
Doit lire 24 questions et réponses d'entrevue Datastage [Guide ultime 2022]
Publié: 2021-01-08Datastage est un ETL, c'est-à-dire un outil d'extraction, de transformation et de chargement fourni par IBM dans sa suite InfoSphere et sa suite Information Solutions Platforms. C'est un outil ETL populaire et est utilisé pour travailler avec de grands ensembles de données et des entrepôts pour créer et maintenir les référentiels de données. Dans cet article, nous examinerons les questions d'entretien DataStage les plus fréquemment posées et nous fournirons également les réponses à ces questions. Si vous êtes débutant et que vous souhaitez en savoir plus sur la science des données, consultez notre formation en science des données dispensée par les meilleures universités.
Les questions et réponses les plus courantes des entretiens DataStage sont les suivantes :
Table des matières
Questions et réponses de l'entretien DataStage
1. Qu'est-ce qu'IBM DataStage et pourquoi est-il utilisé ?
DataStage est un outil fourni par IBM et utilisé pour concevoir, développer et exécuter les applications pour remplir les données dans les entrepôts de données en extrayant les données des bases de données des serveurs Windows. Il contient la fonctionnalité de visualisations graphiques pour les intégrations de données et peut également extraire des données de plusieurs sources. Il est donc considéré comme l'un des outils ETL les plus puissants. DataStage propose différentes versions que les entreprises peuvent utiliser en fonction de leurs besoins. Les versions sont Server Edition, MVS Edition et Enterprise Edition.
2. Quelles sont les caractéristiques de DataStage ?
Les caractéristiques d'IBM DataStage sont les suivantes :
- Il peut être déployé sur des serveurs locaux ainsi que sur le cloud selon les besoins et les exigences.
- Il est facile à utiliser et peut augmenter efficacement la vitesse et la flexibilité de l'intégration des données.
- Il prend en charge le Big Data et peut accéder au Big Data de plusieurs manières, telles que l'intégrateur JDBC, le support JSON et les systèmes de fichiers distribués.
3. Décrivez brièvement l'architecture DataStage.
IBM DataStage suit un modèle client-serveur comme architecture et a différents types d'architecture pour ses différentes versions. Les composants de l'architecture client-serveur sont :
- Composants clients
- Les serveurs
- Étapes
- Définitions des tableaux
- Conteneurs
- Projets
- Travaux
4. Comment exécuter une tâche à l'aide de la ligne de commande dans DataStage ?
La commande est la suivante : dsjob -run -jobstatus <nom du projet> <nom du travail>
5. Énumérez quelques fonctions que nous pouvons exécuter à l'aide de la commande 'dsjob'.
Les différentes fonctions que nous pouvons effectuer à l'aide de la commande $dsjob sont :
- $dsjob -run : il est utilisé pour exécuter le travail DataStage
- $dsjob -stop : Il est utilisé pour arrêter le travail actuellement présent dans le processus
- $dsjob -jobid : Il est utilisé pour fournir les informations sur le travail
- $dsjob -report : Il est utilisé pour afficher le rapport de travail complet
- $dsjob -lprojects : Il est utilisé pour lister tous les projets qui sont présents
- $dsjob -ljobs : Il est utilisé pour lister tous les travaux qui sont présents dans le projet
- $dsjob -lstages : Il est utilisé pour lister toutes les étapes du travail en cours
- $dsjob -llinks : Il est utilisé pour lister tous les liens
- $dsjobs -lparams : Il est utilisé pour lister tous les paramètres du travail
- $dsjob -projectinfo : Il est utilisé pour récupérer les informations sur le projet
- $dsjob -jobinfo : Il est utilisé pour la récupération des informations du travail
- $dsjob -stageinfo : Il est utilisé pour la récupération d'informations de cette étape de ce travail
- $dsjob -linkinfo : Il est utilisé pour obtenir les informations de ce lien
- $dsjob -paraminfo : Il fournit les informations de tous les paramètres
- $dsjob -loginfo : Il est utilisé pour obtenir les informations sur le journal
- $dsjob -log : il est utilisé pour ajouter un message texte dans le journal
- $dsjob -logsum : Il est utilisé pour afficher les données du journal
- $dsjob -logdetail : Il est utilisé pour afficher tous les détails du journal
- $dsjob -lognewest : il est utilisé pour récupérer l'identifiant du journal le plus récent
6. Qu'est-ce qu'un concepteur de flux dans IBM DataStage ?
Le concepteur de flux est l'interface utilisateur Web de DataStage et est utilisé pour créer, modifier, charger et exécuter les tâches dans DataStage.
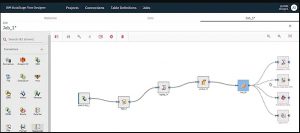
La source
7. Quelles sont les principales fonctionnalités du concepteur de flux ?
Les principales fonctionnalités du concepteur de flux sont :
- Il est très utile pour effectuer des travaux avec un grand nombre d'étapes.
- Il n'est pas nécessaire de migrer les travaux pour utiliser le concepteur de flux.
- Nous pouvons utiliser la palette fournie pour ajouter et supprimer des connecteurs et des opérateurs sur le canevas du concepteur à l'aide de la fonction glisser-déposer.
Apprenez-en plus à propos de : Data Science Vs Data Mining : Différence entre Data Science et Data Mining
8. Comment convertir un job serveur en job parallèle dans DataStage ?
Un travail de serveur peut être converti en travail parallèle à l'aide d'un collecteur Link et d'un collecteur IPC.
9 . Qu'est-ce qu'un connecteur HBase ?
Un connecteur HBase dans DataStage est un outil utilisé pour connecter les bases de données et les tables présentes dans la base de données HBase. Il est principalement utilisé pour effectuer les tâches suivantes :
- Lire et écrire des données depuis et vers la base de données HBase.
- Lecture de données en mode parallèle.
- Utilisation de HBase comme table de vue
10. Qu'est-ce qu'un connecteur Hive ?
Le connecteur Hive est un outil utilisé pour prendre en charge les modes de partition lors de la lecture des données. Cela peut se faire de deux manières :
- mode de partition de module
- mode de partition minimum-maximum
11. Qu'est-ce qu'Infosphere dans DataStage ?
Le serveur d'informations de l'infosphère est capable de gérer les exigences de volume élevé des entreprises et fournit des résultats de haute qualité et plus rapides. Il fournit aux entreprises une plate-forme unique pour gérer les données où elles peuvent comprendre, nettoyer, transformer et fournir d'énormes quantités d'informations.


La source
12. Répertorier tous les différents niveaux d'InfoSphere Information Server ?
Les différents niveaux d'InfoSphere Information Server sont :
- Niveau client
- Niveau de services
- Niveau moteur
- Niveau référentiel de métadonnées
13. Décrivez brièvement le niveau Client de l'Infosphere Information Server.
Le niveau client d'Infosphere Information Server est utilisé pour le développement et l'administration complète des ordinateurs utilisant les programmes clients et les consoles.
14. Décrivez brièvement le niveau Services d'Infosphere Information Server.
Le niveau de services d'Infosphere Information Server est utilisé pour fournir des services standard tels que les métadonnées et la journalisation et certains autres services spécifiques au module. Il contient un serveur d'applications, divers modules de produit et d'autres services de produit.
15. Décrivez brièvement le niveau moteur d'Infosphere Information Server.
Le niveau moteur d'Infosphere Information Server est un ensemble de composants logiques utilisés pour exécuter les travaux et autres tâches pour les modules du produit.
16. Décrivez brièvement le niveau de référentiel de métadonnées d'Infosphere Information Server.
Le niveau référentiel de métadonnées d'Infosphere Information Server comprend le référentiel de métadonnées, la base de données d'analyse et l'ordinateur. Il est utilisé pour partager les métadonnées, les données partagées et les informations de configuration.
17. Quels sont les types de traitement parallèle dans le DataStage ?
Il existe deux types différents de traitement parallèle, qui sont :
- Partitionnement des données
- Canalisation de données
18 . Qu'est-ce que le partitionnement des données ?
Le partitionnement des données est un type d'approche parallèle pour le traitement des données. Cela implique le processus de décomposition des enregistrements en partitions pour le traitement. Il augmente l'efficacité du traitement dans un modèle linéaire.
Lire la suite : Prétraitement des données dans l'apprentissage automatique : 7 étapes faciles à suivre
19. Qu'est-ce que le pipeline de données ?
Le pipeline de données est un type d'approche parallèle pour le traitement des données dans lequel nous exécutons l'extraction des données à partir de la source, puis les faisons passer par une séquence de fonctions de traitement pour obtenir la sortie requise.
20. Qu'est-ce que la SST dans DataStage ?
OSH est une abréviation d'Orchestrate Shell et est un langage de script utilisé dans DataStage en interne par le moteur parallèle.
21. Que sont les joueurs ?
Les joueurs dans DataStage sont les processus de bête de somme. Ils nous aident à effectuer le traitement parallèle et sont affectés aux opérateurs sur chaque nœud.
22. Qu'est-ce qu'une bibliothèque de collection dans le DataStage ?
Les bibliothèques de collection sont l'ensemble des opérateurs et sont utilisées pour collecter les données partitionnées.
23. Quels sont les types de collecteurs disponibles dans la bibliothèque de collections de DataStage ?
Les types de collecteurs disponibles dans la bibliothèque de collections sont :
- Collecteur Sortmerg
- Collecteur Roundrobin
- Collecteur commandé
24. Comment le fichier source est-il rempli dans DataStage ?
Le fichier source peut être rempli à l'aide de requêtes SQL et également à l'aide de l'outil d'extraction du générateur de lignes.
Conclusion
Nous espérons que notre article contenant toutes les questions et réponses de l'entretien DataStage vous a aidé à vous préparer à l'entretien DataStage. Vous pouvez jeter un œil à ces cours proposés par upGrad pour approfondir vos connaissances sur ces sujets :
- Diplôme PG en développement logiciel Spécialisation en Big Data : Ce cours est créé par upGrad en association avec l'IIIT-B pour fournir aux individus les connaissances dont ils ont besoin pour le développement de logiciels et couvrir les connaissances sur la gestion du Big Data.
- PGC in Full Stack Development : Ce cours sur le développement full-stack est créé par upGrad et des professionnels de l'industrie de Tech Mahindra pour rendre les individus capables de résoudre les défis au niveau de l'industrie et d'acquérir toutes les compétences nécessaires pour entrer et travailler dans les industries.
Chez upGrad, nous sommes toujours là pour vous aider dans votre préparation. Vous pouvez également consulter nos cours qui peuvent vous aider à acquérir toutes les compétences et techniques requises par l'industrie pour bien vous préparer à vos entretiens et à vos futures ambitions professionnelles, comme nous le disons toujours "Raho Ambitious". Ces cours ont été conçus par des experts de l'industrie et des universitaires expérimentés pour vous permettre de maîtriser la technologie et les compétences que vous souhaitez acquérir.
Si vous êtes intéressé à apprendre python et que vous voulez vous salir les mains sur divers outils et bibliothèques, consultez le programme Executive PG in Data Science.
Quelles sont les quatre étapes principales de Datastage ?
IBM Datastage est un outil puissant pour concevoir, développer et exécuter les applications pour remplir les données dans les entrepôts de données en extrayant les données des bases de données. Vous trouverez ci-dessous les quatre principales étapes de Datastage. L'administrateur est utilisé pour les tâches d'administration telles que la configuration des utilisateurs DataStage et la purge des critères, la mobilisation et la démobilisation des projets, etc. Le concepteur ou l'interface de conception développe les applications OU les travaux Datastage qui sont régulés par le directeur et exécutés par le serveur. Comme son nom l'indique, le gestionnaire maintient et gère les référentiels et permet aux utilisateurs de modifier les données stockées à travers celui-ci. Le directeur remplit diverses fonctions, notamment la validation des travaux, leur planification et leur exécution ainsi que la surveillance des travaux parallèles.
A quelles fins la commande « dsjob » est-elle utilisée ?
La commande dsjob est utilisée pour diverses fonctions, notamment la récupération et l'affichage des données sur les projets ou les travaux. Voici quelques-unes des fonctions pouvant être exécutées à l'aide de la commande dsjob. $dsjob -run utilisé pour exécuter le travail DataStage, $dsjob -stop utilisé pour arrêter le travail actuellement présent dans le processus, $dsjob -jobid utilisé pour fournir les informations sur le travail, $dsjob -report utilisé pour afficher le rapport complet du travail , etc.
Quelles sont les caractéristiques de DataStage ?
Datastage est un puissant outil d'architecture de données et possède diverses caractéristiques. Certaines des caractéristiques de Datastage sont les suivantes : Datastage peut être déployé sur les serveurs locaux et sur les serveurs cloud en fonction des besoins de l'utilisateur. La vitesse et la flexibilité de l'intégration des données peuvent être augmentées à tout moment et peuvent être utilisées efficacement. Il prend en charge le Big Data et peut accéder au Big Data de plusieurs manières, telles que l'intégrateur JDBC, le support JSON et les systèmes de fichiers distribués.