
Une interface utilisateur vocale alternative aux assistants vocaux
Publié: 2022-03-10Pour la plupart des gens, la première chose qui vient à l'esprit lorsque l'on pense aux interfaces utilisateur vocales sont les assistants vocaux, tels que Siri, Amazon Alexa ou Google Assistant. En fait, les assistants sont le seul contexte où la plupart des gens ont déjà utilisé la voix pour interagir avec un système informatique.
Alors que les assistants vocaux ont généralisé les interfaces utilisateur vocales , le paradigme de l'assistant n'est pas le seul, ni même le meilleur moyen d'utiliser, de concevoir et de créer des interfaces utilisateur vocales.
Dans cet article, je vais passer en revue les problèmes dont souffrent les assistants vocaux et présenter une nouvelle approche pour les interfaces utilisateur vocales que j'appelle les interactions vocales directes.
Les assistants vocaux sont des chatbots vocaux
Un assistant vocal est un logiciel qui utilise le langage naturel au lieu d'icônes et de menus comme interface utilisateur. Les assistants répondent généralement aux questions et essaient souvent de manière proactive d'aider l'utilisateur.
Au lieu de transactions et de commandes simples, les assistants imitent une conversation humaine et utilisent le langage naturel de manière bidirectionnelle comme modalité d'interaction, ce qui signifie qu'il prend à la fois l'entrée de l'utilisateur et répond à l'utilisateur en utilisant le langage naturel.
Les premiers assistants étaient des systèmes de questions-réponses basés sur le dialogue. Un des premiers exemples est Clippy de Microsoft, qui a tristement essayé d'aider les utilisateurs de Microsoft Office en leur donnant des instructions basées sur ce qu'il pensait que l'utilisateur essayait d'accomplir. De nos jours, un cas d'utilisation typique du paradigme de l'assistant sont les chatbots, souvent utilisés pour le support client dans une discussion par chat.
Les assistants vocaux, quant à eux, sont des chatbots qui utilisent la voix au lieu de taper et de texte . L'entrée de l'utilisateur n'est pas des sélections ou du texte mais de la parole et la réponse du système est également prononcée à haute voix. Ces assistants peuvent être des assistants généraux tels que Google Assistant ou Alexa qui peuvent répondre à une multitude de questions de manière raisonnable ou des assistants personnalisés conçus dans un but particulier, comme la commande de fast-food.
Bien que souvent l'entrée de l'utilisateur ne soit qu'un mot ou deux et puisse être présentée sous forme de sélections au lieu de texte réel, à mesure que la technologie évolue, les conversations seront plus ouvertes et complexes . La première caractéristique déterminante des chatbots et des assistants est l'utilisation du langage naturel et du style conversationnel au lieu des icônes, des menus et du style transactionnel qui définissent une expérience utilisateur typique d'une application mobile ou d'un site Web.
Lecture recommandée : Construire un chatbot IA simple avec l'API Web Speech et Node.js
La deuxième caractéristique déterminante qui découle des réponses en langage naturel est l'illusion d'un personnage. Le ton, la qualité et le langage utilisés par le système définissent à la fois l'expérience de l'assistant, l'illusion d'empathie et de sensibilité au service, et sa personnalité. L'idée d'une bonne expérience d'assistant, c'est comme être engagé avec une vraie personne .
Étant donné que la voix est le moyen le plus naturel pour nous de communiquer, cela peut sembler génial, mais l'utilisation de réponses en langage naturel pose deux problèmes majeurs. L'un de ces problèmes, lié à la capacité des ordinateurs à imiter les humains, pourrait être résolu à l'avenir avec le développement des technologies d'IA conversationnelle , mais le problème de la façon dont les cerveaux humains traitent l'information est un problème humain, non réparable dans un avenir prévisible. Examinons ces problèmes ensuite.
Deux problèmes avec les réponses en langage naturel
Les interfaces utilisateur vocales sont bien sûr des interfaces utilisateur qui utilisent la voix comme modalité. Mais la modalité vocale peut être utilisée dans les deux sens : pour saisir des informations de l'utilisateur et pour renvoyer des informations du système à l'utilisateur. Par exemple, certains ascenseurs utilisent la synthèse vocale pour confirmer la sélection de l'utilisateur après que l'utilisateur a appuyé sur un bouton. Nous discuterons plus tard des interfaces utilisateur vocales qui n'utilisent que la voix pour saisir des informations et utilisent des interfaces utilisateur graphiques traditionnelles pour afficher les informations à l'utilisateur.
Les assistants vocaux, quant à eux, utilisent la voix pour l'entrée et la sortie . Cette approche présente deux problèmes principaux :
Problème #1 : L'imitation d'un humain échoue
En tant qu'êtres humains, nous avons une tendance innée à attribuer des caractéristiques humaines à des objets non humains. Nous voyons les traits d'un homme dans un nuage passer à la dérive ou regardons un sandwich et il semble qu'il nous sourit. C'est ce qu'on appelle l'anthropomorphisme .

Ce phénomène s'applique également aux assistants, et il est déclenché par leurs réponses en langage naturel. Bien qu'une interface utilisateur graphique puisse être construite de manière quelque peu neutre, il est impossible qu'un humain ne puisse pas commencer à se demander si la voix de quelqu'un appartient à une personne jeune ou âgée ou si elle est un homme ou une femme. De ce fait, l'utilisateur commence presque à penser que l'assistant est bien un humain.
Cependant, nous, les humains, sommes très bons pour détecter les contrefaçons . Curieusement, plus quelque chose ressemble à un humain, plus les petites déviations commencent à nous déranger. Il y a un sentiment de chair de poule envers quelque chose qui essaie d'être humain mais qui n'est pas tout à fait à la hauteur. Dans la robotique et les animations par ordinateur, cela s'appelle la « vallée étrange ».

Plus nous essayons de rendre l'assistant meilleur et plus humain, plus l'expérience utilisateur peut être effrayante et décevante lorsque quelque chose ne va pas. Tous ceux qui ont essayé les assistants sont probablement tombés sur le problème de répondre avec quelque chose qui semble idiot ou même grossier.
L'étrange vallée des assistants vocaux pose un problème de qualité de l'expérience utilisateur des assistants difficile à surmonter. En fait, le test de Turing (du nom du célèbre mathématicien Alan Turing) est réussi lorsqu'un évaluateur humain présentant une conversation entre deux agents ne peut pas distinguer lequel d'entre eux est une machine et lequel est un humain. Jusqu'à présent, il n'a jamais été adopté.
Cela signifie que le paradigme de l'assistant fixe la promesse d'une expérience de service de type humain qui ne pourra jamais être tenue et l'utilisateur sera forcément déçu. Les expériences réussies ne font qu'accumuler la déception éventuelle, car l'utilisateur commence à faire confiance à son assistant humain.
Problème 2 : Interactions séquentielles et lentes
Le deuxième problème des assistants vocaux est que la nature au tour par tour des réponses en langage naturel retarde l'interaction. Cela est dû à la façon dont notre cerveau traite les informations.
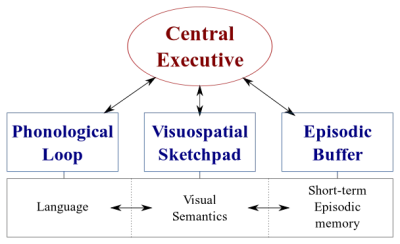
Il existe deux types de systèmes de traitement de données dans notre cerveau :
- Un système linguistique qui traite la parole ;
- Un système visuospatial spécialisé dans le traitement des informations visuelles et spatiales.
Ces deux systèmes peuvent fonctionner en parallèle, mais les deux systèmes ne traitent qu'une seule chose à la fois . C'est pourquoi vous pouvez parler et conduire une voiture en même temps, mais vous ne pouvez pas envoyer de SMS et conduire, car ces deux activités se dérouleraient dans le système visuospatial.

De même, lorsque vous parlez à l'assistant vocal, l'assistant doit rester silencieux et vice versa. Cela crée une conversation au tour par tour, où l'autre partie est toujours entièrement passive.
Cependant, considérez un sujet difficile dont vous voulez discuter avec votre ami. Vous discuteriez probablement en face-à-face plutôt qu'au téléphone, n'est-ce pas ? En effet, dans une conversation en face à face, nous utilisons la communication non verbale pour donner un retour visuel en temps réel à notre interlocuteur. Cela crée une boucle d'échange d'informations bidirectionnelle et permet aux deux parties d'être activement impliquées dans la conversation simultanément.
Les assistants ne donnent pas de retour visuel en temps réel. Ils s'appuient sur une technologie appelée end-pointing pour décider quand l'utilisateur a cessé de parler et ne répond qu'après cela. Et lorsqu'ils répondent, ils ne prennent aucune entrée de l'utilisateur en même temps. L'expérience est entièrement unidirectionnelle et au tour par tour.
Dans une conversation face à face bidirectionnelle et en temps réel, les deux parties peuvent réagir immédiatement aux signaux visuels et linguistiques. Cela utilise les différents systèmes de traitement de l'information du cerveau humain et la conversation devient plus fluide et plus efficace.
Les assistants vocaux sont bloqués en mode unidirectionnel car ils utilisent le langage naturel à la fois comme canaux d'entrée et de sortie. Alors que la voix est jusqu'à quatre fois plus rapide que la saisie pour la saisie, elle est nettement plus lente à digérer que la lecture. Étant donné que les informations doivent être traitées de manière séquentielle , cette approche ne fonctionne bien que pour des commandes simples telles que « éteindre les lumières » qui ne nécessitent pas beaucoup de sortie de l'assistant.

Plus tôt, j'ai promis de discuter des interfaces utilisateur vocales qui n'utilisent la voix que pour saisir les données de l'utilisateur. Ce type d'interfaces utilisateur vocales bénéficie des meilleures parties des interfaces utilisateur vocales - naturel, vitesse et facilité d'utilisation - mais ne souffre pas des mauvaises parties - vallée étrange et interactions séquentielles
Considérons cette alternative.
Une meilleure alternative à l'assistant vocal
La solution pour surmonter ces problèmes dans les assistants vocaux consiste à abandonner les réponses en langage naturel et à les remplacer par un retour visuel en temps réel. Passer des commentaires au visuel permettra à l'utilisateur de donner et d'obtenir des commentaires simultanément. Cela permettra à l'application de réagir sans interrompre l'utilisateur et d'activer un flux d'informations bidirectionnel. Comme le flux d'informations est bidirectionnel, son débit est plus important.
Actuellement, les principaux cas d'utilisation des assistants vocaux sont le réglage d'alarmes, la lecture de musique, la vérification de la météo et la pose de questions simples. Ce sont toutes des tâches à faible enjeu qui ne frustrent pas trop l'utilisateur en cas d'échec.
Comme David Pierce du Wall Street Journal l'a écrit un jour :
"Je ne peux pas imaginer réserver un vol ou gérer mon budget via un assistant vocal, ou suivre mon alimentation en criant des ingrédients sur mon haut-parleur."
—David Pierce du Wall Street Journal
Ce sont des tâches gourmandes en informations qui doivent se dérouler correctement.
Cependant, l'interface utilisateur vocale finira par échouer. La clé est de couvrir cela aussi vite que possible. De nombreuses erreurs se produisent lors de la frappe sur un clavier ou même lors d'une conversation en face à face. Cependant, ce n'est pas du tout frustrant car l'utilisateur peut récupérer simplement en cliquant sur le retour arrière et en réessayant ou en demandant des éclaircissements.
Cette récupération rapide des erreurs permet à l'utilisateur d'être plus efficace et ne l'oblige pas à avoir une conversation bizarre avec un assistant.
Interactions vocales directes
Dans la plupart des applications, les actions sont effectuées en manipulant des éléments graphiques à l'écran, en poussant ou en glissant (sur les écrans tactiles), en cliquant sur une souris et/ou en appuyant sur les boutons d'un clavier. L'entrée vocale peut être ajoutée en tant qu'option ou modalité supplémentaire pour manipuler ces éléments graphiques. Ce type d'interaction peut être appelé interaction vocale directe .
La différence entre les interactions vocales directes et les assistants est qu'au lieu de demander à un avatar, l'assistant, d'effectuer une tâche, l'utilisateur manipule directement l'interface utilisateur graphique avec la voix.
"N'est-ce pas de la sémantique ?", pourriez-vous demander. Si vous allez parler à l'ordinateur, est-il vraiment important que vous parliez directement à l'ordinateur ou par l'intermédiaire d'un personnage virtuel ? Dans les deux cas, vous ne faites que parler à un ordinateur !
Oui, la différence est subtile, mais critique. Lorsque vous cliquez sur un bouton ou un élément de menu dans une GUI ( interface utilisateur graphique), il est évident que nous utilisons une machine. Il n'y a aucune illusion d'une personne. En remplaçant ce clic par une commande vocale, nous améliorons l'interaction homme-ordinateur. Avec le paradigme de l'assistant, d'autre part, nous créons une version détériorée de l'interaction entre humains et, par conséquent, voyageons dans la vallée étrange.
L'intégration de fonctionnalités vocales dans l'interface utilisateur graphique offre également la possibilité d'exploiter la puissance de différentes modalités. Bien que l'utilisateur puisse utiliser la voix pour faire fonctionner l'application, il a également la possibilité d'utiliser l'interface graphique traditionnelle. Cela permet à l'utilisateur de basculer entre le toucher et la voix de manière transparente et de choisir la meilleure option en fonction de son contexte et de sa tâche.
Par exemple, la voix est une méthode très efficace pour saisir des informations riches. Choisir entre quelques alternatives valides, toucher ou cliquer est probablement mieux. L'utilisateur peut alors remplacer la saisie et la navigation en disant quelque chose comme "Montrez-moi les vols de Londres à New York au départ demain", et sélectionnez la meilleure option dans la liste en utilisant le toucher.
Maintenant, vous pourriez demander « OK, ça a l'air génial, alors pourquoi n'avons-nous pas vu d'exemples de telles interfaces utilisateur vocales auparavant ? Pourquoi les grandes entreprises technologiques ne créent-elles pas d'outils pour quelque chose comme ça ? » Eh bien, il y a probablement plusieurs raisons à cela. L'une des raisons est que le paradigme actuel de l'assistant vocal est probablement le meilleur moyen pour eux d'exploiter les données qu'ils obtiennent des utilisateurs finaux. Une autre raison est liée à la façon dont leur technologie vocale est construite.
Une interface utilisateur vocale qui fonctionne bien nécessite deux parties distinctes :
- Reconnaissance vocale qui transforme la parole en texte ;
- Composants de compréhension du langage naturel qui extraient le sens de ce texte.
La deuxième partie est la magie qui transforme les énoncés "Éteignez les lumières du salon" et "Veuillez éteindre les lumières du salon" en la même action.
Lecture recommandée : Comment créer votre propre action pour Google Home à l'aide d'API.AI
Si vous avez déjà utilisé un assistant avec un écran (tel que Siri ou Google Assistant), vous avez probablement remarqué que vous obtenez la transcription en temps quasi réel, mais après avoir cessé de parler, il faut quelques secondes avant que le système exécute réellement l'action que vous avez demandée. Cela est dû au fait que la reconnaissance vocale et la compréhension du langage naturel se déroulent de manière séquentielle.
Voyons comment cela pourrait être changé.
Compréhension de la langue parlée en temps réel : la sauce secrète pour des commandes vocales plus efficaces
La rapidité avec laquelle une application réagit aux entrées de l'utilisateur est un facteur majeur dans l'expérience utilisateur globale de l'application. L'innovation la plus importante de l'iPhone d'origine était l'écran tactile extrêmement réactif et réactif. La capacité d'une interface utilisateur vocale à réagir instantanément à une entrée vocale est tout aussi importante.
Afin d'établir une boucle d'échange d'informations bidirectionnelle rapide entre l'utilisateur et l'interface utilisateur, l'interface graphique à commande vocale doit être capable de réagir instantanément - même au milieu d'une phrase - chaque fois que l'utilisateur dit quelque chose d'actionnable. Cela nécessite une technique appelée compréhension de la langue parlée en continu .
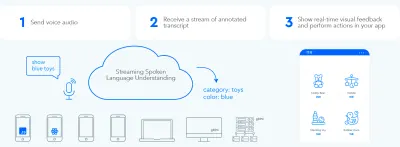
Contrairement aux systèmes d'assistance vocale traditionnels au tour par tour qui attendent que l'utilisateur arrête de parler avant de traiter la demande de l'utilisateur, les systèmes utilisant la compréhension de la langue parlée en continu tentent activement de comprendre l'intention de l'utilisateur dès le moment où l'utilisateur commence à parler. Dès que l'utilisateur dit quelque chose d'actionnable, l'interface utilisateur réagit instantanément.
La réponse instantanée valide immédiatement que le système comprend l'utilisateur et l'encourage à continuer. C'est analogue à un hochement de tête ou à un court "a-ha" dans la communication interhumaine. Cela se traduit par des énoncés plus longs et plus complexes pris en charge. Respectivement, si le système ne comprend pas l'utilisateur ou si l'utilisateur parle mal, un retour instantané permet une récupération rapide . L'utilisateur peut immédiatement corriger et continuer, ou même se corriger verbalement : "Je veux ceci, non je voulais dire, je veux cela." Vous pouvez essayer vous-même ce type d'application dans notre démo de recherche vocale.
Comme vous pouvez le voir dans la démo, le retour visuel en temps réel permet à l'utilisateur de se corriger naturellement et l'encourage à poursuivre l'expérience vocale. Comme ils ne sont pas confondus par un personnage virtuel, ils peuvent se rapporter à d'éventuelles erreurs de la même manière que les fautes de frappe - et non comme des insultes personnelles. L'expérience est plus rapide et plus naturelle car les informations transmises à l'utilisateur ne sont pas limitées par le débit typique d'environ 150 mots par minute.
Lecture recommandée : Concevoir des expériences vocales par Lyndon Cerejo
conclusion
Alors que les assistants vocaux ont été de loin l'utilisation la plus courante des interfaces utilisateur vocales jusqu'à présent, l'utilisation de réponses en langage naturel les rend inefficaces et non naturelles. La voix est une excellente modalité pour saisir des informations, mais écouter une machine parler n'est pas très inspirant. C'est le gros problème des assistants vocaux.
L'avenir de la voix ne devrait donc pas être dans les conversations avec un ordinateur mais dans le remplacement des tâches fastidieuses de l'utilisateur par le moyen de communication le plus naturel : la parole . Les interactions vocales directes peuvent être utilisées pour améliorer l'expérience de remplissage de formulaires dans les applications Web ou mobiles, pour créer de meilleures expériences de recherche et pour permettre un contrôle ou une navigation plus efficace dans une application.
Les concepteurs et les développeurs d'applications recherchent constamment des moyens de réduire les frictions dans leurs applications ou leurs sites Web. L'amélioration de l'interface utilisateur graphique actuelle avec une modalité vocale permettrait des interactions utilisateur plusieurs fois plus rapides, en particulier dans certaines situations telles que lorsque l'utilisateur final est sur mobile et en déplacement et que la saisie est difficile. En fait, la recherche vocale peut être jusqu'à cinq fois plus rapide qu'une interface utilisateur de filtrage de recherche traditionnelle, même lorsque vous utilisez un ordinateur de bureau.
La prochaine fois, lorsque vous réfléchirez à la façon dont vous pouvez rendre une certaine tâche utilisateur dans votre application plus facile à utiliser, plus agréable à utiliser, ou si vous souhaitez augmenter les conversions, demandez-vous si cette tâche utilisateur peut être décrite avec précision en langage naturel. Si oui, complétez votre interface utilisateur avec une modalité vocale mais n'obligez pas vos utilisateurs à converser avec un ordinateur.
Ressources
- "Voice First contre les interfaces utilisateur multimodales du futur", Joan Palmiter Bajorek, UXmatters
- "Lignes directrices pour la création d'applications vocales productives", Hannes Heikinheimo, Speechly
- "6 raisons pour lesquelles vos applications à écran tactile devraient avoir des capacités vocales", Ottomatias Peura, UXmatters
- Mélanger tangible et intangible : concevoir des interfaces multimodales à l'aide d'Adobe XD, Nick Babich, Smashing Magazine
( Adobe XD peut servir à prototyper quelque chose de similaire ) - "L'efficacité à la vitesse du son : la promesse des opérations vocales", Eric Turkington, RAIN
- Une démo présentant un retour visuel en temps réel dans le filtrage de la recherche vocale du commerce électronique (version vidéo)
- Speechly fournit des outils de développement pour ce type d'interfaces utilisateur
- Alternative open source : voice2json