
Comprendre GraphQl côté client avec Apollo-Client dans les applications React
Publié: 2022-03-10Selon State of JavaScript 2019, 38,7 % des développeurs aimeraient utiliser GraphQL, tandis que 50,8 % des développeurs aimeraient apprendre GraphQL.
En tant que langage de requête, GraphQL simplifie le workflow de création d'une application cliente. Il supprime la complexité de la gestion des points de terminaison d'API dans les applications côté client, car il expose un seul point de terminaison HTTP pour récupérer les données requises. Par conséquent, il élimine la surextraction et la sous-extraction de données, comme dans le cas de REST.
Mais GraphQL n'est qu'un langage de requête. Afin de l'utiliser facilement, nous avons besoin d'une plate-forme qui fait le gros du travail pour nous. L'une de ces plates-formes est Apollo.
La plate-forme Apollo est une implémentation de GraphQL qui transfère les données entre le cloud (le serveur) et l'interface utilisateur de votre application. Lorsque vous utilisez Apollo Client, toute la logique de récupération des données, de suivi, de chargement et de mise à jour de l'interface utilisateur est encapsulée par le hook useQuery (comme dans le cas de React). Par conséquent, la récupération de données est déclarative. Il a également une mise en cache sans configuration. En configurant simplement Apollo Client dans votre application, vous obtenez un cache intelligent prêt à l'emploi, sans configuration supplémentaire requise.
Apollo Client est également interopérable avec d'autres frameworks, tels que Angular, Vue.js et React.
Remarque : Ce tutoriel profitera à ceux qui ont déjà travaillé avec RESTful ou d'autres formes d'API côté client et qui veulent voir si GraphQL vaut la peine d'être essayé. Cela signifie que vous devriez avoir travaillé avec une API auparavant ; ce n'est qu'alors que vous pourrez comprendre à quel point GraphQL pourrait vous être bénéfique. Bien que nous couvrions quelques bases de GraphQL et d'Apollo Client, une bonne connaissance de JavaScript et de React Hooks sera utile.
Bases de GraphQL
Cet article n'est pas une introduction complète à GraphQL, mais nous définirons quelques conventions avant de continuer.
Qu'est-ce que GraphQL ?
GraphQL est une spécification qui décrit un langage de requête déclaratif que vos clients peuvent utiliser pour demander à une API les données exactes qu'ils souhaitent. Ceci est réalisé en créant un schéma de type fort pour votre API, avec une flexibilité ultime. Il garantit également que l'API résout les données et que les requêtes des clients sont validées par rapport à un schéma. Cette définition signifie que GraphQL contient certaines spécifications qui en font un langage de requête déclaratif, avec une API typée statiquement (construite autour de Typescript) et permettant au client d'exploiter ces systèmes de type pour demander à l'API les données exactes qu'il souhaite. .
Donc, si nous créons des types avec des champs, alors, du côté client, nous pourrions dire : « Donnez-nous ces données avec ces champs exacts ». Ensuite, l'API répondra avec cette forme exacte, comme si nous utilisions un système de type dans un langage fortement typé. Vous pouvez en savoir plus dans mon article Typescript.
Examinons quelques conventions de GraphQl qui nous aideront à continuer.
Les bases
- Opérations
Dans GraphQL, chaque action effectuée est appelée une opération. Il y a quelques opérations, à savoir :- Mettre en doute
Cette opération concerne la récupération des données du serveur. Vous pouvez également appeler cela une récupération en lecture seule. - Mutation
Cette opération implique la création, la mise à jour et la suppression de données d'un serveur. Il est communément appelé une opération CUD (création, mise à jour et suppression). - Abonnements
Cette opération dans GraphQL consiste à envoyer des données d'un serveur à ses clients lorsque des événements spécifiques se produisent. Ils sont généralement implémentés avec WebSockets.
- Mettre en doute
Dans cet article, nous ne traiterons que des opérations de requête et de mutation.
- Noms d'opération
Il existe des noms uniques pour vos opérations de requête et de mutation côté client. - Variables et arguments
Les opérations peuvent définir des arguments, un peu comme une fonction dans la plupart des langages de programmation. Ces variables peuvent ensuite être transmises à des appels de requête ou de mutation à l'intérieur de l'opération en tant qu'arguments. Les variables sont censées être fournies au moment de l'exécution lors de l'exécution d'une opération à partir de votre client. - Crénelage
Il s'agit d'une convention dans GraphQL côté client qui implique de renommer des noms de champs verbeux ou vagues avec des noms de champs simples et lisibles pour l'interface utilisateur. La création d'alias est nécessaire dans les cas d'utilisation où vous ne souhaitez pas avoir de noms de champ en conflit.
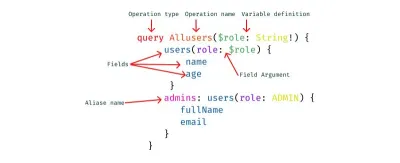
Qu'est-ce que GraphQL côté client ?
Lorsqu'un ingénieur front-end crée des composants d'interface utilisateur à l'aide de n'importe quel framework, comme Vue.js ou (dans notre cas) React, ces composants sont modélisés et conçus à partir d'un certain modèle sur le client pour s'adapter aux données qui seront extraites du serveur.
L'un des problèmes les plus courants avec les API RESTful est la surextraction et la sous-extraction. Cela se produit parce que le seul moyen pour un client de télécharger des données est d'atteindre des points de terminaison qui renvoient des structures de données fixes . La surrécupération dans ce contexte signifie qu'un client télécharge plus d'informations que ce qui est requis par l'application.
Dans GraphQL, en revanche, vous enverriez simplement une seule requête au serveur GraphQL qui inclut les données requises. Le serveur répondrait alors avec un objet JSON des données exactes que vous avez demandées - donc pas de surextraction. Sebastian Eschweiler explique les différences entre les API RESTful et GraphQL.
GraphQL côté client est une infrastructure côté client qui s'interface avec les données d'un serveur GraphQL pour exécuter les fonctions suivantes :
- Il gère les données en envoyant des requêtes et en mutant les données sans que vous ayez à créer vous-même des requêtes HTTP. Vous pouvez passer moins de temps à analyser les données et plus de temps à créer l'application proprement dite.
- Il gère pour vous la complexité d'un cache. Ainsi, vous pouvez stocker et récupérer les données extraites du serveur, sans aucune interférence de tiers, et éviter facilement de récupérer à nouveau des ressources en double. Ainsi, il identifie quand deux ressources sont identiques, ce qui est idéal pour une application complexe.
- Il maintient votre interface utilisateur cohérente avec l'interface utilisateur optimiste, une convention qui simule les résultats d'une mutation (c'est-à-dire les données créées) et met à jour l'interface utilisateur avant même de recevoir une réponse du serveur. Une fois la réponse reçue du serveur, le résultat optimiste est rejeté et remplacé par le résultat réel.
Pour plus d'informations sur GraphQL côté client, passez une heure avec le co-créateur de GraphQL et d'autres personnes sympas sur GraphQL Radio.
Qu'est-ce qu'Apollo Client ?
Apollo Client est un client GraphQL interopérable, ultra-flexible et communautaire pour JavaScript et les plateformes natives. Ses fonctionnalités impressionnantes incluent un outil de gestion d'état robuste (Apollo Link), un système de mise en cache sans configuration, une approche déclarative de la récupération des données, une pagination facile à mettre en œuvre et l'interface utilisateur optimiste pour votre application côté client.
Apollo Client stocke non seulement l'état des données extraites du serveur, mais également l'état qu'il a créé localement sur votre client ; par conséquent, il gère l'état des données d'API et des données locales.
Il est également important de noter que vous pouvez utiliser Apollo Client avec d'autres outils de gestion d'état, comme Redux, sans conflit. De plus, il est possible de migrer votre gestion d'état de, par exemple, Redux vers Apollo Client (ce qui dépasse le cadre de cet article). En fin de compte, l'objectif principal d'Apollo Client est de permettre aux ingénieurs d'interroger les données d'une API de manière transparente.
Fonctionnalités du client Apollo
Apollo Client a conquis de nombreux ingénieurs et entreprises en raison de ses fonctionnalités extrêmement utiles qui facilitent la création d'applications modernes et robustes. Les fonctionnalités suivantes sont intégrées :
- Mise en cache
Apollo Client prend en charge la mise en cache à la volée. - Interface utilisateur optimiste
Apollo Client prend en charge l'interface utilisateur optimiste. Il s'agit d'afficher temporairement l'état final d'une opération (mutation) pendant que l'opération est en cours. Une fois l'opération terminée, les données réelles remplacent les données optimistes. - Pagination
Apollo Client possède une fonctionnalité intégrée qui facilite l'implémentation de la pagination dans votre application. Il prend en charge la plupart des maux de tête techniques liés à la récupération d'une liste de données, soit par patchs, soit en une seule fois, à l'aide de la fonctionfetchMore, fournie avec le crochetuseQuery.
Dans cet article, nous examinerons une sélection de ces fonctionnalités.
Assez de théorie. Serrez votre ceinture de sécurité et prenez une tasse de café pour accompagner vos crêpes, car nous nous salissons les mains.
Construire notre application Web
Ce projet est inspiré par Scott Moss.
Nous allons créer une simple application Web pour animalerie, dont les fonctionnalités incluent :
- récupérer nos animaux de compagnie du côté serveur ;
- créer un animal de compagnie (ce qui implique de créer le nom, le type d'animal de compagnie et l'image);
- en utilisant l'interface utilisateur optimiste ;
- utiliser la pagination pour segmenter nos données.
Pour commencer, clonez le référentiel, en vous assurant que la branche de starter est celle que vous avez clonée.
Commencer
- Installez l'extension Apollo Client Developer Tools pour Chrome.
- À l'aide de l'interface de ligne de commande (CLI), accédez au répertoire du référentiel cloné et exécutez la commande pour obtenir toutes les dépendances :
npm install. - Exécutez la commande
npm run apppour démarrer l'application. - Toujours dans le dossier racine, exécutez la commande
npm run server. Cela démarrera notre serveur principal pour nous, que nous utiliserons au fur et à mesure.
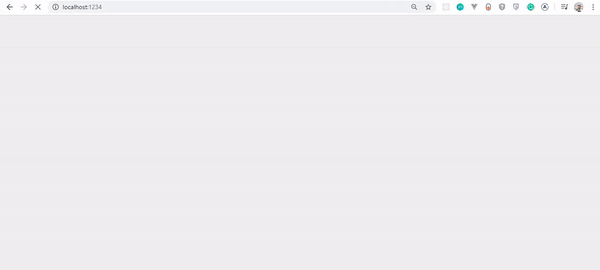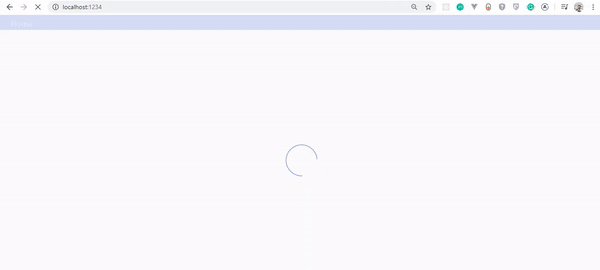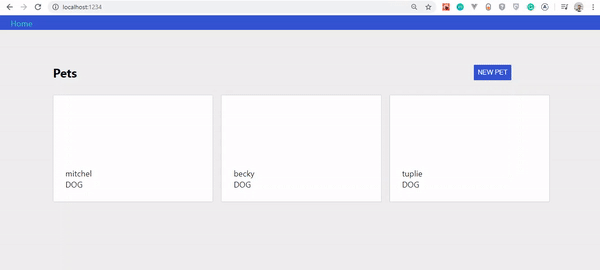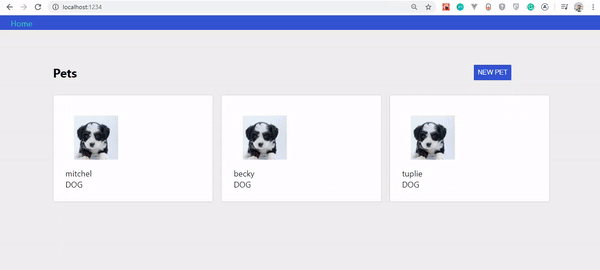
L'application devrait s'ouvrir dans un port configuré. Le mien est https://localhost:1234/ ; le vôtre est probablement autre chose.
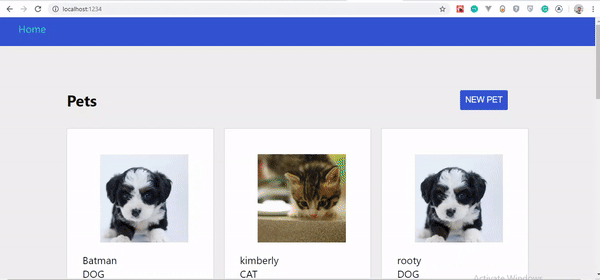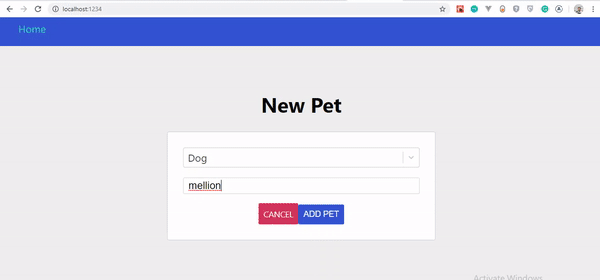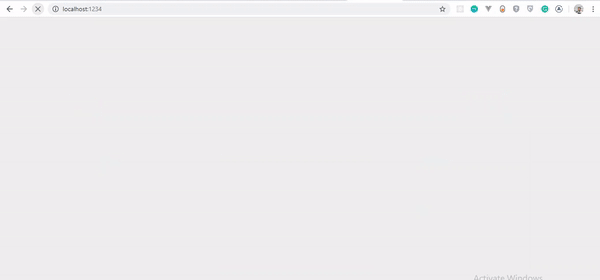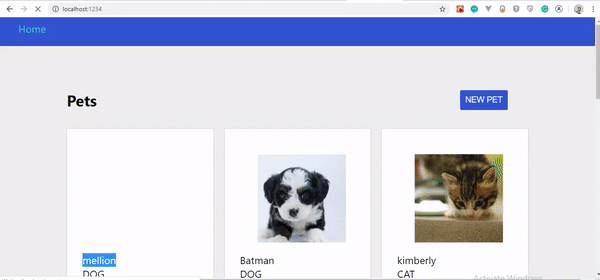
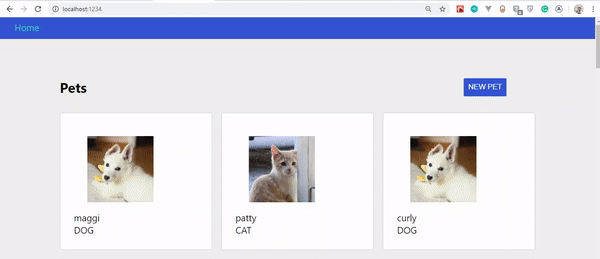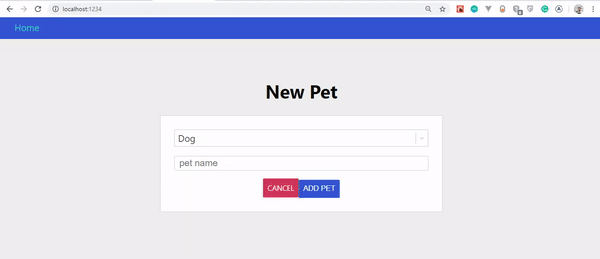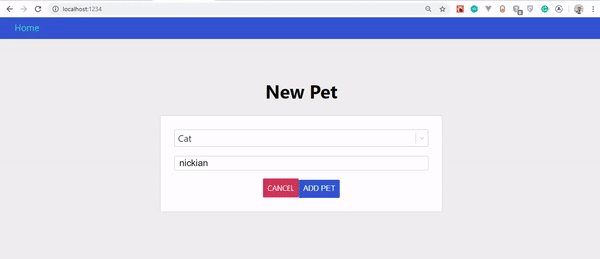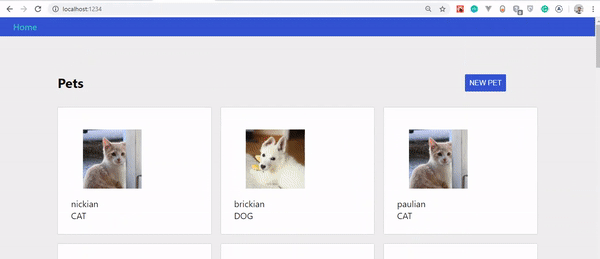
Si tout a bien fonctionné, votre application devrait ressembler à ceci :
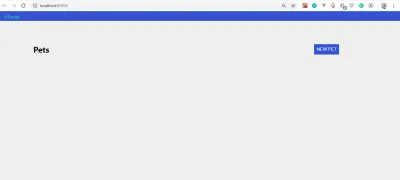
Vous remarquerez que nous n'avons pas d'animaux à afficher. C'est parce que nous n'avons pas encore créé une telle fonctionnalité.
Si vous avez correctement installé Apollo Client Developer Tools, ouvrez les outils de développement et cliquez sur l'icône de la barre d'état. Vous verrez "Apollo" et quelque chose comme ceci :
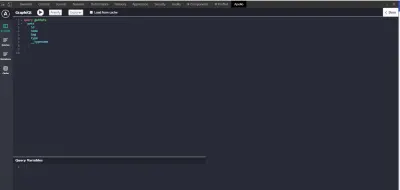
Comme les outils de développement Redux et React, nous utiliserons Apollo Client Developer Tools pour écrire et tester nos requêtes et mutations. L'extension est fournie avec le GraphQL Playground.
Aller chercher des animaux de compagnie
Ajoutons la fonctionnalité qui récupère les animaux de compagnie. Passez à client/src/client.js . Nous allons écrire Apollo Client, le lier à une API, l'exporter en tant que client par défaut et écrire une nouvelle requête.
Copiez le code suivant et collez-le dans client.js :
import { ApolloClient } from 'apollo-client' import { InMemoryCache } from 'apollo-cache-inmemory' import { HttpLink } from 'apollo-link-http' const link = new HttpLink({ uri: 'https://localhost:4000/' }) const cache = new InMemoryCache() const client = new ApolloClient({ link, cache }) export default clientVoici une explication de ce qui se passe ci-dessus :
-
ApolloClient
Ce sera la fonction qui encapsule notre application et, par conséquent, s'interface avec HTTP, met en cache les données et met à jour l'interface utilisateur. -
InMemoryCache
Il s'agit du magasin de données normalisé dans Apollo Client qui aide à manipuler le cache dans notre application. -
HttpLink
Il s'agit d'une interface réseau standard pour modifier le flux de contrôle des requêtes GraphQL et récupérer les résultats GraphQL. Il agit comme un middleware, récupérant les résultats du serveur GraphQL chaque fois que le lien est déclenché. De plus, c'est un bon substitut pour d'autres options, commeAxiosetwindow.fetch. - Nous déclarons une variable de lien qui est assignée à une instance de
HttpLink. Il faut une propriétéuriet une valeur à notre serveur, qui esthttps://localhost:4000/. - Vient ensuite une variable de cache qui contient la nouvelle instance de
InMemoryCache. - La variable client prend également une instance d'
ApolloClientet encapsule lelinket lecache. - Enfin, nous exportons le
clientafin de pouvoir l'utiliser dans toute l'application.
Avant de voir cela en action, nous devons nous assurer que toute notre application est exposée à Apollo et que notre application peut recevoir des données extraites du serveur et qu'elle peut muter ces données.
Pour y parvenir, passons à client/src/index.js :
import React from 'react' import ReactDOM from 'react-dom' import { BrowserRouter } from 'react-router-dom' import { ApolloProvider } from '@apollo/react-hooks' import App from './components/App' import client from './client' import './index.css' const Root = () => ( <BrowserRouter><ApolloProvider client={client}> <App /> </ApolloProvider></BrowserRouter> ); ReactDOM.render(<Root />, document.getElementById('app')) if (module.hot) { module.hot.accept() }
Comme vous le remarquerez dans le code en surbrillance, nous avons encapsulé le composant App dans ApolloProvider et transmis le client en tant que prop au client . ApolloProvider est similaire à Context.Provider de React. Il encapsule votre application React et place le client dans son contexte, ce qui vous permet d'y accéder de n'importe où dans votre arborescence de composants.
Pour récupérer nos animaux de compagnie sur le serveur, nous devons écrire des requêtes qui demandent les champs exacts que nous voulons. Rendez-vous sur client/src/pages/Pets.js , et copiez et collez-y le code suivant :
import React, {useState} from 'react' import gql from 'graphql-tag' import { useQuery, useMutation } from '@apollo/react-hooks' import PetsList from '../components/PetsList' import NewPetModal from '../components/NewPetModal' import Loader from '../components/Loader'const GET_PETS = gql` query getPets { pets { id name type img } } `;export default function Pets () { const [modal, setModal] = useState(false)const { loading, error, data } = useQuery(GET_PETS); if (loading) return <Loader />; if (error) return <p>An error occured!</p>;const onSubmit = input => { setModal(false) } if (modal) { return <NewPetModal onSubmit={onSubmit} onCancel={() => setModal(false)} /> } return ( <div className="page pets-page"> <section> <div className="row betwee-xs middle-xs"> <div className="col-xs-10"> <h1>Pets</h1> </div> <div className="col-xs-2"> <button onClick={() => setModal(true)}>new pet</button> </div> </div> </section> <section><PetsList pets={data.pets}/></section> </div> ) }
Avec quelques morceaux de code, nous sommes en mesure de récupérer les animaux de compagnie du serveur.

Qu'est-ce que gql ?
Il est important de noter que les opérations dans GraphQL sont généralement des objets JSON écrits avec graphql-tag et avec des backticks.
Les balises gql sont des balises littérales de modèle JavaScript qui analysent les chaînes de requête GraphQL dans l'AST GraphQL (arbre de syntaxe abstraite).
- Opérations de requête
Afin de récupérer nos animaux de compagnie sur le serveur, nous devons effectuer une opération de requête.- Comme nous effectuons une opération de
query, nous devions spécifier letyped'opération avant de la nommer. - Le nom de notre requête est
GET_PETS. C'est une convention de dénomination de GraphQL d'utiliser camelCase pour les noms de champs. - Le nom de nos champs est
pets. Par conséquent, nous spécifions les champs exacts dont nous avons besoin du serveur(id, name, type, img). -
useQueryest un crochet React qui sert de base à l'exécution de requêtes dans une application Apollo. Pour effectuer une opération de requête dans notre composant React, nous appelons le hookuseQuery, qui a été initialement importé de@apollo/react-hooks. Ensuite, nous lui transmettons une chaîne de requête GraphQL, qui estGET_PETSdans notre cas.
- Comme nous effectuons une opération de
- Lorsque notre composant est rendu,
useQueryrenvoie une réponse d'objet du client Apollo qui contient les propriétés de chargement, d'erreur et de données. Ainsi, ils sont déstructurés, afin que nous puissions les utiliser pour rendre l'interface utilisateur. -
useQueryest génial. Nous n'avons pas besoin d'inclureasync-await. C'est déjà pris en charge en arrière-plan. Plutôt cool, n'est-ce pas ?-
loading
Cette propriété nous aide à gérer l'état de chargement de l'application. Dans notre cas, nous renvoyons un composantLoaderpendant le chargement de notre application. Par défaut, le chargement estfalse. -
error
Au cas où, nous utilisons cette propriété pour gérer toute erreur qui pourrait se produire. -
data
Celui-ci contient nos données réelles du serveur. - Enfin, dans notre composant
PetsList, nous passons les accessoirespets, avecdata.petscomme valeur d'objet.
-
À ce stade, nous avons interrogé avec succès notre serveur.
Pour lancer notre application, lançons la commande suivante :
- Démarrez l'application cliente. Exécutez la commande
npm run appdans votre CLI. - Démarrez le serveur. Exécutez la commande
npm run serverdans une autre CLI.
Si tout s'est bien passé, vous devriez voir ceci :
Données en mutation
Muter des données ou créer des données dans Apollo Client revient presque à interroger des données, avec de très légères modifications.
Toujours dans client/src/pages/Pets.js , copions et collons le code en surbrillance :
.... const GET_PETS = gql` query getPets { pets { id name type img } } `;const NEW_PETS = gql` mutation CreateAPet($newPet: NewPetInput!) { addPet(input: $newPet) { id name type img } } `;const Pets = () => { const [modal, setModal] = useState(false) const { loading, error, data } = useQuery(GET_PETS);const [createPet, newPet] = useMutation(NEW_PETS);const onSubmit = input => { setModal(false)createPet({ variables: { newPet: input } }); } if (loading || newPet.loading) return <Loader />; if (error || newPet.error) return <p>An error occured</p>;if (modal) { return <NewPetModal onSubmit={onSubmit} onCancel={() => setModal(false)} /> } return ( <div className="page pets-page"> <section> <div className="row betwee-xs middle-xs"> <div className="col-xs-10"> <h1>Pets</h1> </div> <div className="col-xs-2"> <button onClick={() => setModal(true)}>new pet</button> </div> </div> </section> <section> <PetsList pets={data.pets}/> </section> </div> ) } export default Pets
Pour créer une mutation, nous prendrions les mesures suivantes.
1. mutation
Pour créer, mettre à jour ou supprimer, nous devons effectuer l'opération de mutation . L'opération de mutation a un nom CreateAPet , avec un argument. Cet argument a une variable $newPet , avec un type de NewPetInput . Le ! signifie que l'opération est nécessaire ; ainsi, GraphQL n'exécutera pas l'opération à moins que nous passions une variable newPet dont le type est NewPetInput .
2. addPet
La fonction addPet , qui est à l'intérieur de l'opération de mutation , prend un argument d' input et est définie sur notre variable $newPet . Les ensembles de champs spécifiés dans notre fonction addPet doivent être égaux aux ensembles de champs de notre requête. Les ensembles de champs dans notre opération sont :
-
id -
name -
type -
img
3. useMutation
Le crochet useMutation React est l'API principale pour exécuter des mutations dans une application Apollo. Lorsque nous devons muter des données, nous appelons useMutation dans un composant React et lui transmettons une chaîne GraphQL (dans notre cas, NEW_PETS ).
Lorsque notre composant useMutation , il renvoie un tuple (c'est-à-dire un ensemble ordonné de données constituant un enregistrement) dans un tableau qui inclut :
- une fonction
mutateque nous pouvons appeler à tout moment pour exécuter la mutation ; - un objet avec des champs qui représentent l'état actuel de l'exécution de la mutation.
Le hook useMutation reçoit une chaîne de mutation GraphQL (qui est NEW_PETS dans notre cas). Nous avons déstructuré le tuple, qui est la fonction ( createPet ) qui va muter les données et le champ objet ( newPets ).
4. createPet
Dans notre fonction onSubmit , peu de temps après l'état setModal , nous avons défini notre createPet . Cette fonction prend une variable avec une propriété d'objet d'une valeur définie sur { newPet: input } . L' input représente les différents champs d'entrée de notre formulaire (tels que le nom, le type, etc.).
Ceci fait, le résultat devrait ressembler à ceci :
Si vous observez attentivement le GIF, vous remarquerez que notre animal de compagnie créé n'apparaît pas instantanément, uniquement lorsque la page est actualisée. Cependant, il a été mis à jour sur le serveur.
La grande question est, pourquoi notre animal de compagnie ne se met-il pas à jour instantanément ? Découvrons-le dans la section suivante.
Mise en cache dans le client Apollo
La raison pour laquelle notre application ne se met pas à jour automatiquement est que nos données nouvellement créées ne correspondent pas aux données de cache dans Apollo Client. Il y a donc un conflit quant à ce qu'il faut exactement mettre à jour à partir du cache.
En termes simples, si nous effectuons une mutation qui met à jour ou supprime plusieurs entrées (un nœud), nous sommes alors responsables de la mise à jour de toutes les requêtes faisant référence à ce nœud, afin qu'il modifie nos données en cache pour correspondre aux modifications qu'une mutation apporte à notre back- données finales .
Garder le cache synchronisé
Il existe plusieurs façons de synchroniser notre cache chaque fois que nous effectuons une opération de mutation.
La première consiste à récupérer les requêtes correspondantes après une mutation, en utilisant la propriété d'objet refetchQueries (la manière la plus simple).
Remarque : Si nous devions utiliser cette méthode, elle prendrait une propriété d'objet dans notre fonction createPet appelée refetchQueries , et elle contiendrait un tableau d'objets avec une valeur de la requête : refetchQueries: [{ query: GET_PETS }] .
Parce que notre objectif dans cette section n'est pas seulement de mettre à jour nos animaux de compagnie créés dans l'interface utilisateur, mais de manipuler le cache, nous n'utiliserons pas cette méthode.
La deuxième approche consiste à utiliser la fonction de update à jour. Dans Apollo Client, il existe une fonction d'assistance à la mise à update qui aide à modifier les données du cache, afin qu'elles se synchronisent avec les modifications qu'une mutation apporte à nos données back-end. En utilisant cette fonction, nous pouvons lire et écrire dans le cache.
Mise à jour du cache
Copiez le code en surbrillance suivant et collez-le dans client/src/pages/Pets.js :
...... const Pets = () => { const [modal, setModal] = useState(false) const { loading, error, data } = useQuery(GET_PETS);const [createPet, newPet] = useMutation(NEW_PETS, { update(cache, { data: { addPet } }) { const data = cache.readQuery({ query: GET_PETS }); cache.writeQuery({ query: GET_PETS, data: { pets: [addPet, ...data.pets] }, }); }, } );.....
La fonction de update reçoit deux arguments :
- Le premier argument est le cache d'Apollo Client.
- La seconde est la réponse de mutation exacte du serveur. Nous déstructurons la propriété
dataet la définissons sur notre mutation (addPet).
Ensuite, pour mettre à jour la fonction, nous devons vérifier quelle requête doit être mise à jour (dans notre cas, la requête GET_PETS ) et lire le cache.
Deuxièmement, nous devons écrire dans la query qui a été lue, afin qu'elle sache que nous sommes sur le point de la mettre à jour. Pour ce faire, nous passons un objet qui contient une propriété d'objet de query , avec la valeur définie sur notre opération de query ( GET_PETS ), et une propriété de data dont la valeur est un objet pet et qui a un tableau de la mutation addPet et une copie de la les données de l'animal.
Si vous avez suivi attentivement ces étapes, vous devriez voir vos animaux se mettre à jour automatiquement au fur et à mesure que vous les créez. Voyons les changements :
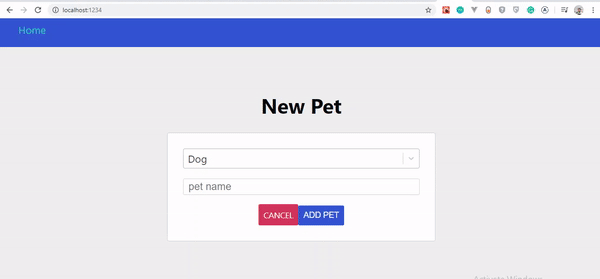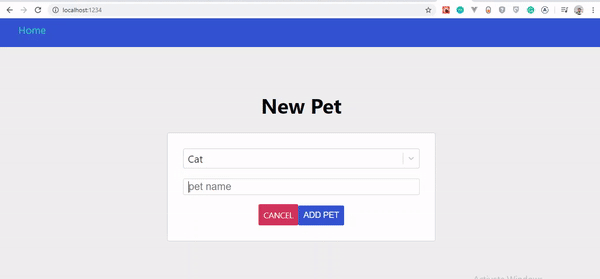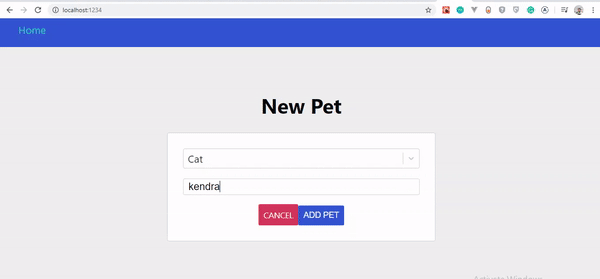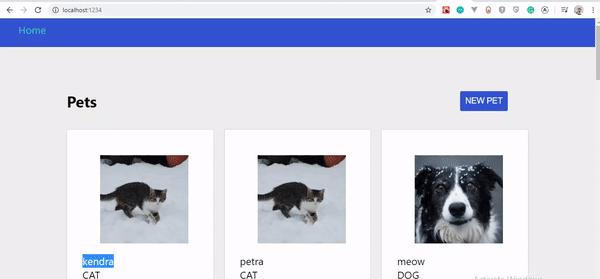
Interface utilisateur optimiste
Beaucoup de gens sont de grands fans de chargeurs et de spinners. Il n'y a rien de mal à utiliser un chargeur ; il existe des cas d'utilisation parfaits où un chargeur est la meilleure option. J'ai écrit sur les chargeurs par rapport aux spinners et sur leurs meilleurs cas d'utilisation.
Les chargeurs et les spinners jouent en effet un rôle important dans la conception de l'interface utilisateur et de l'expérience utilisateur, mais l'arrivée d'Optimistic UI a volé la vedette.
Qu'est-ce que l'interface utilisateur optimiste ?
L'interface utilisateur optimiste est une convention qui simule les résultats d'une mutation (données créées) et met à jour l'interface utilisateur avant de recevoir une réponse du serveur. Une fois la réponse reçue du serveur, le résultat optimiste est rejeté et remplacé par le résultat réel.
En fin de compte, une interface utilisateur optimiste n'est rien de plus qu'un moyen de gérer les performances perçues et d'éviter les états de chargement.
Apollo Client a une manière très intéressante d'intégrer l'interface utilisateur optimiste. Cela nous donne un crochet simple qui nous permet d'écrire dans le cache local après la mutation. Voyons voir comment ça fonctionne!
Étape 1
Rendez-vous sur client/src/client.js et ajoutez uniquement le code en surbrillance.
import { ApolloClient } from 'apollo-client' import { InMemoryCache } from 'apollo-cache-inmemory' import { HttpLink } from 'apollo-link-http'import { setContext } from 'apollo-link-context' import { ApolloLink } from 'apollo-link' const http = new HttpLink({ uri: "https://localhost:4000/" }); const delay = setContext( request => new Promise((success, fail) => { setTimeout(() => { success() }, 800) }) ) const link = ApolloLink.from([ delay, http ])const cache = new InMemoryCache() const client = new ApolloClient({ link, cache }) export default client
La première étape implique ce qui suit :
- Nous importons
setContextdepuisapollo-link-context. La fonctionsetContextprend une fonction de rappel et renvoie une promesse dontsetTimeoutest défini sur800ms, afin de créer un délai lorsqu'une opération de mutation est effectuée. - La méthode
ApolloLink.fromgarantit que l'activité réseau qui représente le lien (notre API) depuisHTTPest retardée.
Étape 2
L'étape suivante consiste à utiliser le hook Optimistic UI. Revenez à client/src/pages/Pets.js et ajoutez uniquement le code en surbrillance ci-dessous.
..... const Pets = () => { const [modal, setModal] = useState(false) const { loading, error, data } = useQuery(GET_PETS); const [createPet, newPet] = useMutation(NEW_PETS, { update(cache, { data: { addPet } }) { const data = cache.readQuery({ query: GET_PETS }); cache.writeQuery({ query: GET_PETS, data: { pets: [addPet, ...data.pets] }, }); }, } ); const onSubmit = input => { setModal(false) createPet({ variables: { newPet: input },optimisticResponse: { __typename: 'Mutation', addPet: { __typename: 'Pet', id: Math.floor(Math.random() * 10000 + ''), name: input.name, type: input.type, img: 'https://via.placeholder.com/200' } }}); } .....
L'objet optimisticResponse est utilisé si nous voulons que l'interface utilisateur se mette à jour immédiatement lorsque nous créons un animal de compagnie, au lieu d'attendre la réponse du serveur.
Les extraits de code ci-dessus incluent les éléments suivants :
-
__typenameest injecté par Apollo dans la requête pour récupérer letypedes entités interrogées. Ces types sont utilisés par Apollo Client pour construire la propriétéid(qui est un symbole) à des fins de mise en cache dansapollo-cache. Ainsi,__typenameest une propriété valide de la réponse à la requête. - La mutation est définie comme
__typenamedeoptimisticResponse. - Comme défini précédemment, le nom de notre mutation est
addPetet le__typenameestPet. - Viennent ensuite les champs de notre mutation que nous voulons que la réponse optimiste mette à jour :
-
id
Comme nous ne savons pas quel sera l'ID du serveur, nous en avons créé un en utilisantMath.floor. -
name
Cette valeur est définie surinput.name. -
type
La valeur du type estinput.type. -
img
Maintenant, parce que notre serveur génère des images pour nous, nous avons utilisé un espace réservé pour imiter notre image à partir du serveur.
-
Ce fut en effet un long trajet. Si vous êtes arrivé au bout, n'hésitez pas à faire une pause sur votre chaise avec votre tasse de café.
Jetons un coup d'œil à notre résultat. Le référentiel de support pour ce projet est sur GitHub. Cloner et expérimenter avec.
Conclusion
Les fonctionnalités étonnantes d'Apollo Client, telles que l'interface utilisateur et la pagination optimistes, font de la création d'applications côté client une réalité.
Alors qu'Apollo Client fonctionne très bien avec d'autres frameworks, tels que Vue.js et Angular, les développeurs React ont Apollo Client Hooks, et ils ne peuvent donc pas s'empêcher de profiter de la création d'une excellente application.
Dans cet article, nous n'avons fait qu'effleurer la surface. Maîtriser Apollo Client demande une pratique constante. Alors, allez-y et clonez le référentiel, ajoutez la pagination et jouez avec les autres fonctionnalités qu'il offre.
Veuillez partager vos commentaires et votre expérience dans la section des commentaires ci-dessous. Nous pouvons également discuter de vos progrès sur Twitter. Acclamations!
Les références
- « GraphQL côté client en réaction », Scott Moss, maître frontend
- « Documentation », client Apollo
- "L'interface utilisateur optimiste avec React", Patryk Andrzejewski
- "Les vrais mensonges des interfaces utilisateur optimistes", Smashing Magazine