
Détection de fausses nouvelles dans l'apprentissage automatique [expliqué avec un exemple de codage]
Publié: 2021-02-08Les fausses nouvelles sont l'un des plus gros problèmes de l'ère actuelle d'Internet et des médias sociaux. Bien que ce soit une bénédiction que les nouvelles circulent d'un coin du monde à l'autre en quelques heures, il est également douloureux de voir de nombreuses personnes et groupes répandre de fausses nouvelles.
Les techniques d'apprentissage automatique utilisant le traitement du langage naturel et l'apprentissage en profondeur peuvent être utilisées pour résoudre ce problème dans une certaine mesure. Dans ce didacticiel, nous allons créer un modèle de détection de fausses nouvelles à l'aide de l'apprentissage automatique.
À la fin de cet article, vous saurez ce qui suit :
- Gestion des données textuelles
- Techniques de traitement PNL
- Vectorisation de comptage & TF-IDF
- Faire des prédictions et classer les textes d'actualité
Rejoignez le cours AI & ML en ligne des meilleures universités du monde - Masters, Executive Post Graduate Programs et Advanced Certificate Program in ML & AI pour accélérer votre carrière.
Table des matières
Données et problème
Nous utiliserons les données du défi Kaggle Fake News pour créer un classificateur. L'ensemble de données se compose de 4 caractéristiques et d'une cible binaire. Les 4 fonctionnalités sont les suivantes :
- id : identifiant unique pour un article de presse
- title : le titre d'un article d'actualité
- auteur : auteur de l'article de presse
- text : le texte de l'article ; pourrait être incomplet
Et la cible est "label" qui contient des valeurs binaires 0s et 1s. Où 0 signifie qu'il s'agit d'une source d'informations fiable, ou en d'autres termes, Not Fake. 1 signifie qu'il s'agit d'une information potentiellement fausse et non fiable. L'ensemble de données que nous avons consistait en 20800 instances. Plongeons dedans.

Prétraitement et nettoyage des données
| importer des pandas en tant que pd df=pd.read_csv( 'fake-news/train.csv' ) df.head() |
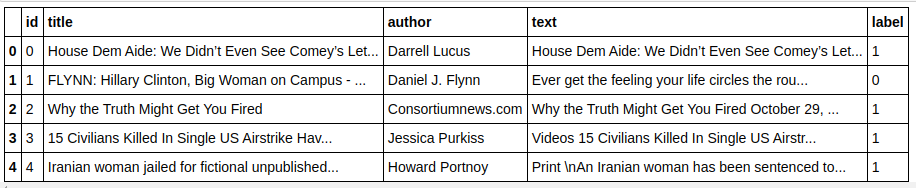
| X=df.drop( 'label' ,axis= 1 ) # Caractéristiques y=df[ 'étiquette' ] # Cible |
Nous devons supprimer les instances avec des données manquantes maintenant.
| df=df.dropna() |
![]()
Comme nous pouvons le voir, il a supprimé toutes les instances avec des données manquantes.
| messages=df.copy() messages.reset_index(inplace= Vrai ) messages.head( 10 ) |
Jetons un coup d'œil aux données une fois.
| messages['texte'][6] |

Comme nous pouvons le voir, il est nécessaire de suivre les étapes suivantes :
- Suppression des mots vides : il y a beaucoup de mots qui n'ajoutent aucune valeur à un texte, quelles que soient les données. Par exemple, "je", "un", "suis", etc. Ces mots n'ont aucune valeur informative et peuvent donc être supprimés pour réduire la taille de notre corpus afin que nous puissions nous concentrer uniquement sur les mots/tokens qui ont une valeur réelle .
- Stemming des mots: Stemming et Lemmatization sont les techniques pour réduire les mots à leurs tiges ou racines. Le principal avantage de cette étape est de réduire la taille du vocabulaire. Par exemple, des mots comme Play, Playing, Played seront réduits à "Play". La radicalisation tronque simplement les mots au mot le plus court et ne prend pas en considération l'aspect grammatical du texte. La lemmatisation, d'autre part, prend également en compte la grammaire et produit donc de bien meilleurs résultats. Cependant, la lemmatisation est généralement plus lente que la radicalisation car elle doit se référer au dictionnaire et prendre en compte l'aspect grammatical.
- Tout supprimer sauf les valeurs alphabétiques : les valeurs non alphabétiques ne sont pas très utiles ici, elles peuvent donc être supprimées. Cependant, vous pouvez explorer davantage pour voir si la présence de données numériques ou d'autres types de données a un impact sur la cible.
- Minuscules des mots : Minuscules des mots pour réduire le vocabulaire.
- Tokéniser les phrases : générer des jetons à partir de phrases.
| à partir de sklearn.feature_extraction.text importer CountVectorizer, TfidfVectorizer, HashingVectorizer à partir de nltk.corpus importer des mots vides depuis nltk.stem.porter importer PorterStemmer importer re ps = PorterStemmer() corpus = [] for i in range(0, len(messages)): review = re.sub('[^a-zA-Z]', ' ', messages['text'][i]) review = review.lower() review = review.split() review = [ps.stem(word) for word in review if not word in stopwords.words('english')] review = ' '.join(review) corpus.append(révision) |
Regardons maintenant notre corpus.
| corpus[ 3 ] |
![]()
Comme nous pouvons le voir, les mots sont maintenant issus des mots racines.
Vectoriseur TF-IDF
Maintenant, nous devons vectoriser les mots en données numériques, ce qui est également appelé vectorisation. Le moyen le plus simple de vectoriser est d'utiliser le sac de mots. Mais Bag of Words crée une matrice clairsemée et nécessite donc beaucoup de mémoire de traitement. De plus, BoW ne tient pas compte de la fréquence des mots ce qui en fait un mauvais algorithme.
TF-IDF (Term Frequency - Inverse Document Frequency) est une autre façon de vectoriser les mots qui prend en compte les fréquences des mots. Par exemple, des mots courants tels que "nous", "notre", "le" sont présents dans chaque document/instance, la valeur BoW sera donc trop élevée et donc trompeuse. Cela conduira à un mauvais modèle. TF-IDF est la multiplication de la fréquence du terme et de la fréquence inverse du document.
La fréquence de terme prend en compte la fréquence des mots dans un document et la fréquence de document inverse prend en compte les mots présents dans l'ensemble du corpus. Les mots qui sont présents sur l'ensemble du corpus ont une importance réduite car la valeur IDF est beaucoup plus faible. Les mots présents spécifiquement dans un document ont une valeur IDF élevée, ce qui rend la valeur TF-IDF totale élevée.
| ## TFi df Vectoriseur à partir de sklearn.feature_extraction.text importer TfidfVectorizer tfidf_v = TfidfVectorizer(max_features= 5000 ,ngram_range=( 1 , 3 )) X=tfidf_v.fit_transform(corpus).toarray() y=messages[ 'label' ] |
Dans le code ci-dessus, nous importons le vecteur TF-IDF du module d'extraction de caractéristiques de Sklearn. Nous faisons son objet en passant max_features comme 5000 et ngram_range comme (1,3). Le paramètre max_features définit le nombre maximum de vecteurs de caractéristiques que nous voulons créer et le paramètre ngram_range définit les combinaisons ngram que nous voulons inclure. Dans notre cas, nous obtiendrons 3 combinaisons de 1 mot, 2 mots et 3 mots. Jetons un coup d'œil à certaines des fonctionnalités créées.

| tfidf_v.get_feature_names()[: 20 ] |

Comme nous pouvons le voir, il existe plusieurs types de combinaisons formées. Il existe des noms de fonctionnalités avec 1 jeton, 2 jetons et également avec 3 jetons.
Créer une trame de données
| ## Diviser l'ensemble de données en Train et Test depuis sklearn.model_selection importer train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.33 , random_state= 0 ) count_df = pd.DataFrame(X_train, colonnes=tfidf_v.get_feature_names()) count_df.head() |
Nous divisons l'ensemble de données en train et en test afin de pouvoir tester les performances du modèle sur des données invisibles. Nous créons ensuite un nouveau Dataframe qui contient les nouveaux vecteurs de caractéristiques.
Modélisation et réglage
Algorithme multinomialNB
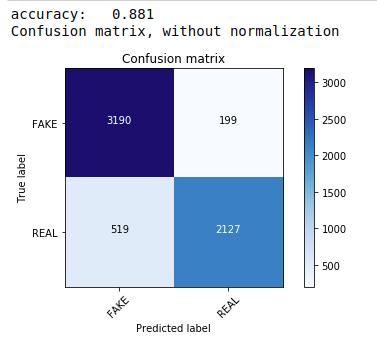
Tout d'abord, nous utilisons le théorème multinomial naïf de Bayes qui est l'algorithme le plus courant et le plus simple préféré pour la classification des données textuelles. Nous nous adaptons aux données d'entraînement et prévoyons sur les données de test. Plus tard, nous calculons et traçons la matrice de confusion et obtenons une précision de 88,1 %.
| de sklearn.naive_bayes importer MultinomialNB à partir des métriques d' importation sklearn importer numpy en tant que np importer des itertools à partir de sklearn.metrics importer plot_confusion_matrix classifieur=MultinomialNB() classifier.fit(X_train, y_train) pred = classifier.predict(X_test) score = metrics.accuracy_score(y_test, pred) print( "précision : %0.3f" % score) cm = metrics.confusion_matrix(y_test, pred) plot_confusion_matrix(cm, classes=[ 'FAKE' , 'REAL' ]) |
Classificateur multinomial avec réglage d'hyperparamètres
MultinomialNB a un paramètre alpha qui peut être ajusté davantage. Par conséquent, nous exécutons une boucle pour essayer plusieurs classificateurs MultinomialNB avec différentes valeurs alpha et vérifier leurs scores de précision. Et nous vérifions si le score actuel est supérieur au score précédent. Si c'est le cas, nous définissons le classificateur comme le classificateur actuel.
| score_précédent= 0 pour alpha dans np.arange( 0 , 1 , 0.1 ): sub_classifier=NB multinomial(alpha=alpha) sub_classifier.fit(X_train,y_train) y_pred=sub_classifier.predict(X_test) score = metrics.accuracy_score(y_test, y_pred) si score> score_précédent : classificateur=sub_classifier print( "Alpha : {}, Score : {}" .format(alpha,score)) |
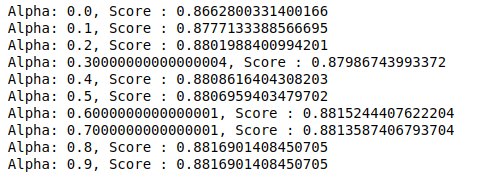
Par conséquent, nous pouvons voir qu'une valeur alpha de 0,9 ou 0,8 a donné le score de précision le plus élevé.
Interprétation des résultats
Voyons maintenant ce que signifient ces valeurs de coefficient de classificateur. Nous allons d'abord enregistrer tous les noms de fonctionnalités dans une autre variable.
| ## G et Noms des fonctionnalités feature_names = cv.get_feature_names() |
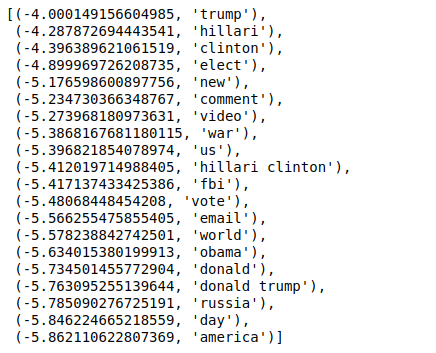
Maintenant, lorsque nous trions les valeurs dans l'ordre inverse, nous obtenons des valeurs avec une valeur minimale de -4. Ceux-ci désignent les mots les plus vrais ou les moins faux.
| ### Le plus réel trié(zip(classifier.coef_[ 0 ], feature_names), reverse= True )[: 20 ] |
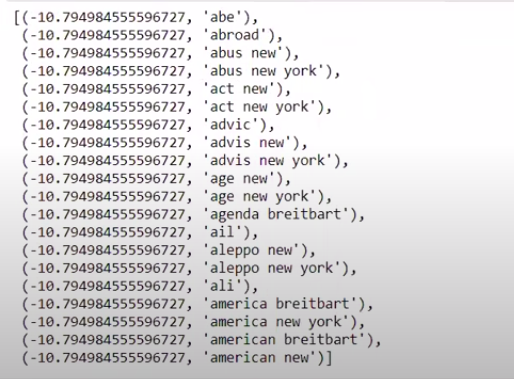
Lorsque nous trions les valeurs dans un ordre non inverse, nous obtenons des valeurs avec une valeur minimale de -10. Ceux-ci désignent les mots les moins réels ou les plus faux.
| ### Le plus réel trié(zip(classifier.coef_[ 0 ], feature_names))[: 20 ] |
Conclusion
Dans ce didacticiel, nous n'avons utilisé que des algorithmes ML, mais vous utilisez également d'autres méthodes de réseaux de neurones. De plus, pour vectoriser les données textuelles, nous avons utilisé le vectoriseur TF-IDF. Il y a plus de vectoriseurs comme Count Vectorizer, Hashing Vectorizer, etc. qui peuvent être meilleurs pour faire le travail. Essayez et expérimentez d'autres algorithmes et techniques pour voir si vous pouvez produire de meilleurs résultats ou non.
Si vous souhaitez en savoir plus sur l'apprentissage automatique, consultez le programme Executive PG d'IIIT-B & upGrad en apprentissage automatique et IA , conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions, IIIT -B Statut d'anciens élèves, 5+ projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
Pourquoi faut-il détecter les fake news ?
Dans leur état actuel, les plateformes de médias sociaux sont très puissantes et précieuses car elles permettent aux utilisateurs de discuter et d'échanger des idées ainsi que de débattre de sujets tels que la démocratie, l'éducation et la santé. Cependant, certaines entités utilisent mal ces plateformes, pour un gain monétaire dans certaines circonstances et pour produire des points de vue préjugés, modifier les mentalités et diffuser la satire ou le ridicule dans d'autres. Les fausses nouvelles sont le terme pour désigner ce phénomène. La prolifération d'articles en ligne qui ne correspondent pas à la réalité a entraîné une multitude de problèmes dans les domaines de la politique, du sport, de la santé, de la science et d'autres domaines.
Quelles entreprises utilisent principalement la détection de fausses nouvelles ?
La détection des fausses nouvelles est utilisée sur des plateformes telles que les médias sociaux et les sites Web d'actualités. Les géants des médias sociaux comme Facebook, Instagram et Twitter sont vulnérables aux fausses nouvelles puisque la majorité de ses utilisateurs les utilisent comme sources d'information quotidiennes pour obtenir les informations les plus récentes. Les fausses techniques de détection sont également utilisées par les entreprises de médias pour déterminer l'authenticité des informations dont elles disposent. Le courrier électronique est un autre moyen par lequel les individus peuvent recevoir des nouvelles, ce qui rend difficile l'identification et la vérification de leur véracité. Les canulars, les spams et les courriers indésirables sont bien connus pour être transmis par e-mail. En conséquence, la majorité des plates-formes d'e-mailing utilisent la détection de fausses nouvelles pour identifier les spams et les courriers indésirables.