
Choisir une nouvelle technologie de base de données sans serveur dans une agence (étude de cas)
Publié: 2022-03-10Cet article a été aimablement soutenu par nos chers amis de Fauna qui rendent le travail avec des données opérationnelles productif, évolutif et sécurisé pour chaque équipe de développement de logiciels. Merci!

L'adoption d'une nouvelle technologie est l'une des décisions les plus difficiles pour un technologue dans un rôle de leadership. Il s'agit souvent d'une zone de risque vaste et inconfortable, que vous développiez des logiciels pour une autre organisation ou au sein de la vôtre.
Au cours des douze dernières années en tant qu'ingénieur logiciel, je me suis retrouvé dans la position de devoir évaluer une nouvelle technologie à une fréquence croissante. Cela peut être le prochain framework frontal, un nouveau langage, ou même des architectures entièrement nouvelles comme le serverless.
La phase d'expérimentation est souvent amusante et excitante. C'est là que les ingénieurs logiciels sont le plus à l'aise, embrassant la nouveauté et l'euphorie des moments "aha" tout en explorant de nouveaux concepts. En tant qu'ingénieurs, nous aimons réfléchir et bricoler, mais avec suffisamment d'expérience, chaque ingénieur apprend que même la technologie la plus incroyable a ses défauts. Vous ne les avez pas encore trouvés.
Maintenant, en tant que co-fondateur d'une agence créative, mon équipe et moi sommes souvent dans une position unique pour utiliser les nouvelles technologies. Nous voyons de nombreux projets entièrement nouveaux, qui deviennent l'occasion idéale d'introduire quelque chose de nouveau. Ces projets voient également un niveau d'isolement technique par rapport à l'organisation plus large et sont souvent moins accablés par les décisions préalables.
Cela étant dit, un bon chef d'agence est chargé de s'occuper de la grande idée de quelqu'un d'autre et de la diffuser dans le monde. Nous devons le traiter avec encore plus de soin que nous ne le ferions pour nos propres projets. Chaque fois que je suis sur le point de faire le dernier appel à une nouvelle technologie, je réfléchis souvent à cette sagesse du co-fondateur Stack Overflow Joel Spolski :
"Vous devez transpirer et saigner avec la chose pendant un an ou deux avant de savoir vraiment que c'est assez bon ou de réaliser que peu importe à quel point vous essayez, vous ne pouvez pas..."
C'est la peur, c'est l'endroit où aucun responsable technique ne veut se retrouver. Choisir une nouvelle technologie pour un projet réel est déjà assez difficile, mais en tant qu'agence, vous devez prendre ces décisions avec le projet de quelqu'un d'autre, quelqu'un le rêve d'un autre, l'argent de quelqu'un d'autre. Dans une agence, la dernière chose que vous souhaitez est de trouver l'un de ces défauts à l'approche de la date limite d'un projet. Les délais et les budgets serrés rendent presque impossible de faire marche arrière après avoir franchi un certain seuil, donc découvrir qu'une technologie ne peut pas faire quelque chose de critique ou n'est pas fiable trop tard dans un projet peut être catastrophique.
Tout au long de ma carrière d'ingénieur logiciel, j'ai travaillé dans des entreprises SaaS et des agences créatives. Lorsqu'il s'agit d'adopter une nouvelle technologie pour un projet, ces deux environnements ont des critères très différents. Les critères se chevauchent, mais dans l'ensemble, l'environnement de l'agence doit travailler avec des budgets rigides et des contraintes de temps rigoureuses . Bien que nous souhaitions que les produits que nous construisons vieillissent bien au fil du temps, il est souvent plus difficile d'investir dans quelque chose de moins éprouvé ou d'adopter une technologie avec des courbes d'apprentissage plus abruptes et des aspérités.
Cela étant dit, les agences ont également des contraintes uniques qu'une seule organisation peut ne pas avoir. Nous devons privilégier l'efficacité et la stabilité. L'heure facturable est souvent l'unité de mesure finale lorsqu'un projet est terminé. J'ai été dans des entreprises SaaS où passer un jour ou deux sur la configuration ou un pipeline de construction n'est pas un gros problème.
Dans une agence, ce type de coût en temps met à rude épreuve les relations, car les équipes financières constatent une réduction des marges bénéficiaires pour des résultats peu visibles. Il faut aussi tenir compte de la pérennité d'un projet, et à l'inverse de ce qui se passe si un projet doit être restitué au client. Nous devons donc privilégier l'efficacité, la courbe d'apprentissage et la stabilité de la technologie que nous choisissons.
Lors de l'évaluation d'une nouvelle technologie, j'examine trois domaines principaux :
- La technologie
- L'expérience développeur
- Les affaires
Chacun de ces domaines a un ensemble de critères que j'aime rencontrer avant de commencer à vraiment plonger dans le code et à expérimenter. Dans cet article, nous examinerons ces critères et utiliserons l'exemple de l'examen d'une nouvelle base de données pour un projet et l'examinerons à un niveau élevé sous chaque objectif. Prendre une décision tangible comme celle-ci aidera à démontrer comment nous pouvons appliquer ce cadre dans le monde réel.
La technologie
La toute première chose à examiner lors de l'évaluation d'une nouvelle technologie est de savoir si cette solution peut résoudre les problèmes qu'elle prétend résoudre. Avant de se plonger dans la façon dont une technologie peut aider nos processus et nos opérations commerciales, il est important d'établir d'abord qu'elle répond à nos exigences fonctionnelles . C'est aussi là que j'aime jeter un œil aux solutions existantes que nous utilisons et comment cette nouvelle se compare à elles.
Je vais me poser des questions comme :
- Résout-il au minimum le problème de ma solution existante ?
- En quoi cette solution est-elle meilleure ?
- En quoi est-ce pire ?
- Pour les domaines où c'est pire, que faudra-t-il pour surmonter ces lacunes?
- Va-t-il remplacer plusieurs outils ?
- Quelle est la stabilité de la technologie ?
Notre pourquoi ?
À ce stade, je veux également examiner pourquoi nous recherchons une autre solution. Une réponse simple est que nous rencontrons un problème que les solutions existantes ne résolvent pas . Cependant, c'est souvent rarement le cas. Nous avons résolu de nombreux problèmes logiciels au fil des ans avec toute la technologie dont nous disposons aujourd'hui. Ce qui se passe généralement, c'est que nous nous tournons vers une nouvelle technologie qui rend quelque chose que nous faisons actuellement plus facile, plus stable, plus rapide ou moins cher.
Prenons React comme exemple. Pourquoi avons-nous décidé d'adopter React alors que jQuery ou Vanilla JavaScript faisaient le travail ? Dans ce cas, l'utilisation du framework a mis en évidence qu'il s'agissait d'une bien meilleure façon de gérer les interfaces avec état. Il est devenu plus rapide pour nous de créer des éléments tels que des fonctionnalités de filtrage et de tri en travaillant avec des structures de données au lieu d'une manipulation directe du DOM. C'était un gain de temps et une stabilité accrue de nos solutions.
Typescript est un autre exemple où nous avons décidé de l'adopter parce que nous avons constaté une augmentation de la stabilité de notre code et de sa maintenabilité. Avec l'adoption de nouvelles technologies, il n'y a souvent pas de problème clair que nous cherchons à résoudre, mais plutôt simplement à rester à jour, puis à découvrir des solutions plus efficaces et stables que celles que nous utilisons actuellement.
Dans le cas d'une base de données, nous envisageons spécifiquement de passer à une option sans serveur . Nous avions connu beaucoup de succès avec des applications et des déploiements sans serveur, réduisant nos frais généraux en tant qu'organisation. Un domaine où nous avons estimé que cela manquait était notre couche de données. Nous avons vu des services comme Amazon Aurora, Fauna, Cosmos et Firebase qui appliquaient les principes sans serveur aux bases de données et nous voulions voir s'il était temps de sauter le pas nous-mêmes. Dans ce cas, nous cherchions à réduire nos frais généraux opérationnels et à augmenter notre vitesse et notre efficacité de développement.
Il est important à ce niveau de comprendre pourquoi avant de commencer à plonger dans de nouvelles offres. Cela peut être dû au fait que vous résolvez un nouveau problème, mais bien plus souvent, vous cherchez à améliorer votre capacité à résoudre un type de problème que vous résolvez déjà. Dans ce cas, vous devez faire l'inventaire des endroits où vous êtes allé pour déterminer ce qui apporterait une amélioration significative à votre flux de travail. En nous basant sur notre exemple d'examen des bases de données sans serveur, nous devrons examiner comment nous résolvons actuellement les problèmes et où ces solutions échouent.
Où nous avons été…
En tant qu'agence, nous avons déjà utilisé une large gamme de bases de données, y compris, mais sans s'y limiter, MySQL, PostgreSQL, MongoDB, DynamoDB, BigQuery et Firebase Cloud Storage. La grande majorité de notre travail s'est concentrée sur trois bases de données principales : PostgreSQL, MongoDB et Firebase Realtime Database. En fait, chacun d'entre eux propose des offres semi-sans serveur, mais certaines caractéristiques clés des nouvelles offres nous ont amenés à réévaluer nos hypothèses précédentes. Jetons un coup d'œil à notre expérience historique avec chacun de ces premiers et pourquoi nous sommes laissés à envisager des alternatives en premier lieu.
Nous avons généralement choisi PostgreSQL pour des projets plus importants et à long terme, car il s'agit de l'étalon-or éprouvé pour presque tout. Il prend en charge les transactions classiques, les données normalisées et est conforme à ACID. Il existe une multitude d'outils et d'ORM disponibles dans presque toutes les langues et il peut même être utilisé comme base de données NoSQL ad hoc avec sa prise en charge des colonnes JSON. Il s'intègre bien avec de nombreux frameworks, bibliothèques et langages de programmation existants, ce qui en fait un véritable cheval de bataille passe-partout. Il est également open-source et ne nous enferme donc pas dans un seul fournisseur. Comme on dit, personne n'a jamais été licencié pour avoir choisi Postgres.
Cela étant dit, nous nous sommes progressivement retrouvés à utiliser de moins en moins PostgreSQL au fur et à mesure que nous devenions davantage une boutique orientée Node. Nous avons constaté que les ORM pour Node étaient ternes et nécessitaient davantage de requêtes personnalisées (bien que cela soit devenu moins problématique maintenant) et NoSQL semblait être un ajustement plus naturel lorsque vous travaillez dans un environnement d'exécution JavaScript ou TypeScript. Cela dit, nous avions souvent des projets qui pouvaient être réalisés assez rapidement avec des modélisations relationnelles classiques comme les workflows e-commerce. Cependant, gérer la configuration locale de la base de données, unifier le flux de test entre les équipes et gérer les migrations locales étaient des choses que nous n'aimions pas et que nous étions heureux de laisser derrière nous à mesure que NoSQL, les bases de données basées sur le cloud devenaient plus populaires.
MongoDB était de plus en plus notre base de données de référence lorsque nous avons adopté Node.js comme back-end préféré. Travailler avec MongoDB Atlas a facilité la création rapide de bases de données de développement et de test que notre équipe pourrait utiliser. Pendant un certain temps, MongoDB n'était pas conforme à ACID, ne prenait pas en charge les transactions et décourageait trop d'opérations de type jointure interne. Ainsi, pour les applications de commerce électronique, nous utilisions toujours Postgres le plus souvent. Cela étant dit, il existe une multitude de bibliothèques qui vont avec et le langage de requête de Mongo et le support JSON de première classe nous ont donné une vitesse et une efficacité que nous n'avions pas connues avec les bases de données relationnelles. MongoDB a récemment ajouté la prise en charge des transactions ACID, mais pendant longtemps, c'était la principale raison pour laquelle nous opterions plutôt pour Postgres.
MongoDB nous a également présenté un nouveau niveau de flexibilité. Au milieu d'un projet d'agence, les exigences sont vouées à changer. Peu importe à quel point vous vous en défendez, il y a toujours un besoin de données de dernière minute . Avec les bases de données NoSQL, en général, la flexibilité de la structure des données a rendu ces types de modifications moins sévères. Nous ne nous sommes pas retrouvés avec un dossier plein de fichiers de migration pour gérer les colonnes ajoutées, supprimées et ajoutées à nouveau avant même qu'un projet ne voit le jour.
En tant que service, Mongo Atlas était également assez proche de ce que nous souhaitions dans un service cloud de base de données. J'aime penser à Atlas comme une offre semi -sans serveur, car vous avez encore des frais généraux opérationnels pour la gérer. Vous devez provisionner une base de données d'une certaine taille et sélectionner une quantité de mémoire à l'avance. Ces éléments ne seront pas mis à l'échelle automatiquement pour vous, vous devrez donc le surveiller lorsqu'il sera temps de fournir plus d'espace ou de mémoire. Dans une base de données véritablement sans serveur, tout cela se produirait automatiquement et à la demande.
Nous avons également utilisé Firebase Realtime Database pour quelques projets. Il s'agissait en effet d'une offre sans serveur où la base de données évolue à la demande, et avec une tarification à l'utilisation, cela avait du sens pour les applications où l'échelle n'était pas connue à l'avance et le budget était limité. Nous l'avons utilisé à la place de MongoDB pour des projets de courte durée qui avaient des exigences de données simples.
Une chose que nous n'avons pas appréciée à propos de Firebase, c'est qu'il se sentait plus éloigné du modèle relationnel typique construit autour de données normalisées auquel nous étions habitués. Garder les structures de données plates signifiait que nous avions souvent plus de duplication, ce qui pouvait devenir un peu moche à mesure qu'un projet se développait. Vous finissez par devoir mettre à jour les mêmes données à plusieurs endroits ou essayer de joindre différentes références, ce qui entraîne plusieurs requêtes qui peuvent devenir difficiles à raisonner dans le code. Bien que nous aimions Firebase, nous ne sommes jamais vraiment tombés amoureux du langage de requête et avons parfois trouvé la documentation terne.
En général, MongoDB et Firebase avaient un objectif similaire sur les données dénormalisées , et sans accès à des transactions efficaces, nous avons souvent trouvé de nombreux flux de travail faciles à modéliser dans les bases de données relationnelles, ce qui a conduit à un code plus complexe au niveau de la couche application avec leur homologues NoSQL. Si nous pouvions obtenir la flexibilité et la facilité de ces offres NoSQL avec la robustesse et la modélisation relationnelle d'une base de données SQL traditionnelle, nous aurions vraiment trouvé une excellente adéquation. Nous avons estimé que MongoDB avait la meilleure API et les meilleures capacités, mais Firebase avait le modèle véritablement sans serveur sur le plan opérationnel.
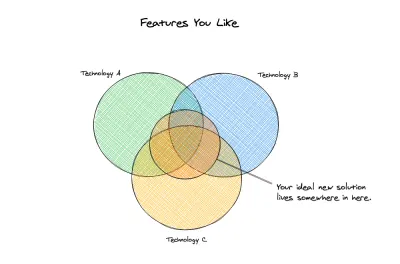
Notre idéal
À ce stade, nous pouvons commencer à examiner les nouvelles options que nous envisagerons. Nous avons clairement défini nos solutions précédentes et nous avons identifié les choses qu'il est important pour nous d'avoir au minimum dans notre nouvelle solution. Nous avons non seulement une base ou un ensemble minimum d'exigences, mais nous avons également un ensemble de problèmes que nous aimerions que la nouvelle solution résolve pour nous. Voici les exigences techniques que nous avons :
- Opérationnellement sans serveur avec mise à l'échelle à la demande
- Modélisation flexible (sans schéma)
- Pas de dépendance aux migrations ou aux ORM
- Transactions conformes ACID
- Prend en charge les relations et les données normalisées
- Fonctionne avec les backends sans serveur et traditionnels
Alors maintenant que nous avons une liste des incontournables, nous pouvons réellement évaluer certaines options. Il n'est peut-être pas important que la nouvelle solution cloue chaque cible ici. Il se peut simplement qu'il atteigne la bonne combinaison de fonctionnalités là où les solutions existantes ne se chevauchent pas. Par exemple, si vous vouliez une flexibilité sans schéma , vous deviez abandonner les transactions ACID. (Ce fut le cas pendant longtemps avec les bases de données.)
Un exemple d'un autre domaine est que si vous souhaitez avoir une validation dactylographiée dans votre rendu de modèle, vous devez utiliser TSX et React. Si vous optez pour des options comme Svelte ou Vue, vous pouvez l'avoir - partiellement mais pas complètement - via le rendu du modèle . Ainsi, une solution qui vous a donné l'empreinte et la vitesse minimes de Svelte avec la vérification du type au niveau du modèle de React et TypeScript pourrait être suffisante pour l'adoption même s'il manquait une autre fonctionnalité. L'équilibre entre les désirs et les besoins va changer d'un projet à l'autre. C'est à vous de déterminer où sera la valeur et de décider comment cocher les points les plus importants de votre analyse.
Nous pouvons maintenant examiner une solution et voir comment elle s'évalue par rapport à la solution souhaitée. Fauna est une solution de base de données sans serveur qui bénéficie d'une échelle à la demande avec une distribution mondiale. Il s'agit d'une base de données sans schéma, qui fournit des transactions conformes à ACID et prend en charge les requêtes relationnelles et les données normalisées en tant que fonctionnalité. Fauna peut être utilisé aussi bien dans des applications sans serveur que dans des backends plus traditionnels et fournit des bibliothèques pour travailler avec les langages les plus populaires. Fauna fournit en outre des flux de travail pour l'authentification ainsi qu'une multilocation simple et efficace. Ce sont deux caractéristiques supplémentaires solides à noter car elles pourraient être les facteurs déterminants lorsque deux technologies sont nez à nez dans notre évaluation.
Maintenant, après avoir examiné toutes ces forces, nous devons évaluer les faiblesses . L'un d'entre eux est Fauna n'est pas open source. Cela signifie qu'il existe des risques de dépendance vis-à-vis d'un fournisseur ou de changements commerciaux et tarifaires qui sont hors de votre contrôle. L'open source peut être agréable car vous pouvez souvent mettre la technologie à la disposition d'un autre fournisseur si vous le souhaitez ou potentiellement contribuer au projet.
Dans le monde des agences, le verrouillage du fournisseur est quelque chose que nous devons surveiller de près, pas tant à cause du prix, mais la viabilité de l'activité sous-jacente est importante. Devoir changer de bases de données sur un projet en cours de développement ou vieux de quelques années est à la fois désastreux pour une agence. Souvent, un client devra payer la facture pour cela, ce qui n'est pas une conversation agréable à avoir.
Une autre faiblesse qui nous préoccupait est l'accent mis sur JAMstack . Bien que nous aimions JAMstack, nous nous retrouvons plus souvent à créer une grande variété d'applications Web traditionnelles. Nous voulons nous assurer que Fauna continue de prendre en charge ces cas d'utilisation. Nous avons eu une mauvaise expérience dans le passé avec un fournisseur d'hébergement qui a tout fait sur JAMstack et nous avons fini par devoir migrer un assez grand nombre de sites du service, nous voulons donc être sûrs que tous les cas d'utilisation continueront à voir soutien solide. À l'heure actuelle, cela semble être le cas, et les flux de travail sans serveur fournis par Fauna peuvent en fait très bien compléter une application plus traditionnelle.

À ce stade, nous avons fait nos recherches fonctionnelles et la seule façon de savoir si cette solution est viable est de descendre et d'écrire du code. Dans un environnement d'agence, nous ne pouvons pas simplement prendre des semaines sur le calendrier pour que les gens évaluent plusieurs solutions. C'est la nature du travail dans une agence par rapport à un environnement SaaS . Dans ce dernier cas, vous pouvez créer quelques prototypes pour essayer de trouver la bonne solution. Dans une agence, vous aurez quelques jours pour expérimenter, ou peut-être l'opportunité de faire un projet parallèle, mais dans l'ensemble, nous devons vraiment réduire cela à une ou deux technologies à ce stade, puis mettre les doigts sur le clavier.
L'expérience développeur
Juger le côté expérience d'une nouvelle technologie est peut-être le plus difficile des trois domaines car il est par nature subjectif. Il y aura aussi des variations d'une équipe à l'autre. Par exemple, si vous demandez à un programmeur Ruby, à un programmeur Python et à un programmeur Rust de donner leur avis sur différentes fonctionnalités du langage, vous obtiendrez un éventail de réponses. Ainsi, avant de commencer à juger une expérience, vous devez d'abord décider quelles caractéristiques sont les plus importantes pour votre équipe dans son ensemble.

Pour les agences, je pense qu'il y a deux goulots d'étranglement majeurs en ce qui concerne l'expérience des développeurs :
- Temps d'installation et configuration
- Apprentissage
Ces deux éléments affectent la viabilité à long terme d'une nouvelle technologie de différentes manières. Garder des équipes de développeurs temporaires synchronisées dans une agence peut être un casse-tête. Les outils qui ont beaucoup de coûts d'installation et de configuration initiaux sont notoirement difficiles à utiliser pour les agences. L'autre est la facilité d'apprentissage et la facilité avec laquelle les développeurs peuvent développer la nouvelle technologie. Nous les aborderons plus en détail et expliquerons pourquoi ils constituent ma base lorsque je commence à évaluer l'expérience des développeurs.
Temps d'installation et configuration
Les agences ont tendance à avoir peu de patience et de temps pour la configuration. Pour moi, j'aime les outils pointus, avec des conceptions ergonomiques, qui me permettent de me mettre rapidement au travail sur le problème métier en cours. Il y a plusieurs années, j'ai travaillé pour une entreprise SaaS qui avait une configuration locale complexe qui impliquait de nombreuses configurations et échouait souvent à des points aléatoires du processus de configuration. Une fois que vous avez été configuré, la sagesse conventionnelle était de ne rien toucher et d'espérer que vous n'étiez pas dans l'entreprise assez longtemps pour devoir le configurer à nouveau sur une autre machine. J'ai rencontré des développeurs qui ont beaucoup aimé configurer chaque petit élément de leur configuration emacs et qui n'ont pas pensé à perdre quelques heures dans un environnement local défectueux.
En général, j'ai constaté que les ingénieurs d'agence méprisaient ce genre de choses dans leur travail quotidien. À la maison, ils peuvent bricoler avec ces types d'outils, mais lorsqu'ils ont un délai, rien ne vaut des outils qui fonctionnent. Dans les agences, nous préférons généralement apprendre quelques nouvelles choses qui fonctionnent bien, de manière cohérente, plutôt que de pouvoir configurer chaque élément technologique selon les goûts personnels de chacun.
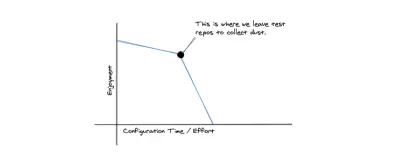
Une chose qui est bien dans le fait de travailler avec une plate-forme cloud qui n'est pas open source, c'est qu'elle possède entièrement l'installation et la configuration. Bien qu'un inconvénient soit le verrouillage du fournisseur, l'avantage est que ces types d'outils font souvent ce pour quoi ils sont configurés. Il n'y a pas de bricolage avec les environnements, pas de configurations locales et pas de pipelines de déploiement. Nous avons aussi moins de décisions à prendre.
C'est intrinsèquement l' attrait du serverless . Le sans serveur en général dépend davantage des services et des outils propriétaires. Nous échangeons la flexibilité de l'hébergement et du code source afin de gagner en stabilité et de nous concentrer sur les problèmes du domaine métier que nous essayons de résoudre. Je noterai également que lorsque j'évalue une technologie et que j'ai le sentiment qu'il pourrait être nécessaire de migrer hors d'une plate-forme, c'est souvent un mauvais signe au départ.
Dans le cas des bases de données, la configuration set-it-and-forget-it est idéale lorsque vous travaillez avec des clients où les besoins de la base de données peuvent être ambigus. Nous avons eu des clients qui n'étaient pas sûrs de la popularité d'un programme ou d'une application. Nous avons eu des clients que nous n'avions techniquement pas pris en charge de cette manière, mais nous avons néanmoins appelé dans la panique lorsqu'ils avaient besoin de nous pour faire évoluer leur base de données ou leur application.
Dans le passé, nous devions toujours prendre en compte des éléments tels que la redondance, la réplication des données et le partage à grande échelle lorsque nous élaborions nos cahiers des charges. Essayer de couvrir chaque scénario tout en étant prêt à déplacer un volume d'affaires complet au cas où une base de données ne serait pas mise à l'échelle est une situation impossible à préparer. En fin de compte, une base de données sans serveur facilite ces choses.
Vous ne perdez jamais de données , vous n'avez pas à vous soucier de la réplication des données sur un réseau, ni de l'approvisionnement d'une base de données et d'une machine plus grandes pour les exécuter - tout fonctionne. Nous nous concentrons uniquement sur le problème métier en question, l'architecture technique et l'échelle seront toujours gérées. Pour notre équipe de développement, c'est une énorme victoire ; nous avons moins d'exercices d'incendie, de surveillance et de changement de contexte.
Apprentissage
Il existe une mesure classique de l'expérience utilisateur, qui, je pense, s'applique à l'expérience des développeurs, qui est la capacité d'apprentissage . Lors de la conception d'une certaine expérience utilisateur, nous ne nous contentons pas de regarder si quelque chose est apparent ou facile du premier coup. La technologie est simplement plus complexe que cela la plupart du temps. Ce qui est important, c'est la facilité avec laquelle un nouvel utilisateur peut apprendre et maîtriser le système.
En ce qui concerne les outils techniques, en particulier les puissants, ce serait beaucoup demander qu'il n'y ait aucune courbe d'apprentissage . Habituellement, ce que nous recherchons, c'est qu'il y ait une excellente documentation pour les cas d'utilisation les plus courants et que ces connaissances soient facilement et rapidement exploitées dans un projet. Perdre un peu de temps pour apprendre sur le premier projet avec une technologie, c'est bien. Après cela, nous devrions voir l'efficacité s'améliorer à chaque projet successif.
Ce que je recherche spécifiquement ici, c'est comment nous pouvons tirer parti des connaissances et des modèles que nous connaissons déjà pour aider à raccourcir la courbe d'apprentissage. Par exemple, avec les bases de données sans serveur, il n'y aura pratiquement aucune courbe d'apprentissage pour les configurer dans le cloud et les déployer. En ce qui concerne l'utilisation de la base de données, l'une des choses que j'aime, c'est quand nous pouvons encore tirer parti de toutes les années de maîtrise des bases de données relationnelles et appliquer ces apprentissages à notre nouvelle configuration. Dans ce cas, nous apprenons à utiliser un nouvel outil, mais cela ne nous oblige pas à repenser notre modélisation des données à partir de zéro.

À titre d'exemple, lors de l'utilisation de Firebase, MongoDB et DynamoDB, nous avons constaté que cela encourageait les données dénormalisées plutôt que d'essayer de joindre différents documents. Cela a créé beaucoup de frictions cognitives lors de la modélisation de nos données, car nous devions penser en termes de modèles d'accès plutôt qu'en termes d'entités commerciales. De l'autre côté de cette faune nous a permis de tirer parti de nos années de connaissances relationnelles ainsi que de notre préférence pour les données normalisées en matière de modélisation des données.
La partie à laquelle nous avons dû nous habituer consistait à utiliser des index et un nouveau langage de requête pour rassembler ces éléments. En général, j'ai constaté que la préservation des concepts qui font partie de paradigmes de conception logicielle plus larges facilite la tâche de l'équipe de développement en termes d'apprentissage et d'adoption.
Comment savons-nous qu'une équipe adopte et aime une nouvelle technologie ? Je pense que le meilleur signe est lorsque nous nous demandons si cet outil s'intègre à ladite nouvelle technologie ? Lorsqu'une nouvelle technologie atteint un niveau de désirabilité et de plaisir que l'équipe recherche des moyens de l'intégrer à d'autres projets, c'est un bon signe que vous avez un gagnant.
Les affaires
Dans cette section, nous devons examiner comment une nouvelle technologie répond aux besoins de notre entreprise . Celles-ci incluent des questions telles que :
- Avec quelle facilité peut-il être tarifé et intégré dans nos plans de support ?
- Pouvons-nous le transférer facilement aux clients ?
- Les clients peuvent-ils être intégrés à cet outil si nécessaire ?
- Combien de temps cet outil permet-il réellement de gagner, le cas échéant ?
La montée en puissance du serverless en tant que paradigme convient bien aux agences. Quand on parle de bases de données et de DevOps, le besoin de spécialistes dans ces domaines au sein des agences est limité. Souvent, nous transmettons un projet lorsque nous en avons terminé ou le soutenons dans une capacité limitée à long terme. Nous avons tendance à privilégier les ingénieurs full-stack, car ces besoins dépassent largement les besoins DevOps. Si nous embauchions un ingénieur DevOps, il passerait probablement quelques heures à déployer un projet et de nombreuses autres heures à attendre un incendie.
À cet égard, nous avons toujours des sous-traitants DevOps prêts, mais nous ne dotons pas ces postes à plein temps. Cela signifie que nous ne pouvons pas compter sur un ingénieur DevOps pour être prêt à intervenir en cas de problème inattendu. Pour nous, nous savons que nous pouvons obtenir de meilleurs tarifs d'hébergement en allant directement à AWS, mais nous savons également qu'en utilisant Heroku, nous pouvons compter sur notre personnel existant pour déboguer la plupart des problèmes. À moins que nous ayons un client que nous devons prendre en charge à long terme avec des besoins backend spécifiques, nous aimons utiliser par défaut les plates-formes gérées en tant que service.
Les bases de données ne font pas exception. Nous aimons nous appuyer sur des services comme Mongo Atlas ou Heroku Postgres pour rendre ce processus aussi simple que possible. Alors que nous commencions à voir de plus en plus de notre pile se diriger vers des outils sans serveur comme Vercel, Netlify ou AWS Lambda, nos besoins en matière de base de données ont dû évoluer avec cela. Les bases de données sans serveur telles que Firebase, DynamoDB et Fauna sont excellentes car elles s'intègrent bien aux applications sans serveur, mais libèrent également complètement notre entreprise du provisionnement et de la mise à l'échelle.
Ces solutions fonctionnent également bien pour les applications plus traditionnelles, où nous n'avons pas d'application sans serveur, mais nous pouvons toujours tirer parti de l'efficacité sans serveur au niveau de la base de données. En tant qu'entreprise, il est plus productif pour nous d'apprendre une base de données unique qui peut s'appliquer aux deux mondes que de changer de contexte. Ceci est similaire à notre décision d'adopter Node et JavaScript isomorphe (et TypeScript).
L'un des inconvénients que nous avons trouvés avec le sans serveur a été de proposer des prix pour les clients pour lesquels nous gérons ces services. Dans une architecture plus traditionnelle, les niveaux de taux forfaitaires permettent de les traduire très facilement en un taux pour les clients dont les circonstances prévisibles entraînent des augmentations et des dépassements. En ce qui concerne le sans serveur, cela peut être ambigu. Les gens de la finance n'aiment généralement pas entendre des choses comme nous facturons 1/10e de centime pour chaque lecture au-delà d'un million, et ainsi de suite.
C'est difficile à traduire en un nombre fixe, même pour les ingénieurs, car nous construisons souvent des applications dont nous ne sommes pas certains de l'utilisation qui en sera faite . Nous devons souvent créer nous-mêmes des niveaux, mais les nombreuses variables qui entrent dans le calcul du coût d'un lambda peuvent être difficiles à comprendre. En fin de compte, pour un produit SaaS, ces modèles de tarification par répartition sont excellents, mais pour les agences, les comptables préfèrent des chiffres plus concrets et prévisibles.
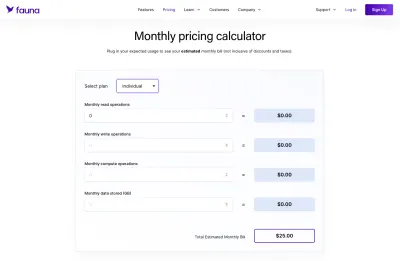
En ce qui concerne Fauna, c'était nettement plus ambigu à comprendre que de dire une base de données MySQL standard qui avait un hébergement forfaitaire pour une quantité d'espace définie. L'avantage était que Fauna fournit une belle calculatrice que nous avons pu utiliser pour mettre en place nos propres systèmes de tarification.
Un autre aspect difficile du sans serveur peut être que bon nombre de ces fournisseurs ne permettent pas une ventilation facile de chaque application hébergée. Par exemple, la plate-forme Heroku rend cela assez facile en créant de nouveaux pipelines et équipes. Nous pouvons même entrer la carte de crédit d'un client pour lui au cas où il ne souhaite pas utiliser nos plans d'hébergement. Tout cela peut également être fait dans le même tableau de bord, nous n'avons donc pas eu besoin de créer plusieurs connexions.
En ce qui concerne les autres outils sans serveur, cela était beaucoup plus difficile. Lors de l'évaluation des bases de données sans serveur, Firebase prend en charge le fractionnement des paiements par projet . Dans le cas de Fauna ou de DynamoDB, ce n'est pas possible, nous devons donc faire du travail pour surveiller l'utilisation dans leur tableau de bord, et si le client veut quitter notre service, nous devrons transférer la base de données sur son propre compte.
En fin de compte, les outils sans serveur offrent d'excellentes opportunités commerciales en termes d'économies de coûts, de gestion et d'efficacité des processus. Cependant, ils s'avèrent souvent difficiles pour les agences en matière de tarification et de gestion des comptes. C'est un domaine où nous avons dû tirer parti des calculateurs de coûts pour créer nos propres niveaux de tarification prévisibles ou configurer les clients avec leurs propres comptes afin qu'ils puissent effectuer les paiements directement.
Conclusion
Il peut être difficile d'adopter une nouvelle technologie en tant qu'agence. Bien que nous soyons dans une position unique pour travailler avec de nouveaux projets entièrement nouveaux qui offrent des opportunités pour les nouvelles technologies, nous devons également tenir compte de l'investissement à long terme de ceux-ci. Comment vont-ils performer ? Nos employés seront-ils productifs et apprécieront-ils de les utiliser ? Can we incorporate them into our business offering?
You need to have a firm grasp of where you have been before you figure out where you want to go technologically. When evaluating a new tool or platform it's important to think of what you have tried in the past and figure out what is most important to you and your team. We took a look at the concept of a serverless database and passed it through our three lenses – the technology, the experience, and the business. We were left with some pros and cons and had to strike the right balance.
After we evaluated serverless databases, we decided to adopt Fauna over the alternatives. We felt the technology was robust and ticked all of our boxes for our technology filter. When it came to the experience, virtually zero configuration and being able to leverage our existing knowledge of relational data modeling made this a winner with the development team. On the business side serverless provides clear wins to efficiency and productivity , however on the pricing side and account management there are still some difficulties. We decided the benefits in the other areas outweighed the pricing difficulties.
Overall, we highly recommend giving Fauna a shot on one of your next projects. It has become one of our favorite tools and our go-to database of choice for smaller serverless projects and even more traditional large backend applications. The community is very helpful, the learning curve is gentle, and we believe you'll find levels of productivity you hadn't realized before with existing databases.
When we first use a new technology on a project, we start with something either internal or on the smaller side. We try to mitigate the risk by wading into the water rather than leaping into the deep end by trying it on a large and complex project. As the team builds understanding of the technology, we start using it for larger projects but only after we feel comfortable that it has handled similar use cases well for us in the past.
In general, it can take up to a year for a technology to become a ubiquitous part of most projects so it is important to be patient. Agencies have a lot of flexibility but also are required to ensure stability in the products they produce, we don't get a second chance. Always be experimenting and pushing your agency to adopt new technologies, but do so carefully and you will reap the benefits.
Lectures complémentaires
- Serverless Database Wishlist - What's Missing Today
- Relational NoSQL: Yes, that is an option
- Concerning toolkits - A great piece about the merits of zero configuration on developer experience