
Construire un service central de journalisation en interne
Publié: 2022-03-10Nous savons tous à quel point le débogage est important pour améliorer les performances et les fonctionnalités des applications. BrowserStack exécute un million de sessions par jour sur une pile d'applications hautement distribuée ! Chacun implique plusieurs parties mobiles, car une session unique d'un client peut couvrir plusieurs composants dans plusieurs régions géographiques.
Sans le bon framework et les bons outils, le processus de débogage peut être un cauchemar. Dans notre cas, nous avions besoin d'un moyen de collecter les événements qui se produisent au cours des différentes étapes de chaque processus afin d'obtenir une compréhension approfondie de tout ce qui se passe au cours d'une session. Avec notre infrastructure, la résolution de ce problème est devenue compliquée car chaque composant peut avoir plusieurs événements de son cycle de vie de traitement d'une demande.
C'est pourquoi nous avons développé notre propre outil interne Central Logging Service (CLS) pour enregistrer tous les événements importants enregistrés au cours d'une session. Ces événements aident nos développeurs à identifier les conditions dans lesquelles quelque chose ne va pas dans une session et aident à suivre certaines mesures clés du produit.
Les données de débogage vont de choses simples comme la latence de réponse de l'API à la surveillance de la santé du réseau d'un utilisateur. Dans cet article, nous partageons notre histoire de construction de notre outil CLS qui collecte 70 G de données chronologiques pertinentes par jour à partir de plus de 100 composants de manière fiable, à grande échelle et avec deux instances EC2 M3.large.
La décision de construire en interne
Voyons d'abord pourquoi nous avons construit notre outil CLS en interne plutôt que d'utiliser une solution existante. Chacune de nos sessions envoie 15 événements en moyenne, de plusieurs composants au service, ce qui se traduit par environ 15 millions d'événements au total par jour.
Notre service avait besoin de pouvoir stocker toutes ces données. Nous recherchions une solution complète pour prendre en charge le stockage, l'envoi et l'interrogation d'événements à travers les événements. Comme nous avons envisagé des solutions tierces telles qu'Amplitude et Keen, nos mesures d'évaluation comprenaient le coût, les performances dans le traitement des demandes parallèles élevées et la facilité d'adoption. Malheureusement, nous n'avons pas pu trouver un ajustement qui répondait à toutes nos exigences dans les limites du budget - bien que les avantages auraient inclus un gain de temps et une minimisation des alertes. Bien que cela nécessiterait des efforts supplémentaires, nous avons décidé de développer nous-mêmes une solution interne.

Détails techniques
En termes d'architecture pour notre composant, nous avons défini les exigences de base suivantes :
- Performances des clients
N'affecte pas les performances du client/composant envoyant les événements. - Escalader
Capable de gérer un grand nombre de requêtes en parallèle. - Performance du service
Traitement rapide de tous les événements qui lui sont envoyés. - Aperçu des données
Chaque événement enregistré doit avoir des méta-informations pour pouvoir identifier de manière unique le composant ou l'utilisateur, le compte ou le message et donner plus d'informations pour aider le développeur à déboguer plus rapidement. - Interface interrogeable
Les développeurs peuvent interroger tous les événements d'une session particulière, aider à déboguer une session particulière, créer des rapports sur l'état des composants ou générer des statistiques de performances significatives de nos systèmes. - Adoption plus rapide et plus facile
Intégration facile avec un composant existant ou nouveau sans alourdir les équipes et accaparer leurs ressources. - Faible entretien
Nous sommes une petite équipe d'ingénieurs, nous avons donc cherché une solution pour minimiser les alertes !
Construire notre solution CLS
Décision 1 : Choisir une interface à exposer
En développant CLS, nous ne voulions évidemment perdre aucune de nos données, mais nous ne voulions pas non plus que les performances des composants en pâtissent. Sans parler du facteur supplémentaire d'empêcher les composants existants de devenir plus compliqués, car cela retarderait l'adoption et la publication globales. Pour déterminer notre interface, nous avons considéré les choix suivants :
- Stockage des événements dans Redis local dans chaque composant, car un processeur d'arrière-plan le pousse vers CLS. Cependant, cela nécessite un changement dans tous les composants, ainsi qu'une introduction de Redis pour les composants qui ne le contenaient pas déjà.
- Un modèle Editeur - Abonné, où Redis est plus proche du CLS. Comme tout le monde publie des événements, nous avons encore une fois le facteur de composants fonctionnant à travers le monde. Pendant la période de trafic élevé, cela retarderait les composants. De plus, cette écriture peut sauter par intermittence jusqu'à cinq secondes (en raison d'Internet uniquement).
- Envoi d'événements via UDP, qui offre un impact moindre sur les performances de l'application. Dans ce cas, les données seraient envoyées et oubliées, cependant, l'inconvénient ici serait la perte de données.
Fait intéressant, notre perte de données sur UDP était inférieure à 0,1 %, ce qui était un montant acceptable pour nous d'envisager de créer un tel service. Nous avons réussi à convaincre toutes les équipes que ce montant de perte valait la performance, et nous sommes allés de l'avant pour tirer parti d'une interface UDP qui écoutait tous les événements envoyés.
Bien que l'un des résultats ait été un impact moindre sur les performances d'une application, nous avons été confrontés à un problème car le trafic UDP n'était pas autorisé depuis tous les réseaux, principalement ceux de nos utilisateurs - nous obligeant dans certains cas à ne recevoir aucune donnée. Pour contourner ce problème, nous avons pris en charge la journalisation des événements à l'aide de requêtes HTTP. Tous les événements provenant du côté de l'utilisateur seraient envoyés via HTTP, tandis que tous les événements enregistrés à partir de nos composants seraient via UDP.
Décision 2 : Tech Stack (Langage, Framework & Stockage)
Nous sommes une boutique Ruby. Cependant, nous ne savions pas si Ruby serait un meilleur choix pour notre problème particulier. Notre service devrait gérer un grand nombre de demandes entrantes, ainsi que traiter un grand nombre d'écritures. Avec le verrou Global Interpreter, il serait difficile d'obtenir du multithreading ou de la simultanéité dans Ruby (ne vous vexez pas, nous adorons Ruby !). Nous avions donc besoin d'une solution qui nous aiderait à atteindre ce type de concurrence.
Nous souhaitions également évaluer un nouveau langage dans notre pile technologique, et ce projet semblait parfait pour expérimenter de nouvelles choses. C'est à ce moment-là que nous avons décidé d'essayer Golang, car il offrait un support intégré pour la concurrence, les threads légers et les routines go. Chaque point de données enregistré ressemble à une paire clé-valeur où la « clé » est l'événement et la « valeur » sert de valeur associée.
Mais avoir une clé et une valeur simples ne suffit pas pour récupérer des données liées à une session - il y a plus de métadonnées. Pour résoudre ce problème, nous avons décidé que tout événement devant être enregistré aurait un identifiant de session avec sa clé et sa valeur. Nous avons également ajouté des champs supplémentaires tels que l'horodatage, l'ID utilisateur et le composant enregistrant les données, de sorte qu'il est devenu plus facile de récupérer et d'analyser les données.

Maintenant que nous avons décidé de notre structure de charge utile, nous devions choisir notre magasin de données. Nous avons envisagé Elastic Search, mais nous voulions également prendre en charge les demandes de mise à jour des clés. Cela déclencherait la réindexation du document entier, ce qui pourrait affecter les performances de nos écritures. MongoDB avait plus de sens en tant que magasin de données car il serait plus facile d'interroger tous les événements en fonction de l'un des champs de données qui seraient ajoutés. C'était facile !
Décision 3 : La taille de la base de données est énorme et les requêtes et l'archivage sont nuls !
Afin de réduire la maintenance, notre service devrait gérer autant d'événements que possible. Compte tenu de la vitesse à laquelle BrowserStack publie des fonctionnalités et des produits, nous étions certains que le nombre de nos événements augmenterait à des taux plus élevés au fil du temps, ce qui signifie que notre service devrait continuer à bien fonctionner. À mesure que l'espace augmente, les lectures et les écritures prennent plus de temps, ce qui pourrait avoir un impact considérable sur les performances du service.
La première solution que nous avons explorée consistait à déplacer les journaux d'une certaine période loin de la base de données (dans notre cas, nous avons décidé de 15 jours). Pour ce faire, nous avons créé une base de données différente pour chaque jour, nous permettant de retrouver des journaux antérieurs à une période particulière sans avoir à scanner tous les documents écrits. Maintenant, nous supprimons continuellement les bases de données de plus de 15 jours de Mongo, tout en conservant bien sûr des sauvegardes au cas où.
La seule pièce restante était une interface développeur pour interroger les données liées à la session. Honnêtement, c'était le problème le plus facile à résoudre. Nous fournissons une interface HTTP, où les utilisateurs peuvent rechercher des événements liés à la session dans la base de données correspondante de MongoDB, pour toutes les données ayant un ID de session particulier.
Architecture
Parlons des composants internes du service, en tenant compte des points suivants :
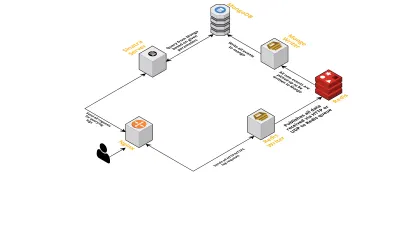
- Comme indiqué précédemment, nous avions besoin de deux interfaces - une écoutant sur UDP et une autre écoutant sur HTTP. Nous avons donc construit deux serveurs, encore un pour chaque interface, pour écouter les événements. Dès qu'un événement arrive, nous l'analysons pour vérifier s'il contient les champs requis - il s'agit de l'ID de session, de la clé et de la valeur. Si ce n'est pas le cas, les données sont supprimées. Sinon, les données sont transmises via un canal Go à une autre goroutine, dont la seule responsabilité est d'écrire dans MongoDB.
- Une préoccupation possible ici est d'écrire à MongoDB. Si les écritures sur MongoDB sont plus lentes que le débit de réception des données, cela crée un goulot d'étranglement. Ceci, à son tour, affame d'autres événements entrants et signifie des données supprimées. Le serveur doit donc être rapide dans le traitement des journaux entrants et être prêt à traiter ceux à venir. Pour résoudre le problème, nous avons divisé le serveur en deux parties : la première reçoit tous les événements et les met en file d'attente pour la seconde, qui les traite et les écrit dans MongoDB.
- Pour la file d'attente, nous avons choisi Redis. En divisant l'ensemble du composant en ces deux éléments, nous avons réduit la charge de travail du serveur, lui permettant de gérer davantage de journaux.
- Nous avons écrit un petit service utilisant le serveur Sinatra pour gérer tout le travail d'interrogation de MongoDB avec des paramètres donnés. Il renvoie une réponse HTML/JSON aux développeurs lorsqu'ils ont besoin d'informations sur une session particulière.
Tous ces processus s'exécutent sans problème sur une seule instance m3.large .
Requêtes de nouvelles fonctionnalités
Comme notre outil CLS a été de plus en plus utilisé au fil du temps, il avait besoin de plus de fonctionnalités. Ci-dessous, nous en discutons et comment ils ont été ajoutés.
Métadonnées manquantes
Au fur et à mesure que le nombre de composants dans BrowserStack augmente, nous avons demandé plus à CLS. Par exemple, nous avions besoin de pouvoir consigner les événements des composants dépourvus d'identifiant de session. Sinon, en obtenir un alourdirait notre infrastructure, en affectant les performances des applications et en provoquant du trafic sur nos serveurs principaux.
Nous avons résolu ce problème en activant la journalisation des événements à l'aide d'autres clés, telles que les ID de terminal et d'utilisateur. Désormais, chaque fois qu'une session est créée ou mise à jour, CLS est informé de l'ID de session, ainsi que des ID d'utilisateur et de terminal respectifs. Il stocke une carte qui peut être récupérée par le processus d'écriture sur MongoDB. Chaque fois qu'un événement contenant l'ID de l'utilisateur ou du terminal est récupéré, l'ID de session est ajouté.
Gérer le spam (problèmes de code dans d'autres composants)
CLS a également dû faire face aux difficultés habituelles de gestion des événements de spam. Nous avons souvent trouvé des déploiements dans des composants qui ont généré un énorme volume de demandes envoyées à CLS. D'autres journaux souffriraient du processus, car le serveur devenait trop occupé pour les traiter et des journaux importants étaient supprimés.
Pour la plupart, la plupart des données enregistrées étaient via des requêtes HTTP. Pour les contrôler, nous activons la limitation de débit sur nginx (à l'aide du module limit_req_zone), qui bloque les requêtes de toute adresse IP que nous avons trouvée atteignant plus d'un certain nombre de requêtes en peu de temps. Bien sûr, nous exploitons les rapports de santé sur toutes les adresses IP bloquées et informons les équipes responsables.
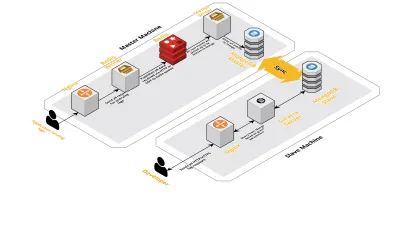
Échelle v2
À mesure que nos sessions quotidiennes augmentaient, les données enregistrées dans CLS augmentaient également. Cela a affecté les requêtes que nos développeurs exécutaient quotidiennement, et bientôt le goulot d'étranglement que nous avons eu était avec la machine elle-même. Notre configuration consistait en deux machines principales exécutant tous les composants ci-dessus, ainsi qu'un ensemble de scripts pour interroger Mongo et suivre les métriques clés pour chaque produit. Au fil du temps, les données sur la machine avaient considérablement augmenté et les scripts ont commencé à prendre beaucoup de temps CPU. Même après avoir essayé d'optimiser les requêtes Mongo, nous revenions toujours aux mêmes problèmes.
Pour résoudre ce problème, nous avons ajouté une autre machine pour exécuter les scripts de rapport de santé et l'interface pour interroger ces sessions. Le processus impliquait de démarrer une nouvelle machine et de configurer un esclave du Mongo fonctionnant sur la machine principale. Cela a permis de réduire les pics de CPU que nous voyions tous les jours causés par ces scripts.
Conclusion
La création d'un service pour une tâche aussi simple que l'enregistrement de données peut devenir compliquée, à mesure que la quantité de données augmente. Cet article décrit les solutions que nous avons explorées, ainsi que les défis rencontrés lors de la résolution de ce problème. Nous avons expérimenté Golang pour voir dans quelle mesure il s'intégrerait à notre écosystème, et jusqu'à présent, nous avons été satisfaits. Notre choix de créer un service interne plutôt que de payer pour un service externe s'est avéré merveilleusement rentable. Nous n'avons pas non plus eu à adapter notre configuration à une autre machine jusqu'à bien plus tard - lorsque le volume de nos sessions a augmenté. Bien sûr, nos choix dans le développement de CLS étaient entièrement basés sur nos besoins et nos priorités.
Aujourd'hui, CLS gère jusqu'à 15 millions d'événements chaque jour, constituant jusqu'à 70 Go de données. Ces données sont utilisées pour nous aider à résoudre les problèmes auxquels nos clients sont confrontés au cours d'une session. Nous utilisons également ces données à d'autres fins. Compte tenu des informations fournies par les données de chaque session sur les différents produits et composants internes, nous avons commencé à exploiter ces données pour suivre chaque produit. Ceci est réalisé en extrayant les métriques clés pour tous les composants importants.
Dans l'ensemble, nous avons connu un grand succès dans la création de notre propre outil CLS. Si cela a du sens pour vous, je vous recommande d'envisager de faire de même !