
Apache Kafka : architecture, concepts, fonctionnalités et applications
Publié: 2021-03-09Kafka a été lancé en 2011, tout cela grâce à LinkedIn. Depuis lors, il a connu une croissance incroyable au point que la plupart des entreprises cotées au Fortune 500 l'utilisent désormais. Il s'agit d'un produit hautement évolutif, durable et à haut débit qui peut gérer de grandes quantités de données en continu. Mais est-ce la seule raison de sa formidable popularité ? Et bien non. Nous n'avons même pas commencé sur ses fonctionnalités, la qualité qu'il produit et la facilité qu'il offre aux utilisateurs.
Nous y plongerons plus tard. Commençons par comprendre ce qu'est Kafka et où il est utilisé.
Table des matières
Qu'est-ce qu'Apache Kafka ?
Apache Kafka est un logiciel de traitement de flux open source qui vise à fournir un haut débit et une faible latence tout en gérant les données en temps réel. Écrit en Java et Scala, Kafka offre une durabilité via des microservices en mémoire et a un rôle essentiel à jouer dans la maintenance des événements d'approvisionnement des services de streaming d'événements complexes, également connus sous le nom de CEP ou Automation Systems.
Il s'agit d'un système distribué exceptionnellement polyvalent et infaillible, qui permet à des entreprises comme Uber de gérer l'appariement des passagers et des chauffeurs. Il fournit également des données en temps réel et une maintenance proactive pour les produits de maison intelligente de British Gas, en plus d'aider LinkedIn à suivre plusieurs services en temps réel.
Souvent utilisé dans l'architecture de données de streaming en temps réel pour fournir des analyses en temps réel, Kafka est un système de messagerie rapide, robuste, évolutif et de publication-abonnement. Apache Kafka peut être utilisé comme substitut du MOM traditionnel en raison de son excellente compatibilité et de son architecture flexible qui lui permet de suivre les appels de service ou les données des capteurs IoT.
Kafka fonctionne brillamment avec Apache Flume/Flafka, Apache Spark Streaming, Apache Storm, HBase, Apache Flink et Apache Spark pour l'ingestion, la recherche, l'analyse et le traitement en temps réel des données de streaming. Les intermédiaires Kafka facilitent également les rapports de suivi à faible latence dans Hadoop ou Spark. Kafka a également un projet subsidiaire nommé Kafka Stream qui fonctionne comme un outil efficace pour l'analyse en temps réel.

Architecture et composants Kafka
Kafka est utilisé pour diffuser des données en temps réel vers plusieurs systèmes destinataires. Kafka fonctionne comme une couche centrale pour découpler les pipelines de données en temps réel. Il ne trouve pas beaucoup d'utilité dans les calculs directs. Il est le plus compatible avec les systèmes d'alimentation en voie rapide, en temps réel ou basés sur des données opérationnelles, pour diffuser une quantité importante de données pour l'analyse de données par lots.
Les frameworks Storm, Flink, Spark et CEP sont quelques systèmes de données avec lesquels Kafka travaille pour effectuer des analyses en temps réel, créer des sauvegardes, des audits, etc. Il peut également être intégré à des plates-formes de données volumineuses ou à des systèmes de bases de données tels que RDBMS, Cassandra, Spark, etc., pour l'analyse, la création de rapports, etc.
Le schéma ci-dessous illustre l'écosystème Kafka :
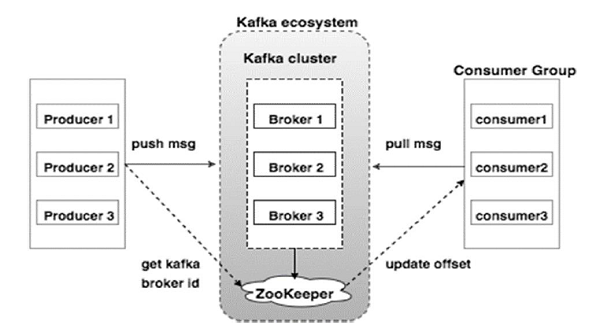
La source
Voici les différents composants de l'écosystème Kafka tels qu'illustrés dans le diagramme d'architecture Kafka :
1. Courtier Kafka
Kafka émule un cluster qui comprend plusieurs serveurs, chacun connu sous le nom de "courtier". Toute communication entre clients et serveurs adhère à un protocole TCP haute performance. Il comprend plus d'un courtier sans état pour gérer les charges lourdes. Un seul courtier Kafka est capable de gérer plusieurs lacs de lectures et d'écritures chaque seconde sans compromettre les performances. Ils utilisent ZooKeeper pour maintenir les clusters et élire le leader du courtier.
2. Kafka ZooKeeper
Comme mentionné ci-dessus, ZooKeeper est en charge de la gestion des courtiers Kafka. Tout nouvel ajout ou défaillance d'un courtier dans l'écosystème Kafka est porté à la connaissance d'un producteur ou d'un consommateur via le ZooKeeper.
3. Producteurs de Kafka
Ils sont responsables de l'envoi des données aux courtiers. Les producteurs ne comptent pas sur les courtiers pour accuser réception d'un message. Au lieu de cela, ils déterminent combien un courtier peut gérer et envoyer des messages en conséquence.

4. Consommateurs Kafka
Il est de la responsabilité des consommateurs Kafka de conserver un enregistrement du nombre de messages consommés par l'offset de partition. L'accusé de réception d'un message indique que les messages envoyés avant d'avoir été consommés. Pour s'assurer que le courtier dispose d'un tampon d'octets prêts à être envoyés au consommateur, le consommateur lance une demande d'extraction asynchrone. Le ZooKeeper a un rôle à jouer dans le maintien de la valeur de décalage du saut ou du rembobinage d'un message.
Le mécanisme de Kafka consiste à envoyer des messages entre applications dans des systèmes distribués. Kafka utilise un journal de validation qui, lorsqu'il est abonné, publie les données présentes dans diverses applications de streaming. L'expéditeur envoie des messages à Kafka, tandis que le destinataire reçoit des messages du flux distribué par Kafka.
Les messages sont assemblés en sujets – une délibération efficace de Kafka. Un sujet donné représente un flux organisé de données basé sur un type ou une classification spécifique. Le producteur écrit des messages à lire par les consommateurs qui sont basés sur un sujet.
Chaque sujet reçoit un nom unique. Tout message d'un sujet donné envoyé par un expéditeur est reçu par tous les utilisateurs qui se connectent à ce sujet. Une fois publiées, les données d'un sujet ne peuvent pas être mises à jour ou modifiées.
Caractéristiques de Kafka
- Kafka consiste en un journal de validation perpétuel qui vous permet de vous y abonner, puis de publier des données sur plusieurs systèmes ou applications en temps réel.
- Il donne aux applications la possibilité de contrôler ces données au fur et à mesure qu'elles arrivent. L'API Streams d'Apache Kafka est une bibliothèque puissante et légère qui facilite le traitement de données par lots à la volée.
- Il s'agit d'une application Java qui vous permet de réguler votre flux de travail et réduit considérablement toute exigence de maintenance.
- Kafka fonctionne comme un « stockage de vérité » distribuant des données à plusieurs nœuds en permettant le déploiement de données via plusieurs systèmes de données.
- Le journal de validation de Kafka en fait un système de stockage fiable. Kafka crée des répliques/sauvegardes d'une partition qui aident à prévenir la perte de données (les bonnes configurations peuvent entraîner une perte de données nulle). Cela évite également les pannes de serveur et améliore la durabilité de Kafka.
- Les sujets dans Kafka ont des milliers de partitions, ce qui le rend capable de gérer une quantité arbitraire de données et un chargement lourd.
- Kafka dépend du noyau du système d'exploitation pour déplacer les données à un rythme rapide. Ces grappes d'informations sont cryptées de bout en bout, du producteur au système de fichiers jusqu'au consommateur final.
- Le traitement par lots dans Kafka améliore l'efficacité de la compression des données et réduit la latence des E/S.
Applications de Kafka
De nombreuses entreprises qui traitent quotidiennement de grandes quantités de données utilisent Kafka.

- LinkedIn utilise Kafka pour suivre l'activité des utilisateurs et les mesures de performance. Twitter le combine avec Storm pour activer un cadre de traitement de flux.
- Square utilise Kafka pour faciliter le déplacement de tous les événements système vers d'autres centres de données Square. Cela inclut les journaux, les événements personnalisés et les métriques.
- Parmi les autres sociétés populaires qui profitent des avantages de Kafka, citons Netflix, Spotify, Uber, Tumblr, CloudFlare et PayPal.
Pourquoi devriez-vous apprendre Apache Kafka ?
Kafka est une excellente plate-forme de streaming d'événements qui peut gérer, suivre et surveiller efficacement les données en temps réel. Son architecture tolérante aux pannes et évolutive permet une intégration de données à faible latence, ce qui se traduit par un débit élevé d'événements de streaming. Kafka réduit considérablement le « time-to-value » des données.
Il fonctionne comme le système de base produisant des informations pour les organisations en éliminant les « journaux » autour des données. Cela permet aux data scientists et aux spécialistes d'accéder facilement aux informations à tout moment.
Pour ces raisons, il s'agit de la première plateforme de streaming de choix pour de nombreuses grandes entreprises et, par conséquent, les candidats qualifiés en Apache Kafka sont très recherchés.
Si vous souhaitez en savoir plus sur Kafka, Big Data, vous devriez consulter le diplôme PG d'upGrad en spécialisation en développement de logiciels en Big Data qui propose plus de 7 études de cas et projets et le mentorat de professeurs et d'experts de l'industrie de classe mondiale. Le programme de 13 mois couvre 14 langages de programmation et enseigne le traitement des données, MapReduce, l'entreposage des données, le traitement en temps réel, le traitement des mégadonnées sur le cloud, entre autres compétences.
Consultez nos autres cours de génie logiciel sur upGrad.