
Chargement d'image plus rapide avec des aperçus d'image intégrés
Publié: 2022-03-10L'aperçu d'image de faible qualité (LQIP) et la variante SQIP basée sur SVG sont les deux techniques prédominantes pour le chargement d'image paresseux. Ce que les deux ont en commun, c'est que vous générez d'abord une image d'aperçu de faible qualité. Celle-ci sera affichée floue et remplacée plus tard par l'image d'origine. Et si vous pouviez présenter une image d'aperçu au visiteur du site Web sans avoir à charger de données supplémentaires ?
Les fichiers JPEG, pour lesquels le chargement différé est principalement utilisé, ont la possibilité, selon la spécification, de stocker les données qu'ils contiennent de manière à afficher d'abord le contenu grossier puis le contenu détaillé de l'image. Au lieu d'avoir l'image construite de haut en bas lors du chargement (mode de base), une image floue peut être affichée très rapidement, qui devient progressivement de plus en plus nette (mode progressif).


En plus de la meilleure expérience utilisateur fournie par l'apparence qui s'affiche plus rapidement, les JPEG progressifs sont généralement aussi plus petits que leurs homologues codés de base. Pour les fichiers de plus de 10 Ko, il y a une probabilité de 94 % d'avoir une image plus petite lors de l'utilisation du mode progressif selon Stoyan Stefanov de l'équipe de développement de Yahoo.
Si votre site Web se compose de nombreux JPEG, vous remarquerez que même les JPEG progressifs se chargent les uns après les autres. En effet, les navigateurs modernes n'autorisent que six connexions simultanées à un domaine. Les JPEG progressifs seuls ne sont donc pas la solution pour donner à l'utilisateur l'impression la plus rapide possible de la page. Dans le pire des cas, le navigateur chargera complètement une image avant de commencer à charger la suivante.
L'idée présentée ici est maintenant de ne charger qu'un certain nombre d'octets d'un JPEG progressif à partir du serveur afin que vous puissiez rapidement vous faire une idée du contenu de l'image. Plus tard, à un moment défini par nous (par exemple, lorsque toutes les images d'aperçu dans la fenêtre actuelle ont été chargées), le reste de l'image doit être chargé sans demander à nouveau la partie déjà demandée pour l'aperçu.

Malheureusement, vous ne pouvez pas indiquer à une balise img dans un attribut quelle quantité d'image doit être chargée à quel moment. Avec Ajax, cependant, cela est possible, à condition que le serveur fournissant l'image prenne en charge les requêtes de plage HTTP.
À l'aide de requêtes de plage HTTP, un client peut informer le serveur dans un en-tête de requête HTTP quels octets du fichier demandé doivent être contenus dans la réponse HTTP. Cette fonctionnalité, prise en charge par chacun des serveurs les plus importants (Apache, IIS, nginx), est principalement utilisée pour la lecture vidéo. Si un utilisateur saute à la fin d'une vidéo, il ne serait pas très efficace de charger la vidéo complète avant que l'utilisateur ne puisse enfin voir la partie souhaitée. Par conséquent, seules les données vidéo autour de l'heure demandée par l'utilisateur sont demandées par le serveur, afin que l'utilisateur puisse regarder la vidéo le plus rapidement possible.
Nous sommes maintenant confrontés aux trois défis suivants :
- Création du JPEG progressif
- Déterminer le décalage d'octet jusqu'auquel la première demande de plage HTTP doit charger l'image d'aperçu
- Création du code JavaScript frontal
1. Création du JPEG progressif
Un JPEG progressif se compose de plusieurs segments dits de balayage, dont chacun contient une partie de l'image finale. Le premier scan ne montre l'image que très grossièrement, tandis que ceux qui suivent plus tard dans le fichier ajoutent des informations de plus en plus détaillées aux données déjà chargées et forment finalement l'apparence finale.
L'aspect exact des numérisations individuelles est déterminé par le programme qui génère les JPEG. Dans les programmes en ligne de commande comme cjpeg du projet mozjpeg, vous pouvez même définir quelles données contiennent ces analyses. Cependant, cela nécessite des connaissances plus approfondies, ce qui dépasserait le cadre de cet article. Pour cela, je me réfère à mon article "Enfin Comprendre JPG", qui enseigne les bases de la compression JPEG. Les paramètres exacts qui doivent être transmis au programme dans un script d'analyse sont expliqués dans le fichier wizard.txt du projet mozjpeg. A mon avis, les paramètres du script de scan (sept scans) utilisés par mozjpeg par défaut sont un bon compromis entre structure progressive rapide et taille de fichier et peuvent donc être adoptés.
Pour transformer notre JPEG initial en JPEG progressif, nous utilisons jpegtran du projet mozjpeg. Il s'agit d'un outil permettant d'apporter des modifications sans perte à un JPEG existant. Des versions précompilées pour Windows et Linux sont disponibles ici : https://mozjpeg.codelove.de/binaries.html. Si vous préférez jouer la sécurité pour des raisons de sécurité, il est préférable de les construire vous-même.
Depuis la ligne de commande, nous créons maintenant notre JPEG progressif :
$ jpegtran input.jpg > progressive.jpgLe fait que nous voulions construire un JPEG progressif est supposé par jpegtran et n'a pas besoin d'être explicitement spécifié. Les données d'image ne seront en aucun cas modifiées. Seule la disposition des données d'image dans le fichier est modifiée.
Les métadonnées sans rapport avec l'apparence de l'image (telles que les données Exif, IPTC ou XMP) devraient idéalement être supprimées du JPEG puisque les segments correspondants ne peuvent être lus par les décodeurs de métadonnées que s'ils précèdent le contenu de l'image. Comme nous ne pouvons pas les déplacer derrière les données d'image dans le fichier pour cette raison, ils seraient déjà livrés avec l'image d'aperçu et agrandiraient la première demande en conséquence. Avec le programme en ligne de exiftool , vous pouvez facilement supprimer ces métadonnées :
$ exiftool -all= progressive.jpgSi vous ne souhaitez pas utiliser d'outil en ligne de commande, vous pouvez également utiliser le service de compression en ligne compress-or-die.com pour générer un JPEG progressif sans métadonnées.
2. Déterminer le décalage d'octets jusqu'auquel la première demande de plage HTTP doit charger l'image d'aperçu
Un fichier JPEG est divisé en différents segments, chacun contenant différents composants (données d'image, métadonnées telles que IPTC, Exif et XMP, profils de couleurs intégrés, tables de quantification, etc.). Chacun de ces segments commence par un marqueur introduit par un octet hexadécimal FF . Ceci est suivi d'un octet indiquant le type de segment. Par exemple, D8 complète le marqueur jusqu'au marqueur SOI FF D8 (Start Of Image), par lequel commence chaque fichier JPEG.
Chaque début de scan est marqué par le marqueur SOS (Start Of Scan, hexadécimal FF DA ). Étant donné que les données derrière le marqueur SOS sont codées entropie (les JPEG utilisent le codage Huffman), il existe un autre segment avec les tables Huffman (DHT, hexadécimal FF C4 ) requis pour le décodage avant le segment SOS. La zone qui nous intéresse dans un fichier JPEG progressif consiste donc en une alternance de tables de Huffman/segments de données de numérisation. Ainsi, si nous voulons afficher le premier scan très grossier d'une image, nous devons demander tous les octets jusqu'à la deuxième occurrence d'un segment DHT (hexadécimal FF C4 ) au serveur.
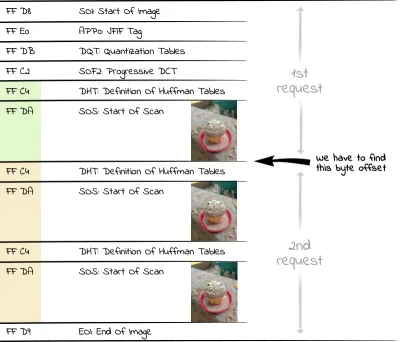
En PHP, nous pouvons utiliser le code suivant pour lire le nombre d'octets requis pour tous les scans dans un tableau :
<?php $img = "progressive.jpg"; $jpgdata = file_get_contents($img); $positions = []; $offset = 0; while ($pos = strpos($jpgdata, "\xFF\xC4", $offset)) { $positions[] = $pos+2; $offset = $pos+2; }Nous devons ajouter la valeur de deux à la position trouvée car le navigateur n'affiche que la dernière ligne de l'image d'aperçu lorsqu'il rencontre un nouveau marqueur (qui se compose de deux octets comme nous venons de le mentionner).
Puisque nous nous intéressons à la première image de prévisualisation dans cet exemple, nous trouvons la position correcte dans $positions[1] jusqu'à laquelle nous devons demander le fichier via HTTP Range Request. Pour demander une image avec une meilleure résolution, nous pourrions utiliser une position ultérieure dans le tableau, par exemple $positions[3] .

3. Création du code JavaScript frontal
Tout d'abord, nous définissons une balise img , à laquelle nous donnons la position d'octet qui vient d'être évaluée :
<img data-src="progressive.jpg" data-bytes="<?= $positions[1] ?>"> Comme c'est souvent le cas avec les bibliothèques de chargement différé, nous ne définissons pas directement l'attribut src afin que le navigateur ne commence pas immédiatement à demander l'image au serveur lors de l'analyse du code HTML.
Avec le code JavaScript suivant, nous chargeons maintenant l'image d'aperçu :
var $img = document.querySelector("img[data-src]"); var URL = window.URL || window.webkitURL; var xhr = new XMLHttpRequest(); xhr.onload = function(){ if (this.status === 206){ $img.src_part = this.response; $img.src = URL.createObjectURL(this.response); } } xhr.open('GET', $img.getAttribute('data-src')); xhr.setRequestHeader("Range", "bytes=0-" + $img.getAttribute('data-bytes')); xhr.responseType = 'blob'; xhr.send(); Ce code crée une requête Ajax qui indique au serveur dans un en-tête de plage HTTP de renvoyer le fichier du début à la position spécifiée en data-bytes ... et pas plus. Si le serveur comprend les requêtes de plage HTTP, il renvoie les données d'image binaires dans une réponse HTTP-206 (HTTP 206 = contenu partiel) sous la forme d'un blob, à partir duquel nous pouvons générer une URL interne au navigateur à l'aide createObjectURL . Nous utilisons cette URL comme src pour notre balise img . Ainsi, nous avons chargé notre image de prévisualisation.
Nous stockons le blob en plus dans l'objet DOM dans la propriété src_part , car nous aurons besoin de ces données immédiatement.
Dans l'onglet réseau de la console développeur, vous pouvez vérifier que nous n'avons pas chargé l'image complète, mais seulement une petite partie. De plus, le chargement de l'URL du blob doit être affiché avec une taille de 0 octet.
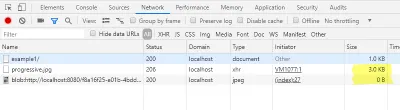
Comme nous chargeons déjà l'en-tête JPEG du fichier d'origine, l'image d'aperçu a la bonne taille. Ainsi, selon l'application, nous pouvons omettre la hauteur et la largeur de la balise img .
Alternative : charger l'image d'aperçu en ligne
Pour des raisons de performances, il est également possible de transférer les données de l'image d'aperçu sous forme d'URI de données directement dans le code source HTML. Cela nous évite les frais généraux liés au transfert des en-têtes HTTP, mais l'encodage base64 agrandit les données d'image d'un tiers. Ceci est relativisé si vous fournissez le code HTML avec un encodage de contenu comme gzip ou brotli , mais vous devez toujours utiliser des URI de données pour les petites images d'aperçu.
Beaucoup plus important est le fait que les images de prévisualisation sont disponibles immédiatement et qu'il n'y a pas de retard notable pour l'utilisateur lors de la construction de la page.
Tout d'abord, nous devons créer l'URI de données, que nous utilisons ensuite dans la balise img en tant que src . Pour cela, nous créons l'URI de données via PHP, ce code étant basé sur le code qui vient d'être créé, qui détermine les décalages d'octets des marqueurs SOS :
<?php … $fp = fopen($img, 'r'); $data_uri = 'data:image/jpeg;base64,'. base64_encode(fread($fp, $positions[1])); fclose($fp); L'URI de données créée est maintenant directement insérée dans la balise `img` en tant que src :
<img src="<?= $data_uri ?>" data-src="progressive.jpg" alt="">Bien entendu, le code JavaScript doit également être adapté :
<script> var $img = document.querySelector("img[data-src]"); var binary = atob($img.src.slice(23)); var n = binary.length; var view = new Uint8Array(n); while(n--) { view[n] = binary.charCodeAt(n); } $img.src_part = new Blob([view], { type: 'image/jpeg' }); $img.setAttribute('data-bytes', $img.src_part.size - 1); </script> Au lieu de demander les données via une requête Ajax, où nous recevrons immédiatement un blob, dans ce cas, nous devons créer le blob nous-mêmes à partir de l'URI de données. Pour ce faire, nous libérons le data-URI de la partie qui ne contient pas de données d'image : data:image/jpeg;base64 . Nous décodons les données codées en base64 restantes avec la commande atob . Afin de créer un blob à partir des données de chaîne désormais binaires, nous devons transférer les données dans un tableau Uint8, ce qui garantit que les données ne sont pas traitées comme un texte encodé en UTF-8. À partir de ce tableau, nous pouvons maintenant créer un blob binaire avec les données d'image de l'image de prévisualisation.
Afin que nous n'ayons pas à adapter le code suivant pour cette version en ligne, nous ajoutons l'attribut data-bytes sur la balise img , qui dans l'exemple précédent contient le décalage d'octet à partir duquel la deuxième partie de l'image doit être chargée .
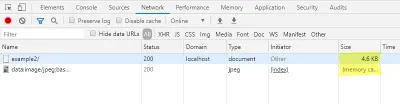
Dans l'onglet réseau de la console développeur, vous pouvez également vérifier ici que le chargement de l'image de prévisualisation ne génère pas de requête supplémentaire, alors que la taille du fichier de la page HTML a augmenté.
Chargement de l'image finale
Dans un second temps nous chargeons le reste du fichier image après deux secondes à titre d'exemple :
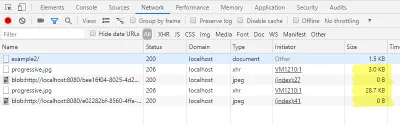
setTimeout(function(){ var xhr = new XMLHttpRequest(); xhr.onload = function(){ if (this.status === 206){ var blob = new Blob([$img.src_part, this.response], { type: 'image/jpeg'} ); $img.src = URL.createObjectURL(blob); } } xhr.open('GET', $img.getAttribute('data-src')); xhr.setRequestHeader("Range", "bytes="+ (parseInt($img.getAttribute('data-bytes'), 10)+1) +'-'); xhr.responseType = 'blob'; xhr.send(); }, 2000); Dans l'en-tête Range, nous spécifions cette fois que nous voulons demander l'image de la position finale de l'image d'aperçu à la fin du fichier. La réponse à la première requête est stockée dans la propriété src_part de l'objet DOM. Nous utilisons les réponses des deux requêtes pour créer un nouveau blob par new Blob() , qui contient les données de l'image entière. L'URL blob générée à partir de ceci est à nouveau utilisée comme src de l'objet DOM. Maintenant, l'image est complètement chargée.
De plus, nous pouvons maintenant vérifier à nouveau les tailles chargées dans l'onglet réseau de la console du développeur.
Prototype
À l'URL suivante, j'ai fourni un prototype où vous pouvez expérimenter différents paramètres : https://embedded-image-preview.cerdmann.com/prototype/
Le référentiel GitHub pour le prototype peut être trouvé ici : https://github.com/McSodbrenner/embedded-image-preview
Considérations à la fin
En utilisant la technologie Embedded Image Preview (EIP) présentée ici, nous pouvons charger des images d'aperçu qualitativement différentes à partir de JPEG progressifs à l'aide d'Ajax et de requêtes de plage HTTP. Les données de ces images d'aperçu ne sont pas supprimées mais réutilisées pour afficher l'intégralité de l'image.
De plus, aucune image d'aperçu ne doit être créée. Côté serveur, seul le décalage d'octet auquel l'image d'aperçu se termine doit être déterminé et enregistré. Dans un système CMS, il devrait être possible d'enregistrer ce numéro en tant qu'attribut sur une image et d'en tenir compte lors de sa sortie dans la balise img . Même un flux de travail serait concevable, qui complète le nom de fichier de l'image par le décalage, par exemple progressive-8343.jpg , afin de ne pas avoir à enregistrer le décalage en dehors du fichier image. Ce décalage pourrait être extrait par le code JavaScript.
Étant donné que les données d'image d'aperçu sont réutilisées, cette technique pourrait constituer une meilleure alternative à l'approche habituelle consistant à charger une image d'aperçu, puis un WebP (et à fournir une solution de repli JPEG pour les navigateurs ne prenant pas en charge WebP). L'image d'aperçu détruit souvent les avantages de stockage du WebP, qui ne prend pas en charge le mode progressif.
Actuellement, les images de prévisualisation dans LQIP normal sont de qualité inférieure, car on suppose que le chargement des données de prévisualisation nécessite une bande passante supplémentaire. Comme Robin Osborne l'a déjà précisé dans un article de blog en 2018, cela n'a pas beaucoup de sens de montrer des espaces réservés qui ne vous donnent pas une idée de l'image finale. En utilisant la technique suggérée ici, nous pouvons montrer un peu plus de l'image finale en tant qu'image d'aperçu sans hésitation en présentant à l'utilisateur un scan ultérieur du JPEG progressif.
En cas de connexion réseau faible de l'utilisateur, il peut être judicieux, selon l'application, de ne pas charger tout le JPEG, mais par exemple d'omettre les deux derniers scans. Cela produit un JPEG beaucoup plus petit avec une qualité légèrement réduite. L'utilisateur nous en remerciera, et nous n'avons pas à stocker un fichier supplémentaire sur le serveur.
Maintenant, je vous souhaite beaucoup de plaisir à essayer le prototype et j'attends vos commentaires avec impatience.