
Le guide du scraping éthique des sites Web dynamiques avec Node.js et Puppeteer
Publié: 2022-03-10Commençons par une petite section sur ce que signifie réellement le web scraping. Nous utilisons tous le web scraping dans notre vie de tous les jours. Il décrit simplement le processus d'extraction d'informations à partir d'un site Web. Par conséquent, si vous copiez et collez une recette de votre plat de nouilles préféré depuis Internet vers votre ordinateur portable personnel, vous effectuez un grattage Web .
Lorsque nous utilisons ce terme dans l'industrie du logiciel, nous nous référons généralement à l' automatisation de cette tâche manuelle à l'aide d'un logiciel. S'en tenir à notre exemple précédent de "plat de nouilles", ce processus implique généralement deux étapes :
- Récupération de la page
Nous devons d'abord télécharger la page dans son ensemble. Cette étape revient à ouvrir la page dans votre navigateur Web lors du grattage manuel. - Analyser les données
Maintenant, nous devons extraire la recette dans le HTML du site Web et la convertir dans un format lisible par machine comme JSON ou XML.
Dans le passé, j'ai travaillé pour de nombreuses entreprises en tant que consultant en données. J'ai été étonné de voir combien de tâches d'extraction, d'agrégation et d'enrichissement de données sont encore effectuées manuellement, bien qu'elles puissent facilement être automatisées avec seulement quelques lignes de code. C'est exactement ce qu'est le web scraping pour moi : extraire et normaliser des informations précieuses d'un site Web pour alimenter un autre processus commercial générateur de valeur.
Pendant ce temps, j'ai vu des entreprises utiliser le web scraping pour toutes sortes de cas d'utilisation. Les entreprises d'investissement se concentraient principalement sur la collecte de données alternatives, telles que des critiques de produits , des informations sur les prix ou des publications sur les réseaux sociaux pour étayer leurs investissements financiers.
Voici un exemple. Un client m'a approché pour récupérer les données d'avis sur les produits d'une longue liste de produits de plusieurs sites Web de commerce électronique, y compris la note, l'emplacement de l'examinateur et le texte de l'avis pour chaque avis soumis. Les données de résultat ont permis au client d' identifier les tendances concernant la popularité du produit sur différents marchés. C'est un excellent exemple de la façon dont une seule information apparemment "inutile" peut devenir précieuse par rapport à une plus grande quantité.
D'autres entreprises accélèrent leur processus de vente en utilisant le web scraping pour la génération de leads. Ce processus implique généralement l'extraction d'informations de contact telles que le numéro de téléphone, l'adresse e-mail et le nom du contact pour une liste donnée de sites Web. L'automatisation de cette tâche donne plus de temps aux équipes commerciales pour approcher les prospects. Par conséquent, l'efficacité du processus de vente augmente.
Respectez les règles
En général, le grattage Web des données accessibles au public est légal, comme l'a confirmé la juridiction de l'affaire Linkedin contre HiQ. Cependant, je me suis fixé un ensemble de règles éthiques que j'aime respecter lors du démarrage d'un nouveau projet de grattage Web. Ceci comprend:
- Vérification du fichier robots.txt.
Il contient généralement des informations claires sur les parties du site auxquelles le propriétaire de la page peut accéder par des robots et des grattoirs et met en évidence les sections qui ne doivent pas être consultées. - Lire les termes et conditions.
Par rapport au robots.txt, cette information n'est pas disponible moins souvent, mais indique généralement comment ils traitent les grattoirs de données. - Raclage à vitesse modérée.
Le scraping crée une charge serveur sur l'infrastructure du site cible. En fonction de ce que vous scrapez et du niveau de simultanéité de votre scraper, le trafic peut causer des problèmes à l'infrastructure du serveur du site cible. Bien sûr, la capacité du serveur joue un grand rôle dans cette équation. Par conséquent, la vitesse de mon scraper est toujours un équilibre entre la quantité de données que je vise à scraper et la popularité du site cible. Trouver cet équilibre peut être atteint en répondant à une seule question : « La vitesse prévue va-t-elle modifier significativement le trafic organique du site ? ». Dans les cas où je ne suis pas sûr de la quantité de trafic naturel d'un site, j'utilise des outils comme ahrefs pour avoir une idée approximative.
Choisir la bonne technologie
En fait, le scraping avec un navigateur sans tête est l'une des technologies les moins performantes que vous puissiez utiliser, car elle impacte fortement votre infrastructure. Un cœur du processeur de votre machine peut gérer approximativement une instance de Chrome.
Faisons un rapide exemple de calcul pour voir ce que cela signifie pour un projet de scraping Web réel.
Scénario
- Vous voulez gratter 20 000 URL.
- Le temps de réponse moyen du site cible est de 6 secondes.
- Votre serveur dispose de 2 cœurs de processeur.
Le projet prendra 16 heures à compléter.
Par conséquent, j'essaie toujours d'éviter d'utiliser un navigateur lors de la réalisation d'un test de faisabilité de grattage pour un site Web dynamique.
Voici une petite liste de contrôle que je passe toujours:
- Puis-je forcer l'état de page requis via les paramètres GET dans l'URL ? Si oui, nous pouvons simplement exécuter une requête HTTP avec les paramètres ajoutés.
- Les informations dynamiques font-elles partie de la source de la page et sont-elles disponibles via un objet JavaScript quelque part dans le DOM ? Si oui, nous pouvons à nouveau utiliser une requête HTTP normale et analyser les données de l'objet stringifié.
- Les données sont-elles récupérées via une requête XHR ? Si oui, puis-je accéder directement au point de terminaison avec un client HTTP ? Si oui, nous pouvons envoyer une requête HTTP directement au point de terminaison. Souvent, la réponse est même formatée en JSON, ce qui nous facilite la vie.
Si toutes les questions reçoivent une réponse définitive « Non », nous manquons officiellement d'options réalisables pour l'utilisation d'un client HTTP. Bien sûr, il pourrait y avoir plus de réglages spécifiques au site que nous pourrions essayer, mais généralement, le temps nécessaire pour les comprendre est trop élevé, par rapport aux performances plus lentes d'un navigateur sans tête. La beauté du scraping avec un navigateur est que vous pouvez scraper tout ce qui est soumis à la règle de base suivante :
Si vous pouvez y accéder avec un navigateur, vous pouvez le gratter.
Prenons le site suivant comme exemple pour notre scraper : https://quotes.toscrape.com/search.aspx. Il comporte des citations d'une liste d'auteurs donnés pour une liste de sujets. Toutes les données sont récupérées via XHR.
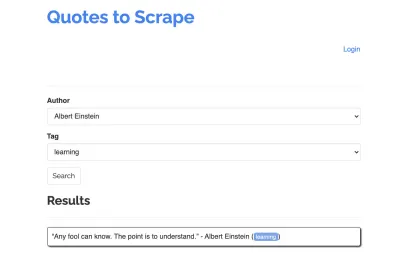
Celui qui a examiné de près le fonctionnement du site et parcouru la liste de contrôle ci-dessus s'est probablement rendu compte que les guillemets pouvaient en fait être extraits à l'aide d'un client HTTP, car ils peuvent être récupérés en effectuant directement une requête POST sur le point de terminaison des guillemets. Mais comme ce didacticiel est censé expliquer comment gratter un site Web à l'aide de Puppeteer, nous prétendrons que c'était impossible.
Installation des prérequis
Puisque nous allons tout construire en utilisant Node.js, commençons par créer et ouvrir un nouveau dossier, puis créons un nouveau projet Node à l'intérieur, en exécutant la commande suivante :
mkdir js-webscraper cd js-webscraper npm initVeuillez vous assurer que vous avez déjà installé npm. Le programme d'installation nous posera quelques questions sur les méta-informations sur ce projet, que nous pouvons tous ignorer en appuyant sur Entrée .
Installation de Marionnettiste
Nous avons déjà parlé de scraper avec un navigateur. Puppeteer est une API Node.js qui nous permet de parler à une instance Chrome sans tête par programmation.
Installons-le en utilisant npm :
npm install puppeteerConstruire notre grattoir
Maintenant, commençons à construire notre scraper en créant un nouveau fichier, appelé scraper.js .
Tout d'abord, nous importons la bibliothèque précédemment installée, Puppeteer :
const puppeteer = require('puppeteer');Dans une prochaine étape, nous disons à Puppeteer d'ouvrir une nouvelle instance de navigateur à l'intérieur d'une fonction asynchrone et auto-exécutable :
(async function scrape() { const browser = await puppeteer.launch({ headless: false }); // scraping logic comes here… })();Remarque : Par défaut, le mode sans tête est désactivé, car cela augmente les performances. Cependant, lors de la construction d'un nouveau grattoir, j'aime désactiver le mode sans tête. Cela nous permet de suivre le processus suivi par le navigateur et de voir tout le contenu rendu. Cela nous aidera à déboguer notre script plus tard.
Dans notre instance de navigateur ouverte, nous ouvrons maintenant une nouvelle page et nous dirigeons vers notre URL cible :
const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); Dans le cadre de la fonction asynchrone, nous utiliserons l'instruction await pour attendre que la commande suivante soit exécutée avant de passer à la ligne de code suivante.
Maintenant que nous avons réussi à ouvrir une fenêtre de navigateur et à accéder à la page, nous devons créer l'état du site Web afin que les informations souhaitées deviennent visibles pour le grattage.

Les rubriques disponibles sont générées dynamiquement pour un auteur sélectionné. Par conséquent, nous allons d'abord sélectionner 'Albert Einstein' et attendre la liste de sujets générée. Une fois la liste entièrement générée, nous sélectionnons « apprentissage » comme sujet et le sélectionnons comme deuxième paramètre de formulaire. Nous cliquons ensuite sur soumettre et extrayons les citations récupérées du conteneur contenant les résultats.
Comme nous allons maintenant convertir cela en logique JavaScript, faisons d'abord une liste de tous les sélecteurs d'éléments dont nous avons parlé dans le paragraphe précédent :
| Champ de sélection de l'auteur | #author |
| Champ de sélection de balise | #tag |
| Bouton de soumission | input[type="submit"] |
| Conteneur de devis | .quote |
Avant de commencer à interagir avec la page, nous nous assurerons que tous les éléments auxquels nous accéderons sont visibles, en ajoutant les lignes suivantes à notre script :
await page.waitForSelector('#author'); await page.waitForSelector('#tag');Ensuite, nous sélectionnerons des valeurs pour nos deux champs de sélection :
await page.select('select#author', 'Albert Einstein'); await page.select('select#tag', 'learning');Nous sommes maintenant prêts à effectuer notre recherche en appuyant sur le bouton "Rechercher" sur la page et en attendant que les citations apparaissent :
await page.click('.btn'); await page.waitForSelector('.quote'); Puisque nous allons maintenant accéder à la structure HTML DOM de la page, nous appelons la fonction page.evaluate() fournie, en sélectionnant le conteneur qui contient les guillemets (il n'y en a qu'un dans ce cas). Nous construisons ensuite un objet et définissons null comme valeur de repli pour chaque paramètre d' object :
let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, }; }); return quotes; });Nous pouvons rendre tous les résultats visibles dans notre console en les enregistrant :
console.log(quotes);Enfin, fermons notre navigateur et ajoutons une instruction catch :
await browser.close();Le grattoir complet ressemble à ceci :
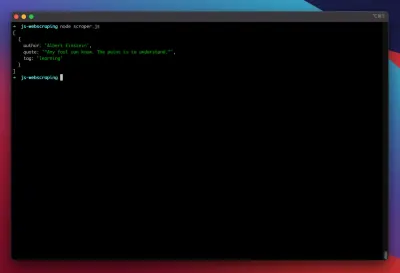
const puppeteer = require('puppeteer'); (async function scrape() { const browser = await puppeteer.launch({ headless: false }); const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('#author'); await page.select('#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); // logging results console.log(quotes); await browser.close(); })();Essayons de faire fonctionner notre scraper avec :
node scraper.jsEt voilà ! Le grattoir renvoie notre objet quote comme prévu :
Optimisations avancées
Notre grattoir de base fonctionne maintenant. Ajoutons quelques améliorations pour le préparer à des tâches de grattage plus sérieuses.
Définition d'un agent utilisateur
Par défaut, Puppeteer utilise un agent utilisateur qui contient la chaîne HeadlessChrome . De nombreux sites Web recherchent ce type de signature et bloquent les demandes entrantes avec une signature comme celle-ci. Pour éviter que cela ne soit une raison potentielle d'échec du scraper, je définis toujours un agent utilisateur personnalisé en ajoutant la ligne suivante à notre code :
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36');Cela pourrait être encore amélioré en choisissant un agent utilisateur aléatoire avec chaque demande parmi un tableau des 5 agents utilisateurs les plus courants. Une liste des agents utilisateurs les plus courants peut être trouvée dans un article sur les agents utilisateurs les plus courants.
Implémentation d'un proxy
Puppeteer facilite la connexion à un proxy, car l'adresse du proxy peut être transmise à Puppeteer au lancement, comme ceci :
const browser = await puppeteer.launch({ headless: false, args: [ '--proxy-server=<PROXY-ADDRESS>' ] });sslproxies fournit une grande liste de proxys gratuits que vous pouvez utiliser. Alternativement, des services proxy rotatifs peuvent être utilisés. Comme les proxys sont généralement partagés entre de nombreux clients (ou utilisateurs gratuits dans ce cas), la connexion devient beaucoup moins fiable qu'elle ne l'est déjà dans des circonstances normales. C'est le moment idéal pour parler de la gestion des erreurs et de la gestion des nouvelles tentatives.
Gestion des erreurs et des nouvelles tentatives
De nombreux facteurs peuvent entraîner la défaillance de votre grattoir. Par conséquent, il est important de gérer les erreurs et de décider de ce qui doit se passer en cas de panne. Puisque nous avons connecté notre scraper à un proxy et que nous nous attendons à ce que la connexion soit instable (surtout parce que nous utilisons des proxys gratuits), nous voulons réessayer quatre fois avant d'abandonner.
De plus, il est inutile de réessayer une requête avec la même adresse IP si elle a déjà échoué. Par conséquent, nous allons construire un petit système de rotation de proxy .
Tout d'abord, nous créons deux nouvelles variables :
let retry = 0; let maxRetries = 5; Chaque fois que nous exécutons notre fonction scrape() , nous augmentons notre variable retry de 1. Nous enveloppons ensuite notre logique de grattage complète avec une instruction try et catch afin de pouvoir gérer les erreurs. La gestion des nouvelles tentatives se produit dans notre fonction catch :
L'instance de navigateur précédente sera fermée, et si notre variable retry est plus petite que notre variable maxRetries , la fonction scrape est appelée de manière récursive.
Notre grattoir ressemblera maintenant à ceci :
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); … // our scraping logic } catch(e) { console.log(e); await browser.close(); if (retry < maxRetries) { scrape(); } };Maintenant, ajoutons le rotateur de proxy mentionné précédemment.
Commençons par créer un tableau contenant une liste de proxy :
let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ];Maintenant, choisissez une valeur aléatoire dans le tableau :
var proxy = proxyList[Math.floor(Math.random() * proxyList.length)];Nous pouvons maintenant exécuter le proxy généré dynamiquement avec notre instance Puppeteer :
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] });Bien sûr, ce rotateur de proxy pourrait être davantage optimisé pour signaler les proxys morts, etc., mais cela dépasserait certainement le cadre de ce didacticiel.
Voici le code de notre scraper (y compris toutes les améliorations) :
const puppeteer = require('puppeteer'); // starting Puppeteer let retry = 0; let maxRetries = 5; (async function scrape() { retry++; let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ]; var proxy = proxyList[Math.floor(Math.random() * proxyList.length)]; console.log('proxy: ' + proxy); const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36'); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('select#author'); await page.select('select#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('select#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); console.log(quotes); await browser.close(); } catch (e) { await browser.close(); if (retry < maxRetries) { scrape(); } } })();Voila ! L'exécution de notre grattoir à l'intérieur de notre terminal renverra les citations.
Dramaturge comme alternative au marionnettiste
Marionnettiste a été développé par Google. Début 2020, Microsoft a publié une alternative appelée Playwright. Microsoft a recruté de nombreux ingénieurs de la Puppeteer-Team. Par conséquent, Playwright a été développé par de nombreux ingénieurs qui ont déjà mis la main sur Puppeteer. En plus d'être le nouveau venu sur le blog, le principal point de différenciation de Playwright est la prise en charge de plusieurs navigateurs, car il prend en charge Chromium, Firefox et WebKit (Safari).
Les tests de performance (comme celui-ci mené par Checkly) montrent que Puppeteer fournit généralement des performances environ 30% supérieures à celles de Playwright, ce qui correspond à ma propre expérience - du moins au moment de la rédaction.
D'autres différences, comme le fait que vous pouvez exécuter plusieurs appareils avec une seule instance de navigateur, ne sont pas vraiment utiles dans le contexte du scraping Web.
Ressources et liens supplémentaires
- Documentation Marionnettiste
- Apprentissage Marionnettiste & Dramaturge
- Web Scraping avec Javascript par Zenscrape
- Agents utilisateurs les plus courants
- Marionnettiste contre dramaturge