
Un guide de la régression linéaire à l'aide de Scikit [avec exemples]
Publié: 2021-06-18Les algorithmes d'apprentissage supervisé sont généralement de deux types : la régression et la classification avec la prédiction de sorties continues et discrètes.
L'article suivant traitera de la régression linéaire et de sa mise en œuvre à l'aide de l'une des bibliothèques d'apprentissage automatique les plus populaires de python, la bibliothèque Scikit-learn. Des outils d'apprentissage automatique et des modèles statistiques sont disponibles dans la bibliothèque Python pour la classification, la régression, le regroupement et la réduction de la dimensionnalité. Écrite dans le langage de programmation python, la bibliothèque est construite sur les bibliothèques python NumPy, SciPy et Matplotlib.
Table des matières
Régression linéaire
La régression linéaire effectue la tâche de régression dans le cadre de la méthode d'apprentissage supervisé. Sur la base de variables indépendantes, une valeur cible est prédite. La méthode est principalement utilisée pour prévoir et identifier une relation entre les variables.
En algèbre, le terme linéarité désigne une relation linéaire entre des variables. Une droite est déduite entre les variables dans un espace à deux dimensions.
Si une ligne est un tracé entre les variables indépendantes sur l'axe X et les variables dépendantes sur l'axe Y, une ligne droite est obtenue par régression linéaire qui correspond le mieux aux points de données.
L'équation d'une droite se présente sous la forme

Y = mx + b
Où, b= intercepter
m= pente de la droite
Ainsi, par régression linéaire,
- Les valeurs les plus optimales pour l'ordonnée à l'origine et la pente sont déterminées en deux dimensions.
- Il n'y a pas de changement dans les variables x et y car ce sont les caractéristiques des données et restent donc les mêmes.
- Seules les valeurs d'interception et de pente peuvent être contrôlées.
- Plusieurs lignes droites basées sur les valeurs de pente et d'interception peuvent exister, mais grâce à l'algorithme de régression linéaire, plusieurs lignes sont ajustées sur les points de données et la ligne avec le moins d'erreur est renvoyée.
Régression linéaire avec Python
Pour implémenter la régression linéaire en python, des packages appropriés doivent être appliqués avec ses fonctions et ses classes. Le package NumPy en Python est open source et permet plusieurs opérations sur les tableaux, à la fois des tableaux simples et multidimensionnels.
Une autre bibliothèque largement utilisée en python est Scikit-learn qui est utilisée pour les problèmes d'apprentissage automatique.
Scikit-learN
La bibliothèque Scikit-learn propose aux développeurs des algorithmes basés à la fois sur l'apprentissage supervisé et non supervisé. La bibliothèque open-source de python est conçue pour les tâches d'apprentissage automatique.
Les scientifiques des données peuvent importer les données, les prétraiter, les tracer et prédire les données grâce à l'utilisation de scikit-learn.
David Cournapeau a développé scikit-learn pour la première fois en 2007, et la bibliothèque a connu une croissance depuis des décennies.
Les outils fournis par scikit-learn sont :
- Régression : comprend la régression logistique et la régression linéaire
- Classification : Inclut la méthode des K-plus proches voisins
- Sélection d'un modèle
- Clustering : inclut à la fois K-Means++ et K-Means
- Prétraitement
Les avantages de la bibliothèque sont :
- L'apprentissage et la mise en œuvre de la bibliothèque sont faciles.
- C'est une bibliothèque open-source et donc gratuite.
- Les aspects de l'apprentissage automatique peuvent être couverts, y compris l'apprentissage en profondeur.
- C'est un ensemble puissant et polyvalent.
- La bibliothèque possède une documentation détaillée.
- L'une des boîtes à outils les plus utilisées pour l'apprentissage automatique.
Importer scikit-learn
Le scikit-learn doit d'abord être installé via pip ou via conda.
- Exigences : version 64 bits de python 3 avec les bibliothèques installées NumPy et Scipy. Également pour la visualisation des tracés de données, matplotlib est requis.
Commande d'installation : pip install -U scikit-learn
Vérifiez ensuite si l'installation est terminée
Installation de Numpy, Scipy et matplotlib
L'installation peut être confirmée par :
La source
Régression linéaire via Scikit-learn
La mise en œuvre de la régression linéaire via le package scikit-learn implique les étapes suivantes.
- Les packages et les classes nécessaires sont à importer.
- Les données sont nécessaires pour travailler avec et aussi pour effectuer les transformations appropriées.
- Un modèle de régression doit être créé et ajusté avec les données existantes.
- Les données d'ajustement du modèle doivent être vérifiées pour analyser si le modèle créé est satisfaisant.
- Les prévisions doivent être faites par l'application du modèle.
Le package NumPy et la classe LinearRegression sont à importer depuis le sklearn.linear_model.

La source
Les fonctionnalités requises pour la régression linéaire sklearn sont toutes présentes pour enfin implémenter la régression linéaire. La classe sklearn.linear_model.LinearRegression est utilisée pour effectuer une analyse de régression (à la fois linéaire et polynomiale) et effectuer des prédictions.
Pour tous les algorithmes d'apprentissage automatique et scikit learn linear regression , l'ensemble de données doit d'abord être importé. Trois options sont disponibles dans Scikit-learn pour obtenir les données :
- Des ensembles de données comme la classification de l'iris ou l'ensemble de régression pour le prix du logement de Boston.
- Les ensembles de données du monde réel peuvent être téléchargés depuis Internet directement via les fonctions prédéfinies de Scikit-learn.
- Un ensemble de données peut être généré de manière aléatoire pour être comparé à un modèle spécifique via le générateur de données Scikit-learn.
Quelle que soit l'option sélectionnée, les jeux de données du module doivent être importés.

importer sklearn.datasets en tant qu'ensembles de données
1. L'ensemble de classification de l'iris
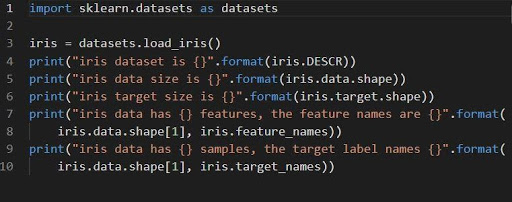
iris = datasets.load_iris()
L'iris de l'ensemble de données est stocké sous la forme d'un champ de données de tableau 2D de n_échantillons * n_caractéristiques. Son importation s'effectue en tant qu'objet d'un dictionnaire. Il contient toutes les données nécessaires ainsi que les métadonnées.
Les fonctions DESCR, shape et _names peuvent être utilisées pour obtenir des descriptions et le formatage des données. L'impression des résultats de la fonction affichera les informations de l'ensemble de données qui pourraient être nécessaires lors du travail sur l'ensemble de données de l'iris.
Le code suivant chargera les informations de l'ensemble de données de l'iris.
La source
2. Génération de données de régression
S'il n'y a aucune exigence pour les données intégrées, les données peuvent être générées via une distribution qui peut être choisie.
Génération de données de régression avec un ensemble de 1 fonctionnalité informative et 1 fonctionnalité.
X , Y = datasets.make_regression(n_features=1, n_informative=1)
Les données générées sont enregistrées dans un jeu de données 2D avec les objets x et y. Les caractéristiques des données générées peuvent être modifiées en modifiant les paramètres de la fonction make_regression.
Dans cet exemple, les paramètres des fonctionnalités informatives et des fonctionnalités sont modifiés d'une valeur par défaut de 10 à 1.
Les autres paramètres pris en compte sont les échantillons et les cibles où le nombre de cibles et de variables d'échantillon suivies est contrôlé.
- Les fonctionnalités qui fournissent des informations utiles aux algorithmes de ML sont appelées fonctionnalités informatives, tandis que celles qui ne sont pas utiles sont appelées fonctionnalités non informatives.
3. Tracer les données
Les données sont tracées à l'aide de la bibliothèque matplotlib. Tout d'abord, le matplotlib doit être importé.
Importer matplotlib.pyplot en tant que plt
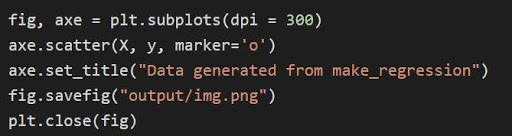
Le graphique ci-dessus est tracé à travers le matplotlib à travers le code
La source
Dans le code ci-dessus :
- Les variables de tuple sont décompressées et enregistrées en tant que variables distinctes à la ligne 1 du code. Par conséquent, les attributs séparés peuvent être manipulés et enregistrés.
- Le jeu de données x, y est utilisé pour générer un nuage de points jusqu'à la ligne 2. Avec la disponibilité du paramètre marqueur dans matplotlib, les visuels sont améliorés en marquant les points de données avec un point (o).
- Le titre du tracé généré est défini jusqu'à la ligne 3.
- La figure peut être enregistrée en tant que fichier image .png, puis la figure actuelle est fermée.
Le tracé de régression généré par le code ci-dessus est
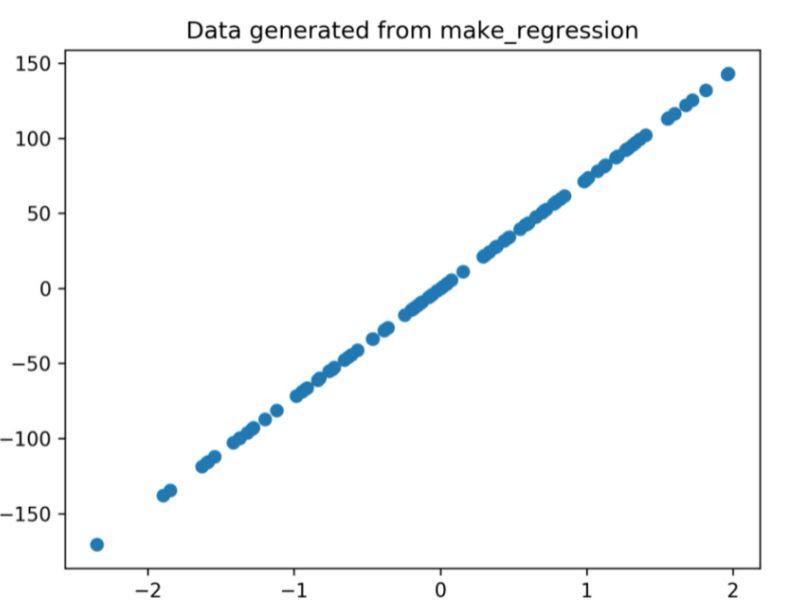
Figure 1 : Le tracé de régression généré à partir du code ci-dessus.
4. Implémentation de l'algorithme de régression linéaire
En utilisant les données d'échantillon du prix du logement à Boston, l'algorithme de régression linéaire Scikit-learn est implémenté dans l'exemple suivant. Comme d'autres algorithmes ML, l'ensemble de données est importé puis formé à l'aide des données précédentes.
La méthode linéaire de régression est utilisée par les entreprises, car il s'agit d'un modèle prédictif prédisant la relation entre une quantité numérique et ses variables à la valeur de sortie avec une signification ayant une valeur dans la réalité.
Lorsqu'un journal de données antérieures est présent, le modèle peut être mieux appliqué car il peut prédire les résultats futurs de ce qui se passera à l'avenir s'il y a une continuation du modèle.
Mathématiquement, les données peuvent être ajustées pour minimiser la somme de tous les résidus existant entre les points de données et la valeur prédite.
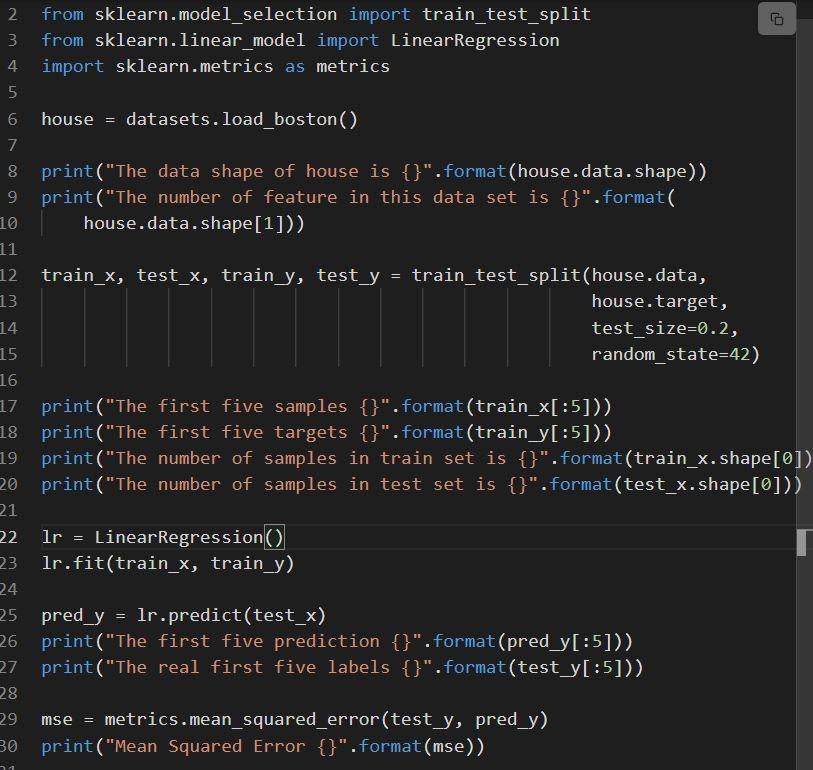
L'extrait suivant montre l'implémentation de la régression linéaire sklearn.
La source
Le code est expliqué comme suit :
- La ligne 6 charge le jeu de données appelé load_boston.
- L'ensemble de données est divisé en ligne 12, c'est-à-dire l'ensemble d'apprentissage avec 80% de données et l'ensemble du test avec 20% de données.
- Création d'un modèle de régression linéaire à la ligne 23 puis entraîné à.
- La performance du modèle est évaluée au niveau du linge 29 en appelant mean_squared_error.
Le tracé de régression linéaire sklearn est illustré ci-dessous :
Modèle de régression linéaire des données de l'échantillon sur les prix des logements à Boston
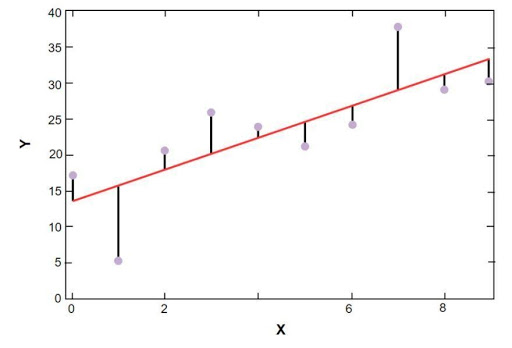
La source
Dans la figure ci-dessus, la ligne rouge représente le modèle linéaire qui a été résolu pour les données d'échantillon du prix du logement à Boston. Les points bleus représentent les données d'origine et la distance entre la ligne rouge et les points bleus représentent la somme des résidus. L'objectif du modèle de régression linéaire scikit-learn est de réduire la somme des résidus.
Conclusion
L'article traitait de la régression linéaire et de sa mise en œuvre grâce à l'utilisation d'un package python open source appelé scikit-learn. À présent, vous êtes en mesure de comprendre comment implémenter la régression linéaire via ce package. Cela vaut la peine d'apprendre à utiliser la bibliothèque pour votre analyse de données.
Si vous souhaitez approfondir le sujet, comme l'implémentation de packages python dans l'apprentissage automatique et les problèmes liés à l'IA, vous pouvez consulter le cours Master of Science in Machine Learning & AI proposé par upGrad . Ciblant les professionnels débutants de 21 à 45 ans, le cours vise à former les étudiants à l'apprentissage automatique à travers plus de 650 heures de formation en ligne, plus de 25 études de cas et des devoirs. Certifié par LJMU , le cours offre une orientation parfaite et une aide au placement. Si vous avez des questions ou des questions, laissez-nous un message, nous serons heureux de vous contacter.