
6 fonctionnalités révolutionnaires d'Apache Spark en 2022 [Comment devriez-vous utiliser]
Publié: 2021-01-07Depuis que le Big Data a pris d'assaut les mondes de la technologie et des affaires, il y a eu une énorme recrudescence des outils et des plateformes de Big Data, en particulier d'Apache Hadoop et d'Apache Spark. Aujourd'hui, nous allons nous concentrer uniquement sur Apache Spark et discuter longuement de ses avantages commerciaux et de ses applications.
Apache Spark est apparu sous les feux de la rampe en 2009, et depuis, il s'est progressivement taillé une place dans l'industrie. Selon Apache org., Spark est un "moteur d'analyse unifié ultra-rapide" conçu pour traiter des quantités colossales de Big Data. Grâce à une communauté active, Spark est aujourd'hui l'une des plus grandes plateformes de Big Data open-source au monde.
Table des matières
Qu'est-ce qu'Apache Spark ?
Développé à l'origine dans l'AMPLab de l'Université de Californie (Berkeley), Spark a été conçu comme un moteur de traitement robuste pour les données Hadoop, avec un accent particulier sur la vitesse et la facilité d'utilisation. C'est une alternative open-source à MapReduce de Hadoop. Spark est essentiellement un framework de traitement de données parallèle qui peut collaborer avec Apache Hadoop pour faciliter le développement fluide et rapide d'applications Big Data sophistiquées sur Hadoop.
Spark est livré avec une large gamme de bibliothèques pour les algorithmes d'apprentissage automatique (ML) et les algorithmes de graphes. Non seulement cela, il prend également en charge le streaming en temps réel et les applications SQL via Spark Streaming et Shark, respectivement. La meilleure partie de l'utilisation de Spark est que vous pouvez écrire des applications Spark en Java, Scala ou même Python, et ces applications s'exécuteront presque dix fois plus rapidement (sur disque) et 100 fois plus rapidement (en mémoire) que les applications MapReduce.
Apache Spark est assez polyvalent car il peut être déployé de plusieurs façons, et il offre également des liaisons natives pour les langages de programmation Java, Scala, Python et R. Il prend en charge SQL, le traitement de graphes, le streaming de données et l'apprentissage automatique. C'est pourquoi Spark est largement utilisé dans divers secteurs de l'industrie, notamment les banques, les sociétés de télécommunications, les sociétés de développement de jeux, les agences gouvernementales et, bien sûr, dans toutes les grandes entreprises du monde de la technologie - Apple, Facebook, IBM et Microsoft.
6 meilleures fonctionnalités d'Apache Spark
Les fonctionnalités qui font de Spark l'une des plateformes Big Data les plus utilisées sont :

1. Vitesse de traitement ultra-rapide
Le traitement du Big Data consiste à traiter de gros volumes de données complexes. Par conséquent, en ce qui concerne le traitement du Big Data, les organisations et les entreprises veulent de tels cadres capables de traiter des quantités massives de données à grande vitesse. Comme nous l'avons mentionné précédemment, les applications Spark peuvent s'exécuter jusqu'à 100 fois plus vite en mémoire et 10 fois plus vite sur disque dans les clusters Hadoop.
Il s'appuie sur Resilient Distributed Dataset (RDD) qui permet à Spark de stocker de manière transparente des données en mémoire et de les lire/écrire sur disque uniquement si nécessaire. Cela permet de réduire la majeure partie du temps de lecture et d'écriture du disque pendant le traitement des données.
2. Facilité d'utilisation
Spark vous permet d'écrire des applications évolutives en Java, Scala, Python et R. Ainsi, les développeurs ont la possibilité de créer et d'exécuter des applications Spark dans leurs langages de programmation préférés. De plus, Spark est équipé d'un ensemble intégré de plus de 80 opérateurs de haut niveau. Vous pouvez utiliser Spark de manière interactive pour interroger les données des shells Scala, Python, R et SQL.
3. Il offre un support pour des analyses sophistiquées
Non seulement Spark prend en charge les opérations simples de « mappage » et de « réduction », mais il prend également en charge les requêtes SQL, les données en continu et les analyses avancées, y compris les algorithmes de ML et de graphe. Il est livré avec une puissante pile de bibliothèques telles que SQL & DataFrames et MLlib (pour ML), GraphX et Spark Streaming. Ce qui est fascinant, c'est que Spark vous permet de combiner les capacités de toutes ces bibliothèques au sein d'un seul workflow/application.
4. Traitement de flux en temps réel
Spark est conçu pour gérer le streaming de données en temps réel. Alors que MapReduce est conçu pour gérer et traiter les données déjà stockées dans les clusters Hadoop, Spark peut faire les deux et également manipuler les données en temps réel via Spark Streaming.
Contrairement à d'autres solutions de streaming, Spark Streaming peut récupérer le travail perdu et fournir la sémantique exacte prête à l'emploi sans nécessiter de code ou de configuration supplémentaire. De plus, il vous permet également de réutiliser le même code pour le traitement par lots et par flux et même pour joindre des données en continu à des données historiques.
5. Il est flexible
Spark peut fonctionner indépendamment en mode cluster, et il peut également fonctionner sur Hadoop YARN, Apache Mesos, Kubernetes et même dans le cloud. De plus, il peut accéder à diverses sources de données. Par exemple, Spark peut s'exécuter sur le gestionnaire de cluster YARN et lire toutes les données Hadoop existantes. Il peut lire à partir de n'importe quelle source de données Hadoop comme HBase, HDFS, Hive et Cassandra. Cet aspect de Spark en fait un outil idéal pour migrer des applications Hadoop pures, à condition que le cas d'utilisation des applications soit compatible avec Spark.
6. Communauté active et en expansion
Les développeurs de plus de 300 entreprises ont contribué à la conception et à la construction d'Apache Spark. Depuis 2009, plus de 1200 développeurs ont activement contribué à faire de Spark ce qu'il est aujourd'hui ! Naturellement, Spark est soutenu par une communauté active de développeurs qui travaillent continuellement à l'amélioration de ses fonctionnalités et de ses performances. Pour contacter la communauté Spark, vous pouvez utiliser des listes de diffusion pour toute question, et vous pouvez également assister à des groupes de rencontre et à des conférences Spark.
L'anatomie des applications Spark
Chaque application Spark comprend deux processus principaux : un processus pilote principal et un ensemble de processus exécuteurs .
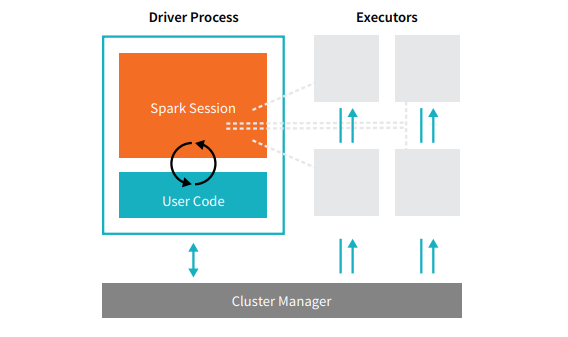
La source

Le processus du pilote qui se trouve sur un nœud du cluster est responsable de l'exécution de la fonction main(). Il gère également trois autres tâches : maintenir les informations sur l'application Spark, répondre au code ou à l'entrée d'un utilisateur, et analyser, distribuer et planifier le travail entre les exécuteurs. Le processus du pilote constitue le cœur d'une application Spark - il contient et conserve toutes les informations critiques couvrant la durée de vie de l'application Spark.
Les exécuteurs ou processus exécuteurs sont des éléments secondaires qui doivent exécuter la tâche qui leur est assignée par le driver. Fondamentalement, chaque exécuteur remplit deux fonctions cruciales : exécuter le code qui lui est attribué par le pilote et signaler l'état du calcul (sur cet exécuteur) au nœud du pilote. Les utilisateurs peuvent décider et configurer le nombre d'exécuteurs que chaque nœud doit avoir.
Dans une application Spark, le gestionnaire de cluster contrôle toutes les machines et alloue des ressources à l'application. Ici, le gestionnaire de cluster peut être n'importe lequel des principaux gestionnaires de cluster de Spark, y compris YARN (le gestionnaire de cluster autonome de Spark) ou Mesos. Cela implique qu'un cluster peut exécuter plusieurs applications Spark simultanément.
Applications Apache Spark du monde réel
Spark est une plate-forme Big Dara de premier ordre et largement utilisée dans l'industrie moderne. Certains des exemples réels les plus acclamés d'applications Apache Spark sont :
Étincelle pour l'apprentissage automatique
Apache Spark se vante d'une bibliothèque évolutive d'apprentissage automatique - MLlib. Cette bibliothèque est explicitement conçue pour la simplicité, l'évolutivité et la facilitation d'une intégration transparente avec d'autres outils. MLlib possède non seulement l'évolutivité, la compatibilité linguistique et la vitesse de Spark, mais il peut également effectuer une multitude de tâches d'analyse avancées telles que la classification, le clustering, la réduction de la dimensionnalité. Grâce à MLlib, Spark peut être utilisé pour l'analyse prédictive, l'analyse des sentiments, la segmentation des clients et l'intelligence prédictive.
Une autre caractéristique impressionnante d'Apache Spark réside dans le domaine de la sécurité du réseau. Spark Streaming permet aux utilisateurs de surveiller les paquets de données en temps réel avant de les transférer vers le stockage. Au cours de ce processus, il peut identifier avec succès toute activité suspecte ou malveillante provenant de sources de menace connues. Même après l'envoi des paquets de données au stockage, Spark utilise MLlib pour analyser les données plus en détail et identifier les risques potentiels pour le réseau. Cette fonctionnalité peut également être utilisée pour détecter les fraudes et les événements.
Spark pour le Fog Computing
Apache Spark est un excellent outil pour le fog computing, en particulier lorsqu'il concerne l'Internet des objets (IoT). L'IoT s'appuie fortement sur le concept de traitement parallèle à grande échelle. Étant donné que le réseau IoT est composé de milliers et de millions d'appareils connectés, les données générées par ce réseau chaque seconde dépassent l'entendement.
Naturellement, pour traiter de si gros volumes de données produites par des appareils IoT, vous avez besoin d'une plate-forme évolutive prenant en charge le traitement parallèle. Et quoi de mieux que l'architecture robuste et les capacités de calcul de brouillard de Spark pour gérer de telles quantités de données !
Le Fog Computing décentralise les données et le stockage, et au lieu d'utiliser le traitement cloud, il exécute la fonction de traitement des données à la périphérie du réseau (principalement intégré dans les appareils IoT).
Pour ce faire, le fog computing nécessite trois capacités, à savoir une faible latence, un traitement parallèle du ML et des algorithmes complexes d'analyse de graphes, chacun étant présent dans Spark. De plus, la présence de Spark Streaming, Shark (un outil de requête interactif qui peut fonctionner en temps réel), MLlib et GraphX (un moteur d'analyse de graphes) améliore encore la capacité de calcul du brouillard de Spark.
Spark pour l'analyse interactive
Contrairement à MapReduce, Hive ou Pig, qui ont une vitesse de traitement relativement faible, Spark peut se vanter d'une analyse interactive à grande vitesse. Il est capable de gérer des requêtes exploratoires sans nécessiter d'échantillonnage des données. De plus, Spark est compatible avec presque tous les langages de développement populaires, notamment R, Python, SQL, Java et Scala.
La dernière version de Spark – Spark 2.0 – propose une nouvelle fonctionnalité connue sous le nom de Structured Streaming. Grâce à cette fonctionnalité, les utilisateurs peuvent exécuter des requêtes structurées et interactives sur des données en continu en temps réel.
Utilisateurs de Spark
Maintenant que vous connaissez bien les fonctionnalités et les capacités de Spark, parlons des quatre principaux utilisateurs de Spark !
1.Yahoo
Yahoo utilise Spark pour deux de ses projets, l'un pour personnaliser les pages d'actualités pour les visiteurs et l'autre pour exécuter des analyses pour la publicité. Pour personnaliser les pages d'actualités, Yahoo utilise des algorithmes ML avancés exécutés sur Spark pour comprendre les intérêts, les préférences et les besoins des utilisateurs individuels et catégoriser les histoires en conséquence.
Pour le deuxième cas d'utilisation, Yahoo exploite la capacité interactive de Hive on Spark (pour s'intégrer à tout outil qui se connecte à Hive) pour afficher et interroger les données analytiques publicitaires de Yahoo recueillies sur Hadoop.
2.Uber
Uber utilise Spark Streaming en combinaison avec Kafka et HDFS pour ETL (extraire, transformer et charger) de grandes quantités de données en temps réel d'événements discrets en données structurées et utilisables pour une analyse plus approfondie. Ces données aident Uber à concevoir des solutions améliorées pour les clients.

3. Convivialité
En tant que société de streaming vidéo, Conviva obtient en moyenne plus de 4 millions de flux vidéo chaque mois, ce qui entraîne un taux de désabonnement massif des clients. Ce défi est encore aggravé par le problème de la gestion du trafic vidéo en direct. Pour lutter efficacement contre ces défis, Conviva utilise Spark Streaming pour connaître les conditions du réseau en temps réel et optimiser son trafic vidéo en conséquence. Cela permet à Conviva de fournir une expérience de visionnage cohérente et de haute qualité aux utilisateurs.
4. Pinterest
Sur Pinterest, les utilisateurs peuvent épingler leurs sujets favoris au gré de leurs envies tout en surfant sur le Web et les réseaux sociaux. Pour offrir une expérience client personnalisée et améliorée, Pinterest utilise les capacités ETL de Spark pour identifier les besoins et les intérêts uniques des utilisateurs individuels et leur fournir des recommandations pertinentes sur Pinterest.
Conclusion
Pour conclure, Spark est une plateforme Big Data extrêmement polyvalente avec des fonctionnalités conçues pour impressionner. Puisqu'il s'agit d'un framework open-source, il s'améliore et évolue continuellement, avec de nouvelles fonctionnalités et fonctionnalités qui y sont ajoutées. Au fur et à mesure que les applications du Big Data se diversifient et s'étendent, les cas d'utilisation d'Apache Spark le deviendront également.
Si vous souhaitez en savoir plus sur le Big Data, consultez notre programme PG Diploma in Software Development Specialization in Big Data qui est conçu pour les professionnels en activité et fournit plus de 7 études de cas et projets, couvre 14 langages et outils de programmation, pratique pratique ateliers, plus de 400 heures d'apprentissage rigoureux et d'aide au placement dans les meilleures entreprises.
Consultez nos autres cours de génie logiciel sur upGrad.