
Ajout de capacités de fractionnement de code à un site Web WordPress via PoP
Publié: 2022-03-10La vitesse est l'une des principales priorités de tout site Web de nos jours. Une façon d'accélérer le chargement d'un site Web consiste à diviser le code : diviser une application en morceaux pouvant être chargés à la demande - en ne chargeant que le JavaScript requis et rien d'autre. Les sites Web basés sur des frameworks JavaScript peuvent immédiatement implémenter le fractionnement de code via Webpack, le bundle JavaScript populaire. Pour les sites Web WordPress, cependant, ce n'est pas si facile. Tout d'abord, Webpack n'a pas été intentionnellement conçu pour fonctionner avec WordPress, donc sa configuration nécessitera une certaine solution de contournement ; deuxièmement, aucun outil ne semble être disponible pour fournir des capacités natives de chargement d'actifs à la demande pour WordPress.
Compte tenu de ce manque de solution appropriée pour WordPress, j'ai décidé d'implémenter ma propre version de fractionnement de code pour PoP, un framework open-source pour la construction de sites Web WordPress que j'ai créé. Un site Web WordPress avec PoP installé aura des capacités de fractionnement de code nativement, il n'aura donc pas besoin de dépendre de Webpack ou de tout autre bundler. Dans cet article, je vais vous montrer comment c'est fait, en expliquant quelles décisions ont été prises en fonction des aspects de l'architecture du framework. En fin de compte, j'analyserai les performances d'un site Web avec et sans fractionnement de code, ainsi que les avantages et les inconvénients de l'utilisation d'une implémentation personnalisée par rapport à un bundler externe. J'espère que vous apprécierez la balade !
Définir la stratégie
Le fractionnement de code peut être globalement divisé en ces deux étapes :
- Calculer quels actifs doivent être chargés pour chaque itinéraire,
- Chargement dynamique de ces ressources à la demande.
Pour aborder la première étape, nous devrons produire une carte de dépendance des actifs, comprenant tous les actifs de notre application. Les actifs doivent être ajoutés de manière récursive à cette carte - les dépendances des dépendances doivent également être ajoutées, jusqu'à ce qu'aucun autre actif ne soit nécessaire. Nous pouvons ensuite calculer toutes les dépendances requises pour une route spécifique en parcourant la carte des dépendances des actifs, en partant du point d'entrée de la route (c'est-à-dire le fichier ou le morceau de code à partir duquel elle commence l'exécution) jusqu'au dernier niveau.
Pour aborder la deuxième étape, nous pourrions calculer quels actifs sont nécessaires pour l'URL demandée côté serveur, puis envoyer la liste des actifs nécessaires dans la réponse, sur laquelle l'application aurait besoin de les charger, ou directement HTTP/ 2 poussez les ressources parallèlement à la réponse.
Ces solutions ne sont cependant pas optimales. Dans le premier cas, l'application doit demander tous les actifs après le retour de la réponse, il y aurait donc une série supplémentaire de demandes aller-retour pour récupérer les actifs, et la vue ne pourrait pas être générée avant qu'ils ne soient tous chargés, ce qui entraînerait l'utilisateur devant attendre (ce problème est atténué par le fait que tous les actifs sont pré-cachés via les agents de service, ce qui réduit le temps d'attente, mais nous ne pouvons pas éviter l'analyse des actifs qui ne se produit qu'après le retour de la réponse). Dans le second cas, nous pourrions pousser les mêmes actifs à plusieurs reprises (à moins que nous n'ajoutions une logique supplémentaire, comme pour indiquer quelles ressources nous avons déjà chargées via les cookies, mais cela ajoute en effet une complexité indésirable et empêche la réponse d'être mise en cache), et nous ne peut pas servir les actifs à partir d'un CDN.
Pour cette raison, j'ai décidé de faire gérer cette logique côté client. Une liste des actifs nécessaires pour chaque route est mise à la disposition de l'application sur le client, de sorte qu'elle sait déjà quels actifs sont nécessaires pour l'URL demandée. Cela résout les problèmes mentionnés ci-dessus :
- Les actifs peuvent être chargés immédiatement, sans avoir à attendre la réponse du serveur. (Lorsque nous associons cela à des techniciens de service, nous pouvons être sûrs qu'au moment où la réponse est de retour, toutes les ressources auront été chargées et analysées, il n'y a donc pas de temps d'attente supplémentaire.)
- L'application sait quels actifs ont déjà été chargés ; par conséquent, il ne demandera pas tous les actifs requis pour cette route, mais uniquement les actifs qui n'ont pas encore été chargés.
L'aspect négatif de la livraison de cette liste au front-end est qu'elle peut devenir lourde, en fonction de la taille du site Web (comme le nombre de routes qu'il met à disposition). Nous devons trouver un moyen de le charger sans augmenter le temps de chargement perçu de l'application. Plus à ce sujet plus tard.
Après avoir pris ces décisions, nous pouvons procéder à la conception puis à la mise en œuvre du fractionnement de code dans l'application. Pour faciliter la compréhension, le processus a été divisé en plusieurs étapes :
- Comprendre l'architecture de l'application,
- Cartographier les dépendances des actifs,
- Lister toutes les voies d'application,
- Générer une liste qui définit les actifs nécessaires pour chaque itinéraire,
- Chargement dynamique des actifs,
- Application des optimisations.
Allons droit au but !
0. Comprendre l'architecture de l'application
Nous devrons cartographier la relation de tous les actifs les uns avec les autres. Passons en revue les particularités de l'architecture de PoP afin de concevoir la solution la plus adaptée pour atteindre cet objectif.
PoP est une couche qui entoure WordPress, nous permettant d'utiliser WordPress comme CMS qui alimente l'application, tout en fournissant un cadre JavaScript personnalisé pour rendre le contenu côté client afin de créer des sites Web dynamiques. Il redéfinit les composants de construction de la page Web : alors que WordPress est actuellement basé sur le concept de modèles hiérarchiques qui produisent du HTML (tels que single.php , home.php et archive.php ), PoP est basé sur le concept de « modules, ” qui sont soit une fonctionnalité atomique, soit une composition d'autres modules. Construire une application PoP s'apparente à jouer avec LEGO - empiler des modules les uns sur les autres ou s'envelopper les uns les autres, créant finalement une structure plus complexe. Cela pourrait également être considéré comme une implémentation de la conception atomique de Brad Frost, et cela ressemble à ceci :
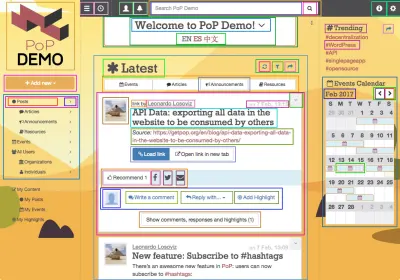
Les modules peuvent être regroupés en entités d'ordre supérieur, à savoir : blocks, blockGroups, pageSections et topLevels. Ces entités sont également des modules, avec juste des propriétés et des responsabilités supplémentaires, et elles se contiennent les unes les autres selon une architecture strictement descendante dans laquelle chaque module peut voir et modifier les propriétés de tous ses modules internes. La relation entre les modules est la suivante :
- 1 topLevel contient N pageSections,
- 1 pageSection contient N blocs ou blockGroups,
- 1 blockGroup contient N blocs ou blockGroups,
- 1 bloc contient N modules,
- 1 module contient N modules, à l'infini.
Exécuter du code JavaScript dans PoP
PoP crée dynamiquement du code HTML en commençant au niveau de la pageSection, en parcourant tous les modules sur la ligne, en affichant chacun d'eux via le modèle de guidon prédéfini du module et, enfin, en ajoutant les éléments nouvellement créés correspondants du module dans le DOM. Une fois cela fait, il exécute des fonctions JavaScript sur celles-ci, qui sont prédéfinies module par module.
PoP diffère des frameworks JavaScript (tels que React et AngularJS) en ce que le flux de l'application ne provient pas du client, mais il est toujours configuré dans le back-end, à l'intérieur de la configuration du module (qui est codé dans un objet PHP). Influencé par les crochets d'action WordPress, PoP implémente un modèle de publication-abonnement :
- Chaque module définit quelles fonctions JavaScript doivent être exécutées sur ses éléments DOM nouvellement créés correspondants, sans nécessairement savoir à l'avance ce qui exécutera ce code ni d'où il viendra.
- Les objets JavaScript doivent enregistrer les fonctions JavaScript qu'ils implémentent.
- Enfin, lors de l'exécution, PoP calcule quels objets JavaScript doivent exécuter quelles fonctions JavaScript et les invoque de manière appropriée.
Par exemple, via son objet PHP correspondant, un module calendrier indique qu'il a besoin que la fonction calendar soit exécutée sur ses éléments DOM comme ceci :
class CalendarModule { function get_jsmethods() { $methods = parent::get_jsmethods(); $this->add_jsmethod($methods, 'calendar'); return $methods; } ... } Ensuite, un objet JavaScript - dans ce cas, popFullCalendar - annonce qu'il a implémenté la fonction de calendar . Cela se fait en appelant popJSLibraryManager.register :
window.popFullCalendar = { calendar : function(elements) { ... } }; popJSLibraryManager.register(popFullCalendar, ['calendar', ...]); Enfin, popJSLibraryManager fait la correspondance sur ce qui exécute quel code. Il permet aux objets JavaScript d'enregistrer les fonctions qu'ils implémentent et fournit une méthode pour exécuter une fonction particulière à partir de tous les objets JavaScript abonnés :
window.popJSLibraryManager = { libraries: [], methods: {}, register : function(library, methods) { this.libraries.push(library); for (var i = 0; i < methods.length; i++) { var method = methods[i]; this.methods[method] = this.methods[method] || []; this.methods[method].push(library); } }, execute : function(method, elements) { var libraries = this.methods[method] || []; for (var i = 0; i < libraries.length; i++) { var library = libraries[i]; library[method](elements); } } } Après l'ajout d'un nouvel élément de calendrier au DOM, dont l'ID est calendar-293 , PoP exécutera simplement la fonction suivante :
popJSLibraryManager.execute("calendar", document.getElementById("calendar-293"));Point d'accès
Pour PoP, le point d'entrée pour l'exécution du code JavaScript est cette ligne à la fin de la sortie HTML :
<script type="text/javascript">popManager.init();</script> popManager.init() initialise d'abord le framework frontal, puis exécute les fonctions JavaScript définies par tous les modules rendus, comme expliqué ci-dessus. Vous trouverez ci-dessous une forme très simplifiée de cette fonction (le code original est sur GitHub). En popJSLibraryManager.execute('pageSectionInitialized', pageSection) et popJSLibraryManager.execute('documentInitialized') , tous les objets JavaScript qui implémentent ces fonctions ( pageSectionInitialized et documentInitialized ) les exécuteront.
(function($){ window.popManager = { // The configuration for all the modules (including pageSections and blocks) in the application configuration : {...}, init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { // Obtain the pageSection element in the DOM from the ID var pageSection = $('#'+pageSectionId); // Run all required JavaScript methods on it this.runJSMethods(pageSection, configuration); // Trigger an event marking the block as initialized popJSLibraryManager.execute('pageSectionInitialized', pageSection); }); // Trigger an event marking the document as initialized popJSLibraryManager.execute('documentInitialized'); }, ... }; })(jQuery); La fonction runJSMethods exécute les méthodes JavaScript définies pour chaque module, en commençant par la pageSection, qui est le module le plus haut, puis en descendant pour tous ses blocs internes et leurs modules internes :
(function($){ window.popManager = { ... runJSMethods : function(pageSection, configuration) { // Initialize the heap with "modules", starting from the top one, and recursively iterate over its inner modules var heap = [pageSection.data('module')], i; while (heap.length > 0) { // Get the first element of the heap var module = heap.pop(); // The configuration for that module contains which JavaScript methods to execute, and which are the module's inner modules var moduleConfiguration = configuration[module]; // The list of all JavaScript functions that must be executed on the module's newly created DOM elements var jsMethods = moduleConfiguration['js-methods']; // Get all of the elements added to the DOM for that module, which have been stored in JavaScript object `popJSRuntimeManager` upon creation var elements = popJSRuntimeManager.getDOMElements(module); // Iterate through all of the JavaScript methods and execute them, passing the elements as argument for (i = 0; i < jsMethods.length; i++) { popJSLibraryManager.execute(jsMethods[i], elements); } // Finally, add the inner-modules to the heap heap = heap.concat(moduleConfiguration['inner-modules']); } }, }; })(jQuery);En résumé, l'exécution de JavaScript dans PoP est faiblement couplée : au lieu d'avoir des dépendances fixes, nous exécutons des fonctions JavaScript via des crochets auxquels tout objet JavaScript peut s'abonner.
Pages Web et API
Un site Web PoP est une API auto-consommée. Dans PoP, il n'y a pas de distinction entre une page Web et une API : chaque URL renvoie la page Web par défaut, et en ajoutant simplement le paramètre output=json , elle renvoie son API à la place (par exemple, getpop.org/en/ est un page Web, et getpop.org/en/?output=json est son API). L'API est utilisée pour rendre dynamiquement le contenu dans PoP ; ainsi, lorsque vous cliquez sur un lien vers une autre page, l'API est ce qui est demandé, car à ce moment-là, le cadre du site Web sera chargé (comme la navigation supérieure et latérale) - alors l'ensemble des ressources nécessaires pour le mode API sera être un sous-ensemble de celui de la page Web. Nous devrons en tenir compte lors du calcul des dépendances d'un itinéraire : charger l'itinéraire lors du premier chargement du site Web ou le charger dynamiquement en cliquant sur un lien produira différents ensembles d'actifs requis.
Ce sont les aspects les plus importants du PoP qui définiront la conception et la mise en œuvre du fractionnement de code. Passons à l'étape suivante.
1. Cartographier les dépendances des actifs
Nous pourrions ajouter un fichier de configuration pour chaque fichier JavaScript, détaillant leurs dépendances explicites. Cependant, cela dupliquerait le code et serait difficile à maintenir cohérent. Une solution plus propre consisterait à conserver les fichiers JavaScript comme seule source de vérité, en extrayant le code qu'ils contiennent, puis en analysant ce code pour recréer les dépendances.
Les métadonnées que nous recherchons dans les fichiers source JavaScript, pour pouvoir recréer le mapping, sont les suivantes :
- appels de méthodes internes, tels que
this.runJSMethods(...); - appels de méthodes externes, tels que
popJSRuntimeManager.getDOMElements(...); - toutes les occurrences de
popJSLibraryManager.execute(...), qui exécute une fonction JavaScript dans tous les objets qui l'implémentent ; - toutes les occurrences de
popJSLibraryManager.register(...), pour obtenir quels objets JavaScript implémentent quelles méthodes JavaScript.
Nous utiliserons jParser et jTokenizer pour tokeniser nos fichiers source JavaScript en PHP et extraire les métadonnées, comme suit :
- Les appels de méthode internes (tels que
this.runJSMethods) sont déduits lors de la recherche de la séquence suivante : soit jetonthisouthat+.+ un autre jeton, qui est le nom de la méthode interne (runJSMethods). - Les appels de méthodes externes (tels que
popJSRuntimeManager.getDOMElements) sont déduits lors de la recherche de la séquence suivante : un jeton inclus dans la liste de tous les objets JavaScript de notre application (nous aurons besoin de cette liste à l'avance ; dans ce cas, elle contiendra l'objetpopJSRuntimeManager) +.+ un autre jeton, qui est le nom de la méthode externe (getDOMElements). - Chaque fois que nous trouvons
popJSLibraryManager.execute("someFunctionName"), nous déduisons que la méthode Javascript estsomeFunctionName. - Chaque fois que nous trouvons
popJSLibraryManager.register(someJSObject, ["someFunctionName1", "someFunctionName2"])nous déduisons l'objet JavascriptsomeJSObjectpour implémenter les méthodessomeFunctionName1,someFunctionName2.
J'ai implémenté le script mais je ne le décrirai pas ici. (C'est trop long n'ajoute pas beaucoup de valeur, mais on peut le trouver dans le référentiel de PoP). Le script, qui s'exécute lors de la demande d'une page interne sur le serveur de développement du site Web (dont j'ai parlé de la méthodologie dans un article précédent sur les service workers), générera le fichier de mappage et le stockera sur le serveur. J'ai préparé un exemple du fichier de mappage généré. Il s'agit d'un simple fichier JSON, contenant les attributs suivants :
-
internalMethodCalls
Pour chaque objet JavaScript, répertoriez les dépendances des fonctions internes entre elles. -
externalMethodCalls
Pour chaque objet JavaScript, répertoriez les dépendances entre les fonctions internes et les fonctions d'autres objets JavaScript. -
publicMethods
Répertoriez toutes les méthodes enregistrées et, pour chaque méthode, quels objets JavaScript l'implémentent. -
methodExecutions
Pour chaque objet JavaScript et chaque fonction interne, répertoriez toutes les méthodes exécutées viapopJSLibraryManager.execute('someMethodName').
Veuillez noter que le résultat n'est pas encore une carte de dépendance des actifs, mais plutôt une carte de dépendance des objets JavaScript. À partir de cette carte, nous pouvons établir, chaque fois qu'une fonction d'un objet est exécutée, quels autres objets seront également requis. Nous devons encore configurer les objets JavaScript contenus dans chaque actif, pour tous les actifs (dans le script jTokenizer, les objets JavaScript sont les jetons que nous recherchons pour identifier les appels de méthode externes, donc cette information est une entrée du script et peut 't être obtenu à partir des fichiers source eux-mêmes). Cela se fait via des objets PHP ResourceLoaderProcessor , comme resourceloader-processor.php.
Enfin, en combinant la carte et la configuration, nous pourrons calculer tous les atouts nécessaires pour chaque itinéraire dans l'application.
2. Liste de toutes les routes d'application
Nous devons identifier tous les itinéraires disponibles dans notre application. Pour un site Web WordPress, cette liste commencera par l'URL de chacune des hiérarchies de modèles. Ceux mis en œuvre pour PoP sont les suivants :
- page d'accueil : https://getpop.org/fr/
- auteur : https://getpop.org/en/u/leo/
- single : https://getpop.org/en/blog/new-feature-code-splitting/
- balise : https://getpop.org/en/tags/internet/
- page : https://getpop.org/fr/philosophie/
- catégorie : https://getpop.org/en/blog/ (la catégorie est en fait implémentée comme une page, pour supprimer la
category/du chemin de l'URL) - 404 : https://getpop.org/en/this-page-does-not-exist/
Pour chacune de ces hiérarchies, nous devons obtenir toutes les routes qui produisent une configuration unique (c'est-à-dire qui nécessiteront un ensemble unique d'actifs). Dans le cas de PoP, nous avons ce qui suit :
- la page d'accueil et le 404 sont uniques.
- Les pages de balises ont toujours la même configuration pour toutes les balises. Ainsi, une seule URL pour n'importe quelle balise suffira.
- La publication unique dépend de la combinaison du type de publication (tel que « événement » ou « publication ») et de la catégorie principale de la publication (telle que « blog » ou « article »). Ensuite, nous avons besoin d'une URL pour chacune de ces combinaisons.
- La configuration d'une page de catégorie dépend de la catégorie. Nous aurons donc besoin de l'URL de chaque catégorie de publication.
- Une page d'auteur dépend du rôle de l'auteur ("individu", "organisation" ou "communauté"). Nous aurons donc besoin d'URL pour trois auteurs, chacun d'eux avec l'un de ces rôles.
- Chaque page peut avoir sa propre configuration (« se connecter », « nous contacter », « notre mission », etc.). Ainsi, toutes les URL de page doivent être ajoutées à la liste.
On le voit, la liste est déjà assez longue. De plus, notre application peut ajouter des paramètres à l'URL qui modifient la configuration, modifiant éventuellement également les actifs requis. PoP, par exemple, propose d'ajouter les paramètres d'URL suivants :
- tab (
?tab=…), pour afficher une information connexe : https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors ; - format (
?format=…), pour modifier l'affichage des données : https://getpop.org/en/blog/?format=list; - target (
?target=…), pour ouvrir la page dans une autre pageSection : https://getpop.org/en/add-post/?target=addons.
Certains des itinéraires initiaux peuvent avoir un, deux ou même trois des paramètres ci-dessus, créant un large éventail de combinaisons :
- message unique : https://getpop.org/en/blog/new-feature-code-splitting/
- auteurs d'articles uniques : https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors
- les auteurs d'un article unique sous forme de liste : https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list
- auteurs d'un article unique sous forme de liste dans une fenêtre modale : https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list&target=modals
En résumé, pour PoP, tous les itinéraires possibles sont une combinaison des éléments suivants :
- tous les itinéraires de hiérarchie de modèles initiaux ;
- toutes les valeurs différentes pour lesquelles la hiérarchie produira une configuration différente ;
- tous les onglets possibles pour chaque hiérarchie (différentes hiérarchies peuvent avoir des valeurs d'onglet différentes : un même article peut avoir les onglets « auteurs » et « réponses », tandis qu'un auteur peut avoir les onglets « articles » et « abonnés ») ;
- tous les formats possibles pour chaque onglet (différents onglets peuvent se voir appliquer différents formats : l'onglet « auteurs » peut avoir le format « carte », mais pas l'onglet « réponses ») ;
- toutes les cibles possibles indiquant les sections de la page où chaque parcours peut être affiché (alors qu'une publication peut être créée dans la section principale ou dans une fenêtre flottante, la page "Partager avec vos amis" peut être paramétrée pour s'ouvrir dans une fenêtre modale).
Ainsi, pour une application un peu complexe, la production de la liste avec toutes les routes ne peut se faire manuellement. Nous devons ensuite créer un script pour extraire ces informations de la base de données, les manipuler et, enfin, les sortir dans le format requis. Ce script obtiendra toutes les catégories d'articles, à partir desquelles nous pourrons produire la liste de toutes les différentes URL de page de catégorie, puis, pour chaque catégorie, interrogera la base de données pour tout article sous le même, ce qui produira l'URL d'un seul poster sous chaque catégorie, et ainsi de suite. Le script complet est disponible, à partir de function get_resources() , qui expose les crochets à implémenter par chacun des cas de la hiérarchie.
3. Génération de la liste qui définit les actifs requis pour chaque itinéraire
À présent, nous avons la carte de dépendance des actifs et la liste de toutes les routes de l'application. Il est maintenant temps de combiner ces deux et de produire une liste qui indique, pour chaque itinéraire, quels actifs sont nécessaires.
Pour créer cette liste, nous appliquons la procédure suivante :
- Produisez une liste contenant toutes les méthodes JavaScript à exécuter pour chaque route :
Calculez les modules de la route, puis obtenez la configuration de chaque module, puis extrayez de la configuration les fonctions JavaScript que le module doit exécuter, et additionnez-les. - Ensuite, parcourez la carte des dépendances des actifs pour chaque fonction JavaScript, rassemblez la liste de toutes ses dépendances requises et ajoutez-les toutes ensemble.
- Enfin, ajoutez les modèles Handlebars nécessaires pour rendre chaque module à l'intérieur de cette route.
De plus, comme indiqué précédemment, chaque URL a des modes page Web et API, nous devons donc exécuter la procédure ci-dessus deux fois, une fois pour chaque mode (c'est-à-dire une fois en ajoutant le paramètre output=json à l'URL, représentant la route pour le mode API, et une fois en gardant l'URL inchangée pour le mode page Web). Nous produirons alors deux listes, qui auront des usages différents :

- La liste des modes de page Web sera utilisée lors du chargement initial du site Web, de sorte que les scripts correspondants pour cet itinéraire soient inclus dans la réponse HTML initiale. Cette liste sera stockée sur le serveur.
- La liste des modes API sera utilisée lors du chargement dynamique d'une page sur le site Web. Cette liste sera chargée sur le client, pour permettre à l'application de calculer quels actifs supplémentaires doivent être chargés, à la demande, lorsqu'un lien est cliqué.
La majeure partie de la logique a été implémentée à partir de function add_resources_from_settingsprocessors($fetching_json, ...) , (vous pouvez la trouver dans le référentiel). Le paramètre $fetching_json différencie les modes page Web ( false ) et API ( true ).
Lorsque le script du mode page Web est exécuté, il génère resourceloader-bundle-mapping.json, qui est un objet JSON avec les propriétés suivantes :
-
bundle-ids
Il s'agit d'une collection de jusqu'à quatre ressources (leurs noms ont été mutilés pour l'environnement de production :eq=>handlebars,er=>handlebars-helpers, etc.), regroupées sous un ID de bundle. -
bundlegroup-ids
Il s'agit d'une collection debundle-ids. Chaque bundleGroup représente un ensemble unique de ressources. -
key-ids
Il s'agit du mappage entre les routes (représentées par leur hachage, qui identifie l'ensemble de tous les attributs qui rendent une route unique) et leur bundleGroup correspondant.
Comme on peut le constater, la correspondance entre un itinéraire et ses ressources n'est pas directe. Au lieu de mapper key-ids sur une liste de ressources, il les mappe sur un bundleGroup unique, qui est lui-même une liste de bundles , et seul chaque bundle est une liste de resources (jusqu'à quatre éléments par bundle). Pourquoi a-t-il été fait ainsi ? Cela sert deux objectifs :
- Il nous permet d'identifier toutes les ressources sous un bundleGroup unique. Ainsi, au lieu d'inclure toutes les ressources dans la réponse HTML, nous sommes en mesure d'inclure un actif JavaScript unique, qui est le fichier bundleGroup correspondant à la place, qui se regroupe dans toutes les ressources correspondantes. Ceci est utile lorsque vous servez des appareils qui ne prennent toujours pas en charge HTTP/2, et cela augmentera également le temps de chargement, car Gziper un seul fichier groupé est plus efficace que de compresser ses fichiers constitutifs par eux-mêmes, puis de les additionner. Alternativement, nous pourrions également charger une série de bundles au lieu d'un bundleGroup unique, qui est un compromis entre les ressources et les bundleGroups (le chargement des bundles est plus lent que celui des bundleGroups à cause de Gzip'ing, mais il est plus performant si l'invalidation se produit souvent, de sorte que nous téléchargerait uniquement le bundle mis à jour et non l'ensemble du bundleGroup). Les scripts pour regrouper toutes les ressources en bundles et bundleGroups se trouvent dans filegenerator-bundles.php et filegenerator-bundlegroups.php.
- Diviser les ensembles de ressources en faisceaux nous permet d'identifier des modèles communs (par exemple, identifier des ensembles de quatre ressources qui sont partagés entre plusieurs routes), permettant ainsi à différentes routes de se lier au même faisceau. Par conséquent, la liste générée aura une taille plus petite. Cela peut ne pas être d'une grande utilité pour la liste des pages Web, qui réside sur le serveur, mais c'est très bien pour la liste des API, qui sera chargée sur le client, comme nous le verrons plus tard.
Lorsque le script pour le mode API est exécuté, il génère le fichier resources.js, avec les propriétés suivantes :
- les
bundlesetbundle-groupsont le même objectif que celui indiqué pour le mode page Web - Les
keysont également le même objectif que les ID dekey-idspour le mode page Web. Cependant, au lieu d'avoir un hachage comme clé pour représenter la route, c'est une concaténation de tous ces attributs qui rendent une route unique - dans notre cas, format (f), tabulation (t) et cible (r). -
sourcesest le fichier source de chaque ressource. -
typesest le CSS ou JavaScript pour chaque ressource (même si, par souci de simplicité, nous n'avons pas couvert dans cet article que les ressources JavaScript peuvent également définir des ressources CSS en tant que dépendances, et que les modules peuvent charger leurs propres actifs CSS, implémentant la stratégie de chargement CSS progressif ). -
resourcescapture les bundleGroups qui doivent être chargés pour chaque hiérarchie. -
ordered-load-resourcescontient les ressources qui doivent être chargées dans l'ordre, pour empêcher les scripts d'être chargés avant leurs scripts dépendants (par défaut, ils sont asynchrones).
Nous verrons comment utiliser ce fichier dans la section suivante.
4. Chargement dynamique des actifs
Comme indiqué, la liste des API sera chargée sur le client, afin que nous puissions commencer à charger les actifs requis pour un itinéraire immédiatement après que l'utilisateur a cliqué sur un lien.
Chargement du script de mappage
Le fichier JavaScript généré avec la liste des ressources pour toutes les routes de l'application n'est pas léger - dans ce cas, il est sorti à 85 Ko (qui est lui-même optimisé, après avoir mutilé les noms de ressources et produit des bundles pour identifier les modèles communs à travers les routes) . Le temps d'analyse ne devrait pas être un gros goulot d'étranglement, car l'analyse de JSON est 10 fois plus rapide que l'analyse de JavaScript pour les mêmes données. Cependant, la taille est un problème de transfert réseau, nous devons donc charger ce script d'une manière qui n'affecte pas le temps de chargement perçu de l'application ou ne fasse pas attendre l'utilisateur.
La solution que j'ai implémentée consiste à mettre en cache ce fichier à l'aide de service workers, à le charger à l'aide de defer afin qu'il ne bloque pas le thread principal lors de l'exécution des méthodes JavaScript critiques, puis à afficher un message de notification de secours si l'utilisateur clique sur un lien avant le chargement du script : "Le site Web est toujours en cours de chargement, veuillez patienter quelques instants avant de cliquer sur les liens." Ceci est accompli en ajoutant une div fixe avec une classe de loadingscreen placée au-dessus de tout pendant le chargement des scripts, puis en ajoutant le message de notification, avec une classe de notificationmsg , à l'intérieur de la div, et ces quelques lignes de CSS :
.loadingscreen > .notificationmsg { display: none; } .loadingscreen:focus > .notificationmsg, .loadingscreen:active > .notificationmsg { display: block; }Une autre solution est de scinder ce fichier en plusieurs et de les charger au fur et à mesure des besoins (stratégie que j'ai déjà codée). De plus, le fichier de 85 Ko inclut tous les itinéraires possibles dans l'application, y compris des itinéraires tels que "les annonces de l'auteur, affichées dans des vignettes, affichées dans la fenêtre des modaux", qui peuvent être consultées une fois dans une lune bleue, voire pas du tout. Les routes les plus consultées sont à peine quelques-unes (page d'accueil, single, auteur, balise et toutes les pages, toutes sans attributs supplémentaires), ce qui devrait produire un fichier beaucoup plus petit, aux alentours de 30 Ko.
Obtention de la route à partir de l'URL demandée
Nous devons être en mesure d'identifier la route à partir de l'URL demandée. Par exemple:
-
https://getpop.org/en/u/leo/correspond à la route "author", -
https://getpop.org/en/u/leo/?tab=followerscorrespond à la route "abonnés de l'auteur", -
https://getpop.org/en/tags/internet/correspond à la route "tag", -
https://getpop.org/en/tags/correspond à la route "page/tags/", - etc.
Pour cela, il va falloir évaluer l'URL, et en déduire les éléments qui rendent une route unique : la hiérarchie et l'ensemble des attributs (format, onglet et cible). L'identification des attributs ne pose aucun problème, car ce sont des paramètres dans l'URL. Le seul défi consiste à déduire la hiérarchie (accueil, auteur, single, page ou tag) à partir de l'URL, en faisant correspondre l'URL à plusieurs modèles. Par exemple,
- Tout ce qui commence par
https://getpop.org/en/u/est un auteur. - Tout ce qui commence par mais n'est pas exactement
https://getpop.org/en/tags/est une balise. Si c'est exactementhttps://getpop.org/en/tags/, alors c'est une page. - Etc.
La fonction ci-dessous, implémentée à partir de la ligne 321 de resourceloader.js, doit être alimentée avec une configuration avec les patrons pour toutes ces hiérarchies. Il vérifie d'abord s'il n'y a pas de sous-chemin dans l'URL - auquel cas, il s'agit de "home". Ensuite, il vérifie un par un pour faire correspondre les hiérarchies pour "auteur", "tag" et "single". S'il ne réussit avec aucun de ceux-ci, alors c'est le cas par défaut, qui est "page":
window.popResourceLoader = { // The config will be populated externally, using a config.js file, generated by a script config : {}, getPath : function(url) { var parser = document.createElement('a'); parser.href = url; return parser.pathname; }, getHierarchy : function(url) { var path = this.getPath(url); if (!path) { return 'home'; } var config = this.config; if (path.startsWith(config.paths.author) && path != config.paths.author) { return 'author'; } if (path.startsWith(config.paths.tag) && path != config.paths.tag) { return 'tag'; } // We must also check that this path is, itself, not a potential page (https://getpop.org/en/posts/articles/ is "page", but https://getpop.org/en/posts/this-is-a-post/ is "single") if (config.paths.single.indexOf(path) === -1 && config.paths.single.some(function(single_path) { return path.startsWith(single_path) && path != single_path;})) { return 'single'; } return 'page'; }, ... };Étant donné que toutes les données requises sont déjà dans la base de données (toutes les catégories, tous les slugs de page, etc.), nous exécuterons un script pour créer automatiquement ce fichier de configuration dans un environnement de développement ou de staging. The implemented script is resourceloader-config.php, which produces config.js with the URL patterns for the hierarchies “author”, “tag” and “single”, under the key “paths”:
popResourceLoader.config = { "paths": { "author": "u/", "tag": "tags/", "single": ["posts/articles/", "posts/announcements/", ...] }, ... };Loading Resources for the Route
Once we have identified the route, we can obtain the required assets from the generated JavaScript file under the key “resources”, which looks like this:
config.resources = { "home": { "1": [1, 110, ...], "2": [2, 111, ...], ... }, "author": { "7": [6, 114, ...], "8": [7, 114, ...], ... }, "tag": { "119": [66, 127, ...], "120": [66, 127, ...], ... }, "single": { "posts/": { "7": [190, 142, ...], "3": [190, 142, ...], ... }, "events/": { "7": [213, 389, ...], "3": [213, 389, ...], ... }, ... }, "page": { "log-in/": { "3": [233, 115, ...] }, "log-out/": { "3": [234, 115, ...] }, "add-post/": { "3": [239, 398, ...] }, "posts/": { "120": [268, 127, ...], "122": [268, 127, ...], ... }, ... } };At the first level, we have the hierarchy (home, author, tag, single or page). Hierarchies are divided into two groups: those that have only one set of resources (home, author and tag), and those that have a specific subpath (page permalink for the pages, custom post type or category for the single). Finally, at the last level, for each key ID (which represents a unique combination of the possible values of “format”, “tab” and “target”, stored under “keys”), we have an array of two elements: [JS bundleGroup ID, CSS bundleGroup ID], plus additional bundleGroup IDs if executing progressive booting (JS bundleGroups to be loaded as "async" or "defer" are bundled separately; this will be explained in the optimizations section below).
Please note: For the single hierarchy, we have different configurations depending on the custom post type. This can be reflected in the subpath indicated above (for example, events and posts ) because this information is in the URL (for example, https://getpop.org/en/posts/the-winners-of-climate-change-techno-fixes/ and https://getpop.org/en/events/debate-post-fork/ ), so that, when clicking on a link, we will know the corresponding post type and can thus infer the corresponding route. However, this is not the case with the author hierarchy. As indicated earlier, an author may have three different configurations, depending on the user role ( individual , organization or community ); however, in this file, we've defined only one configuration for the author hierarchy, not three. That is because we are not able to tell from the URL what is the role of the author: user leo (under https://getpop.org/en/u/leo/ ) is an individual, whereas user pop (under https://getpop.org/en/u/pop/ ) is a community; however, their URLs have the same pattern. If we could instead have the URLs https://getpop.org/en/u/individuals/leo/ and https://getpop.org/en/u/communities/pop/ , then we could add a configuration for each user role. However, I've found no way to achieve this in WordPress. As a consequence, only for the API mode, we must merge the three routes (individuals, organizations and communities) into one, which will have all of the resources for the three cases; and clicking on the link for user leo will also load the resources for organizations and communities, even if we don't need them.
Finally, when a URL is requested, we obtain its route, from which we obtain the bundleGroup IDs (for both JavaScript and CSS assets). From each bundleGroup, we find the corresponding bundles under bundlegroups . Then, for each bundle, we obtain all resources under the key bundles . Finally, we identify which assets have not yet been loaded, and we load them by getting their source, which is stored under the key sources . The whole logic is coded starting from line 472 in resourceloader.js.
And with that, we have implemented code-splitting for our application! From now on, we can get better loading times by applying optimizations. Let's tackle that next.
5. Applying Optimizations
The objective is to load as little code as possible, as delayed as possible, and to cache as much of it as possible. Let's explore how to do this.
Splitting Up the Code Into Smaller Units
A single JavaScript asset may implement several functions (by calling popJSLibraryManager.register ), yet maybe only one of those functions is actually needed by the route. Thus, it makes sense to split up the asset into several subassets, implementing a single function on each of them, and extracting all common code from all of the functions into yet another asset, depended upon by all of them.
For instance, in the past, there was a unique file, waypoints.js , that implemented the functions waypointsFetchMore , waypointsTheater and a few more. However, in most cases, only the function waypointsFetchMore was needed, so I was loading the code for the function waypointsTheater unnecessarily. Then, I split up waypoints.js into the following assets:
- waypoints.js, with all common code and implementing no public functions;
- waypoints-fetchmore.js, which implements just the public function
waypointsFetchMore; - waypoints-theater.js, which implements just the public function
waypointsTheater.
Evaluating how to split the files is a manual job. Luckily, there is a tool that greatly eases the task: Chrome Developer Tools' “Coverage” tab, which displays in red those portions of JavaScript code that have not been invoked:
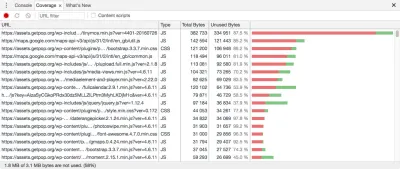
By using this tool, we can better understand how to split our JavaScript files into more granular units, thus reducing the amount of unneeded code that is loaded.
Integration With Service Workers
By precaching all of the resources using service workers, we can be pretty sure that, by the time the response is back from the server, all of the required assets will have been loaded and parsed. I wrote an article on Smashing Magazine on how to accomplish this.
Progressive Booting
PoP's architecture plays very nice with the concept of loading assets in different stages. When defining the JavaScript methods to execute on each module (by doing $this->add_jsmethod($methods, 'calendar') ), these can be set as either critical or non-critical . By default, all methods are set as non-critical, and critical methods must be explicitly defined by the developer, by adding an extra parameter: $this->add_jsmethod($methods, 'calendar', 'critical') . Then, we will be able to load scripts immediately for critical functions, and wait until the page is loaded to load non-critical functions, the JavaScript files of which are loaded using defer .
(function($){ window.popManager = { init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'critical'); ... }); window.addEventListener('load', function() { $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'non-critical'); ... }); }); ... }, ... }; })(jQuery);The gains from progressive booting are major: The JavaScript engine needs not spend time parsing non-critical JavaScript initially, when a quick response to the user is most important, and overall reduces the time to interactive.
Testing And Analizying Performance Gains
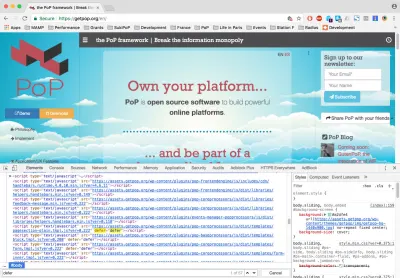
We can use https://getpop.org/en/, a PoP website, for testing purposes. When loading the home page, opening Chrome Developer Tools' “Elements” tab and searching for “defer”, it shows 4 occurrences. Thanks to progressive booting, that is 4 bundleGroup JavaScript files containing the contents of 57 Javascript files with non-critical methods that could wait until the website finished loading to be loaded:
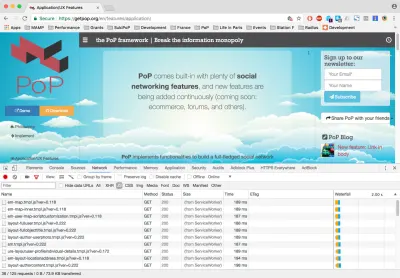
If we now switch to the “Network” tab and click on a link, we can see which assets get loaded. For instance, click on the link “Application/UX Features” on the left side. Filtering by JavaScript, we see it loaded 38 files, including JavaScript libraries and Handlebars templates. Filtering by CSS, we see it loaded 9 files. These 47 files have all been loaded on demand:
Let's check whether the loading time got boosted. We can use WebPagetest to measure the application with and without code-splitting, and calculate the difference.
- Without code-splitting: testing URL, WebPagetest results

- With code-splitting, loading resources: testing URL, WebPagetest Results

- With code-splitting, loading a bundleGroup: testing URL, WebPagetest Results

We can see that when loading the app bundle with all resources or when doing code-splitting and loading resources, there is not so much gain. However, when doing code-splitting and loading a bundleGroup, the gains are significant: 1.7 seconds in loading time, 500 milliseconds to the first meaningful paint, and 1 second to interactive.
Conclusion: Is It Worth It?
You might be thinking, Is it worth it all this trouble? Let's analyze the advantages and disadvantages of implementing our own code-splitting features.
Désavantages
- Nous devons le maintenir.
Si nous utilisions simplement Webpack, nous pourrions compter sur sa communauté pour maintenir le logiciel à jour et bénéficier de son écosystème de plugins. - Les scripts prennent du temps à s'exécuter.
Le site Web PoP Agenda Urbana propose 304 itinéraires différents, à partir desquels il produit 422 ensembles de ressources uniques. Pour ce site Web, l'exécution du script qui génère la carte de dépendance des actifs, à l'aide d'un MacBook Pro de 2012, prend environ 8 minutes, et l'exécution du script qui génère les listes avec toutes les ressources et crée les fichiers bundle et bundleGroup prend 15 minutes. . C'est plus qu'assez de temps pour aller prendre un café ! - Cela nécessite un environnement de mise en scène.
Si nous devons attendre environ 25 minutes pour exécuter les scripts, nous ne pouvons pas les exécuter en production. Nous aurions besoin d'un environnement intermédiaire avec exactement la même configuration que le système de production. - Un code supplémentaire est ajouté au site Web, uniquement pour la gestion.
Les 85 Ko de code ne sont pas fonctionnels en eux-mêmes, mais simplement du code pour gérer d'autres codes. - La complexité est ajoutée.
C'est inévitable en tout cas si nous voulons diviser nos actifs en unités plus petites. Webpack ajouterait également de la complexité à l'application.
Avantages
- Cela fonctionne avec WordPress.
Webpack ne fonctionne pas avec WordPress prêt à l'emploi, et pour le faire fonctionner, il faut une certaine solution de contournement. Cette solution fonctionne prête à l'emploi pour WordPress (tant que PoP est installé). - Il est évolutif et extensible.
La taille et la complexité de l'application peuvent croître sans limites, car les fichiers JavaScript sont chargés à la demande. - Il prend en charge Gutenberg (alias le WordPress de demain).
Parce qu'il nous permet de charger des frameworks JavaScript à la demande, il prendra en charge les blocs de Gutenberg (appelés Gutenblocks), qui sont censés être codés dans le framework choisi par le développeur, avec pour résultat potentiel que différents frameworks soient nécessaires pour la même application. - C'est pratique.
L'outil de construction se charge de générer les fichiers de configuration. Mis à part l'attente, aucun effort supplémentaire de notre part n'est nécessaire. - Cela facilite l'optimisation.
Actuellement, si un plugin WordPress souhaite charger de manière sélective des actifs JavaScript, il utilisera de nombreuses conditions pour vérifier si l'ID de page est le bon. Avec cet outil, il n'y a pas besoin de cela ; le processus est automatique. - L'application se chargera plus rapidement.
C'est la raison pour laquelle nous avons codé cet outil. - Cela nécessite un environnement de mise en scène.
Un effet secondaire positif est une fiabilité accrue : nous n'exécuterons pas les scripts en production, donc nous ne casserons rien là-bas ; le processus de déploiement n'échouera pas à cause d'un comportement inattendu ; et le développeur sera obligé de tester l'application en utilisant la même configuration qu'en production. - Il est adapté à notre application.
Il n'y a pas de frais généraux ou de solutions de contournement. Ce que nous obtenons correspond exactement à ce dont nous avons besoin, en fonction de l'architecture avec laquelle nous travaillons.
En conclusion : oui, cela en vaut la peine, car nous sommes maintenant en mesure d'appliquer des ressources de chargement à la demande sur notre site Web WordPress et de le faire charger plus rapidement.
Autres ressources
- Webpack, y compris le guide ""Code Splitting""
- "Meilleures constructions Webpack" (vidéo), K. Adam White
Intégration de Webpack avec WordPress - « Gutenberg et le WordPress de demain », Morten Rand-Hendriksen, WP Tavern
- "WordPress explore une approche indépendante du framework JavaScript pour créer des blocs Gutenberg", Sarah Gooding, WP Tavern