
Tests floconneux : se débarrasser d'un cauchemar vivant dans les tests
Publié: 2022-03-10Il y a une fable à laquelle je pense beaucoup ces temps-ci. La fable m'a été racontée quand j'étais enfant. Il s'intitule « Le garçon qui criait au loup » d'Ésope. Il s'agit d'un garçon qui garde les moutons de son village. Il s'ennuie et prétend qu'un loup attaque le troupeau, appelant les villageois à l'aide - seulement pour qu'ils réalisent avec déception qu'il s'agit d'une fausse alerte et laissent le garçon tranquille. Puis, lorsqu'un loup apparaît réellement et que le garçon appelle à l'aide, les villageois pensent qu'il s'agit d'une autre fausse alerte et ne viennent pas à la rescousse, et les moutons finissent par se faire manger par le loup.
La morale de l'histoire est mieux résumée par l'auteur lui-même :
"Un menteur ne sera pas cru, même s'il dit la vérité."
Un loup attaque le mouton et le garçon crie à l'aide, mais après de nombreux mensonges, plus personne ne le croit. Cette morale peut s'appliquer aux tests : l'histoire d'Ésope est une belle allégorie d'un schéma d'appariement sur lequel je suis tombé : des tests aléatoires qui ne fournissent aucune valeur.
Tests frontaux : pourquoi s'en soucier ?
La plupart de mes journées sont consacrées aux tests frontaux. Cela ne devrait donc pas vous surprendre que les exemples de code de cet article proviendront principalement des tests frontaux que j'ai rencontrés dans mon travail. Cependant, dans la plupart des cas, ils peuvent être facilement traduits dans d'autres langues et appliqués à d'autres frameworks. J'espère donc que cet article vous sera utile, quelle que soit votre expertise.
Il convient de rappeler ce que signifie le test frontal. Dans leur essence, les tests frontaux sont un ensemble de pratiques permettant de tester l'interface utilisateur d'une application Web, y compris ses fonctionnalités.
Commençant comme ingénieur en assurance qualité, je connais la douleur des tests manuels interminables à partir d'une liste de contrôle juste avant une version. Ainsi, en plus de l'objectif de s'assurer qu'une application reste sans erreur lors des mises à jour successives, je me suis efforcé d' alléger la charge de travail des tests causés par ces tâches de routine pour lesquelles vous n'avez pas réellement besoin d'un humain. Maintenant, en tant que développeur, je trouve le sujet toujours d'actualité, d'autant plus que j'essaie d'aider directement les utilisateurs et les collègues. Et il y a un problème avec les tests en particulier qui nous a donné des cauchemars.
La science des tests floconneux
Un test floconneux est un test qui ne produit pas le même résultat à chaque fois que la même analyse est exécutée. Le build n'échouera qu'occasionnellement : une fois, il réussira, une autre fois, il échouera, la prochaine fois, il passera à nouveau, sans qu'aucune modification du build n'ait été apportée.
Quand je me souviens de mes cauchemars de test, un cas en particulier me vient à l'esprit. C'était dans un test d'interface utilisateur. Nous avons construit une zone de liste déroulante de style personnalisé (c'est-à-dire une liste sélectionnable avec un champ de saisie):
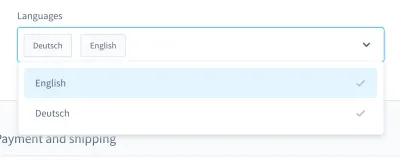
Avec cette zone de liste déroulante, vous pouvez rechercher un produit et sélectionner un ou plusieurs des résultats. Plusieurs jours, ce test s'est bien passé, mais à un moment donné, les choses ont changé. Dans l'une des quelque dix versions de notre système d'intégration continue (CI), le test de recherche et de sélection d'un produit dans cette zone de liste déroulante a échoué.
La capture d'écran de l'échec montre que la liste des résultats n'est pas filtrée, malgré le succès de la recherche :
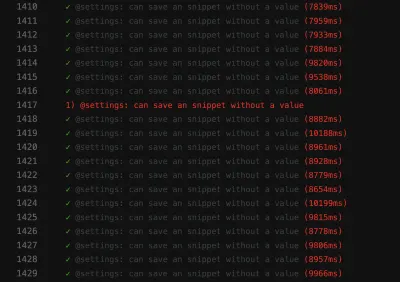
Un test aléatoire comme celui-ci peut bloquer le pipeline de déploiement continu , ce qui rend la livraison des fonctionnalités plus lente que nécessaire. De plus, un test floconneux est problématique car il n'est plus déterministe, ce qui le rend inutile. Après tout, vous ne feriez pas plus confiance à quelqu'un qu'à un menteur.
De plus, les tests floconneux sont coûteux à réparer , nécessitant souvent des heures voire des jours de débogage. Même si les tests de bout en bout sont plus enclins à être floconneux, je les ai expérimentés dans toutes sortes de tests : tests unitaires, tests fonctionnels, tests de bout en bout et tout le reste.
Un autre problème important avec les tests floconneux est l'attitude qu'ils imprègnent chez nous, les développeurs. Quand j'ai commencé à travailler dans l'automatisation des tests, j'ai souvent entendu des développeurs dire ceci en réponse à un test raté :
« Ahh, cette construction. Peu importe, relancez-le à nouveau. Ça finira par passer, un jour.
C'est un énorme drapeau rouge pour moi . Cela me montre que l'erreur dans la construction ne sera pas prise au sérieux. Il existe une hypothèse selon laquelle un test floconneux n'est pas un vrai bogue, mais est "juste" floconneux, sans avoir besoin d'être pris en charge ni même débogué. Le test passera à nouveau plus tard de toute façon, n'est-ce pas ? Nan! Si un tel commit est fusionné, dans le pire des cas, nous aurons un nouveau test floconneux dans le produit.
Les causes
Ainsi, les tests floconneux sont problématiques. Que devons-nous faire à leur sujet? Eh bien, si nous connaissons le problème, nous pouvons concevoir une contre-stratégie.
Je rencontre souvent des causes dans la vie de tous les jours. Ils peuvent être trouvés dans les tests eux-mêmes . Les tests peuvent être rédigés de manière sous-optimale, contenir des hypothèses erronées ou contenir de mauvaises pratiques. Cependant, pas seulement cela. Les tests floconneux peuvent être une indication de quelque chose de bien pire.
Dans les sections suivantes, nous passerons en revue les plus courantes que j'ai rencontrées.
1. Causes côté test
Dans un monde idéal, l'état initial de votre application devrait être vierge et prévisible à 100 %. En réalité, vous ne savez jamais si l'identifiant que vous avez utilisé dans votre test sera toujours le même.
Examinons deux exemples d'un seul échec de ma part. L'erreur numéro un était d'utiliser un ID dans mes appareils de test :
{ "id": "f1d2554b0ce847cd82f3ac9bd1c0dfca", "name": "Variant product", }L'erreur numéro deux était de rechercher un sélecteur unique à utiliser dans un test d'interface utilisateur et de penser : "Ok, cet ID semble unique. Je vais l'utiliser.
<!-- This is a text field I took from a project I worked on --> <input type="text" />Cependant, si j'exécutais le test sur une autre installation ou, plus tard, sur plusieurs versions de CI, ces tests pourraient échouer. Notre application générerait à nouveau les identifiants, en les modifiant entre les versions. Ainsi, la première cause possible se trouve dans les identifiants codés en dur .
La deuxième cause peut provenir de données de démonstration générées de manière aléatoire (ou autre). Bien sûr, vous pensez peut-être que cette "défaut" est justifiée - après tout, la génération de données est aléatoire - mais pensez à déboguer ces données. Il peut être très difficile de voir si un bogue se trouve dans les tests eux-mêmes ou dans les données de démonstration.
Ensuite, il y a une cause côté test avec laquelle j'ai lutté à plusieurs reprises : les tests avec des dépendances croisées . Certains tests peuvent ne pas pouvoir s'exécuter indépendamment ou dans un ordre aléatoire, ce qui est problématique. De plus, les tests précédents pourraient interférer avec les suivants. Ces scénarios peuvent provoquer des tests floconneux en introduisant des effets secondaires.
Cependant, n'oubliez pas que les tests impliquent des hypothèses difficiles . Que se passe-t-il si vos hypothèses sont erronées au départ ? J'en ai souvent fait l'expérience, ma préférée étant les hypothèses erronées sur le temps.
Un exemple est l'utilisation de temps d'attente inexacts, en particulier dans les tests d'interface utilisateur - par exemple, en utilisant des temps d'attente fixes . La ligne suivante est tirée d'un test Nightwatch.js.
// Please never do that unless you have a very good reason! // Waits for 1 second browser.pause(1000);Une autre hypothèse erronée concerne le temps lui-même. J'ai découvert une fois qu'un test PHPUnit floconneux n'échouait que dans nos versions nocturnes. Après quelques débogages, j'ai trouvé que le décalage horaire entre hier et aujourd'hui était le coupable. Un autre bon exemple est celui des pannes dues aux fuseaux horaires .
Les fausses hypothèses ne s'arrêtent pas là. Nous pouvons également avoir de mauvaises hypothèses sur l' ordre des données . Imaginez une grille ou une liste contenant plusieurs entrées avec des informations, comme une liste de devises :
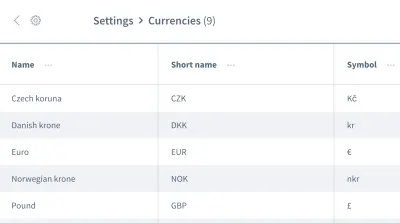
Nous souhaitons travailler avec les informations de la première entrée, la devise « couronne tchèque ». Pouvez-vous être sûr que votre application placera toujours cette donnée en première entrée à chaque exécution de votre test ? Se pourrait-il que l'« euro » ou une autre devise soit la première entrée à certaines occasions ?
Ne présumez pas que vos données arriveront dans l'ordre dans lequel vous en avez besoin. Semblable aux ID codés en dur, un ordre peut changer entre les versions, en fonction de la conception de l'application.
2. Causes liées à l'environnement
La prochaine catégorie de causes concerne tout ce qui n'est pas lié à vos tests. Plus précisément, nous parlons de l'environnement dans lequel les tests sont exécutés, des dépendances liées au CI et au docker en dehors de vos tests - toutes ces choses que vous pouvez à peine influencer, du moins dans votre rôle de testeur.
Une cause courante côté environnement est les fuites de ressources : il s'agit souvent d'une application sous charge, provoquant des temps de chargement variables ou un comportement inattendu. Les tests volumineux peuvent facilement provoquer des fuites et consommer beaucoup de mémoire. Un autre problème courant est le manque de nettoyage .
L'incompatibilité entre les dépendances me donne des cauchemars en particulier. Un cauchemar s'est produit lorsque je travaillais avec Nightwatch.js pour les tests d'interface utilisateur. Nightwatch.js utilise WebDriver, qui dépend bien sûr de Chrome. Lorsque Chrome a lancé une mise à jour, il y a eu un problème de compatibilité : Chrome, WebDriver et Nightwatch.js lui-même ne fonctionnaient plus ensemble, ce qui a entraîné l'échec de nos versions de temps en temps.
En parlant de dépendances : une mention honorable va à tous les problèmes de npm, tels que les autorisations manquantes ou l'arrêt de npm. J'ai vécu tout cela en observant CI.
En ce qui concerne les erreurs dans les tests d'interface utilisateur dues à des problèmes environnementaux, gardez à l'esprit que vous avez besoin de toute la pile d'applications pour qu'elles s'exécutent. Plus il y a de choses impliquées, plus il y a de risques d'erreur . Les tests JavaScript sont donc les tests les plus difficiles à stabiliser en développement web, car ils couvrent une grande quantité de code.
3. Causes côté produit
Enfin et surtout, nous devons vraiment faire attention à ce troisième domaine – un domaine avec de vrais bugs. Je parle des causes de la desquamation côté produit. L'un des exemples les plus connus est celui des conditions de concurrence dans une application. Lorsque cela se produit, le bogue doit être corrigé dans le produit, pas dans le test ! Essayer de corriger le test ou l'environnement n'aura aucune utilité dans ce cas.
Façons de lutter contre la desquamation
Nous avons identifié trois causes de flakiness. Nous pouvons construire notre contre-stratégie là-dessus ! Bien sûr, vous aurez déjà beaucoup gagné en gardant à l'esprit les trois causes lorsque vous rencontrerez des tests feuilletés. Vous saurez déjà ce qu'il faut rechercher et comment améliorer les tests. Cependant, en plus de cela, il existe certaines stratégies qui nous aideront à concevoir, écrire et déboguer des tests, et nous les examinerons ensemble dans les sections suivantes.
Concentrez-vous sur votre équipe
Votre équipe est sans doute le facteur le plus important . Dans un premier temps, admettez que vous avez un problème avec les tests floconneux. Obtenir l'engagement de toute l'équipe est crucial ! Ensuite, en équipe, vous devez décider comment traiter les tests floconneux.
Au cours des années où j'ai travaillé dans la technologie, j'ai découvert quatre stratégies utilisées par les équipes pour contrer la flakiness :

- Ne rien faire et accepter le résultat du test floconneux.
Bien sûr, cette stratégie n'est pas du tout une solution. Le test ne rapportera aucune valeur parce que vous ne pouvez plus lui faire confiance - même si vous acceptez la fragilité. Nous pouvons donc sauter celui-ci assez rapidement. - Recommencez le test jusqu'à ce qu'il réussisse.
Cette stratégie était courante au début de ma carrière, ce qui a entraîné la réponse que j'ai mentionnée plus tôt. Il y avait une certaine acceptation avec les tests répétés jusqu'à ce qu'ils réussissent. Cette stratégie ne nécessite pas de débogage, mais elle est paresseuse. En plus de masquer les symptômes du problème, cela ralentira encore plus votre suite de tests, ce qui rendra la solution non viable. Cependant, il peut y avoir quelques exceptions à cette règle, que j'expliquerai plus tard. - Supprimez et oubliez le test.
Celui-ci est explicite : supprimez simplement le test floconneux, afin qu'il ne perturbe plus votre suite de tests. Bien sûr, cela vous fera économiser de l'argent car vous n'aurez plus besoin de déboguer et de corriger le test. Mais cela se fait au détriment de la perte d'un peu de couverture de test et de la perte de correctifs de bogues potentiels. Le test existe pour une raison ! Ne tirez pas sur le messager en supprimant le test. - Mettre en quarantaine et réparer.
J'ai eu le plus de succès avec cette stratégie. Dans ce cas, nous sauterions temporairement le test et la suite de tests nous rappellerait constamment qu'un test a été sauté. Pour nous assurer que le correctif ne soit pas oublié, nous programmerions un ticket pour le prochain sprint. Les rappels de bot fonctionnent également bien. Une fois que le problème à l'origine de la flakiness a été résolu, nous intégrons (c'est-à-dire annulons) le test à nouveau. Malheureusement, nous perdrons temporairement la couverture, mais elle reviendra avec un correctif, donc cela ne prendra pas longtemps.
Ces stratégies nous aident à gérer les problèmes de test au niveau du workflow, et je ne suis pas le seul à les avoir rencontrés. Dans son article, Sam Saffron arrive à la même conclusion. Mais dans notre travail quotidien, ils nous aident dans une mesure limitée. Alors, comment procédons-nous lorsqu'une telle tâche se présente à nous ?
Gardez les tests isolés
Lors de la planification de vos cas de test et de votre structure, gardez toujours vos tests isolés des autres tests, afin qu'ils puissent être exécutés dans un ordre indépendant ou aléatoire. L'étape la plus importante consiste à restaurer une installation propre entre les tests . En outre, testez uniquement le flux de travail que vous souhaitez tester et créez des données fictives uniquement pour le test lui-même. Un autre avantage de ce raccourci est qu'il améliore les performances des tests . Si vous suivez ces points, aucun effet secondaire d'autres tests ou données restantes ne vous gênera.
L'exemple ci-dessous est issu des tests UI d'une plateforme e-commerce, et il traite de la connexion du client dans la vitrine de la boutique. (Le test est écrit en JavaScript, en utilisant le framework Cypress.)
// File: customer-login.spec.js let customer = {}; beforeEach(() => { // Set application to clean state cy.setInitialState() .then(() => { // Create test data for the test specifically return cy.setFixture('customer'); }) }): La première étape consiste à réinitialiser l'application sur une nouvelle installation. Il s'agit de la première étape du hook de cycle de vie beforeEach pour s'assurer que la réinitialisation est exécutée à chaque occasion. Ensuite, les données de test sont créées spécifiquement pour le test - pour ce cas de test, un client serait créé via une commande personnalisée. Par la suite, nous pouvons commencer par le seul workflow que nous souhaitons tester : le login du client.
Optimiser davantage la structure de test
Nous pouvons faire quelques autres petits ajustements pour rendre notre structure de test plus stable. La première est assez simple : commencez par des tests plus petits. Comme dit précédemment, plus vous en faites dans un test, plus vous pouvez mal tourner. Gardez les tests aussi simples que possible et évitez beaucoup de logique dans chacun d'eux.
Lorsqu'il s'agit de ne pas supposer un ordre des données (par exemple, lorsqu'il s'agit de l' ordre des entrées dans une liste dans les tests d'interface utilisateur), nous pouvons concevoir un test pour qu'il fonctionne indépendamment de tout ordre. Pour reprendre l'exemple de la grille contenant des informations, nous n'utiliserions pas de pseudo-sélecteurs ou d'autres CSS fortement dépendants de l'ordre. Au lieu du sélecteur nth-child(3) , nous pourrions utiliser du texte ou d'autres éléments pour lesquels l'ordre n'a pas d'importance. Par exemple, nous pourrions utiliser une assertion telle que "Trouvez-moi l'élément avec cette chaîne de texte dans ce tableau".
Attendez! Les tentatives de test sont parfois OK ?
Réessayer les tests est un sujet controversé, et à juste titre. Je considère toujours cela comme un anti-modèle si le test est retenté aveuglément jusqu'à ce qu'il réussisse. Cependant, il existe une exception importante : lorsque vous ne pouvez pas contrôler les erreurs, réessayer peut être un dernier recours (par exemple, pour exclure les erreurs des dépendances externes). Dans ce cas, nous ne pouvons pas influencer la source de l'erreur. Cependant, soyez très prudent lorsque vous faites cela : ne devenez pas aveugle à la flakiness lorsque vous réessayez un test et utilisez des notifications pour vous rappeler quand un test est ignoré.
L'exemple suivant est celui que j'ai utilisé dans notre CI avec GitLab. D'autres environnements peuvent avoir une syntaxe différente pour effectuer des tentatives, mais cela devrait vous donner un avant-goût :
test: script: rspec retry: max: 2 when: runner_system_failureDans cet exemple, nous configurons le nombre de tentatives à effectuer si la tâche échoue. Ce qui est intéressant, c'est la possibilité de réessayer s'il y a une erreur dans le système d'exécution (par exemple, la configuration du travail a échoué). Nous choisissons de réessayer notre travail uniquement si quelque chose dans la configuration du menu fixe échoue.
Notez que cela réessayera tout le travail lorsqu'il sera déclenché. Si vous souhaitez réessayer uniquement le test défectueux, vous devrez rechercher une fonctionnalité dans votre infrastructure de test pour le prendre en charge. Vous trouverez ci-dessous un exemple de Cypress, qui prend en charge la nouvelle tentative d'un seul test depuis la version 5 :
{ "retries": { // Configure retry attempts for 'cypress run` "runMode": 2, // Configure retry attempts for 'cypress open` "openMode": 2, } } Vous pouvez activer les nouvelles tentatives de test dans le fichier de configuration de Cypress, cypress.json . Là, vous pouvez définir les nouvelles tentatives dans le testeur et le mode sans tête.
Utilisation des temps d'attente dynamiques
Ce point est important pour toutes sortes de tests, mais surtout pour les tests d'interface utilisateur. Je ne saurais trop insister là-dessus : n'utilisez jamais de temps d'attente fixes - du moins pas sans une très bonne raison. Si vous le faites, considérez les résultats possibles. Dans le meilleur des cas, vous choisirez des temps d'attente trop longs, rendant la suite de tests plus lente que nécessaire. Dans le pire des cas, vous n'attendrez pas assez longtemps, donc le test ne se poursuivra pas car l'application n'est pas encore prête, ce qui entraînera l'échec du test de manière irrégulière. D'après mon expérience, c'est la cause la plus fréquente de tests floconneux.
Utilisez plutôt des temps d'attente dynamiques. Il existe de nombreuses façons de le faire, mais Cypress les gère particulièrement bien.
Toutes les commandes Cypress possèdent une méthode d'attente implicite : elles vérifient déjà si l'élément auquel la commande est appliquée existe dans le DOM pendant la durée spécifiée - pointant vers la possibilité de réessayer de Cypress. Cependant, il ne vérifie que l'existence , et rien de plus. Je recommande donc d'aller plus loin - d'attendre tout changement dans l'interface utilisateur de votre site Web ou de votre application qu'un véritable utilisateur verrait également, comme des changements dans l'interface utilisateur elle-même ou dans l'animation.
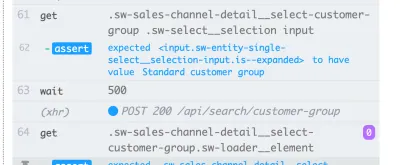
Cet exemple utilise un temps d'attente explicite sur l'élément avec le sélecteur .offcanvas . Le test ne se poursuivra que si l'élément est visible jusqu'au délai spécifié, que vous pouvez configurer :
// Wait for changes in UI (until element is visible) cy.get(#element).should('be.visible'); Une autre possibilité intéressante dans Cypress pour l'attente dynamique est ses fonctionnalités réseau. Oui, nous pouvons attendre que les demandes se produisent et les résultats de leurs réponses. J'utilise ce genre d'attente particulièrement souvent. Dans l'exemple ci-dessous, nous définissons la requête à attendre, utilisons une commande wait pour attendre la réponse et affirmons son code d'état :
// File: checkout-info.spec.js // Define request to wait for cy.intercept({ url: '/widgets/customer/info', method: 'GET' }).as('checkoutAvailable'); // Imagine other test steps here... // Assert the response's status code of the request cy.wait('@checkoutAvailable').its('response.statusCode') .should('equal', 200);De cette façon, nous sommes en mesure d'attendre exactement le temps nécessaire à notre application, ce qui rend les tests plus stables et moins sujets aux flocons dus à des fuites de ressources ou à d'autres problèmes environnementaux.
Débogage des tests floconneux
Nous savons maintenant comment éviter les tests floconneux dès la conception. Mais que se passe-t-il si vous avez déjà affaire à un test floconneux ? Comment pouvez-vous vous en débarrasser?
Lorsque j'étais en train de déboguer, mettre le test défectueux dans une boucle m'a beaucoup aidé à découvrir les irrégularités. Par exemple, si vous exécutez un test 50 fois et qu'il réussit à chaque fois, vous pouvez être plus certain que le test est stable - peut-être que votre solution a fonctionné. Sinon, vous pouvez au moins avoir plus d'informations sur le test floconneux.
// Use in build Lodash to repeat the test 100 times Cypress._.times(100, (k) => { it(`typing hello ${k + 1} / 100`, () => { // Write your test steps in here }) }) Obtenir plus d'informations sur ce test feuilleté est particulièrement difficile en CI. Pour obtenir de l'aide, voyez si votre infrastructure de test est en mesure d'obtenir plus d'informations sur votre build. En ce qui concerne les tests front-end, vous pouvez généralement utiliser un console.log dans vos tests :
it('should be a Vue.JS component', () => { // Mock component by a method defined before const wrapper = createWrapper(); // Print out the component's html console.log(wrapper.html()); expect(wrapper.isVueInstance()).toBe(true); }) Cet exemple est tiré d'un test unitaire Jest dans lequel j'utilise un console.log pour obtenir la sortie du code HTML du composant testé. Si vous utilisez cette possibilité de journalisation dans le test runner de Cypress, vous pouvez même inspecter la sortie dans les outils de développement de votre choix. De plus, en ce qui concerne Cypress dans CI, vous pouvez inspecter cette sortie dans le journal de votre CI en utilisant un plugin.
Examinez toujours les fonctionnalités de votre infrastructure de test pour obtenir de l'aide pour la journalisation. Dans les tests d'interface utilisateur, la plupart des frameworks fournissent des fonctionnalités de capture d'écran - au moins en cas d'échec, une capture d'écran sera prise automatiquement. Certains frameworks fournissent même un enregistrement vidéo , ce qui peut être d'une grande aide pour avoir un aperçu de ce qui se passe dans votre test.
Combattez les cauchemars de Flakiness !
Il est important de rechercher en permanence les tests erronés, que ce soit en les prévenant en premier lieu ou en les déboguant et en les corrigeant dès qu'ils se produisent. Nous devons les prendre au sérieux, car ils peuvent faire allusion à des problèmes dans votre application.
Repérer les drapeaux rouges
Prévenir les tests floconneux en premier lieu est bien sûr préférable. Pour récapituler rapidement, voici quelques drapeaux rouges :
- Le test est grand et contient beaucoup de logique.
- Le test couvre beaucoup de code (par exemple, dans les tests d'interface utilisateur).
- Le test utilise des temps d'attente fixes.
- Le test dépend des tests précédents.
- Le test affirme des données qui ne sont pas prévisibles à 100 %, telles que l'utilisation d'identifiants, d'heures ou de données de démonstration, en particulier celles générées de manière aléatoire.
Si vous gardez à l'esprit les conseils et les stratégies de cet article, vous pouvez empêcher les tests aléatoires avant qu'ils ne se produisent. Et s'ils arrivent, vous saurez comment les déboguer et les réparer.
Ces étapes m'ont vraiment aidé à reprendre confiance dans notre suite de tests. Notre suite de tests semble stable pour le moment. Il pourrait y avoir des problèmes à l'avenir - rien n'est parfait à 100%. Ces connaissances et ces stratégies m'aideront à y faire face. Ainsi, je gagnerai en confiance dans ma capacité à lutter contre ces cauchemars de test floconneux .
J'espère avoir pu soulager au moins une partie de votre douleur et de vos inquiétudes concernant la desquamation !
Lectures complémentaires
Si vous voulez en savoir plus sur ce sujet, voici quelques ressources et articles intéressants, qui m'ont beaucoup aidé :
- Articles sur "flake", Cypress.io
- "Réessayer vos tests est en fait une bonne chose (si votre approche est correcte)", Filip Hric, Cypress.io
- " Test Flakiness: Méthodes d'identification et de traitement des tests floconneux ", Jason Palmer, Spotify R&D Engineering
- "Tests floconneux chez Google et comment nous les atténuons", John Micco, Google Testing Blog