
Créer une application de bookmarking avec FaunaDB, Netlify et 11ty
Publié: 2022-03-10La révolution JAMstack (JavaScript, API et Markup) bat son plein. Les sites statiques sont sécurisés, rapides, fiables et agréables à travailler. Au cœur de JAMstack se trouvent des générateurs de sites statiques (SSG) qui stockent vos données sous forme de fichiers plats : Markdown, YAML, JSON, HTML, etc. Parfois, la gestion des données de cette manière peut être trop compliquée. Parfois, nous avons encore besoin d'une base de données.
Dans cet esprit, Netlify - un hébergeur de site statique et FaunaDB - une base de données cloud sans serveur - ont collaboré pour faciliter la combinaison des deux systèmes.
Pourquoi un site de bookmarking ?
Le JAMstack est idéal pour de nombreuses utilisations professionnelles, mais l'un de mes aspects préférés de cet ensemble de technologies est sa faible barrière à l'entrée pour les outils et projets personnels.
Il existe de nombreux bons produits sur le marché pour la plupart des applications que je pourrais proposer, mais aucun ne serait exactement configuré pour moi. Aucun ne me donnerait un contrôle total sur mon contenu. Aucun ne viendrait sans coût (monétaire ou informationnel).
Dans cet esprit, nous pouvons créer nos propres mini-services en utilisant les méthodes JAMstack. Dans ce cas, nous allons créer un site pour stocker et publier tous les articles intéressants que je rencontre dans mes lectures quotidiennes sur la technologie.
Je passe beaucoup de temps à lire des articles qui ont été partagés sur Twitter. Quand j'en aime un, j'appuie sur l'icône "cœur". Puis, en quelques jours, il est presque impossible de trouver avec l'afflux de nouveaux favoris. Je veux construire quelque chose d'aussi proche de la facilité du "cœur", mais que je possède et contrôle.
Comment allons-nous faire cela? Je suis content que vous ayez demandé.
Intéressé à obtenir le code? Vous pouvez le récupérer sur Github ou simplement le déployer directement sur Netlify à partir de ce référentiel ! Jetez un œil au produit fini ici.
Nos technologies
Fonctions d'hébergement et sans serveur : Netlify
Pour l'hébergement et les fonctions sans serveur, nous utiliserons Netlify. En prime, avec la nouvelle collaboration mentionnée ci-dessus, la CLI de Netlify - "Netlify Dev" - se connectera automatiquement à FaunaDB et stockera nos clés API en tant que variables d'environnement.
Base de données : FaunaDB
FaunaDB est une base de données NoSQL « sans serveur ». Nous l'utiliserons pour stocker nos données de signets.
Générateur de site statique : 11ty
Je suis un grand partisan du HTML. Pour cette raison, le didacticiel n'utilisera pas JavaScript frontal pour rendre nos signets. Au lieu de cela, nous utiliserons 11ty comme générateur de site statique. 11ty a une fonctionnalité de données intégrée qui rend la récupération de données à partir d'une API aussi simple que l'écriture de quelques fonctions JavaScript courtes.
Raccourcis iOS
Nous aurons besoin d'un moyen facile de publier des données dans notre base de données. Dans ce cas, nous utiliserons l'application iOS Shortcuts. Cela pourrait également être converti en un bookmarklet JavaScript Android ou de bureau.
Configuration de FaunaDB via Netlify Dev
Que vous soyez déjà inscrit à FaunaDB ou que vous ayez besoin de créer un nouveau compte, le moyen le plus simple de configurer un lien entre FaunaDB et Netlify est via la CLI de Netlify : Netlify Dev. Vous pouvez trouver des instructions complètes de FaunaDB ici ou suivre ci-dessous.
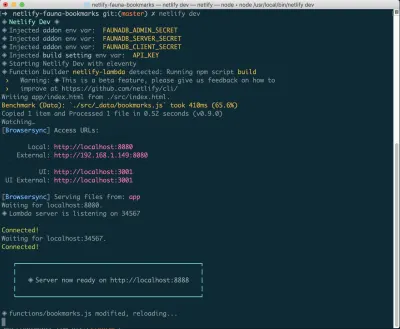
Si vous ne l'avez pas déjà installé, vous pouvez exécuter la commande suivante dans Terminal :
npm install netlify-cli -gDepuis le répertoire de votre projet, exécutez les commandes suivantes :
netlify init // This will connect your project to a Netlify project netlify addons:create fauna // This will install the FaunaDB "addon" netlify addons:auth fauna // This command will run you through connecting your account or setting up an account Une fois que tout est connecté, vous pouvez exécuter netlify dev dans votre projet. Cela exécutera tous les scripts de construction que nous avons configurés, mais se connectera également aux services Netlify et FaunaDB et saisira toutes les variables d'environnement nécessaires. Pratique!
Créer nos premières données
À partir de là, nous allons nous connecter à FaunaDB et créer notre premier ensemble de données. Nous allons commencer par créer une nouvelle base de données appelée "signets". À l'intérieur d'une base de données, nous avons des collections, des documents et des index.
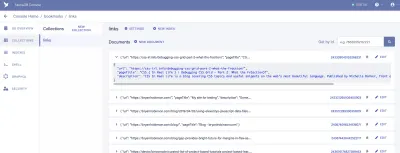
Une collection est un groupe catégorisé de données. Chaque donnée prend la forme d'un Document. Un document est un « enregistrement unique et modifiable dans une base de données FaunaDB », selon la documentation de Fauna. Vous pouvez considérer les collections comme une table de base de données traditionnelle et un document comme une ligne.
Pour notre application, nous avons besoin d'une collection, que nous appellerons "liens". Chaque document de la collection "links" sera un simple objet JSON avec trois propriétés. Pour commencer, nous allons ajouter un nouveau document que nous utiliserons pour créer notre première récupération de données.
{ "url": "https://css-irl.info/debugging-css-grid-part-2-what-the-fraction/", "pageTitle": "CSS { In Real Life } | Debugging CSS Grid – Part 2: What the Fr(action)?", "description": "CSS In Real Life is a blog covering CSS topics and useful snippets on the web's most beautiful language. Published by Michelle Barker, front end developer at Ordoo and CSS superfan." }Cela crée la base des informations que nous devrons extraire de nos signets et nous fournit notre premier ensemble de données à extraire dans notre modèle.
Si vous êtes comme moi, vous voulez voir les fruits de votre travail tout de suite. Mettons quelque chose sur la page !
Installer 11ty et extraire des données dans un modèle
Puisque nous voulons que les signets soient rendus en HTML et non récupérés par le navigateur, nous aurons besoin de quelque chose pour faire le rendu. Il existe de nombreuses façons de le faire, mais pour plus de facilité et de puissance, j'adore utiliser le générateur de site statique 11ty.
Puisque 11ty est un générateur de site statique JavaScript, nous pouvons l'installer via NPM.
npm install --save @11ty/eleventy À partir de cette installation, nous pouvons exécuter onze ou eleventy --serve eleventy notre projet pour être opérationnel.
Netlify Dev détectera souvent 11ty comme une exigence et exécutera la commande pour nous. Pour que cela fonctionne - et nous assurer que nous sommes prêts à déployer, nous pouvons également créer des commandes "serve" et "build" dans notre package.json .
"scripts": { "build": "npx eleventy", "serve": "npx eleventy --serve" }Fichiers de données de 11ty
La plupart des générateurs de sites statiques ont une idée d'un "fichier de données" intégré. Habituellement, ces fichiers seront des fichiers JSON ou YAML qui vous permettront d'ajouter des informations supplémentaires à votre site.
Dans 11ty, vous pouvez utiliser des fichiers de données JSON ou des fichiers de données JavaScript. En utilisant un fichier JavaScript, nous pouvons réellement effectuer nos appels API et renvoyer les données directement dans un modèle.
Par défaut, 11ty veut que les fichiers de données soient stockés dans un répertoire _data . Vous pouvez ensuite accéder aux données en utilisant le nom du fichier comme variable dans vos modèles. Dans notre cas, nous allons créer un fichier dans _data/bookmarks.js et y accéder via le nom de la variable {{ bookmarks }} .
Si vous souhaitez approfondir la configuration des fichiers de données, vous pouvez lire des exemples dans la documentation 11ty ou consulter ce didacticiel sur l'utilisation des fichiers de données 11ty avec l'API Meetup.
Le fichier sera un module JavaScript. Donc, pour que quoi que ce soit fonctionne, nous devons exporter soit nos données, soit une fonction. Dans notre cas, nous allons exporter une fonction.
module.exports = async function() { const data = mapBookmarks(await getBookmarks()); return data.reverse() } Décomposons cela. Nous avons deux fonctions qui font notre travail principal ici : mapBookmarks() et getBookmarks() .
La fonction getBookmarks() ira chercher nos données dans notre base de données FaunaDB et mapBookmarks() prendra un tableau de signets et le restructurera pour mieux fonctionner avec notre modèle.
getBookmarks() .
getBookmarks()
Tout d'abord, nous devrons installer et initialiser une instance du pilote JavaScript FaunaDB.
npm install --save faunadbMaintenant que nous l'avons installé, ajoutons-le en haut de notre fichier de données. Ce code provient directement de la documentation de Fauna.
// Requires the Fauna module and sets up the query module, which we can use to create custom queries. const faunadb = require('faunadb'), q = faunadb.query; // Once required, we need a new instance with our secret var adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET }); Après cela, nous pouvons créer notre fonction. Nous allons commencer par créer notre première requête en utilisant des méthodes intégrées sur le pilote. Ce premier morceau de code renverra les références de base de données que nous pouvons utiliser pour obtenir des données complètes pour tous nos liens favoris. Nous utilisons la méthode Paginate , comme aide pour gérer l'état du curseur si nous décidons de paginer les données avant de les transmettre à 11ty. Dans notre cas, nous renverrons simplement toutes les références.
Dans cet exemple, je suppose que vous avez installé et connecté FaunaDB via Netlify Dev CLI. En utilisant ce processus, vous obtenez les variables d'environnement locales des secrets FaunaDB. Si vous ne l'avez pas installé de cette façon ou si vous n'exécutez pas netlify dev dans votre projet, vous aurez besoin d'un package comme dotenv pour créer les variables d'environnement. Vous devrez également ajouter vos variables d'environnement à la configuration de votre site Netlify pour que les déploiements fonctionnent ultérieurement.
adminClient.query(q.Paginate( q.Match( // Match the reference below q.Ref("indexes/all_links") // Reference to match, in this case, our all_links index ) )) .then( response => { ... })Ce code renverra un tableau de tous nos liens sous forme de référence. Nous pouvons maintenant créer une liste de requêtes à envoyer à notre base de données.
adminClient.query(...) .then((response) => { const linkRefs = response.data; // Get just the references for the links from the response const getAllLinksDataQuery = linkRefs.map((ref) => { return q.Get(ref) // Return a Get query based on the reference passed in }) return adminClient.query(getAllLinksDataQuery).then(ret => { return ret // Return an array of all the links with full data }) }).catch(...) À partir de là, nous avons juste besoin de nettoyer les données renvoyées. C'est là que mapBookmarks() entre en jeu !
mapBookmarks()
Dans cette fonction, nous traitons deux aspects des données.
Tout d'abord, nous obtenons un dateTime gratuit dans FaunaDB. Pour toutes les données créées, il existe une propriété timestamp ( ts ). Il n'est pas formaté de manière à rendre le filtre de date par défaut de Liquid heureux, alors corrigeons cela.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); ... }) } Avec cela à l'écart, nous pouvons créer un nouvel objet pour nos données. Dans ce cas, il aura une propriété time et nous utiliserons l'opérateur Spread pour déstructurer notre objet de data afin qu'ils vivent tous à un seul niveau.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); return { time: dateTime, ...bookmark.data } }) }Voici nos données avant notre fonction :
{ ref: Ref(Collection("links"), "244778237839802888"), ts: 1569697568650000, data: { url: 'https://sample.com', pageTitle: 'Sample title', description: 'An escaped description goes here' } }Voici nos données après notre fonction :

{ time: 1569697568650, url: 'https://sample.com', pageTitle: 'Sample title' description: 'An escaped description goes here' }Maintenant, nous avons des données bien formatées prêtes pour notre modèle !
Écrivons un modèle simple. Nous allons parcourir nos signets et valider que chacun a un titre de pageTitle et une url afin de ne pas avoir l'air idiot.
<div class="bookmarks"> {% for link in bookmarks %} {% if link.url and link.pageTitle %} // confirms there's both title AND url for safety <div class="bookmark"> <h2><a href="{{ link.url }}">{{ link.pageTitle }}</a></h2> <p>Saved on {{ link.time | date: "%b %d, %Y" }}</p> {% if link.description != "" %} <p>{{ link.description }}</p> {% endif %} </div> {% endif %} {% endfor %} </div>Nous ingérons et affichons maintenant les données de FaunaDB. Prenons un moment et réfléchissons à quel point il est agréable que cela rende du HTML pur et qu'il n'y ait pas besoin de récupérer des données côté client !
Mais ce n'est pas vraiment suffisant pour en faire une application utile pour nous. Trouvons un meilleur moyen que d'ajouter un signet dans la console FaunaDB.
Entrez les fonctions Netlify
Le module complémentaire Functions de Netlify est l'un des moyens les plus simples de déployer les fonctions AWS lambda. Puisqu'il n'y a pas d'étape de configuration, c'est parfait pour les projets de bricolage où vous voulez juste écrire le code.
Cette fonction vivra à une URL dans votre projet qui ressemble à ceci : https://myproject.com/.netlify/functions/bookmarks en supposant que le fichier que nous créons dans notre dossier de fonctions est bookmarks.js .
Flux de base
- Passez une URL en tant que paramètre de requête à notre URL de fonction.
- Utilisez la fonction pour charger l'URL et gratter le titre et la description de la page si disponible.
- Formatez les détails pour FaunaDB.
- Poussez les détails vers notre collection FaunaDB.
- Reconstruire le site.
Conditions
Nous avons quelques packages dont nous aurons besoin au fur et à mesure de la construction. Nous utiliserons la CLI netlify-lambda pour construire nos fonctions localement. request-promise est le package que nous utiliserons pour faire des requêtes. Cheerio.js est le package que nous utiliserons pour récupérer des éléments spécifiques de notre page demandée (pensez à jQuery pour Node). Et enfin, nous aurons besoin de FaunaDb (qui devrait déjà être installé.
npm install --save netlify-lambda request-promise cheerioUne fois cela installé, configurons notre projet pour construire et servir les fonctions localement.
Nous allons modifier nos scripts "build" et "serve" dans notre package.json pour qu'ils ressemblent à ceci :
"scripts": { "build": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy", "serve": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy --serve" } Avertissement : il y a une erreur avec le pilote NodeJS de Fauna lors de la compilation avec Webpack, que les fonctions de Netlify utilisent pour construire. Pour contourner cela, nous devons définir un fichier de configuration pour Webpack. Vous pouvez enregistrer le code suivant dans un nouveau — ou existant — webpack.config.js .
const webpack = require('webpack'); module.exports = { plugins: [ new webpack.DefinePlugin({ "global.GENTLY": false }) ] }; Une fois que ce fichier existe, lorsque nous utilisons la commande netlify-lambda , nous devrons lui dire de s'exécuter à partir de cette configuration. C'est pourquoi nos scripts "serve" et "build utilisent la valeur --config pour cette commande.
Fonction Ménage
Afin de garder notre fichier Function principal aussi propre que possible, nous allons créer nos fonctions dans un répertoire de bookmarks séparé et les importer dans notre fichier Function principal.
import { getDetails, saveBookmark } from "./bookmarks/create"; getDetails(url)
La fonction getDetails() prendra une URL, transmise par notre gestionnaire exporté. À partir de là, nous allons atteindre le site à cette URL et récupérer les parties pertinentes de la page à stocker en tant que données pour notre marque-page.
Nous commençons par exiger les packages NPM dont nous avons besoin :
const rp = require('request-promise'); const cheerio = require('cheerio'); Ensuite, nous utiliserons le module request-promise pour renvoyer une chaîne HTML pour la page demandée et la transmettrons à cheerio pour nous donner une interface très jQuery-esque.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); ... }À partir de là, nous devons obtenir le titre de la page et une méta description. Pour ce faire, nous utiliserons des sélecteurs comme vous le feriez dans jQuery.
Remarque : Dans ce code, nous utilisons 'head > title' comme sélecteur pour obtenir le titre de la page. Si vous ne le spécifiez pas, vous risquez d'obtenir des balises <title> à l'intérieur de tous les SVG de la page, ce qui n'est pas idéal.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); const title = $('head > title').text(); // Get the text inside the tag const description = $('meta[name="description"]').attr('content'); // Get the text of the content attribute // Return out the data in the structure we expect return { pageTitle: title, description: description }; }); return data //return to our main function }Avec les données en main, il est temps d'envoyer notre signet à notre collection dans FaunaDB !
saveBookmark(details)
Pour notre fonction de sauvegarde, nous voudrons transmettre les détails que nous avons acquis de getDetails ainsi que l'URL en tant qu'objet singulier. L'opérateur Spread a encore frappé !
const savedResponse = await saveBookmark({url, ...details}); Dans notre fichier create.js , nous devons également exiger et configurer notre pilote FaunaDB. Cela devrait sembler très familier à partir de notre fichier de données 11ty.
const faunadb = require('faunadb'), q = faunadb.query; const adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET });Une fois que nous avons réglé cela, nous pouvons coder.
Tout d'abord, nous devons formater nos détails dans une structure de données que Fauna attend pour notre requête. Fauna attend un objet avec une propriété data contenant les données que nous souhaitons stocker.
const saveBookmark = async function(details) { const data = { data: details }; ... }Ensuite, nous ouvrirons une nouvelle requête à ajouter à notre collection. Dans ce cas, nous utiliserons notre assistant de requête et utiliserons la méthode Create. Create() prend deux arguments. La première est la collection dans laquelle nous voulons stocker nos données et la seconde est la donnée elle-même.
Après avoir enregistré, nous renvoyons le succès ou l'échec à notre gestionnaire.
const saveBookmark = async function(details) { const data = { data: details }; return adminClient.query(q.Create(q.Collection("links"), data)) .then((response) => { /* Success! return the response with statusCode 200 */ return { statusCode: 200, body: JSON.stringify(response) } }).catch((error) => { /* Error! return the error with statusCode 400 */ return { statusCode: 400, body: JSON.stringify(error) } }) }Jetons un coup d'œil au fichier Function complet.
import { getDetails, saveBookmark } from "./bookmarks/create"; import { rebuildSite } from "./utilities/rebuild"; // For rebuilding the site (more on that in a minute) exports.handler = async function(event, context) { try { const url = event.queryStringParameters.url; // Grab the URL const details = await getDetails(url); // Get the details of the page const savedResponse = await saveBookmark({url, ...details}); //Save the URL and the details to Fauna if (savedResponse.statusCode === 200) { // If successful, return success and trigger a Netlify build await rebuildSite(); return { statusCode: 200, body: savedResponse.body } } else { return savedResponse //or else return the error } } catch (err) { return { statusCode: 500, body: `Error: ${err}` }; } }; rebuildSite()
L'œil avisé remarquera que nous avons une autre fonction importée dans notre gestionnaire : rebuildSite() . Cette fonction utilisera la fonctionnalité Deploy Hook de Netlify pour reconstruire notre site à partir des nouvelles données chaque fois que nous soumettrons une nouvelle sauvegarde de signet réussie.
Dans les paramètres de votre site dans Netlify, vous pouvez accéder à vos paramètres Build & Deploy et créer un nouveau "Build Hook". Les crochets ont un nom qui apparaît dans la section Déployer et une option pour une branche non-maître à déployer si vous le souhaitez. Dans notre cas, nous le nommerons "new_link" et déploierons notre branche master.
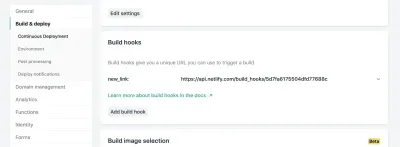
À partir de là, il nous suffit d'envoyer une requête POST à l'URL fournie.
Nous avons besoin d'un moyen de faire des requêtes et puisque nous avons déjà installé request-promise , nous continuerons à utiliser ce paquet en l'exigeant en haut de notre fichier.
const rp = require('request-promise'); const rebuildSite = async function() { var options = { method: 'POST', uri: 'https://api.netlify.com/build_hooks/5d7fa6175504dfd43377688c', body: {}, json: true }; const returned = await rp(options).then(function(res) { console.log('Successfully hit webhook', res); }).catch(function(err) { console.log('Error:', err); }); return returned } Configurer un raccourci iOS
Donc, nous avons une base de données, un moyen d'afficher les données et une fonction pour ajouter des données, mais nous ne sommes toujours pas très conviviaux.
Netlify fournit des URL pour nos fonctions Lambda, mais elles ne sont pas amusantes à saisir sur un appareil mobile. Nous devrons également lui transmettre une URL en tant que paramètre de requête. C'est BEAUCOUP d'efforts. Comment faire le moins d'efforts possible ?
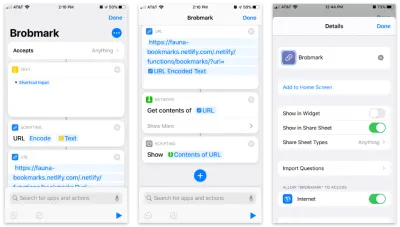
L'application Raccourcis d'Apple permet de créer des éléments personnalisés à intégrer dans votre feuille de partage. À l'intérieur de ces raccourcis, nous pouvons envoyer différents types de demandes de données collectées dans le processus de partage.
Voici le raccourci étape par étape :
- Acceptez tous les éléments et stockez cet élément dans un bloc "texte".
- Passez ce texte dans un bloc "Scripting" pour encoder l'URL (juste au cas où).
- Transmettez cette chaîne dans un bloc d'URL avec l'URL de notre fonction Netlify et un paramètre de requête de
url. - À partir de "Réseau", utilisez un bloc "Obtenir le contenu" pour POSTer sur JSON vers notre URL.
- Facultatif : À partir de "Scripting", "Afficher" le contenu de la dernière étape (pour confirmer les données que nous envoyons).
Pour y accéder à partir du menu de partage, nous ouvrons les paramètres de ce raccourci et basculons sur l'option "Afficher dans la feuille de partage".
À partir d'iOS13, ces "Actions" partagées peuvent être mises en favoris et déplacées vers une position élevée dans la boîte de dialogue.
Nous avons maintenant une "application" fonctionnelle pour partager des signets sur plusieurs plateformes !
Faites un effort supplémentaire !
Si vous êtes inspiré pour essayer cela vous-même, il existe de nombreuses autres possibilités pour ajouter des fonctionnalités. La joie du Web de bricolage est que vous pouvez faire fonctionner ces types d'applications pour vous. Voici quelques idées:
- Utilisez une fausse "clé API" pour une authentification rapide, afin que les autres utilisateurs ne publient pas sur votre site (le mien utilise une clé API, alors n'essayez pas de publier dessus !).
- Ajoutez une fonctionnalité de balise pour organiser les signets.
- Ajoutez un flux RSS pour votre site afin que d'autres puissent s'y abonner.
- Envoyez un e-mail récapitulatif hebdomadaire par programme pour les liens que vous avez ajoutés.
Vraiment, le ciel est la limite, alors commencez à expérimenter !