
La feuille de triche ultime de la science des données que tous les scientifiques des données devraient avoir
Publié: 2021-01-29Pour tous les professionnels en herbe et les débutants qui envisagent de plonger dans le monde en plein essor de la science des données, nous avons compilé une feuille de triche rapide pour vous familiariser avec les bases et les méthodologies qui sous-tendent ce domaine.
Table des matières
Science des données - Les bases
Les données générées dans notre monde sont sous une forme brute, c'est-à-dire des chiffres, des codes, des mots, des phrases, etc. La science des données prend ces données très brutes pour les traiter à l'aide de méthodes scientifiques afin de les transformer en formes significatives pour acquérir des connaissances et des idées .
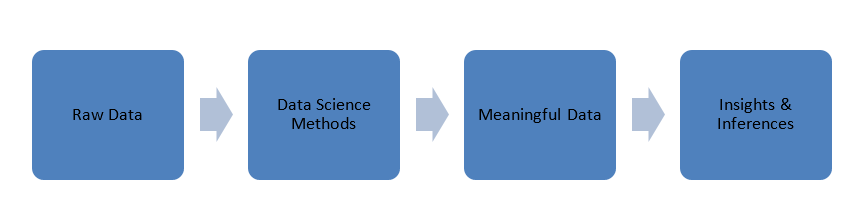
Données
Avant de plonger dans les principes de la science des données, parlons un peu des données, de leurs types et du traitement des données.
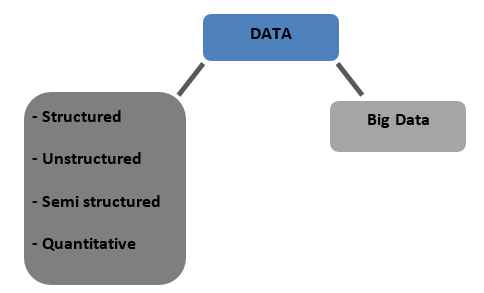
Types de données
Structuré – Données stockées sous forme de tableau dans des bases de données. Il peut être numérique ou textuel
Non structurées - Les données qui ne peuvent pas être tabulées avec une structure définitive à proprement parler sont appelées données non structurées
Semi-structurées - Données mixtes avec des caractéristiques de données structurées et non structurées
Quantitatif - Données avec des valeurs numériques définies qui peuvent être quantifiées
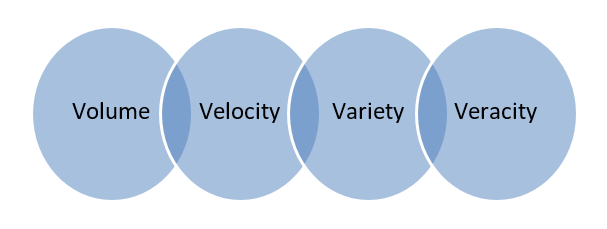
Big Data - Les données stockées dans d'énormes bases de données couvrant plusieurs ordinateurs ou batteries de serveurs sont appelées Big Data. Les données biométriques, les données des médias sociaux, etc. sont considérées comme du Big Data. Le Big Data est caractérisé par 4 V
Prétraitement des données
Classification des données - C'est le processus de catégorisation ou d'étiquetage des données en classes comme numérique, textuel ou image, texte, vidéo, etc.
Nettoyage des données - Il consiste à éliminer les données manquantes/incohérentes/incompatibles ou à remplacer les données en utilisant l'une des méthodes suivantes.
- Interpolation
- Heuristique
- Assignation aléatoire
- Voisin le plus proche
Masquage des données – Masquer ou masquer des données confidentielles pour préserver la confidentialité des informations sensibles tout en étant en mesure de les traiter.
De quoi est faite la science des données ?
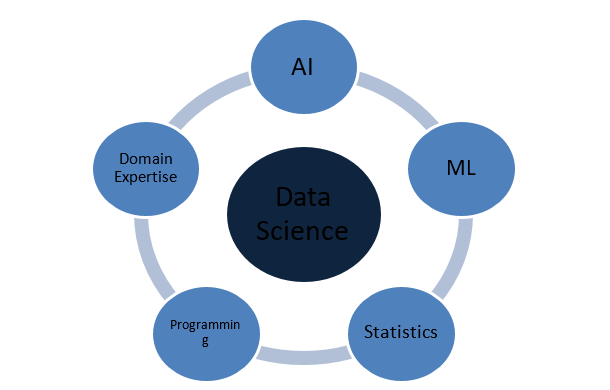
Concepts de statistiques
Régression
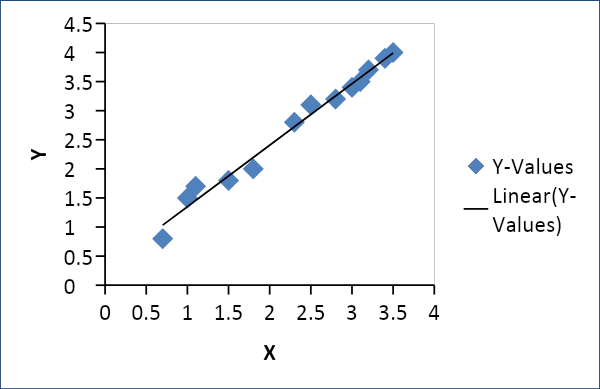
Régression linéaire
La régression linéaire est utilisée pour établir une relation entre deux variables telles que l'offre et la demande, le prix et la consommation, etc. Elle relie une variable x en tant que fonction linéaire d'une autre variable y comme suit
Y = f(x) ou Y =mx + c, où m = coefficient
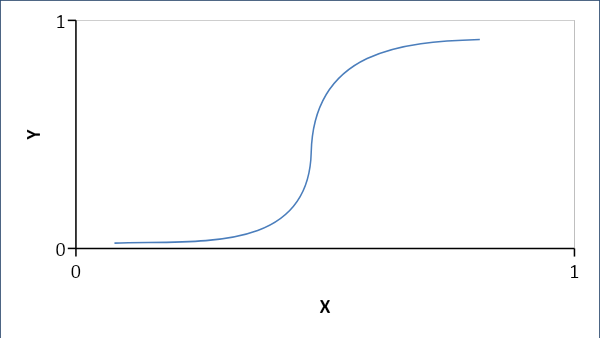
Régression logistique
La régression logistique établit une relation probabiliste plutôt qu'une relation linéaire entre les variables. La réponse résultante est soit 0 soit 1 et nous recherchons des probabilités et la courbe est en forme de S.
Si p < 0,5, alors c'est 0 sinon 1
Formule:
Y = e^ (b0 + b1x) / (1 + e^ (b0 +b1x))
où b0 = biais et b1 = coefficient
Probabilité
La probabilité permet de prédire la probabilité d'occurrence d'un événement. Quelques terminologies :
Échantillon : L'ensemble des résultats probables
Événement : il s'agit d'un sous-ensemble de l'espace d'échantillonnage
Variable aléatoire : les variables aléatoires aident à cartographier ou à quantifier les résultats probables en nombres ou en ligne dans un espace d'échantillonnage
Distributions de probabilité
Distributions discrètes : donne la probabilité sous la forme d'un ensemble de valeurs discrètes (entier)
P[X=x] = p(x)
 Source des images
Source des images
Distributions continues : donne la probabilité sur un certain nombre de points ou d'intervalles continus au lieu de valeurs discrètes. Formule:
P[a ≤ x ≤ b] = a∫bf(x) dx, où a, b sont les points
Source des images
Corrélation et covariance
Écart type : la variation ou l'écart d'un ensemble de données donné par rapport à sa valeur moyenne
σ = √ {(Σi=1N ( xi – x ) ) / (N -1)}
Covariance
Il définit l'étendue de l'écart des variables aléatoires X et Y avec la moyenne de l'ensemble de données.
Cov(X,Y) = σ2XY = E[(X−μX)(Y−μY)] = E[XY]−μXμY
Corrélation
La corrélation définit l'étendue d'une relation linéaire entre les variables ainsi que leur direction, +ve ou -ve
ρXY= σ2XY/ σX * *σY
Intelligence artificielle
La capacité des machines à acquérir des connaissances et à prendre des décisions basées sur des entrées s'appelle l'intelligence artificielle ou simplement l'IA.
Les types
- Machines réactives : l'IA de la machine réactive fonctionne en apprenant à réagir à des scénarios prédéfinis en se limitant aux options les plus rapides et les meilleures. Ils manquent de mémoire et conviennent mieux aux tâches avec un ensemble défini de paramètres. Très fiable et cohérent.
- Mémoire limitée : Cette IA est alimentée par des données d'observation et héritées du monde réel. Il peut apprendre et prendre des décisions sur la base des données fournies, mais ne peut pas acquérir de nouvelles expériences.
- Théorie de l'esprit : il s'agit d'une IA interactive qui peut prendre des décisions en fonction du comportement des entités environnantes.
- Conscience de soi : cette IA est consciente de son existence et de son fonctionnement en dehors de l'environnement. Il peut développer des capacités cognitives et comprendre et évaluer les impacts de ses propres actions sur l'environnement.
Termes de l'IA
Les réseaux de neurones
Les réseaux de neurones sont un groupe ou un réseau de nœuds interconnectés qui relaient les données et les informations dans un système. Les NN sont modélisés pour imiter les neurones de notre cerveau et peuvent prendre des décisions en apprenant et en prédisant.
Heuristique
L'heuristique est la capacité de prédire sur la base d'approximations et d'estimations rapidement en utilisant l'expérience antérieure dans des situations où les informations disponibles sont inégales. C'est rapide mais pas exact ni précis.
Raisonnement par cas
La capacité d'apprendre des cas précédents de résolution de problèmes et de les appliquer dans des situations actuelles pour arriver à une solution acceptable
Traitement du langage naturel
C'est simplement la capacité d'une machine à comprendre et à interagir directement avec la parole ou le texte humain. Par exemple, les commandes vocales dans une voiture
Apprentissage automatique
L'apprentissage automatique est simplement une application de l'IA utilisant divers modèles et algorithmes pour prédire et résoudre des problèmes.
Les types

Supervisé
Cette méthode repose sur des données d'entrée qui sont associatives avec les données de sortie. La machine est munie d'un ensemble de variables cibles Y et elle doit arriver à la variable cible par un ensemble de variables d'entrée X sous la supervision d'un algorithme d'optimisation. Des exemples d'apprentissage supervisé sont les réseaux de neurones, la forêt aléatoire, l'apprentissage en profondeur, les machines à vecteurs de support, etc.
Non surveillé
Dans cette méthode, les variables d'entrée n'ont ni étiquetage ni association, et les algorithmes fonctionnent pour trouver des modèles et des clusters résultant en de nouvelles connaissances et idées.
Renforcé
L'apprentissage renforcé se concentre sur les techniques d'improvisation pour affiner ou peaufiner le comportement d'apprentissage. C'est une méthode basée sur la récompense où la machine améliore progressivement ses techniques pour gagner une récompense cible.
Méthodes de modélisation
Régression
Les modèles de régression donnent toujours des nombres en sortie par interpolation ou extrapolation de données continues.
Classification
Les modèles de classification proposent des sorties sous forme de classe ou d'étiquette et sont plus efficaces pour prédire des résultats discrets comme "quel type"
La régression et la classification sont des modèles supervisés.
Regroupement
Le clustering est un modèle non supervisé qui identifie les clusters en fonction de traits, d'attributs, de caractéristiques, etc.
Algorithmes ML
Arbres de décision
Les arbres de décision utilisent une approche binaire pour arriver à une solution basée sur des questions successives à chaque étape de telle sorte que le résultat soit l'un des deux possibles comme "Oui" ou "Non". Les arbres de décision sont simples à mettre en œuvre et à interpréter.
Forêt aléatoire ou ensachage
Random Forest est un algorithme avancé d'arbres de décision. Il utilise un grand nombre d'arbres de décision ce qui rend la structure dense et complexe comme une forêt. Il génère de multiples résultats et conduit ainsi à des résultats et des performances plus précis.
K- Voisin le plus proche (KNN)
kNN utilise la proximité des points de données les plus proches sur une parcelle par rapport à un nouveau point de données pour prédire dans quelle catégorie il se situe. Le nouveau point de données est affecté à la catégorie avec un nombre plus élevé de voisins.
k = nombre de voisins les plus proches
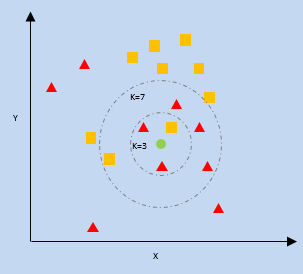
Bayes naïf
Naive Bayes travaille sur deux piliers, premièrement que chaque caractéristique des points de données est indépendante, sans rapport les unes avec les autres, c'est-à-dire unique, et deuxièmement sur le théorème de Bayes qui prédit les résultats en fonction d'une condition ou d'une hypothèse.
Théorème de Bayes :
P(X|Y) = {P(Y|X) * P(X)} / P(Y)
Où P(X|Y) = probabilité conditionnelle de X compte tenu de l'occurrence de Y
P(Y|X) = Probabilité conditionnelle de Y compte tenu de l'occurrence de X
P(X), P(Y) = Probabilité de X et Y individuellement
Soutenir les machines vectorielles
Cet algorithme essaie de séparer les données dans l'espace en fonction de limites qui peuvent être soit une ligne, soit un plan. Cette limite est appelée un « hyperplan » et est définie par les points de données les plus proches de chaque classe qui, à leur tour, sont appelés « vecteurs de support ». La distance maximale entre les vecteurs de support de chaque côté est appelée marge.
Les réseaux de neurones
Perceptron
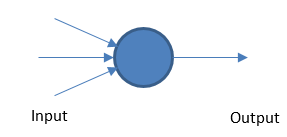
Le réseau neuronal fondamental fonctionne en prenant des entrées et des sorties pondérées en fonction d'une valeur seuil.
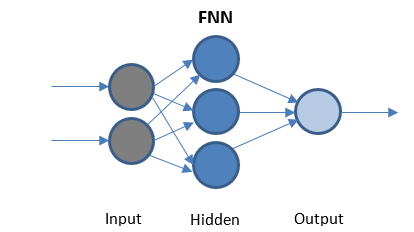
Réseau de neurones Feed Forward
FFN est le réseau le plus simple qui transmet des données dans une seule direction. Peut ou non avoir des couches cachées.
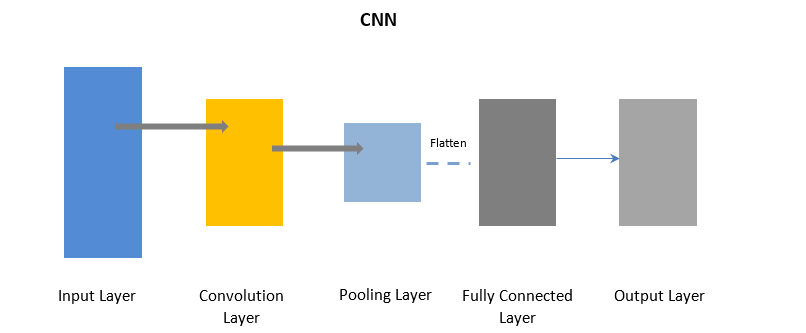
Réseaux de neurones convolutifs
CNN utilise une couche de convolution pour traiter certaines parties des données d'entrée par lots, suivies d'une couche de regroupement pour compléter la sortie.
Réseaux de neurones récurrents
RNN se compose de quelques couches récurrentes entre les couches d'E / S qui peuvent stocker des données «historiques». Le flux de données est bidirectionnel et est transmis aux couches récurrentes pour améliorer les prédictions.
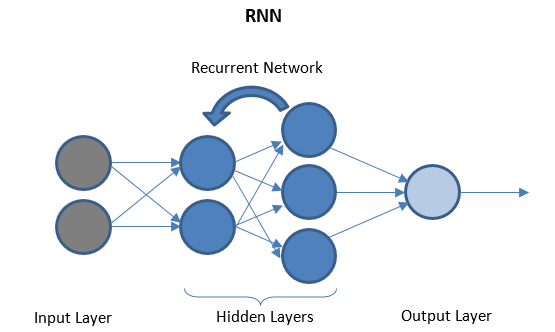
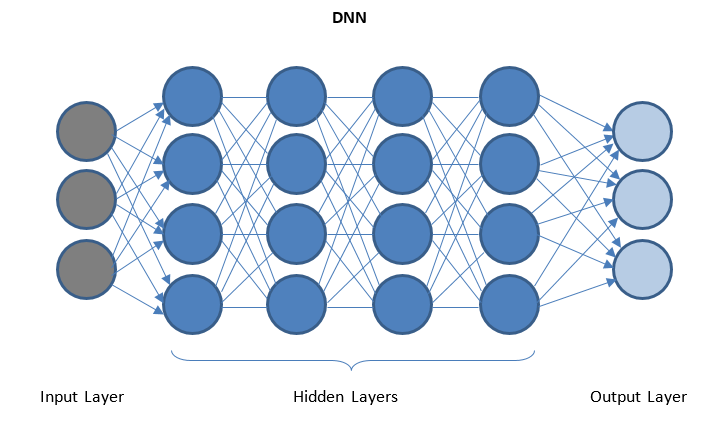
Réseaux de neurones profonds et apprentissage en profondeur
DNN est un réseau avec plusieurs couches cachées entre les couches d'E/S. Les couches cachées appliquent des transformations successives aux données avant de les envoyer à la couche de sortie.
Le 'Deep Learning' est facilité par DNN et peut gérer d'énormes quantités de données complexes et atteindre une grande précision en raison de plusieurs couches cachées
Obtenez une certification en science des données des meilleures universités du monde. Apprenez les programmes Executive PG, les programmes de certificat avancés ou les programmes de maîtrise pour accélérer votre carrière.
Conclusion
La science des données est un vaste domaine qui traverse différents courants mais apparaît comme une révolution et une révélation pour nous. La science des données est en plein essor et changera la façon dont nos systèmes fonctionnent et se sentent à l'avenir.
Si vous êtes curieux d'en savoir plus sur la science des données, consultez le diplôme PG de IIIT-B & upGrad en science des données qui est créé pour les professionnels en activité et propose plus de 10 études de cas et projets, des ateliers pratiques, un mentorat avec des experts de l'industrie, 1- on-1 avec des mentors de l'industrie, plus de 400 heures d'apprentissage et d'aide à l'emploi avec les meilleures entreprises.
Quel langage de programmation est le mieux adapté à la Data Science et pourquoi ?
Il existe des dizaines de langages de programmation pour la science des données, mais la majorité de la communauté des sciences des données pense que si vous voulez exceller en science des données, Python est le bon choix. Voici quelques-unes des raisons qui soutiennent cette croyance :
1. Python propose une large gamme de modules et de bibliothèques comme TensorFlow et PyTorch qui facilitent la gestion des concepts de science des données.
2. Une vaste communauté de développeurs Python aide constamment les débutants à passer à la prochaine phase de leur parcours en science des données.
3. Ce langage est de loin l'un des langages les plus pratiques et les plus faciles à écrire avec une syntaxe propre qui améliore sa lisibilité.
Quels sont les concepts qui rendent la science des données complète ?
La science des données est un vaste domaine qui agit comme un parapluie pour divers autres domaines cruciaux. Voici les concepts les plus importants qui constituent la science des données :
Statistiques
Les statistiques sont un concept important dans lequel vous devez exceller pour progresser dans la science des données. Il contient en outre quelques sous-thèmes :
1. Régression linéaire
2. Probabilité
3. Distribution de probabilité
Intelligence artificielle
La science qui fournit aux machines un cerveau et les laisse prendre leurs propres décisions en fonction des entrées est connue sous le nom d'intelligence artificielle. Les machines réactives, la mémoire limitée, la théorie de l'esprit et la conscience de soi sont quelques-uns des types d'intelligence artificielle.
Apprentissage automatique
L'apprentissage automatique est un autre élément crucial de la science des données qui consiste à enseigner aux machines à prédire les résultats futurs en fonction des données fournies. L'apprentissage automatique a trois méthodes de modélisation importantes : le clustering, la régression et la classification.
Décrire les types d'apprentissage automatique ?
Machine Learning ou simple ML a trois grands types en fonction de leurs méthodes de travail. Ces types sont les suivants :
1. Apprentissage supervisé
Il s'agit du type de ML le plus primitif où les données d'entrée sont étiquetées. La machine est fournie avec un ensemble de données plus petit qui donne à la machine un aperçu du problème et est entraînée dessus.
2. Apprentissage non supervisé
Le plus grand avantage de ce type est que les données ne sont pas étiquetées ici et que le travail humain est presque négligeable. Cela ouvre la porte à l'introduction d'ensembles de données beaucoup plus volumineux dans le modèle.
3. Apprentissage renforcé C'est le type de ML le plus avancé qui s'inspire de la vie des êtres humains. Les sorties souhaitées sont renforcées tandis que les sorties inutiles sont découragées.