
Cadres de données en Python : Tutoriel approfondi Python 2022
Publié: 2021-01-09Si vous êtes un développeur ou un codeur qui travaille dans le langage de programmation Python, vous devez être familiarisé avec l'une des bibliothèques de gestion de données les plus étonnantes - Pandas, l'une des meilleures bibliothèques Python. Au fil des ans, Pandas est devenu un outil standard d'analyse et de gestion de données à l'aide de Python. Découvrez d'autres outils Python importants.
Pandas est sans aucun doute le package Python le plus polyvalent pour la science des données et à juste titre. Il fournit des structures de données puissantes, expressives et flexibles pour faciliter la manipulation et l'analyse des données, et Data Frames en Python est l'une de ces structures.
Ce sont précisément nos sujets de discussion dans cet article - nous vous présenterons le format de données de base pour Pandas, c'est-à-dire la trame de données Pandas.
Table des matières
Qu'est-ce qu'une trame de données ?
Selon la documentation de la bibliothèque Pandas , un Data Frame est une "structure de données tabulaire bidimensionnelle, variable en taille et potentiellement hétérogène avec des axes étiquetés (lignes et colonnes)". En termes simples, une trame de données est une structure de données dans laquelle les données sont alignées de manière tabulaire, c'est-à-dire en lignes et en colonnes.
Une Data Frame a généralement les caractéristiques suivantes :
- Il peut avoir plusieurs lignes et colonnes.
- Alors que chaque ligne représente un échantillon de données, chaque colonne comprend une variable différente qui décrit les échantillons (lignes).
- Les données de chaque colonne sont généralement du même type de données (par exemple, des nombres, des chaînes, des dates, etc.).
- Contrairement aux ensembles de données Excel, il évite d'avoir des valeurs manquantes, il n'y a donc pas d'espaces ou de valeurs vides entre les lignes ou les colonnes.
Dans un cadre de données Pandas, vous pouvez également spécifier les noms d'index et de colonne pour votre cadre de données. Alors que l'index indique la différence entre les lignes, les noms de colonne indiquent la différence entre les colonnes.
Comment créer une trame de données en Python (à l'aide de Pandas)
La création d'un cadre de données est la première étape de la gestion des données en Python. Vous pouvez créer un cadre de données Pandas en utilisant des entrées telles que :
- Dict
- Listes
- Séries
- Numpy "ndarray"
- Une autre trame de données
- Fichiers externes tels que CS
- Création d'un bloc de données vide
Il est assez facile de créer une trame de données de base, c'est-à-dire une trame de données vide. Voici un exemple :
Contribution -

Sortir -

- Création d'un bloc de données à partir de listes
Vous pouvez créer un bloc de données à l'aide d'une seule liste ou de plusieurs listes.
Contribution -

Sortir -

- Création d'un cadre de données à partir de Dict de "ndarrays" ou de listes
Pour créer un Data Frame à partir d'un dict de ndarrays, tous les ndarrays doivent avoir la même longueur. De plus, s'il est indexé, la longueur de l'index doit être égale à la longueur des tableaux. Cependant, s'il n'est pas indexé, l'index sera range(n) par défaut, où 'n' indique la longueur du tableau.
Contribution -

Sortir -

Ici, les valeurs 0,1,2,3 sont l'index par défaut attribué à chaque ligne à l'aide de la fonction range(n).
Quelles sont les opérations fondamentales sur les trames de données ?
Maintenant que nous avons vu trois façons de créer des cadres de données en Python, il est temps d'en savoir plus sur les différentes opérations au sein d'un cadre de données.
- Sélection d'un index ou d'une colonne à partir d'un cadre de données Pandas
Il est important de savoir comment sélectionner un index ou une colonne avant de commencer à ajouter, supprimer et renommer les composants dans un DataFrame. Supposons qu'il s'agisse de votre cadre de données :

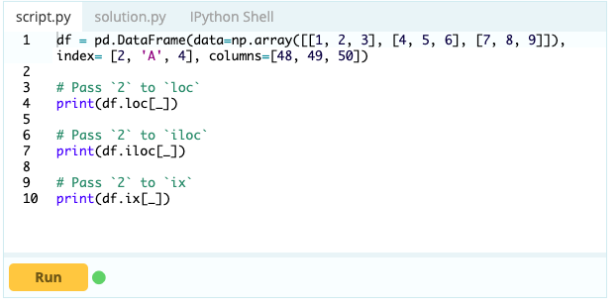
Vous souhaitez accéder à la valeur sous l'index 0 dans la colonne 'A' - la valeur est 1. Il existe plusieurs façons d'accéder à cette valeur, mais deux des plus importantes sont - .loc[] et .iloc[].
Contribution -
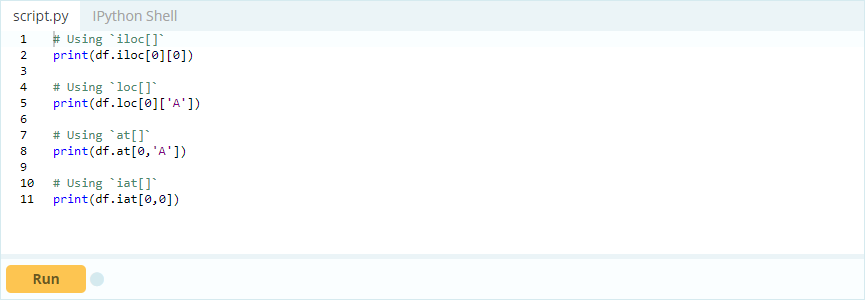
Sortir -
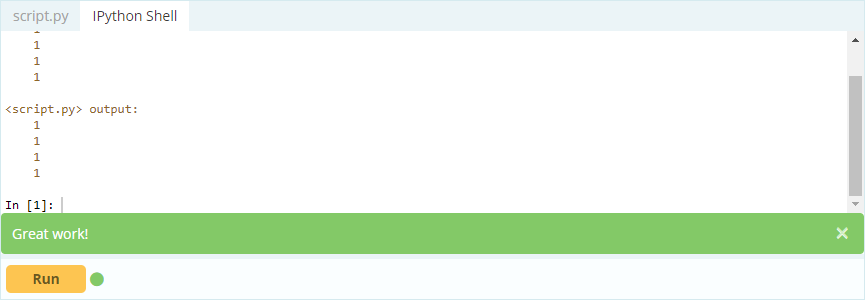
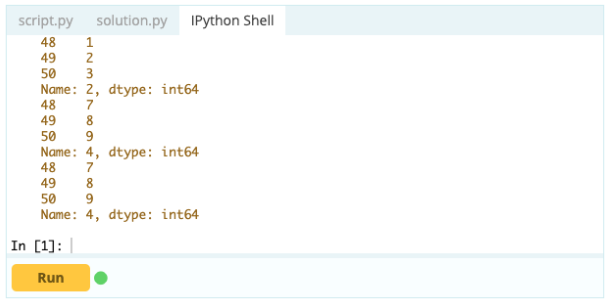
Ainsi, comme vous pouvez le voir, vous pouvez accéder aux valeurs soit en les appelant par leur étiquette, soit en déclarant leur position dans l'index ou la colonne. Alors qu'il s'agissait de sélectionner une valeur à partir d'un bloc de données, comment pouvez-vous sélectionner des lignes et des colonnes à partir de celui-ci ?
C'est ainsi:
Contribution -
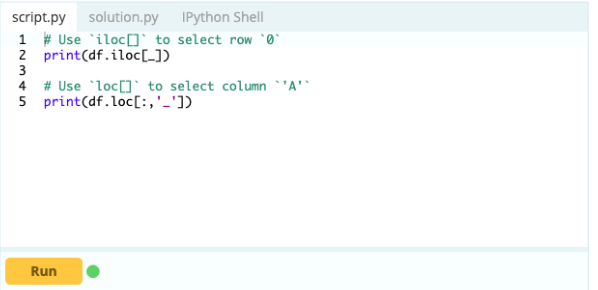
Sortir-
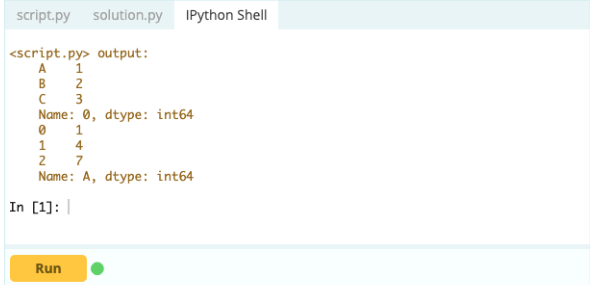
- Comment ajouter un index, une ligne ou une colonne à un DataFrame Pandas
Une fois que vous avez appris à accéder aux valeurs et à sélectionner des colonnes à partir d'un cadre de données, vous pouvez apprendre à ajouter un index, une ligne ou une colonne dans un cadre de données Pandas.
Ajout d'un index :
Lors de la création d'un bloc de données, vous pouvez choisir d'ajouter une entrée à l'argument 'index'. Cela garantit que vous pouvez facilement accéder à l'index que vous désirez. Si vous ne spécifiez pas l'index, par défaut, un index à valeur numérique commençant par 0 et continuant jusqu'à la dernière ligne du DataFrame lui sera ajouté. Bien que, même après que l'index soit spécifié par défaut, vous pouvez utiliser une colonne et la convertir en index en appelant la fonction set_index() dans le Data Frame.

Ajout d'une ligne :
Vous pouvez ajouter des lignes à un DataFrame à l'aide de la fonction append.
Contribution -

Sortir -

Vous pouvez également utiliser .loc pour insérer des lignes dans votre DataFrame comme ceci :
Contribution -
Sortir -
Ajout d'une colonne
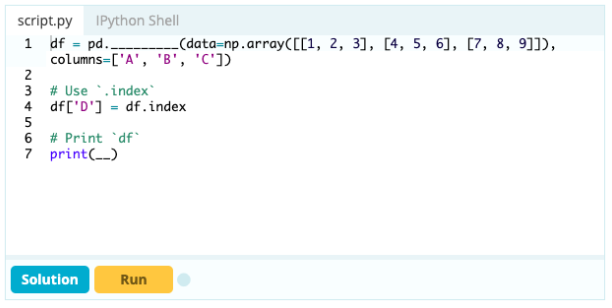
Si vous souhaitez faire d'un index une partie d'un Data Frame, vous pouvez prendre une colonne du Data Frame ou faire référence à une colonne qui n'a pas encore été créée, et l'affecter à la propriété .index comme ceci :
Contribution -
Sortir -
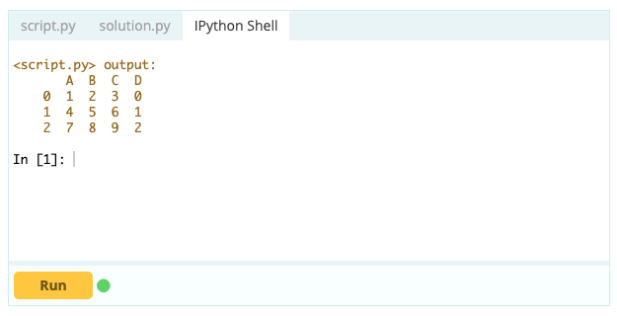
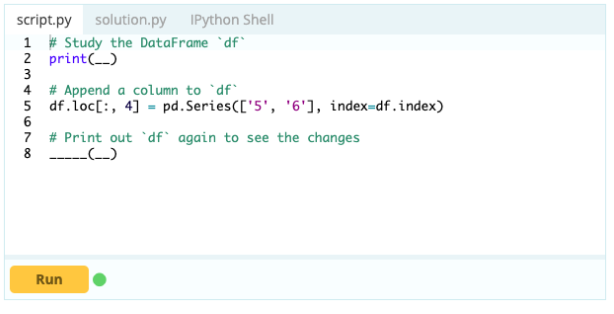
Pour ajouter des colonnes à une trame de données, vous pouvez également utiliser la même approche que vous utiliseriez pour ajouter un index à la trame de données, c'est-à-dire que vous pouvez utiliser la fonction .loc[ ] ou .iloc[ ]. Par exemple:
Contribution -
Sortir
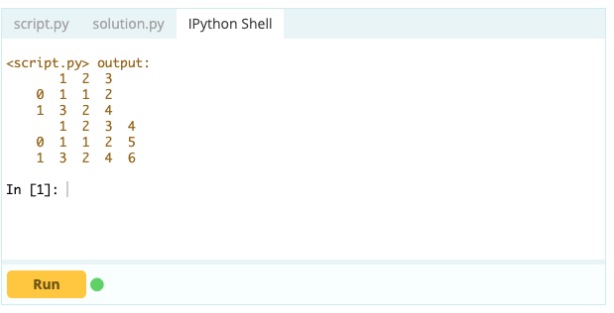
Avec .loc[ ], vous pouvez ajouter une série à un DataFrame existant. Puisqu'un objet Series est assez similaire à une colonne d'un Data Frame, il est très facile d'ajouter une Series à un Data Frame existant.
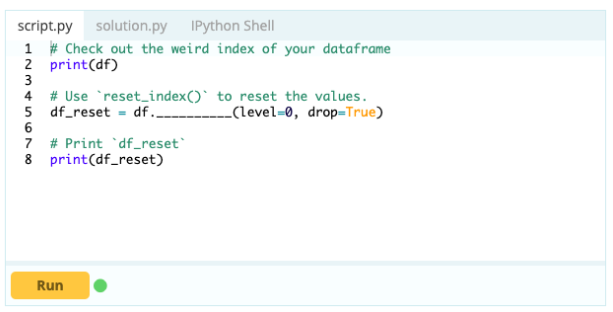
- Comment réinitialiser l'index d'une trame de données ?
Vous pouvez réinitialiser l'index d'un bloc de données s'il ne se présente pas comme vous le souhaitez. Vous pouvez utiliser la fonction .reset_index() pour ce faire.
Contribution -
Sortir -
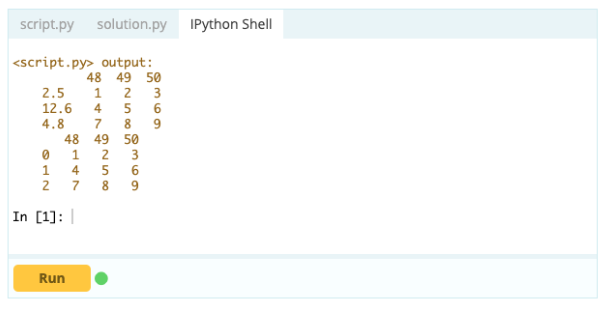
- Comment supprimer un index, une ligne ou une colonne dans un DataFrame Pandas
Suppression d'un index
- Réinitialisation de l'index de la trame de données.
- Supprimez le nom de l'index (le cas échéant) à l'aide de la fonction del df.index.name.
- Supprimer un index avec une ligne.
- Supprimez toutes les valeurs d'index en double en réinitialisant l'index, en supprimant les doublons de la colonne d'index qui a été ajoutée au bloc de données et en rétablissant la nouvelle colonne (sans index en double) en tant qu'index.
Suppression d'une colonne
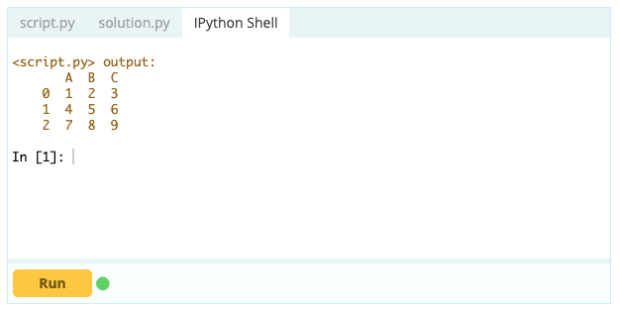
Pour supprimer des colonnes d'un Data Frame, vous pouvez utiliser la fonction drop().
Contribution -
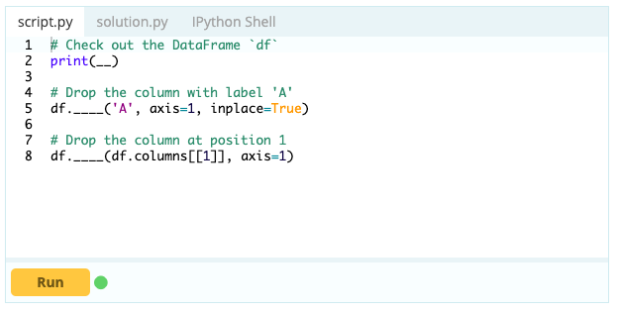
Sortir -
Suppression d'une ligne
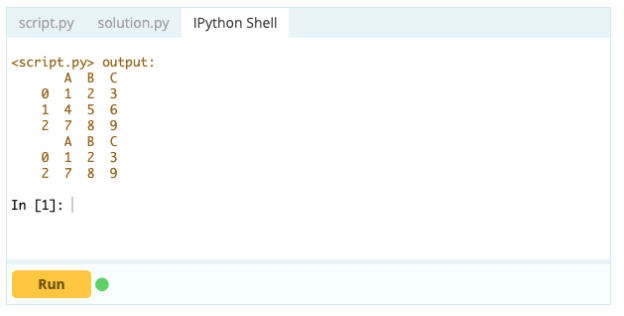
Pour supprimer une ligne d'un Data Frame, vous pouvez utiliser la fonction drop() en utilisant la propriété index pour spécifier l'index des lignes que vous souhaitez supprimer du DataFrame.
Contribution -
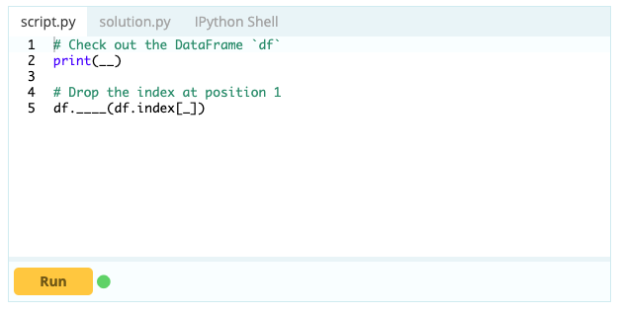
Sortir -
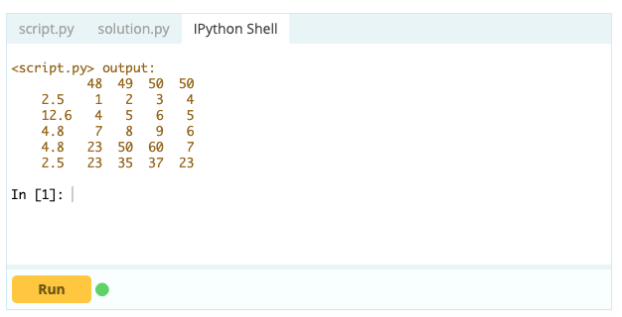
Cependant, pour supprimer les lignes en double, vous pouvez utiliser la fonction df.drop_duplicates().
Contribution -
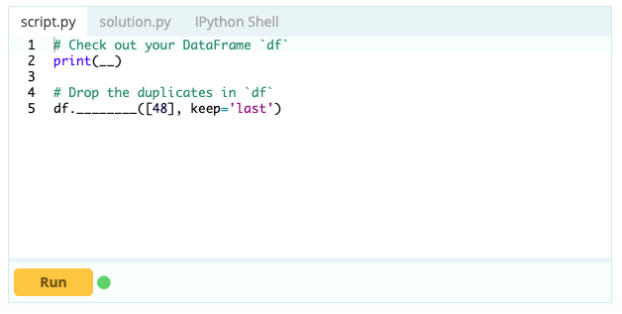
Sortir -
Sources : Tutorielspoint Datacamp
Conclusion
Donc, il y a votre tutoriel de base pour Data Frame en Python en utilisant Pandas.
Si vous êtes intéressé à apprendre Python, la science des données, consultez le diplôme PG de IIIT-B & upGrad en science des données qui est créé pour les professionnels en activité et propose plus de 10 études de cas et projets, des ateliers pratiques, un mentorat avec des experts de l'industrie, 1-on-1 avec des mentors de l'industrie, plus de 400 heures d'apprentissage et d'aide à l'emploi avec les meilleures entreprises.
Pourquoi Pandas est-il l'une des bibliothèques préférées pour créer des cadres de données en Python ?
La bibliothèque Pandas est considérée comme la mieux adaptée à la création de trames de données car elle fournit diverses fonctionnalités qui la rendent efficace pour créer une trame de données. Certaines de ces fonctionnalités sont les suivantes : Les pandas nous fournissent diverses trames de données qui permettent non seulement une représentation efficace des données, mais nous permettent également de les manipuler. Il fournit des fonctionnalités d'alignement et d'indexation efficaces qui offrent des moyens intelligents d'étiqueter et d'organiser les données. Certaines fonctionnalités de Pandas rendent le code propre et augmentent sa lisibilité, le rendant ainsi plus efficace. Il peut également lire plusieurs formats de fichiers. JSON, CSV, HDF5 et Excel sont quelques-uns des formats de fichiers pris en charge par Pandas. La fusion de plusieurs ensembles de données a été un véritable défi pour de nombreux programmeurs. Les pandas surmontent également cela et fusionnent très efficacement plusieurs ensembles de données.
Quels sont les autres bibliothèques et outils qui complètent la bibliothèque Pandas ?
Pandas fonctionne non seulement comme une bibliothèque centrale pour créer des cadres de données, mais il fonctionne également avec d'autres bibliothèques et outils de Python pour être plus efficace. Pandas est construit sur le package NumPy Python, ce qui indique que la majeure partie de la structure de la bibliothèque Pandas est répliquée à partir du package NumPy. L'analyse statistique des données de la bibliothèque Pandas est opérée par SciPy, des fonctions de traçage sur Matplotlib et des algorithmes d'apprentissage automatique dans Scikit-learn. Jupyter Notebook est un environnement interactif basé sur le Web qui fonctionne comme un IDE et offre un bon environnement pour Pandas.
Quelles sont les opérations fondamentales sur les trames de données ?
Il est important de sélectionner un index ou une colonne avant de commencer toute opération comme l'ajout ou la suppression. Une fois que vous avez appris à accéder aux valeurs et à sélectionner des colonnes à partir d'un cadre de données, vous pouvez apprendre à ajouter un index, une ligne ou une colonne dans un cadre de données Pandas. Si l'index dans le bloc de données ne correspond pas à ce que vous souhaitiez, vous pouvez le réinitialiser. Pour réinitialiser l'index, vous pouvez utiliser la fonction "reset_index()".