
Architecture Apache Kafka : guide complet pour les débutants [2022]
Publié: 2021-12-23Avant de nous plonger dans les détails de l'architecture Apache Kafka, il est pertinent de faire la lumière sur les raisons pour lesquelles Kafka fait les gros titres en premier lieu. Pour commencer, Apache Kafka trouve principalement une utilisation dans les architectures de données de streaming en temps réel pour fournir des analyses en temps réel. Durable, rapide, évolutif et tolérant aux pannes, le système de messagerie de publication-abonnement de Kafka a des cas d'utilisation pour des choses comme le suivi des données des capteurs IoT ou le suivi des appels de service.
Des entreprises comme LinkedIn, Netflix, Microsoft, Uber, Spotify, Goldman Sachs, Cisco, PayPal et bien d'autres utilisent Apache Kafka pour traiter les données de streaming en temps réel. Par exemple, LinkedIn, d'où Kafka est originaire, l'utilise pour suivre les mesures opérationnelles et les données d'activité. De même, pour Netflix, Apache Kafka est la norme de facto pour ses besoins de messagerie, d'événements et de traitement de flux.
Apprenez la formation en développement de logiciels en ligne des meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.
L'utilité d'Apache Kafka est mieux appréciée avec une compréhension de l'architecture Apache Kafka et de ses composants sous-jacents. Alors, explorons les détails de l'architecture de Kafka.
Table des matières
Concepts fondamentaux de l'architecture Kafka
Les concepts suivants sont fondamentaux pour comprendre l'architecture Apache Kafka :
1. Sujets
Les rubriques Kafka définissent les canaux par lesquels les données sont diffusées. Ainsi, les producteurs publient des messages sur les sujets et les consommateurs lisent les messages des sujets auxquels ils sont abonnés. Il n'y a pas de limite au nombre de sujets créés dans un cluster Kafka, et un nom unique identifie chaque sujet.

2. Courtiers
Les courtiers sont des serveurs dans un cluster Kafka qui fonctionnent comme des conteneurs et contiennent plusieurs sujets avec des partitions distinctes. Un identifiant entier unique identifie les courtiers dans un cluster Kafka, et une connexion avec l'un de ces courtiers signifie une connexion avec l'ensemble du cluster.
3. Cloisons
Les sujets Kafka sont divisés en plusieurs parties appelées partitions. Les partitions sont séparées dans l'ordre et permettent à plusieurs consommateurs de lire les données d'un sujet particulier en parallèle. Les partitions d'un sujet sont réparties sur plusieurs serveurs du cluster Kafka, et chaque serveur gère les données et les requêtes pour son lot de partitions. Les messages atteignent le courtier et une clé, et la clé détermine la partition à laquelle le message particulier ira. Par conséquent, les messages avec la même clé vont dans la même partition. Dans le cas où la clé n'est pas spécifiée, la partition est décidée selon une approche circulaire.
4. Répliques
Dans Kafka, les répliques sont comme des sauvegardes de partition pour garantir l'absence de perte de données en cas d'arrêt ou de panne planifié. En d'autres termes, les répliques sont des copies de partitions.
5. Décalages de partition
Étant donné que les messages ou les enregistrements dans Kafka sont affectés à des partitions, chaque enregistrement est fourni avec un décalage pour spécifier sa position dans la partition. Ainsi, la valeur de décalage associée à un enregistrement facilite son identification au sein de la partition. Un décalage de partition n'a de sens que dans cette partition particulière, et puisque les enregistrements sont ajoutés aux extrémités de la partition, les enregistrements plus anciens auront des valeurs de décalage inférieures.
6. Producteurs
Les producteurs Kafka publient des messages sur un ou plusieurs sujets et envoient des données au cluster Kafka. Dès qu'un producteur publie un message dans un sujet Kafka, le courtier reçoit le message et l'ajoute à une partition spécifique. Ensuite, les producteurs peuvent choisir la partition où ils souhaitent publier leur message.
7. Consommateurs et groupes de consommateurs
Les consommateurs lisent les messages du cluster Kafka. Lorsqu'un consommateur est prêt à recevoir le message, les données sont extraites du courtier. Les consommateurs appartiennent à un groupe de consommateurs, et chaque consommateur au sein d'un groupe particulier est responsable de la lecture d'un sous-ensemble des partitions de chaque sujet auquel il est abonné.
8. Leader et suiveur
Chaque partition Kafka a un serveur jouant le rôle de leader. Le leader effectue toutes les tâches de lecture et d'écriture pour cette partition particulière. D'autre part, le travail du suiveur est de répliquer les données du leader. Lorsqu'un leader d'une partition spécifique tombe en panne, l'un des nœuds suiveurs assume le rôle de leader. Une partition peut avoir aucun ou plusieurs abonnés.
Le schéma suivant est une présentation simplifiée des interrelations entre les composants de l'architecture Apache Kafka évoqués ci-dessus.
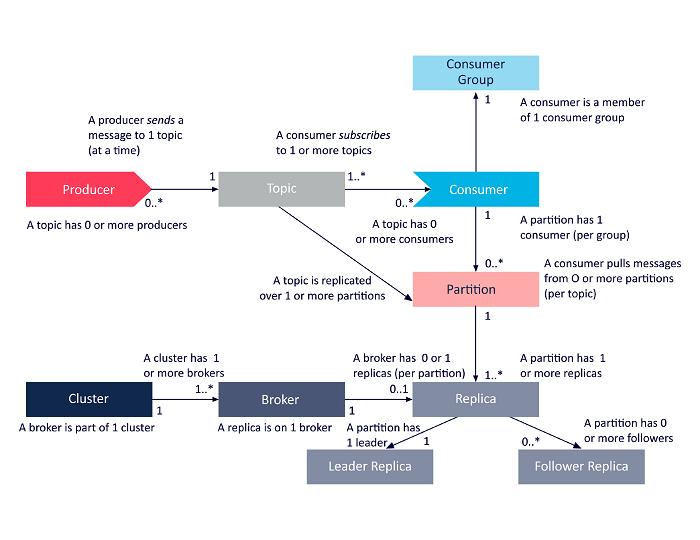
La source
Architecture de cluster Apache Kafka
Voici un aperçu détaillé des principaux composants architecturaux de Kafka :

1. Courtiers Kafka
Les clusters Kafka contiennent généralement plusieurs nœuds appelés courtiers. Les courtiers maintiennent l'équilibre de la charge. Chaque courtier Kafka peut gérer des centaines et des milliers de lectures et d'écritures chaque seconde. Un courtier sert de leader pour une partition particulière. Le leader a un ou plusieurs suiveurs, les données sur le leader étant répliquées sur les suiveurs de cette partition particulière.
Les abonnés doivent rester à jour avec les données du leader. Le leader, à son tour, garde une trace des suiveurs qui sont synchronisés avec lui. Si un suiveur ne rattrape pas le leader ou n'est plus en vie, il est supprimé de la liste des répliques synchronisées associées au leader particulier. Un nouveau chef est élu parmi les partisans à la mort du chef, et le ZooKeeper supervise l'élection. Étant donné que les courtiers sont sans état, le ZooKeeper conserve son état de cluster. Les nœuds d'un cluster envoient des messages de pulsation au ZooKeeper pour informer ce dernier qu'ils sont en vie.
2. Producteurs de Kafka
Les producteurs de Kafka envoient directement des données aux courtiers qui jouent le rôle de leader pour une partition particulière. Les courtiers ou nœuds des clusters Kafka aident les producteurs à envoyer des messages directs. Pour ce faire, ils répondent aux demandes de métadonnées sur lesquelles les serveurs sont actifs et à l'état en direct des chefs de partition d'un sujet, permettant au producteur d'orienter ses demandes en conséquence. Le producteur décide de la partition sur laquelle il souhaite publier les messages. Les messages dans Kafka sont envoyés par lots, appelés lots d'enregistrements. Les producteurs collectent les messages en mémoire et les envoient par lots soit après qu'une période fixe s'est écoulée, soit après qu'un certain nombre de messages se sont accumulés.
3. Consommateurs Kafka
Les consommateurs Kafka envoient des requêtes aux courtiers indiquant les partitions qu'ils souhaitent consommer. Le consommateur spécifie le décalage de partition dans sa demande et reçoit un morceau de journal (à partir de la position de décalage) du courtier. Un journal contient les enregistrements pour une période configurable appelée période de rétention.
Les consommateurs peuvent également réutiliser les données tant que le journal contient les données. Les consommateurs Kafka travaillent sur une approche basée sur l'extraction, ce qui signifie que les courtiers ne transmettent pas immédiatement les données aux consommateurs. Au lieu de cela, les consommateurs envoient d'abord des demandes aux courtiers signalant qu'ils sont prêts à consommer des données. Par conséquent, le système basé sur l'extraction garantit que les consommateurs ne sont pas submergés de messages et peuvent rattraper leur retard s'ils prennent du retard.
Voici un schéma d'architecture Apache Kafka simplifié :
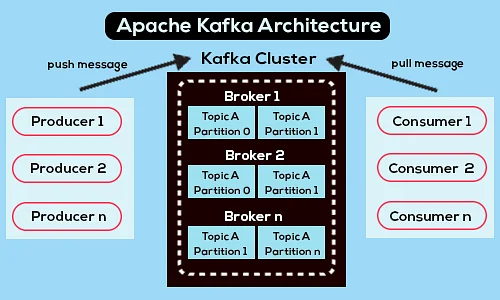
La source
En savoir plus sur Apache Kafka.
Architecture de l'API Apache Kafka
Apache Kafka dispose de quatre API clés : l'API Streams, l'API Connector, l'API Producer et l'API Consumer. Voyons quel rôle chacun doit jouer dans l'amélioration des capacités d'Apache Kafka :
1. API de flux
L'API Streams de Kafka permet à une application de traiter des données à l'aide d'un algorithme de traitement de flux. À l'aide de l'API Streams, les applications peuvent consommer des flux d'entrée d'un ou plusieurs sujets, les traiter avec des opérations de flux, produire des flux de sortie et éventuellement les envoyer à un ou plusieurs sujets. Ainsi, l'API Streams facilite la transformation des flux d'entrée en flux de sortie.
2. API de connecteur
L'API de connecteur de Kafka est utile pour créer, exécuter et gérer des producteurs et des consommateurs réutilisables qui connectent les sujets Kafka aux systèmes de données ou aux applications existants. Par exemple, un connecteur vers une base de données relationnelle pourrait capturer toutes les mises à jour et s'assurer que les modifications sont disponibles dans un sujet Kafka.

3. API de producteur
L'API Producer de Kafka permet aux applications de publier un flux d'enregistrements dans les rubriques Kafka.
4. API consommateur
L'API consommateur de Kafka permet aux applications de s'abonner aux rubriques Kafka. Il permet également aux applications de traiter les flux d'enregistrements qui sont produits dans ces rubriques Kafka.
Aller de l'avant
L'architecture Apache Kafka n'est qu'une infime partie du vaste répertoire d'outils et de langages que les développeurs de logiciels traitent. Supposons que vous soyez un développeur de logiciels en herbe avec une inclination pour le Big Data. Dans ce cas, vous pouvez faire le premier pas vers vos objectifs avec le programme Executive PG d'upGrad en développement de logiciels - Spécialisation en Big Data .
Voici un aperçu du programme avec quelques points saillants :
- PGP exécutif de l'IIIT Bangalore avec des certifications en science des données et en infrastructure cloud
- Sessions en ligne et conférences en direct avec plus de 400 heures de contenu
- 7+ études de cas et projets
- Plus de 14 langages et outils de programmation
- Un accompagnement de carrière à 360 degrés
- Mise en réseau des pairs et de l'industrie
Inscrivez-vous pour plus de détails sur le cours!
A quoi sert Kafka ?
Apache Kafka est principalement utilisé pour créer des pipelines de données de streaming en temps réel et des applications s'adaptant à ces flux de données. Il permet à la fois le stockage et l'analyse de données en temps réel et historiques grâce à une combinaison de messagerie, de stockage et de traitement de flux.
Kafka est-il un cadre ?
Apache Kafka est un logiciel open source qui fournit un cadre pour le stockage, la lecture et l'analyse des données de streaming. Comme il est open-source, Kafka est libre d'utilisation avec de nombreux développeurs et utilisateurs contribuant aux nouvelles fonctionnalités, mises à jour et prise en charge des nouveaux utilisateurs.
Pourquoi avons-nous besoin des flux Kafka ?
Kafka Streams est une bibliothèque cliente pour créer des microservices et des applications de streaming où les données d'entrée et les données de sortie sont stockées dans le cluster Apache Kafka. D'une part, il offre les avantages de la technologie de cluster côté serveur d'Apache Kafka. D'autre part, il simplifie l'écriture et le déploiement d'applications Scala et Java standard côté client.