
¿Qué es el árbol de decisión en minería de datos? Tipos, ejemplos del mundo real y aplicaciones
Publicado: 2021-06-15Tabla de contenido
Introducción a la minería de datos
Los datos a menudo están presentes como datos sin procesar que deben procesarse de manera efectiva para convertirlos en información útil. La predicción de los resultados a menudo se basa en el proceso de encontrar patrones, anomalías o correlaciones dentro de los datos. El proceso se denominó “descubrimiento de conocimiento en bases de datos”.
Fue recién en la década de 1990 cuando se acuñó el término “minería de datos”. La minería de datos se basó en tres disciplinas: estadísticas, inteligencia artificial y aprendizaje automático. La minería de datos automatizada ha cambiado el proceso de análisis de un enfoque tedioso a uno más rápido. La minería de datos permite al usuario
- Elimina todos los datos ruidosos y caóticos
- Comprender los datos relevantes y utilizarlos para la predicción de información útil.
- El proceso de predicción de decisiones informadas se acelera .
La minería de datos también puede denominarse como el proceso de identificar patrones ocultos de información que requieren categorización. Solo entonces los datos se pueden convertir en datos útiles. Los datos útiles se pueden introducir en un almacén de datos, algoritmos de minería de datos, análisis de datos para la toma de decisiones.
Árbol de decisión en minería de datos
Un tipo de técnica de minería de datos, el árbol de decisión en la minería de datos construye un modelo para la clasificación de datos. Los modelos se construyen en forma de estructura de árbol y, por lo tanto, pertenecen a la forma de aprendizaje supervisado. Aparte de los modelos de clasificación, los árboles de decisión se utilizan para construir modelos de regresión para predecir etiquetas de clase o valores que ayudan en el proceso de toma de decisiones. Tanto los datos numéricos como categóricos como el género, la edad, etc. pueden ser utilizados por un árbol de decisión.
Estructura de un árbol de decisión
La estructura de un árbol de decisión consta de un nodo raíz, ramas y nodos hoja. Los nodos ramificados son los resultados de un árbol y los nodos internos representan la prueba de un atributo. Los nodos hoja representan una etiqueta de clase.
Funcionamiento de un árbol de decisión
1. Un árbol de decisión funciona bajo el enfoque de aprendizaje supervisado tanto para variables discretas como continuas. El conjunto de datos se divide en subconjuntos en función del atributo más significativo del conjunto de datos. La identificación del atributo y la división se realiza a través de los algoritmos.
2. La estructura del árbol de decisión consta del nodo raíz, que es el nodo predictor significativo. El proceso de división se produce a partir de los nodos de decisión, que son los subnodos del árbol. Los nodos que no se dividen más se denominan nodos de hoja o terminales.
3. El conjunto de datos se divide en regiones homogéneas y que no se superponen siguiendo un enfoque de arriba hacia abajo. La capa superior proporciona las observaciones en un solo lugar que luego se divide en ramas. El proceso se denomina "Enfoque codicioso" debido a que se centra solo en el nodo actual en lugar de los nodos futuros.
4. Hasta que ya menos que se alcance un criterio de parada, el árbol de decisión seguirá ejecutándose.
5. Con la construcción de un árbol de decisión, se genera mucho ruido y valores atípicos. Para eliminar estos valores atípicos y datos ruidosos, se aplica un método de "poda de árboles". Por lo tanto, la precisión del modelo aumenta.
6. La precisión de un modelo se verifica en un conjunto de prueba que consta de tuplas de prueba y etiquetas de clase. Se define un modelo preciso en función de los porcentajes de tuplas y clases del conjunto de pruebas de clasificación del modelo.
Figura 1 : Un ejemplo de un árbol podado y no podado
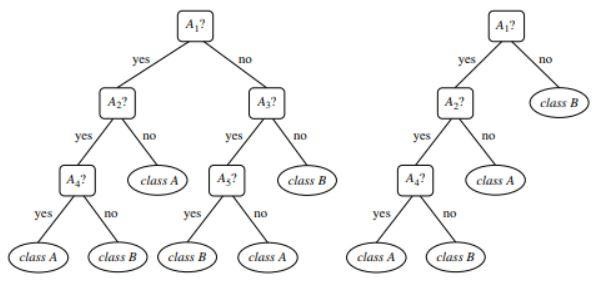
Fuente
Tipos de árbol de decisión
Los árboles de decisión conducen al desarrollo de modelos de clasificación y regresión basados en una estructura similar a un árbol. Los datos se dividen en subconjuntos más pequeños. El resultado de un árbol de decisión es un árbol con nodos de decisión y nodos hoja. A continuación se explican dos tipos de árboles de decisión:
1. Clasificación
La clasificación incluye la construcción de modelos que describen etiquetas de clase importantes. Se aplican en las áreas de aprendizaje automático y reconocimiento de patrones. Los árboles de decisión en el aprendizaje automático a través de modelos de clasificación conducen a la detección de fraudes, diagnósticos médicos, etc. El proceso de dos pasos de un modelo de clasificación incluye:
- Aprendizaje: Se construye un modelo de clasificación basado en los datos de entrenamiento.
- Clasificación: la precisión del modelo se verifica y luego se usa para la clasificación de los nuevos datos. Las etiquetas de clase tienen la forma de valores discretos como "sí" o "no", etc.
Figura 2 : Ejemplo de un modelo de clasificación .
Fuente
2. Regresión
Los modelos de regresión se utilizan para el análisis de regresión de datos, es decir, la predicción de atributos numéricos. Estos también se denominan valores continuos. Por lo tanto, en lugar de predecir las etiquetas de clase, el modelo de regresión predice los valores continuos.
Lista de algoritmos utilizados
Un algoritmo de árbol de decisión conocido como "ID3" fue desarrollado en 1980 por un investigador de máquinas llamado J. Ross Quinlan. Este algoritmo fue sucedido por otros algoritmos como C4.5 desarrollado por él. Ambos algoritmos aplicaron el enfoque codicioso. El algoritmo C4.5 no utiliza el retroceso y los árboles se construyen de manera recursiva de arriba hacia abajo de dividir y conquistar. El algoritmo utilizó un conjunto de datos de entrenamiento con etiquetas de clase que se dividen en subconjuntos más pequeños a medida que se construye el árbol.
- Inicialmente se seleccionan tres parámetros: lista de atributos, método de selección de atributos y partición de datos. Los atributos del conjunto de entrenamiento se describen en la lista de atributos.
- El método de selección de atribuciones incluye el método para la selección del mejor atributo para la discriminación entre las tuplas.
- Una estructura de árbol depende del método de selección de atributos.
- La construcción de un árbol comienza con un solo nodo.
- La división de las tuplas se produce cuando se representan diferentes etiquetas de clase en una tupla. Esto conducirá a la formación de ramas del árbol.
- El método de división determina qué atributo debe seleccionarse para la partición de datos. Según este método, las ramas crecen a partir de un nodo según el resultado de la prueba.
- El método de división y partición se lleva a cabo de forma recursiva, lo que finalmente da como resultado un árbol de decisión para las tuplas del conjunto de datos de entrenamiento.
- El proceso de formación del árbol continúa hasta que ya menos que las tuplas restantes no puedan dividirse más.
- La complejidad del algoritmo se denota por
n * |D| * registro |D|
Donde, n es el número de atributos en el conjunto de datos de entrenamiento D y |D| es el número de tuplas.
Fuente
Figura 3: Una división de valor discreto
Las listas de algoritmos utilizados en un árbol de decisión son:
ID3
Todo el conjunto de datos S se considera como el nodo raíz al formar el árbol de decisión. Luego se realiza una iteración en cada atributo y se dividen los datos en fragmentos. El algoritmo comprueba y toma aquellos atributos que no se tomaron antes de los iterados. La división de datos en el algoritmo ID3 requiere mucho tiempo y no es un algoritmo ideal, ya que sobreajusta los datos.
C4.5
Es una forma avanzada de un algoritmo ya que los datos se clasifican como muestras. Tanto los valores continuos como los discretos se pueden manejar de manera eficiente a diferencia de ID3. Existe un método de poda que elimina las ramas no deseadas.
CARRO
Tanto las tareas de clasificación como las de regresión pueden ser realizadas por el algoritmo. A diferencia de ID3 y C4.5, los puntos de decisión se crean considerando el índice de Gini. Se aplica un algoritmo codicioso para el método de división con el objetivo de reducir la función de costo. En las tareas de clasificación, el índice de Gini se utiliza como función de costo para indicar la pureza de los nodos de hoja. En las tareas de regresión, la suma del error cuadrático se usa como función de costo para encontrar la mejor predicción.
CHAID
Como sugiere el nombre, significa Chi-square Automatic Interaction Detector, un proceso que trata con cualquier tipo de variables. Pueden ser variables nominales, ordinales o continuas. Los árboles de regresión usan la prueba F, mientras que la prueba Chi-cuadrado se usa en el modelo de clasificación.

MARTE
Es sinónimo de splines de regresión adaptativa multivariante. El algoritmo se implementa especialmente en tareas de regresión, donde los datos son en su mayoría no lineales.
División binaria recursiva codiciosa
Se produce un método de división binaria que da como resultado dos ramas. El desdoblamiento de las tuplas se realiza con el cálculo de la función de costo de desdoblamiento. Se selecciona la división de menor costo y el proceso se lleva a cabo recursivamente para calcular la función de costo de las otras tuplas.
Árbol de decisión con ejemplo del mundo real
Predecir el proceso de elegibilidad del préstamo a partir de los datos proporcionados.
Paso 1: Carga de los datos
Los valores nulos pueden eliminarse o rellenarse con algunos valores. La forma del conjunto de datos original era (614,13), y el nuevo conjunto de datos después de descartar los valores nulos es (480,13).
Paso 2: una mirada al conjunto de datos.

Paso 3: Dividir los datos en conjuntos de entrenamiento y prueba.
Paso 4: construye el modelo y ajusta el juego de trenes

Antes de la visualización se deben realizar algunos cálculos.
Cálculo 1: calcular la entropía del conjunto de datos total.

Cálculo 2: encuentre la entropía y la ganancia para cada columna.
- columna de género
- Condición 1: conjunto de datos con todos los hombres y luego,
p = 278, n = 116, p + n = 489
Entropía (G=Masculino) = 0.87
- Condición 2: conjunto de datos con todas las mujeres y luego,
p = 54 , n = 32 , p+n = 86
Entropía (G = Mujer) = 0.95
- Información promedio en la columna de género

- columna casada
- Condición 1: Casado = Sí(1)
En esta división, todo el conjunto de datos con estado Casado sí
p = 227 , n = 84 , p + n = 311
E(Casado = Sí) = 0,84
- Condición 2: Casado = No(0)
En esta división, todo el conjunto de datos con el estado Casado no
p = 105 , n = 64 , p + n = 169
E(Casado = No) = 0.957
- La información promedio en la columna Casado es
- columna educativa
- Condición 1: Educación = Graduado(1)
p = 271 , n = 112 , p + n = 383
E(Educación = Graduado) = 0.87
- Condición 2: Educación = No graduado (0)
p = 61 , n = 36 , p+n = 97
E(Educación = No Graduado) = 0.95
- Información promedio de la columna Educación= 0.886
Ganancia = 0.01
4) Columna de Trabajadores por Cuenta Propia
- Condición 1: Trabajador por Cuenta Propia = Sí(1)
p = 43 , n = 23 , p + n = 66
E(Autónomo=Sí) = 0,93
- Condición 2: Autónomo = No(0)
p = 289 , n = 125 , p+n = 414
E(Autónomo=No) = 0,88
- Información Promedio en Columna de Trabajadores por Cuenta Propia en Educación = 0.886
Ganancia = 0.01
- Columna Credit Score: la columna tiene 0 y 1 valor.
- Condición 1: Puntaje de crédito = 1
p = 325 , n = 85 , p+n = 410
E (puntuación de crédito = 1) = 0,73
- Condición 2: Puntaje de crédito = 0
p = 63 , n = 7 , p+n = 70
E (puntuación de crédito = 0) = 0,46
- Información promedio en la columna de puntuación de crédito = 0,69
Ganancia = 0.2
Comparar todos los valores de ganancia

La puntuación de crédito tiene la ganancia más alta. Por lo tanto, se utilizará como nodo raíz.
Paso 5: visualizar el árbol de decisión

Figura 5: Árbol de decisión con criterio Gini
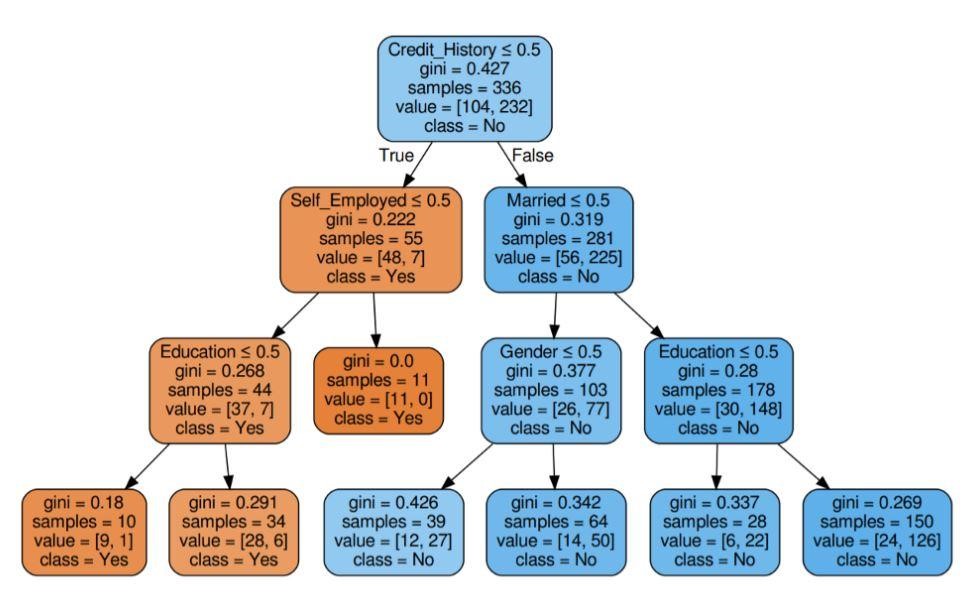 Fuente
Fuente
Figura 6: Árbol de decisión con entropía de criterio
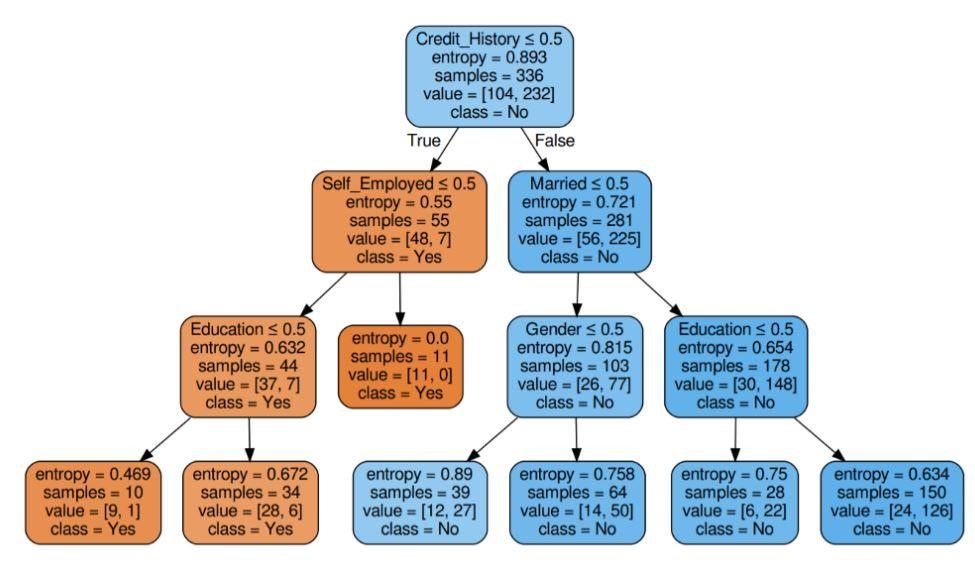
Fuente
Paso 6: Comprobar la puntuación del modelo
Casi el 80% por ciento de precisión anotó.
Lista de aplicaciones
Los expertos en información utilizan principalmente los árboles de decisión para llevar a cabo una investigación analítica. Pueden usarse ampliamente con fines comerciales para analizar o predecir dificultades. La flexibilidad del árbol de decisión permite que se utilicen en un área diferente:
1. Salud
Los árboles de decisión permiten predecir si un paciente padece una determinada enfermedad con condiciones de edad, peso, sexo, etc. Otras predicciones incluyen decidir el efecto del medicamento considerando factores como la composición, el período de fabricación, etc.
2. Sectores bancarios
Los árboles de decisión ayudan a predecir si una persona es elegible para un préstamo considerando su estado financiero, salario, miembros de la familia, etc. También pueden identificar fraudes con tarjetas de crédito, incumplimientos de préstamos, etc.
3. Sectores educativos
La preselección de un estudiante en función de su puntaje de mérito, asistencia, etc. se puede decidir con la ayuda de árboles de decisión.
Lista de ventajas
- Los resultados interpretables de un modelo de decisión se pueden representar para la alta dirección y las partes interesadas.
- Al construir un modelo de árbol de decisión, no se requiere preprocesamiento de los datos, es decir, normalización, escalado, etc.
- Ambos tipos de datos, numéricos y categóricos, pueden ser manejados por un árbol de decisión que muestra su mayor eficiencia de uso sobre otros algoritmos.
- El valor faltante en los datos no afecta el proceso de un árbol de decisión, lo que lo convierte en un algoritmo flexible.
¿Qué sigue?
Si está interesado en obtener experiencia práctica en minería de datos y recibir capacitación de expertos en el tema, puede consultar el Programa PG ejecutivo en ciencia de datos de upGrad. El curso está dirigido a cualquier grupo de edad entre 21 y 45 años de edad con un criterio mínimo de elegibilidad del 50 % o calificaciones equivalentes para aprobar en la graduación. Cualquier profesional que trabaje puede unirse a este programa ejecutivo PG certificado por IIIT Bangalore.
Los árboles de decisión en minería de datos tienen la capacidad de manejar datos muy complicados. Todos los árboles de decisión tienen tres nodos o porciones vitales. Vamos a discutir cada uno de ellos a continuación. Ahora que hemos entendido el funcionamiento de los árboles de decisión, intentemos ver algunas ventajas de usar árboles de decisión en la minería de datos.¿Qué es un árbol de decisión en minería de datos?
Un árbol de decisión es una forma de construir modelos en minería de datos. Puede entenderse como un árbol binario invertido. Incluye un nodo raíz, algunas ramas y nodos hoja al final.
Cada uno de los nodos internos en un árbol de decisión representa un estudio sobre un atributo. Cada una de las divisiones significa la consecuencia de ese estudio o examen en particular. Y finalmente, cada nodo hoja representa una etiqueta de clase.
El principal objetivo de construir un árbol de decisión es crear un ideal que se pueda utilizar para prever la clase en particular mediante el uso de procedimientos de juicio sobre datos anteriores.
Comenzamos con el nodo raíz, hacemos algunas relaciones con la variable raíz y hacemos divisiones que concuerdan con esos valores. Según las opciones base, saltamos a los nodos posteriores. ¿Cuáles son algunos de los nodos importantes que se utilizan en los árboles de decisión?
Cuando conectamos todos estos nodos, obtenemos divisiones. Podemos formar árboles con una variedad de dificultades utilizando estos nodos y divisiones un número infinito de veces. ¿Cuáles son las ventajas de utilizar árboles de decisión?
1. Cuando los comparamos con otros métodos, los árboles de decisión no requieren tanto cálculo para el entrenamiento de datos durante el preprocesamiento.
2. La estabilización de la información no está involucrada en los árboles de decisión.
3. Además, ni siquiera requieren escalado de información.
4. Incluso si se omiten algunos valores en el conjunto de datos, esto no interfiere en la construcción de árboles.
5. Estos modelos instintivos son idénticos. También están libres de estrés para la descripción.