
Que sont les structures de données en C et comment les utiliser ?
Publié: 2021-02-26Table des matières
introduction
Pour commencer, une structure de données est une collection d'éléments de données qui sont conservés ensemble sous un nom ou un en-tête et constitue une manière spécifique de stocker et d'assembler les données afin que les données puissent être utilisées efficacement.
Les types
Les structures de données sont répandues et utilisées dans presque tous les systèmes logiciels. Certains des exemples les plus courants de structures de données sont les tableaux, les files d'attente, les piles, les listes chaînées et les arbres.
Applications
Dans la conception de compilateurs, de systèmes d'exploitation, de création de bases de données, d'applications d'intelligence artificielle et bien d'autres.
Classification
Les structures de données sont classées en deux catégories : les structures de données primitives et les structures de données non primitives.
1. Primitive : ce sont les types de données de base pris en charge par un langage de programmation. Un exemple courant de cette classification est les nombres entiers, les caractères et les booléens.
2. Non-Primitive : Ces catégories de structures de données sont créées à l'aide de structures de données primitives. Les exemples incluent les piles liées, les listes liées, les graphiques et les arbres.

Tableaux
Un tableau est une simple collection d'éléments de données qui ont le même type de données. Cela signifie qu'un tableau d'entiers de type ne peut stocker que des valeurs entières. Un tableau de type de données float peut stocker des valeurs qui correspondent au type de données float et rien d'autre.
Les éléments stockés dans un tableau sont accessibles de manière linéaire et sont présents dans des blocs de mémoire contigus auxquels il est possible de se référer à l'aide d'un index.
Déclarer un tableau
En C, un tableau peut être déclaré comme :
nom_type_données[longueur] ;
Par exemple,
commandes int[10] ;
La ligne de code ci-dessus crée un tableau de 10 blocs de mémoire dans lequel une valeur entière peut être stockée. En C, la valeur d'index du tableau commence à partir de 0. Ainsi, les valeurs d'index iront de 0 à 9. Si nous voulons accéder à une valeur particulière dans ce tableau, nous devons simplement taper :
printf(commande[numéro_index]);
Une autre façon de déclarer un tableau est la suivante :
data_type array_name[taille]={liste de valeurs} ;
Par exemple,
marques int[5]={9, 8, 7, 9, 8} ;
La ligne de commande ci-dessus crée un tableau comportant 5 blocs de mémoire avec des valeurs fixes dans chacun des blocs. Sur un compilateur 32 bits, la mémoire 32 bits occupée par le type de données int est de 4 octets. Ainsi, 5 blocs de mémoire occuperaient 20 octets de mémoire.
Une autre façon légitime d'initialiser les tableaux est :
marques int [5] = {9 , 45} ;
Cette commande créera un tableau de 5 blocs, les 3 derniers blocs ayant 0 comme valeur.
Une autre façon légitime est:
marques int [] = {9 , 5, 2, 1, 3,4} ;
Le compilateur C comprend que seuls 5 blocs sont nécessaires pour insérer ces données dans un tableau. Il va donc initialiser un tableau de marques de nom de taille 5.
De même, un tableau 2-D peut être initialisé de la manière suivante
marques int[2][3]={{9,7,7},{6, 2, 1}} ;
La commande ci-dessus créera un tableau 2-D ayant 2 lignes et 3 colonnes.
Lire : Idées et sujets de projet de structure de données
Opérations
Certaines opérations peuvent être effectuées sur des tableaux. Par exemple:
- traversant un tableau
- Insérer un élément dans le tableau
- Recherche d'un élément particulier dans le tableau
- Supprimer un élément particulier du tableau
- Fusionner les deux tableaux et,
- Trier le tableau — par ordre croissant ou décroissant.
Désavantages
La mémoire allouée à la baie est fixe. C'est en fait un problème. Disons que nous avons créé un tableau de taille 50 et que nous n'avons accédé qu'à 30 blocs de mémoire. Les 20 blocs restants occupent de la mémoire sans aucune utilisation. Par conséquent, pour résoudre ce problème, nous avons une liste chaînée.
Liste liée
La liste liée, tout comme les tableaux, stocke les données en série. La principale différence est qu'il ne stocke pas tout en même temps. Au lieu de cela, stocke les données ou rend un bloc de mémoire disponible au fur et à mesure des besoins. Dans une liste chaînée, les blocs sont divisés en deux parties. La première partie contient les données réelles.
La deuxième partie est un pointeur qui pointe vers le bloc suivant dans une liste chaînée. Le pointeur stocke l'adresse du bloc suivant contenant les données. Il existe un autre pointeur connu sous le nom de pointeur de tête. head pointe vers le premier bloc de mémoire de la liste chaînée. Voici la représentation de la liste chaînée. Ces blocs sont également appelés « nœuds ».
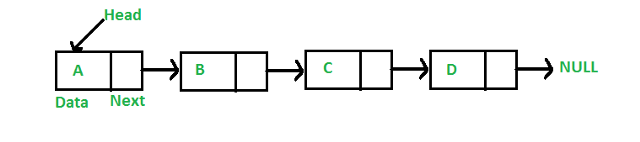
la source
Initialisation des listes chaînées
Pour initialiser la liste de liens, nous créons un nœud de noms de structure. La structure a deux choses. 1. Les données qu'il contient et 2. Le pointeur qui pointe vers le nœud suivant. Le type de données du pointeur sera celui de la structure car il pointe vers le nœud de la structure.

nœud de structure
{
données entières ;
struct node *next;
} ;
Dans une liste chaînée, le pointeur du dernier nœud ne pointera sur rien, ou pointera simplement sur null.
A lire aussi : Graphiques dans la structure des données
Traversée de liste liée
Dans une liste chaînée, le pointeur du dernier nœud ne pointera sur rien, ou simplement, il pointera sur null. Donc, pour parcourir une liste chaînée entière, nous créons un pointeur factice qui pointe initialement vers la tête. Et, pour la longueur de la liste chaînée, le pointeur continue d'avancer jusqu'à ce qu'il pointe sur null ou atteigne le dernier nœud de la liste chaînée.
Ajout d'un nœud
L'algorithme pour ajouter un nœud avant un nœud spécifique serait le suivant :
- définir deux pointeurs factices (ptr et preptr) qui pointent vers la tête initialement
- déplacez le ptr jusqu'à ce que ptr.data soit égal aux données avant que nous ayons l'intention d'insérer le nœud. preptr sera 1 nœud derrière ptr.
- Créer un nœud
- Le nœud vers lequel le preptr factice pointait, le prochain nœud de ce nœud pointera vers ce nouveau nœud
- Le prochain nœud pointera vers le ptr.
L'algorithme pour ajouter un nœud après une donnée particulière se ferait de la même manière.
Avantages de la liste liée
- Taille dynamique contrairement à un tableau
- L'insertion et la suppression sont plus faciles dans la liste chaînée que dans un tableau.
File d'attente
La file d'attente suit un système de type premier entré, premier sorti ou FIFO. Dans une implémentation de tableau, nous aurons deux pointeurs pour démontrer le cas d'utilisation de Queue.
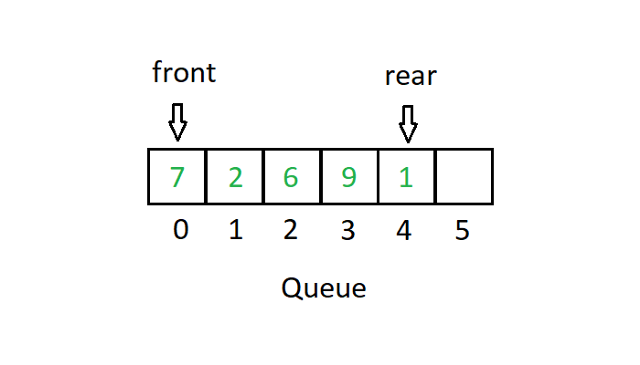
La source
FIFO signifie essentiellement que la valeur qui entre en premier dans la pile quitte le tableau en premier. Dans le diagramme de file d'attente ci-dessus, le pointeur pointe vers la valeur 7. Si nous supprimons le premier bloc (dequeue), le front pointe maintenant vers la valeur 2. De même, si nous entrons un nombre (en file d'attente), disons 3 dans position 5. Ensuite, le pointeur arrière pointera sur la position 5.
Conditions de débordement et de sous-remplissage
Néanmoins, avant d'entrer une valeur de données dans la file d'attente, nous devons vérifier les conditions de débordement. Un débordement se produira lors d'une tentative d'insertion d'un élément dans une file déjà pleine. Une file d'attente sera pleine lorsque rear = max_size–1.
De même, avant de supprimer des données de la file d'attente, nous devons vérifier les conditions de sous-dépassement. Un sous-dépassement se produira lors d'une tentative de suppression d'un élément d'une file d'attente déjà vide, c'est-à-dire si front = null et rear = null, alors la file d'attente est vide.
Empiler
Une pile est une structure de données dans laquelle nous insérons et supprimons des éléments uniquement à une extrémité, également appelée sommet de la pile. L'implémentation de la pile est donc appelée implémentation dernier entré, premier sorti (LIFO). Contrairement à la file d'attente, pour la pile, nous n'avons besoin que d'un pointeur supérieur.
Si nous voulons entrer (pousser) des éléments dans un tableau, le pointeur supérieur monte ou incrémente de 1. Si nous voulons supprimer (pop) un élément, le pointeur supérieur décrémente de 1 ou descend de 1 unité. Une pile prend en charge trois opérations de base : push, pop et peep. L'opération Peep affiche simplement l'élément le plus haut de la pile.
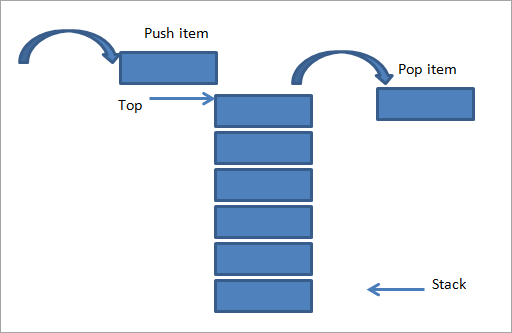
La source
Apprenez des cours de logiciels en ligne dans les meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.
Conclusion
Dans cet article, nous avons parlé de 4 types de structures de données, à savoir les tableaux, les listes chaînées, les files d'attente et les piles. J'espère que vous avez aimé cet article et restez à l'écoute pour des lectures plus intéressantes. Jusqu'à la prochaine fois.
Si vous souhaitez en savoir plus sur Javascript, le développement full-stack, consultez le programme Executive PG de upGrad & IIIT-B en développement logiciel full-stack, conçu pour les professionnels en activité et offrant plus de 500 heures de formation rigoureuse, plus de 9 projets. et affectations, statut d'ancien de l'IIIT-B, projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
Que sont les structures de données en programmation ?
Les structures de données sont la façon dont nous organisons les données dans un programme. Les deux structures de données les plus importantes sont les tableaux et les listes chaînées. Les tableaux sont la structure de données la plus familière et la plus facile à comprendre. Les tableaux sont essentiellement des listes numérotées d'éléments associés. Ils sont simples à comprendre et à utiliser, mais ils ne sont pas très efficaces lorsque vous travaillez avec de grandes quantités de données. Les listes chaînées sont plus complexes, mais elles peuvent être très efficaces si elles sont utilisées correctement. Ce sont de bons choix lorsque vous devez ajouter ou supprimer des éléments au milieu d'une longue liste, ou lorsque vous devez rechercher des éléments dans une longue liste.
Quelles sont les différences entre la liste chaînée et les tableaux ?
Dans les tableaux, un index est utilisé pour accéder à un élément. Les éléments du tableau sont organisés dans un ordre séquentiel, ce qui facilite l'accès et la modification des éléments si un index est utilisé. Array a également une taille fixe. Les éléments sont attribués au moment de sa création. Dans la liste chaînée, un pointeur permet d'accéder à un élément. Les éléments d'une liste chaînée ne sont pas nécessairement stockés dans un ordre séquentiel. Une liste chaînée a une taille inconnue car elle peut contenir des nœuds au moment de sa création. Un pointeur est utilisé pour accéder à un élément, ce qui facilite l'allocation de mémoire.
Qu'est-ce qu'un pointeur en C ?
Un pointeur est un type de données en C qui stocke l'adresse de n'importe quelle variable ou fonction. Il est généralement utilisé comme référence à un autre emplacement mémoire. Un pointeur peut contenir une adresse mémoire d'un tableau, d'une structure, d'une fonction ou de tout autre type. C utilise des pointeurs pour transmettre et recevoir des valeurs de fonctions. Les pointeurs sont utilisés pour allouer dynamiquement de l'espace mémoire.