Guide du débutant pour le réseau de neurones convolutifs (CNN)
Publié: 2021-07-05La dernière décennie a vu une croissance phénoménale de l'intelligence artificielle et des machines plus intelligentes. Le domaine a donné naissance à de nombreuses sous-disciplines spécialisées dans des aspects distincts de l'intelligence humaine. Par exemple, le traitement du langage naturel tente de comprendre et de modéliser la parole humaine, tandis que la vision par ordinateur vise à fournir une vision humaine aux machines.
Puisque nous parlerons des réseaux de neurones convolutifs, nous nous concentrerons principalement sur la vision par ordinateur. La vision par ordinateur vise à permettre aux machines de voir le monde comme nous le faisons et de résoudre des problèmes liés à la reconnaissance d'images, à la classification d'images et bien plus encore. Les réseaux de neurones convolutifs sont utilisés pour réaliser diverses tâches de vision par ordinateur. Aussi connus sous le nom de CNN ou ConvNet, ils suivent une architecture qui ressemble aux schémas et aux connexions des neurones du cerveau humain et s'inspirent de divers processus biologiques se produisant dans le cerveau pour permettre la communication.
Table des matières
La signification biologique d'un réseau neuronal alambiqué
Les CNN sont inspirés de notre cortex visuel. C'est la zone du cortex cérébral qui est impliquée dans le traitement visuel de notre cerveau. Le cortex visuel possède diverses petites régions cellulaires sensibles aux stimuli visuels.
Cette idée a été élargie en 1962 par Hubel et Wiesel dans une expérience où il a été constaté que différentes cellules neuronales distinctes répondent (se déclenchent) à la présence de bords distincts d'une orientation spécifique. Par exemple, certains neurones se déclencheraient en détectant des bords horizontaux, d'autres en détectant des bords diagonaux, et d'autres se déclencheraient en détectant des bords verticaux. Grâce à cette expérience. Hubel et Wiesel ont découvert que les neurones sont organisés de manière modulaire et que tous les modules sont nécessaires pour produire la perception visuelle.
Cette approche modulaire - l'idée que des composants spécialisés à l'intérieur d'un système ont des tâches spécifiques - est à la base des CNN.
Ceci étant réglé, passons à la façon dont les CNN apprennent à percevoir les entrées visuelles.

Apprentissage par réseau neuronal convolutif
Les images sont composées de pixels individuels, qui sont une représentation entre les nombres 0 et 255. Ainsi, toute image que vous voyez peut être convertie en une représentation numérique appropriée en utilisant ces nombres - et c'est ainsi que les ordinateurs fonctionnent également avec les images.
Voici quelques opérations majeures qui entrent dans l'apprentissage d'un CNN pour la détection ou la classification d'images. Cela vous donnera une idée de la façon dont l'apprentissage se déroule dans les CNN.
1. Convolution
La convolution peut mathématiquement être comprise comme l'intégration combinée de deux fonctions différentes pour découvrir comment l'influence de la fonction différente ou se modifie l'une l'autre. Voici comment cela peut être défini en termes mathématiques :
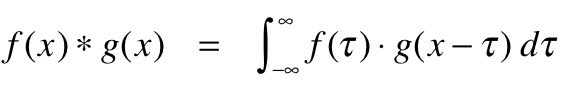
Le but de la convolution est de détecter différentes caractéristiques visuelles dans les images, comme les lignes, les bords, les couleurs, les ombres, etc. Il s'agit d'une propriété très utile car une fois que votre CNN a appris les caractéristiques d'une caractéristique particulière de l'image, il peut ensuite reconnaître cette caractéristique dans n'importe quelle autre partie de l'image.
Les CNN utilisent des noyaux ou des filtres pour détecter les différentes fonctionnalités présentes dans une image. Les noyaux ne sont qu'une matrice de valeurs distinctes (appelées poids dans le monde des réseaux de neurones artificiels) formées pour détecter des caractéristiques spécifiques. Le filtre se déplace sur toute l'image pour vérifier si la présence d'une caractéristique est détectée ou non. Le filtre effectue l'opération de convolution pour fournir une valeur finale qui représente le niveau de confiance qu'une caractéristique particulière est présente.
Si une caractéristique est présente dans l'image, le résultat de l'opération de convolution est un nombre positif avec une valeur élevée. Si la caractéristique est absente, l'opération de convolution donne soit 0, soit un nombre de très faible valeur.
Comprenons cela mieux à l'aide d'un exemple. Dans l'image ci-dessous, un filtre a été formé pour détecter un signe plus. Ensuite, le filtre passe sur l'image d'origine. Puisqu'une partie de l'image d'origine contient les mêmes caractéristiques pour lesquelles le filtre est formé, les valeurs de chaque cellule où la caractéristique existe est un nombre positif. De même, le résultat d'une opération de convolution se traduira également par un grand nombre.
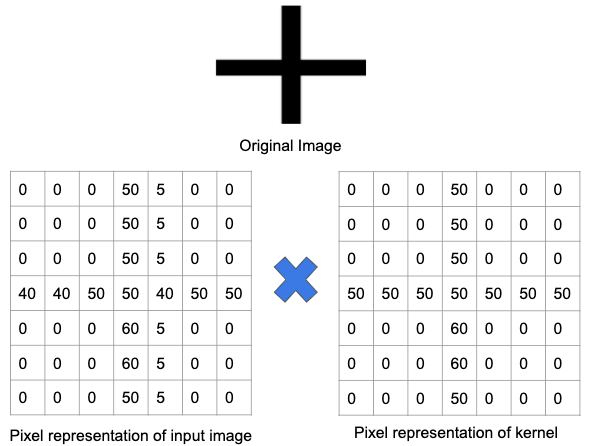
Cependant, lorsque le même filtre est passé sur une image avec un ensemble différent de caractéristiques et de bords, la sortie d'une opération de convolution sera plus faible, ce qui implique qu'il n'y avait pas de forte présence de signe plus dans l'image.
Ainsi, dans le cas d'images complexes ayant diverses caractéristiques telles que des courbes, des bords, des couleurs, etc., nous aurons besoin d'un nombre N de ces détecteurs de caractéristiques.
Lorsque ce filtre est passé à travers l'image, une carte de caractéristiques est générée qui est essentiellement la matrice de sortie qui stocke les convolutions de ce filtre sur différentes parties de l'image. Dans le cas de nombreux filtres, nous nous retrouverons avec une sortie 3D. Ce filtre doit avoir le même nombre de canaux que l'image d'entrée pour que l'opération de convolution ait lieu.
En outre, un filtre peut être glissé sur l'image d'entrée à différents intervalles, en utilisant une valeur de foulée. La valeur de foulée indique de combien le filtre doit se déplacer à chaque pas.
Le nombre de couches de sortie d'un bloc convolutif donné peut donc être déterminé à l'aide de la formule suivante :

2. Rembourrage
Un problème lors de l'utilisation de calques convolutifs est que certains pixels ont tendance à être perdus sur le périmètre de l'image d'origine. Étant donné que généralement, les filtres utilisés sont petits, les pixels perdus par filtre peuvent être peu nombreux, mais cela s'additionne lorsque nous appliquons différentes couches convolutionnelles, ce qui entraîne la perte de nombreux pixels.
Le concept de rembourrage consiste à ajouter des pixels supplémentaires à l'image pendant qu'un filtre d'un CNN la traite. C'est une solution pour aider le filtre dans le traitement d'image - en remplissant l'image avec des zéros pour laisser plus d'espace au noyau pour couvrir toute l'image. En ajoutant zéro rembourrage aux filtres, le traitement d'image par CNN est beaucoup plus précis et exact.
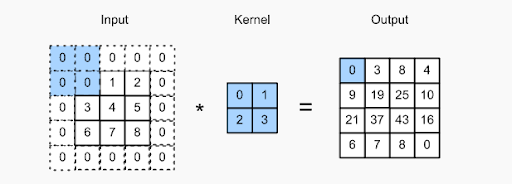

Vérifiez l'image ci-dessus - le remplissage a été effectué en ajoutant des zéros supplémentaires à la limite de l'image d'entrée. Cela permet de capturer toutes les caractéristiques distinctes sans perdre de pixels.
3. Carte d'activation
Les cartes d'entités doivent passer par une fonction de mappage de nature non linéaire. Les cartes de caractéristiques sont incluses avec un terme de biais, puis transmises par la fonction d'activation (ReLu), qui est non linéaire. Cette fonction vise à apporter une certaine non-linéarité dans le CNN puisque les images qui sont détectées et examinées sont également de nature non linéaire, étant composées de différents objets.
4. Étape de mise en commun
Une fois la phase d'activation terminée, nous passons à l'étape de regroupement, dans laquelle le CNN sous-échantillonne les caractéristiques convoluées, ce qui permet de gagner du temps de traitement. Cela aide également à réduire la taille globale de l'image, le surajustement et d'autres problèmes qui surviendraient si les réseaux de neurones convolutés étaient alimentés avec beaucoup d'informations, en particulier si ces informations ne sont pas trop pertinentes pour classer ou détecter l'image.
La mise en commun est essentiellement de deux types - la mise en commun maximale et la mise en commun minimale. Dans le premier cas, une fenêtre est passée sur l'image en fonction d'une valeur de foulée définie, et à chaque étape, la valeur maximale incluse dans la fenêtre est regroupée dans la matrice de sortie. Dans le min pooling, les valeurs minimales sont regroupées dans la matrice de sortie.
La nouvelle matrice formée à la suite des sorties s'appelle une carte d'entités regroupées.
En dehors de la mise en commun minimale et maximale, l'un des avantages de la mise en commun maximale est qu'elle permet au CNN de se concentrer sur quelques neurones qui ont des valeurs élevées au lieu de se concentrer sur tous les neurones. Une telle approche rend très moins probable le surajustement des données d'entraînement et permet à la prédiction et à la généralisation globales de bien se passer.
5. Aplatir
Une fois la mise en commun terminée, la représentation 3D de l'image a maintenant été convertie en un vecteur de caractéristiques. Celui-ci est ensuite passé dans un perceptron multicouche pour produire la sortie. Consultez l'image ci-dessous pour mieux comprendre l'opération d'aplatissement :
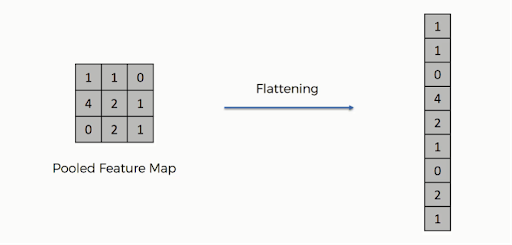
Comme vous pouvez le voir, les lignes de la matrice sont concaténées en un seul vecteur de caractéristiques. Si plusieurs couches en entrée sont présentes, toutes les lignes sont connectées pour former un vecteur de caractéristiques aplati plus long.
6. Couche entièrement connectée (FCL)
Dans cette étape, la carte aplatie est transmise à un réseau de neurones. La connexion complète d'un réseau neuronal comprend une couche d'entrée, le FCL, et une couche de sortie finale. La couche entièrement connectée peut être comprise comme les couches cachées dans les réseaux de neurones artificiels, sauf que, contrairement aux couches cachées, ces couches sont entièrement connectées. L'information traverse tout le réseau et une erreur de prédiction est calculée. Cette erreur est ensuite envoyée sous forme de rétroaction (rétropropagation) à travers les systèmes pour ajuster les poids et améliorer la sortie finale, afin de la rendre plus précise.
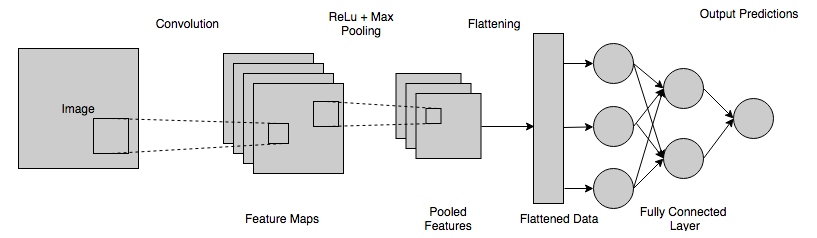
La sortie finale obtenue à partir de la couche ci-dessus du réseau neuronal ne correspond généralement pas à un. Ces sorties doivent être ramenées à des nombres dans la plage de [0,1] - qui représenteront alors les probabilités de chaque classe. Pour cela, la fonction Softmax est utilisée.
La sortie obtenue à partir de la couche dense est transmise à la fonction d'activation Softmax. Grâce à cela, toutes les sorties finales sont mappées sur un vecteur où la somme de tous les éléments devient un.
La couche entièrement connectée fonctionne en examinant la sortie de la couche précédente, puis en déterminant quelle caractéristique est la plus corrélée à une classe spécifique. Ainsi, si le programme prédit si une image contient ou non un chat, elle aura des valeurs élevées dans les cartes d'activation qui représentent des caractéristiques telles que quatre pattes, pattes, queue, etc. De même, si le programme prédit autre chose, il aura différents types de cartes d'activation. Une couche entièrement connectée prend en charge les différentes caractéristiques qui sont fortement corrélées à des classes et des pondérations particulières afin que le calcul entre les pondérations et la couche précédente soit précis et que vous obteniez des probabilités correctes pour des classes de sortie distinctes.
Un bref résumé du fonctionnement des CNN
Voici un bref résumé de l'ensemble du processus de fonctionnement de CNN et d'aide à la vision par ordinateur :
- Les différents pixels de l'image sont envoyés à la couche convolutive, où une opération de convolution est effectuée.
- L'étape précédente donne une carte convoluée.
- Cette carte est passée par une fonction redresseuse pour donner lieu à une carte rectifiée.
- L'image est traitée avec différentes convolutions et fonctions d'activation pour localiser et détecter différentes caractéristiques.
- Les couches de regroupement sont utilisées pour identifier des parties spécifiques et distinctes de l'image.
- La couche regroupée est aplatie et utilisée comme entrée de la couche entièrement connectée.
- La couche entièrement connectée calcule les probabilités et donne une sortie dans la plage de [0,1].
En conclusion
Le fonctionnement interne de CNN est très excitant et ouvre de nombreuses possibilités d'innovation et de création. De même, d'autres technologies sous l'égide de l'intelligence artificielle sont fascinantes et tentent de travailler entre les capacités humaines et l'intelligence artificielle. Par conséquent, des personnes du monde entier, appartenant à différents domaines, réalisent leur intérêt pour ce domaine et font les premiers pas.
Heureusement, l'industrie de l'IA est exceptionnellement accueillante et ne fait pas de distinction en fonction de votre parcours universitaire. Tout ce dont vous avez besoin est une connaissance pratique des technologies ainsi que des qualifications de base, et le tour est joué !
Si vous souhaitez maîtriser les moindres détails du ML et de l'IA, la marche à suivre idéale serait de vous inscrire à un programme professionnel d'IA/ML. Par exemple, notre programme exécutif en apprentissage automatique et IA est le cours idéal pour les aspirants en science des données. Le programme couvre des sujets tels que les statistiques et l'analyse exploratoire des données, l'apprentissage automatique et le traitement du langage naturel. En outre, il comprend plus de 13 projets industriels, plus de 25 sessions en direct et 6 projets de synthèse. La meilleure partie de ce cours est que vous pouvez interagir avec des pairs du monde entier. Il facilite l'échange d'idées et aide les apprenants à établir des liens durables avec des personnes d'horizons divers. Notre assistance professionnelle à 360 degrés est exactement ce dont vous avez besoin pour exceller dans votre parcours ML et IA !
Menez la révolution technologique basée sur l'IA