
Développer pour le Web sémantique
Publié: 2022-03-10En juillet, la Wikimedia Foundation a annoncé Abstract Wikipedia, une tentative de balisage des connaissances indépendantes de la langue. À bien des égards, c'est l'aboutissement de décennies de construction, au cours desquelles le rêve d'un Web sémantique n'a jamais tout à fait décollé, mais n'a jamais tout à fait disparu non plus.
En fait, le Web sémantique se développe et, à mesure qu'il renouvelle sa mission, nous avons tous à gagner à intégrer le balisage sémantique dans nos sites Web, qu'il s'agisse de blogs personnels ou de géants des médias sociaux. Que vous vous souciez des expériences Web sophistiquées, du référencement ou de la lutte contre la tyrannie des monopoles du Web, le Web sémantique mérite notre attention.
Les avantages du développement pour le Web sémantique ne sont pas toujours immédiats ou visibles, mais chaque site qui le fait renforce les fondations d'un Internet ouvert, transparent et décentralisé.
Le Web sémantique
Qu'est-ce que le Web sémantique exactement ? Il s'agit d'un site Web lisible par machine, fournissant par le biais de métadonnées "un cadre commun qui permet aux données d'être partagées et réutilisées au-delà des limites des applications, des entreprises et des communautés".
L'idée est aussi vieille que le World Wide Web lui-même. Plus vieux, en fait. C'était un point central de la proposition de Tim Berners-Lee en 1989. Comme il l'a souligné, non seulement les documents doivent former des toiles, mais les données qu'ils contiennent doivent également :
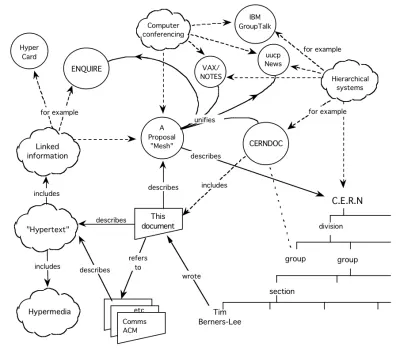
Le Web sémantique a parcouru un chemin semé d'embûches au cours des décennies qui ont suivi. Depuis le tournant du millénaire, il s'est transformé en plusieurs concepts - données ouvertes, graphes de connaissances - signifiant tous en fait la même chose : des réseaux de données.
Comme le résume le W3C, il s'agit "d'une extension du Web actuel dans lequel l'information prend une signification bien définie, permettant mieux aux ordinateurs et aux personnes de travailler en coopération".

L'idée a eu son lot de partisans. Le hacktiviste Internet Aaron Swartz a écrit un manuscrit sur le Web sémantique intitulé A Programmable Web . Il y écrit :
« Les documents ne peuvent pas vraiment être fusionnés, intégrés et interrogés ; ils servent principalement d'instances isolées à visualiser et à réviser. Mais les données sont protéiformes, capables de prendre la forme qui convient le mieux à vos besoins. »
Pour diverses raisons, le Web sémantique n'a pas décollé de la même manière que le Web, même s'il rattrape son retard. Plusieurs balisages ont tenté de s'emparer du manteau au fil des ans - RDFa, OWL et Schema pour n'en nommer que quelques-uns - bien qu'aucun ne soit devenu standard de la manière, disons, HTML ou CSS. La barrière à l'entrée était trop haute.
Cependant, le rêve du Web sémantique a perduré, et comme de plus en plus de sites l'intègrent dans leurs conceptions, il y a d'autant plus de raisons de se joindre à la fête. Plus il y a de sites qui embarquent, plus le Web sémantique devient fort.
Lectures complémentaires
- Intelligence des données
- The Semantic Web , un article de 2001 de Tim Berners-Lee, James Hensley et Ora Lassila
- Groupe communautaire Web crédible au W3C
Savoir sans frontières
Avant d'entrer dans les détails de la conception pour le Web sémantique, il vaut la peine d'approfondir un peu le pourquoi . Qu'importe que les données soient connectées ? Les documents connectés ne suffisent-ils pas ?
Il y a plusieurs raisons pour lesquelles le Web sémantique continue d'être poussé par ceux qui se soucient d'un Internet libre et ouvert. Comprendre ces raisons est essentiel au processus de mise en œuvre. Il ne devrait pas s'agir de "mangez vos légumes, utilisez un balisage sémantique". Le Web sémantique est une chose à laquelle croire et dont il faut faire partie.
Les avantages du Web sémantique incluent :
- Des expériences Web plus riches et plus sophistiquées
- Contourner les silos de contenu et les monopoles Internet
- Amélioration de la lisibilité et des classements des moteurs de recherche
- Démocratisation de l'information
La plupart d'entre eux remontent à un principe fondamental du Web sémantique : un langage universel pour les données. Bien qu'Internet ait déjà fait des merveilles pour la communication internationale, il est indéniable que certains pays l'ont bien mieux que d'autres. Prenez les langues utilisées sur le Web par rapport aux langues utilisées dans le monde réel, par exemple. Les plus perspicaces parmi vous pourront peut-être repérer un léger déséquilibre dans les données ci-dessous…
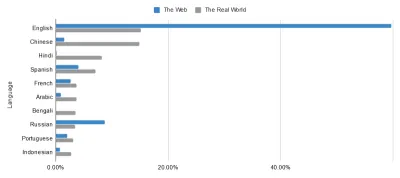
L'utopie sans frontières du Web n'est pas aussi proche qu'elle pourrait le sembler à ceux d'entre nous à l'intérieur de la bulle anglophone. Est-ce quelque chose pour qui châtier quelqu'un? Pas nécessairement, mais c'est quelque chose à affronter. Cela met en évidence l'importance du balisage qui comble ces lacunes. En enrichissant les données du web, on soulage ses langages.
C'est le cœur de la Wikipédia abstraite récemment annoncée, qui tentera de dissocier les articles de la langue dans laquelle ils sont écrits. La directrice exécutive de Wikimedia, Katherine Maher, écrit : leurs propres langues. En cas de succès, cela pourrait éventuellement permettre à chacun de lire sur n'importe quel sujet dans Wikidata dans sa propre langue.
Résumé Le créateur de Wikipédia, Denny Vrandecic, est un défenseur du Web sémantique depuis des années, reconnaissant son potentiel à libérer un potentiel inexploité en ligne. L'élimination des barrières nationales est essentielle à ce processus.
"Peu importe la langue dans laquelle vous publiez votre contenu, vous allez manquer d'inclure la grande majorité des gens dans le monde. Le Web nous a donné cette merveilleuse opportunité d'avoir une portée mondiale - mais en nous appuyant sur une seule langue, ou un petit ensemble de langues, nous gaspillons cette opportunité. Alors que l'objectif le plus important est de créer un bon contenu en premier lieu, vous invitez plus de personnes à participer au développement d'un meilleur contenu en étant indépendant de la langue. Cela vous aide à réduire les obstacles à la contribution et à la consommation, et cela permet à beaucoup plus de personnes de bénéficier de cet effort. »
— Denny Vrandecic, créateur de Wikipédia abstrait
Un exemple opportun de cela a été la visualisation des données pendant la pandémie de COVID-19. Le virus a fait des ravages indescriptibles dans le monde entier, mais il a également été un moment brillant pour les réseaux de données ouverts, permettant à de superbes applications Web, des rapports et bien plus encore d'être communs sur le Web.
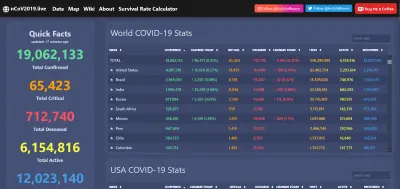
Et bien sûr, lorsque les données sont transparentes et facilement accessibles, cela facilite l'identification des anomalies… ou carrément des tromperies. Un accès public généralisé au type d'informations ci-dessus serait impensable il y a encore 20 ans. Maintenant, nous l'attendons et sentons un rat quand il nous est refusé. Les données sont puissantes et, si nous le voulons, peuvent être utilisées pour de bon.
De même, nous extraire des silos de contenu - une caractéristique de l'expérience Web moderne - enlève du pouvoir aux monopoles du Web tels que Google, Facebook et Twitter. Nous sommes tellement habitués à ce que des plateformes tierces déchiffrent et présentent des informations que nous oublions qu'elles ne sont pas strictement nécessaires.
"Si nous avions des formats partagés, des protocoles partagés, nous pourrions encore nous retrouver avec certains fournisseurs jouant un rôle important sur certains marchés - pensez à Gmail pour le courrier électronique - mais tout le monde est libre de passer à un autre fournisseur, et le marché reste concurrentiel."
— Denny Vrandecic, créateur de Wikipédia abstrait
Le Web sémantique est sans silo ; il est gratuit, ouvert et abstrait, permettant une communication entre différentes langues et plates-formes qui serait autrement beaucoup plus difficile.
Contenu en ligne axé sur les données
Concevoir pour le Web sémantique se résume à un contenu en ligne axé sur les données - en examinant votre contenu et en voyant ce qui peut (et devrait) être abstrait. Qu'est-ce que cela signifie en termes pratiques, au-delà de convenir vaguement que c'est une chose valable à faire ? Ça dépend:
- Si vous démarrez un projet à partir de zéro, intégrez les considérations du Web sémantique dans ce que vous faites. Au fur et à mesure qu'un site Web prend forme, intégrez le balisage sémantique dans son ADN.
- Si vous mettez à jour ou reconstruisez un projet, évaluez ce qui pourrait être tissé dans le Web sémantique qui ne l'est pas actuellement, puis mettez-le en œuvre.
Les deux cas équivalent essentiellement à un contenu de données. Dans cette section, nous allons passer en revue quelques exemples d'abstraction de données et comment elle peut rendre le contenu meilleur, plus intelligent et plus largement disponible.
Résumé des informations
Concevoir et développer pour le Web sémantique signifie regarder le contenu en ligne avec votre chapeau de données. La plupart d'entre nous percevons le Web comme une série de documents ou de pages connectés ; ce que vous voulez faire avec le Web sémantique, ce sont des informations de connexion. Cela signifie évaluer votre contenu pour les points de données, puis ajuster la conception en fonction de ce que vous trouvez.
James Hendler, défenseur du Web sémantique, décrit particulièrement bien ce processus avec sa philosophie DIVE. ( PLONGEZ dans les données, hein ? Eh ?). Il se décompose comme suit :
- Découvrir
Trouvez des ensembles de données et/ou du contenu (y compris en dehors de votre propre organisation). - Intégrer
Reliez les relations à l'aide d'étiquettes significatives. - Valider
Fournir des entrées aux systèmes de modélisation et de simulation. - Explorer
Développer des approches pour transformer les données en connaissances exploitables.
Développer pour le Web sémantique consiste en grande partie à avoir une vue d'ensemble de ce que vous faites, et comment cela alimente potentiellement des expériences Web infiniment plus riches. Comme le dit Hendler, la connaissance exploitable est l'objectif.
Cela peut vraiment s'appliquer à presque tous les types de contenu Web, mais commençons par un exemple courant : les recettes . Disons que vous dirigez un blog de cuisine, avec de nouvelles recettes tous les jeudis. Si vous êtes français et publiez une recette de soufflé sensationnelle sur votre blog personnel en texte brut, cela n'est utile que pour ceux qui savent lire le français.
Cependant, en mettant en œuvre un balisage sémantique, le blog peut être transformé en un ensemble de données de recette lisible par machine. Il existe une syntaxe pour les termes de cuisine à extraire. Le schéma, par exemple, qui peut fonctionner avec Microdata, RDFa ou JSON-LD, a un balisage comprenant :
- temps de préparation
- temps de cuisson
- recetteRendement
- recetteIngrédient
- coût estimé
- nutrition, décomposée en calories et matières grasses
- adaptéPourRégime.
Je pourrais continuer. La gamme complète d'options, avec des exemples, peut être lue sur Schema.org. En les ajoutant au format de publication, le format de la recette n'a pas besoin de changer du tout - vous mettez simplement les informations dans des termes que les ordinateurs peuvent comprendre.

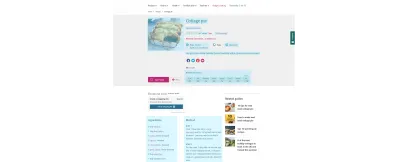
Par exemple, tout ce qui est surligné en bleu dans la recette de la BBC ci-dessus a également reçu un balisage sémantique - du temps de cuisson au contenu nutritionnel. Vous pouvez voir ce qui se passe sous le capot en saisissant l'URL de la recette dans le test de résultats enrichis de Google. Notez la fonctionnalité 'Ajouter à la liste de courses', un exemple de connexion rendue possible par l'implémentation du Web sémantique. Un bon contenu devient une donnée utilisable.
La plupart d'entre nous ont croisé ce type de sophistication via les résultats de recherche, mais les applications sont beaucoup plus larges que cela. Le balisage sémantique des recettes facilite la recherche et l'utilisation des sites Web par les assistants à domicile. Les ingrédients listés peuvent être commandés au supermarché local. Les recettes peuvent être filtrées de toutes sortes de façons - pour les régimes, les allergies, la religion, le coût, etc. Ou disons que vous aviez un nombre limité d'ingrédients dans la maison. Avec une base de données, vous pouvez entrer ces ingrédients et voir quelles recettes correspondent à la facture.
L'éventail des possibilités est vraiment illimité. Comme l'a dit Swartz, les données sont protéiformes. Une fois que vous l'avez, vous pouvez l'utiliser de toutes sortes de façons étranges et merveilleuses. Cette pièce ne concerne pas tant ces manières étranges et merveilleuses que de les rendre possibles. Concevoir pour le Web sémantique rend la conception ultérieure infiniment plus riche.
Voici un exemple plus personnel pour montrer ce que je veux dire. Un couple d'amis et moi gérons un petit webzine musical comme passe-temps. Bien que nous publions quelques articles ou interviews, l'« événement principal » est nos critiques d'albums hebdomadaires, dans lesquelles nous attribuons tous les trois une note, choisissons nos morceaux préférés et écrivons des résumés. Nous y allons depuis plus de cinq ans, ce qui signifie que nous avons près de 250 avis, ce qui signifie énormément de données potentielles. Nous n'avions pas réalisé à quel point jusqu'à ce que nous commencions à repenser le site.
J'en ai parlé dans un article sur l'intégration de données structurées dans le processus de conception. En disséquant nos critiques, nous avons réalisé qu'elles regorgeaient d'informations pouvant recevoir un balisage sémantique. Artistes, noms d'albums, illustrations, date de sortie, partitions individuelles, notes globales, type de sortie, etc. De plus — et c'est là que ça devient vraiment excitant — nous avons réalisé que nous pouvions nous connecter à une base de données existante : MusicBrainz.
Cette approche à double sens est au cœur du Web sémantique. Lorsque notre site Web de musique sera relancé, ce sera sa propre source de données ouverte avec des milliers de points de données uniques. La connexion à une base de données musicale existante donnera à nos propres données plus de contexte et de potentiel. Des milliers de points de données deviennent des dizaines de milliers de points de données, peut-être plus.
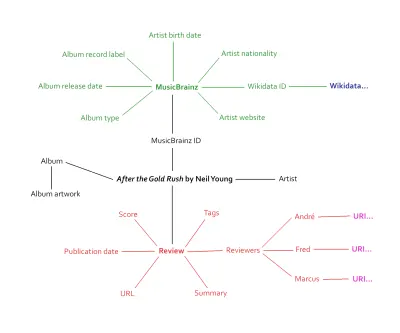
Le graphique ci-dessus ne fait qu'effleurer la quantité d'informations qui seront connectées aux pages d'avis. Le contenu est le même qu'avant, sauf qu'il est désormais connecté à un écosystème de métadonnées - le Giant Global Graph, comme Berners-Lee l'appelait autrefois.
Développer pour le Web sémantique signifie identifier vos propres données, les baliser, puis déterminer comment elles se connectent à d'autres données. Parce que c'est le cas. C'est toujours le cas. Et ce processus est la façon dont cela…
… avec le temps devient ceci…
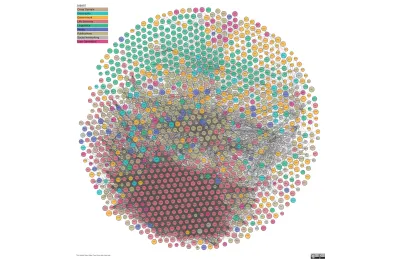
La deuxième image est The Linked Open Data Cloud, une visualisation constamment mise à jour des données connectées du Web. Cette ruche rouge de connexions, ce sont les sciences ; le reste a du chemin à faire. C'est là que nous intervenons.
Ressources utiles sur le Web sémantique
- RDF sur w3schools.com
- Validateur RDF du W3C
- « Le Web sémantique simplifié » par le W3C
- « Qu'est-il arrivé au Web sémantique ? » par Histoire à deux bits
- Générateur JSON-LD
- Aide au balisage des données structurées de Google
Branchement
L'idéal du Web sémantique est la connexion. Créer des données, partager des données, exiger des données. Faites partie d'un écosystème d'information. Lorsque vous créez des données originales, c'est parfait. Partagez-le. Lorsque des données existent déjà et que vous souhaitez les utiliser, extrayez-les.
Voici quelques-unes des ressources de données disponibles :
- DPpedia
- MusiqueBrainz
- WorldCat
- ISBNdb
En effet, là où des bases de données comme celles-ci existent, j'irais jusqu'à dire que la bonne chose à faire serait de les mettre à jour là où elles manquent d'informations. Pourquoi le garder pour soi ? Devenez contributeur, défenseur du Web sémantique.
Mise en œuvre
En ce qui concerne l'intégration du Web sémantique dans vos sites, je ne préconise certainement pas un balisage manuel, doc par doc. Qui a le temps pour ça ? Le plus souvent, la solution consiste à normaliser un format et à le modéliser.
Les modèles sont la grande opportunité ici. Combien de personnes ont vraiment le temps de baliser manuellement toutes ces informations ? Cependant, si vous avez des entrées personnalisées, vous obtenez le meilleur des deux mondes. Le contenu peut être rempli d'informations conviviales et les informations existent sous forme de données prêtes à servir n'importe quel objectif qui vous vient à l'esprit.
Prenez, par exemple, un générateur de site statique comme Eleventy, qui a récemment bénéficié d'un peu d'amour de la part de la communauté des développeurs. Vous écrivez un article, l'exécutez dans un modèle et vous êtes en or. Alors pourquoi ne pas incorporer le balisage sémantique dans le modèle lui-même ?
Comme Eleventy, la nouvelle version de notre site webzine musical utilise Markdown pour ses posts. Bien que nous ayons toujours les mêmes anciens articles de texte, chaque révision inclut désormais également les entrées de métadonnées suivantes, qui sont ensuite insérées dans le modèle :
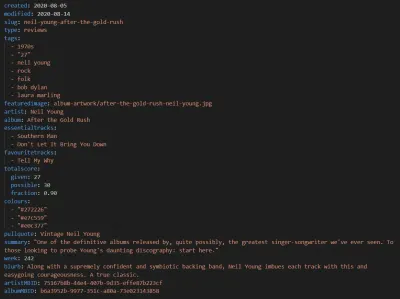
Avec les détails de l'auteur dans le corps du message et quelques informations génériques sur le site Web, cela se traduit ensuite par le balisage sémantique suivant :
<script type="application/ld+json"> { "@context": "https://schema.org/", "@type": "Review", "reviewBody": "One of the definitive albums released by, quite possibly, the greatest singer-songwriter we've ever seen. To those looking to probe Young's daunting discography: start here.", "datePublished": "2020-08-14", "author": [{ "@type": "Person", "name": "Andre Dack" }, { "@type": "Person", "name": "Frederick O'Brien" }, { "@type": "Person", "name": "Marcus Lawrence" }], "itemReviewed": { "@type": "MusicAlbum", "name": "After the Gold Rush", "@id": "https://musicbrainz.org/release-group/b6a3952b-9977-351c-a80a-73e023143858", "image": "https://audioxide.com/images/album-artwork/after-the-gold-rush-neil-young.jpg", "albumProductionType": "https://schema.org/StudioAlbum", "albumReleaseType": "https://schema.org/AlbumRelease", "byArtist": { "@type": "MusicGroup", "name": "Neil Young", "@id": "https://musicbrainz.org/artist/75167b8b-44e4-407b-9d35-effe87b223cf" } }, "reviewRating": { "@type": "Rating", "ratingValue": 27, "worstRating": 0, "bestRating": 30 }, "publisher": { "@type": "Organization", "name": "Audioxide", "description": "Independent music webzine founded in 2015. Publishes reviews, articles, interviews, and other oddities.", "url": "https://audioxide.com", "logo": "https://audioxide.com/logo-location.jpg", "sameAs" : [ "https://facebook.com/audioxide", "https://twitter.com/audioxide", "https://instagram.com/audioxidecom" ] } } </script>Là où auparavant il n'y avait que du texte, sur chaque page de révision, il y aura désormais également des versions lisibles par machine de ce que les lecteurs voient lorsqu'ils visitent le site. Les mots sont toujours là, le contenu a à peine changé - il vient d'être basé sur les données. Des résultats de recherche riches aux pages de statistiques de révision interactives, cela augmente considérablement ce qui est possible. La route à parcourir est large et ouverte. Cela nous donne également un intérêt dans l'avenir de MusicBrainz. En connectant leurs données à nos propres données, nous voulons à notre tour qu'elles fonctionnent bien et nous ferons notre part pour que ce soit le cas.
Le balisage sémantique approprié dépend de la nature d'un site Web, mais il y a de fortes chances qu'il existe. Commencez par les entrées évidentes (date, auteur, type de contenu, etc.) et progressez dans les détails du contenu. La première étape pourrait être aussi simple qu'une hCard (une sorte de carte d'identité numérique) pour votre site Web personnel. Imprimez des captures d'écran des pages et commencez à annoter. Vous serez étonné de voir combien de contenu peut être basé sur les données.
Au-delà de l'imagination
Concevoir et développer pour le Web sémantique est une pratique qui remonte aux idéaux fondateurs d'Internet. Que vous appréciiez une visualisation de données belle et informative, que vous souhaitiez des résultats de recherche plus sophistiqués, que vous souhaitiez retirer le pouvoir des monopoles du Web ou que vous croyiez simplement en une information gratuite et ouverte, le Web sémantique est votre allié.
Aaron Swartz a clôturé son manuscrit par un appel à l'espoir :
"Le Web sémantique est basé sur le pari, un pari que donner au monde des outils pour collaborer et communiquer facilement conduira à des possibilités si merveilleuses que nous pouvons à peine les imaginer en ce moment."
Résumé Wikipedia Denny Vrandecic fait écho à ces sentiments aujourd'hui, en disant :
"Il y a un besoin d'une infrastructure Web qui facilitera l'interopérabilité entre les services, ce qui nécessite un ensemble commun de normes pour représenter les données et des protocoles communs entre les fournisseurs."
Le Web sémantique a marché assez longtemps pour qu'il soit clair qu'un langage miracle n'apparaîtra probablement pas, mais il y en a suffisamment qui coexistent maintenant pacifiquement pour que le rêve fondateur de Berners-Lee soit une réalité pour la majeure partie du Web. Chacun de nous peut être un porte-parole dans son propre quartier.
Soyez meilleur, exigez mieux
Comme l'a dit Tim Berners-Lee, le Web sémantique est une culture autant qu'un obstacle technique. Dans un TED Talk de 2009, il l'a bien résumé : faire des données liées, demander des données liées . C'est plus vrai que jamais. Le World Wide Web est aussi ouvert, connecté et bon que nous le forçons à l'être. Chaque fois que vous créez quelque chose en ligne, demandez-vous : « Comment cela peut-il se connecter au Web sémantique ? » Les réponses ajouteront de nouvelles dimensions aux choses que nous créons et créeront de nouvelles possibilités incroyablement merveilleuses pour les années à venir.