
Ajout de fonctionnalités dynamiques et asynchrones aux sites JAMstack
Publié: 2022-03-10Cela signifie-t-il que les sites JAMstack ne peuvent pas gérer les interactions dynamiques ? Définitivement pas!
Les sites JAMstack sont parfaits pour créer des interactions asynchrones hautement dynamiques. Avec quelques petits ajustements à la façon dont nous pensons à notre code, nous pouvons créer des interactions amusantes et immersives en utilisant uniquement des ressources statiques !
Il est de plus en plus courant de voir des sites Web construits à l'aide de JAMstack, c'est-à-dire des sites Web qui peuvent être servis sous forme de fichiers HTML statiques construits à partir de JavaScript, de balisage et d'API. Les entreprises adorent le JAMstack car il réduit les coûts d'infrastructure, accélère la livraison et réduit les obstacles à l'amélioration des performances et de la sécurité, car l'expédition d'actifs statiques élimine le besoin de mettre à l'échelle des serveurs ou de maintenir des bases de données hautement disponibles (ce qui signifie également qu'il n'y a pas de serveurs ou de bases de données qui peuvent être piraté). Les développeurs aiment le JAMstack parce qu'il réduit la complexité de la mise en ligne d'un site Web sur Internet : il n'y a pas de serveurs à gérer ou à déployer ; nous pouvons écrire du code frontal et il est mis en ligne , comme par magie .
("Magic" dans ce cas, ce sont des déploiements statiques automatisés, qui sont disponibles gratuitement auprès d'un certain nombre d'entreprises, y compris Netlify, où je travaille.)
Mais si vous passez beaucoup de temps à parler aux développeurs de la JAMstack, la question de savoir si la JAMstack peut ou non gérer les applications Web sérieuses se posera. Après tout, les sites JAMstack sont des sites statiques, n'est-ce pas ? Et les sites statiques ne sont-ils pas très limités dans ce qu'ils peuvent faire ?
Il s'agit d'une idée fausse très courante, et dans cet article, nous allons plonger dans l'origine de l'idée fausse, examiner les capacités de la JAMstack et parcourir plusieurs exemples d'utilisation de la JAMstack pour créer des applications Web sérieuses.
Fondamentaux de JAMstack
Phil Hawksworth explique ce que JAMStack signifie réellement et quand il est judicieux de l'utiliser dans vos projets, ainsi que son impact sur l'outillage et l'architecture frontale. Lire un article connexe →
Qu'est-ce qui rend un site JAMstack "statique" ?
Les navigateurs Web chargent aujourd'hui des fichiers HTML, CSS et JavaScript, comme ils le faisaient dans les années 90.
Un site JAMstack, à la base, est un dossier rempli de fichiers HTML, CSS et JavaScript.
Ce sont des "actifs statiques", ce qui signifie que nous n'avons pas besoin d'étape intermédiaire pour les générer (par exemple, les projets PHP comme WordPress ont besoin d'un serveur pour générer le HTML à chaque requête).
C'est la véritable puissance du JAMstack : il ne nécessite aucune infrastructure spécialisée pour fonctionner. Vous pouvez exécuter un site JAMstack sur votre ordinateur local, en le plaçant sur votre réseau de diffusion de contenu (CDN) préféré, en l'hébergant avec des services tels que GitHub Pages - vous pouvez même faire glisser et déposer le dossier dans votre client FTP préféré pour le télécharger. à l'hébergement mutualisé.
Les actifs statiques ne signifient pas nécessairement des expériences statiques
Étant donné que les sites JAMstack sont constitués de fichiers statiques, il est facile de supposer que l'expérience sur ces sites est, vous savez, statique . Mais ce n'est pas le cas !
JavaScript est capable de faire beaucoup de choses dynamiques. Après tout, les frameworks JavaScript modernes sont des fichiers statiques une fois l'étape de construction terminée - et il existe des centaines d'exemples d'expériences de sites Web incroyablement dynamiques alimentées par eux.
Il y a une idée fausse commune selon laquelle « statique » signifie inflexible ou fixe. Mais tout ce que "statique" signifie vraiment dans le contexte des "sites statiques", c'est que les navigateurs n'ont pas besoin d'aide pour diffuser leur contenu - ils sont capables de les utiliser nativement sans qu'un serveur ne gère d'abord une étape de traitement.
Ou, mis d'une autre manière:
« Actifs statiques » ne signifie pas des applications statiques ; cela signifie qu'aucun serveur n'est requis.
"
Le JAMstack peut-il faire cela ?
Si quelqu'un pose des questions sur la création d'une nouvelle application, il est courant de voir des suggestions d'approches JAMstack telles que Gatsby, Eleventy, Nuxt et d'autres outils similaires. Il est également courant de voir des objections surgir : « les générateurs de sites statiques ne peuvent pas faire _______ », où _______ est quelque chose de dynamique.
Mais - comme nous l'avons évoqué dans la section précédente - les sites JAMstack peuvent gérer du contenu et des interactions dynamiques !
Voici une liste incomplète de choses que j'ai entendues à plusieurs reprises dire que le JAMstack ne peut pas gérer qu'il le peut définitivement :
- Charger les données de manière asynchrone
- Gérer les fichiers de traitement, tels que la manipulation d'images
- Lire et écrire dans une base de données
- Gérer l'authentification des utilisateurs et protéger le contenu derrière une connexion
Dans les sections suivantes, nous verrons comment mettre en œuvre chacun de ces workflows sur un site JAMstack.
Si vous avez hâte de voir le JAMstack dynamique en action, vous pouvez d'abord consulter les démos, puis revenir et apprendre comment elles fonctionnent.
Une note sur les démos :
Ces démos sont écrites sans aucun framework. Ce ne sont que du HTML, du CSS et du JavaScript standard. Ils ont été conçus pour les navigateurs modernes (par exemple Chrome, Firefox, Safari, Edge) et tirent parti des nouvelles fonctionnalités telles que les modules JavaScript, les modèles HTML et l'API Fetch. Aucun polyfill n'a été ajouté, donc si vous utilisez un navigateur non pris en charge, les démos échoueront probablement.
Charger des données à partir d'une API tierce de manière asynchrone
« Et si j'ai besoin d'obtenir de nouvelles données après la création de mes fichiers statiques ? »
Dans le JAMstack, nous pouvons tirer parti de nombreuses bibliothèques de requêtes asynchrones, y compris l'API Fetch intégrée, pour charger des données à l'aide de JavaScript à tout moment.
Démo : rechercher une API tierce à partir d'un site JAMstack
Un scénario courant qui nécessite un chargement asynchrone est lorsque le contenu dont nous avons besoin dépend de l'entrée de l'utilisateur. Par exemple, si nous créons une page de recherche pour l ' API Rick & Morty , nous ne savons pas quel contenu afficher tant que quelqu'un n'a pas saisi un terme de recherche.
Pour gérer cela, nous devons :
- Créer un formulaire où les gens peuvent taper leur terme de recherche,
- Écoutez une soumission de formulaire,
- Obtenez le terme de recherche à partir de la soumission du formulaire,
- Envoyez une requête asynchrone à l'API Rick & Morty en utilisant le terme de recherche,
- Affichez les résultats de la demande sur la page.
Tout d'abord, nous devons créer un formulaire et un élément vide qui contiendra nos résultats de recherche, qui ressemble à ceci :
<form> <label for="name">Find characters by name</label> <input type="text" name="name" required /> <button type="submit">Search</button> </form> <ul></ul>Ensuite, nous devons écrire une fonction qui gère les soumissions de formulaires. Cette fonction va :
- Empêcher le comportement de soumission de formulaire par défaut
- Obtenir le terme de recherche à partir de l'entrée du formulaire
- Utilisez l'API Fetch pour envoyer une requête à l'API Rick & Morty en utilisant le terme de recherche
- Appeler une fonction d'assistance qui affiche les résultats de la recherche sur la page
Nous devons également ajouter un écouteur d'événement sur le formulaire pour l'événement submit qui appelle notre fonction de gestionnaire.
Voici à quoi ressemble ce code :
<script type="module"> import showResults from './show-results.js'; const form = document.querySelector('form'); const handleSubmit = async event => { event.preventDefault(); // get the search term from the form input const name = form.elements['name'].value; // send a request to the Rick & Morty API based on the user input const characters = await fetch( `https://rickandmortyapi.com/api/character/?name=${name}`, ) .then(response => response.json()) .catch(error => console.error(error)); // add the search results to the DOM showResults(characters.results); }; form.addEventListener('submit', handleSubmit); </script>Remarque : pour rester concentré sur les comportements dynamiques de JAMstack, nous ne discuterons pas de la manière dont les fonctions utilitaires telles que showResults sont écrites. Le code est commenté en détail, alors consultez la source pour savoir comment cela fonctionne !
Avec ce code en place, nous pouvons charger notre site dans un navigateur et nous verrons le formulaire vide sans aucun résultat :
Si nous entrons un nom de personnage (par exemple "rick") et cliquez sur "rechercher", nous voyons une liste de personnages dont les noms contiennent "rick" s'afficher :
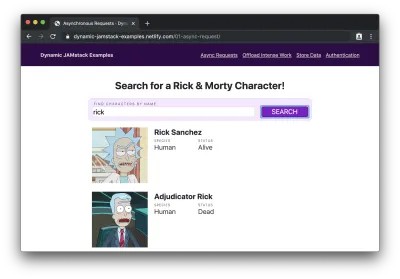
Hé! Ce site statique a-t-il simplement chargé dynamiquement des données ? Sacrés seaux !
Vous pouvez l'essayer par vous-même sur la démo en direct ou consulter le code source complet pour plus de détails.
Gérer les tâches informatiques coûteuses hors de l'appareil de l'utilisateur
Dans de nombreuses applications, nous devons faire des choses qui demandent beaucoup de ressources, comme le traitement d'une image. Bien que certains de ces types d'opérations soient possibles en utilisant uniquement JavaScript côté client, ce n'est pas nécessairement une bonne idée de faire en sorte que les appareils de vos utilisateurs fassent tout ce travail. S'ils utilisent un appareil à faible puissance ou s'ils essaient d'allonger les 5 % restants de la durée de vie de leur batterie, faire en sorte que leur appareil fasse beaucoup de travail sera probablement une expérience frustrante pour eux.
Cela signifie-t-il que les applications JAMstack n'ont pas de chance ? Pas du tout!
Le "A" dans JAMstack signifie API. Cela signifie que nous pouvons envoyer ce travail à une API et éviter de faire tourner les ventilateurs de l'ordinateur de nos utilisateurs jusqu'au paramètre « survol ».
"Mais attendez", pourriez-vous dire. "Si notre application doit effectuer un travail personnalisé et que ce travail nécessite une API, cela ne signifie-t-il pas simplement que nous construisons un serveur ?"
Grâce à la puissance des fonctions sans serveur, nous n'avons pas à le faire !
Les fonctions sans serveur (également appelées «fonctions lambda») sont une sorte d'API sans qu'aucun serveur standard ne soit requis. Nous pouvons écrire une ancienne fonction JavaScript, et tout le travail de déploiement, de mise à l'échelle, de routage, etc. est transféré à notre fournisseur sans serveur de choix.
L'utilisation de fonctions sans serveur ne signifie pas qu'il n'y a pas de serveur ; cela signifie simplement que nous n'avons pas besoin de penser à un serveur.
"
Les fonctions sans serveur sont le beurre de cacahuète de notre JAMstack : elles débloquent tout un monde de fonctionnalités dynamiques et puissantes sans jamais nous demander de gérer le code du serveur ou les devops.
Démo : Convertir une image en niveaux de gris
Supposons que nous ayons une application qui doit :
- Télécharger une image à partir d'une URL
- Convertir cette image en niveaux de gris
- Téléchargez l'image convertie dans un dépôt GitHub
Autant que je sache, il n'y a aucun moyen de faire des conversions d'images comme ça entièrement dans le navigateur - et même s'il y en avait, c'est une chose assez gourmande en ressources à faire, donc nous ne voulons probablement pas mettre cette charge sur nos utilisateurs ' dispositifs.
Au lieu de cela, nous pouvons soumettre l'URL à convertir en une fonction sans serveur, qui fera le gros du travail pour nous et renverra une URL à une image convertie.
Pour notre fonction sans serveur, nous utiliserons les fonctions Netlify. Dans le code de notre site, nous ajoutons un dossier au niveau racine appelé "fonctions" et créons un nouveau fichier appelé "convert-image.js" à l'intérieur. Ensuite, nous écrivons ce qu'on appelle un gestionnaire, qui est ce qui reçoit et - comme vous l'avez peut-être deviné - gère les demandes adressées à notre fonction sans serveur.
Pour convertir une image, cela ressemble à ceci :
exports.handler = async event => { // only try to handle POST requests if (event.httpMethod !== 'POST') { return { statusCode: 404, body: '404 Not Found' }; } try { // get the image URL from the POST submission const { imageURL } = JSON.parse(event.body); // use a temporary directory to avoid intermediate file cruft // see https://www.npmjs.com/package/tmp const tmpDir = tmp.dirSync(); const convertedPath = await convertToGrayscale(imageURL, tmpDir); // upload the processed image to GitHub const response = await uploadToGitHub(convertedPath, tmpDir.name); return { statusCode: 200, body: JSON.stringify({ url: response.data.content.download_url, }), }; } catch (error) { return { statusCode: 500, body: JSON.stringify(error.message), }; } };Cette fonction effectue les opérations suivantes :
- Vérifie que la demande a été envoyée à l'aide de la méthode HTTP POST
- Attrape l'URL de l'image à partir du corps POST
- Crée un répertoire temporaire pour stocker les fichiers qui seront nettoyés une fois l'exécution de la fonction terminée
- Appelle une fonction d'assistance qui convertit l'image en niveaux de gris
- Appelle une fonction d'assistance qui télécharge l'image convertie sur GitHub
- Renvoie un objet de réponse avec un code d'état HTTP 200 et l'URL de l'image nouvellement téléchargée
Note : Nous n'expliquerons pas comment fonctionne l'assistant pour la conversion d'image ou le téléchargement sur GitHub, mais le code source est bien commenté afin que vous puissiez voir comment cela fonctionne.
Ensuite, nous devons ajouter un formulaire qui sera utilisé pour soumettre les URL à traiter et un endroit pour afficher l'avant et l'après :
<form action="/.netlify/functions/convert-image" method="POST" > <label for="imageURL">URL of an image to convert</label> <input type="url" name="imageURL" required /> <button type="submit">Convert</button> </form> <div></div>Enfin, nous devons ajouter un écouteur d'événement au formulaire afin de pouvoir envoyer les URL à notre fonction sans serveur pour traitement :
<script type="module"> import showResults from './show-results.js'; const form = document.querySelector('form'); form.addEventListener('submit', event => { event.preventDefault(); // get the image URL from the form const imageURL = form.elements['imageURL'].value; // send the image off for processing const promise = fetch('/.netlify/functions/convert-image', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ imageURL }), }) .then(result => result.json()) .catch(error => console.error(error)); // do the work to show the result on the page showResults(imageURL, promise); }); </script>Après avoir déployé le site (avec son nouveau dossier « fonctions ») sur Netlify et/ou démarré Netlify Dev dans notre CLI, nous pouvons voir le formulaire dans notre navigateur :
Si nous ajoutons une URL d'image au formulaire et cliquons sur "convertir", nous verrons "traitement…" pendant un moment pendant que la conversion se produit, puis nous verrons l'image d'origine et sa contrepartie en niveaux de gris nouvellement créée :

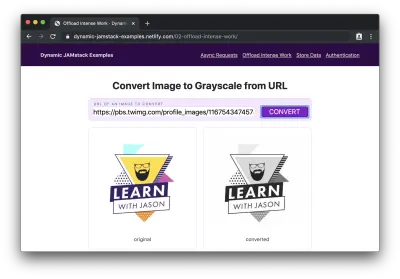
Oh putain ! Notre site JAMstack vient de gérer des affaires assez sérieuses et nous n'avons pas eu à penser aux serveurs une seule fois ni à vider les batteries de nos utilisateurs !
Utiliser une base de données pour stocker et récupérer des entrées
Dans de nombreuses applications, nous aurons inévitablement besoin de la possibilité d'enregistrer les entrées de l'utilisateur. Et cela signifie que nous avons besoin d'une base de données.
Vous pensez peut-être : « Alors c'est ça, n'est-ce pas ? Le gabarit est en place ? Un site JAMstack - dont vous nous avez dit qu'il n'est qu'une collection de fichiers dans un dossier - ne peut certainement pas être connecté à une base de données !
Au contraire.
Comme nous l'avons vu dans la section précédente, les fonctions sans serveur nous permettent de faire toutes sortes de choses puissantes sans avoir à créer nos propres serveurs.
De même, nous pouvons utiliser des outils de base de données en tant que service (DBaaS) (tels que Fauna) pour lire et écrire dans une base de données sans avoir à en créer une ou à l'héberger nous-mêmes.
Les outils DBaaS simplifient considérablement le processus de configuration des bases de données pour les sites Web : la création d'une nouvelle base de données est aussi simple que la définition des types de données que nous voulons stocker. Les outils génèrent automatiquement tout le code pour gérer les opérations de création, de lecture, de mise à jour et de suppression (CRUD) et le rendent disponible pour que nous l'utilisions via l'API, nous n'avons donc pas à gérer réellement une base de données ; nous arrivons juste à l' utiliser .
Démo : créer une page de pétition
Si nous voulons créer une petite application pour collecter des signatures numériques pour une pétition, nous devons créer une base de données pour stocker ces signatures et permettre à la page de les lire pour les afficher.
Pour cette démo, nous utiliserons Fauna comme fournisseur DBaaS. Nous n'entrerons pas dans les détails du fonctionnement de Fauna, mais dans le but de démontrer le peu d'effort requis pour configurer une base de données, énumérons chaque étape et cliquez pour obtenir une base de données prête à l'emploi :
- Créez un compte Fauna sur https://fauna.com
- Cliquez sur "créer une nouvelle base de données"
- Donnez un nom à la base de données (par exemple "dynamic-jamstack-demos")
- Cliquez sur "créer"
- Cliquez sur "sécurité" dans le menu de gauche sur la page suivante
- Cliquez sur "nouvelle clé"
- Changez le menu déroulant du rôle en "Serveur"
- Ajoutez un nom pour la clé (par exemple "Dynamic JAMstack Demos")
- Conservez la clé dans un endroit sûr pour l'utiliser avec l'application
- Cliquez sur "enregistrer"
- Cliquez sur "GraphQL" dans le menu de gauche
- Cliquez sur "importer le schéma"
- Importez un fichier appelé
db-schema.gqlcontenant le code suivant :
type Signature { name: String! } type Query { signatures: [Signature!]! }Une fois que nous téléchargeons le schéma, notre base de données est prête à être utilisée. (Sérieusement.)
Treize étapes, c'est beaucoup, mais avec ces treize étapes, nous venons d'avoir une base de données, une API GraphQL, la gestion automatique de la capacité, la mise à l'échelle, le déploiement, la sécurité, etc., le tout géré par des experts en bases de données. Gratuitement. Quel temps pour vivre!
Pour l'essayer, l'option "GraphQL" dans le menu de gauche nous donne un explorateur GraphQL avec une documentation sur les requêtes et les mutations disponibles qui nous permettent d'effectuer des opérations CRUD.
Remarque : Nous n'entrerons pas dans les détails des requêtes et des mutations GraphQL dans cet article, mais Eve Porcello a écrit une excellente introduction à l'envoi de requêtes et de mutations GraphQL si vous voulez une introduction à son fonctionnement.
Avec la base de données prête à fonctionner, nous pouvons créer une fonction sans serveur qui stocke les nouvelles signatures dans la base de données :
const qs = require('querystring'); const graphql = require('./util/graphql'); exports.handler = async event => { try { // get the signature from the POST data const { signature } = qs.parse(event.body); const ADD_SIGNATURE = ` mutation($signature: String!) { createSignature(data: { name: $signature }) { _id } } `; // store the signature in the database await graphql(ADD_SIGNATURE, { signature }); // send people back to the petition page return { statusCode: 302, headers: { Location: '/03-store-data/', }, // body is unused in 3xx codes, but required in all function responses body: 'redirecting...', }; } catch (error) { return { statusCode: 500, body: JSON.stringify(error.message), }; } };Cette fonction effectue les opérations suivantes :
- Récupère la valeur de la signature à partir des données
POSTdu formulaire - Appelle une fonction d'assistance qui stocke la signature dans la base de données
- Définit une mutation GraphQL pour écrire dans la base de données
- Envoie la mutation à l'aide d'une fonction d'assistance GraphQL
- Redirige vers la page qui a soumis les données
Ensuite, nous avons besoin d'une fonction sans serveur pour lire toutes les signatures de la base de données afin que nous puissions montrer combien de personnes soutiennent notre pétition :
const graphql = require('./util/graphql'); exports.handler = async () => { const { signatures } = await graphql(` query { signatures { data { name } } } `); return { statusCode: 200, body: JSON.stringify(signatures.data), }; };Cette fonction envoie une requête et la renvoie.
Une note importante sur les clés sensibles et les applications JAMstack :
Une chose à noter à propos de cette application est que nous utilisons des fonctions sans serveur pour effectuer ces appels car nous devons transmettre une clé de serveur privée à Fauna qui prouve que nous avons un accès en lecture et en écriture à cette base de données. Nous ne pouvons pas mettre cette clé dans le code côté client, car cela signifierait que n'importe qui pourrait la trouver dans le code source et l'utiliser pour effectuer des opérations CRUD sur notre base de données. Les fonctions sans serveur sont essentielles pour garder les clés privées privées dans les applications JAMstack.
Une fois que nous avons configuré nos fonctions sans serveur, nous pouvons ajouter un formulaire qui se soumet à la fonction pour ajouter une signature, un élément pour afficher les signatures existantes et un peu de JS pour appeler la fonction pour obtenir des signatures et les mettre dans notre affichage élément:
<form action="/.netlify/functions/add-signature" method="POST"> <label for="signature">Your name</label> <input type="text" name="signature" required /> <button type="submit">Sign</button> </form> <ul class="signatures"></ul> <script> fetch('/.netlify/functions/get-signatures') .then(res => res.json()) .then(names => { const signatures = document.querySelector('.signatures'); names.forEach(({ name }) => { const li = document.createElement('li'); li.innerText = name; signatures.appendChild(li); }); }); </script>Si nous chargeons ceci dans le navigateur, nous verrons notre formulaire de pétition avec des signatures en dessous :
Ensuite, si nous ajoutons notre signature…
…et soumettez-le, nous verrons notre nom ajouté au bas de la liste :
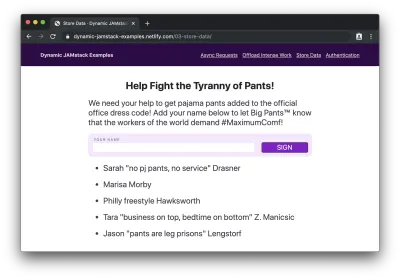
Chien diggity chaud! Nous venons d'écrire une application JAMstack complète alimentée par une base de données avec environ 75 lignes de code et 7 lignes de schéma de base de données !
Protégez le contenu avec l'authentification de l'utilisateur
"D'accord, vous êtes certainement coincé cette fois", pensez-vous peut-être. "Il n'y a aucun moyen qu'un site JAMstack puisse gérer l'authentification des utilisateurs. Comment diable cela fonctionnerait-il, même ? !"
Je vais vous dire comment cela fonctionne, mon ami : avec nos fonctions sans serveur de confiance et OAuth.
OAuth est une norme largement adoptée pour permettre aux utilisateurs de donner aux applications un accès limité aux informations de leur compte plutôt que de partager leurs mots de passe. Si vous vous êtes déjà connecté à un service en utilisant un autre service (par exemple, « connectez-vous avec votre compte Google »), vous avez déjà utilisé OAuth.
Remarque : Nous n'allons pas approfondir le fonctionnement d'OAuth, mais Aaron Parecki a rédigé un solide aperçu d'OAuth qui couvre les détails et le flux de travail.
Dans les applications JAMstack, nous pouvons tirer parti d'OAuth et des jetons Web JSON (JWT) qu'il nous fournit pour identifier les utilisateurs, protéger le contenu et autoriser uniquement les utilisateurs connectés à le voir.
Démo : Connexion requise pour afficher le contenu protégé
Si nous devons créer un site qui ne montre du contenu qu'aux utilisateurs connectés, nous avons besoin de quelques éléments :
- Un fournisseur d'identité qui gère les utilisateurs et le flux de connexion
- Éléments d'interface utilisateur pour gérer la connexion et la déconnexion
- Une fonction sans serveur qui recherche un utilisateur connecté à l'aide de JWT et renvoie le contenu protégé s'il en existe un
Pour cet exemple, nous utiliserons Netlify Identity, qui nous offre une expérience de développeur vraiment agréable pour ajouter l'authentification et fournit un widget intégré pour gérer les actions de connexion et de déconnexion.
Pour l'activer :
- Visitez votre tableau de bord Netlify
- Choisissez le site qui a besoin d'authentification dans votre liste de sites
- Cliquez sur "Identité" dans la barre de navigation supérieure
- Cliquez sur le bouton "Activer l'identité"
Nous pouvons ajouter Netlify Identity à notre site en ajoutant un balisage qui affiche le contenu déconnecté et ajoute un élément pour afficher le contenu protégé après la connexion :
<div class="content logged-out"> <h1>Super Secret Stuff!</h1> <p> only my bestest friends can see this content</p> <button class="login">log in / sign up to be my best friend</button> </div> <div class="content logged-in"> <div class="secret-stuff"></div> <button class="logout">log out</button> </div>Ce balisage s'appuie sur CSS pour afficher le contenu selon que l'utilisateur est connecté ou non. Cependant, nous ne pouvons pas compter là-dessus pour protéger réellement le contenu - n'importe qui pourrait voir le code source et voler nos secrets !
Au lieu de cela, nous avons créé une div vide qui contiendra notre contenu protégé, mais nous devrons faire une demande à une fonction sans serveur pour obtenir ce contenu. Nous verrons comment cela fonctionne sous peu.
Ensuite, nous devons ajouter du code pour faire fonctionner notre bouton de connexion, charger le contenu protégé et l'afficher à l'écran :
<script src="https://identity.netlify.com/v1/netlify-identity-widget.js"></script> <script> const login = document.querySelector('.login'); login.addEventListener('click', () => { netlifyIdentity.open(); }); const logout = document.querySelector('.logout'); logout.addEventListener('click', () => { netlifyIdentity.logout(); }); netlifyIdentity.on('logout', () => { document.querySelector('body').classList.remove('authenticated'); }); netlifyIdentity.on('login', async () => { document.querySelector('body').classList.add('authenticated'); const token = await netlifyIdentity.currentUser().jwt(); const response = await fetch('/.netlify/functions/get-secret-content', { headers: { Authorization: `Bearer ${token}`, }, }).then(res => res.text()); document.querySelector('.secret-stuff').innerHTML = response; }); </script>Voici ce que fait ce code :
- Charge le widget Netlify Identity, qui est une bibliothèque d'assistance qui crée un modal de connexion, gère le flux de travail OAuth avec Netlify Identity et donne à notre application l'accès aux informations de l'utilisateur connecté
- Ajoute un écouteur d'événement au bouton de connexion qui déclenche l'ouverture du modal de connexion Netlify Identity
- Ajoute un écouteur d'événement au bouton de déconnexion qui appelle la méthode de déconnexion Netlify Identity
- Ajoute un gestionnaire d'événements pour la déconnexion afin de supprimer la classe authentifiée lors de la déconnexion, qui masque le contenu connecté et affiche le contenu déconnecté
- Ajoute un gestionnaire d'événements pour la connexion qui :
- Ajoute la classe authentifiée pour afficher le contenu connecté et masquer le contenu déconnecté
- Saisit le JWT de l'utilisateur connecté
- Appelle une fonction sans serveur pour charger le contenu protégé, en envoyant le JWT dans l'en-tête d'autorisation
- Place le contenu secret dans la div secret-stuff afin que les utilisateurs connectés puissent le voir
À l'heure actuelle, la fonction sans serveur que nous appelons dans ce code n'existe pas. Créons-le avec le code suivant :
exports.handler = async (_event, context) => { try { const { user } = context.clientContext; if (!user) throw new Error('Not Authorized'); return { statusCode: 200, headers: { 'Content-Type': 'text/html', }, body: `Vous êtes invité, ${user.user_metadata.full_name} !
Si vous pouvez lire ceci, cela signifie que nous sommes les meilleurs amis.
Voici les détails secrets pour ma fête d'anniversaire :
`, } ; } capture (erreur) { retourner { code d'état : 401, body : 'Non autorisé', } ; } } ;
jason.af/party
Cette fonction effectue les opérations suivantes :
- Recherche un utilisateur dans l'argument de contexte de la fonction sans serveur
- Génère une erreur si aucun utilisateur n'est trouvé
- Renvoie le contenu secret après s'être assuré qu'un utilisateur connecté l'a demandé
Les fonctions Netlify détecteront les JWT Netlify Identity dans les en-têtes d'autorisation et mettront automatiquement ces informations en contexte - cela signifie que nous pouvons vérifier un JWT valide sans avoir à écrire de code pour valider les JWT !
Lorsque nous chargeons cette page dans notre navigateur, nous verrons d'abord la page de déconnexion :
Si nous cliquons sur le bouton pour nous connecter, nous verrons le widget Netlify Identity :
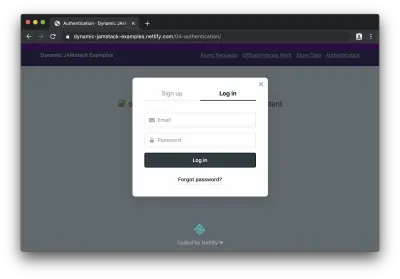
Après la connexion (ou l'inscription), nous pouvons voir le contenu protégé :
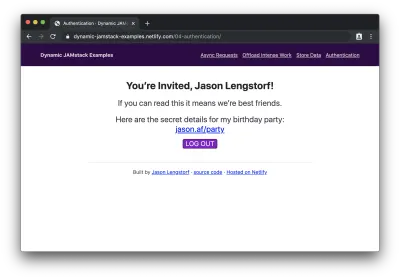
Waouh ! Nous venons d'ajouter la connexion utilisateur et le contenu protégé à une application JAMstack !
Que faire ensuite
Le JAMstack est bien plus que de «simples sites statiques» - nous pouvons répondre aux interactions des utilisateurs, stocker des données, gérer l'authentification des utilisateurs et à peu près tout ce que nous voulons faire sur un site Web moderne. Et tout cela sans avoir à provisionner, configurer ou déployer un serveur !
Que voulez-vous construire avec le JAMstack ? Y a-t-il quelque chose que vous n'êtes toujours pas convaincu que le JAMstack peut gérer ? J'aimerais en entendre parler — contactez-moi sur Twitter ou dans les commentaires !