un AV1 aux performances comparables : AV1 (tout comme H.265) se comprime deux fois mieux que WebM .

AV1 a de bonnes chances de devenir la norme ultime pour la vidéo sur le Web. (Crédit image: Wikimedia.org) ( Grand aperçu ) En fait, Apple utilise actuellement le format HEIF et HEVC (H.265), et toutes les photos et vidéos du dernier iOS sont enregistrées dans ces formats, et non en JPEG. Alors que HEIF et HEVC (H.265) ne sont pas correctement exposés au Web (encore ?), AV1 l'est - et il est de plus en plus pris en charge par les navigateurs. Il est donc raisonnable d'ajouter la source
AV1dans votre<video>, car tous les fournisseurs de navigateurs semblent être de la partie.Pour l'instant, l'encodage le plus largement utilisé et pris en charge est H.264, servi par les fichiers MP4, donc avant de servir le fichier, assurez-vous que vos MP4 sont traités avec un encodage multipasse, flouté avec l'effet frei0r iirblur (le cas échéant) et Les métadonnées moov atom sont déplacées vers l'en-tête du fichier, tandis que votre serveur accepte le service d'octets. Boris Schapira fournit des instructions précises à FFmpeg pour optimiser les vidéos au maximum. Bien sûr, fournir le format WebM comme alternative serait également utile.
Besoin de commencer à rendre les vidéos plus rapidement mais les fichiers vidéo sont encore trop volumineux ? Par exemple, chaque fois que vous avez une grande vidéo d'arrière-plan sur une page de destination ? Une technique courante à utiliser consiste à afficher d'abord la toute première image sous forme d'image fixe, ou à afficher un court segment en boucle fortement optimisé qui pourrait être interprété comme faisant partie de la vidéo, puis, chaque fois que la vidéo est suffisamment mise en mémoire tampon, commencer à jouer la vidéo réelle. Doug Sillars a écrit un guide détaillé sur les performances vidéo en arrière-plan qui pourrait être utile dans ce cas. ( Merci Guy Podjarny ! ).
Pour le scénario ci-dessus, vous souhaiterez peut-être fournir des images d'affiches réactives . Par défaut, les éléments
videon'autorisent qu'une seule image comme affiche, ce qui n'est pas nécessairement optimal. Nous pouvons utiliser Responsive Video Poster, une bibliothèque JavaScript qui vous permet d'utiliser différentes images d'affiches pour différents écrans, tout en ajoutant une superposition de transition et un contrôle complet du style des espaces réservés vidéo.La recherche montre que la qualité du flux vidéo a un impact sur le comportement des spectateurs. En fait, les téléspectateurs commencent à abandonner la vidéo si le délai de démarrage dépasse environ 2 secondes. Au-delà de ce point, une augmentation d'une seconde du délai entraîne une augmentation d'environ 5,8 % du taux d'abandon. Il n'est donc pas surprenant que le temps de démarrage vidéo médian soit de 12,8 s, avec 40 % des vidéos ayant au moins 1 blocage et 20 % au moins 2 s de lecture vidéo bloquée. En fait, les décrochages vidéo sont inévitables sur la 3G car les vidéos sont lues plus rapidement que le réseau ne peut fournir de contenu.
Alors, quelle est la solution ? Habituellement, les appareils à petit écran ne peuvent pas gérer les 720p et 1080p que nous desservons sur le bureau. Selon Doug Sillars, nous pouvons soit créer des versions plus petites de nos vidéos, et utiliser Javascript pour détecter la source des écrans plus petits afin d'assurer une lecture rapide et fluide sur ces appareils. Alternativement, nous pouvons utiliser la vidéo en streaming. Les flux vidéo HLS fourniront une vidéo de taille appropriée à l'appareil, évitant ainsi la nécessité de créer différentes vidéos pour différents écrans. Il négociera également la vitesse du réseau et adaptera le débit vidéo à la vitesse du réseau que vous utilisez.
Pour éviter le gaspillage de bande passante, nous ne pouvions ajouter la source vidéo que pour les appareils capables de lire correctement la vidéo. Alternativement, nous pouvons supprimer complètement l'attribut de
autoplayde la balisevideoet utiliser JavaScript pour insérer laautoplaypour les écrans plus grands. De plus, nous devons ajouterpreload="none"survideopour dire au navigateur de ne télécharger aucun des fichiers vidéo jusqu'à ce qu'il ait réellement besoin du fichier :<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>Ensuite, nous pouvons cibler spécifiquement les navigateurs qui prennent réellement en charge AV1 :
<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.av1.mp4" type="video/mp4; codecs=av01.0.05M.08"> <source src="video.hevc.mp4" type="video/mp4; codecs=hevc"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>On pourrait alors rajouter l'
autoplayau dessus d'un certain seuil (par exemple 1000px) :/* By Doug Sillars. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ */ <script> window.onload = addAutoplay(); var videoLocation = document.getElementById("hero-video"); function addAutoplay() { if(window.innerWidth > 1000){ videoLocation.setAttribute("autoplay",""); }; } </script>
Nombre de décrochages par appareil et vitesse du réseau. Les appareils plus rapides sur des réseaux plus rapides n'ont pratiquement pas de décrochage. D'après les recherches de Doug Sillars. ( Grand aperçu ) Les performances de lecture vidéo sont une histoire en soi, et si vous souhaitez vous plonger dans les détails, jetez un œil à une autre série de Doug Sillars sur l'état actuel des meilleures pratiques de diffusion vidéo et vidéo qui inclut des détails sur les mesures de diffusion vidéo. , préchargement vidéo, compression et streaming. Enfin, vous pouvez vérifier la lenteur ou la rapidité de votre streaming vidéo avec Stream or Not.
- La livraison des polices Web est-elle optimisée ?
The first question that's worth asking is if we can get away with using UI system fonts in the first place — we just need to make sure to double check that they appear correctly on various platforms. If it's not the case, chances are high that the web fonts we are serving include glyphs and extra features and weights that aren't being used. We can ask our type foundry to subset web fonts or if we are using open-source fonts, subset them on our own with Glyphhanger or Fontsquirrel. We can even automate our entire workflow with Peter Muller's subfont, a command line tool that statically analyses your page in order to generate the most optimal web font subsets, and then inject them into our pages.WOFF2 support is great, and we can use WOFF as fallback for browsers that don't support it — or perhaps legacy browsers could be served system fonts. There are many, many, many options for web font loading, and we can choose one of the strategies from Zach Leatherman's "Comprehensive Guide to Font-Loading Strategies," (code snippets also available as Web font loading recipes).
Probably the better options to consider today are Critical FOFT with
preloadand "The Compromise" method. Both of them use a two-stage render for delivering web fonts in steps — first a small supersubset required to render the page fast and accurately with the web font, and then load the rest of the family async. The difference is that "The Compromise" technique loads polyfill asynchronously only if font load events are not supported, so you don't need to load the polyfill by default. Need a quick win? Zach Leatherman has a quick 23-min tutorial and case study to get your fonts in order.In general, it might be a good idea to use the
preloadresource hint to preload fonts, but in your markup include the hints after the link to critical CSS and JavaScript. Withpreload, there is a puzzle of priorities, so consider injectingrel="preload"elements into the DOM just before the external blocking scripts. According to Andy Davies, "resources injected using a script are hidden from the browser until the script executes, and we can use this behaviour to delay when the browser discovers thepreloadhint." Otherwise, font loading will cost you in the first render time.
When everything is critical, nothing is critical. preload only one or a maximum of two fonts of each family. (Image credit: Zach Leatherman – slide 93) (Large preview) It's a good idea to be selective and choose files that matter most, eg the ones that are critical for rendering or that would help you avoiding visible and disruptive text reflows. In general, Zach advises to preload one or two fonts of each family — it also makes sense to delay some font loading if they are less critical.
It has become quite common to use
local()value (which refers to a local font by name) when defining afont-familyin the@font-facerule:/* Warning! Not a good idea! */ @font-face { font-family: Open Sans; src: local('Open Sans Regular'), local('OpenSans-Regular'), url('opensans.woff2') format ('woff2'), url('opensans.woff') format('woff'); }The idea is reasonable: some popular open-source fonts such as Open Sans are coming pre-installed with some drivers or apps, so if the font is available locally, the browser doesn't need to download the web font and can display the local font immediately. As Bram Stein noted, "though a local font matches the name of a web font, it most likely isn't the same font . Many web fonts differ from their "desktop" version. The text might be rendered differently, some characters may fall back to other fonts, OpenType features can be missing entirely, or the line height may be different."
Also, as typefaces evolve over time, the locally installed version might be very different from the web font, with characters looking very different. So, according to Bram, it's better to never mix locally installed fonts and web fonts in
@font-facerules. Google Fonts has followed suit by disablinglocal()on the CSS results for all users, other than Android requests for Roboto.Nobody likes waiting for the content to be displayed. With the
font-displayCSS descriptor, we can control the font loading behavior and enable content to be readable immediately (withfont-display: optional) or almost immediately (with a timeout of 3s, as long as the font gets successfully downloaded — withfont-display: swap). (Well, it's a bit more complicated than that.)However, if you want to minimize the impact of text reflows, we could use the Font Loading API (supported in all modern browsers). Specifically that means for every font, we'd creata a
FontFaceobject, then try to fetch them all, and only then apply them to the page. This way, we group all repaints by loading all fonts asynchronously, and then switch from fallback fonts to the web font exactly once. Take a look at Zach's explanation, starting at 32:15, and the code snippet):/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));To initiate a very early fetch of the fonts with Font Loading API in use, Adrian Bece suggests to add a non-breaking space
nbsp;at the top of thebody, and hide it visually witharia-visibility: hiddenand a.hiddenclass:<body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body><body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body>This goes along with CSS that has different font families declared for different states of loading, with the change triggered by Font Loading API once the fonts have successfully loaded:
body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }If you ever wondered why despite all your optimizations, Lighthouse still suggests to eliminate render-blocking resources (fonts), in the same article Adrian Bece provides a few techniques to make Lighthouse happy, along with a Gatsby Omni Font Loader, a performant asynchronous font loading and Flash Of Unstyled Text (FOUT) handling plugin for Gatsby.
Now, many of us might be using a CDN or a third-party host to load web fonts from. In general, it's always better to self-host all your static assets if you can, so consider using google-webfonts-helper, a hassle-free way to self-host Google Fonts. And if it's not possible, you can perhaps proxy the Google Font files through the page origin.
It's worth noting though that Google is doing quite a bit of work out of the box, so a server might need a bit of tweaking to avoid delays ( thanks, Barry! )

This is quite important especially as since Chrome v86 (released October 2020), cross-site resources like fonts can't be shared on the same CDN anymore — due to the partitioned browser cache. This behavior was a default in Safari for years.
But if it's not possible at all, there is a way to get to the fastest possible Google Fonts with Harry Roberts' snippet:
<!-- By Harry Roberts. https://csswizardry.com/2020/05/the-fastest-google-fonts/ - 1. Preemptively warm up the fonts' origin. - 2. Initiate a high-priority, asynchronous fetch for the CSS file. Works in - most modern browsers. - 3. Initiate a low-priority, asynchronous fetch that gets applied to the page - only after it's arrived. Works in all browsers with JavaScript enabled. - 4. In the unlikely event that a visitor has intentionally disabled - JavaScript, fall back to the original method. The good news is that, - although this is a render-blocking request, it can still make use of the - preconnect which makes it marginally faster than the default. --> <!-- [1] --> <link rel="preconnect" href="https://fonts.gstatic.com" crossorigin /> <!-- [2] --> <link rel="preload" as="style" href="$CSS&display=swap" /> <!-- [3] --> <link rel="stylesheet" href="$CSS&display=swap" media="print" onload="this.media='all'" /> <!-- [4] --> <noscript> <link rel="stylesheet" href="$CSS&display=swap" /> </noscript>Harry's strategy is to pre-emptively warm up the fonts' origin first. Then we initiate a high-priority, asynchronous fetch for the CSS file. Afterwards, we initiate a low-priority, asynchronous fetch that gets applied to the page only after it's arrived (with a print stylesheet trick). Finally, if JavaScript isn't supported, we fall back to the original method.
Ah, talking about Google Fonts: you can shave up to 90% of the size of Google Fonts requests by declaring only characters you need with
&text. Plus, the support for font-display was added recently to Google Fonts as well, so we can use it out of the box.Un petit avertissement cependant. Si vous utilisez
font-display: optional, il peut être sous-optimal d'utiliser également lepreloadcar il déclenchera cette demande de police Web plus tôt (provoquant une congestion du réseau si vous avez d'autres ressources de chemin critique qui doivent être récupérées). Utilisez lapreconnectpour des requêtes de polices d'origines différentes plus rapides, mais soyez prudent avec lepreloadcar le préchargement de polices d'une origine différente entraînera des conflits de réseau. Toutes ces techniques sont couvertes dans les recettes de chargement de polices Web de Zach.D'un autre côté, il peut être judicieux de désactiver les polices Web (ou au moins le rendu de deuxième étape) si l'utilisateur a activé Réduire le mouvement dans les préférences d'accessibilité ou a opté pour le mode Économiseur de données (voir l'en-tête
Save-Data) , ou lorsque l'utilisateur a une connexion lente (via l'API Network Information).Nous pouvons également utiliser la requête multimédia CSS
prefers-reduced-datapour ne pas définir de déclaration de police si l'utilisateur a opté pour le mode d'économie de données (il existe également d'autres cas d'utilisation). La requête multimédia exposerait essentiellement si l'en-tête de requêteSave-Datade l'extension HTTP Client Hint est activé/désactivé pour permettre une utilisation avec CSS. Actuellement pris en charge uniquement dans Chrome et Edge derrière un drapeau.Métrique? Pour mesurer les performances de chargement des polices Web, considérez la métrique Tout le texte visible (le moment où toutes les polices sont chargées et tout le contenu est affiché dans les polices Web), le temps de mise en italique réel ainsi que le nombre de refusions des polices Web après le premier rendu. Évidemment, plus les deux mesures sont basses, meilleures sont les performances.
Qu'en est-il des polices variables , me demanderez-vous ? Il est important de noter que les polices variables peuvent nécessiter une prise en compte significative des performances. Ils nous donnent un espace de conception beaucoup plus large pour les choix typographiques, mais cela se fait au prix d'une seule demande en série par opposition à un certain nombre de demandes de fichiers individuels.
Alors que les polices variables réduisent considérablement la taille de fichier globale combinée des fichiers de polices, cette requête unique peut être lente, bloquant le rendu de tout le contenu d'une page. Donc, le sous-ensemble et la division de la police en jeux de caractères sont toujours importants. Du bon côté cependant, avec une police variable en place, nous aurons exactement un reflow par défaut, donc aucun JavaScript ne sera nécessaire pour regrouper les repaints.
Maintenant, qu'est-ce qui constituerait alors une stratégie de chargement de polices Web à l'épreuve des balles ? Créez des sous-ensembles de polices et préparez-les pour le rendu en deux étapes, déclarez-les avec un descripteur
font-display, utilisez l'API de chargement de police pour regrouper les repeints et stocker les polices dans le cache d'un service worker persistant. Lors de la première visite, injectez le préchargement des scripts juste avant le blocage des scripts externes. Vous pouvez vous rabattre sur Font Face Observer de Bram Stein si nécessaire. Et si vous souhaitez mesurer les performances de chargement des polices, Andreas Marschke explore le suivi des performances avec l'API Font et l'API UserTiming.Enfin, n'oubliez pas d'inclure
unicode-rangepour décomposer une grande police en polices plus petites spécifiques à la langue, et utilisez le font-style-matcher de Monica Dinculescu pour minimiser un changement de mise en page discordant, en raison des écarts de taille entre le repli et le polices Web.Alternativement, pour émuler une police Web pour une police de secours, nous pouvons utiliser des descripteurs @font-face pour remplacer les métriques de police (démo, activé dans Chrome 87). (Notez que les ajustements sont compliqués avec des piles de polices compliquées.)
L'avenir s'annonce-t-il radieux ? Avec l'enrichissement progressif des polices, nous pourrons éventuellement "télécharger uniquement la partie requise de la police sur une page donnée, et pour les demandes ultérieures de cette police, "corriger" dynamiquement le téléchargement d'origine avec des ensembles supplémentaires de glyphes selon les besoins sur la page suivante vues", comme l'explique Jason Pamental. La démo de transfert incrémentiel est déjà disponible, et c'est en cours.
Construire des optimisations
- Avons-nous défini nos priorités ?
C'est une bonne idée de savoir à quoi vous avez affaire en premier. Faites un inventaire de tous vos actifs (JavaScript, images, polices, scripts tiers et modules "coûteux" sur la page, tels que des carrousels, des infographies complexes et du contenu multimédia), et décomposez-les en groupes.Mettre en place une feuille de calcul . Définissez l'expérience de base de base pour les navigateurs hérités (c'est-à-dire un contenu de base entièrement accessible), l'expérience améliorée pour les navigateurs capables (c'est-à-dire une expérience enrichie et complète) et les extras (actifs qui ne sont pas absolument nécessaires et peuvent être chargés paresseusement, tels que polices Web, styles inutiles, scripts de carrousel, lecteurs vidéo, widgets de médias sociaux, grandes images). Il y a des années, nous avons publié un article sur "Améliorer les performances de Smashing Magazine", qui décrit cette approche en détail.
Lors de l'optimisation des performances, nous devons refléter nos priorités. Chargez immédiatement l' expérience de base , puis les améliorations , puis les extras .
- Utilisez-vous des modules JavaScript natifs en production ?
Vous souvenez-vous de la bonne vieille technique de coupe de la moutarde pour envoyer l'expérience de base aux navigateurs hérités et une expérience améliorée aux navigateurs modernes ? Une variante mise à jour de la technique pourrait utiliser ES2017+<script type="module">, également connu sous le nom de modèle module/nomodule (également introduit par Jeremy Wagner en tant que service différentiel ).L'idée est de compiler et de servir deux bundles JavaScript distincts : le build "normal", celui avec Babel-transforms et polyfills et de les servir uniquement aux anciens navigateurs qui en ont réellement besoin, et un autre bundle (même fonctionnalité) qui n'a pas de transformations ou polyfills.
En conséquence, nous aidons à réduire le blocage du thread principal en réduisant la quantité de scripts que le navigateur doit traiter. Jeremy Wagner a publié un article complet sur le service différentiel et comment le configurer dans votre pipeline de construction, de la configuration de Babel aux modifications que vous devrez apporter à Webpack, ainsi que sur les avantages de faire tout ce travail.
Les scripts de module JavaScript natif sont différés par défaut, donc pendant l'analyse HTML, le navigateur télécharge le module principal.

Les modules JavaScript natifs sont différés par défaut. À peu près tout sur les modules JavaScript natifs. ( Grand aperçu ) Une note d'avertissement cependant : le modèle module/nomodule peut se retourner contre certains clients, vous pouvez donc envisager une solution de contournement : le modèle de service différentiel moins risqué de Jeremy qui, cependant, évite le scanner de préchargement, ce qui pourrait affecter les performances d'une manière que l'on ne pourrait pas anticiper. ( merci Jérémie ! )
En fait, Rollup prend en charge les modules comme format de sortie, nous pouvons donc regrouper le code et déployer les modules en production. Parcel prend en charge les modules dans Parcel 2. Pour Webpack, module-nomodule-plugin automatise la génération de scripts module/nomodule.
Remarque : Il convient de préciser que la détection de fonctionnalités seule ne suffit pas pour prendre une décision éclairée sur la charge utile à expédier à ce navigateur. À lui seul, nous ne pouvons pas déduire la capacité de l'appareil à partir de la version du navigateur. Par exemple, les téléphones Android bon marché dans les pays en développement exécutent principalement Chrome et réduiront la moutarde malgré leurs capacités de mémoire et de processeur limitées.
Finalement, en utilisant l'en-tête Device Memory Client Hints Header, nous serons en mesure de cibler les appareils bas de gamme de manière plus fiable. Au moment de l'écriture, l'en-tête n'est pris en charge que dans Blink (cela vaut pour les conseils client en général). Étant donné que la mémoire de l'appareil dispose également d'une API JavaScript disponible dans Chrome, une option pourrait être de détecter les fonctionnalités en fonction de l'API et de revenir au modèle module/nomodule s'il n'est pas pris en charge ( merci, Yoav ! ).
- Utilisez-vous l'arborescence, le levage de portée et le fractionnement de code ?
L'arborescence est un moyen de nettoyer votre processus de construction en n'incluant que le code réellement utilisé en production et en éliminant les importations inutilisées dans Webpack. Avec Webpack et Rollup, nous avons également un levage de portée qui permet aux deux outils de détecter où le chaînageimportpeut être aplati et converti en une fonction en ligne sans compromettre le code. Avec Webpack, nous pouvons également utiliser JSON Tree Shaking.Le fractionnement de code est une autre fonctionnalité de Webpack qui divise votre base de code en "morceaux" qui sont chargés à la demande. Tout le JavaScript ne doit pas être téléchargé, analysé et compilé immédiatement. Une fois que vous avez défini des points de partage dans votre code, Webpack peut prendre en charge les dépendances et les fichiers de sortie. Il vous permet de limiter le téléchargement initial et de demander du code à la demande lorsque l'application le demande. Alexander Kondrov a une introduction fantastique au fractionnement de code avec Webpack et React.
Envisagez d'utiliser preload-webpack-plugin qui prend les routes que vous divisez en code, puis invite le navigateur à les précharger en utilisant
<link rel="preload">ou<link rel="prefetch">. Les directives en ligne Webpack donnent également un certain contrôle sur lepreload/prefetch. (Attention aux problèmes de priorisation cependant.)Où définir les points de partage ? En suivant quels morceaux de CSS/JavaScript sont utilisés et lesquels ne sont pas utilisés. Umar Hansa explique comment vous pouvez utiliser la couverture de code de Devtools pour y parvenir.
Lorsqu'il s'agit d'applications d'une seule page, nous avons besoin d'un certain temps pour initialiser l'application avant de pouvoir afficher la page. Votre configuration nécessitera votre solution personnalisée, mais vous pouvez faire attention aux modules et aux techniques pour accélérer le temps de rendu initial. Par exemple, voici comment déboguer les performances de React et éliminer les problèmes de performances courants de React, et voici comment améliorer les performances dans Angular. En général, la plupart des problèmes de performances proviennent du démarrage initial de l'application.
Alors, quelle est la meilleure façon de diviser le code de manière agressive, mais pas trop agressive ? Selon Phil Walton, "en plus du fractionnement de code via des importations dynamiques, [nous pourrions] également utiliser le fractionnement de code au niveau du package , où chaque module de nœud importé est placé dans un bloc en fonction du nom de son package". Phil fournit également un tutoriel sur la façon de le construire.
- Pouvons-nous améliorer la sortie de Webpack ?
Comme Webpack est souvent considéré comme mystérieux, il existe de nombreux plugins Webpack qui peuvent être utiles pour réduire davantage la sortie de Webpack. Vous trouverez ci-dessous quelques-uns des plus obscurs qui pourraient nécessiter un peu plus d'attention.L'un des plus intéressants vient du fil d'Ivan Akulov. Imaginez que vous avez une fonction que vous appelez une fois, stockez son résultat dans une variable, puis n'utilisez pas cette variable. Tree-shaking supprimera la variable, mais pas la fonction, car elle pourrait être utilisée autrement. Cependant, si la fonction n'est utilisée nulle part, vous souhaiterez peut-être la supprimer. Pour ce faire, faites précéder l'appel de fonction de
/*#__PURE__*/qui est pris en charge par Uglify et Terser - c'est fait !
Pour supprimer une telle fonction lorsque son résultat n'est pas utilisé, ajoutez à l'appel de fonction /*#__PURE__*/. Via Ivan Akulov. ( Grand aperçu )Voici quelques-uns des autres outils recommandés par Ivan :
- purgecss-webpack-plugin supprime les classes inutilisées, en particulier lorsque vous utilisez Bootstrap ou Tailwind.
- Activer
optimization.splitChunks: 'all'avec split-chunks-plugin. Cela permettrait à Webpack de diviser automatiquement le code de vos bundles d'entrée pour une meilleure mise en cache. - Définir
optimization.runtimeChunk: true. Cela déplacerait l'exécution de Webpack dans un bloc séparé - et améliorerait également la mise en cache. - google-fonts-webpack-plugin télécharge les fichiers de polices, afin que vous puissiez les servir depuis votre serveur.
- workbox-webpack-plugin vous permet de générer un service worker avec une configuration de mise en cache préalable pour tous vos actifs webpack. Consultez également Service Worker Packages, un guide complet de modules pouvant être appliqués immédiatement. Ou utilisez preload-webpack-plugin pour générer un
preload/prefetchpour tous les morceaux JavaScript. - speed-measure-webpack-plugin mesure la vitesse de construction de votre webpack, fournissant des informations sur les étapes du processus de construction qui prennent le plus de temps.
- duplicate-package-checker-webpack-plugin vous avertit lorsque votre bundle contient plusieurs versions du même package.
- Utilisez l'isolation de portée et raccourcissez dynamiquement les noms de classe CSS au moment de la compilation.
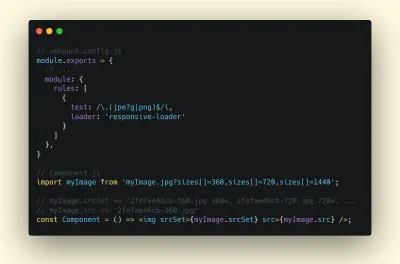
- Pouvez-vous décharger JavaScript dans un Web Worker ?
Pour réduire l'impact négatif sur le Time-to-Interactive, il peut être judicieux d'envisager de décharger du JavaScript lourd dans un Web Worker.Au fur et à mesure que la base de code continue de croître, les goulots d'étranglement des performances de l'interface utilisateur apparaîtront, ralentissant l'expérience de l'utilisateur. C'est parce que les opérations DOM s'exécutent parallèlement à votre JavaScript sur le thread principal. Avec les web workers, nous pouvons déplacer ces opérations coûteuses vers un processus d'arrière-plan qui s'exécute sur un thread différent. Les cas d'utilisation typiques pour les travailleurs Web sont la prélecture des données et les applications Web progressives pour charger et stocker certaines données à l'avance afin que vous puissiez les utiliser plus tard en cas de besoin. Et vous pouvez utiliser Comlink pour rationaliser la communication entre la page principale et le travailleur. Encore du travail à faire, mais nous y arrivons.
Il existe quelques études de cas intéressantes sur les travailleurs Web qui montrent différentes approches de déplacement du framework et de la logique d'application vers les travailleurs Web. La conclusion : en général, il y a encore des défis, mais il y a déjà de bons cas d'utilisation ( merci, Ivan Akulov ! ).
À partir de Chrome 80, un nouveau mode pour les travailleurs Web avec les avantages de performances des modules JavaScript a été livré, appelé modules workers. Nous pouvons modifier le chargement et l'exécution du script pour qu'ils correspondent au
script type="module", et nous pouvons également utiliser des importations dynamiques pour le chargement différé du code sans bloquer l'exécution du travailleur.Comment commencer? Voici quelques ressources qui valent la peine d'être consultées :
- Surma a publié un excellent guide sur la façon d'exécuter JavaScript à partir du fil principal du navigateur et aussi Quand devriez-vous utiliser Web Workers ?
- Consultez également le discours de Surma sur l'architecture du thread principal.
- A Quest to Guarantee Responsiveness de Shubhie Panicker et Jason Miller expliquent en détail comment utiliser les web workers et quand les éviter.
- Sortir du chemin des utilisateurs : Moins de Jank avec les Web Workers met en évidence des modèles utiles pour travailler avec les Web Workers, des moyens efficaces de communiquer entre les travailleurs, de gérer le traitement de données complexes hors du thread principal, de les tester et de les déboguer.
- Workerize vous permet de déplacer un module dans un Web Worker, reflétant automatiquement les fonctions exportées en tant que proxys asynchrones.
- Si vous utilisez Webpack, vous pouvez utiliser workerize-loader. Alternativement, vous pouvez également utiliser worker-plugin.

Utilisez les travailleurs Web lorsque le code bloque pendant une longue période, mais évitez-les lorsque vous comptez sur le DOM, gérez la réponse d'entrée et avez besoin d'un délai minimal. (via Addy Osmani) ( Grand aperçu ) Notez que les Web Workers n'ont pas accès au DOM car le DOM n'est pas "thread-safe", et le code qu'ils exécutent doit être contenu dans un fichier séparé.
- Pouvez-vous décharger les "chemins d'accès directs" vers WebAssembly ?
Nous pourrions décharger les tâches de calcul lourdes sur WebAssembly ( WASM ), un format d'instruction binaire, conçu comme une cible portable pour la compilation de langages de haut niveau comme C/C++/Rust. Son support de navigateur est remarquable, et il est récemment devenu viable car les appels de fonction entre JavaScript et WASM deviennent plus rapides. De plus, il est même pris en charge sur le cloud périphérique de Fastly.Bien sûr, WebAssembly n'est pas censé remplacer JavaScript, mais il peut le compléter dans les cas où vous remarquez des porcs CPU. Pour la plupart des applications Web, JavaScript convient mieux et WebAssembly est mieux utilisé pour les applications Web à forte intensité de calcul , telles que les jeux.
Si vous souhaitez en savoir plus sur WebAssembly :
- Lin Clark a écrit une série complète sur WebAssembly et Milica Mihajlija fournit un aperçu général de la façon d'exécuter du code natif dans le navigateur, pourquoi vous pourriez vouloir le faire et ce que tout cela signifie pour JavaScript et l'avenir du développement Web.
- Comment nous avons utilisé WebAssembly pour accélérer notre application Web par 20X (étude de cas) met en évidence une étude de cas sur la façon dont les calculs JavaScript lents ont été remplacés par WebAssembly compilé et ont apporté des améliorations significatives des performances.
- Patrick Hamann a parlé du rôle croissant de WebAssembly, et il démystifie certains mythes sur WebAssembly, explore ses défis et nous pouvons l'utiliser pratiquement dans les applications d'aujourd'hui.
- Google Codelabs propose une introduction à WebAssembly, un cours de 60 minutes dans lequel vous apprendrez à prendre du code natif en C et à le compiler en WebAssembly, puis à l'appeler directement à partir de JavaScript.
- Alex Danilo a expliqué WebAssembly et son fonctionnement lors de sa conférence Google I/O. En outre, Benedek Gagyi a partagé une étude de cas pratique sur WebAssembly, en particulier sur la manière dont l'équipe l'utilise comme format de sortie pour sa base de code C++ vers iOS, Android et le site Web.
Vous ne savez toujours pas quand utiliser les Web Workers, l'assemblage Web, les flux ou peut-être l'API JavaScript WebGL pour accéder au GPU ? Accélérer JavaScript est un guide court mais utile qui explique quand utiliser quoi et pourquoi - également avec un organigramme pratique et de nombreuses ressources utiles.
- Ne diffusons-nous le code hérité qu'aux navigateurs hérités ?
ES2017 étant remarquablement bien pris en charge dans les navigateurs modernes, nous pouvons utiliserbabelEsmPluginpour transpiler uniquement les fonctionnalités ES2017+ non prises en charge par les navigateurs modernes que vous ciblez.Houssein Djirdeh et Jason Miller ont récemment publié un guide complet sur la façon de transpiler et de servir du JavaScript moderne et hérité, en expliquant en détail comment le faire fonctionner avec Webpack et Rollup, et les outils nécessaires. Vous pouvez également estimer la quantité de JavaScript que vous pouvez éliminer sur votre site ou vos ensembles d'applications.
Les modules JavaScript sont pris en charge dans tous les principaux navigateurs, utilisez donc le
script type="module"pour permettre aux navigateurs prenant en charge le module ES de charger le fichier, tandis que les navigateurs plus anciens pourraient charger des versions héritées avecscript nomodule.De nos jours, nous pouvons écrire du JavaScript basé sur des modules qui s'exécute nativement dans le navigateur, sans transpilers ni bundlers. L'en-tête
<link rel="modulepreload">fournit un moyen d'initier le chargement précoce (et prioritaire) des scripts de module. Fondamentalement, c'est un moyen astucieux d'aider à maximiser l'utilisation de la bande passante, en indiquant au navigateur ce qu'il doit récupérer afin qu'il ne soit pas coincé avec quoi que ce soit à faire pendant ces longs allers-retours. De plus, Jake Archibald a publié un article détaillé avec des pièges et des choses à garder à l'esprit avec les modules ES qui mérite d'être lu.
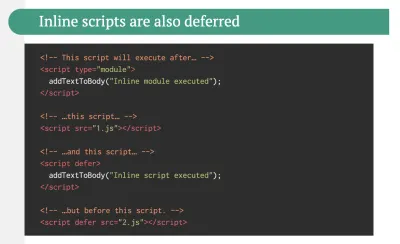
- Identifiez et réécrivez le code hérité avec un découplage incrémentiel .
Les projets de longue durée ont tendance à accumuler de la poussière et du code daté. Revoyez vos dépendances et évaluez le temps nécessaire pour refactoriser ou réécrire le code hérité qui a causé des problèmes ces derniers temps. Bien sûr, c'est toujours une grande entreprise, mais une fois que vous connaissez l'impact du code hérité, vous pouvez commencer par un découplage incrémentiel.Tout d'abord, configurez des métriques qui permettent de savoir si le ratio d'appels de code hérité reste constant ou diminue, et non augmente. Découragez publiquement l'équipe d'utiliser la bibliothèque et assurez-vous que votre CI alerte les développeurs si elle est utilisée dans les demandes d'extraction. les polyfills pourraient aider à passer du code hérité à une base de code réécrite qui utilise les fonctionnalités standard du navigateur.
- Identifiez et supprimez les CSS/JS inutilisés .
La couverture du code CSS et JavaScript dans Chrome vous permet de savoir quel code a été exécuté/appliqué et lequel ne l'a pas été. Vous pouvez commencer à enregistrer la couverture, effectuer des actions sur une page, puis explorer les résultats de la couverture du code. Une fois que vous avez détecté du code inutilisé, recherchez ces modules et chargez-les avecimport()(voir l'intégralité du fil). Ensuite, répétez le profil de couverture et confirmez qu'il expédie désormais moins de code lors du chargement initial.Vous pouvez utiliser Puppeteer pour collecter par programme la couverture du code. Chrome vous permet également d'exporter les résultats de la couverture du code. Comme l'a noté Andy Davies, vous souhaiterez peut-être collecter la couverture de code pour les navigateurs modernes et hérités.
Il existe de nombreux autres cas d'utilisation et outils pour Puppetter qui pourraient nécessiter un peu plus d'exposition :
- Cas d'utilisation de Puppeteer, tels que, par exemple, la différenciation visuelle automatique ou la surveillance des CSS inutilisés à chaque build,
- Recettes de performance web avec Puppeteer,
- Outils utiles pour enregistrer et générer des scripts de marionnettiste et de dramaturge,
- De plus, vous pouvez même enregistrer des tests directement dans DevTools,
- Présentation complète de Puppeteer par Nitay Neeman, avec des exemples et des cas d'utilisation.
Nous pouvons utiliser Puppeteer Recorder et Puppeteer Sandbox pour enregistrer l'interaction du navigateur et générer des scripts Puppeteer et Playwright. ( Grand aperçu ) De plus, purgecss, UnCSS et Helium peuvent vous aider à supprimer les styles inutilisés du CSS. Et si vous n'êtes pas certain qu'un morceau de code suspect est utilisé quelque part, vous pouvez suivre les conseils de Harry Roberts : créez un GIF transparent 1×1px pour une classe particulière et déposez-le dans un répertoire
dead/, par exemple/assets/img/dead/comments.gif.Après cela, vous définissez cette image spécifique comme arrière-plan sur le sélecteur correspondant dans votre CSS, asseyez-vous et attendez quelques mois si le fichier doit apparaître dans vos journaux. S'il n'y a pas d'entrées, personne n'a rendu ce composant hérité sur son écran : vous pouvez probablement continuer et tout supprimer.
Pour le département I-feel-adventurous , vous pouvez même automatiser la collecte sur les CSS inutilisés via un ensemble de pages en surveillant DevTools à l'aide de DevTools.
- Réduisez la taille de vos bundles JavaScript.
Comme Addy Osmani l'a noté, il y a de fortes chances que vous expédiez des bibliothèques JavaScript complètes lorsque vous n'avez besoin que d'une fraction, ainsi que des polyfills datés pour les navigateurs qui n'en ont pas besoin, ou simplement du code en double. Pour éviter les frais généraux, envisagez d'utiliser webpack-libs-optimizations qui supprime les méthodes et polyfills inutilisés pendant le processus de construction.Vérifiez et passez en revue les polyfills que vous envoyez aux navigateurs hérités et aux navigateurs modernes, et soyez plus stratégique à leur sujet. Jetez un œil à polyfill.io qui est un service qui accepte une demande pour un ensemble de fonctionnalités du navigateur et renvoie uniquement les polyfills nécessaires au navigateur demandeur.
Ajoutez également l' audit de bundle à votre flux de travail habituel. Il peut y avoir des alternatives légères aux bibliothèques lourdes que vous avez ajoutées il y a des années, par exemple Moment.js (maintenant abandonné) pourrait être remplacé par :
- API d'internationalisation native,
- Day.js avec une API et des modèles Moment.js familiers,
- date-fns ou
- Luxon.
- Vous pouvez également utiliser Skypack Discover qui combine des recommandations de packages examinées par un humain avec une recherche axée sur la qualité.
Les recherches de Benedikt Rotsch ont montré qu'un passage de Moment.js à date-fns pourrait réduire d'environ 300 ms pour First paint sur 3G et un téléphone mobile bas de gamme.
Pour l'audit de bundle, Bundlephobia peut vous aider à déterminer le coût de l'ajout d'un package npm à votre bundle. size-limit étend la vérification de base de la taille du bundle avec des détails sur le temps d'exécution de JavaScript. Vous pouvez même intégrer ces coûts à un audit personnalisé Lighthouse. Cela vaut aussi pour les frameworks. En supprimant ou en coupant l'adaptateur Vue MDC (composants matériels pour Vue), les styles passent de 194 Ko à 10 Ko.
Il existe de nombreux autres outils pour vous aider à prendre une décision éclairée sur l'impact de vos dépendances et des alternatives viables :
- analyseur de bundle webpack
- Explorateur de carte source
- Pack Ami
- Bundlephobie
- L'analyse Webpack montre pourquoi un module spécifique est inclus dans le bundle.
- bundle-wizard construit également une carte des dépendances pour toute la page.
- Plugin de taille Webpack
- Coût d'importation pour le code visuel
Au lieu d'expédier l'ensemble du framework, vous pouvez découper votre framework et le compiler dans un bundle JavaScript brut qui ne nécessite pas de code supplémentaire. Svelte le fait, tout comme le plug-in Rawact Babel qui transpile les composants React.js en opérations DOM natives au moment de la construction. Pourquoi? Eh bien, comme l'expliquent les responsables, "react-dom inclut du code pour chaque composant/HTMLElement possible qui peut être rendu, y compris le code pour le rendu incrémentiel, la planification, la gestion des événements, etc. Mais il existe des applications qui n'ont pas besoin de toutes ces fonctionnalités (au départ chargement de la page). Pour de telles applications, il peut être judicieux d'utiliser des opérations DOM natives pour créer l'interface utilisateur interactive."
- Utilisons-nous une hydratation partielle?
Avec la quantité de JavaScript utilisé dans les applications, nous devons trouver des moyens d'en envoyer le moins possible au client. Une façon de le faire - et nous l'avons déjà brièvement couvert - consiste à hydrater partiellement. L'idée est assez simple : au lieu de faire de la SSR puis d'envoyer l'intégralité de l'application au client, seuls de petits morceaux de JavaScript de l'application seraient envoyés au client, puis hydratés. Nous pouvons le considérer comme plusieurs petites applications React avec plusieurs racines de rendu sur un site Web autrement statique.Dans l'article "Le cas de l'hydratation partielle (avec Next et Preact)", Lukas Bombach explique comment l'équipe derrière Welt.de, l'un des organes de presse en Allemagne, a obtenu de meilleures performances avec l'hydratation partielle. Vous pouvez également consulter le prochain référentiel GitHub super performant avec des explications et des extraits de code.
Vous pouvez également envisager des options alternatives :
- hydratation partielle avec Preact et Eleventy,
- hydratation progressive dans React GitHub repo,
- hydratation paresseuse dans Vue.js (dépôt GitHub),
- Importez sur le modèle d'interaction pour charger paresseusement les ressources non critiques (par exemple, les composants, les intégrations) lorsqu'un utilisateur interagit avec l'interface utilisateur qui en a besoin.
Jason Miller a publié des démos de travail sur la façon dont l'hydratation progressive pourrait être mise en œuvre avec React, vous pouvez donc les utiliser immédiatement : démo 1, démo 2, démo 3 (également disponible sur GitHub). De plus, vous pouvez consulter la bibliothèque de composants pré-rendus de réaction.
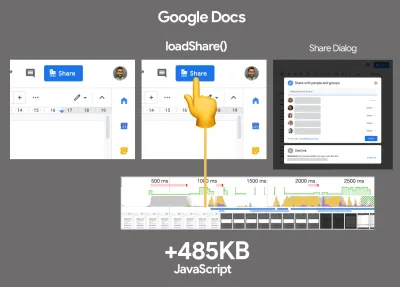
L'importation sur interaction pour le code propriétaire ne doit être effectuée que si vous ne parvenez pas à préextraire les ressources avant l'interaction. ( Grand aperçu ) - Avons-nous optimisé la stratégie pour React/SPA ?
Vous avez des difficultés avec les performances de votre application d'application monopage ? Jeremy Wagner a exploré l'impact des performances du framework côté client sur une variété d'appareils, soulignant certaines des implications et des directives dont nous pourrions vouloir être conscients lors de l'utilisation d'un.En conséquence, voici une stratégie SPA que Jeremy suggère d'utiliser pour le framework React (mais cela ne devrait pas changer de manière significative pour les autres frameworks) :
- Refactorisez les composants avec état en tant que composants sans état dans la mesure du possible.
- Prérendez les composants sans état lorsque cela est possible pour minimiser le temps de réponse du serveur. Rendu uniquement sur le serveur.
- Pour les composants avec état avec une interactivité simple, envisagez le prérendu ou le rendu du serveur de ce composant, et remplacez son interactivité par des écouteurs d'événement indépendants du framework .
- Si vous devez hydrater des composants avec état sur le client, utilisez l'hydratation paresseuse sur la visibilité ou l'interaction.
- Pour les composants hydratés paresseusement, planifiez leur hydratation pendant le temps d'inactivité du thread principal avec
requestIdleCallback.
Il existe quelques autres stratégies que vous voudrez peut-être poursuivre ou revoir :
- Considérations sur les performances pour CSS-in-JS dans les applications React
- Réduisez la taille du bundle Next.js en chargeant des polyfills uniquement lorsque cela est nécessaire, en utilisant des importations dynamiques et une hydratation paresseuse.
- Secrets of JavaScript: A tale of React, Performance Optimization and Multi-threading, une longue série en 7 parties sur l'amélioration des défis de l'interface utilisateur avec React,
- Comment mesurer les performances de React et comment profiler les applications React.
- Construire des animations Web mobiles d'abord dans React, une conférence fantastique d'Alex Holachek, ainsi que des diapositives et un dépôt GitHub ( merci pour le conseil, Addy ! ).
- webpack-libs-optimizations est un référentiel GitHub fantastique avec de nombreuses optimisations utiles liées aux performances spécifiques à Webpack. Maintenu par Ivan Akulov.
- Améliorations des performances de React dans Notion, un guide d'Ivan Akulov sur la façon d'améliorer les performances dans React, avec de nombreux conseils utiles pour rendre l'application environ 30 % plus rapide.
- React Refresh Webpack Plugin (expérimental) permet un rechargement à chaud qui préserve l'état des composants et prend en charge les hooks et les composants fonctionnels.
- Méfiez-vous des composants de serveur React de taille nulle, un nouveau type de composants proposé qui n'aura aucun impact sur la taille du bundle. Le projet est actuellement en développement, mais tout retour de la communauté est très apprécié (super explicatif de Sophie Alpert).
- Utilisez-vous la prélecture prédictive pour les morceaux JavaScript ?
Nous pourrions utiliser des heuristiques pour décider quand précharger les morceaux JavaScript. Guess.js est un ensemble d'outils et de bibliothèques qui utilisent les données de Google Analytics pour déterminer quelle page un utilisateur est le plus susceptible de visiter ensuite à partir d'une page donnée. Sur la base des modèles de navigation des utilisateurs collectés à partir de Google Analytics ou d'autres sources, Guess.js construit un modèle d'apprentissage automatique pour prédire et prérécupérer le JavaScript qui sera requis sur chaque page suivante.Par conséquent, chaque élément interactif reçoit un score de probabilité d'engagement et, sur la base de ce score, un script côté client décide de prérécupérer une ressource à l'avance. Vous pouvez intégrer la technique à votre application Next.js, Angular et React, et il existe un plugin Webpack qui automatise également le processus de configuration.
Évidemment, vous pourriez demander au navigateur de consommer des données inutiles et de pré-extraire des pages indésirables, c'est donc une bonne idée d'être assez prudent dans le nombre de requêtes pré-extraites. Un bon cas d'utilisation serait la prélecture des scripts de validation requis lors du paiement, ou la prélecture spéculative lorsqu'un appel à l'action critique arrive dans la fenêtre d'affichage.
Besoin de quelque chose de moins sophistiqué ? DNStradamus effectue une prélecture DNS pour les liens sortants tels qu'ils apparaissent dans la fenêtre d'affichage. Quicklink, InstantClick et Instant.page sont de petites bibliothèques qui prélèvent automatiquement les liens dans la fenêtre d'affichage pendant le temps d'inactivité afin d'accélérer le chargement des navigations de la page suivante. Quicklink permet de prérécupérer les routes React Router et Javascript ; de plus, il tient compte des données, il ne précharge donc pas sur 2G ou si
Data-Saverest activé. Il en va de même pour Instant.page si le mode est défini pour utiliser la prélecture de la fenêtre d'affichage (qui est une valeur par défaut).Si vous souhaitez examiner en détail la science de la prélecture prédictive, Divya Tagtachian a une excellente conférence sur L'art de la prélecture prédictive, couvrant toutes les options du début à la fin.
- Profitez des optimisations pour votre moteur JavaScript cible.
Étudiez quels moteurs JavaScript dominent dans votre base d'utilisateurs, puis explorez les moyens de les optimiser. Par exemple, lors de l'optimisation pour V8 qui est utilisé dans les navigateurs Blink, l'environnement d'exécution Node.js et Electron, utilisez le streaming de scripts pour les scripts monolithiques.La diffusion de scripts permet d'analyser les
defer scriptsasyncou différés sur un thread d'arrière-plan séparé une fois le téléchargement commencé, ce qui, dans certains cas, améliore les temps de chargement des pages jusqu'à 10 %. Practically, use<script defer>in the<head>, so that the browsers can discover the resource early and then parse it on the background thread.Caveat : Opera Mini doesn't support script deferment, so if you are developing for India or Africa,
deferwill be ignored, resulting in blocking rendering until the script has been evaluated (thanks Jeremy!) .You could also hook into V8's code caching as well, by splitting out libraries from code using them, or the other way around, merge libraries and their uses into a single script, group small files together and avoid inline scripts. Or perhaps even use v8-compile-cache.
When it comes to JavaScript in general, there are also some practices that are worth keeping in mind:
- Clean Code concepts for JavaScript, a large collection of patterns for writing readable, reusable, and refactorable code.
- You can Compress data from JavaScript with the CompressionStream API, eg to gzip before uploading data (Chrome 80+).
- Detached window memory leaks and Fixing memory leaks in web apps are detailed guides on how to find and fix tricky JavaScript memory leaks. Plus, you can use queryObjects(SomeConstructor) from the DevTools Console ( thanks, Mathias! ).
- Reexports are bad for loading and runtime performance, and avoiding them can help reduce the bundle size significantly.
- We can improve scroll performance with passive event listeners by setting a flag in the
optionsparameter. So browsers can scroll the page immediately, rather than after the listener has finished. (via Kayce Basques). - If you have any
scrollortouch*listeners, passpassive: trueto addEventListener. This tells the browser you're not planning to callevent.preventDefault()inside, so it can optimize the way it handles these events. (via Ivan Akulov) - We can achieve better JavaScript scheduling with isInputPending(), a new API that attempts to bridge the gap between loading and responsiveness with the concepts of interrupts for user inputs on the web, and allows for JavaScript to be able to check for input without yielding to the browser.
- You can also automatically remove an event listener after it has executed.
- Firefox's recently released Warp, a significant update to SpiderMonkey (shipped in Firefox 83), Baseline Interpreter and there are a few JIT Optimization Strategies available as well.
- Always prefer to self-host third-party assets.
Yet again, self-host your static assets by default. It's common to assume that if many sites use the same public CDN and the same version of a JavaScript library or a web font, then the visitors would land on our site with the scripts and fonts already cached in their browser, speeding up their experience considerably. However, it's very unlikely to happen.For security reasons, to avoid fingerprinting, browsers have been implementing partitioned caching that was introduced in Safari back in 2013, and in Chrome last year. So if two sites point to the exact same third-party resource URL, the code is downloaded once per domain , and the cache is "sandboxed" to that domain due to privacy implications ( thanks, David Calhoun! ). Hence, using a public CDN will not automatically lead to better performance.
Furthermore, it's worth noting that resources don't live in the browser's cache as long as we might expect, and first-party assets are more likely to stay in the cache than third-party assets. Therefore, self-hosting is usually more reliable and secure, and better for performance, too.
- Constrain the impact of third-party scripts.
With all performance optimizations in place, often we can't control third-party scripts coming from business requirements. Third-party-scripts metrics aren't influenced by end-user experience, so too often one single script ends up calling a long tail of obnoxious third-party scripts, hence ruining a dedicated performance effort. To contain and mitigate performance penalties that these scripts bring along, it's not enough to just defer their loading and execution and warm up connections via resource hints, iedns-prefetchorpreconnect.Currently 57% of all JavaScript code excution time is spent on third-party code. The median mobile site accesses 12 third-party domains , with a median of 37 different requests (or about 3 requests made to each third party).
Furthermore, these third-parties often invite fourth-party scripts to join in, ending up with a huge performance bottleneck, sometimes going as far as to the eigth-party scripts on a page. So regularly auditing your dependencies and tag managers can bring along costly surprises.
Another problem, as Yoav Weiss explained in his talk on third-party scripts, is that in many cases these scripts download resources that are dynamic. The resources change between page loads, so we don't necessarily know which hosts the resources will be downloaded from and what resources they would be.
Deferring, as shown above, might be just a start though as third-party scripts also steal bandwidth and CPU time from your app. We could be a bit more aggressive and load them only when our app has initialized.
/* Before */ const App = () => { return <div> <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> </div> } /* After */ const App = () => { const[isRendered, setRendered] = useState(false); useEffect(() => setRendered(true)); return <div> {isRendered ? <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> : null} </div> }In a fantastic post on "Reducing the Site-Speed Impact of Third-Party Tags", Andy Davies explores a strategy of minimizing the footprint of third-parties — from identifying their costs towards reducing their impact.
According to Andy, there are two ways tags impact site-speed — they compete for network bandwidth and processing time on visitors' devices, and depending on how they're implemented, they can delay HTML parsing as well. So the first step is to identify the impact that third-parties have, by testing the site with and without scripts using WebPageTest. With Simon Hearne's Request Map, we can also visualize third-parties on a page along with details on their size, type and what triggered their load.
Preferably self-host and use a single hostname, but also use a request map to exposes fourth-party calls and detect when the scripts change. You can use Harry Roberts' approach for auditing third parties and produce spreadsheets like this one (also check Harry's auditing workflow).
Afterwards, we can explore lightweight alternatives to existing scripts and slowly replace duplicates and main culprits with lighter options. Perhaps some of the scripts could be replaced with their fallback tracking pixel instead of the full tag.

Loading YouTube with facades, eg lite-youtube-embed that's significantly smaller than an actual YouTube player. (Source de l'image) ( Grand aperçu ) If it's not viable, we can at least lazy load third-party resources with facades, ie a static element which looks similar to the actual embedded third-party, but is not functional and therefore much less taxing on the page load. The trick, then, is to load the actual embed only on interaction .
For example, we can use:
- lite-vimeo-embed for the Vimeo player,
- lite-vimeo for the Vimeo player,
- lite-youtube-embed for the YouTube player,
- react-live-chat-loader for a live chat (case study, and another case-study),
- lazyframe for iframes.
One of the reasons why tag managers are usually large in size is because of the many simultaneous experiments that are running at the same time, along with many user segments, page URLs, sites etc., so according to Andy, reducing them can reduce both the download size and the time it takes to execute the script in the browser.
And then there are anti-flicker snippets. Third-parties such as Google Optimize, Visual Web Optimizer (VWO) and others are unanimous in using them. These snippets are usually injected along with running A/B tests : to avoid flickering between the different test scenarios, they hide the
bodyof the document withopacity: 0, then adds a function that gets called after a few seconds to bring theopacityback. This often results in massive delays in rendering due to massive client-side execution costs.
With A/B testing in use, customers would often see flickering like this one. Anti-Flicker snippets prevent that, but they also cost in performance. Via Andy Davies. ( Grand aperçu ) Therefore keep track how often the anti-flicker timeout is triggered and reduce the timeout. Default blocks display of your page by up to 4s which will ruin conversion rates. According to Tim Kadlec, "Friends don't let friends do client side A/B testing". Server-side A/B testing on CDNs (eg Edge Computing, or Edge Slice Rerendering) is always a more performant option.
If you have to deal with almighty Google Tag Manager , Barry Pollard provides some guidelines to contain the impact of Google Tag Manager. Also, Christian Schaefer explores strategies for loading ads.
Attention : certains widgets tiers se cachent des outils d'audit, ils peuvent donc être plus difficiles à repérer et à mesurer. Pour tester les tiers, examinez les résumés ascendants dans la page de profil de performance dans DevTools, testez ce qui se passe si une demande est bloquée ou si elle a expiré - pour ce dernier, vous pouvez utiliser le serveur Blackhole de WebPageTest
blackhole.webpagetest.orgque vous peut pointer vers des domaines spécifiques dans votre fichierhosts.Quelles options avons-nous alors? Envisagez d'utiliser des techniciens de service en accélérant le téléchargement de la ressource avec un délai d'attente et si la ressource n'a pas répondu dans un certain délai, renvoyez une réponse vide pour indiquer au navigateur de poursuivre l'analyse de la page. Vous pouvez également consigner ou bloquer les demandes de tiers qui n'aboutissent pas ou qui ne remplissent pas certains critères. Si vous le pouvez, chargez le script tiers depuis votre propre serveur plutôt que depuis le serveur du fournisseur et chargez-le paresseux.
Une autre option consiste à établir une politique de sécurité du contenu (CSP) pour limiter l'impact des scripts tiers, par exemple en interdisant le téléchargement d'audio ou de vidéo. La meilleure option consiste à intégrer des scripts via
<iframe>afin que les scripts s'exécutent dans le contexte de l'iframe et n'aient donc pas accès au DOM de la page et ne puissent pas exécuter de code arbitraire sur votre domaine. Les iframes peuvent être davantage contraints à l'aide de l'attributsandbox, de sorte que vous pouvez désactiver toutes les fonctionnalités que l'iframe peut faire, par exemple empêcher l'exécution des scripts, empêcher les alertes, la soumission de formulaires, les plugins, l'accès à la navigation supérieure, etc.Vous pouvez également garder les tiers sous contrôle via le linting des performances du navigateur avec les politiques de fonctionnalités, une fonctionnalité relativement nouvelle qui vous permet
activer ou désactiver certaines fonctionnalités du navigateur sur votre site. (En passant, il pourrait également être utilisé pour éviter les images surdimensionnées et non optimisées, les médias non dimensionnés, les scripts de synchronisation et autres). Actuellement pris en charge dans les navigateurs basés sur Blink. /* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'/* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'Comme de nombreux scripts tiers s'exécutent dans des iframes, vous devez probablement être minutieux pour limiter leurs allocations. Les iframes en bac à sable sont toujours une bonne idée, et chacune des limitations peut être levée via un certain nombre de valeurs d'
allowsur l'attributsandbox. Le sandboxing est pris en charge presque partout, alors limitez les scripts tiers au strict minimum de ce qu'ils devraient être autorisés à faire.
ThirdPartyWeb.Today regroupe tous les scripts tiers par catégorie (analytique, social, publicité, hébergement, gestionnaire de balises, etc.) et visualise le temps d'exécution (en moyenne) des scripts de l'entité. ( Grand aperçu ) Envisagez d'utiliser un observateur d'intersection ; cela permettrait aux annonces d'être encadrées tout en continuant à envoyer des événements ou à obtenir les informations dont elles ont besoin du DOM (par exemple, la visibilité des annonces). Méfiez-vous des nouvelles politiques telles que la politique des fonctionnalités, les limites de taille des ressources et la priorité CPU/bande passante pour limiter les fonctionnalités Web nuisibles et les scripts qui ralentiraient le navigateur, par exemple les scripts synchrones, les requêtes XHR synchrones, document.write et les implémentations obsolètes.
Enfin, lors du choix d'un service tiers, pensez à vérifier ThirdPartyWeb.Today de Patrick Hulce, un service qui regroupe tous les scripts tiers par catégorie (analytique, social, publicité, hébergement, gestionnaire de balises, etc.) et visualise la durée des scripts de l'entité prendre pour exécuter (en moyenne). De toute évidence, les plus grandes entités ont le pire impact sur les performances des pages sur lesquelles elles se trouvent. En parcourant simplement la page, vous aurez une idée de l'empreinte de performance à laquelle vous devriez vous attendre.
Ah, et n'oubliez pas les suspects habituels : au lieu de widgets tiers pour le partage, nous pouvons utiliser des boutons de partage social statiques (comme par SSBG) et des liens statiques vers des cartes interactives au lieu de cartes interactives.
- Définissez correctement les en-têtes de cache HTTP.
La mise en cache semble être une chose si évidente à faire, mais il peut être assez difficile de bien faire les choses. Nous devons revérifier queexpires,max-age,cache-controlet les autres en-têtes de cache HTTP ont été correctement définis. Sans les en-têtes de cache HTTP appropriés, les navigateurs les définiront automatiquement à 10 % du temps écoulé depuislast-modified, ce qui entraînera une sous- et une sur-cache potentielles.En général, les ressources doivent pouvoir être mises en cache pendant une très courte période (si elles sont susceptibles de changer) ou indéfiniment (si elles sont statiques) - vous pouvez simplement changer leur version dans l'URL si nécessaire. Vous pouvez appeler cela une stratégie Cache-Forever, dans laquelle nous pourrions relayer les en-têtes
Cache-ControletExpiresau navigateur pour autoriser uniquement les actifs à expirer dans un an. Par conséquent, le navigateur ne ferait même pas de demande pour l'actif s'il l'avait dans le cache.L'exception concerne les réponses API (par exemple
/api/user). Pour éviter la mise en cache, nous pouvons utiliserprivate, no store, et nonmax-age=0, no-store:Cache-Control: private, no-storeUtilisez
Cache-control: immutablepour éviter la revalidation de longues durées de vie explicites du cache lorsque les utilisateurs cliquent sur le bouton de rechargement. Pour le cas de rechargement,immutableenregistre les requêtes HTTP et améliore le temps de chargement du HTML dynamique car ils ne concurrencent plus la multitude de réponses 304.Un exemple typique où nous voulons utiliser
immutablesont les actifs CSS/JavaScript avec un hachage dans leur nom. Pour eux, nous voulons probablement mettre en cache le plus longtemps possible et nous assurer qu'ils ne soient jamais revalidés :Cache-Control: max-age: 31556952, immutableSelon les recherches de Colin Bendell,
immutableréduit les redirections 304 d'environ 50 %, car même avecmax-ageutilisé, les clients revalident et bloquent toujours lors de l'actualisation. Il est pris en charge dans Firefox, Edge et Safari et Chrome débat toujours de la question.Selon Web Almanac, "son utilisation est passée à 3,5 %, et il est largement utilisé dans les réponses de tiers Facebook et Google".

Cache-Control : Immutable réduit les 304 d'environ 50 %, selon les recherches de Colin Bendell chez Cloudinary. ( Grand aperçu ) Vous souvenez-vous du bon vieux stale-while-revalidate ? Lorsque nous spécifions le temps de mise en cache avec l'en-tête de réponse
Cache-Control(par exempleCache-Control: max-age=604800), après l'expiration demax-age, le navigateur récupère le contenu demandé, ce qui ralentit le chargement de la page. Ce ralentissement peut être évité avecstale-while-revalidate; il définit essentiellement une fenêtre de temps supplémentaire pendant laquelle un cache peut utiliser un actif obsolète tant qu'il le revalide de manière asynchrone en arrière-plan. Ainsi, il "cache" la latence (à la fois dans le réseau et sur le serveur) aux clients.En juin-juillet 2019, Chrome et Firefox ont lancé la prise en charge de
stale-while-revalidatedans l'en-tête HTTP Cache-Control. Par conséquent, cela devrait améliorer les latences de chargement de page ultérieures, car les actifs obsolètes ne se trouvent plus dans le chemin critique. Résultat : zéro RTT pour les vues répétées.Méfiez-vous de l'en-tête varie, en particulier en ce qui concerne les CDN, et faites attention aux variantes de représentation HTTP qui permettent d'éviter un aller-retour supplémentaire pour la validation chaque fois qu'une nouvelle requête diffère légèrement (mais pas de manière significative) des requêtes précédentes ( merci, Guy et Mark ! ).
Vérifiez également que vous n'envoyez pas d'en-têtes inutiles (par exemple
x-powered-by,pragma,x-ua-compatible,expires,X-XSS-Protectionet autres) et que vous incluez des en-têtes de sécurité et de performance utiles (tels que commeContent-Security-Policy,X-Content-Type-Optionset autres). Enfin, gardez à l'esprit le coût des performances des requêtes CORS dans les applications monopage.Remarque : Nous supposons souvent que les actifs mis en cache sont récupérés instantanément, mais la recherche montre que la récupération d'un objet du cache peut prendre des centaines de millisecondes. En fait, selon Simon Hearne, "parfois, le réseau peut être plus rapide que le cache, et la récupération des actifs du cache peut être coûteuse avec un grand nombre d'actifs mis en cache (pas la taille du fichier) et les appareils de l'utilisateur. Par exemple : récupération moyenne du cache de Chrome OS double de ~50 ms avec 5 ressources en cache jusqu'à ~100 ms avec 25 ressources".
En outre, nous supposons souvent que la taille du bundle n'est pas un gros problème et que les utilisateurs le téléchargeront une fois, puis utiliseront la version en cache. Dans le même temps, avec CI/CD, nous poussons le code en production plusieurs fois par jour, le cache est invalidé à chaque fois, il faut donc être stratégique en matière de mise en cache.
En ce qui concerne la mise en cache, il existe de nombreuses ressources qui valent la peine d'être lues :
- Cache-Control for Civilians, une plongée en profondeur dans tout ce qui concerne la mise en cache avec Harry Roberts.
- L'introduction d'Heroku sur les en-têtes de mise en cache HTTP,
- Meilleures pratiques de mise en cache par Jake Archibald,
- Introduction à la mise en cache HTTP par Ilya Grigorik,
- Garder les choses fraîches avec stale-while-revalidate de Jeff Posnick.
- CS Visualized: CORS par Lydia Hallie est un excellent explicateur sur CORS, comment cela fonctionne et comment lui donner un sens.
- En parlant de CORS, voici un petit rappel sur la politique d'origine identique par Eric Portis.
Optimisations de livraison
- Utilisons-nous le
deferpour charger le JavaScript critique de manière asynchrone ?
Lorsque l'utilisateur demande une page, le navigateur récupère le HTML et construit le DOM, puis récupère le CSS et construit le CSSOM, puis génère un arbre de rendu en faisant correspondre le DOM et le CSSOM. Si un code JavaScript doit être résolu, le navigateur ne commencera pas à rendre la page tant qu'il n'est pas résolu, ce qui retarde le rendu. En tant que développeurs, nous devons dire explicitement au navigateur de ne pas attendre et de commencer à rendre la page. La façon de procéder pour les scripts est d'utiliser les attributsdeferetasyncen HTML.En pratique, il s'avère qu'il est préférable d'utiliser
deferau lieu deasync. Ah, c'est quoi la différence déjà ? Selon Steve Souders, une fois que les scriptsasyncarrivent, ils sont exécutés immédiatement - dès que le script est prêt. Si cela se produit très rapidement, par exemple lorsque le script est déjà dans le cache, il peut en fait bloquer l'analyseur HTML. Avecdefer, le navigateur n'exécute pas les scripts tant que le HTML n'est pas analysé. Donc, à moins que vous ayez besoin de JavaScript pour s'exécuter avant de commencer le rendu, il est préférable d'utiliserdefer. En outre, plusieurs fichiers asynchrones s'exécuteront dans un ordre non déterministe.Il convient de noter qu'il existe quelques idées fausses sur
asyncetdefer. Plus important encore,asyncne signifie pas que le code s'exécutera dès que le script sera prêt ; cela signifie qu'il s'exécutera chaque fois que les scripts seront prêts et que tout le travail de synchronisation précédent sera terminé. Selon les mots de Harry Roberts, "Si vous placez un scriptasyncaprès les scripts de synchronisation, votre scriptasyncn'est aussi rapide que votre script de synchronisation le plus lent."De plus, il n'est pas recommandé d'utiliser à la fois
asyncetdefer. Les navigateurs modernes prennent en charge les deux, mais chaque fois que les deux attributs sont utilisés,asyncl'emportera toujours.Si vous souhaitez plonger dans plus de détails, Milica Mihajlija a écrit un guide très détaillé sur Construire le DOM plus rapidement, en entrant dans les détails de l'analyse spéculative, asynchrone et différée.
- Chargement paresseux de composants coûteux avec IntersectionObserver et des conseils de priorité.
En général, il est recommandé de charger paresseusement tous les composants coûteux, tels que le JavaScript lourd, les vidéos, les iframes, les widgets et potentiellement les images. Le chargement paresseux natif est déjà disponible pour les images et les iframes avec l'attribut deloading(uniquement Chromium). Sous le capot, cet attribut diffère le chargement de la ressource jusqu'à ce qu'elle atteigne une distance calculée de la fenêtre d'affichage.<!-- Lazy loading for images, iframes, scripts. Probably for images outside of the viewport. --> <img loading="lazy" ... /> <iframe loading="lazy" ... /> <!-- Prompt an early download of an asset. For critical images, eg hero images. --> <img loading="eager" ... /> <iframe loading="eager" ... />Ce seuil dépend de quelques éléments, du type de ressource d'image récupérée au type de connexion effectif. Mais les expériences menées à l'aide de Chrome sur Android suggèrent que sur la 4G, 97,5 % des images en dessous de la ligne de flottaison qui sont chargées paresseusement ont été entièrement chargées dans les 10 ms suivant leur apparition, elles devraient donc être sûres.
Nous pouvons également utiliser l'attribut
importance(highoulow) sur un élément<script>,<img>ou<link>(Blink uniquement). En fait, c'est un excellent moyen de déprioriser les images dans les carrousels, ainsi que de re-prioriser les scripts. Cependant, nous pourrions parfois avoir besoin d'un contrôle un peu plus granulaire.<!-- When the browser assigns "High" priority to an image, but we don't actually want that. --> <img src="less-important-image.svg" importance="low" ... /> <!-- We want to initiate an early fetch for a resource, but also deprioritize it. --> <link rel="preload" importance="low" href="/script.js" as="script" />La façon la plus performante d'effectuer un chargement paresseux légèrement plus sophistiqué consiste à utiliser l'API Intersection Observer qui permet d' observer de manière asynchrone les changements dans l'intersection d'un élément cible avec un élément ancêtre ou avec la fenêtre d'affichage d'un document de niveau supérieur. Fondamentalement, vous devez créer un nouvel objet
IntersectionObserver, qui reçoit une fonction de rappel et un ensemble d'options. Ensuite, nous ajoutons une cible à observer.La fonction de rappel s'exécute lorsque la cible devient visible ou invisible, donc lorsqu'elle intercepte la fenêtre d'affichage, vous pouvez commencer à prendre certaines mesures avant que l'élément ne devienne visible. En fait, nous avons un contrôle granulaire sur le moment où le rappel de l'observateur doit être invoqué, avec
rootMargin(marge autour de la racine) et lethreshold(un nombre unique ou un tableau de nombres qui indiquent à quel pourcentage de la visibilité de la cible nous visons).Alejandro Garcia Anglada a publié un tutoriel pratique sur la façon de l'implémenter, Rahul Nanwani a écrit un article détaillé sur le chargement paresseux des images de premier plan et d'arrière-plan, et Google Fundamentals fournit également un tutoriel détaillé sur le chargement paresseux d'images et de vidéos avec Intersection Observer.
Vous souvenez-vous de la narration artistique de longues lectures avec des objets en mouvement et collants ? Vous pouvez également implémenter un scrollytelling performant avec Intersection Observer.
Vérifiez à nouveau ce que vous pourriez charger paresseux. Même les chaînes de traduction et les emoji à chargement paresseux pourraient aider. Ce faisant, Mobile Twitter a réussi à obtenir une exécution JavaScript 80 % plus rapide à partir du nouveau pipeline d'internationalisation.
Un petit avertissement cependant : il convient de noter que le chargement paresseux devrait être une exception plutôt que la règle. Il n'est probablement pas raisonnable de charger paresseux tout ce que vous voulez réellement que les gens voient rapidement, par exemple des images de page de produit, des images de héros ou un script requis pour que la navigation principale devienne interactive.

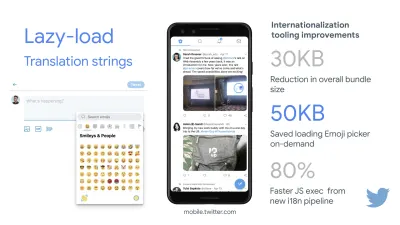
- Charger les images progressivement.
Vous pouvez même faire passer le chargement paresseux au niveau supérieur en ajoutant un chargement progressif des images à vos pages. Comme pour Facebook, Pinterest, Medium et Wolt, vous pouvez d'abord charger des images de faible qualité ou même floues, puis, au fur et à mesure que la page se charge, les remplacer par les versions de qualité complète en utilisant la technique BlurHash ou LQIP (Low Quality Image Placeholders) technique.Les opinions diffèrent si ces techniques améliorent ou non l'expérience utilisateur, mais cela améliore définitivement le temps de First Contentful Paint. Nous pouvons même l'automatiser en utilisant SQIP qui crée une version de faible qualité d'une image en tant qu'espace réservé SVG, ou des espaces réservés d'image dégradés avec des dégradés linéaires CSS.
Ces espaces réservés pourraient être intégrés dans HTML car ils se compriment naturellement bien avec les méthodes de compression de texte. Dans son article, Dean Hume a décrit comment cette technique peut être mise en œuvre à l'aide d'Intersection Observer.
Se retirer? Si le navigateur ne prend pas en charge l'observateur d'intersection, nous pouvons toujours charger paresseux un polyfill ou charger les images immédiatement. Et il y a même une bibliothèque pour ça.
Vous voulez devenir plus chic ? Vous pouvez tracer vos images et utiliser des formes et des bords primitifs pour créer un espace réservé SVG léger, le charger d'abord, puis passer de l'image vectorielle de l'espace réservé à l'image bitmap (chargée).
- Différez-vous le rendu avec
content-visibility?
Pour une mise en page complexe avec de nombreux blocs de contenu, images et vidéos, le décodage des données et le rendu des pixels peuvent être une opération assez coûteuse, en particulier sur les appareils bas de gamme. Aveccontent-visibility: auto, nous pouvons inviter le navigateur à ignorer la disposition des enfants lorsque le conteneur est en dehors de la fenêtre.Par exemple, vous pouvez ignorer le rendu du pied de page et des sections tardives lors du chargement initial :
footer { content-visibility: auto; contain-intrinsic-size: 1000px; /* 1000px is an estimated height for sections that are not rendered yet. */ }Notez que la visibilité du contenu : auto ; se comporte comme un débordement : caché ; , mais vous pouvez résoudre ce problème en appliquant
padding-leftetpadding-rightau lieu de la valeur par défautmargin-left: auto;,margin-right: auto;et une largeur déclarée. Le rembourrage permet essentiellement aux éléments de déborder de la boîte de contenu et d'entrer dans la boîte de remplissage sans quitter le modèle de boîte dans son ensemble et être coupé.De plus, gardez à l'esprit que vous pouvez introduire du CLS lorsque le nouveau contenu est finalement rendu, c'est donc une bonne idée d'utiliser
contain-intrinsic-sizeavec un espace réservé correctement dimensionné ( merci, Una ! ).Thijs Terluin a beaucoup plus de détails sur les deux propriétés et sur la façon dont
contain-intrinsic-sizeest calculée par le navigateur, Malte Ubl montre comment vous pouvez le calculer et une brève vidéo explicative de Jake et Surma explique comment tout cela fonctionne.Et si vous avez besoin d'être un peu plus précis, avec CSS Containment, vous pouvez ignorer manuellement le travail de mise en page, de style et de peinture pour les descendants d'un nœud DOM si vous n'avez besoin que de la taille, de l'alignement ou des styles calculés sur d'autres éléments - ou si l'élément est actuellement hors toile.


content-visibility: auto aux zones de contenu fragmentées donne une amélioration des performances de rendu de 7 fois lors du chargement initial. ( Grand aperçu )- Reportez-vous le décodage avec
decoding="async"?
Parfois, le contenu apparaît hors écran, mais nous voulons nous assurer qu'il est disponible lorsque les clients en ont besoin - idéalement, ne bloquez rien dans le chemin critique, mais décodez et restituez de manière asynchrone. Nous pouvons utiliserdecoding="async"pour autoriser le navigateur à décoder l'image du thread principal, en évitant l'impact de l'utilisateur sur le temps CPU utilisé pour décoder l'image (via Malte Ubl) :<img decoding="async" … />Alternativement, pour les images hors écran, nous pouvons d'abord afficher un espace réservé, et lorsque l'image est dans la fenêtre, en utilisant IntersectionObserver, déclencher un appel réseau pour que l'image soit téléchargée en arrière-plan. De plus, nous pouvons différer le rendu jusqu'au décodage avec img.decode() ou télécharger l'image si l'API Image Decode n'est pas disponible.
Lors du rendu de l'image, nous pouvons utiliser des animations de fondu enchaîné, par exemple. Katie Hempenius et Addy Osmani partagent plus d'informations dans leur conférence Speed at Scale: Web Performance Tips and Tricks from the Trenches.
- Générez-vous et servez-vous des CSS critiques ?
Pour s'assurer que les navigateurs commencent à afficher votre page le plus rapidement possible, il est devenu courant de collecter tous les CSS nécessaires pour commencer à afficher la première partie visible de la page (appelée « CSS critique » ou « CSS au-dessus de la ligne de flottaison ") et incluez-le en ligne dans le<head>de la page, réduisant ainsi les allers-retours. En raison de la taille limitée des packages échangés pendant la phase de démarrage lent, votre budget pour le CSS critique est d'environ 14 Ko.Si vous allez au-delà, le navigateur aura besoin d'allers-retours supplémentaires pour récupérer plus de styles. CriticalCSS et Critical vous permettent de générer des CSS critiques pour chaque modèle que vous utilisez. D'après notre expérience, aucun système automatique n'a jamais été meilleur que la collecte manuelle de CSS critiques pour chaque modèle, et c'est en effet l'approche à laquelle nous sommes revenus récemment.
Vous pouvez ensuite intégrer le CSS critique et charger paresseux le reste avec le plugin Webpack de critters. Si possible, envisagez d'utiliser l'approche d'intégration conditionnelle utilisée par le groupe Filament ou convertissez le code en ligne en actifs statiques à la volée.
Si vous chargez actuellement votre CSS complet de manière asynchrone avec des bibliothèques telles que loadCSS, ce n'est pas vraiment nécessaire. Avec
media="print", vous pouvez inciter le navigateur à récupérer le CSS de manière asynchrone mais à l'appliquer à l'environnement de l'écran une fois qu'il se charge. ( merci Scott! )<!-- Via Scott Jehl. https://www.filamentgroup.com/lab/load-css-simpler/ --> <!-- Load CSS asynchronously, with low priority --> <link rel="stylesheet" href="full.css" media="print" onload="this.media='all'" />Lors de la collecte de tous les CSS critiques pour chaque modèle, il est courant d'explorer uniquement la zone "au-dessus de la ligne de flottaison". Cependant, pour les mises en page complexes, il peut être judicieux d'inclure également les bases de la mise en page pour éviter des coûts de recalcul et de repeinture massifs , ce qui nuit à votre score Core Web Vitals.
Que se passe-t-il si un utilisateur obtient une URL qui renvoie directement au milieu de la page mais que le CSS n'a pas encore été téléchargé ? Dans ce cas, il est devenu courant de masquer le contenu non critique, par exemple avec une
opacity: 0;en CSS intégré etopacity: 1dans le fichier CSS complet, et affichez-le lorsque le CSS est disponible. Il présente cependant un inconvénient majeur , car les utilisateurs ayant des connexions lentes pourraient ne jamais être en mesure de lire le contenu de la page. C'est pourquoi il est préférable de toujours garder le contenu visible, même s'il n'est peut-être pas stylisé correctement.Mettre le CSS critique (et d'autres actifs importants) dans un fichier séparé sur le domaine racine présente des avantages, parfois même plus que l'inlining, en raison de la mise en cache. Chrome ouvre de manière spéculative une deuxième connexion HTTP au domaine racine lors de la demande de la page, ce qui supprime le besoin d'une connexion TCP pour récupérer ce CSS. Cela signifie que vous pouvez créer un ensemble de fichiers -CSS critiques (par exemple, Critical -Homepage.css , Critical-Product-Page.Css, etc.) et les servir à partir de votre racine, sans avoir à les intégrer. ( merci Philippe! )
Un mot d'avertissement : avec HTTP/2, les CSS critiques pourraient être stockées dans un fichier CSS séparé et livrées via une poussée du serveur sans gonfler le HTML. Le hic, c'est que la poussée de serveur était gênante avec de nombreux pièges et conditions de concurrence entre les navigateurs. Il n'a jamais été pris en charge de manière cohérente et présentait des problèmes de mise en cache (voir la diapositive 114 et suivantes de la présentation de Hooman Beheshti).
L'effet pourrait, en fait, être négatif et gonfler les mémoires tampons du réseau, empêchant la livraison des images authentiques du document. Il n'est donc pas très surprenant que pour le moment, Chrome envisage de supprimer la prise en charge de Server Push.
- Essayez de regrouper vos règles CSS.
Nous nous sommes habitués au CSS critique, mais il y a quelques optimisations qui pourraient aller au-delà. Harry Roberts a mené une recherche remarquable avec des résultats assez surprenants. Par exemple, il peut être judicieux de diviser le fichier CSS principal en ses requêtes multimédia individuelles. De cette façon, le navigateur récupérera les CSS critiques avec une priorité élevée et tout le reste avec une faible priorité - complètement hors du chemin critique.Évitez également de placer
<link rel="stylesheet" />avant les extraits deasync. Si les scripts ne dépendent pas des feuilles de style, pensez à placer les scripts de blocage au-dessus des styles de blocage. Si c'est le cas, divisez ce JavaScript en deux et chargez-le de chaque côté de votre CSS.Scott Jehl a résolu un autre problème intéressant en mettant en cache un fichier CSS intégré avec un service worker, un problème courant si vous utilisez des CSS critiques. Fondamentalement, nous ajoutons un attribut ID sur l'élément de
styleafin qu'il soit facile de le trouver en utilisant JavaScript, puis un petit morceau de JavaScript trouve que CSS et utilise l'API Cache pour le stocker dans un cache de navigateur local (avec un type de contenu detext/css) à utiliser sur les pages suivantes. Pour éviter l'intégration sur les pages suivantes et référencer à la place les actifs mis en cache en externe, nous installons ensuite un cookie lors de la première visite sur un site. Voila !Il convient de noter que le style dynamique peut également être coûteux, mais généralement uniquement dans les cas où vous comptez sur des centaines de composants composés rendus simultanément. Donc, si vous utilisez CSS-in-JS, assurez-vous que votre bibliothèque CSS-in-JS optimise l'exécution lorsque votre CSS n'a aucune dépendance sur le thème ou les accessoires, et ne sur-composez pas de composants stylés . Aggelos Arvanitakis partage plus d'informations sur les coûts de performance de CSS-in-JS.
- Diffusez-vous les réponses ?
Souvent oubliés et négligés, les flux fournissent une interface pour lire ou écrire des blocs de données asynchrones, dont seul un sous-ensemble peut être disponible en mémoire à un moment donné. Fondamentalement, ils permettent à la page qui a fait la demande d'origine de commencer à travailler avec la réponse dès que le premier bloc de données est disponible, et utilisent des analyseurs optimisés pour le streaming pour afficher progressivement le contenu.Nous pourrions créer un flux à partir de plusieurs sources. Par exemple, au lieu de servir un shell d'interface utilisateur vide et de laisser JavaScript le remplir, vous pouvez laisser le service worker construire un flux où le shell provient d'un cache, mais le corps provient du réseau. Comme l'a noté Jeff Posnick, si votre application Web est alimentée par un CMS qui rend le HTML par le serveur en assemblant des modèles partiels, ce modèle se traduit directement par l'utilisation de réponses en continu, avec la logique de modélisation répliquée dans le service worker au lieu de votre serveur. L'article The Year of Web Streams de Jake Archibald montre comment vous pouvez le construire. L'amélioration des performances est assez notable.
L'un des avantages importants de la diffusion en continu de l'intégralité de la réponse HTML est que le HTML rendu lors de la demande de navigation initiale peut tirer pleinement parti de l'analyseur HTML en continu du navigateur. Les morceaux de code HTML insérés dans un document après le chargement de la page (comme c'est souvent le cas avec le contenu rempli via JavaScript) ne peuvent pas tirer parti de cette optimisation.
Prise en charge du navigateur ? Toujours en train d'y arriver avec une prise en charge partielle de Chrome, Firefox, Safari et Edge prenant en charge l'API et les Service Workers pris en charge dans tous les navigateurs modernes. Et si vous vous sentez à nouveau aventureux, vous pouvez vérifier une implémentation expérimentale des requêtes de streaming, qui vous permet de commencer à envoyer la requête tout en générant le corps. Disponible dans Chrome 85.
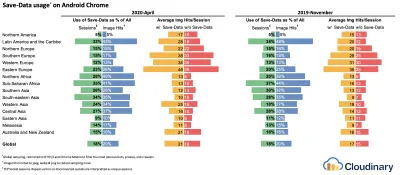
- Envisagez de rendre vos composants compatibles avec la connexion.
Les données peuvent être coûteuses et avec une charge utile croissante, nous devons respecter les utilisateurs qui choisissent d'opter pour des économies de données lorsqu'ils accèdent à nos sites ou applications. L'en-tête de demande d'indice client Save-Data nous permet de personnaliser l'application et la charge utile pour les utilisateurs soumis à des contraintes de coût et de performances.En fait, vous pouvez réécrire les demandes d'images à haute résolution en images à faible résolution, supprimer les polices Web, les effets de parallaxe fantaisistes, prévisualiser les vignettes et le défilement infini, désactiver la lecture automatique des vidéos, les poussées de serveur, réduire le nombre d'éléments affichés et réduire la qualité de l'image, ou même changer la façon dont vous fournissez le balisage. Tim Vereecke a publié un article très détaillé sur les stratégies de data-s(h)aver proposant de nombreuses options de sauvegarde de données.
Qui utilise
save-data, vous vous demandez peut-être ? 18 % des utilisateurs mondiaux d'Android Chrome ont activé le mode Lite (avecSave-Dataactivé), et le nombre est susceptible d'être plus élevé. Selon les recherches de Simon Hearne, le taux d'adhésion est le plus élevé sur les appareils moins chers, mais il existe de nombreuses valeurs aberrantes. Par exemple : les utilisateurs au Canada ont un taux d'adhésion de plus de 34 % (par rapport à environ 7 % aux États-Unis) et les utilisateurs du dernier produit phare de Samsung ont un taux d'adhésion de près de 18 % dans le monde.Avec le mode
Save-Dataactivé, Chrome Mobile fournira une expérience optimisée, c'est-à-dire une expérience Web proxy avec des scripts différés ,font-display: swapet chargement différé forcé. Il est simplement plus judicieux de créer l'expérience par vous-même plutôt que de compter sur le navigateur pour effectuer ces optimisations.L'en-tête est actuellement pris en charge uniquement dans Chromium, sur la version Android de Chrome ou via l'extension Data Saver sur un appareil de bureau. Enfin, vous pouvez également utiliser l'API Network Information pour fournir des modules JavaScript coûteux, des images et des vidéos haute résolution en fonction du type de réseau. L'API d'informations réseau et plus particulièrement
navigator.connection.effectiveTypeutilisent les valeursRTT,downlink,effectiveType(et quelques autres) pour fournir une représentation de la connexion et des données que les utilisateurs peuvent gérer.Dans ce contexte, Max Bock parle de composants sensibles à la connexion et Addy Osmani parle de service de module adaptatif. Par exemple, avec React, nous pourrions écrire un composant qui s'affiche différemment pour différents types de connexion. Comme Max l'a suggéré, un composant
<Media />dans un article de presse peut afficher :-
Offline: un espace réservé avec un textealt, - Mode
2G/save-data: une image basse résolution, -
3Gsur écran non Retina : une image en moyenne résolution, -
3Gsur écrans Retina : image Retina haute résolution, -
4G: une vidéo HD.
Dean Hume fournit une implémentation pratique d'une logique similaire à l'aide d'un service worker. Pour une vidéo, nous pourrions afficher une affiche vidéo par défaut, puis afficher l'icône "Play" ainsi que le shell du lecteur vidéo, les métadonnées de la vidéo, etc. sur de meilleures connexions. En guise de solution de rechange pour les navigateurs non compatibles, nous pourrions écouter l'événement
canplaythroughet utiliserPromise.race()pour expirer le chargement de la source si l'événementcanplaythroughne se déclenche pas dans les 2 secondes.Si vous souhaitez approfondir un peu, voici quelques ressources pour commencer :
- Addy Osmani montre comment implémenter le service adaptatif dans React.
- React Adaptive Loading Hooks & Utilities fournit des extraits de code pour React,
- Netanel Basel explore les composants compatibles avec les connexions dans Angular,
- Theodore Vorilas explique comment fonctionne le service de composants adaptatifs à l'aide de l'API d'informations réseau dans Vue.
- Umar Hansa montre comment télécharger/exécuter sélectivement du JavaScript coûteux.
-
- Envisagez de rendre vos composants compatibles avec la mémoire de l'appareil.
La connexion réseau ne nous donne cependant qu'une seule perspective dans le contexte de l'utilisateur. Pour aller plus loin, vous pouvez également ajuster dynamiquement les ressources en fonction de la mémoire disponible de l'appareil, avec l'API Device Memory.navigator.deviceMemoryreturns how much RAM the device has in gigabytes, rounded down to the nearest power of two. The API also features a Client Hints Header,Device-Memory, that reports the same value.Bonus : Umar Hansa shows how to defer expensive scripts with dynamic imports to change the experience based on device memory, network connectivity and hardware concurrency.
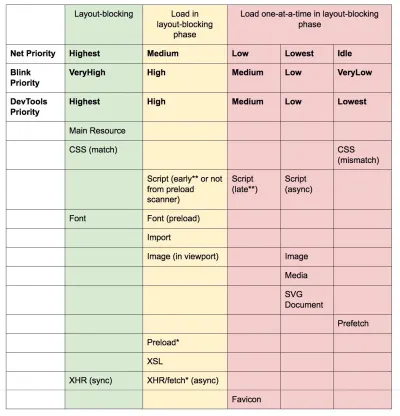
- Warm up the connection to speed up delivery.
Use resource hints to save time ondns-prefetch(which performs a DNS lookup in the background),preconnect(which asks the browser to start the connection handshake (DNS, TCP, TLS) in the background),prefetch(which asks the browser to request a resource) andpreload(which prefetches resources without executing them, among other things). Well supported in modern browsers, with support coming to Firefox soon.Remember
prerender? The resource hint used to prompt browser to build out the entire page in the background for next navigation. The implementations issues were quite problematic, ranging from a huge memory footprint and bandwidth usage to multiple registered analytics hits and ad impressions.Unsurprinsingly, it was deprecated, but the Chrome team has brought it back as NoState Prefetch mechanism. In fact, Chrome treats the
prerenderhint as a NoState Prefetch instead, so we can still use it today. As Katie Hempenius explains in that article, "like prerendering, NoState Prefetch fetches resources in advance ; but unlike prerendering, it does not execute JavaScript or render any part of the page in advance."NoState Prefetch only uses ~45MiB of memory and subresources that are fetched will be fetched with an
IDLENet Priority. Since Chrome 69, NoState Prefetch adds the header Purpose: Prefetch to all requests in order to make them distinguishable from normal browsing.Also, watch out for prerendering alternatives and portals, a new effort toward privacy-conscious prerendering, which will provide the inset
previewof the content for seamless navigations.Using resource hints is probably the easiest way to boost performance , and it works well indeed. When to use what? As Addy Osmani has explained, it's reasonable to preload resources that we know are very likely to be used on the current page and for future navigations across multiple navigation boundaries, eg Webpack bundles needed for pages the user hasn't visited yet.
Addy's article on "Loading Priorities in Chrome" shows how exactly Chrome interprets resource hints, so once you've decided which assets are critical for rendering, you can assign high priority to them. To see how your requests are prioritized, you can enable a "priority" column in the Chrome DevTools network request table (as well as Safari).
Most of the time these days, we'll be using at least
preconnectanddns-prefetch, and we'll be cautious with usingprefetch,preloadandprerender. Note that even withpreconnectanddns-prefetch, the browser has a limit on the number of hosts it will look up/connect to in parallel, so it's a safe bet to order them based on priority ( thanks Philip Tellis! ).Since fonts usually are important assets on a page, sometimes it's a good idea to request the browser to download critical fonts with
preload. However, double check if it actually helps performance as there is a puzzle of priorities when preloading fonts: aspreloadis seen as high importance, it can leapfrog even more critical resources like critical CSS. ( thanks, Barry! )<!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /><!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" />Since
<link rel="preload">accepts amediaattribute, you could choose to selectively download resources based on@mediaquery rules, as shown above.Furthermore, we can use
imagesrcsetandimagesizesattributes to preload late-discovered hero images faster, or any images that are loaded via JavaScript, eg movie posters:<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image><!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image>We can also preload the JSON as fetch , so it's discovered before JavaScript gets to request it:
<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="fetch" href="foo.com/api/movies.json" crossorigin>We could also load JavaScript dynamically, effectively for lazy execution of the script.
/* Adding a preload hint to the head */ var preload = document.createElement("link"); link.href = "myscript.js"; link.rel = "preload"; link.as = "script"; document.head.appendChild(link); /* Injecting a script when we want it to execute */ var script = document.createElement("script"); script.src = "myscript.js"; document.body.appendChild(script);A few gotchas to keep in mind:
preloadis good for moving the start download time of an asset closer to the initial request, but preloaded assets land in the memory cache which is tied to the page making the request.preloadplays well with the HTTP cache: a network request is never sent if the item is already there in the HTTP cache.Hence, it's useful for late-discovered resources, hero images loaded via
background-image, inlining critical CSS (or JavaScript) and pre-loading the rest of the CSS (or JavaScript).
Preload important images early; no need to wait on JavaScript to discover them. (Image credit: “Preload Late-Discovered Hero Images Faster” by Addy Osmani) (Large preview) A
preloadtag can initiate a preload only after the browser has received the HTML from the server and the lookahead parser has found thepreloadtag. Preloading via the HTTP header could be a bit faster since we don't to wait for the browser to parse the HTML to start the request (it's debated though).Early Hints will help even further, enabling preload to kick in even before the response headers for the HTML are sent (on the roadmap in Chromium, Firefox). Plus, Priority Hints will help us indicate loading priorities for scripts.
Beware : if you're using
preload,asmust be defined or nothing loads, plus preloaded fonts without thecrossoriginattribute will double fetch. If you're usingprefetch, beware of theAgeheader issues in Firefox.
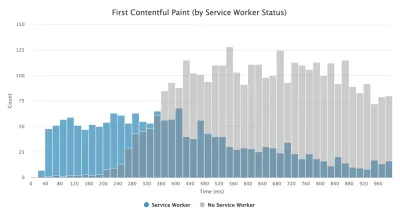
- Use service workers for caching and network fallbacks.
No performance optimization over a network can be faster than a locally stored cache on a user's machine (there are exceptions though). If your website is running over HTTPS, we can cache static assets in a service worker cache and store offline fallbacks (or even offline pages) and retrieve them from the user's machine, rather than going to the network.As suggested by Phil Walton, with service workers, we can send smaller HTML payloads by programmatically generating our responses. A service worker can request just the bare minimum of data it needs from the server (eg an HTML content partial, a Markdown file, JSON data, etc.), and then it can programmatically transform that data into a full HTML document. So once a user visits a site and the service worker is installed, the user will never request a full HTML page again. The performance impact can be quite impressive.
Browser support? Service workers are widely supported and the fallback is the network anyway. Does it help boost performance ? Oh yes, it does. And it's getting better, eg with Background Fetch allowing background uploads/downloads via a service worker as well.
There are a number of use cases for a service worker. For example, you could implement "Save for offline" feature, handle broken images, introduce messaging between tabs or provide different caching strategies based on request types. In general, a common reliable strategy is to store the app shell in the service worker's cache along with a few critical pages, such as offline page, frontpage and anything else that might be important in your case.
There are a few gotchas to keep in mind though. With a service worker in place, we need to beware range requests in Safari (if you are using Workbox for a service worker it has a range request module). If you ever stumbled upon
DOMException: Quota exceeded.error in the browser console, then look into Gerardo's article When 7KB equals 7MB.Comme l'écrit Gerardo, "Si vous créez une application Web progressive et que vous rencontrez un stockage de cache gonflé lorsque votre service worker met en cache des actifs statiques servis à partir de CDN, assurez-vous que l'en-tête de réponse CORS approprié existe pour les ressources d'origine croisée, vous ne mettez pas en cache les réponses opaques avec votre travailleur de service involontairement, vous optez pour les ressources d'image cross-origin en mode CORS en ajoutant l'attribut
crossoriginà la<img>.Il existe de nombreuses ressources intéressantes pour démarrer avec les techniciens de service :
- Service Worker Mindset, qui vous aide à comprendre comment les travailleurs de service travaillent dans les coulisses et les choses à comprendre lors de la création d'un.
- Chris Ferdinandi propose une excellente série d'articles sur les techniciens de service, expliquant comment créer des applications hors ligne et couvrant une variété de scénarios, de l'enregistrement hors ligne des pages récemment consultées à la définition d'une date d'expiration pour les éléments d'un cache de technicien de service.
- Pièges et meilleures pratiques des techniciens de service, avec quelques conseils sur la portée, retarder l'enregistrement d'un technicien de service et la mise en cache du technicien de service.
- Super série d'Ire Aderinokun sur "Offline First" avec Service Worker, avec une stratégie sur le precaching du shell de l'app.
- Service Worker : Une introduction avec des conseils pratiques sur la façon d'utiliser le service worker pour des expériences hors ligne riches, des synchronisations périodiques en arrière-plan et des notifications push.
- Il vaut toujours la peine de se référer au bon vieux livre de recettes hors ligne de Jake Archibald avec un certain nombre de recettes sur la façon de préparer votre propre travailleur de service.
- Workbox est un ensemble de bibliothèques de service worker spécialement conçues pour créer des applications Web progressives.
- Exécutez-vous des serveurs de travail sur le CDN/Edge, par exemple pour des tests A/B ?
À ce stade, nous sommes assez habitués à exécuter des service workers sur le client, mais avec les CDN qui les implémentent sur le serveur, nous pourrions également les utiliser pour ajuster les performances en périphérie.Par exemple, dans les tests A/B, lorsque HTML doit faire varier son contenu pour différents utilisateurs, nous pouvons utiliser Service Workers sur les serveurs CDN pour gérer la logique. Nous pourrions également diffuser la réécriture HTML pour accélérer les sites qui utilisent Google Fonts.
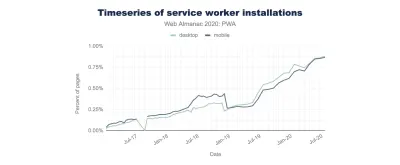
- Optimisez les performances de rendu.
Chaque fois que l'application est lente, cela se remarque tout de suite. Nous devons donc nous assurer qu'il n'y a pas de décalage lors du défilement de la page ou lorsqu'un élément est animé, et que vous atteignez systématiquement 60 images par seconde. Si ce n'est pas possible, alors au moins rendre les images par seconde cohérentes est préférable à une plage mixte de 60 à 15. Utilisez CSS'will-changepour informer le navigateur des éléments et des propriétés qui vont changer.Chaque fois que vous rencontrez des problèmes, déboguez les repeints inutiles dans DevTools :
- Mesurez les performances de rendu à l'exécution. Découvrez quelques conseils utiles sur la façon de lui donner un sens.
- Pour commencer, consultez le cours Udacity gratuit de Paul Lewis sur l'optimisation du rendu du navigateur et l'article de Georgy Marchuk sur la peinture du navigateur et les considérations pour les performances Web.
- Activez Paint Flashing dans "Plus d'outils → Rendu → Paint Flashing" dans Firefox DevTools.
- Dans React DevTools, cochez "Mises à jour en surbrillance" et activez "Enregistrer pourquoi chaque composant est rendu",
- Vous pouvez également utiliser Why Did You Render, ainsi, lorsqu'un composant est rendu à nouveau, un flash vous avertit du changement.
Utilisez-vous une disposition de maçonnerie ? Gardez à l'esprit que vous pourrez peut-être créer une mise en page Masonry avec une grille CSS seule, très bientôt.
Si vous souhaitez approfondir le sujet, Nolan Lawson a partagé des astuces pour mesurer avec précision les performances de mise en page dans son article, et Jason Miller a également suggéré des techniques alternatives. Nous avons également un petit article de Sergey Chikuyonok sur la façon d'obtenir une bonne animation GPU.

Les navigateurs peuvent animer la transformation et l'opacité à moindre coût. CSS Triggers est utile pour vérifier si CSS déclenche des re-layouts ou des reflows. (Crédit image : Addy Osmani)( Grand aperçu ) Remarque : les modifications apportées aux couches composées par GPU sont les moins coûteuses, donc si vous pouvez vous en tirer en ne déclenchant que la composition via
opacityettransform, vous serez sur la bonne voie. Anna Migas a également fourni de nombreux conseils pratiques dans son exposé sur le débogage des performances de rendu de l'interface utilisateur. Et pour comprendre comment déboguer les performances de peinture dans DevTools, consultez la vidéo d'audit des performances de peinture d'Umar. - Avez-vous optimisé les performances perçues ?
Bien que la séquence d'affichage des composants sur la page et la stratégie de diffusion des actifs dans le navigateur soient importantes, nous ne devons pas non plus sous-estimer le rôle des performances perçues. Le concept traite des aspects psychologiques de l'attente, en gardant essentiellement les clients occupés ou engagés pendant que quelque chose d'autre se passe. C'est là que la gestion de la perception, le démarrage préemptif, l'achèvement précoce et la gestion de la tolérance entrent en jeu.Qu'est-ce que tout cela veut dire? Lors du chargement des actifs, nous pouvons essayer d'avoir toujours une longueur d'avance sur le client, afin que l'expérience soit rapide alors qu'il se passe beaucoup de choses en arrière-plan. Pour garder le client engagé, nous pouvons tester des écrans squelettes (démo d'implémentation) au lieu de charger des indicateurs, ajouter des transitions/animations et essentiellement tromper l'UX lorsqu'il n'y a plus rien à optimiser.
Dans leur étude de cas sur The Art of UI Skeletons, Kumar McMillan partage quelques idées et techniques sur la façon de simuler des listes dynamiques, du texte et l'écran final, ainsi que sur la façon d'envisager la pensée squelette avec React.
Attention cependant : les écrans squelettes doivent être testés avant d'être déployés, car certains tests ont montré que les écrans squelettes peuvent être les pires selon toutes les métriques.
- Empêchez-vous les changements de mise en page et les repeints ?
Dans le domaine des performances perçues, l'une des expériences les plus perturbatrices est probablement le changement de mise en page , ou les refusions , causées par des images et des vidéos redimensionnées, des polices Web, des publicités injectées ou des scripts découverts tardivement qui remplissent les composants avec du contenu réel. Par conséquent, un client peut commencer à lire un article juste pour être interrompu par un saut de mise en page au-dessus de la zone de lecture. L'expérience est souvent abrupte et assez déroutante : et c'est probablement un cas de priorités de chargement qu'il faut revoir.La communauté a développé quelques techniques et solutions de contournement pour éviter les refusions. En général, il est conseillé d' éviter d'insérer un nouveau contenu au-dessus du contenu existant , sauf si cela se produit en réponse à une interaction de l'utilisateur. Définissez toujours les attributs de largeur et de hauteur sur les images, afin que les navigateurs modernes allouent la boîte et réservent l'espace par défaut (Firefox, Chrome).
Pour les images ou les vidéos, nous pouvons utiliser un espace réservé SVG pour réserver la zone d'affichage dans laquelle le média apparaîtra. Cela signifie que la zone sera réservée correctement lorsque vous devrez également conserver son rapport d'aspect. Nous pouvons également utiliser des espaces réservés ou des images de secours pour les publicités et le contenu dynamique, ainsi que des emplacements de mise en page pré-alloués.
Au lieu de charger des images paresseuses avec des scripts externes, envisagez d'utiliser le chargement paresseux natif ou le chargement paresseux hybride lorsque nous chargeons un script externe uniquement si le chargement paresseux natif n'est pas pris en charge.
Comme mentionné ci-dessus, regroupez toujours les repeints de polices Web et passez de toutes les polices de secours à toutes les polices Web à la fois - assurez-vous simplement que ce changement n'est pas trop brusque, en ajustant la hauteur de ligne et l'espacement entre les polices avec font-style-matcher .
Pour remplacer les métriques de police pour une police de secours afin d'émuler une police Web, nous pouvons utiliser des descripteurs @font-face pour remplacer les métriques de police (démo, activé dans Chrome 87). (Notez que les ajustements sont compliqués avec des piles de polices compliquées.)
Pour les CSS tardifs, nous pouvons nous assurer que le CSS critique pour la mise en page est intégré dans l'en-tête de chaque modèle. Encore plus loin que cela : pour les longues pages, lorsque la barre de défilement verticale est ajoutée, elle décale le contenu principal de 16 px vers la gauche. Pour afficher une barre de défilement plus tôt, nous pouvons ajouter
overflow-y: scrollonhtmlpour appliquer une barre de défilement au premier dessin. Ce dernier est utile car les barres de défilement peuvent provoquer des changements de mise en page non triviaux en raison du contenu au-dessus du pli qui se redistribue lorsque la largeur change. Cela devrait surtout se produire sur des plates-formes avec des barres de défilement non superposées comme Windows. Mais : pausesposition: stickycar ces éléments ne défileront jamais hors du conteneur.Si vous traitez des en-têtes qui deviennent fixes ou collants positionnés en haut de la page lors du défilement, réservez de l'espace pour l'en-tête lorsqu'il devient piné, par exemple avec un élément d'espace réservé ou une
margin-topsur le contenu. Une exception devrait être les bannières de consentement aux cookies qui ne devraient pas avoir d'impact sur CLS, mais parfois elles en ont : cela dépend de la mise en œuvre. Il y a quelques stratégies et plats à emporter intéressants dans ce fil Twitter.Pour un composant d'onglet pouvant inclure différentes quantités de texte, vous pouvez empêcher les changements de mise en page avec des piles de grilles CSS. En plaçant le contenu de chaque onglet dans la même zone de grille et en masquant l'un d'eux à la fois, nous pouvons nous assurer que le conteneur prend toujours la hauteur de l'élément le plus grand, de sorte qu'aucun changement de disposition ne se produira.
Ah, et bien sûr, le défilement infini et "Charger plus" peuvent également entraîner des changements de mise en page s'il y a du contenu sous la liste (par exemple, le pied de page). Pour améliorer CLS, réservez suffisamment d'espace pour le contenu qui serait chargé avant que l'utilisateur ne fasse défiler cette partie de la page, supprimez le pied de page ou tout élément DOM au bas de la page qui pourrait être poussé vers le bas par le chargement du contenu. En outre, prérécupérez les données et les images pour le contenu en dessous de la ligne de flottaison afin qu'au moment où un utilisateur défile aussi loin, il soit déjà là. Vous pouvez également utiliser des bibliothèques de virtualisation de liste comme react-window pour optimiser de longues listes ( merci, Addy Osmani ! ).
Pour vous assurer que l'impact des refusions est contenu, mesurez la stabilité de la mise en page avec l'API Layout Instability. Avec lui, vous pouvez calculer le score Cumulative Layout Shift ( CLS ) et l'inclure comme exigence dans vos tests, de sorte qu'à chaque fois qu'une régression apparaît, vous pouvez la suivre et la corriger.
Pour calculer le score de décalage de mise en page, le navigateur examine la taille de la fenêtre et le mouvement des éléments instables dans la fenêtre entre deux images rendues. Idéalement, le score serait proche de
0. Il existe un excellent guide de Milica Mihajlija et Philip Walton sur ce qu'est CLS et comment le mesurer. C'est un bon point de départ pour mesurer et maintenir les performances perçues et éviter les interruptions, en particulier pour les tâches critiques de l'entreprise.Petite astuce : pour découvrir ce qui a provoqué un changement de disposition dans DevTools, vous pouvez explorer les changements de disposition sous "Expérience" dans le panneau de performances.
Bonus : si vous souhaitez réduire les reflows et les repaints, consultez le guide de Charis Theodoulou sur Minimizing DOM Reflow/Layout Thrashing et la liste de Paul Irish sur What forces layout / reflow ainsi que CSSTriggers.com, une table de référence sur les propriétés CSS qui déclenchent layout, paint et composition.
Réseau et HTTP/2
- L'agrafage OCSP est-il activé ?
En activant l'agrafage OCSP sur votre serveur, vous pouvez accélérer vos poignées de main TLS. Le protocole OCSP (Online Certificate Status Protocol) a été créé comme une alternative au protocole de liste de révocation de certificats (CRL). Les deux protocoles sont utilisés pour vérifier si un certificat SSL a été révoqué.Cependant, le protocole OCSP n'exige pas que le navigateur passe du temps à télécharger puis à rechercher une liste d'informations sur les certificats, ce qui réduit le temps requis pour une prise de contact.
- Avez-vous réduit l'impact de la révocation des certificats SSL ?
Dans son article sur "Le coût de performance des certificats EV", Simon Hearne donne un excellent aperçu des certificats courants et de l'impact que le choix d'un certificat peut avoir sur la performance globale.Comme l'écrit Simon, dans le monde du HTTPS, il existe quelques types de niveaux de validation de certificat utilisés pour sécuriser le trafic :
- La validation de domaine (DV) valide que le demandeur de certificat possède le domaine,
- La validation d'organisation (OV) valide qu'une organisation possède le domaine,
- La validation étendue (EV) valide qu'une organisation possède le domaine, avec une validation rigoureuse.
Il est important de noter que tous ces certificats sont les mêmes en termes de technologie ; ils ne diffèrent que par les informations et les propriétés fournies dans ces certificats.
Les certificats EV sont coûteux et chronophages car ils nécessitent un humain pour examiner un certificat et garantir sa validité. Les certificats DV, en revanche, sont souvent fournis gratuitement, par exemple par Let's Encrypt, une autorité de certification ouverte et automatisée bien intégrée à de nombreux fournisseurs d'hébergement et CDN. En fait, au moment de la rédaction de cet article, il alimente plus de 225 millions de sites Web (PDF), bien qu'il ne représente que 2,69 % des pages (ouvertes dans Firefox).
Alors quel est le problème alors ? Le problème est que les certificats EV ne prennent pas entièrement en charge l'agrafage OCSP mentionné ci-dessus. Alors que l'agrafage permet au serveur de vérifier auprès de l'autorité de certification si le certificat a été révoqué, puis d'ajouter ("agrafer") ces informations au certificat, sans agrafer, le client doit faire tout le travail, ce qui entraîne des demandes inutiles lors de la négociation TLS . Sur de mauvaises connexions, cela peut entraîner des coûts de performances notables (1000 ms +).
Les certificats EV ne sont pas un excellent choix pour les performances Web, et ils peuvent avoir un impact beaucoup plus important sur les performances que les certificats DV. Pour des performances Web optimales, servez toujours un certificat DV agrafé OCSP. Ils sont également beaucoup moins chers que les certificats EV et moins compliqués à acquérir. Eh bien, au moins jusqu'à ce que CRLite soit disponible.
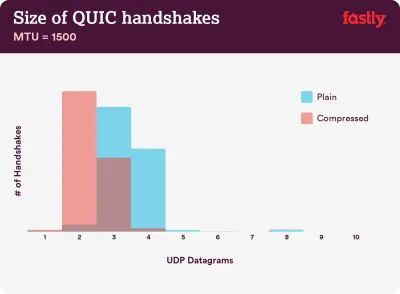
La compression est importante : 40 à 43 % des chaînes de certificats non compressées sont trop volumineuses pour tenir dans un seul vol QUIC de 3 datagrammes UDP. (Crédit image :) Fastly) ( Grand aperçu ) Remarque : Avec QUIC/HTTP/3 sur nous, il convient de noter que la chaîne de certificats TLS est le seul contenu de taille variable qui domine le nombre d'octets dans le QUIC Handshake. La taille varie entre quelques centaines d'octets et plus de 10 Ko.
Il est donc très important de garder les certificats TLS petits sur QUIC/HTTP/3, car les certificats volumineux entraîneront plusieurs poignées de main. De plus, nous devons nous assurer que les certificats sont compressés, sinon les chaînes de certificats seraient trop grandes pour tenir dans un seul vol QUIC.
Vous pouvez trouver beaucoup plus de détails et des pointeurs sur le problème et les solutions sur :
- Les certificats EV rendent le Web lent et peu fiable par Aaron Peters,
- L'impact de la révocation des certificats SSL sur les performances web par Matt Hobbs,
- Le coût de performance des certificats EV par Simon Hearne,
- La poignée de main QUIC nécessite-t-elle une compression pour être rapide ? par Patrick McManus.
- Avez-vous déjà adopté IPv6 ?
Parce que nous manquons d'espace avec IPv4 et que les principaux réseaux mobiles adoptent rapidement IPv6 (les États-Unis ont presque atteint un seuil d'adoption d'IPv6 de 50 %), c'est une bonne idée de mettre à jour votre DNS vers IPv6 pour rester à l'épreuve des balles pour l'avenir. Assurez-vous simplement que la prise en charge de la double pile est fournie sur le réseau - cela permet à IPv6 et IPv4 de fonctionner simultanément l'un à côté de l'autre. Après tout, IPv6 n'est pas rétrocompatible. De plus, des études montrent qu'IPv6 a rendu ces sites Web 10 à 15 % plus rapides grâce à la découverte de voisins (NDP) et à l'optimisation des itinéraires. - Assurez-vous que tous les actifs s'exécutent sur HTTP/2 (ou HTTP/3).
Avec Google poussant vers un Web HTTPS plus sécurisé au cours des dernières années, un passage à l'environnement HTTP/2 est certainement un bon investissement. En fait, selon Web Almanac, 64 % de toutes les requêtes s'exécutent déjà sur HTTP/2.Il est important de comprendre que HTTP/2 n'est pas parfait et a des problèmes de priorisation, mais il est très bien pris en charge ; et, dans la plupart des cas, il vaut mieux s'en servir.
Un mot d'avertissement : HTTP/2 Server Push est supprimé de Chrome, donc si votre implémentation repose sur Server Push, vous devrez peut-être le revoir. Au lieu de cela, nous pourrions envisager Early Hints, qui sont déjà intégrés en tant qu'expérience dans Fastly.
Si vous utilisez toujours HTTP, la tâche la plus fastidieuse consistera à migrer d'abord vers HTTPS, puis à ajuster votre processus de génération pour prendre en charge le multiplexage et la parallélisation HTTP/2. Apporter HTTP/2 à Gov.uk est une étude de cas fantastique sur le fait de faire exactement cela, trouver un chemin à travers CORS, SRI et WPT en cours de route. Pour le reste de cet article, nous supposons que vous passez ou avez déjà basculé vers HTTP/2.
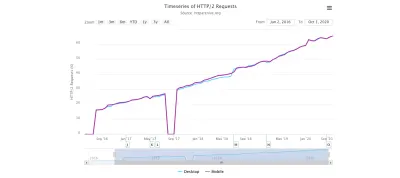
- Déployez correctement HTTP/2.
Encore une fois, la diffusion d'actifs via HTTP/2 peut bénéficier d'une refonte partielle de la façon dont vous avez servi les actifs jusqu'à présent. Vous devrez trouver un juste équilibre entre l'empaquetage des modules et le chargement de nombreux petits modules en parallèle. En fin de compte, la meilleure demande reste l'absence de demande, cependant, l'objectif est de trouver un juste équilibre entre la première livraison rapide des actifs et la mise en cache.D'une part, vous voudrez peut-être éviter de concaténer complètement les actifs, au lieu de décomposer votre interface entière en plusieurs petits modules, de les compresser dans le cadre du processus de construction et de les charger en parallèle. Une modification dans un fichier ne nécessitera pas le retéléchargement de la feuille de style entière ou de JavaScript. Il minimise également le temps d'analyse et maintient les charges utiles des pages individuelles à un niveau bas.
D'autre part, l'emballage compte toujours. En utilisant de nombreux petits scripts, la compression globale en souffrira et le coût de récupération des objets du cache augmentera. La compression d'un grand paquet bénéficiera de la réutilisation du dictionnaire, contrairement aux petits paquets séparés. Il existe un travail standard pour résoudre ce problème, mais il est loin pour le moment. Deuxièmement, les navigateurs n'ont pas encore été optimisés pour de tels workflows. Par exemple, Chrome déclenchera des communications inter-processus (IPC) linéaires en fonction du nombre de ressources, de sorte que l'inclusion de centaines de ressources entraînera des coûts d'exécution du navigateur.
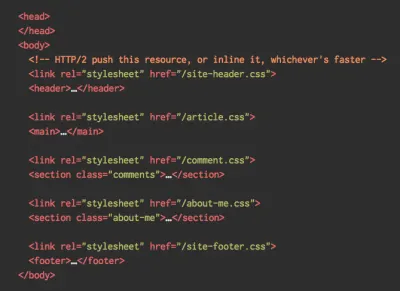
Pour obtenir les meilleurs résultats avec HTTP/2, pensez à charger progressivement le CSS, comme suggéré par Jake Archibald de Chrome. Néanmoins, vous pouvez essayer de charger le CSS progressivement. En fait, le CSS intégré au corps ne bloque plus le rendu pour Chrome. Mais il y a quelques problèmes de priorisation, donc ce n'est pas aussi simple, mais cela vaut la peine d'être expérimenté.
Vous pouvez vous en tirer avec la fusion de connexion HTTP/2, qui vous permet d'utiliser le partage de domaine tout en bénéficiant de HTTP/2, mais y parvenir en pratique est difficile et, en général, ce n'est pas considéré comme une bonne pratique. De plus, HTTP/2 et Subresource Integrity ne s'entendent pas toujours.
Ce qu'il faut faire? Eh bien, si vous utilisez HTTP/2, envoyer environ 6 à 10 packages semble être un bon compromis (et n'est pas trop mal pour les anciens navigateurs). Expérimentez et mesurez pour trouver le bon équilibre pour votre site Web.
- Envoyons-nous tous les éléments via une seule connexion HTTP/2 ?
L'un des principaux avantages de HTTP/2 est qu'il nous permet d'envoyer des ressources via une seule connexion. Cependant, nous avons parfois fait quelque chose de mal - par exemple, avoir un problème CORS ou mal configurer l'attributcrossorigin, de sorte que le navigateur serait obligé d'ouvrir une nouvelle connexion.Pour vérifier si toutes les requêtes utilisent une seule connexion HTTP/2, ou si quelque chose est mal configuré, activez la colonne "ID de connexion" dans DevTools → Réseau. Par exemple, ici, toutes les requêtes partagent la même connexion (286) — sauf manifest.json, qui en ouvre une autre (451).
- Vos serveurs et CDN prennent-ils en charge HTTP/2 ?
Différents serveurs et CDN prennent (encore) en charge HTTP/2 différemment. Utilisez la comparaison CDN pour vérifier vos options ou recherchez rapidement les performances de vos serveurs et les fonctionnalités que vous pouvez vous attendre à prendre en charge.Consultez les incroyables recherches de Pat Meenan sur les priorités HTTP/2 (vidéo) et testez la prise en charge du serveur pour la hiérarchisation HTTP/2. Selon Pat, il est recommandé d'activer le contrôle de congestion BBR et de définir
tcp_notsent_lowatsur 16 Ko pour que la hiérarchisation HTTP/2 fonctionne de manière fiable sur les noyaux Linux 4.9 et versions ultérieures ( merci, Yoav ! ). Andy Davies a effectué une recherche similaire pour la hiérarchisation HTTP/2 sur les navigateurs, les CDN et les services d'hébergement cloud.Pendant que vous y êtes, vérifiez si votre noyau prend en charge TCP BBR et activez-le si possible. Il est actuellement utilisé sur Google Cloud Platform, Amazon Cloudfront, Linux (par exemple Ubuntu).
- La compression HPACK est-elle utilisée ?
Si vous utilisez HTTP/2, vérifiez que vos serveurs implémentent la compression HPACK pour les en-têtes de réponse HTTP afin de réduire les frais généraux inutiles. Certains serveurs HTTP/2 peuvent ne pas prendre entièrement en charge la spécification, HPACK étant un exemple. H2spec est un excellent outil (bien que très détaillé techniquement) pour vérifier cela. L'algorithme de compression de HPACK est assez impressionnant et fonctionne. - Assurez-vous que la sécurité de votre serveur est à toute épreuve.
Toutes les implémentations de navigateur de HTTP/2 s'exécutent sur TLS, vous voudrez donc probablement éviter les avertissements de sécurité ou certains éléments de votre page qui ne fonctionnent pas. Vérifiez que vos en-têtes de sécurité sont correctement définis, éliminez les vulnérabilités connues et vérifiez votre configuration HTTPS.Assurez-vous également que tous les plugins externes et les scripts de suivi sont chargés via HTTPS, que les scripts intersites ne sont pas possibles et que les en-têtes HTTP Strict Transport Security et les en-têtes Content Security Policy sont correctement définis.
- Vos serveurs et CDN prennent-ils en charge HTTP/3 ?
Bien que HTTP/2 ait apporté un certain nombre d'améliorations significatives des performances sur le Web, il a également laissé de nombreux points à améliorer, en particulier le blocage de tête de ligne dans TCP, qui était perceptible sur un réseau lent avec une perte de paquets importante. HTTP/3 résout ces problèmes pour de bon (article).Pour résoudre les problèmes HTTP/2, l'IETF, avec Google, Akamai et d'autres, ont travaillé sur un nouveau protocole qui a récemment été normalisé sous le nom de HTTP/3.
Robin Marx a très bien expliqué HTTP/3, et l'explication suivante est basée sur son explication. Dans son noyau, HTTP/3 est très similaire à HTTP/2 en termes de fonctionnalités, mais sous le capot, il fonctionne très différemment. HTTP/3 apporte un certain nombre d'améliorations : des poignées de main plus rapides, un meilleur cryptage, des flux indépendants plus fiables, un meilleur cryptage et un meilleur contrôle des flux. Une différence notable est que HTTP/3 utilise QUIC comme couche de transport, avec des paquets QUIC encapsulés au-dessus des diagrammes UDP, plutôt que TCP.
QUIC intègre pleinement TLS 1.3 dans le protocole, tandis que dans TCP, il est superposé. Dans la pile TCP typique, nous avons quelques temps d'aller-retour parce que TCP et TLS doivent faire leurs propres poignées de main séparées, mais avec QUIC, les deux peuvent être combinés et terminés en un seul aller-retour . Étant donné que TLS 1.3 nous permet de configurer des clés de chiffrement pour une connexion conséquente, à partir de la deuxième connexion, nous pouvons déjà envoyer et recevoir des données de la couche application lors du premier aller-retour, appelé "0-RTT".
De plus, l'algorithme de compression d'en-tête de HTTP/2 a été entièrement réécrit, ainsi que son système de priorisation. De plus, QUIC prend en charge la migration de connexion du Wi-Fi vers le réseau cellulaire via les identifiants de connexion dans l'en-tête de chaque paquet QUIC. La plupart des implémentations sont effectuées dans l'espace utilisateur, et non dans l'espace noyau (comme c'est le cas avec TCP), nous devrions donc nous attendre à ce que le protocole évolue à l'avenir.
Est-ce que tout cela ferait une grande différence ? Probablement oui, ayant notamment un impact sur les temps de chargement sur mobile, mais aussi sur la façon dont nous servons les ressources aux utilisateurs finaux. Alors qu'en HTTP/2, plusieurs requêtes partagent une connexion, en HTTP/3, les requêtes partagent également une connexion mais sont diffusées indépendamment, de sorte qu'un paquet abandonné n'affecte plus toutes les requêtes, mais un seul flux.
Cela signifie qu'avec un seul gros bundle JavaScript, le traitement des actifs sera ralenti lorsqu'un flux s'interrompt, l'impact sera moins important lorsque plusieurs fichiers sont diffusés en parallèle (HTTP/3). L' emballage est donc toujours important .
HTTP/3 est toujours en cours de développement. Chrome, Firefox et Safari ont déjà des implémentations. Certains CDN prennent déjà en charge QUIC et HTTP/3. Fin 2020, Chrome a commencé à déployer HTTP/3 et IETF QUIC, et en fait tous les services Google (Google Analytics, YouTube, etc.) fonctionnent déjà sur HTTP/3. LiteSpeed Web Server prend en charge HTTP/3, mais ni Apache, nginx ni IIS ne le prennent encore en charge, mais il est susceptible de changer rapidement en 2021.
L' essentiel : si vous avez la possibilité d'utiliser HTTP/3 sur le serveur et sur votre CDN, c'est probablement une très bonne idée de le faire. Le principal avantage proviendra de la récupération simultanée de plusieurs objets, en particulier sur les connexions à latence élevée. Nous ne savons pas encore avec certitude car il n'y a pas beaucoup de recherches effectuées dans cet espace, mais les premiers résultats sont très prometteurs.
Si vous souhaitez vous plonger davantage dans les spécificités et les avantages du protocole, voici quelques bons points de départ à vérifier :
- HTTP/3 expliqué, un effort collaboratif pour documenter les protocoles HTTP/3 et QUIC. Disponible en plusieurs langues, également au format PDF.
- Améliorer les performances Web avec HTTP/3 avec Daniel Stenberg.
- Un guide académique sur QUIC avec Robin Marx présente les concepts de base des protocoles QUIC et HTTP/3, explique comment HTTP/3 gère le blocage de tête de ligne et la migration de connexion, et comment HTTP/3 est conçu pour être permanent (merci, Simon !).
- Vous pouvez vérifier si votre serveur fonctionne sur HTTP/3 sur HTTP3Check.net.
Test et surveillance
- Avez-vous optimisé votre flux de travail d'audit ?
Cela peut ne pas sembler être un gros problème, mais avoir les bons paramètres en place à portée de main peut vous faire gagner beaucoup de temps lors des tests. Envisagez d'utiliser Alfred Workflow pour WebPageTest de Tim Kadlec pour soumettre un test à l'instance publique de WebPageTest. En fait, WebPageTest possède de nombreuses fonctionnalités obscures, alors prenez le temps d'apprendre à lire un graphique WebPageTest Waterfall View et à lire un graphique WebPageTest Connection View pour diagnostiquer et résoudre plus rapidement les problèmes de performances.Vous pouvez également piloter WebPageTest à partir d'une feuille de calcul Google et intégrer les scores d'accessibilité, de performance et de référencement dans votre configuration Travis avec Lighthouse CI ou directement dans Webpack.
Jetez un coup d'œil au récent AutoWebPerf, un outil modulaire qui permet la collecte automatique de données de performances à partir de plusieurs sources. Par exemple, nous pourrions définir un test quotidien sur vos pages critiques pour capturer les données de terrain de l'API CrUX et les données de laboratoire d'un rapport Lighthouse de PageSpeed Insights.
Et si vous avez besoin de déboguer quelque chose rapidement mais que votre processus de construction semble être remarquablement lent, gardez à l'esprit que "la suppression des espaces blancs et la modification des symboles représentent 95 % de la réduction de la taille du code minifié pour la plupart des JavaScript - pas des transformations de code élaborées. Vous pouvez désactivez simplement la compression pour accélérer les builds Uglify de 3 à 4 fois."
- Avez-vous testé dans les navigateurs proxy et les anciens navigateurs ?
Tester dans Chrome et Firefox ne suffit pas. Examinez le fonctionnement de votre site Web dans les navigateurs proxy et les anciens navigateurs. UC Browser et Opera Mini, par exemple, détiennent une part de marché importante en Asie (jusqu'à 35 % en Asie). Mesurez la vitesse Internet moyenne dans les pays qui vous intéressent pour éviter les grosses surprises en cours de route. Testez avec la limitation du réseau et émulez un appareil haute résolution. BrowserStack est fantastique pour tester sur des appareils réels distants et le compléter avec au moins quelques appareils réels dans votre bureau également - cela en vaut la peine.
- Avez-vous testé les performances de vos pages 404 ?
Normalement, nous ne réfléchissons pas à deux fois quand il s'agit de 404 pages. Après tout, lorsqu'un client demande une page qui n'existe pas sur le serveur, le serveur va répondre avec un code d'état 404 et la page 404 associée. Il n'y a pas grand-chose, n'est-ce pas ?Un aspect important des réponses 404 est la taille réelle du corps de la réponse qui est envoyée au navigateur. Selon les 404 pages de recherche de Matt Hobbs, la grande majorité des 404 réponses proviennent de favicons manquants, de requêtes de téléchargement WordPress, de requêtes JavaScript brisées, de fichiers manifestes ainsi que de fichiers CSS et de polices. Chaque fois qu'un client demande un actif qui n'existe pas, il reçoit une réponse 404 - et souvent cette réponse est énorme.
Assurez-vous d'examiner et d'optimiser la stratégie de mise en cache pour vos pages 404. Notre objectif est de servir le code HTML au navigateur uniquement lorsqu'il attend une réponse HTML et de renvoyer une petite charge utile d'erreur pour toutes les autres réponses. Selon Matt, "si nous plaçons un CDN devant notre origine, nous avons la possibilité de mettre en cache la réponse de la page 404 sur le CDN. C'est utile car sans cela, frapper une page 404 pourrait être utilisé comme vecteur d'attaque DoS, par forçant le serveur d'origine à répondre à chaque requête 404 plutôt que de laisser le CDN répondre avec une version en cache."
Non seulement les erreurs 404 peuvent nuire à vos performances, mais elles peuvent également coûter du trafic, c'est donc une bonne idée d'inclure une page d'erreur 404 dans votre suite de tests Lighthouse et de suivre son score au fil du temps.
- Avez-vous testé les performances de vos invites de consentement RGPD ?
À l'époque du RGPD et du CCPA, il est devenu courant de s'appuyer sur des tiers pour offrir aux clients de l'UE la possibilité d'activer ou de désactiver le suivi. Cependant, comme avec tout autre script tiers, leurs performances peuvent avoir un impact assez dévastateur sur l'ensemble de l'effort de performance.Bien sûr, le consentement réel est susceptible de modifier l'impact des scripts sur les performances globales, donc, comme l'a noté Boris Schapira, nous pourrions vouloir étudier quelques profils de performances Web différents :
- Le consentement a été entièrement refusé,
- Le consentement a été partiellement refusé,
- Le consentement a été entièrement donné.
- L'utilisateur n'a pas répondu à l'invite de consentement (ou l'invite a été bloquée par un bloqueur de contenu),
Normalement, les invites de consentement aux cookies ne devraient pas avoir d'impact sur CLS, mais parfois elles le font, alors pensez à utiliser les options libres et open source Osano ou cookie-consent-box.
En général, il vaut la peine d'examiner les performances de la fenêtre contextuelle, car vous devrez déterminer le décalage horizontal ou vertical de l'événement de souris et positionner correctement la fenêtre contextuelle par rapport à l'ancre. Noam Rosenthal partage les apprentissages de l'équipe Wikimédia dans l'article Étude de cas sur les performances Web : aperçus des pages Wikipédia (également disponible sous forme de vidéo et de minutes).
- Conservez-vous un CSS de diagnostic des performances ?
Bien que nous puissions inclure toutes sortes de vérifications pour nous assurer que le code non performant est déployé, il est souvent utile d'avoir une idée rapide de certains des fruits à portée de main qui pourraient être résolus facilement. Pour cela, nous pourrions utiliser le brillant Performance Diagnostics CSS de Tim Kadlec (inspiré de l'extrait de Harry Roberts qui met en évidence les images chargées paresseusement, les images non dimensionnées, les images au format hérité et les scripts synchrones.Par exemple, vous voudrez peut-être vous assurer qu'aucune image au-dessus du pli n'est chargée paresseusement. Vous pouvez personnaliser l'extrait de code selon vos besoins, par exemple pour mettre en évidence les polices Web qui ne sont pas utilisées ou détecter les polices d'icônes. Un super petit outil pour s'assurer que les erreurs sont visibles lors du débogage, ou tout simplement pour auditer très rapidement le projet en cours.
/* Performance Diagnostics CSS */ /* via Harry Roberts. https://twitter.com/csswizardry/status/1346477682544951296 */ img[loading=lazy] { outline: 10px solid red; }
- Have you tested the impact on accessibility?
When the browser starts to load a page, it builds a DOM, and if there is an assistive technology like a screen reader running, it also creates an accessibility tree. The screen reader then has to query the accessibility tree to retrieve the information and make it available to the user — sometimes by default, and sometimes on demand. And sometimes it takes time.When talking about fast Time to Interactive, usually we mean an indicator of how soon a user can interact with the page by clicking or tapping on links and buttons. The context is slightly different with screen readers. In that case, fast Time to Interactive means how much time passes by until the screen reader can announce navigation on a given page and a screen reader user can actually hit keyboard to interact.
Leonie Watson has given an eye-opening talk on accessibility performance and specifically the impact slow loading has on screen reader announcement delays. Screen readers are used to fast-paced announcements and quick navigation, and therefore might potentially be even less patient than sighted users.
Large pages and DOM manipulations with JavaScript will cause delays in screen reader announcements. A rather unexplored area that could use some attention and testing as screen readers are available on literally every platform (Jaws, NVDA, Voiceover, Narrator, Orca).
- Is continuous monitoring set up?
Having a private instance of WebPagetest is always beneficial for quick and unlimited tests. However, a continuous monitoring tool — like Sitespeed, Calibre and SpeedCurve — with automatic alerts will give you a more detailed picture of your performance. Set your own user-timing marks to measure and monitor business-specific metrics. Also, consider adding automated performance regression alerts to monitor changes over time.Look into using RUM-solutions to monitor changes in performance over time. For automated unit-test-alike load testing tools, you can use k6 with its scripting API. Also, look into SpeedTracker, Lighthouse and Calibre.
Victoires rapides
This list is quite comprehensive, and completing all of the optimizations might take quite a while. So, if you had just 1 hour to get significant improvements, what would you do? Let's boil it all down to 17 low-hanging fruits . Obviously, before you start and once you finish, measure results, including Largest Contentful Paint and Time To Interactive on a 3G and cable connection.
- Measure the real world experience and set appropriate goals. Aim to be at least 20% faster than your fastest competitor. Stay within Largest Contentful Paint < 2.5s, a First Input Delay < 100ms, Time to Interactive < 5s on slow 3G, for repeat visits, TTI < 2s. Optimize at least for First Contentful Paint and Time To Interactive.
- Optimize images with Squoosh, mozjpeg, guetzli, pingo and SVGOMG, and serve AVIF/WebP with an image CDN.
- Prepare critical CSS for your main templates, and inline them in the
<head>of each template. For CSS/JS, operate within a critical file size budget of max. 170KB gzipped (0.7MB decompressed). - Trim, optimize, defer and lazy-load scripts. Invest in the config of your bundler to remove redundancies and check lightweight alternatives.
- Always self-host your static assets and always prefer to self-host third-party assets. Limit the impact of third-party scripts. Use facades, load widgets on interaction and beware of anti-flicker snippets.
- Be selective when choosing a framework. For single-page-applications, identify critical pages and serve them statically, or at least prerender them, and use progressive hydration on component-level and import modules on interaction.
- Client-side rendering alone isn't a good choice for performance. Prerender if your pages don't change much, and defer the booting of frameworks if you can. If possible, use streaming server-side rendering.
- Serve legacy code only to legacy browsers with
<script type="module">and module/nomodule pattern. - Experiment with regrouping your CSS rules and test in-body CSS.
- Add resource hints to speed up delivery with faster
dns-lookup,preconnect,prefetch,preloadandprerender. - Subset web fonts and load them asynchronously, and utilize
font-displayin CSS for fast first rendering. - Check that HTTP cache headers and security headers are set properly.
- Enable Brotli compression on the server. (If that's not possible, at least make sure that Gzip compression is enabled.)
- Enable TCP BBR congestion as long as your server is running on the Linux kernel version 4.9+.
- Enable OCSP stapling and IPv6 if possible. Always serve an OCSP stapled DV certificate.
- Enable HPACK compression for HTTP/2 and move to HTTP/3 if it's available.
- Cache assets such as fonts, styles, JavaScript and images in a service worker cache.
Download The Checklist (PDF, Apple Pages)
With this checklist in mind, you should be prepared for any kind of front-end performance project. Feel free to download the print-ready PDF of the checklist as well as an editable Apple Pages document to customize the checklist for your needs:
- Download the checklist PDF (PDF, 166 KB)
- Download the checklist in Apple Pages (.pages, 275 KB)
- Download the checklist in MS Word (.docx, 151 KB)
If you need alternatives, you can also check the front-end checklist by Dan Rublic, the "Designer's Web Performance Checklist" by Jon Yablonski and the FrontendChecklist.
C'est parti !
Some of the optimizations might be beyond the scope of your work or budget or might just be overkill given the legacy code you have to deal with. That's fine! Use this checklist as a general (and hopefully comprehensive) guide, and create your own list of issues that apply to your context. But most importantly, test and measure your own projects to identify issues before optimizing. Happy performance results in 2021, everyone!
A huge thanks to Guy Podjarny, Yoav Weiss, Addy Osmani, Artem Denysov, Denys Mishunov, Ilya Pukhalski, Jeremy Wagner, Colin Bendell, Mark Zeman, Patrick Meenan, Leonardo Losoviz, Andy Davies, Rachel Andrew, Anselm Hannemann, Barry Pollard, Patrick Hamann, Gideon Pyzer, Andy Davies, Maria Prosvernina, Tim Kadlec, Rey Bango, Matthias Ott, Peter Bowyer, Phil Walton, Mariana Peralta, Pepijn Senders, Mark Nottingham, Jean Pierre Vincent, Philipp Tellis, Ryan Townsend, Ingrid Bergman, Mohamed Hussain SH, Jacob Groß, Tim Swalling, Bob Visser, Kev Adamson, Adir Amsalem, Aleksey Kulikov and Rodney Rehm for reviewing this article, as well as our fantastic community which has shared techniques and lessons learned from its work in performance optimization for everybody to use. Vous êtes vraiment fracassant !