
Visualisation de données en Python : explication des tracés fondamentaux [avec illustration graphique]
Publié: 2021-02-08Table des matières
Principes de conception de base
Pour tout data scientist en herbe ou qui réussit, être capable d'expliquer vos recherches et vos analyses est une compétence très importante et utile à posséder. C'est là que la visualisation des données entre en scène. Il est essentiel d'utiliser cet outil honnêtement car le public peut être très facilement mal informé ou trompé par de mauvais choix de conception.
En tant que data scientists, nous avons tous certaines obligations en matière de préservation de ce qui est vrai.
La première est que nous devons être complètement honnêtes avec nous-mêmes lors du nettoyage et de la synthèse des données. Le prétraitement des données est une étape cruciale pour le fonctionnement de tout algorithme d'apprentissage automatique. Par conséquent, toute malhonnêteté dans les données entraînera des résultats radicalement différents.
Une autre obligation est envers notre public cible. Il existe diverses techniques de visualisation des données qui sont utilisées pour mettre en évidence des sections spécifiques de données et rendre certaines autres données moins importantes. Ainsi, si nous ne sommes pas assez prudents, le lecteur ne pourra pas explorer et juger correctement l'analyse, ce qui peut conduire à des doutes et à un manque de confiance.
Toujours se remettre en question est un bon trait à avoir pour les data scientists. Et nous devons toujours réfléchir à la manière de montrer ce qui compte vraiment d'une manière compréhensible et esthétique, tout en nous rappelant que le contexte est important.
C'est exactement ce qu'Alberto Cairo essaie de représenter dans ses enseignements. Il mentionne les Cinq Qualités des Grandes Visualisations : belles, éclairantes, fonctionnelles, perspicaces et véridiques qui méritent d'être gardées à l'esprit.
Quelques parcelles fondamentales
Maintenant que nous avons une compréhension de base des principes de conception, plongeons dans certaines techniques de visualisation fondamentales à l'aide de la bibliothèque matplotlib en python.
Tout le code ci-dessous peut être exécuté dans un cahier Jupyter.
bloc-notes %matplotlib
# cela fournit un environnement interactif et définit le back-end. ( %matplotlib inline peut également être utilisé mais il n'est pas interactif. Cela signifie que tout autre appel aux fonctions de traçage ne mettra pas automatiquement à jour notre visualisation d'origine.)
importer matplotlib.pyplot en tant que plt # importer le module de bibliothèque requis
Tracés de points
La fonction matplotlib la plus simple pour tracer un point est plot() . Les arguments représentent les coordonnées X et Y, puis une valeur de chaîne qui décrit comment la sortie de données doit être affichée.
plt.figure()
plt.plot( 5, 6, '+' ) # le signe + agit comme un marqueur
Nuages de points
Un nuage de points est un graphique à deux dimensions. La fonction scatter() prend également la valeur X comme premier argument et la valeur Y comme second. Le tracé ci-dessous est une ligne diagonale et matplotlib ajuste automatiquement la taille des deux axes. Ici, le nuage de points ne traite pas les éléments comme une série. Ainsi, on peut également donner dans une liste des couleurs souhaitées correspondant à chacun des points.
importer numpy en tant que np
x = np.tableau( [1, 2, 3, 4, 5, 6, 7, 8] )
y = x
plt.figure()
plt.scatter( x, y )
Tracés linéaires
Un tracé linéaire est créé avec la fonction plot() et trace un certain nombre de séries différentes de points de données comme un nuage de points, mais il relie chaque série de points par une ligne.
importer numpy en tant que np
linear_data = np.array( [1, 2, 3, 4, 5, 6, 7, 8] )
données_carrées = données_linéaires**2
plt.figure()
plt.plot( linear_data, '-o', squared_data, '-o')
Pour rendre le graphique plus lisible, on peut aussi ajouter une légende qui nous dira ce que représente chaque ligne. Un titre approprié pour le graphique et les deux axes est important. De plus, n'importe quelle section du graphique peut être ombrée à l'aide de la fonction fill_between() pour mettre en évidence les régions pertinentes.
plt.xlabel('Valeurs X')
plt.ylabel('Valeurs Y')
plt.title('Tracés linéaires')
plt.legend( ['linéaire', 'au carré'] )
plt.gca().fill_between( range ( len ( linear_data ) ), linear_data, squared_data, facecolor = 'blue', alpha = 0.25)

Voici à quoi ressemble le graphique modifié-
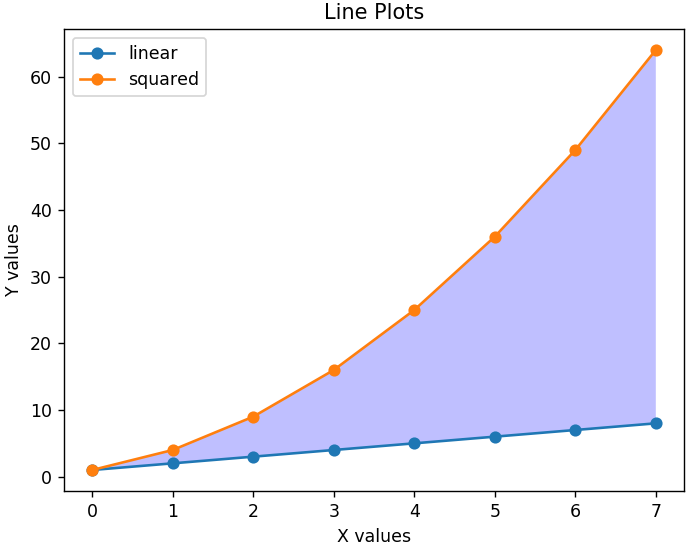
Diagramme à barres
Nous pouvons tracer un graphique à barres en envoyant des arguments pour les valeurs X et la hauteur de chaque barre à la fonction bar() . Vous trouverez ci-dessous un graphique à barres du même tableau de données linéaire que nous avons utilisé ci-dessus.
plt.figure()
x = plage( len ( linear_data ))
plt.bar( x, linear_data )
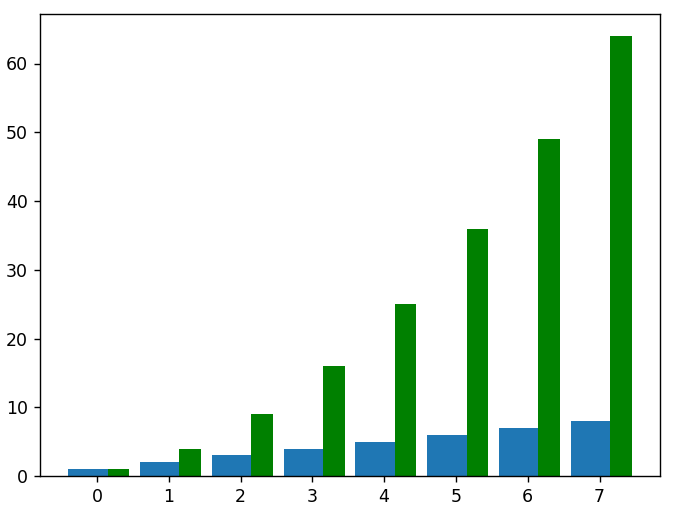
# pour tracer les données au carré comme un autre ensemble de barres sur le même graphique, nous devons ajuster les nouvelles valeurs x pour compenser le premier ensemble de barres
nouveau_x = []
pour les données en x :
new_x.append(données+0.3)
plt.bar(new_x, squared_data, width = 0.3, color = 'green')
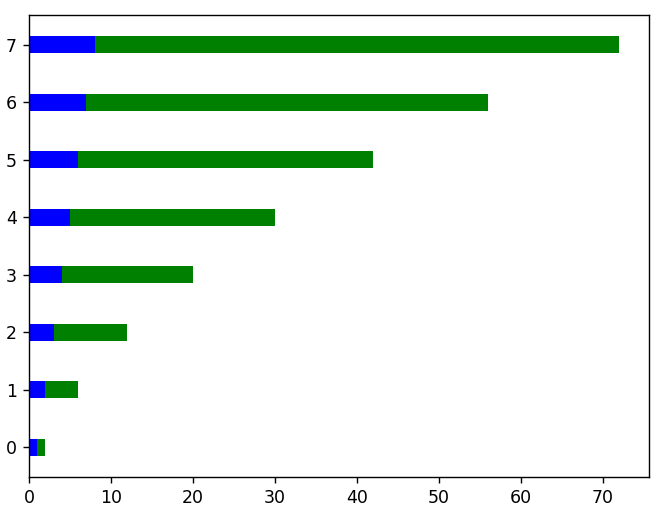
# Pour les graphiques à orientation horizontale, nous utilisons la fonction barh()
plt.figure()
x = plage( len( linear_data ))
plt.barh( x, linear_data, hauteur = 0,3, couleur = 'b')
plt.barh( x, squared_data, hauteur = 0.3, left = linear_data, color = 'g')
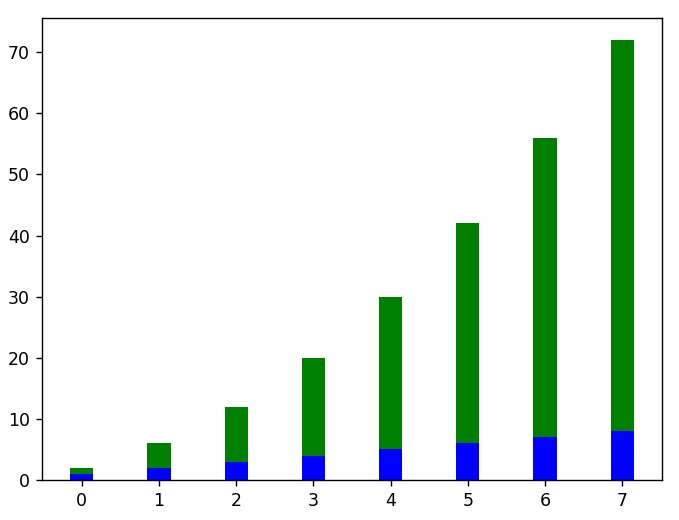
#voici un exemple d'empilement vertical de graphiques à barres
plt.figure()
x = plage( len( linear_data ))
plt.bar( x, linear_data, width = 0.3, color = 'b')
plt.bar( x, squared_data, width = 0.3, bottom = linear_data, color = 'g')
Apprenez des cours de science des données dans les meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.
Conclusion
Les types de visualisation ne s'arrêtent pas là. Python possède également une excellente bibliothèque appelée seaborn qui vaut vraiment la peine d'être explorée. Une bonne visualisation des informations contribue grandement à augmenter la valeur de nos données. La visualisation des données sera toujours la meilleure option pour obtenir des informations et identifier diverses tendances et modèles plutôt que de parcourir des tableaux ennuyeux avec des millions d'enregistrements.
Si vous êtes curieux d'en savoir plus sur la science des données, consultez le diplôme PG de IIIT-B & upGrad en science des données qui est créé pour les professionnels en activité et propose plus de 10 études de cas et projets, des ateliers pratiques, un mentorat avec des experts de l'industrie, 1- on-1 avec des mentors de l'industrie, plus de 400 heures d'apprentissage et d'aide à l'emploi avec les meilleures entreprises.
Quels sont les packages Python utiles pour la visualisation de données ?
Python propose des packages étonnants et utiles pour la visualisation de données. Certains de ces forfaits sont mentionnés ci-dessous :
1. Matplotlib - Matplotlib est une bibliothèque Python populaire utilisée pour la visualisation de données sous diverses formes telles que les nuages de points, les graphiques à barres, les graphiques à secteurs et les graphiques linéaires. Il utilise Numpy pour ses opérations mathématiques.
2. Seaborn - La bibliothèque Seaborn est utilisée pour les représentations statistiques en Python. Il est développé sur Matplotlib et est intégré aux structures de données Pandas.
3. Altair - Altair est une autre bibliothèque Python populaire pour la visualisation de données. Il s'agit d'une bibliothèque statistique déclarative qui permet de créer des visuels avec un minimum de codage possible.
4. Plotly - Plotly est une bibliothèque de visualisation de données interactive et open-source de Python. Les visuels créés par cette bibliothèque basée sur un navigateur sont pris en charge par de nombreuses plates-formes telles que Jupyter Notebook et des fichiers HTML autonomes.
Que savez-vous des diagrammes de points et des nuages de points ?
Les tracés de points sont les tracés les plus basiques et les plus simples pour la visualisation des données. Un diagramme de points affiche les données sous forme de points sur un plan cartésien. Le "+" indique l'augmentation de la valeur tandis que le "-" indique la diminution de la valeur au fil du temps.
Un nuage de points, quant à lui, est un tracé optimisé où les données sont visualisées sur un plan 2D. Il est défini à l'aide de la fonction scatter() qui prend la valeur de l'axe des x comme premier paramètre et la valeur de l'axe des y comme deuxième paramètre.
Quels sont les avantages de la data visualisation ?
Les avantages suivants montrent comment les visualisations de données peuvent devenir le véritable héros de la croissance d'une organisation :
1. La visualisation des données facilite l'interprétation des données brutes et leur compréhension pour une analyse plus approfondie.
2. Après avoir recherché et analysé les données, les résultats peuvent être affichés à l'aide de visualisations significatives. Cela facilite la connexion avec le public et l'explication des résultats.
3. L'une des applications les plus essentielles de cette technique consiste à analyser les modèles et les tendances pour en déduire des prévisions et des domaines de croissance potentiels.
4. Il vous permet également de séparer les données en fonction des préférences des clients. Vous pouvez également identifier les domaines qui nécessitent plus d'attention.