
Construire un détecteur de pièce pour les appareils IoT sur Mac OS
Publié: 2022-03-10Savoir dans quelle pièce vous vous trouvez permet diverses applications IoT, de l'allumage de la lumière au changement de chaînes de télévision. Alors, comment pouvons-nous détecter le moment où vous et votre téléphone êtes dans la cuisine, la chambre ou le salon ? Avec le matériel de base d'aujourd'hui, il existe une myriade de possibilités :
Une solution consiste à équiper chaque pièce d'un appareil bluetooth . Une fois que votre téléphone est à portée d'un appareil Bluetooth, votre téléphone saura de quelle pièce il s'agit, en fonction de l'appareil Bluetooth. Cependant, la maintenance d'une gamme d'appareils Bluetooth représente une surcharge importante, du remplacement des batteries au remplacement des appareils dysfonctionnels. De plus, la proximité de l'appareil Bluetooth n'est pas toujours la solution : si vous êtes dans le salon, près du mur partagé avec la cuisine, vos appareils de cuisine ne devraient pas commencer à produire de la nourriture.
Une autre solution, bien que peu pratique, consiste à utiliser le GPS . Cependant, gardez à l'esprit que le GPS fonctionne mal à l'intérieur où la multitude de murs, d'autres signaux et d'autres obstacles font des ravages sur la précision du GPS.
Notre approche consiste plutôt à tirer parti de tous les réseaux Wi-Fi à portée, même ceux auxquels votre téléphone n'est pas connecté. Voici comment : considérez la force du WiFi A dans la cuisine ; disons que c'est 5. Puisqu'il y a un mur entre la cuisine et la chambre, nous pouvons raisonnablement nous attendre à ce que la puissance du WiFi A dans la chambre soit différente ; disons que c'est 2. Nous pouvons exploiter cette différence pour prédire dans quelle pièce nous nous trouvons. De plus : le réseau WiFi B de notre voisin ne peut être détecté que depuis le salon mais est effectivement invisible depuis la cuisine. Cela rend la prédiction encore plus facile. En somme, la liste de tous les WiFi à portée nous donne de nombreuses informations.
Cette méthode présente les avantages indéniables de :
- ne nécessitant pas plus de matériel ;
- s'appuyer sur des signaux plus stables comme le WiFi ;
- fonctionne bien là où d'autres techniques telles que le GPS sont faibles.
Plus il y a de murs, mieux c'est, car plus les forces du réseau WiFi sont disparates, plus il est facile de classer les pièces. Vous allez créer une application de bureau simple qui collecte des données, apprend à partir des données et prédit dans quelle pièce vous vous trouvez à un moment donné.
Lectures complémentaires sur SmashingMag :
- L'essor de l'interface utilisateur conversationnelle intelligente
- Applications de l'apprentissage automatique pour les concepteurs
- Comment prototyper des expériences IoT : construire le matériel
- Concevoir pour l'Internet des objets émotionnels
Conditions préalables
Pour ce tutoriel, vous aurez besoin d'un Mac OSX. Alors que le code peut s'appliquer à n'importe quelle plate-forme, nous fournirons uniquement des instructions d'installation de dépendance pour Mac.
- Mac OS X
- Homebrew, un gestionnaire de paquets pour Mac OSX. Pour installer, copiez-collez la commande sur brew.sh
- Installation de NodeJS 10.8.0+ et npm
- Installation de Python 3.6+ et pip. Voir les 3 premières sections de "Comment installer virtualenv, installer avec pip et gérer les packages"
Étape 0 : Configuration de l'environnement de travail
Votre application de bureau sera écrite en NodeJS. Cependant, pour tirer parti de bibliothèques de calcul plus efficaces comme numpy , le code d'entraînement et de prédiction sera écrit en Python. Pour commencer, nous allons configurer vos environnements et installer les dépendances. Créez un nouveau répertoire pour héberger votre projet.
mkdir ~/riotNaviguez dans le répertoire.
cd ~/riotUtilisez pip pour installer le gestionnaire d'environnement virtuel par défaut de Python.
sudo pip install virtualenv Créez un environnement virtuel Python3.6 nommé riot .
virtualenv riot --python=python3.6Activez l'environnement virtuel.
source riot/bin/activate Votre invite est maintenant précédée de (riot) . Cela indique que nous sommes entrés avec succès dans l'environnement virtuel. Installez les packages suivants à l'aide de pip :
-
numpy: une bibliothèque d'algèbre linéaire efficace -
scipy: une bibliothèque de calcul scientifique qui implémente des modèles d'apprentissage automatique populaires
pip install numpy==1.14.3 scipy ==1.1.0Avec la configuration du répertoire de travail, nous allons commencer avec une application de bureau qui enregistre tous les réseaux WiFi à portée. Ces enregistrements constitueront des données d'entraînement pour votre modèle d'apprentissage automatique. Une fois que nous aurons les données en main, vous écrirez un classificateur des moindres carrés, entraîné sur les signaux WiFi collectés précédemment. Enfin, nous utiliserons le modèle des moindres carrés pour prédire la pièce dans laquelle vous vous trouvez, en fonction des réseaux WiFi à portée.
Étape 1 : Application de bureau initiale
Dans cette étape, nous allons créer une nouvelle application de bureau à l'aide d'Electron JS. Pour commencer, nous allons plutôt utiliser le gestionnaire de paquets Node npm et un utilitaire de téléchargement wget .
brew install npm wgetPour commencer, nous allons créer un nouveau projet Node.
npm init Cela vous demande le nom du package, puis le numéro de version. Appuyez sur ENTER pour accepter le nom par défaut de riot et la version par défaut de 1.0.0 .
package name: (riot) version: (1.0.0) Cela vous invite à une description du projet. Ajoutez toute description non vide que vous souhaitez. Ci-dessous, la description est room detector
description: room detector Cela vous invite à indiquer le point d'entrée ou le fichier principal à partir duquel exécuter le projet. Entrez app.js .
entry point: (index.js) app.js Cela vous invite à entrer la test command et le git repository . Appuyez sur ENTER pour ignorer ces champs pour l'instant.
test command: git repository: Cela vous invite à saisir les mots- keywords et l' author . Remplissez toutes les valeurs que vous souhaitez. Ci-dessous, nous utilisons iot , wifi pour les mots-clés et John Doe pour l'auteur.
keywords: iot,wifi author: John Doe Cela vous demande la licence. Appuyez sur ENTER pour accepter la valeur par défaut de ISC .
license: (ISC) À ce stade, npm vous proposera un résumé des informations jusqu'à présent. Votre sortie devrait ressembler à ce qui suit.
{ "name": "riot", "version": "1.0.0", "description": "room detector", "main": "app.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [ "iot", "wifi" ], "author": "John Doe", "license": "ISC" } Appuyez sur ENTER pour accepter. npm produit ensuite un package.json . Listez tous les fichiers à revérifier.
lsCela produira le seul fichier de ce répertoire, ainsi que le dossier de l'environnement virtuel.
package.json riotInstallez les dépendances NodeJS pour notre projet.
npm install electron --global # makes electron binary accessible globally npm install node-wifi --save Commencez avec main.js depuis Electron Quick Start, en téléchargeant le fichier, en utilisant ce qui suit. L'argument -O suivant renomme main.js en app.js .
wget https://raw.githubusercontent.com/electron/electron-quick-start/master/main.js -O app.js Ouvrez app.js dans nano ou votre éditeur de texte préféré.
nano app.js À la ligne 12, remplacez index.html par static/index.html , car nous allons créer un répertoire static pour contenir tous les modèles HTML.
function createWindow () { // Create the browser window. win = new BrowserWindow({width: 1200, height: 800}) // and load the index.html of the app. win.loadFile('static/index.html') // Open the DevTools. Enregistrez vos modifications et quittez l'éditeur. Votre fichier doit correspondre au code source du fichier app.js Créez maintenant un nouveau répertoire pour héberger nos modèles HTML.
mkdir staticTéléchargez une feuille de style créée pour ce projet.
wget https://raw.githubusercontent.com/alvinwan/riot/master/static/style.css?token=AB-ObfDtD46ANlqrObDanckTQJ2Q1Pyuks5bf79PwA%3D%3D -O static/style.css Ouvrez static/index.html dans nano ou votre éditeur de texte préféré. Commencez avec la structure HTML standard.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> </head> <body> <main> </main> </body> </html>Juste après le titre, liez la police Montserrat liée par Google Fonts et la feuille de style.
<title>Riot | Room Detector</title> <!-- start new code --> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> <!-- end new code --> </head> Entre les balises main , ajoutez un emplacement pour le nom de pièce prévu.
<main> <!-- start new code --> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> <!-- end new code --> </main>Votre script doit maintenant correspondre exactement à ce qui suit. Quittez l'éditeur.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> </main> </body> </html>Maintenant, modifiez le fichier de package pour qu'il contienne une commande de démarrage.
nano package.json Juste après la ligne 7, ajoutez une commande start dont le pseudonyme est electron . . Assurez-vous d'ajouter une virgule à la fin de la ligne précédente.
"scripts": { "test": "echo \"Error: no test specified\" && exit 1", "start": "electron ." }, Sauvegarder et quitter. Vous êtes maintenant prêt à lancer votre application de bureau dans Electron JS. Utilisez npm pour lancer votre application.
npm startVotre application de bureau doit correspondre aux éléments suivants.

Ceci termine votre application de bureau de départ. Pour quitter, revenez à votre terminal et CTRL + C. Dans l'étape suivante, nous enregistrerons les réseaux wifi et rendrons l'utilitaire d'enregistrement accessible via l'interface utilisateur de l'application de bureau.
Étape 2 : Enregistrer les réseaux WiFi
Dans cette étape, vous allez écrire un script NodeJS qui enregistre la force et la fréquence de tous les réseaux wifi à portée. Créez un répertoire pour vos scripts.
mkdir scripts Ouvrez scripts/observe.js dans nano ou votre éditeur de texte préféré.
nano scripts/observe.jsImportez un utilitaire Wi-Fi NodeJS et l'objet système de fichiers.
var wifi = require('node-wifi'); var fs = require('fs'); Définissez une fonction d' record qui accepte un gestionnaire d'achèvement.
/** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { } Dans la nouvelle fonction, initialisez l'utilitaire wifi. Définissez iface sur null pour initialiser une interface wifi aléatoire, car cette valeur n'est actuellement pas pertinente.
function record(n, completion, hook) { wifi.init({ iface : null }); }Définissez un tableau pour contenir vos échantillons. Les échantillons sont des données d'entraînement que nous utiliserons pour notre modèle. Les exemples de ce didacticiel particulier sont des listes de réseaux wifi à portée et leurs forces, fréquences, noms, etc. associés.
function record(n, completion, hook) { ... samples = [] } Définissez une fonction récursive startScan , qui lancera de manière asynchrone des scans wifi. Une fois terminée, l'analyse Wi-Fi asynchrone appellera alors de manière récursive startScan .
function record(n, completion, hook) { ... function startScan(i) { wifi.scan(function(err, networks) { }); } startScan(n); } Dans le rappel wifi.scan , vérifiez les erreurs ou les listes vides de réseaux et redémarrez l'analyse si c'est le cas.
wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } });Ajoutez le cas de base de la fonction récursive, qui appelle le gestionnaire d'achèvement.
wifi.scan(function(err, networks) { ... if (i <= 0) { return completion({samples: samples}); } });Générez une mise à jour de progression, ajoutez-la à la liste des échantillons et effectuez l'appel récursif.
wifi.scan(function(err, networks) { ... hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); À la fin de votre fichier, appelez la fonction d' record avec un rappel qui enregistre les échantillons dans un fichier sur disque.
function record(completion) { ... } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + (21-i) + " with " + networks.length + " networks"); }) } cli();Vérifiez que votre fichier correspond aux éléments suivants :
var wifi = require('node-wifi'); var fs = require('fs'); /** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { wifi.init({ iface : null // network interface, choose a random wifi interface if set to null }); samples = [] function startScan(i) { wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } if (i <= 0) { return completion({samples: samples}); } hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); } startScan(n); } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks"); }) } cli();Sauvegarder et quitter. Exécutez le script.
node scripts/observe.jsVotre sortie correspondra à ce qui suit, avec un nombre variable de réseaux.
* [INFO] Collected sample 1 with 39 networks Examinez les échantillons qui viennent d'être prélevés. Dirigez vers json_pp pour imprimer joliment le JSON et dirigez vers head pour afficher les 16 premières lignes.
cat samples.json | json_pp | head -16L'exemple ci-dessous est un exemple de sortie pour un réseau 2,4 GHz.
{ "samples": [ [ { "mac": "64:0f:28:79:9a:29", "bssid": "64:0f:28:79:9a:29", "ssid": "SMASHINGMAGAZINEROCKS", "channel": 4, "frequency": 2427, "signal_level": "-91", "security": "WPA WPA2", "security_flags": [ "(PSK/AES,TKIP/TKIP)", "(PSK/AES,TKIP/TKIP)" ] },Ceci conclut votre script d'analyse Wi-Fi NodeJS. Cela nous permet de visualiser tous les réseaux WiFi à portée. À l'étape suivante, vous rendrez ce script accessible à partir de l'application de bureau.
Étape 3 : Connectez le script de numérisation à l'application de bureau
Dans cette étape, vous allez d'abord ajouter un bouton à l'application de bureau pour déclencher le script. Ensuite, vous mettrez à jour l'interface utilisateur de l'application de bureau avec la progression du script.
Ouvrez static/index.html .
nano static/index.htmlInsérez le bouton "Ajouter", comme indiqué ci-dessous.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <div class="buttons"> <a href="add.html" class="button">Add new room</a> </div> <!-- end new code --> </main> Sauvegarder et quitter. Ouvrez static/add.html .
nano static/add.htmlCollez le contenu suivant.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Add New Room</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <h1 class="title">0</h1> <p class="subtitle">of <span>20</span> samples needed. Feel free to move around the room.</p> <input type="text" class="text-field" placeholder="(room name)"> <div class="buttons"> <a href="#" class="button">Start recording</a> <a href="index.html" class="button light">Cancel</a> </div> <p class="text"></p> </main> <script> require('../scripts/observe.js') </script> </body> </html> Sauvegarder et quitter. Rouvrez scripts/observe.js .
nano scripts/observe.js Sous la fonction cli , définissez une nouvelle fonction ui .
function cli() { ... } // start new code function ui() { } // end new code cli();Mettez à jour l'état de l'application de bureau pour indiquer que la fonction a commencé à s'exécuter.
function ui() { var room_name = document.querySelector('#add-room-name').value; var status = document.querySelector('#add-status'); var number = document.querySelector('#add-title'); status.style.display = "block" status.innerHTML = "Listening for wifi..." }Partitionnez les données en ensembles de données de formation et de validation.
function ui() { ... function completion(data) { train_data = {samples: data['samples'].slice(0, 15)} test_data = {samples: data['samples'].slice(15)} var train_json = JSON.stringify(train_data); var test_json = JSON.stringify(test_data); } } Toujours dans le cadre du rappel d' completion , écrivez les deux ensembles de données sur le disque.
function ui() { ... function completion(data) { ... fs.writeFile('data/' + room_name + '_train.json', train_json, 'utf8', function() {}); fs.writeFile('data/' + room_name + '_test.json', test_json, 'utf8', function() {}); console.log(" * [INFO] Done") status.innerHTML = "Done." } } Appelez record avec les rappels appropriés pour enregistrer 20 échantillons et sauvegarder les échantillons sur le disque.
function ui() { ... function completion(data) { ... } record(20, completion, function(i, networks) { number.innerHTML = i console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks") }) } Enfin, appelez les fonctions cli et ui , le cas échéant. Commencez par supprimer le cli(); appeler en bas du fichier.
function ui() { ... } cli(); // remove me Vérifiez si l'objet document est globalement accessible. Sinon, le script est exécuté à partir de la ligne de commande. Dans ce cas, appelez la fonction cli . Si c'est le cas, le script est chargé depuis l'application de bureau. Dans ce cas, liez l'écouteur de clic à la fonction ui .
if (typeof document == 'undefined') { cli(); } else { document.querySelector('#start-recording').addEventListener('click', ui) }Sauvegarder et quitter. Créer un répertoire pour contenir nos données.
mkdir dataLancez l'application de bureau.
npm startVous verrez la page d'accueil suivante. Cliquez sur "Ajouter une salle".
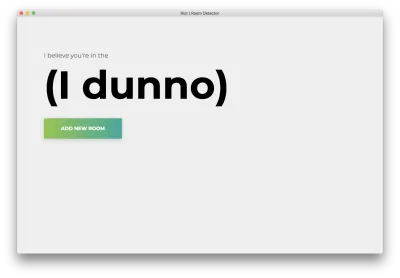
Vous verrez le formulaire suivant. Tapez un nom pour la salle. Rappelez-vous ce nom, car nous l'utiliserons plus tard. Notre exemple sera la bedroom .
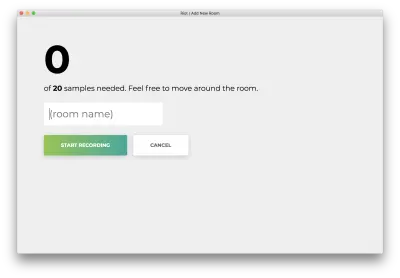
Cliquez sur "Démarrer l'enregistrement" et vous verrez le statut suivant "Écouter le wifi…".

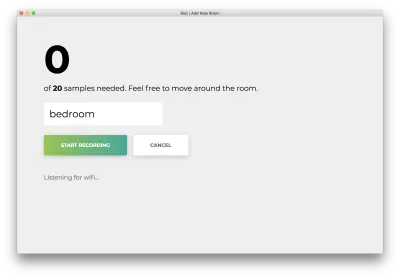
Une fois les 20 échantillons enregistrés, votre application correspondra aux éléments suivants. Le statut indiquera "Terminé".
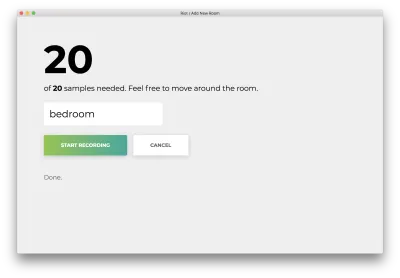
Cliquez sur le mauvais nom "Annuler" pour revenir à la page d'accueil, qui correspond à ce qui suit.
Nous pouvons maintenant analyser les réseaux wifi à partir de l'interface utilisateur du bureau, ce qui enregistrera tous les échantillons enregistrés dans des fichiers sur le disque. Ensuite, nous formerons un algorithme d'apprentissage automatique prêt à l'emploi, basé sur les moindres carrés, sur les données que vous avez collectées.
Étape 4 : Écrire un script de formation Python
Dans cette étape, nous allons écrire un script de formation en Python. Créez un répertoire pour vos utilitaires de formation.
mkdir model Ouvrez model/train.py
nano model/train.py En haut de votre fichier, importez la bibliothèque de calcul numpy et scipy pour son modèle des moindres carrés.
import numpy as np from scipy.linalg import lstsq import json import sysLes trois utilitaires suivants géreront le chargement et la configuration des données à partir des fichiers sur le disque. Commencez par ajouter une fonction utilitaire qui aplatit les listes imbriquées. Vous l'utiliserez pour aplatir une liste de liste d'échantillons.
import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) Ajoutez un deuxième utilitaire qui charge des échantillons à partir des fichiers spécifiés. Cette méthode élimine le fait que les échantillons sont répartis sur plusieurs fichiers, renvoyant un seul générateur pour tous les échantillons. Pour chacun des échantillons, le label est l'index du fichier. Par exemple, si vous appelez get_all_samples('a.json', 'b.json') , tous les échantillons dans a.json auront l'étiquette 0 et tous les échantillons dans b.json auront l'étiquette 1.
def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, labelEnsuite, ajoutez un utilitaire qui encode les échantillons à l'aide d'un modèle de sac de mots. Voici un exemple : Supposons que nous recueillons deux échantillons.
- réseau wifi A à force 10 et réseau wifi B à force 15
- réseau wifi B à force 20 et réseau wifi C à force 25.
Cette fonction produira une liste de trois nombres pour chacun des échantillons : la première valeur est la force du réseau wifi A, la seconde pour le réseau B et la troisième pour C. En effet, le format est [A, B, C ].
- [10, 15, 0]
- [0, 20, 25]
def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [strengths[networks.index(network)] if network in networks else 0 for network in ordering] En utilisant les trois utilitaires ci-dessus, nous synthétisons une collection d'échantillons et leurs étiquettes. Rassemblez tous les échantillons et étiquettes à l'aide get_all_samples . Définissez un ordering de format cohérent pour encoder à chaud tous les échantillons, puis appliquez l'encodage à one_hot aux échantillons. Enfin, construisez les matrices de données et d'étiquettes X et Y respectivement.
def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, orderingCes fonctions complètent le pipeline de données. Ensuite, nous faisons abstraction de la prédiction et de l'évaluation du modèle. Commencez par définir la méthode de prédiction. La première fonction normalise les sorties de notre modèle, de sorte que la somme de toutes les valeurs totalise 1 et que toutes les valeurs soient non négatives ; cela garantit que la sortie est une distribution de probabilité valide. La seconde évalue le modèle.
def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1)Ensuite, évaluez la précision du modèle. La première ligne exécute la prédiction à l'aide du modèle. La seconde compte le nombre de fois que les valeurs prédites et vraies concordent, puis normalise par le nombre total d'échantillons.
def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy Ceci conclut nos utilitaires de prédiction et d'évaluation. Après ces utilitaires, définissez une fonction main qui collectera l'ensemble de données, l'entraînera et l'évaluera. Commencez par lire la liste des arguments depuis la ligne de commande sys.argv ; ce sont les salles à inclure dans la formation. Créez ensuite un ensemble de données volumineux à partir de toutes les pièces spécifiées.
def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering)Appliquez un encodage à chaud aux étiquettes. Un encodage à chaud est similaire au modèle de sac de mots ci-dessus ; nous utilisons cet encodage pour gérer les variables catégorielles. Disons que nous avons 3 étiquettes possibles. Au lieu d'étiqueter 1, 2 ou 3, nous étiquetons les données avec [1, 0, 0], [0, 1, 0] ou [0, 0, 1]. Pour ce didacticiel, nous épargnerons l'explication de l'importance de l'encodage à chaud. Entraînez le modèle et évaluez-le sur les ensembles d'apprentissage et de validation.
def main(): ... X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) test_accuracy = evaluate(X_test, Y_test, w)Imprimez les deux précisions et enregistrez le modèle sur le disque.
def main(): ... print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, test_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() À la fin du fichier, exécutez la fonction main .
if __name__ == '__main__': main()Sauvegarder et quitter. Vérifiez que votre fichier correspond aux éléments suivants :
import numpy as np from scipy.linalg import lstsq import json import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, label def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [int(strengths[networks.index(network)]) if network in networks else 0 for network in ordering] def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, ordering def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1) def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) validation_accuracy = evaluate(X_test, Y_test, w) print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, validation_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() if __name__ == '__main__': main() Sauvegarder et quitter. Rappelez-vous le nom de pièce utilisé ci-dessus lors de l'enregistrement des 20 échantillons. Utilisez ce nom au lieu de bedroom ci-dessous. Notre exemple est bedroom . Nous utilisons -W ignore pour ignorer les avertissements d'un bogue LAPACK.
python -W ignore model/train.py bedroomÉtant donné que nous n'avons collecté que des échantillons de formation pour une pièce, vous devriez voir 100 % de précisions de formation et de validation.
Train accuracy (100.0%), Validation accuracy (100.0%)Ensuite, nous allons lier ce script de formation à l'application de bureau.
Étape 5 : lier le script de train
Dans cette étape, nous recyclerons automatiquement le modèle chaque fois que l'utilisateur prélèvera un nouveau lot d'échantillons. Ouvrez scripts/observe.js .
nano scripts/observe.js Juste après l'importation fs , importez le générateur de processus enfant et les utilitaires.
var fs = require('fs'); // start new code const spawn = require("child_process").spawn; var utils = require('./utils.js'); Dans la fonction ui , ajoutez l'appel suivant pour retrain à la fin du gestionnaire d'achèvement.
function ui() { ... function completion() { ... retrain((data) => { var status = document.querySelector('#add-status'); accuracies = data.toString().split('\n')[0]; status.innerHTML = "Retraining succeeded: " + accuracies }); } ... } Après la fonction ui , ajoutez la fonction de retrain suivante. Cela génère un processus enfant qui exécutera le script python. Une fois terminé, le processus appelle un gestionnaire d'achèvement. En cas d'échec, il consignera le message d'erreur.
function ui() { .. } function retrain(completion) { var filenames = utils.get_filenames() const pythonProcess = spawn('python', ["./model/train.py"].concat(filenames)); pythonProcess.stdout.on('data', completion); pythonProcess.stderr.on('data', (data) => { console.log(" * [ERROR] " + data.toString()) }) } Sauvegarder et quitter. Ouvrez scripts/utils.js .
nano scripts/utils.js Ajoutez l'utilitaire suivant pour récupérer tous les ensembles de données dans data/ .
var fs = require('fs'); module.exports = { get_filenames: get_filenames } function get_filenames() { filenames = new Set([]); fs.readdirSync("data/").forEach(function(filename) { filenames.add(filename.replace('_train', '').replace('_test', '').replace('.json', '' )) }); filenames = Array.from(filenames.values()) filenames.sort(); filenames.splice(filenames.indexOf('.DS_Store'), 1) return filenames }Sauvegarder et quitter. Pour la conclusion de cette étape, déplacez-vous physiquement vers un nouvel emplacement. Idéalement, il devrait y avoir un mur entre votre emplacement d'origine et votre nouvel emplacement. Plus il y a de barrières, mieux votre application de bureau fonctionnera.
Encore une fois, exécutez votre application de bureau.
npm startComme précédemment, exécutez le script de formation. Cliquez sur "Ajouter une salle".
Tapez un nom de pièce différent de celui de votre première pièce. Nous utiliserons le living room .
Cliquez sur "Démarrer l'enregistrement" et vous verrez le statut suivant "Écouter le wifi…".
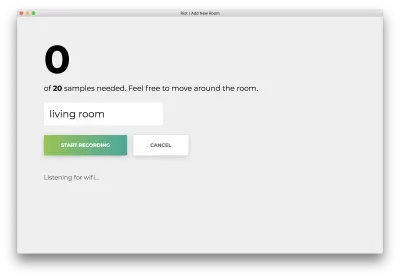
Une fois les 20 échantillons enregistrés, votre application correspondra aux éléments suivants. Le statut indiquera "Terminé. Modèle de reconversion…”
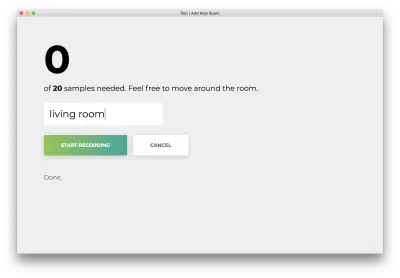
Dans la prochaine étape, nous utiliserons ce modèle recyclé pour prédire la pièce dans laquelle vous vous trouvez, à la volée.
Étape 6 : Écrire un script d'évaluation Python
Dans cette étape, nous allons charger les paramètres du modèle pré-entraînés, rechercher les réseaux Wi-Fi et prédire la pièce en fonction de l'analyse.
Ouvrez model/eval.py .
nano model/eval.pyBibliothèques d'importation utilisées et définies dans notre dernier script.
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate Définissez un utilitaire pour extraire les noms de tous les jeux de données. Cette fonction suppose que tous les ensembles de données sont stockés dans data/ en tant que <dataset>_train.json et <dataset>_test.json .
from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) Définissez la fonction main et commencez par charger les paramètres enregistrés à partir du script de formation.
def get_datasets(): ... def main(): w = np.load('w.npy') ordering = np.load('ordering.npy')Créez le jeu de données et prédisez.
def main(): ... classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w))Calculez un score de confiance basé sur la différence entre les deux premières probabilités.
def main(): ... sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) Enfin, extrayez la catégorie et imprimez le résultat. Pour terminer le script, invoquez la fonction main .
def main() ... category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()Sauvegarder et quitter. Vérifiez que votre code correspond aux éléments suivants (code source) :
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) def main(): w = np.load('w.npy') ordering = np.load('ordering.npy') classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w)) sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()Ensuite, nous allons connecter ce script d'évaluation à l'application de bureau. L'application de bureau exécutera en permanence des analyses Wi-Fi et mettra à jour l'interface utilisateur avec la pièce prévue.
Étape 7 : Connectez l'évaluation à l'application de bureau
Dans cette étape, nous mettrons à jour l'interface utilisateur avec un affichage "confiance". Ensuite, le script NodeJS associé exécutera en continu des analyses et des prédictions, mettant à jour l'interface utilisateur en conséquence.
Ouvrez static/index.html .
nano static/index.htmlAjoutez une ligne de confiance juste après le titre et avant les boutons.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <p class="subtitle">with <span>0%</span> confidence</p> <!-- end new code --> <div class="buttons"> Juste après main mais avant la fin du body , ajoutez un nouveau script predict.js .
</main> <!-- start new code --> <script> require('../scripts/predict.js') </script> <!-- end new code --> </body> Sauvegarder et quitter. Ouvrez scripts/predict.js .
nano scripts/predict.jsImportez les utilitaires NodeJS nécessaires pour le système de fichiers, les utilitaires et le générateur de processus enfant.
var fs = require('fs'); var utils = require('./utils'); const spawn = require("child_process").spawn; Définissez une fonction de predict qui appelle un processus de nœud distinct pour détecter les réseaux Wi-Fi et un processus Python distinct pour prédire la pièce.
function predict(completion) { const nodeProcess = spawn('node', ["scripts/observe.js"]); const pythonProcess = spawn('python', ["-W", "ignore", "./model/eval.py", "samples.json"]); }Une fois les deux processus générés, ajoutez des rappels au processus Python pour les réussites et les erreurs. Le rappel de réussite enregistre les informations, appelle le rappel d'achèvement et met à jour l'interface utilisateur avec la prédiction et la confiance. Le rappel d'erreur enregistre l'erreur.
function predict(completion) { ... pythonProcess.stdout.on('data', (data) => { information = JSON.parse(data.toString()); console.log(" * [INFO] Room '" + information.category + "' with confidence '" + information.confidence + "'") completion() if (typeof document != "undefined") { document.querySelector('#predicted-room-name').innerHTML = information.category document.querySelector('#predicted-confidence').innerHTML = information.confidence } }); pythonProcess.stderr.on('data', (data) => { console.log(data.toString()); }) } Définissez une fonction principale pour invoquer la fonction de predict de manière récursive, pour toujours.
function main() { f = function() { predict(f) } predict(f) } main();Une dernière fois, ouvrez l'application de bureau pour voir la prédiction en direct.
npm startEnviron toutes les secondes, une analyse sera effectuée et l'interface sera mise à jour avec la dernière confiance et la pièce prévue. Toutes nos félicitations; vous avez terminé un simple détecteur de pièce basé sur tous les réseaux WiFi à portée.
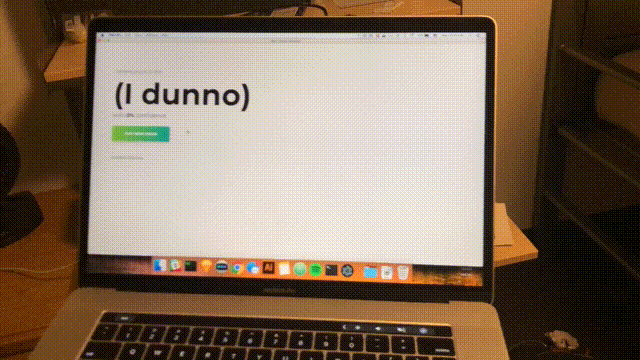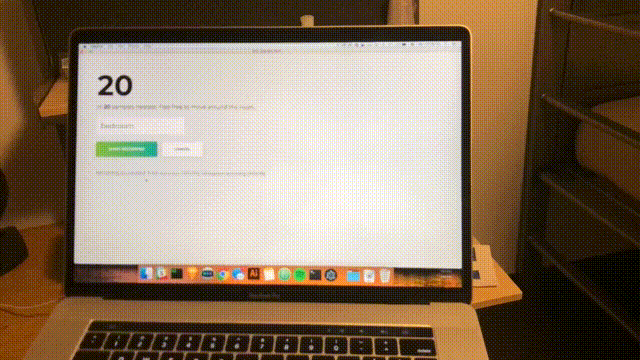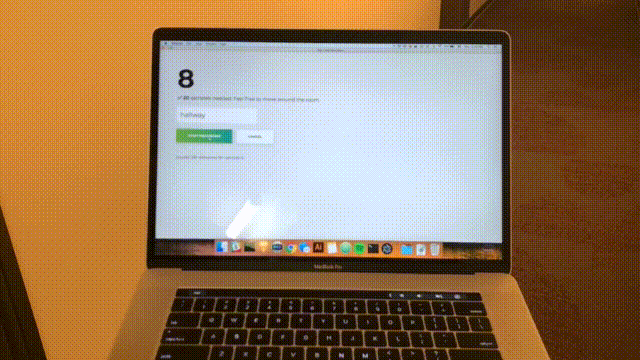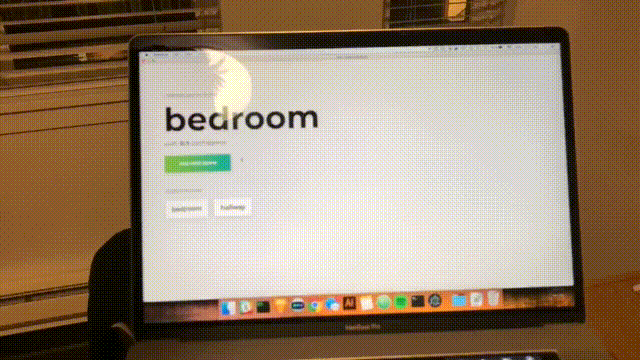
Conclusion
Dans ce didacticiel, nous avons créé une solution utilisant uniquement votre bureau pour détecter votre emplacement dans un bâtiment. Nous avons créé une application de bureau simple à l'aide d'Electron JS et appliqué une méthode simple d'apprentissage automatique sur tous les réseaux WiFi à portée. Cela ouvre la voie aux applications de l'Internet des objets sans avoir besoin de réseaux d'appareils coûteux à entretenir (coût non pas en termes d'argent mais en termes de temps et de développement).
Note : Vous pouvez voir le code source dans son intégralité sur Github.
Avec le temps, vous constaterez peut-être que ces moindres carrés ne fonctionnent pas de manière spectaculaire. Essayez de trouver deux endroits dans une même pièce ou tenez-vous devant les portes. Les moindres carrés seront grands incapables de faire la distinction entre les cas extrêmes. Peut-on faire mieux ? Il s'avère que nous le pouvons, et dans les leçons à venir, nous tirerons parti d'autres techniques et des principes fondamentaux de l'apprentissage automatique pour améliorer les performances. Ce tutoriel sert de banc d'essai rapide pour les expériences à venir.