
Au-delà du navigateur : Premiers pas avec WebAssembly sans serveur
Publié: 2022-03-10Maintenant que WebAssembly est pris en charge par tous les principaux navigateurs et plus de 85 % des utilisateurs dans le monde, JavaScript n'est plus le seul langage de navigateur en ville. Si vous ne l'avez pas entendu, WebAssembly est un nouveau langage de bas niveau qui s'exécute dans le navigateur. C'est également une cible de compilation, ce qui signifie que vous pouvez compiler des programmes existants écrits dans des langages tels que C, C++ et Rust dans WebAssembly, et exécuter ces programmes dans le navigateur. Jusqu'à présent, WebAssembly a été utilisé pour porter toutes sortes d'applications sur le Web, y compris des applications de bureau, des outils de ligne de commande, des jeux et des outils de science des données.
Remarque : Pour une étude de cas approfondie sur la façon dont WebAssembly peut être utilisé dans le navigateur pour accélérer les applications Web, consultez mon article précédent.
WebAssembly en dehors du Web ?
Bien que la plupart des applications WebAssembly soient aujourd'hui centrées sur le navigateur, WebAssembly lui-même n'a pas été conçu à l'origine uniquement pour le Web, mais vraiment pour n'importe quel environnement en bac à sable. En fait, il y a eu récemment beaucoup d'intérêt à explorer comment WebAssembly pourrait être utile en dehors du navigateur, en tant qu'approche générale pour exécuter des binaires sur n'importe quel système d'exploitation ou architecture informatique, tant qu'il existe un environnement d'exécution WebAssembly qui prend en charge ce système. Dans cet article, nous verrons comment WebAssembly peut être exécuté en dehors du navigateur, de manière serverless/Function-as-a-Service (FaaS).
WebAssembly pour les applications sans serveur
En un mot, les fonctions sans serveur sont un modèle informatique dans lequel vous confiez votre code à un fournisseur de cloud et le laissez exécuter et gérer la mise à l'échelle de ce code pour vous. Par exemple, vous pouvez demander que votre fonction sans serveur soit exécutée chaque fois que vous appelez un point de terminaison d'API, ou qu'elle soit pilotée par des événements, comme lorsqu'un fichier est chargé dans votre compartiment cloud. Bien que le terme "sans serveur" puisse sembler impropre puisque les serveurs sont clairement impliqués quelque part en cours de route, il est sans serveur de notre point de vue puisque nous n'avons pas à nous soucier de la façon de gérer, déployer ou faire évoluer ces serveurs.
Bien que ces fonctions soient généralement écrites dans des langages tels que Python et JavaScript (Node.js), il existe un certain nombre de raisons pour lesquelles vous pourriez choisir d'utiliser WebAssembly à la place :
- Temps d'initialisation plus rapides
Les fournisseurs sans serveur qui prennent en charge WebAssembly (y compris Cloudflare et Fastly signalent qu'ils peuvent lancer des fonctions au moins un ordre de grandeur plus rapidement que la plupart des fournisseurs de cloud avec d'autres langages. Ils y parviennent en exécutant des dizaines de milliers de modules WebAssembly dans le même processus, ce qui est possible car la nature sandbox de WebAssembly permet d'obtenir plus efficacement l'isolement pour lequel les conteneurs sont traditionnellement utilisés. - Aucune réécriture nécessaire
L'un des principaux attraits de WebAssembly dans le navigateur est la possibilité de porter du code existant sur le Web sans avoir à tout réécrire en JavaScript. Cet avantage est toujours vrai dans le cas d'utilisation sans serveur, car les fournisseurs de cloud limitent les langages dans lesquels vous pouvez écrire vos fonctions sans serveur. En règle générale, ils prendront en charge Python, Node.js et peut-être quelques autres, mais certainement pas C, C++ ou Rust. . En prenant en charge WebAssembly, les fournisseurs sans serveur peuvent indirectement prendre en charge beaucoup plus de langues. - Plus léger
Lors de l'exécution de WebAssembly dans le navigateur, nous comptons sur l'ordinateur de l'utilisateur final pour effectuer nos calculs. Si ces calculs sont trop intensifs, nos utilisateurs ne seront pas contents lorsque le ventilateur de leur ordinateur se mettra à ronronner. L'exécution de WebAssembly en dehors du navigateur nous donne les avantages de vitesse et de portabilité de WebAssembly, tout en gardant notre application légère. De plus, puisque nous exécutons notre code WebAssembly dans un environnement plus prévisible, nous pouvons potentiellement effectuer des calculs plus intensifs.
Un exemple concret
Dans mon article précédent ici sur Smashing Magazine, nous avons expliqué comment nous avons accéléré une application Web en remplaçant les calculs JavaScript lents par du code C compilé sur WebAssembly. L'application Web en question était fastq.bio, un outil permettant de prévisualiser la qualité des données de séquençage de l'ADN.
Comme exemple concret, réécrivons fastq.bio comme une application qui utilise WebAssembly sans serveur au lieu d'exécuter WebAssembly dans le navigateur. Pour cet article, nous utiliserons Cloudflare Workers, un fournisseur sans serveur qui prend en charge WebAssembly et est construit sur le moteur de navigateur V8. Un autre fournisseur de cloud, Fastly, travaille sur une offre similaire, mais basée sur leur runtime Lucet.

Tout d'abord, écrivons du code Rust pour analyser la qualité des données de séquençage de l'ADN. Pour plus de commodité, nous pouvons tirer parti de la bibliothèque bioinformatique Rust-Bio pour gérer l'analyse des données d'entrée et de la bibliothèque wasm-bindgen pour nous aider à compiler notre code Rust sur WebAssembly.
Voici un extrait du code qui lit les données de séquençage de l'ADN et génère un JSON avec un résumé des mesures de qualité :
// Import packages extern crate wasm_bindgen; use bio::seq_analysis::gc; use bio::io::fastq; ... // This "wasm_bindgen" tag lets us denote the functions // we want to expose in our WebAssembly module #[wasm_bindgen] pub fn fastq_metrics(seq: String) -> String { ... // Loop through lines in the file let reader = fastq::Reader::new(seq.as_bytes()); for result in reader.records() { let record = result.unwrap(); let sequence = record.seq(); // Calculate simple statistics on each record n_reads += 1.0; let read_length = sequence.len(); let read_gc = gc::gc_content(sequence); // We want to draw histograms of these values // so we store their values for later plotting hist_gc.push(read_gc * 100.0); hist_len.push(read_length); ... } // Return statistics as a JSON blob json!({ "n": n_reads, "hist": { "gc": hist_gc, "len": hist_len }, ... }).to_string() }Nous avons ensuite utilisé l'outil de ligne de commande wrangler de Cloudflare pour effectuer le gros du travail de compilation sur WebAssembly et de déploiement sur le cloud. Une fois cela fait, nous recevons un point de terminaison API qui prend les données de séquençage en entrée et renvoie un JSON avec des métriques de qualité des données. Nous pouvons maintenant intégrer cette API dans notre application.
Voici un GIF de l'application en action :
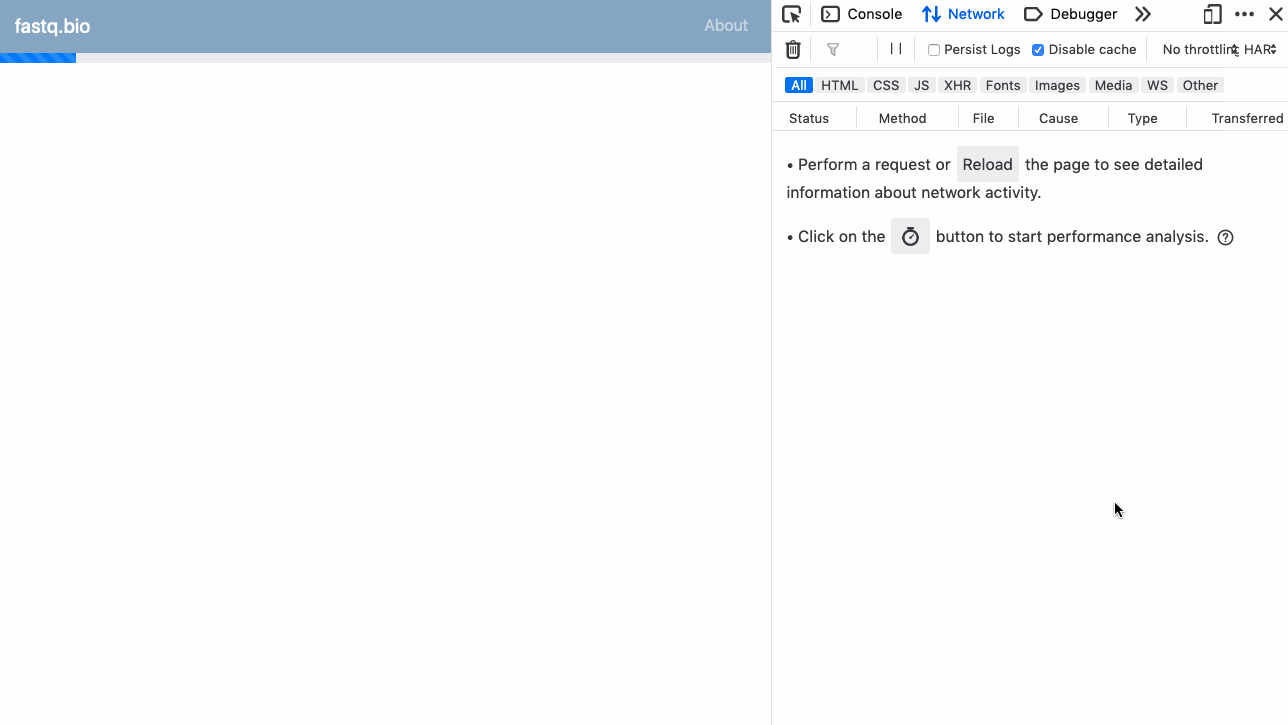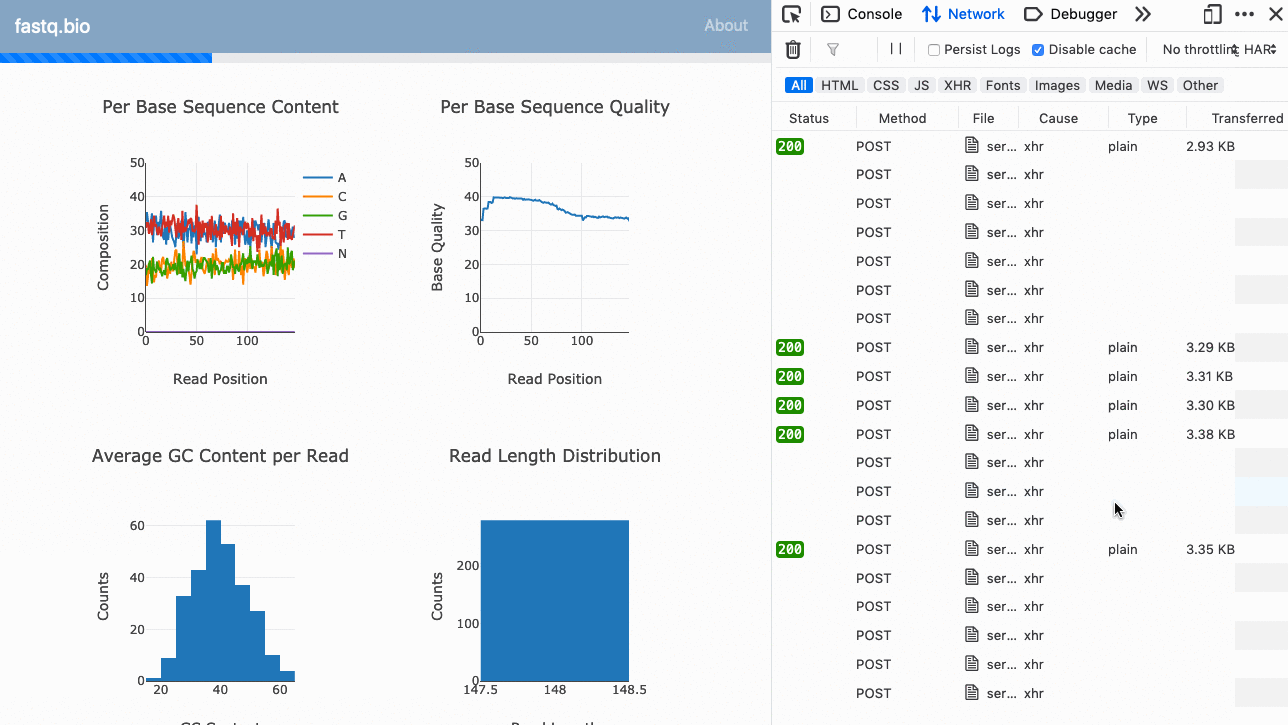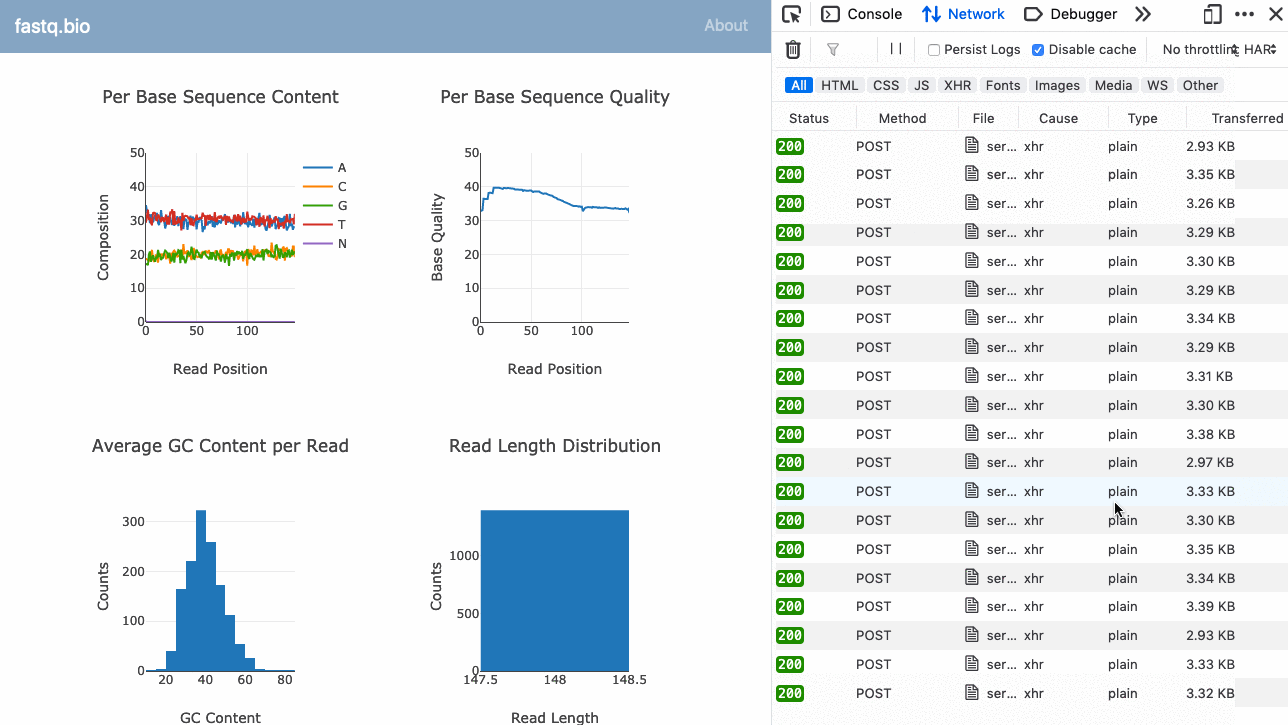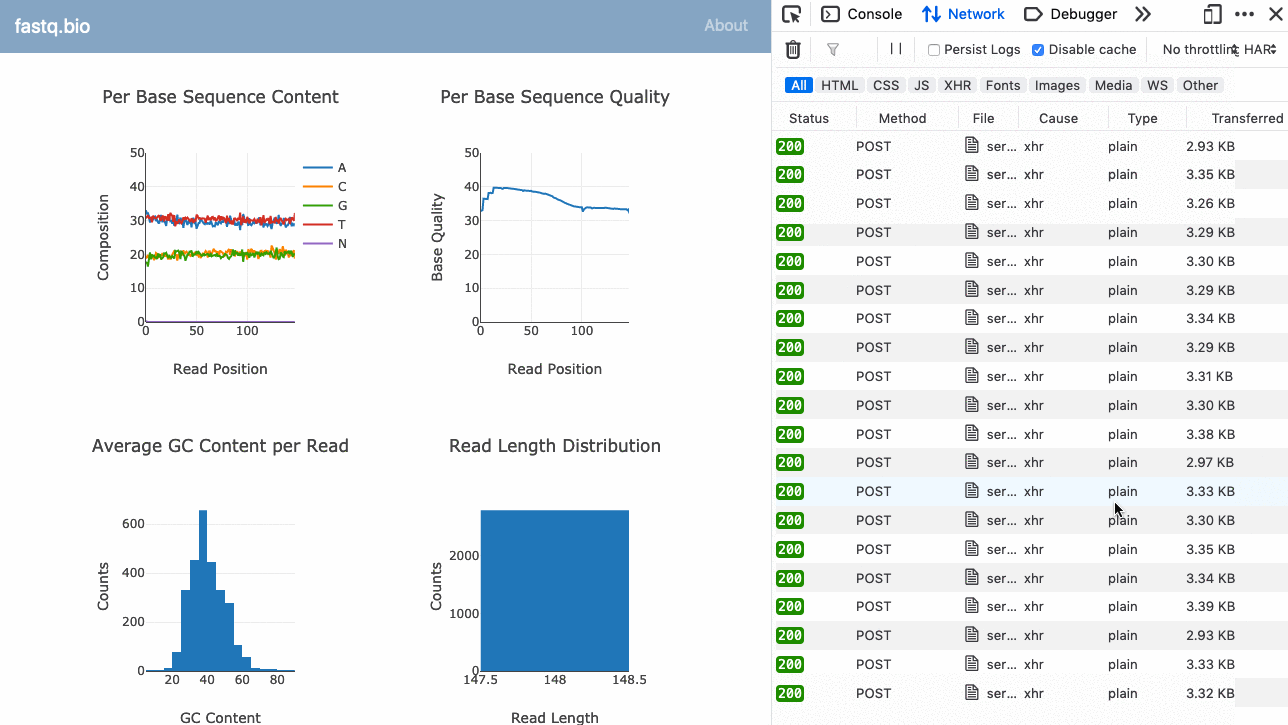
Le code complet est disponible sur GitHub (open-source).
Tout mettre en contexte
Pour mettre en contexte l'approche WebAssembly sans serveur, considérons quatre façons principales de créer des applications Web de traitement de données (c'est-à-dire des applications Web dans lesquelles nous effectuons une analyse des données fournies par l'utilisateur) :
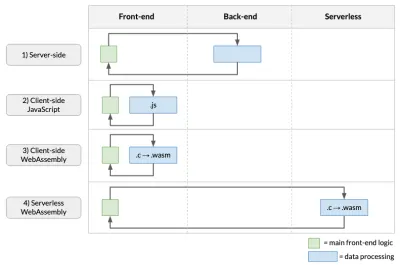
Comme indiqué ci-dessus, le traitement des données peut se faire à plusieurs endroits :
- Du côté serveur
C'est l'approche adoptée par la plupart des applications Web, où les appels d'API effectués dans le traitement des données de lancement front-end sur le back-end. - JavaScript côté client
Dans cette approche, le code de traitement des données est écrit en JavaScript et s'exécute dans le navigateur. L'inconvénient est que vos performances en prendront un coup, et si votre code d'origine n'était pas en JavaScript, vous devrez le réécrire à partir de zéro ! - Assemblage Web côté client
Cela implique de compiler le code d'analyse de données dans WebAssembly et de l'exécuter dans le navigateur. Si le code d'analyse a été écrit dans des langages comme C, C++ ou Rust (comme c'est souvent le cas dans mon domaine de la génomique), cela évite d'avoir à réécrire des algorithmes complexes en JavaScript. Il offre également la possibilité d'accélérer notre application (par exemple, comme indiqué dans un article précédent). - Assemblage Web sans serveur
Cela implique d'exécuter le WebAssembly compilé sur le cloud, en utilisant un type de modèle FaaS (par exemple cet article).
Alors pourquoi choisiriez-vous l'approche sans serveur plutôt que les autres ? D'une part, par rapport à la première approche, elle présente les avantages liés à l'utilisation de WebAssembly, en particulier la possibilité de porter du code existant sans avoir à le réécrire en JavaScript. Par rapport à la troisième approche, WebAssembly sans serveur signifie également que notre application est plus légère car nous n'utilisons pas les ressources de l'utilisateur pour faire des calculs. En particulier, si les calculs sont assez complexes ou si les données sont déjà dans le cloud, cette approche a plus de sens.
D'un autre côté, cependant, l'application doit maintenant établir des connexions réseau, de sorte que l'application sera probablement plus lente. De plus, selon l'échelle du calcul et s'il est possible de le décomposer en éléments d'analyse plus petits, cette approche peut ne pas convenir en raison des limitations imposées par les fournisseurs de cloud sans serveur sur l'exécution, l'UC et l'utilisation de la RAM.
Conclusion
Comme nous l'avons vu, il est désormais possible d'exécuter du code WebAssembly sans serveur et de profiter à la fois des avantages de WebAssembly (portabilité et vitesse) et de ceux des architectures de fonction en tant que service (auto-scaling et tarification à l'utilisation). ). Certains types d'applications, telles que l'analyse de données et le traitement d'images, pour n'en nommer que quelques-unes, peuvent grandement bénéficier d'une telle approche. Bien que le temps d'exécution souffre des allers-retours supplémentaires vers le réseau, cette approche nous permet de traiter plus de données à la fois et de ne pas épuiser les ressources des utilisateurs.