
Prétraitement des données dans l'apprentissage automatique : 7 étapes faciles à suivre
Publié: 2021-07-15Le prétraitement des données dans Machine Learning est une étape cruciale qui permet d'améliorer la qualité des données afin de promouvoir l'extraction d'informations significatives à partir des données. Le prétraitement des données dans Machine Learning fait référence à la technique de préparation (nettoyage et organisation) des données brutes pour les rendre adaptées à la construction et à la formation de modèles Machine Learning. En termes simples, le prétraitement des données dans Machine Learning est une technique d'exploration de données qui transforme les données brutes en un format compréhensible et lisible.
Table des matières
Pourquoi le prétraitement des données dans l'apprentissage automatique ?
Lorsqu'il s'agit de créer un modèle de Machine Learning, le prétraitement des données est la première étape marquant l'initiation du processus. En règle générale, les données du monde réel sont incomplètes, incohérentes, inexactes (contiennent des erreurs ou des valeurs aberrantes) et manquent souvent de valeurs/tendances d'attributs spécifiques. C'est là que le prétraitement des données entre dans le scénario - il aide à nettoyer, formater et organiser les données brutes, les rendant ainsi prêtes à l'emploi pour les modèles d'apprentissage automatique. Explorons différentes étapes du prétraitement des données dans l'apprentissage automatique.
Rejoignez le cours d'intelligence artificielle en ligne des meilleures universités du monde - Masters, programmes de troisième cycle pour cadres et programme de certificat avancé en ML et IA pour accélérer votre carrière.
Étapes du prétraitement des données dans l'apprentissage automatique
Il y a sept étapes importantes dans le prétraitement des données dans Machine Learning :
1. Acquérir le jeu de données
L'acquisition de l'ensemble de données est la première étape du prétraitement des données dans l'apprentissage automatique. Pour créer et développer des modèles d'apprentissage automatique, vous devez d'abord acquérir l'ensemble de données pertinent. Cet ensemble de données sera composé de données recueillies auprès de sources multiples et disparates qui sont ensuite combinées dans un format approprié pour former un ensemble de données. Les formats des jeux de données diffèrent selon les cas d'utilisation. Par exemple, un ensemble de données d'entreprise sera entièrement différent d'un ensemble de données médicales. Alors qu'un ensemble de données d'entreprise contiendra des données sectorielles et commerciales pertinentes, un ensemble de données médicales comprendra des données liées aux soins de santé.
Il existe plusieurs sources en ligne à partir desquelles vous pouvez télécharger des ensembles de données comme https://www.kaggle.com/uciml/datasets et https://archive.ics.uci.edu/ml/index.php . Vous pouvez également créer un ensemble de données en collectant des données via différentes API Python. Une fois que le jeu de données est prêt, vous devez le mettre au format de fichier CSV, HTML ou XLSX.

2. Importez toutes les bibliothèques cruciales
Étant donné que Python est la bibliothèque la plus largement utilisée et aussi la plus préférée par les Data Scientists du monde entier, nous allons vous montrer comment importer des bibliothèques Python pour le prétraitement des données dans Machine Learning. En savoir plus sur les bibliothèques Python pour la science des données ici. Les bibliothèques Python prédéfinies peuvent effectuer des tâches de prétraitement de données spécifiques. L'importation de toutes les bibliothèques cruciales est la deuxième étape du prétraitement des données dans l'apprentissage automatique. Les trois bibliothèques Python principales utilisées pour ce prétraitement des données dans Machine Learning sont :
- NumPy - NumPy est le package fondamental pour le calcul scientifique en Python. Par conséquent, il est utilisé pour insérer tout type d'opération mathématique dans le code. En utilisant NumPy, vous pouvez également ajouter de grands tableaux et matrices multidimensionnels dans votre code.
- Pandas - Pandas est une excellente bibliothèque Python open source pour la manipulation et l'analyse de données. Il est largement utilisé pour importer et gérer les ensembles de données. Il contient des structures de données et des outils d'analyse de données hautes performances et faciles à utiliser pour Python.
- Matplotlib - Matplotlib est une bibliothèque de traçage Python 2D utilisée pour tracer tout type de graphiques en Python. Il peut fournir des chiffres de qualité publication dans de nombreux formats papier et environnements interactifs sur toutes les plateformes (shells IPython, bloc-notes Jupyter, serveurs d'applications Web, etc.).
Lire : Idées de projets d'apprentissage automatique pour les débutants
3. Importer le jeu de données
Dans cette étape, vous devez importer le ou les ensembles de données que vous avez rassemblés pour le projet ML en cours. L'importation de l'ensemble de données est l'une des étapes importantes du prétraitement des données dans l'apprentissage automatique. Cependant, avant de pouvoir importer le ou les jeux de données, vous devez définir le répertoire courant comme répertoire de travail. Vous pouvez définir le répertoire de travail dans Spyder IDE en trois étapes simples :
- Enregistrez votre fichier Python dans le répertoire contenant le jeu de données.
- Accédez à l'option Explorateur de fichiers dans Spyder IDE et choisissez le répertoire requis.
- Maintenant, cliquez sur le bouton F5 ou sur l'option Exécuter pour exécuter le fichier.
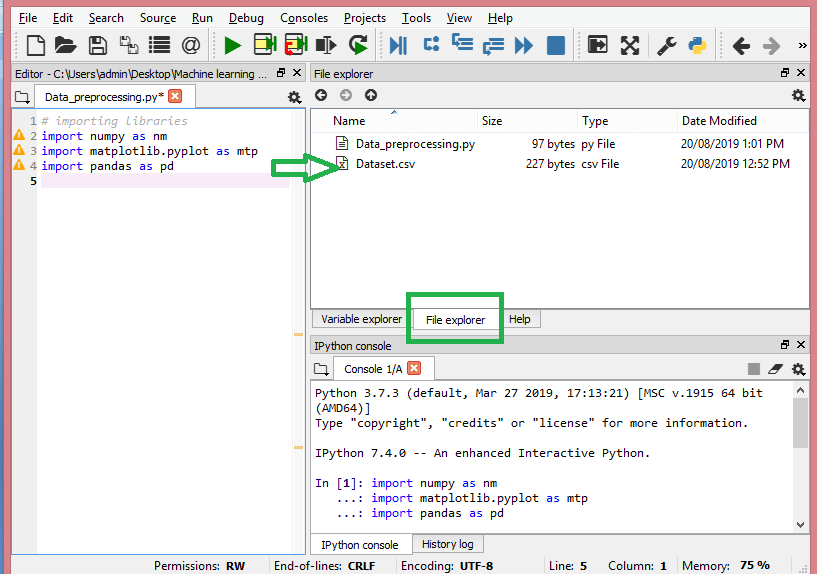
La source
Voici à quoi devrait ressembler le répertoire de travail.
Une fois que vous avez défini le répertoire de travail contenant le jeu de données pertinent, vous pouvez importer le jeu de données à l'aide de la fonction "read_csv()" de la bibliothèque Pandas. Cette fonction peut lire un fichier CSV (soit localement, soit via une URL) et également effectuer diverses opérations dessus. Le read_csv() s'écrit :
data_set= pd.read_csv('Dataset.csv')
Dans cette ligne de code, "data_set" indique le nom de la variable dans laquelle vous avez stocké l'ensemble de données. La fonction contient également le nom du jeu de données. Une fois que vous aurez exécuté ce code, le jeu de données sera importé avec succès.
Pendant le processus d'importation de l'ensemble de données, vous devez effectuer une autre tâche essentielle : extraire les variables dépendantes et indépendantes. Pour chaque modèle de Machine Learning, il est nécessaire de séparer les variables indépendantes (matrice de caractéristiques) et les variables dépendantes dans un jeu de données.
Considérez cet ensemble de données :
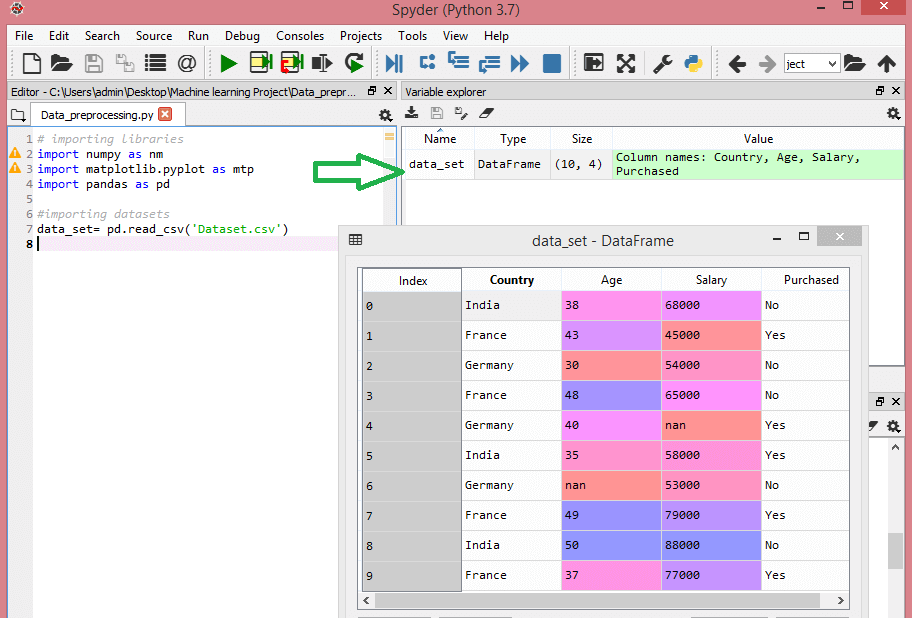
La source
Cet ensemble de données contient trois variables indépendantes - pays, âge et salaire, et une variable dépendante - acheté.
Comment extraire les variables indépendantes ?
Pour extraire les variables indépendantes, vous pouvez utiliser la fonction "iloc[ ]" de la bibliothèque Pandas. Cette fonction peut extraire les lignes et les colonnes sélectionnées du jeu de données.
x= data_set.iloc[:,:-1].values
Dans la ligne de code ci-dessus, le premier deux-points (:) considère toutes les lignes et le deuxième deux-points (:) considère toutes les colonnes. Le code contient ":-1" puisque vous devez omettre la dernière colonne contenant la variable dépendante. En exécutant ce code, vous obtiendrez la matrice des fonctionnalités, comme ceci -
[['Inde' 38.0 68000.0]
['France' 43.0 45000.0]
['Allemagne' 30.0 54000.0]
['France' 48.0 65000.0]
['Allemagne' 40.0 nan]
['Inde' 35.0 58000.0]
['Allemagne' nan 53000.0]
['France' 49.0 79000.0]
['Inde' 50.0 88000.0]
['France' 37.0 77000.0]]
Comment extraire la variable dépendante ?
Vous pouvez également utiliser la fonction "iloc[ ]" pour extraire la variable dépendante. Voici comment vous l'écrivez :
y= data_set.iloc[:,3].values
Cette ligne de code considère toutes les lignes avec la dernière colonne uniquement. En exécutant le code ci-dessus, vous obtiendrez le tableau de variables dépendantes, comme ceci -
array(['Non', 'Oui', 'Non', 'Non', 'Oui', 'Oui', 'Non', 'Oui', 'Non', 'Oui'],
dtype=objet)
4. Identifier et traiter les valeurs manquantes
Dans le prétraitement des données, il est essentiel d'identifier et de gérer correctement les valeurs manquantes, faute de quoi, vous pourriez tirer des conclusions et des inférences inexactes et erronées à partir des données. Inutile de dire que cela entravera votre projet ML.
Fondamentalement, il existe deux façons de gérer les données manquantes :
- Suppression d'une ligne particulière – Dans cette méthode, vous supprimez une ligne spécifique qui a une valeur nulle pour une caractéristique ou une colonne particulière où plus de 75 % des valeurs sont manquantes. Cependant, cette méthode n'est pas efficace à 100 % et il est recommandé de l'utiliser uniquement lorsque le jeu de données contient des échantillons adéquats. Vous devez vous assurer qu'après la suppression des données, il ne reste aucun ajout de biais.
- Calcul de la moyenne - Cette méthode est utile pour les fonctionnalités contenant des données numériques telles que l'âge, le salaire, l'année, etc. Ici, vous pouvez calculer la moyenne, la médiane ou le mode d'une fonctionnalité particulière ou d'une colonne ou d'une ligne contenant une valeur manquante et remplacer le résultat pour la valeur manquante. Cette méthode peut ajouter de la variance à l'ensemble de données et toute perte de données peut être efficacement annulée. Par conséquent, elle donne de meilleurs résultats par rapport à la première méthode (omission de lignes/colonnes). Une autre méthode d'approximation consiste à écarter les valeurs voisines. Cependant, cela fonctionne mieux pour les données linéaires.
Lire : Applications d'applications d'apprentissage automatique utilisant le cloud
5. Encodage des données catégorielles
Les données catégorielles font référence aux informations qui ont des catégories spécifiques dans l'ensemble de données. Dans l'ensemble de données cité ci-dessus, il y a deux variables catégorielles - pays et acheté.
Les modèles d'apprentissage automatique sont principalement basés sur des équations mathématiques. Ainsi, vous pouvez intuitivement comprendre que le fait de conserver les données catégorielles dans l'équation causera certains problèmes puisque vous n'auriez besoin que de nombres dans les équations.
Comment encoder la variable pays ?
Comme on le voit dans notre exemple d'ensemble de données, la colonne de pays causera des problèmes, vous devez donc la convertir en valeurs numériques. Pour ce faire, vous pouvez utiliser la classe LabelEncoder() de la bibliothèque sci-kit learn. Le code sera le suivant -
#Données catégorielles
#pour la variable de pays
de sklearn.preprocessing importer LabelEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
Et la sortie sera -
Sortie[15] :
tableau([[2, 38.0, 68000.0],
[0, 43.0, 45000.0],
[1, 30.0, 54000.0],
[0, 48.0, 65000.0],
[1, 40.0, 65222.22222222222],
[2, 35.0, 58000.0],
[1, 41.111111111111114, 53000.0],
[0, 49.0, 79000.0],
[2, 50.0, 88000.0],
[0, 37.0, 77000.0]], dtype=objet)
Ici, nous pouvons voir que la classe LabelEncoder a codé avec succès les variables en chiffres. Cependant, certaines variables de pays sont encodées sous la forme 0, 1 et 2 dans la sortie ci-dessus. Ainsi, le modèle ML peut supposer qu'il existe une certaine corrélation entre les trois variables, produisant ainsi une sortie erronée. Pour éliminer ce problème, nous allons maintenant utiliser Dummy Encoding.
Les variables fictives sont celles qui prennent les valeurs 0 ou 1 pour indiquer l'absence ou la présence d'un effet catégoriel spécifique qui peut modifier le résultat. Dans ce cas, la valeur 1 indique la présence de cette variable dans une colonne particulière tandis que les autres variables prennent la valeur 0. Dans le codage factice, le nombre de colonnes est égal au nombre de catégories.
Étant donné que notre ensemble de données comporte trois catégories, il produira trois colonnes ayant les valeurs 0 et 1. Pour Dummy Encoding, nous utiliserons la classe OneHotEncoder de la bibliothèque scikit-learn. Le code d'entrée sera le suivant -
#pour la variable de pays

de sklearn.preprocessing importer LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#Encodage pour les variables factices
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
Lors de l'exécution de ce code, vous obtiendrez la sortie suivante -
tableau([[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.80000000e+01,
6.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.30000000e+01,
4.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 3.00000000e+01,
5.40000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.80000000e+01,
6.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.00000000e+01,
6.52222222e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.50000000e+01,
5.80000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.11111111e+01,
5.30000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.90000000e+01,
7.90000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 5.00000000e+01,
8.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 3.70000000e+01,
7.70000000e+04]])
Dans la sortie ci-dessus, toutes les variables sont divisées en trois colonnes et codées dans les valeurs 0 et 1.
Comment encoder la variable achetée ?
Pour la deuxième variable catégorielle, c'est-à-dire achetée, vous pouvez utiliser l'objet "labelencoder" de la classe LableEncoder. Nous n'utilisons pas la classe OneHotEncoder car la variable achetée n'a que deux catégories oui ou non, toutes deux encodées en 0 et 1.
Le code d'entrée pour cette variable sera -
labelencoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
La sortie sera -
Sortie[17] : tableau([0, 1, 0, 0, 1, 1, 0, 1, 0, 1])
6. Diviser le jeu de données
La division de l'ensemble de données est la prochaine étape du prétraitement des données dans l'apprentissage automatique. Chaque ensemble de données pour le modèle d'apprentissage automatique doit être divisé en deux ensembles distincts : l'ensemble d'apprentissage et l'ensemble de test.
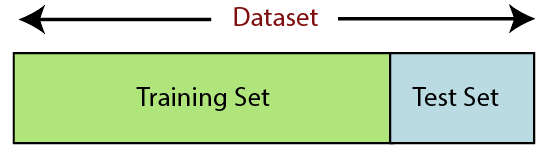
La source
L'ensemble d'apprentissage désigne le sous-ensemble d'un ensemble de données utilisé pour l'apprentissage du modèle d'apprentissage automatique. Ici, vous êtes déjà au courant de la sortie. Un ensemble de test, en revanche, est le sous-ensemble de l'ensemble de données utilisé pour tester le modèle d'apprentissage automatique. Le modèle ML utilise l'ensemble de tests pour prédire les résultats.
Habituellement, l'ensemble de données est divisé en ratio 70:30 ou 80:20. Cela signifie que vous prenez 70 % ou 80 % des données pour entraîner le modèle tout en laissant de côté 30 % ou 20 % du reste. Le processus de fractionnement varie en fonction de la forme et de la taille de l'ensemble de données en question.
Pour diviser l'ensemble de données, vous devez écrire la ligne de code suivante -
depuis sklearn.model_selection importer train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
Ici, la première ligne divise les tableaux de l'ensemble de données en sous-ensembles de train et de test aléatoires. La deuxième ligne de code comprend quatre variables :
- x_train - fonctionnalités pour les données d'entraînement
- x_test - fonctionnalités pour les données de test
- y_train – variables dépendantes pour les données d'entraînement
- y_test – variable indépendante pour tester les données
Ainsi, la fonction train_test_split() inclut quatre paramètres, dont les deux premiers sont pour des tableaux de données. La fonction test_size spécifie la taille de l'ensemble de test. Le test_size peut être .5, .3 ou .2 - cela spécifie le rapport de division entre les ensembles d'apprentissage et de test. Le dernier paramètre, "random_state" définit la graine d'un générateur aléatoire afin que la sortie soit toujours la même.
7. Mise à l'échelle des fonctionnalités
La mise à l'échelle des fonctionnalités marque la fin du prétraitement des données dans Machine Learning. C'est une méthode pour normaliser les variables indépendantes d'un ensemble de données dans une plage spécifique. En d'autres termes, la mise à l'échelle des fonctionnalités limite la plage de variables afin que vous puissiez les comparer sur des bases communes.
Considérez cet ensemble de données par exemple -
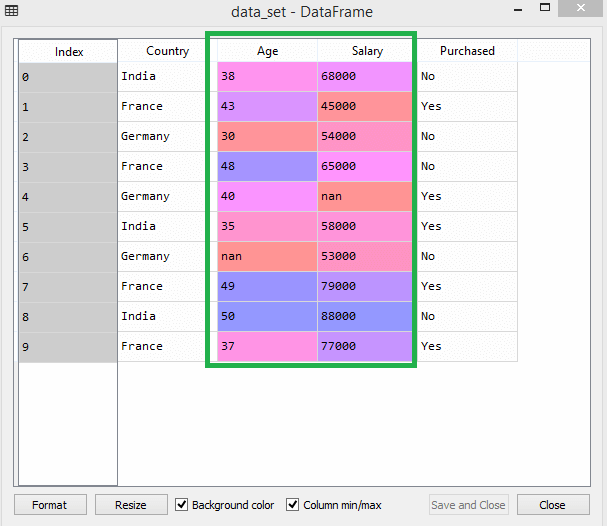
La source
Dans le jeu de données, vous pouvez remarquer que les colonnes d'âge et de salaire n'ont pas la même échelle. Dans un tel scénario, si vous calculez deux valeurs quelconques à partir des colonnes d'âge et de salaire, les valeurs de salaire domineront les valeurs d'âge et fourniront des résultats incorrects. Par conséquent, vous devez supprimer ce problème en effectuant une mise à l'échelle des fonctionnalités pour Machine Learning.
La plupart des modèles ML sont basés sur la distance euclidienne, qui est représentée par :
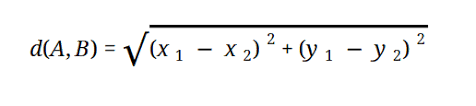
La source
Vous pouvez effectuer la mise à l'échelle des fonctionnalités dans Machine Learning de deux manières :
Standardisation
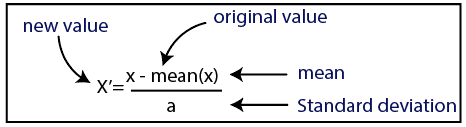
La source
Normalisation
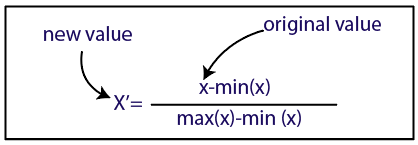
La source
Pour notre jeu de données, nous utiliserons la méthode de standardisation. Pour ce faire, nous allons importer la classe StandardScaler de la bibliothèque sci-kit-learn en utilisant la ligne de code suivante :
depuis sklearn.preprocessing importer StandardScaler
La prochaine étape consistera à créer l'objet de la classe StandardScaler pour les variables indépendantes. Ensuite, vous pouvez ajuster et transformer l'ensemble de données d'entraînement à l'aide du code suivant :
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
Pour l'ensemble de données de test, vous pouvez appliquer directement la fonction transform() (vous n'avez pas besoin d'utiliser la fonction fit_transform() car elle est déjà effectuée dans l'ensemble d'apprentissage). Le code sera le suivant -
x_test= st_x.transform(x_test)
La sortie de l'ensemble de données de test affichera les valeurs mises à l'échelle pour x_train et x_test comme :
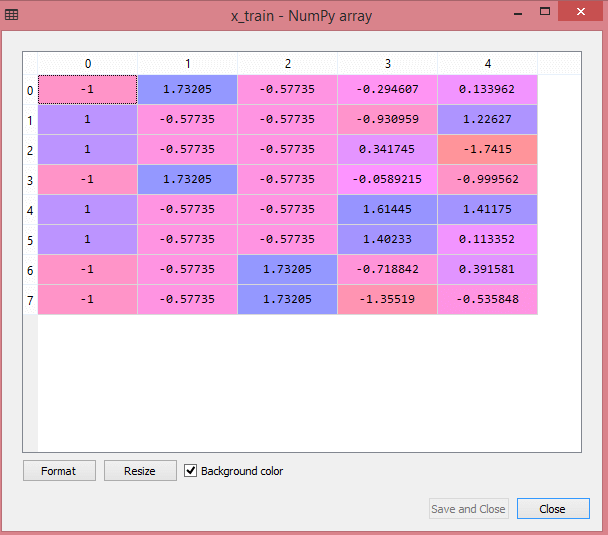
La source
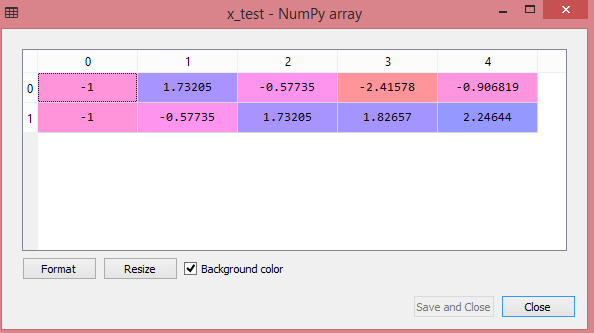
La source
Toutes les variables de la sortie sont mises à l'échelle entre les valeurs -1 et 1.
Maintenant, pour combiner toutes les étapes que nous avons effectuées jusqu'à présent, vous obtenez :
# importer des bibliothèques
importer numpy comme nm
importer matplotlib.pyplot en tant que mtp
importer des pandas en tant que pd
#importer des ensembles de données
data_set= pd.read_csv('Dataset.csv')
#Extraire la variable indépendante
x= data_set.iloc[:, :-1].values
#Extraire la variable dépendante
y= data_set.iloc[:, 3].values
#gestion des données manquantes (remplacement des données manquantes par la valeur moyenne)
de sklearn.preprocessing import Imputer
imputer= Imputer(missing_values ='NaN', strategy='mean', axis = 0)
#Ajustement de l'objet imputer aux variables indépendantes x.
imputerimputer= imputer.fit(x[:, 1:3])
#Remplacer les données manquantes par la valeur moyenne calculée
x[:, 1:3]= imputer.transform(x[:, 1:3])
#pour la variable de pays
de sklearn.preprocessing importer LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#Encodage pour les variables factices
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
#encoding pour la variable achetée
labelencoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
# Diviser l'ensemble de données en ensemble d'entraînement et de test.
depuis sklearn.model_selection importer train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
#Feature Mise à l'échelle des jeux de données
depuis sklearn.preprocessing importer StandardScaler
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
x_test= st_x.transform(x_test)
Voilà donc le traitement des données dans le Machine Learning en un mot !
Vous pouvez consulter le programme Executive PG d'IIT Delhi en Machine Learning & AI en association avec upGrad . IIT Delhi est l'une des institutions les plus prestigieuses d'Inde. Avec plus de 500 membres du corps professoral internes qui sont les meilleurs dans les matières.
Quelle est l'importance du prétraitement des données ?
Étant donné que les erreurs, les redondances, les valeurs manquantes et les incohérences compromettent toutes l'intégrité de l'ensemble de données, vous devez toutes les traiter pour obtenir un résultat plus précis. Supposons que vous utilisez un ensemble de données défectueux pour former un système d'apprentissage automatique pour gérer les achats de vos clients. Le système est susceptible de générer des biais et des déviations, entraînant une mauvaise expérience utilisateur. Par conséquent, avant d'utiliser ces données aux fins prévues, elles doivent être aussi organisées et «propres» que possible. Selon le type de difficulté que vous rencontrez, il existe de nombreuses options.
Qu'est-ce que le nettoyage des données ?
Il y aura presque certainement des données manquantes et bruyantes dans vos ensembles de données. Parce que la procédure de collecte de données n'est pas idéale, vous aurez beaucoup d'informations inutiles et manquantes. Le nettoyage des données est la méthode que vous devez utiliser pour résoudre ce problème. Cela peut être divisé en deux catégories. Le premier explique comment traiter les données manquantes. Vous pouvez choisir d'ignorer les valeurs manquantes dans cette section de la collecte de données (appelée tuple). La deuxième méthode de nettoyage des données concerne les données bruyantes. Il est essentiel de se débarrasser des données inutiles qui ne peuvent pas être lues par les systèmes si vous voulez que l'ensemble du processus se déroule sans heurts.
Qu'entendez-vous par transformation et réduction des données ?
Le prétraitement des données passe à l'étape de transformation après avoir traité les préoccupations. Vous l'utilisez pour convertir les données en conformations pertinentes pour l'analyse. La normalisation, la sélection d'attributs, la discrétisation et la génération de hiérarchie de concepts sont quelques-unes des approches qui peuvent être utilisées pour y parvenir. Même pour les méthodes automatisées, passer au crible de grands ensembles de données peut prendre beaucoup de temps. C'est pourquoi l'étape de réduction des données est si cruciale : elle réduit la taille des ensembles de données en les limitant aux informations les plus importantes, ce qui augmente l'efficacité du stockage tout en réduisant les dépenses financières et temporelles liées à leur utilisation.