
Analyse exploratoire des données en Python : que devez-vous savoir ?
Publié: 2021-03-12L'analyse exploratoire des données (EDA) est une pratique très courante et importante suivie par tous les data scientists. C'est le processus qui consiste à examiner des tableaux et des tableaux de données sous différents angles afin de bien les comprendre. Acquérir une bonne compréhension des données nous aide à les nettoyer et à les résumer, ce qui fait ensuite ressortir les idées et les tendances qui n'étaient pas claires autrement.
L'EDA n'a pas d'ensemble de règles strictes à suivre comme dans «l'analyse des données», par exemple. Les personnes qui débutent dans le domaine ont toujours tendance à confondre les deux termes, qui sont pour la plupart similaires mais différents dans leur objectif. Contrairement à l'EDA, l'analyse des données est plus encline à la mise en œuvre de probabilités et de méthodes statistiques pour révéler des faits et des relations entre différentes variantes.
Pour en revenir, il n'y a pas de bonne ou de mauvaise façon d'effectuer l'EDA. Cela varie d'une personne à l'autre, cependant, il existe certaines directives importantes couramment suivies qui sont énumérées ci-dessous.
- Traitement des valeurs manquantes : les valeurs nulles peuvent être observées lorsque toutes les données n'étaient peut-être pas disponibles ou enregistrées lors de la collecte.
- Suppression des données en double : il est important d'éviter tout surajustement ou biais créé lors de la formation de l'algorithme d'apprentissage automatique à l'aide d'enregistrements de données répétés
- Gestion des valeurs aberrantes : les valeurs aberrantes sont des enregistrements qui diffèrent considérablement du reste des données et ne suivent pas la tendance. Cela peut survenir en raison de certaines exceptions ou inexactitudes lors de la collecte des données
- Mise à l' échelle et normalisation : cette opération n'est effectuée que pour les variables de données numériques. La plupart du temps, les variables diffèrent considérablement dans leur plage et leur échelle, ce qui rend difficile leur comparaison et la recherche de corrélations.
- Analyse univariée et bivariée : L'analyse univariée est généralement effectuée en voyant comment une variable affecte la variable cible. L'analyse bivariée est effectuée entre 2 variables quelconques, elle peut être numérique ou catégorique ou les deux.
Nous verrons comment certains d'entre eux sont mis en œuvre à l'aide d'un ensemble de données très célèbre sur le «risque de défaut de crédit à domicile» disponible sur Kaggle ici . Les données contiennent des informations sur le demandeur de prêt au moment de la demande de prêt. Il contient deux types de scénarios :
- Le client en difficulté de paiement : il a eu un retard de paiement supérieur à X jours
sur au moins une des Y premières échéances du prêt de notre échantillon,
- Tous les autres cas : Tous les autres cas où le paiement est payé à temps.
Nous ne travaillerons que sur les fichiers de données d'application pour les besoins de cet article.
Connexes : Idées et sujets de projet Python pour les débutants
Table des matières
Regarder les données
app_data = pd.read_csv( 'application_data.csv' )
app_data.info()
Après avoir lu les données de l'application, nous utilisons la fonction info() pour obtenir un bref aperçu des données que nous allons traiter. La sortie ci-dessous nous informe que nous avons environ 300 000 enregistrements de prêt avec 122 variables. Parmi celles-ci, il y a 16 variables catégorielles et le reste numérique.
<classe 'pandas.core.frame.DataFrame'>
RangeIndex : 307511 entrées, 0 à 307510
Colonnes : 122 entrées, SK_ID_CURR à AMT_REQ_CREDIT_BUREAU_YEAR
dtypes : float64(65), int64(41), objet(16)
utilisation de la mémoire : 286,2+ Mo
Il est toujours recommandé de traiter et d'analyser séparément les données numériques et catégorielles.
categorical = app_data.select_dtypes(include = object).columns
app_data[categorical].apply(pd.Series.nunique, axe = 0)
En regardant uniquement les caractéristiques catégorielles ci-dessous, nous voyons que la plupart d'entre elles n'ont que quelques catégories qui les rendent plus faciles à analyser à l'aide de graphiques simples.
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
TYPE_DE_PROFESSION 18
WEEKDAY_APPR_PROCESS_START 7
ORGANISATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
ETAT D'URGENCE_MODE 2
dtype: int64
Maintenant pour les caractéristiques numériques, la méthode describe() nous donne les statistiques de nos données :
numéro=app_data.describe()
numérique= nombre.colonnes
chiffre
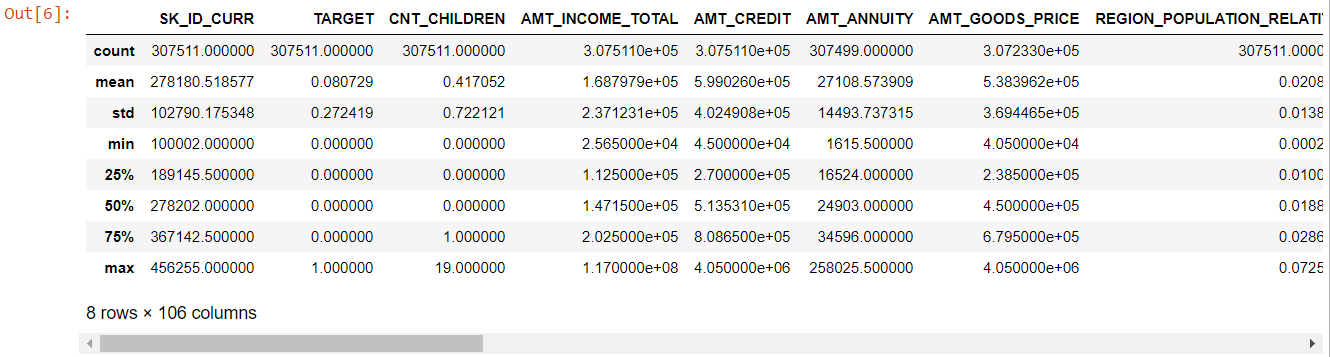
En regardant l'ensemble du tableau, il est évident que :
- days_birth est négatif : âge du demandeur (en jours) par rapport au jour de la demande
- days_employed a des valeurs aberrantes (la valeur maximale est d'environ 100 ans) (635243)
- amt_annuity - signifie beaucoup plus petit que la valeur maximale
Nous savons donc maintenant quelles fonctionnalités devront être analysées plus en détail.
Données manquantes
Nous pouvons créer un graphique ponctuel de toutes les caractéristiques ayant des valeurs manquantes en traçant le % de données manquantes le long de l'axe Y.
manquant = pd.DataFrame( (app_data.isnull().sum()) * 100 / app_data.shape[0]).reset_index()
plt.figure(figsize = (16,5))
ax = sns.pointplot('index', 0, data = missing)

plt.xticks(rotation = 90, taille de police = 7)
plt.title("Pourcentage de valeurs manquantes")
plt.ylabel("POURCENTAGE")
plt.show()
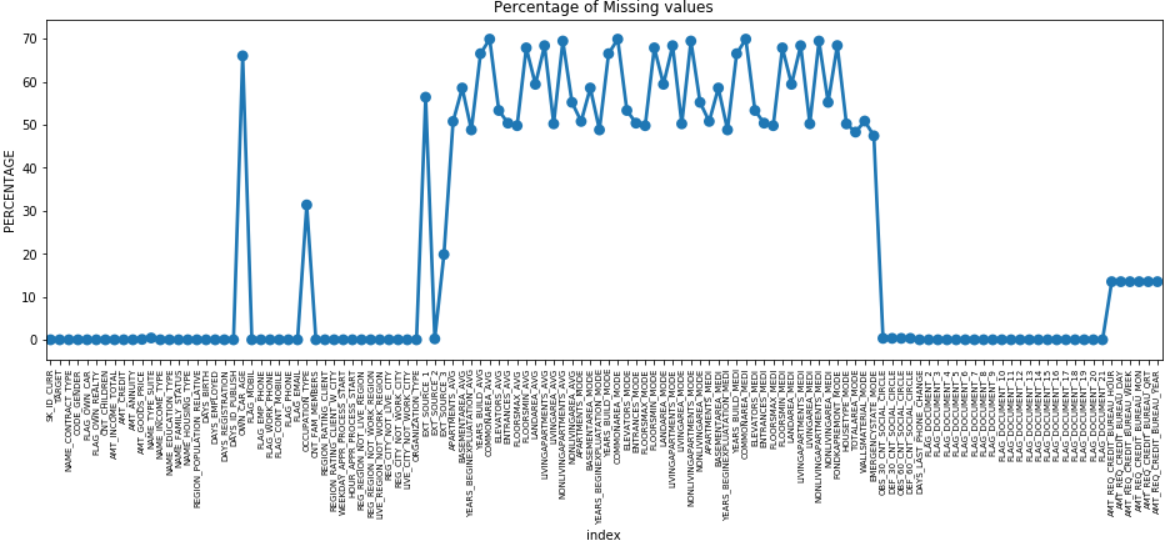
De nombreuses colonnes ont beaucoup de données manquantes (30-70%), certaines ont peu de données manquantes (13-19%) et de nombreuses colonnes n'ont également aucune donnée manquante. Il n'est pas vraiment nécessaire de modifier le jeu de données lorsqu'il suffit d'effectuer de l'EDA. Cependant, pour aller de l'avant avec le prétraitement des données, nous devrions savoir comment gérer les valeurs manquantes.
Pour les entités avec moins de valeurs manquantes, nous pouvons utiliser la régression pour prédire les valeurs manquantes ou remplir avec la moyenne des valeurs présentes, selon l'entité. Et pour les fonctionnalités avec un nombre très élevé de valeurs manquantes, il est préférable de supprimer ces colonnes car elles donnent très moins d'informations sur l'analyse.
Déséquilibre des données
Dans cet ensemble de données, les débiteurs défaillants sont identifiés à l'aide de la variable binaire « TARGET ».
100 * app_data['TARGET'].value_counts() / len(app_data['TARGET'])
0 91.927118
1 8.072882
Nom : CIBLE, dtype : float64
On voit que les données sont fortement déséquilibrées avec un ratio de 92:8. La plupart des prêts ont été remboursés à temps (cible = 0). Donc, chaque fois qu'il y a un tel déséquilibre, il est préférable de prendre des caractéristiques et de les comparer avec la variable cible (analyse ciblée) pour déterminer quelles catégories de ces caractéristiques ont tendance à faire défaut sur les prêts plus que d'autres.
Vous trouverez ci-dessous quelques exemples de graphiques pouvant être créés à l'aide de la bibliothèque seaborn de python et de fonctions simples définies par l'utilisateur.
Le sexe
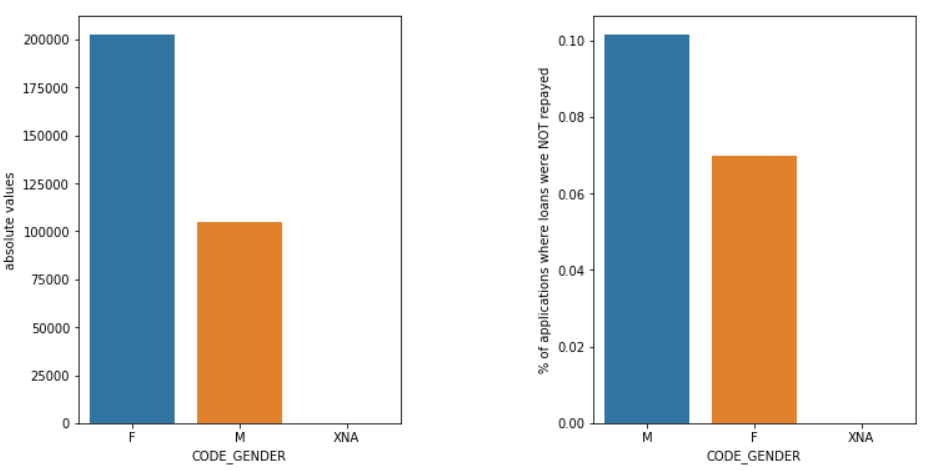
Les hommes (M) ont un risque plus élevé d'abandon que les femmes (F), même si le nombre de femmes candidates est presque deux fois plus élevé. Les femmes sont donc plus fiables que les hommes pour rembourser leurs prêts.
Type d'éducation
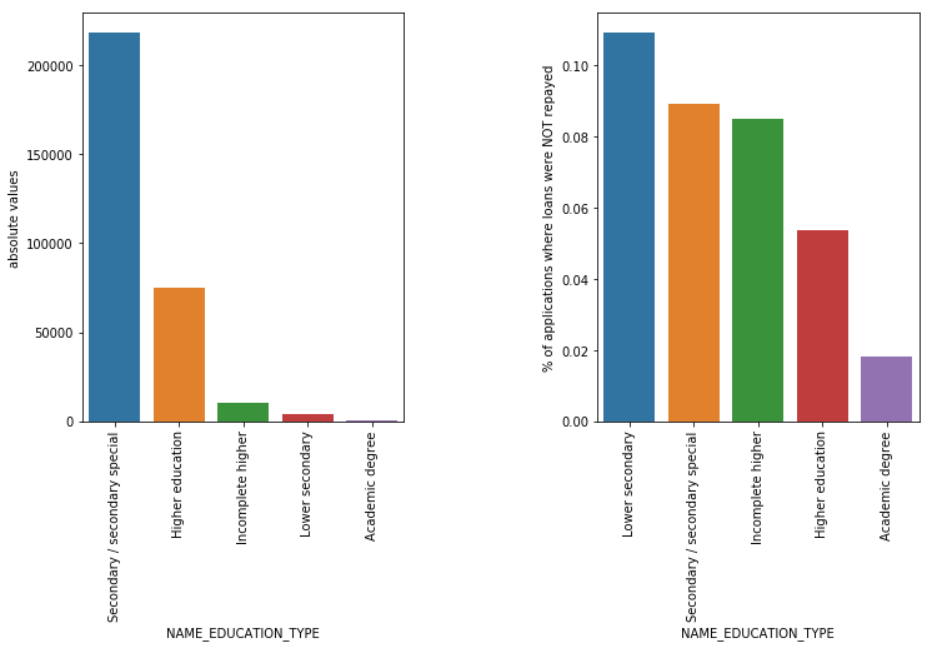
Même si la plupart des prêts étudiants sont destinés à leurs études secondaires ou supérieures, ce sont les prêts du premier cycle du secondaire qui sont les plus risqués pour l'entreprise suivis du secondaire.
Lisez aussi: Carrière en science des données
Conclusion
Ce type d'analyse vu ci-dessus est largement effectué dans l'analyse des risques dans les services bancaires et financiers. De cette façon, les archives de données peuvent être utilisées pour minimiser le risque de perdre de l'argent en prêtant aux clients. La portée de l'EDA dans tous les autres secteurs est infinie et devrait être largement utilisée.
Si vous êtes curieux d'en savoir plus sur la science des données, consultez le PG exécutif de IIIT-B & upGrad en science des données qui est créé pour les professionnels en activité et propose plus de 10 études de cas et projets, des ateliers pratiques, un mentorat avec des experts de l'industrie, 1- on-1 avec des mentors de l'industrie, plus de 400 heures d'apprentissage et d'aide à l'emploi avec les meilleures entreprises.
L'analyse exploratoire des données est considérée comme le niveau initial lorsque vous commencez à modéliser vos données. Il s'agit d'une technique assez perspicace pour analyser les meilleures pratiques de modélisation de vos données. Vous pourrez extraire des tracés visuels, des graphiques et des rapports à partir des données pour en avoir une compréhension complète. Les valeurs aberrantes font référence aux anomalies ou aux légères variations de vos données. Cela peut se produire lors de la collecte de données. Il existe 4 façons de détecter une valeur aberrante dans l'ensemble de données. Ces méthodes sont les suivantes : Contrairement à l'analyse des données, il n'y a pas de règles et de réglementations strictes à suivre pour l'EDA. On ne peut pas dire que c'est la bonne méthode ou que c'est la mauvaise méthode pour effectuer l'EDA. Les débutants sont souvent mal compris et se confondent entre EDA et analyse de données.Pourquoi l'analyse exploratoire des données (EDA) est-elle nécessaire ?
L'EDA implique certaines étapes pour analyser complètement les données, y compris la dérivation des résultats statistiques, la recherche des valeurs de données manquantes, la gestion des entrées de données erronées et enfin la déduction de divers tracés et graphiques.
L'objectif principal de cette analyse est de s'assurer que l'ensemble de données que vous utilisez est approprié pour commencer à appliquer des algorithmes de modélisation. C'est la raison pour laquelle il s'agit de la première étape que vous devez effectuer sur vos données avant de passer à l'étape de modélisation. Que sont les valeurs aberrantes et comment les gérer ?
1. Boxplot - Boxplot est une méthode de détection d'une valeur aberrante où nous séparons les données par leurs quartiles.
2. Nuage de points - Un nuage de points affiche les données de 2 variables sous la forme d'une collection de points marqués sur le plan cartésien. La valeur d'une variable représente l'axe horizontal (x-ais) et la valeur de l'autre variable représente l'axe vertical (y-axis).
3. Z-score - Lors du calcul du Z-score, nous recherchons les points éloignés du centre et les considérons comme des valeurs aberrantes.
4. Plage interquartile (IQR) - La plage interquartile ou IQR est la différence entre les quartiles supérieur et inférieur ou 75e et 25e quartile, souvent appelée dispersion statistique. Quelles sont les directives pour effectuer l'EDA ?
Cependant, il existe certaines directives qui sont couramment pratiquées :
1. Traitement des valeurs manquantes
2. Suppression des données en double
3. Traitement des valeurs aberrantes
4. Mise à l'échelle et normalisation
5. Analyse univariée et bivariée