
CNN vs RNN : Différence entre CNN et RNN
Publié: 2021-02-25Table des matières
introduction
Dans le domaine de l'intelligence artificielle, les réseaux de neurones inspirés du cerveau humain sont largement utilisés pour extraire et traiter des informations complexes à partir de diverses données et l'utilisation à la fois des réseaux de neurones convolutifs (CNN) et des réseaux de neurones récurrents (RNN) dans de telles applications. se révèlent utiles.
Dans cet article, nous allons comprendre les concepts derrière les réseaux de neurones convolutifs et les réseaux de neurones récurrents, voir leurs applications et distinguer les différences entre les deux types populaires de réseaux de neurones.
Apprenez la formation en apprentissage automatique des meilleures universités du monde. Gagnez des programmes de maîtrise, Executive PGP ou Advanced Certificate pour accélérer votre carrière.
Réseaux de neurones et apprentissage en profondeur
Avant d'aborder les concepts de réseaux de neurones convolutifs et de réseaux de neurones récurrents, comprenons les concepts sous-jacents aux réseaux de neurones et comment ils sont liés à l'apprentissage en profondeur.
Ces derniers temps, Deep Learning est une fois un concept largement utilisé dans de nombreux domaines et c'est donc un sujet brûlant ces jours-ci. Mais quelle est la raison pour laquelle on en parle si largement ? Pour répondre à cette question, nous allons découvrir le concept de réseaux de neurones.
En bref, les réseaux de neurones sont l'épine dorsale du Deep Learning. Il s'agit d'un nombre défini de couches constituées d'éléments hautement interconnectés appelés neurones qui effectuent une série de transformations sur les données qui génèrent leur propre compréhension de ces données que nous appelons le terme caractéristiques.

Que sont les réseaux de neurones ?
Le premier concept que nous devons aborder est celui des réseaux de neurones. Nous savons que le cerveau humain est l'une des structures complexes jamais étudiées. En raison de sa complexité, il a été très difficile de démêler son fonctionnement interne, mais à l'heure actuelle, plusieurs types de recherches sont en cours pour révéler ses secrets. Ce cerveau humain sert d'inspiration derrière les modèles de réseau de neurones.
Par définition, les réseaux de neurones sont les unités fonctionnelles de Deep Learning qui utilisent ces réseaux de neurones pour imiter l'activité cérébrale et résoudre des problèmes complexes. Lorsque les données d'entrée sont transmises au réseau de neurones, elles sont traitées à travers les couches de perceptron et donnent finalement la sortie.
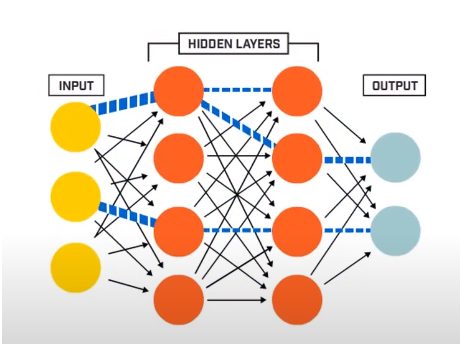
Un réseau de neurones se compose essentiellement de 3 couches -
- Couche d'entrée
- Calques masqués
- Couche de sortie
La couche d'entrée lit les données d'entrée qui sont introduites dans le système de réseau neuronal pour un prétraitement ultérieur par les couches suivantes de neurones artificiels. Toutes les couches qui existent entre la couche d'entrée et la couche de sortie sont appelées couches masquées.
C'est dans ces couches cachées que les neurones qui y sont présents utilisent des entrées et des biais pondérés et produisent une sortie en utilisant les fonctions d'activation. La couche de sortie est la dernière couche de neurones qui nous donne la sortie pour le programme donné.
La source
Comment fonctionnent les réseaux de neurones ?
Maintenant que nous avons une idée de la structure de base des réseaux de neurones, nous allons avancer et comprendre comment ils fonctionnent. Pour comprendre son fonctionnement, nous devons d'abord en apprendre davantage sur l'une des structures de base des réseaux de neurones, connue sous le nom de Perceptron.
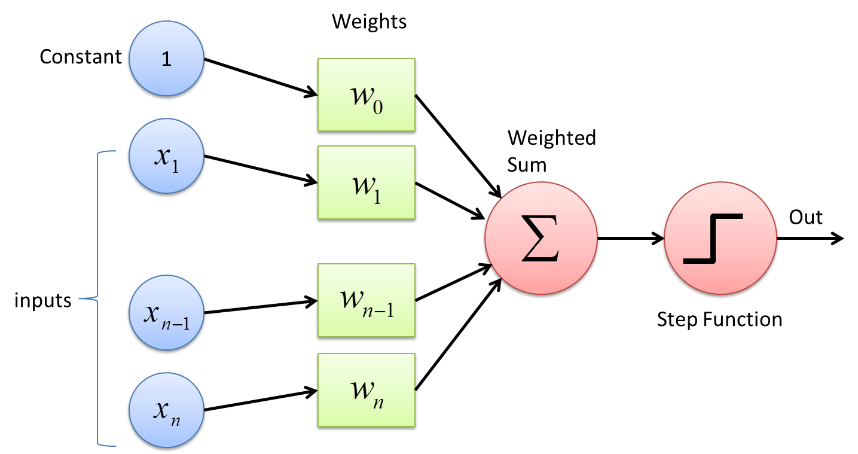
Perceptron est un type de réseau de neurones dont la forme est la plus élémentaire. Il s'agit d'un simple réseau de neurones artificiels avec une seule couche cachée. Dans le réseau Perceptron, chaque neurone est connecté à tous les autres neurones dans le sens direct.
Les connexions entre ces neurones sont pondérées grâce à quoi l'information qui est transférée entre les deux neurones est renforcée ou atténuée par ces poids. Dans le processus de formation des réseaux de neurones, ce sont ces poids qui sont ajustés pour obtenir la valeur correcte.
Le Perceptron utilise une fonction de classificateur binaire dans laquelle il mappe un vecteur de variables de nature binaire à une seule sortie binaire. Cela peut également être utilisé dans l'apprentissage supervisé. Les étapes de l'algorithme d'apprentissage Perceptron sont -
- Multipliez toutes les entrées par leurs poids w, où w sont des nombres réels qui peuvent être initialement fixes ou randomisés.
- Additionnez le produit pour obtenir la somme pondérée, ∑ wj xj
- Une fois que la somme pondérée des entrées est obtenue, la fonction d'activation est appliquée pour déterminer si la somme pondérée est supérieure à une valeur de seuil particulière ou non en fonction de la fonction d'activation appliquée. La sortie est affectée à 1 ou 0 selon la condition de seuil. Ici, la valeur "-seuil" fait également référence au terme biais, b.
Ainsi, l'algorithme Perceptron Learning peut être utilisé pour activer (valeur =1) les neurones présents dans les Réseaux de Neurones qui sont conçus et développés aujourd'hui. Une autre représentation de l'algorithme d'apprentissage Perceptron est -
f(x) = 1, si ∑ wj xj + b ≥ 0
0, si ∑ wj xj + b < 0
Bien que les Perceptrons ne soient pas largement utilisés de nos jours, ils restent l'un des concepts fondamentaux des réseaux de neurones. Lors de recherches plus poussées, il a été compris que de petits changements dans les poids ou le biais, même dans un perceptron, pouvaient modifier considérablement la sortie de 1 à 0 ou vice versa. C'était l'un des principaux inconvénients du Perceptron. Par conséquent, des fonctions d'activation plus complexes telles que les fonctions ReLU et Sigmoïde ont été développées, qui n'introduisent que des changements modérés dans les poids et les biais des neurones artificiels.
La source
Réseaux de neurones convolutifs
Un réseau neuronal convolutif est un algorithme d'apprentissage en profondeur qui prend une image comme entrée, attribue divers poids et biais à différentes parties de l'image de sorte qu'elles soient différenciables les unes des autres. Une fois qu'ils deviennent différentiables, en utilisant diverses fonctions d'activation, le modèle de réseau neuronal convolutif peut effectuer plusieurs tâches dans le domaine du traitement d'images, notamment la reconnaissance d'images, la classification d'images, la détection d'objets et de visages, etc.
Le principe fondamental d'un modèle de réseau neuronal convolutif est qu'il reçoit une image d'entrée. L'image d'entrée peut être étiquetée (telle que chat, chien, lion, etc.) ou non étiquetée. En fonction de cela, les algorithmes d'apprentissage en profondeur sont classés en deux types, à savoir les algorithmes supervisés où les images sont étiquetées et les algorithmes non supervisés où les images ne reçoivent aucune étiquette particulière.
Pour la machine informatique, l'image d'entrée est vue comme un tableau de pixels, le plus souvent sous la forme d'une matrice. Les images sont pour la plupart de la forme hxwxd (Où h = Hauteur, w = Largeur, d = Dimension). Par exemple, une image de matrice de taille 16 x 16 x 3 désigne une image RVB (3 représente les valeurs RVB). D'autre part, une image d'un réseau matriciel 14 x 14 x 1 représente une image en niveaux de gris.
La source
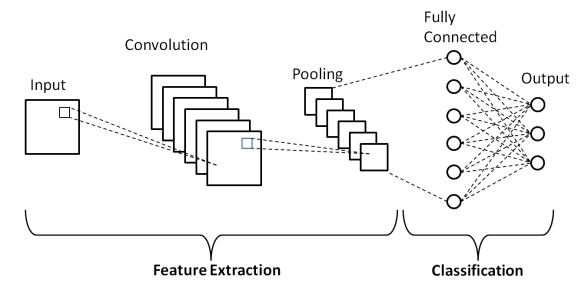
Couches de réseau neuronal convolutif
Comme indiqué dans l'architecture de base ci-dessus d'un réseau neuronal convolutif, un modèle CNN se compose de plusieurs couches à travers lesquelles les images d'entrée subissent un prétraitement pour obtenir la sortie. Fondamentalement, ces couches sont différenciées en deux parties -
- Les trois premières couches, y compris la couche d'entrée, la couche de convolution et la couche de regroupement qui agit comme l'outil d'extraction de caractéristiques pour dériver les caractéristiques de niveau de base à partir des images introduites dans le modèle.
- La couche entièrement connectée finale et la couche de sortie utilisent la sortie des couches d'extraction de caractéristiques et prédisent une classe pour l'image en fonction des caractéristiques extraites.
La première couche est la couche d'entrée où l'image est introduite dans le modèle de réseau neuronal convolutif sous la forme d'un tableau de matrice, c'est-à-dire 32 x 32 x 3, où 3 indique que l'image est une image RVB avec une hauteur et une largeur égales. de 32 pixels. Ensuite, ces images d'entrée traversent la couche convolutive où l'opération mathématique de convolution est effectuée.

L'image d'entrée est convoluée avec une autre matrice carrée appelée noyau ou filtre. En faisant glisser le noyau un par un sur les pixels de l'image d'entrée, nous obtenons l'image de sortie connue sous le nom de carte de caractéristiques qui fournit des informations sur les caractéristiques de base de l'image telles que les bords et les lignes.
La couche convolutive est suivie de la couche de regroupement dont le but est de réduire la taille de la carte d'entités pour réduire les coûts de calcul. Cela se fait par plusieurs types de pooling tels que Max Pooling, Average Pooling et Sum Pooling.
La couche entièrement connectée (FC) est l'avant-dernière couche du modèle de réseau neuronal convolutif où les couches sont aplaties et alimentées vers la couche FC. Ici, en utilisant des fonctions d'activation telles que les fonctions Sigmoid, ReLU et tanH, la prédiction d'étiquette a lieu et est donnée dans la couche de sortie finale .
Là où les CNN échouent
Avec autant d'applications utiles du réseau de neurones convolutifs dans les données d'images visuelles, les CNN ont un petit inconvénient en ce sens qu'ils ne fonctionnent pas bien avec une séquence d'images (vidéos) et échouent à interpréter les informations temporelles et les blocs de texte.
Afin de traiter des données temporelles ou séquentielles telles que les phrases, nous avons besoin d'algorithmes qui apprennent des données passées et aussi des données futures de la séquence. Heureusement, les réseaux de neurones récurrents font exactement cela.
Réseaux de neurones récurrents
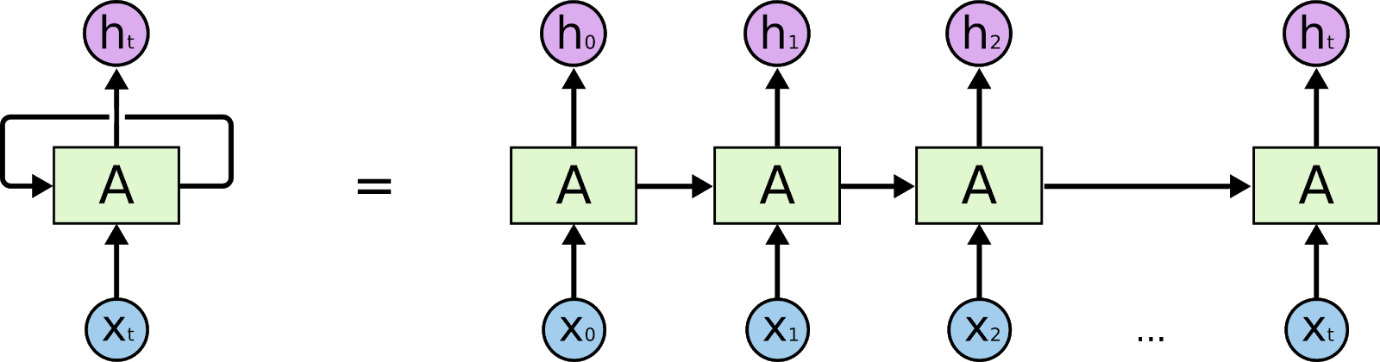
Les réseaux de neurones récurrents sont des réseaux conçus pour interpréter des informations temporelles ou séquentielles. Les RNN utilisent d'autres points de données dans une séquence pour faire de meilleures prédictions. Ils le font en prenant en entrée et en réutilisant les activations des nœuds précédents ou ultérieurs dans la séquence pour influencer la sortie.
La source
En raison de leur mémoire interne, les réseaux de neurones récurrents peuvent se souvenir de détails vitaux tels que les entrées qu'ils ont reçues, ce qui les rend très précis pour prédire ce qui va suivre. Par conséquent, ils constituent l'algorithme le plus préféré pour les données séquentielles telles que les séries chronologiques, la parole, le texte, l'audio, la vidéo et bien d'autres. Les réseaux de neurones récurrents peuvent former une compréhension beaucoup plus profonde d'une séquence et de son contexte par rapport à d'autres algorithmes.
Comment fonctionnent les réseaux de neurones récurrents ?
La base pour comprendre le fonctionnement des réseaux de neurones récurrents est la même que celle des réseaux de neurones convolutifs, les réseaux de neurones à réaction simple, également connus sous le nom de Perceptron. De plus, dans les réseaux de neurones récurrents, la sortie de l'étape précédente est alimentée en entrée de l'étape en cours. Dans la plupart des réseaux de neurones, la sortie est généralement indépendante des entrées et vice versa, c'est la différence fondamentale entre le RNN et les autres réseaux de neurones.
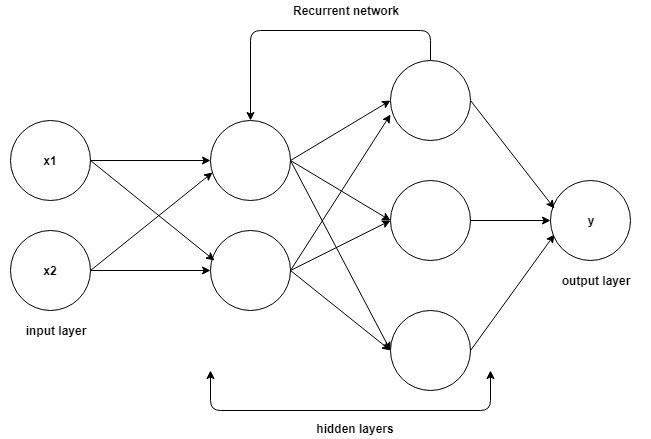
La source
Par conséquent, un RNN a deux entrées : le présent et le passé récent. Ceci est important car la séquence de données contient des informations cruciales sur ce qui va suivre, c'est pourquoi un RNN peut faire des choses que d'autres algorithmes ne peuvent pas faire. La caractéristique principale et la plus importante des réseaux de neurones récurrents est l'état caché, qui mémorise certaines informations sur une séquence.
Les réseaux de neurones récurrents ont une mémoire qui stocke toutes les informations sur ce qui a été calculé. En utilisant les mêmes paramètres pour chaque entrée et en effectuant la même tâche sur toutes les entrées ou couches cachées, la complexité des paramètres est réduite.
Différence entre CNN et RNN
| Réseaux de neurones convolutifs | Réseaux de neurones récurrents |
| Dans l'apprentissage en profondeur, un réseau de neurones convolutifs (CNN ou ConvNet) est une classe de réseaux de neurones profonds, le plus souvent appliqué à l'analyse d'images visuelles. | Un réseau neuronal récurrent (RNN) est une classe de réseaux neuronaux artificiels où les connexions entre les nœuds forment un graphe orienté le long d'une séquence temporelle. |
| Il convient aux données spatiales telles que les images. | RNN est utilisé pour les données temporelles, également appelées données séquentielles. |
| CNN est un type de réseau de neurones artificiels à anticipation avec des variations de perceptrons multicouches conçus pour utiliser des quantités minimales de prétraitement. | RNN, contrairement aux réseaux de neurones à anticipation, peut utiliser sa mémoire interne pour traiter des séquences arbitraires d'entrées. |
| CNN est considéré comme plus puissant que RNN. | RNN inclut moins de compatibilité de fonctionnalités par rapport à CNN. |
| Ce CNN prend des entrées de tailles fixes et génère des sorties de taille fixe. | RNN peut gérer des longueurs d'entrée/sortie arbitraires. |
| Les CNN sont idéales pour le traitement des images et des vidéos. | Les RNN sont idéaux pour l'analyse de texte et de parole. |
| Les applications incluent la reconnaissance d'images, la classification d'images, l'analyse d'images médicales, la détection de visage et la vision par ordinateur. | Les applications incluent la traduction de texte, le traitement du langage naturel, la traduction linguistique, l'analyse des sentiments et l'analyse de la parole. |
Conclusion
Ainsi, dans cet article sur les différences entre les deux types de réseaux de neurones les plus populaires, les réseaux de neurones convolutifs et les réseaux de neurones récurrents, nous avons appris la structure de base d'un réseau de neurones, ainsi que les principes fondamentaux de CNN et de RNN et enfin résumé un brève comparaison entre les deux avec leurs applications dans le monde réel.
Si vous souhaitez en savoir plus sur l'apprentissage automatique, consultez le programme Executive PG d'IIIT-B & upGrad en apprentissage automatique et IA , conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions, IIIT -B Statut d'anciens élèves, 5+ projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
Pourquoi CNN est-il plus rapide que RNN ?
Les CNN sont plus rapides que les RNN car ils sont conçus pour gérer les images, tandis que les RNN sont conçus pour gérer le texte. Bien que les RNN puissent être formés pour gérer les images, il leur est toujours difficile de séparer les caractéristiques contrastées qui sont plus proches les unes des autres. Comme, par exemple, si vous avez une photo d'un visage avec les yeux, le nez et la bouche, les RNN ont du mal à déterminer quelle caractéristique afficher en premier. Les CNN utilisent une grille de points et, en utilisant un algorithme, ils peuvent être entraînés à reconnaître des formes et des motifs. Les CNN sont meilleurs que les RNN pour trier les images ; ils sont plus rapides que les RNN car ils sont simples à calculer et ils sont meilleurs pour trier les images.
A quoi sert le RNN ?
Les réseaux de neurones récurrents (RNN) sont une classe de réseaux de neurones artificiels où les connexions entre les unités forment un cycle dirigé. La sortie d'une unité devient l'entrée d'une autre unité et ainsi de suite, tout comme la sortie d'un neurone devient l'entrée d'un autre. Les RNN ont été utilisés avec succès pour entreprendre des tâches complexes, telles que la reconnaissance vocale et la traduction automatique, difficiles à réaliser avec des méthodes standard.
Qu'est-ce que RNN et en quoi est-il différent des réseaux de neurones Feedforward ?
Les réseaux de neurones récurrents (RNN) sont une sorte de réseaux de neurones utilisés pour le traitement de données séquentielles. Un réseau neuronal récurrent se compose d'une couche d'entrée, d'une ou plusieurs couches cachées et d'une couche de sortie. La ou les couches cachées sont conçues pour apprendre des représentations internes des données d'entrée, qui sont ensuite présentées à la couche de sortie sous la forme d'une représentation externe. Le RNN est formé à l'aide de la rétropropagation. Les RNN sont souvent comparés aux réseaux de neurones feedforward (FNN). Alors que les RNN et les FNN peuvent apprendre des représentations internes des données, les RNN sont capables d'apprendre des dépendances à long terme, ce dont les FNN ne sont pas capables.