
Qu'est-ce que l'analyse exploratoire des données en Python ? Apprendre à partir de zéro
Publié: 2021-03-04L'analyse exploratoire des données ou EDA, en bref, comprend près de 70% du projet Data Science. L'EDA est le processus d'exploration des données à l'aide de divers outils d'analyse pour extraire les statistiques inférentielles des données. Ces explorations se font soit en voyant des nombres simples, soit en traçant des graphiques et des tableaux de différents types.
Chaque graphique ou diagramme décrit une histoire différente et un angle par rapport aux mêmes données. Pour la plupart de la partie analyse et nettoyage des données, Pandas est l'outil le plus utilisé. Pour les visualisations et le traçage des graphiques/graphiques, des bibliothèques de traçage telles que Matplotlib, Seaborn et Plotly sont utilisées.
L'EDA est extrêmement nécessaire pour être effectuée car elle vous fait avouer les données. Un Data Scientist qui fait un très bon EDA en sait beaucoup sur les données et donc le modèle qu'il construira sera automatiquement meilleur que le Data Scientist qui ne fait pas un bon EDA.
À la fin de ce didacticiel, vous saurez ce qui suit :
- Vérification de la vue d'ensemble de base des données
- Vérification des statistiques descriptives des données
- Manipulation des noms de colonnes et des types de données
- Gestion des valeurs manquantes et des lignes en double
- Analyse bivariée
Table des matières
Aperçu de base des données
Nous utiliserons le jeu de données Cars pour ce didacticiel qui peut être téléchargé à partir de Kaggle. La première étape pour presque n'importe quel ensemble de données consiste à l'importer et à vérifier son aperçu de base - sa forme, ses colonnes, ses types de colonnes, les 5 premières lignes, etc. Cette étape vous donne un aperçu rapide des données avec lesquelles vous allez travailler. Voyons comment faire cela en Python.
| # Importation des bibliothèques requises importer des pandas en tant que pd importer numpy en tant que np importer seaborn en tant que sns #visualisation importer matplotlib.pyplot en tant que plt #visualisation %matplotlib en ligne sns.set(color_codes= Vrai ) |
Tête et queue de données
| données = pd.read_csv( "chemin/ensemble de données.csv" ) # Vérifiez les 5 premières lignes de la trame de données data.head() |
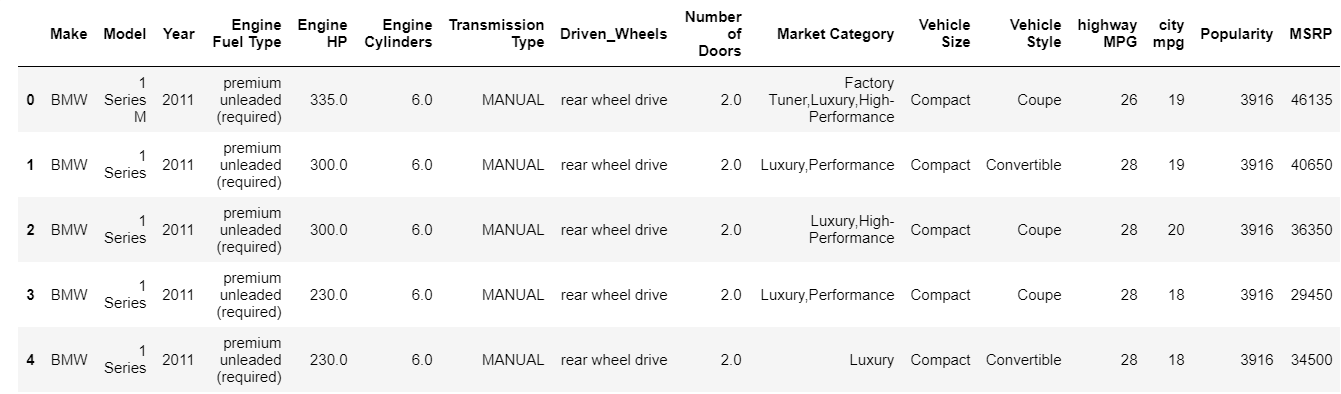
La fonction head imprime par défaut les 5 premiers index de la trame de données. Vous pouvez également spécifier le nombre d'index supérieurs dont vous avez besoin pour voir contourner cette valeur vers la tête. L'impression de la tête nous donne instantanément un aperçu du type de données dont nous disposons, du type de fonctionnalités présentes et des valeurs qu'elles contiennent. Bien sûr, cela ne raconte pas toute l'histoire des données, mais cela vous donne un aperçu rapide des données. Vous pouvez également imprimer la partie inférieure du bloc de données en utilisant la fonction tail.
| # Imprimer les 10 dernières lignes du dataframe data.tail( 10 ) |
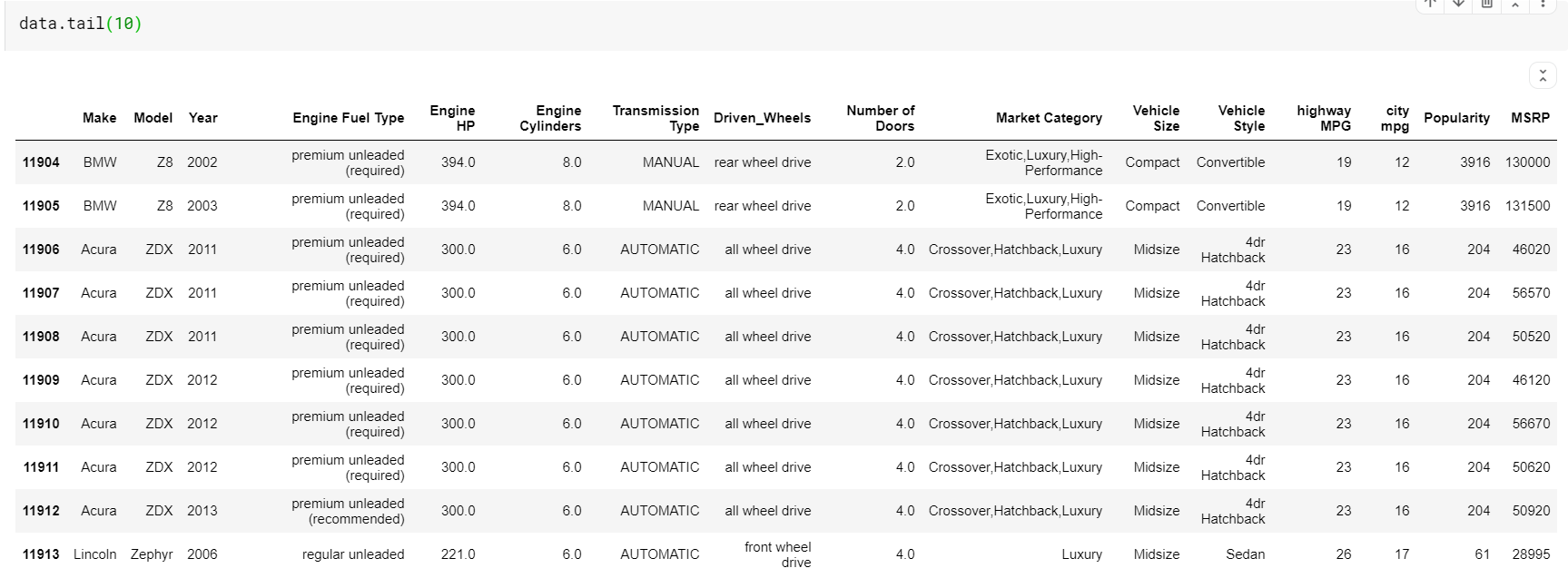
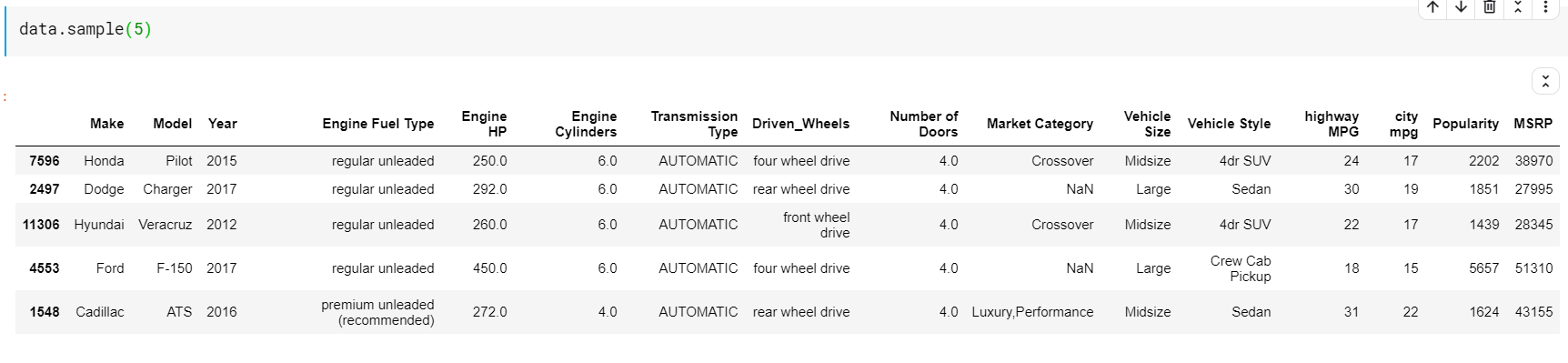
Une chose à remarquer ici est que les fonctions-head et tail nous donnent les index du haut ou du bas. Mais les lignes du haut ou du bas ne sont pas toujours un bon aperçu des données. Ainsi, vous pouvez également imprimer n'importe quel nombre de lignes échantillonnées au hasard à partir de l'ensemble de données à l'aide de la fonction sample ().
| # Imprimer 5 lignes aléatoires data.sample( 5 ) |
Statistiques descriptives
Examinons ensuite les statistiques descriptives de l'ensemble de données. Les statistiques descriptives comprennent tout ce qui « décrit » l'ensemble de données. Nous vérifions la forme du bloc de données, la présence de toutes les colonnes, la présence de toutes les caractéristiques numériques et catégorielles. Nous verrons également comment faire tout cela dans des fonctions simples.
Façonner
| # Vérification de la forme de la trame de données (mxn) # m=nombre de lignes # n=nombre de colonnes data.shape |

Comme nous le voyons, ce bloc de données contient 11914 lignes et 16 colonnes.
Colonnes
| # Imprimer les noms des colonnes données.colonnes |
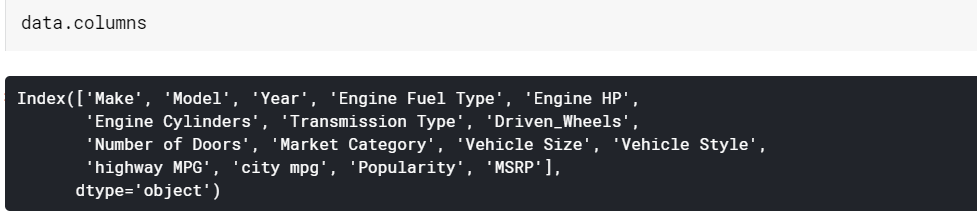
Informations sur la trame de données
| # Imprimer les types de données des colonnes et le nombre de valeurs non manquantes data.info() |
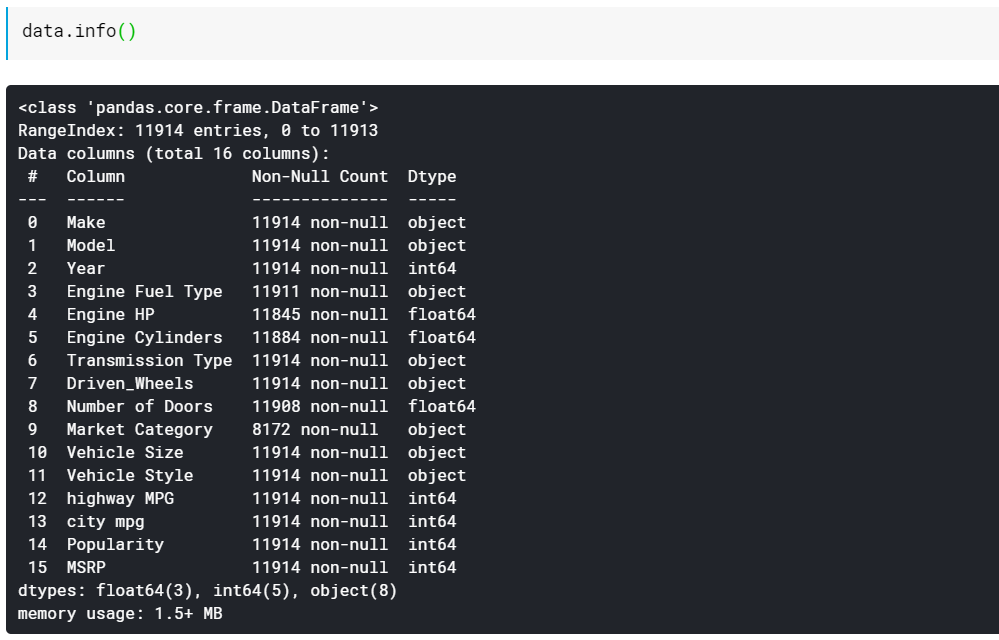
Comme vous le voyez, la fonction info() nous donne toutes les colonnes, le nombre de valeurs non nulles ou non manquantes dans ces colonnes et enfin le type de données de ces colonnes. C'est un bon moyen rapide de voir quelles fonctionnalités sont numériques et quelles sont toutes catégorielles/basées sur du texte. De plus, nous avons maintenant des informations sur ce que toutes les colonnes ont des valeurs manquantes. Nous verrons comment travailler avec les valeurs manquantes plus tard.
Manipulation des noms de colonne et des types de données
Vérifier et manipuler soigneusement chaque colonne est extrêmement crucial dans EDA. Nous devons voir quel type de contenu contient une colonne/fonctionnalité et ce que les pandas ont lu dans son type de données. Les types de données numériques sont principalement int64 ou float64. Les caractéristiques textuelles ou catégorielles se voient attribuer le type de données « objet ».
Les fonctionnalités basées sur la date et l'heure sont attribuées. Il y a des moments où Pandas ne comprend pas le type de données d'une fonctionnalité. Dans de tels cas, il lui attribue paresseusement le type de données "objet". Nous pouvons spécifier explicitement les types de données de colonne lors de la lecture des données avec read_csv.
Sélection de colonnes qualitatives et numériques
| # Ajoutez toutes les colonnes catégorielles et numériques à des listes séparées categorical = data.select_dtypes( 'object' ).columns numérique = data.select_dtypes( 'nombre' ).columns |

Ici, le type que nous avons passé en tant que 'nombre' sélectionne toutes les colonnes avec des types de données qui ont n'importe quel type de nombre, que ce soit int64 ou float64.

Renommer les colonnes
| # Renommer les noms de colonnes data = data.rename(columns={ "Moteur HP" : "HP" , « Cylindres moteurs » : « Cylindres » , « Type de transmission » : « Transmission » , "Driven_Wheels" : "Mode de conduite" , "autoroute MPG" : "MPG-H" , "PDSF" : "Prix" }) data.head( 5 ) |

La fonction de renommage prend simplement un dictionnaire avec les noms des colonnes à renommer et leurs nouveaux noms.
Gestion des valeurs manquantes et des lignes en double
Les valeurs manquantes sont l'un des problèmes/écarts les plus courants dans tout ensemble de données réel. La gestion des valeurs manquantes est en soi un vaste sujet car il existe plusieurs façons de le faire. Certaines méthodes sont plus génériques, et d'autres sont plus spécifiques à l'ensemble de données auquel on peut avoir affaire.
Vérification des valeurs manquantes
| # Vérification des valeurs manquantes data.isnull().sum() |
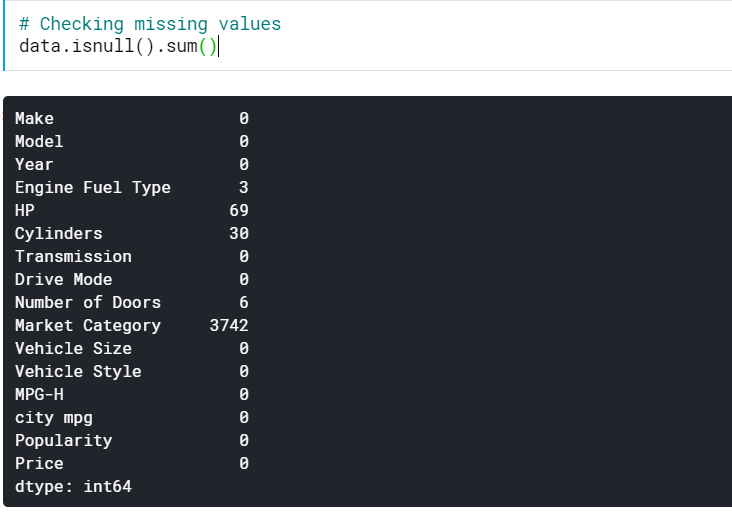
Cela nous donne le nombre de valeurs manquantes dans toutes les colonnes. Nous pouvons également voir le pourcentage de valeurs manquantes.
| # Pourcentage de valeurs manquantes data.isnull().mean()* 100 |
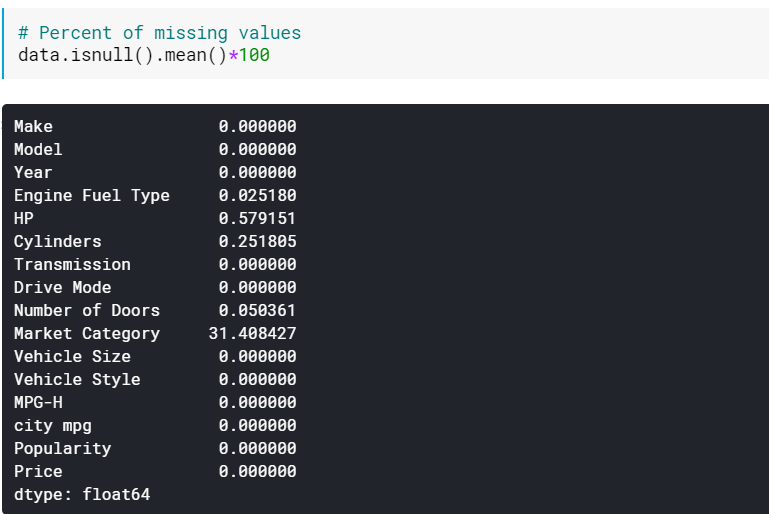
Vérifier les pourcentages peut être utile lorsqu'il y a beaucoup de colonnes qui ont des valeurs manquantes. Dans de tels cas, les colonnes avec beaucoup de valeurs manquantes (par exemple, > 60 % manquantes) peuvent être simplement supprimées.
Imputation des valeurs manquantes
| #Imputing des valeurs manquantes des colonnes numériques par moyenne data[numerical] = data[numerical].fillna(data[numerical].mean().iloc[ 0 ]) #Imputing des valeurs manquantes des colonnes catégorielles par mode données[catégorielles] = données[catégorielles].fillna(données[catégorielles].mode().iloc[ 0 ]) |
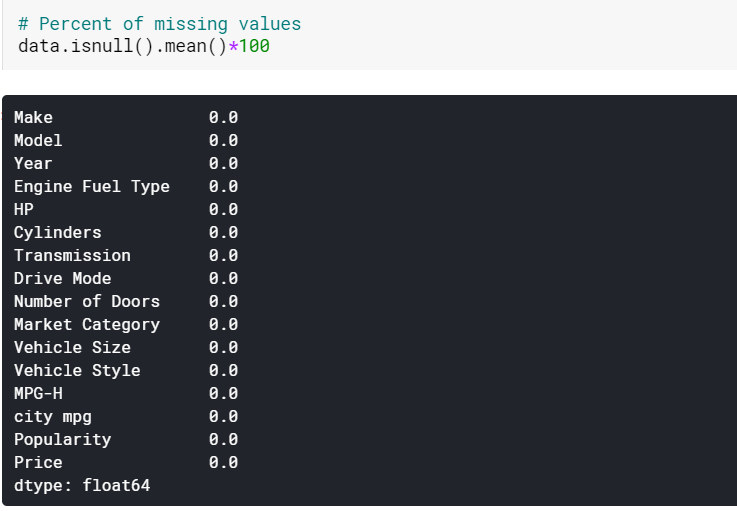
Ici, nous imputons simplement les valeurs manquantes dans les colonnes numériques par leurs moyennes respectives et celles des colonnes catégorielles par leurs modes. Et comme nous pouvons le voir, il n'y a plus de valeurs manquantes maintenant.
Veuillez noter qu'il s'agit de la manière la plus primitive d'imputer les valeurs et qu'elle ne fonctionne pas dans des cas réels où des méthodes plus sophistiquées sont développées, par exemple l'interpolation, KNN, etc.
Gestion des lignes en double
| # Supprimer les lignes en double data.drop_duplicates(inplace= True ) |
Cela supprime simplement les lignes en double.
Paiement : Idées et sujets de projet Python
Analyse bivariée
Voyons maintenant comment obtenir plus d'informations en effectuant une analyse bivariée. Bivariée signifie une analyse qui se compose de 2 variables ou caractéristiques. Il existe différents types de tracés disponibles pour différents types d'entités.
Pour numérique – numérique
- Nuage de points
- Graphique linéaire
- Heatmap pour les corrélations
Pour les catégories-numériques
- Diagramme à bandes
- Complot de violon
- Diagramme d'essaim
Pour Catégorique-Catégorique
- Diagramme à bandes
- Tracé de points
Heatmap pour les corrélations
| # Vérification des corrélations entre les variables. plt.figure(figsize=( 15 , 10 )) c= data.corr() sns.heatmap(c,cmap= "BrBG" ,annot= Vrai ) |
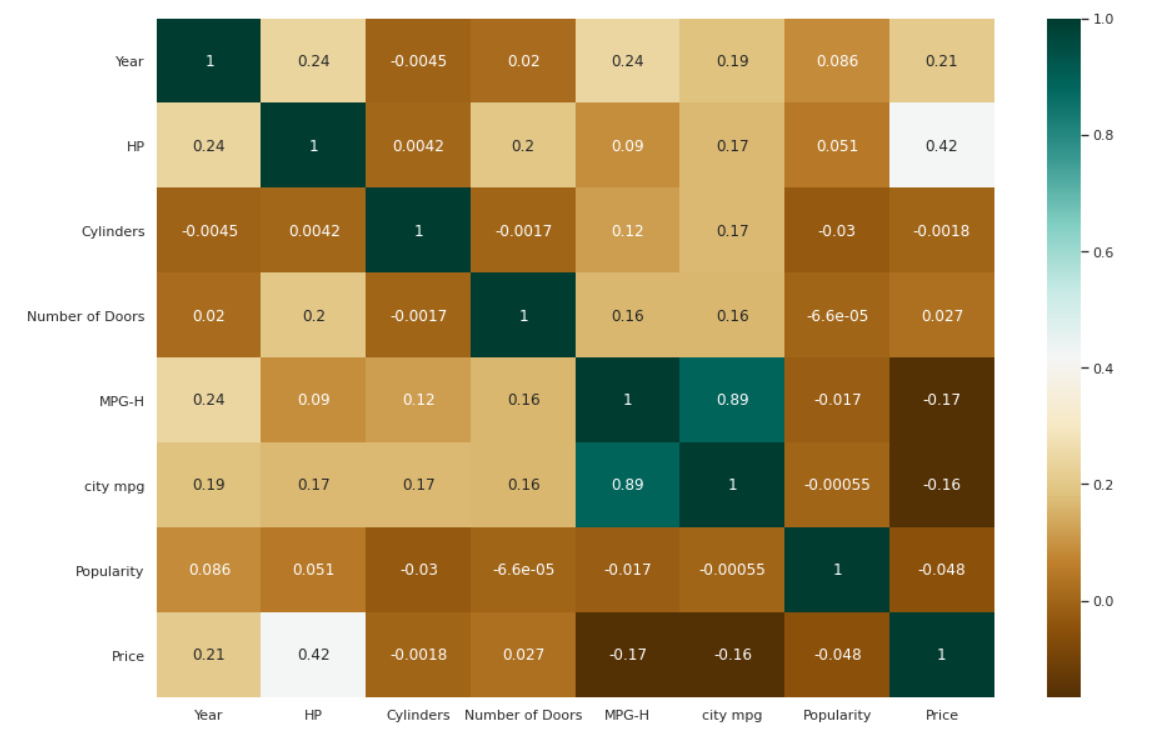
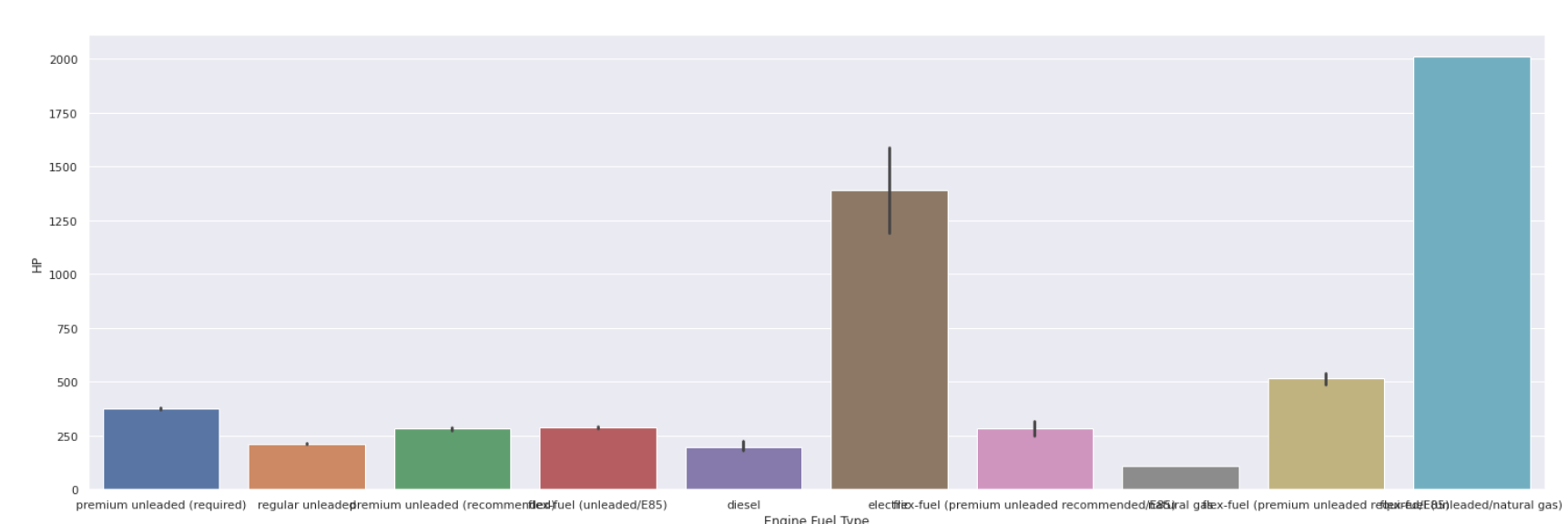
Graphique à barres
| sns.barplot(data[ 'Type de carburant moteur' ], data[ 'HP' ]) |
Obtenez une certification en science des données des meilleures universités du monde. Apprenez les programmes Executive PG, les programmes de certificat avancés ou les programmes de maîtrise pour accélérer votre carrière.
Conclusion
Comme nous l'avons vu, il y a beaucoup d'étapes à couvrir lors de l'exploration d'un jeu de données. Nous n'avons couvert qu'une poignée d'aspects dans ce didacticiel, mais cela vous donnera plus que des connaissances de base sur un bon EDA.
Si vous êtes curieux d'en savoir plus sur Python, tout sur la science des données, consultez le diplôme PG de IIIT-B & upGrad en science des données qui est créé pour les professionnels en activité et propose plus de 10 études de cas et projets, des ateliers pratiques, du mentorat avec l'industrie experts, 1-on-1 avec des mentors de l'industrie, plus de 400 heures d'apprentissage et d'aide à l'emploi avec les meilleures entreprises.
Quelles sont les étapes de l'analyse exploratoire des données ?
Les principales étapes que vous devez effectuer pour effectuer une analyse exploratoire des données sont -
Les variables et les types de données doivent être identifiés.
Analyser les métriques fondamentales
Analyse non graphique univariée
Analyse graphique univariée
Analyse de données bivariées
Des transformations variables
Traitement de la valeur manquante
Traitement des valeurs aberrantes
Analyse de corrélation
Réduction de la dimensionnalité
Quel est le but de l'analyse exploratoire des données ?
L'objectif principal de l'EDA est d'aider à l'analyse des données avant de formuler des hypothèses. Cela peut aider à la détection d'erreurs évidentes, ainsi qu'à une meilleure compréhension des modèles de données, à la détection de valeurs aberrantes ou d'événements inhabituels et à la découverte de relations intéressantes entre les variables.
L'analyse exploratoire peut être utilisée par les scientifiques des données pour garantir que les résultats qu'ils créent sont exacts et appropriés à tous les résultats et objectifs commerciaux ciblés. L'EDA assiste également les parties prenantes en s'assurant qu'elles répondent aux questions appropriées. Les écarts-types, les données catégorielles et les intervalles de confiance peuvent tous être résolus avec EDA. Après l'achèvement de l'EDA et l'extraction des informations, ses fonctionnalités peuvent être appliquées à une analyse ou à une modélisation de données plus avancée, y compris l'apprentissage automatique.
Quels sont les différents types d'analyse exploratoire des données ?
Il existe deux types de techniques EDA : graphique et quantitative (non graphique). L'approche quantitative, en revanche, nécessite la compilation de statistiques sommaires, tandis que les méthodes graphiques consistent à rassembler les données de manière schématique ou visuelle. Les approches univariées et multivariées sont des sous-ensembles de ces deux types de méthodologies.
Pour étudier les relations, les approches univariées examinent une variable (colonne de données) à la fois, tandis que les méthodes multivariées examinent deux variables ou plus à la fois. Graphiques et non graphiques univariés et multivariés sont les quatre formes d'EDA. Les procédures quantitatives sont plus objectives, tandis que les méthodes picturales sont plus subjectives.