
¿Qué es el aprendizaje automático con Java? ¿Cómo implementarlo?
Publicado: 2021-03-10Tabla de contenido
¿Qué es el aprendizaje automático?
El aprendizaje automático es una división de la inteligencia artificial que aprende de los datos, ejemplos y experiencias disponibles para imitar el comportamiento y la inteligencia humanos. Un programa creado con aprendizaje automático puede generar lógica por sí mismo sin que un ser humano tenga que escribir manualmente el código.
Todo comenzó con The Turing Test a principios de la década de 1950, cuando Alan Turning concluyó que para que una computadora tuviera inteligencia real, tendría que manipular o convencer a un humano de que también era humano. El aprendizaje automático es un concepto relativamente antiguo, pero solo hoy en día este campo emergente está sujeto a realización, ya que las computadoras ahora pueden procesar algoritmos complejos. Los algoritmos de aprendizaje automático han evolucionado durante la última década para incluir habilidades computacionales complejas que, a su vez, han llevado a una mejora en sus capacidades de imitación.
Las aplicaciones de aprendizaje automático también han aumentado a un ritmo alarmante. Desde la atención médica, las finanzas, el análisis y la educación hasta la fabricación, el marketing y las operaciones gubernamentales, todas las industrias han visto un aumento significativo en la calidad y la eficiencia después de implementar tecnologías de aprendizaje automático. Ha habido mejoras cualitativas generalizadas en todo el mundo, por lo tanto, impulsando la demanda de profesionales de aprendizaje automático.
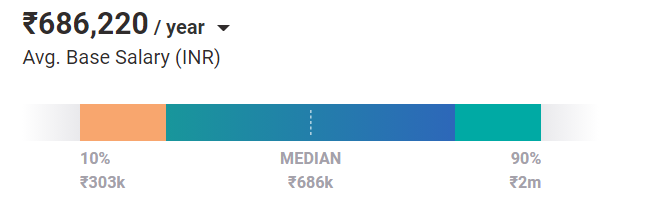
En promedio, los ingenieros de aprendizaje automático tienen un salario de ₹ 686,220 / año en la actualidad. Y ese es el caso de una posición de nivel de entrada. Con experiencia y habilidades, pueden ganar hasta 2 millones de rupias al año en la India.
Tipos de algoritmos de aprendizaje automático
Los algoritmos de aprendizaje automático son de tres tipos:
1. Aprendizaje supervisado : en este tipo de aprendizaje, los conjuntos de datos de entrenamiento guían un algoritmo para hacer predicciones precisas o decisiones analíticas. Emplea el aprendizaje de conjuntos de datos de entrenamiento anteriores para procesar nuevos datos. Estos son algunos ejemplos de modelos de aprendizaje automático de aprendizaje supervisado:

- regresión lineal
- Regresión logística
- Árbol de decisión
2. Aprendizaje no supervisado : en este tipo de aprendizaje, un modelo de aprendizaje automático aprende de piezas de información no etiquetadas. Emplea la agrupación de datos mediante la agrupación de objetos o la comprensión de la relación entre ellos, o la explotación de sus propiedades estadísticas para realizar análisis. Ejemplos de algoritmos de aprendizaje no supervisados son:
- Agrupamiento de K-medias
- Agrupación jerárquica
3. Aprendizaje por refuerzo : este proceso se basa en el golpe y la prueba. Es aprender interactuando con el espacio o un entorno. Un algoritmo RL aprende de sus experiencias pasadas interactuando con el entorno y determinando el mejor curso de acción.
¿Cómo implementar el aprendizaje automático con Java?
Java se encuentra entre los principales lenguajes de programación utilizados para implementar algoritmos de aprendizaje automático. La mayoría de sus bibliotecas son de código abierto y brindan un amplio soporte de documentación, fácil mantenimiento, comerciabilidad y fácil lectura.
Dependiendo de la popularidad, estas son las 10 principales bibliotecas de aprendizaje automático utilizadas para implementar el aprendizaje automático en Java.
1. ADÁN
El sistema de aprendizaje automático y minería de datos avanzada o ADAMS se ocupa de crear sistemas de flujo de trabajo novedosos y flexibles y de gestionar procesos complejos del mundo real. ADAMS emplea una arquitectura en forma de árbol para administrar el flujo de datos en lugar de realizar conexiones manuales de entrada y salida.
Elimina cualquier necesidad de conexiones explícitas. Se basa en el principio de "menos es más" y realiza recuperación, visualización y visualizaciones basadas en datos. ADAMS es experto en procesamiento de datos, transmisión de datos, gestión de bases de datos, secuencias de comandos y documentación.
2. Java ML
JavaML ofrece una variedad de algoritmos de minería de datos y ML que están escritos para Java para ayudar a los ingenieros de software, programadores, científicos de datos e investigadores. Cada algoritmo tiene una interfaz común que es fácil de usar y tiene un amplio soporte de documentación, aunque no hay GUI.
Es bastante simple y directo de implementar en comparación con otros algoritmos de agrupamiento. Sus funciones principales incluyen la manipulación de datos, la documentación, la gestión de bases de datos, la clasificación de datos, la agrupación en clústeres, la selección de funciones, etc.
Únase al curso de aprendizaje automático en línea de las mejores universidades del mundo: maestrías, programas ejecutivos de posgrado y programa de certificado avanzado en ML e IA para acelerar su carrera.
3. WEKA
Weka también es una biblioteca de aprendizaje automático de código abierto escrita para Java que admite el aprendizaje profundo. Proporciona un conjunto de algoritmos de aprendizaje automático y tiene un amplio uso en minería de datos, preparación de datos, agrupación de datos, visualización de datos y regresión, entre otras operaciones de datos.
Ejemplo: Demostraremos esto utilizando un pequeño conjunto de datos de diabetes.
Paso 1 : Cargue los datos usando Weka
| importar weka.core.Instances; importar weka.core.converters.ConverterUtils.DataSource; clase pública Principal { public static void main(String[] args) lanza Exception { // Especificando la fuente de datos DataSource dataSource = new DataSource(“data.arff”); // Cargando el conjunto de datos Instancias instancias de datos = dataSource.getDataSet(); // Mostrar el número de instancias log.info(“El número de instancias cargadas es: ” + dataInstances.numInstances()); log.info(“datos:” + instancias de datos.toString()); } } |
Paso 2: el conjunto de datos tiene 768 instancias. Necesitamos acceder al número de atributos, es decir, 9.
| log.info(“El número de atributos (características) en el conjunto de datos: ” + dataInstances.numAttributes()); |
Paso 3 : Necesitamos determinar la columna de destino antes de construir un modelo y encontrar el número de clases.
| // Identificando el índice de la etiqueta dataInstances.setClassIndex(dataInstances.numAttributes() – 1); // Obtener el número de log.info(“El número de clases: ” + dataInstances.numClasses()); |
Paso 4 : ahora construiremos el modelo utilizando un clasificador de árbol simple, J48.
| // Creando un clasificador de árbol de decisión clasificador de árboles J48 = new J48(); treeClassifier.setOptions(nueva Cadena[] { “-U” }); treeClassifier.buildClassifier(dataInstances); |
El código anterior destaca cómo crear un árbol no podado que consta de las instancias de datos necesarias para el entrenamiento del modelo. Una vez que se imprime la estructura de árbol después del entrenamiento del modelo, podemos determinar cómo se construyeron las reglas internamente.
| pla <= 127 | masa <= 26.4 | | preg <= 7: probado_negativo (117.0/1.0) | | embarazo > 7 | | | masa <= 0: probado_positivo (2.0) | | | masa > 0: probado_negativo (13.0) | masa > 26,4 | | edad <= 28: probado_negativo (180.0/22.0) | | edad > 28 | | | pla <= 99: probado_negativo (55.0/10.0) | | | juegos > 99 | | | | pedi <= 0.56: probado_negativo (84.0/34.0) | | | | pedi > 0,56 | | | | | embarazo <= 6 | | | | | | edad <= 30: probado_positivo (4.0) | | | | | | edad > 30 | | | | | | | edad <= 34: probado_negativo (7.0/1.0) | | | | | | | edad > 34 | | | | | | | | masa <= 33.1: probado_positivo (6.0) | | | | | | | | masa > 33.1: probado_negativo (4.0/1.0) | | | | | embarazo > 6: probado_positivo (13.0) pla > 127 | masa <= 29.9 | | pla <= 145: probado_negativo (41.0/6.0) | | pla > 145 | | | edad <= 25: probado_negativo (4.0) | | | edad > 25 | | | | edad <= 61 | | | | | masa <= 27.1: probado_positivo (12.0/1.0) | | | | | masa > 27,1 | | | | | | presión <= 82 | | | | | | | pedi <= 0.396: probado_positivo (8.0/1.0) | | | | | | | pedi > 0.396: probado_negativo (3.0)  | | | | | | pres > 82: probado_negativo (4.0) | | | | edad > 61: probado_negativo (4.0) | masa > 29,9 | | pla <= 157 | | | pres <= 61: probado_positivo (15.0/1.0) | | | presión > 61 | | | | edad <= 30: probado_negativo (40.0/13.0) | | | | edad > 30: probado_positivo (60.0/17.0) | | pla > 157: probado_positivo (92.0/12.0) Número de hojas: 22 Tamaño del árbol : 43 |
4. Apache Mahaut
Mahaut es una colección de algoritmos para ayudar a implementar el aprendizaje automático usando Java. Es un marco de álgebra lineal escalable mediante el cual los desarrolladores pueden realizar análisis matemáticos y estadísticos. Por lo general, lo utilizan científicos de datos, ingenieros de investigación y profesionales de análisis para crear aplicaciones listas para la empresa. Su escalabilidad y flexibilidad permite a los usuarios implementar clústeres de datos, sistemas de recomendación y crear aplicaciones de aprendizaje automático de alto rendimiento de forma rápida y sencilla.
5. Aprendizaje profundo4j
Deeplearning4j es una biblioteca de programación que está escrita en Java y ofrece un amplio soporte para el aprendizaje profundo. Es un marco de código abierto que combina redes neuronales profundas y aprendizaje de refuerzo profundo para servir a las operaciones comerciales. Es compatible con Scala, Kotlin, Apache Spark, Hadoop y otros lenguajes JVM y marcos de computación de big data.
Por lo general, se usa para detectar patrones y emociones en la voz, el habla y el texto escrito. Sirve como una herramienta de bricolaje que puede descubrir discrepancias en las transacciones y manejar múltiples tareas. Es una biblioteca distribuida de grado comercial que tiene documentación API detallada debido a su naturaleza de código abierto.
Aquí hay un ejemplo de cómo puede implementar el aprendizaje automático usando Deeplearning4j.
Ejemplo : Usando Deeplearning4j, construiremos un modelo de red neuronal de convolución (CNN) para clasificar los dígitos escritos a mano con la ayuda de la biblioteca MNIST.
Paso 1 : Cargue el conjunto de datos para mostrar su tamaño.
| DataSetIterator MNISTTrain = new MnistDataSetIterator(batchSize,true,seed); DataSetIterator MNISTTest = new MnistDataSetIterator(batchSize,false,seed); |
Paso 2 : asegúrese de que el conjunto de datos nos proporcione diez etiquetas únicas.
| log.info(“El número total de etiquetas encontradas en el conjunto de datos de entrenamiento” + MNISTTrain.totalOutcomes()); log.info(“El número total de etiquetas encontradas en el conjunto de datos de prueba” + MNISTTest.totalOutcomes()); |
Paso 3 : Ahora, configuraremos la arquitectura del modelo usando dos capas de convolución junto con una capa aplanada para mostrar la salida.
Hay opciones en Deeplearning4j que le permiten inicializar el esquema de peso.
| // Construyendo el modelo CNN MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .seed(semilla) // semilla aleatoria .l2(0.0005) // regularización .weightInit(WeightInit.XAVIER) // inicialización del esquema de peso .updater(new Adam(1e-3)) // Configuración del algoritmo de optimización .lista() .layer(nueva ConvolutionLayer.Builder(5, 5) //Configuración de la zancada, el tamaño del núcleo y la función de activación. .nIn(nCanales) .paso(1,1) .nFuera(20) .activation(Activación.IDENTIDAD) .construir()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // reducción de resolución de la convolución .kernelSize(2,2) .paso(2,2) .construir()) .layer(nueva ConvolutionLayer.Builder(5, 5) // Configuración de la zancada, el tamaño del kernel y la función de activación. .paso(1,1) .nFuera(50) .activation(Activación.IDENTIDAD) .construir()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // reducción de resolución de la convolución .kernelSize(2,2) .paso(2,2) .construir()) .capa(nueva DenseLayer.Builder().activación(Activación.RELU) .nOut(500).construir()) .layer(new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(númSalida) .activation(Activación.SOFTMAX) .construir()) // la capa de salida final es 28×28 con una profundidad de 1. .setInputType(InputType.convolutionalFlat(28,28,1)) .construir(); |
Paso 4 : Una vez que hayamos configurado la arquitectura, inicializaremos el modo y el conjunto de datos de entrenamiento y comenzaremos el entrenamiento del modelo.
| modelo de MultiLayerNetwork = new MultiLayerNetwork(conf); // inicializa los pesos del modelo. modelo.init(); log.info(“Paso 2: comenzar a entrenar el modelo”); //Configurar un oyente cada 10 iteraciones y evaluar en conjunto de prueba en cada época model.setListeners(new ScoreIterationListener(10), new EvaluativeListener(MNISTTest, 1, InvocationType.EPOCH_END)); // Entrenando el modelo model.fit(MNISTTrain, nEpochs); |
A medida que comience el entrenamiento del modelo, tendrá la matriz de confusión de la precisión de la clasificación.
Aquí está la precisión del modelo después de diez épocas de entrenamiento:
| ========================= Matriz de confusión ======================= == 0 1 2 3 4 5 6 7 8 9 —————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0 879 1 0 1 1 | 5 = 5 4 2 0 0 1 1 949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2 962 2 | 8 = 8 0 2 0 2 11 2 0 3 2 987 | 9 = 9 |
6. ELKI
El entorno para desarrollar aplicaciones KDD compatibles con la estructura de índice o ELKI es una colección de algoritmos y programas integrados que se utilizan para la minería de datos. Escrito en Java, es una biblioteca de código abierto que comprende parámetros altamente configurables en algoritmos. Por lo general, los científicos de investigación y los estudiantes lo utilizan para obtener información sobre los conjuntos de datos. Como sugiere el nombre, proporciona un entorno para desarrollar sofisticados programas de minería de datos y bases de datos utilizando una estructura de índice.
7. JSAT
Java Statistical Analysis Tool o JSAT es una biblioteca GPL3 que utiliza un marco orientado a objetos para ayudar a los usuarios a implementar el aprendizaje automático con Java. Por lo general, los estudiantes y los desarrolladores lo usan con fines de autoeducación. En comparación con otras bibliotecas de implementación de IA, JSAT tiene la mayor cantidad de algoritmos de ML y es el más rápido entre todos los marcos. Con cero dependencias externas, es altamente flexible y eficiente y ofrece un alto rendimiento.
8. El marco de aprendizaje automático de Encog
Encog está escrito en Java y C# y comprende bibliotecas que ayudan a implementar algoritmos de aprendizaje automático. Se utiliza para construir algoritmos genéticos, redes bayesianas, modelos estadísticos como el modelo oculto de Markov y más.
9. mazo
Machine Learning for Language Toolkit o Mallet se utiliza en el procesamiento del lenguaje natural (NLP). Como la mayoría de los otros marcos de implementación de ML, Mallet también brinda soporte para modelado de datos, agrupación de datos, procesamiento de documentos, clasificación de documentos, etc.
10. Chispa MLlib
Las empresas utilizan Spark MLlib para mejorar la eficiencia y la escalabilidad de la gestión del flujo de trabajo. Procesa grandes cantidades de datos y es compatible con algoritmos de aprendizaje automático pesados.
Pago: Ideas de proyectos de aprendizaje automático
Conclusión
Esto nos lleva al final del artículo. Para obtener más información sobre los conceptos de aprendizaje automático, póngase en contacto con los mejores profesores de IIIT Bangalore y la Universidad John Moores de Liverpool a través del programa de Maestría en Ciencias en Aprendizaje Automático e IA de upGrad.
¿Por qué deberíamos usar Java junto con Machine Learning?
A los profesionales del aprendizaje automático les resultará más fácil interactuar con los repositorios de código actuales si eligen Java como lenguaje de programación para sus proyectos. Es un lenguaje de aprendizaje automático de preferencia debido a características como facilidad de uso, servicios de paquete, mejor interacción del usuario, depuración rápida e ilustración gráfica de datos. Java facilita a los desarrolladores de Machine Learning escalar sus sistemas, lo que lo convierte en una excelente opción para crear aplicaciones de Machine Learning grandes y sofisticadas desde cero. Java Virtual Machine (JVM) admite una serie de entornos de desarrollo integrados (IDE) que permiten a los aprendices automáticos diseñar nuevas herramientas rápidamente.
¿Es fácil aprender Java?
Como Java es un lenguaje de alto nivel, es fácil de entender. Como estudiante, no tendrá que entrar en tantos detalles, ya que es un lenguaje bien estructurado y orientado a objetos que es lo suficientemente simple para que los principiantes lo comprendan. Debido a que existen numerosos procedimientos que funcionan automáticamente, puede dominarlos rápidamente. No tienes que entrar en muchos detalles sobre cómo funcionan las cosas allí. Java es un lenguaje de programación independiente de la plataforma. Permite a un programador crear una aplicación móvil que se puede utilizar en cualquier dispositivo. Es el lenguaje preferido de Internet de las cosas, así como la mejor herramienta para desarrollar aplicaciones de nivel empresarial.
¿Qué es ADAMS y cómo es útil en el aprendizaje automático?
El sistema avanzado de aprendizaje automático y minería de datos (ADAMS) es un motor de flujo de trabajo con licencia GPLv3 para crear y administrar rápidamente flujos de trabajo reactivos basados en datos que pueden incorporarse fácilmente en los procesos comerciales. El motor de flujo de trabajo, que sigue el principio de menos es más, se encuentra en el corazón de ADAMS. ADAMS emplea una estructura similar a un árbol en lugar de permitir que el usuario organice los operadores (o actores en la jerga de ADAMS) en un lienzo y luego vincule manualmente las entradas y salidas. No se requieren conexiones explícitas porque esta estructura y los actores de control determinan cómo fluyen los datos en el proceso. La representación de objetos internos y el anidamiento de suboperadores dentro de los controladores de operadores dan como resultado una estructura similar a un árbol. ADAMS proporciona un conjunto diverso de agentes para la recuperación, el procesamiento, la minería y la visualización de datos.