
Distribution binomiale en Python avec des exemples du monde réel [2022]
Publié: 2021-01-09La valeur des probabilités et des statistiques dans le domaine de la science des données a été immense, l'intelligence artificielle et l'apprentissage automatique en dépendant fortement. Nous utilisons des modèles de processus de distribution normale chaque fois que nous effectuons des tests A/B et des modèles d'investissement.
Cependant, la distribution binomiale en Python est appliquée de plusieurs manières pour effectuer plusieurs processus. Mais, avant de commencer avec la distribution binomiale en Python , vous devez connaître la distribution binomiale en général et son utilisation dans la vie quotidienne. Si vous êtes débutant et que vous souhaitez en savoir plus sur la science des données, consultez notre formation en science des données dispensée par les meilleures universités.
Table des matières
Qu'est-ce que la distribution binomiale ?
Avez-vous déjà lancé une pièce? Si vous avez, alors vous devez savoir que la probabilité d'obtenir pile ou face est égale. Mais qu'en est-il de la probabilité d'obtenir sept faces sur un total de dix lancers de pièce ? C'est là que la distribution binomiale peut aider à calculer les résultats de chaque lancer, et donc à déterminer la probabilité d'obtenir sept faces pour dix lancers d'une pièce.
Le nœud de la distribution de probabilité provient de la variance de tout événement. Pour chaque ensemble de dix lancers de pièces, la probabilité d'obtenir pile et face peut être comprise entre une et dix fois, de manière égale et probable. L'incertitude du résultat (également connue sous le nom de variance) aide à générer la distribution des résultats produits.
En d'autres termes, la distribution binomiale est un processus où il n'y a que deux résultats possibles : vrai ou faux. Par conséquent, il a une probabilité égale des deux résultats pour tous les événements, car les mêmes actions sont effectuées à chaque fois. Il n'y a qu'une seule condition… Les étapes doivent être totalement indépendantes les unes des autres, et les résultats peuvent ou non être également probables.
Par conséquent, la fonction de probabilité d'une distribution binomiale est :
f f( k k , n n, p p) = P r Pr( k k; n n, p p) = P r Pr ( X X= k k) =
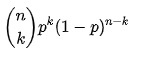
La source
Où,
![]() = n n! k k !( n n!- k k!)
= n n! k k !( n n!- k k!)
Ici, n = nombre total d'essais
p = probabilité de succès
k = nombre cible de succès
Distribution binomiale en Python
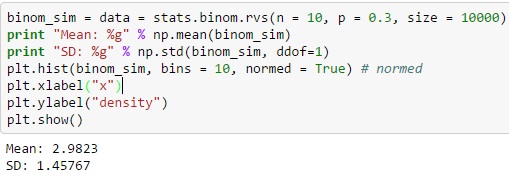
Pour la distribution binomiale via Python, vous pouvez produire la variable aléatoire distincte à partir de la fonction binom.rvs(), où 'n' est défini comme la fréquence totale des essais et 'p' est égal à la probabilité de réussite.
Vous pouvez également déplacer la distribution à l'aide de la fonction loc, et la taille définit la fréquence d'une action qui se répète dans la série. L'ajout d'un random_state peut aider à maintenir la reproductibilité.
La source
Exemples concrets de distribution binomiale en Python
Il y a beaucoup plus d'événements (plus gros que les lancers de pièces) qui peuvent être traités par la distribution binomiale en Python. Certains des cas d'utilisation peuvent aider à suivre et à améliorer le retour sur investissement (ROI) pour les grandes et les petites entreprises. Voici comment:

- Pensez à un centre d'appels où chaque employé reçoit en moyenne 50 appels par jour.
- La probabilité de conversion sur chaque appel est égale à 4 %.
- La génération de revenus moyenne pour l'entreprise basée sur chacune de ces conversions est de 20 USD.
- Si vous analysez 100 de ces employés, qui sont payés 200 USD par jour, alors
n = 50
p = 4 %
Le code peut générer une sortie comme suit :
- Taux de conversion moyen pour chaque employé = 2,13
- L'écart type des conversions pour chaque personnel du centre d'appels = 1,48
- Conversion brute = 213
- Génération de revenus bruts = 21 300 USD
- Dépense brute = 20 000 USD
- Bénéfices bruts = 1 300 USD
Les modèles de distribution binomiale et d'autres distributions de probabilité ne peuvent prédire qu'une approximation qui peut se rapprocher du monde réel en termes de paramètres d'action, « n » et « p ». Cela nous aide à comprendre et à identifier nos domaines d'intervention et à améliorer les chances globales d'amélioration des performances et de l'efficacité.
Lisez aussi: 13 idées de projets de structure de données intéressantes et sujets pour les débutants
Et ensuite ?
Si vous êtes curieux d'en savoir plus sur la science des données, consultez le programme Executive PG en science des données de IIIT-B & upGrad qui est créé pour les professionnels en activité et propose plus de 10 études de cas et projets, des ateliers pratiques, un mentorat avec des experts de l'industrie, 1 -on-1 avec des mentors de l'industrie, plus de 400 heures d'apprentissage et d'aide à l'emploi avec les meilleures entreprises.
Quelle est la différence entre la distribution de probabilité discrète et la distribution de probabilité continue ?
La distribution de probabilité discrète ou simplement la distribution discrète calcule les probabilités d'une variable aléatoire qui peut être discrète. Par exemple, si nous lançons une pièce deux fois, les valeurs probables d'une variable aléatoire X qui indique le nombre total de faces seront {0, 1, 2} et non une valeur aléatoire. Bernoulli, Binomial, Hypergeometric sont quelques exemples de la distribution de probabilité discrète. D'autre part, la distribution de probabilité continue fournit les probabilités d'une valeur aléatoire qui peut être n'importe quel nombre aléatoire. Par exemple, la valeur d'une variable aléatoire X qui indique la taille des citoyens d'une ville peut être n'importe quel nombre comme 161,2, 150,9, etc. Normal, Student's T, Chi-square sont quelques-uns des exemples de distribution continue.
Quelle est l'importance de la probabilité dans la science des données ?
Comme la science des données consiste à étudier les données, la probabilité joue ici un rôle clé. Les raisons suivantes décrivent comment la probabilité est un élément indispensable de la science des données : Elle aide les analystes et les chercheurs à faire des prédictions à partir d'ensembles de données. Ces types de résultats estimés constituent le fondement d'une analyse plus approfondie des données. La probabilité est également utilisée lors du développement d'algorithmes utilisés dans les modèles d'apprentissage automatique. Il aide à analyser les ensembles de données utilisés pour former les modèles. Il vous permet de quantifier les données et de dériver des résultats tels que les dérivées, la moyenne et la distribution. Tous les résultats obtenus en utilisant la probabilité résument finalement les données. Ce résumé aide également à identifier les valeurs aberrantes existantes dans les ensembles de données.
Expliquer la distribution hypergéométrique. Dans quel cas a-t-il tendance à être une distribution binomiale ?
succès sur le nombre d'essais sans aucun remplacement. Disons que nous avons un sac plein de boules rouges et vertes et que nous devons trouver la probabilité de tirer une boule verte en 5 tentatives mais à chaque fois que nous tirons une boule, nous ne la remettons pas dans le sac. Ceci est un bon exemple de la distribution hypergéométrique.
Pour N plus grand, il est très difficile de calculer la distribution hypergéométrique mais lorsque N est petit, il tend vers la distribution binomiale dans ce cas.