
Creación de habilidades de voz para Google Assistant y Amazon Alexa
Publicado: 2022-03-10Durante la última década, ha habido un cambio sísmico hacia las interfaces conversacionales. A medida que las personas alcanzan la "pantalla máxima" e incluso comienzan a reducir el uso de sus dispositivos con funciones de bienestar digital integradas en la mayoría de los sistemas operativos.
Para combatir la fatiga de la pantalla, los asistentes de voz han ingresado al mercado para convertirse en una opción preferida para recuperar información rápidamente. Una estadística muy repetida establece que el 50% de las búsquedas se realizarán por voz en el año 2020. Además, a medida que aumenta la adopción, depende de los desarrolladores agregar "Interfaces conversacionales" y "Asistentes de voz" a su cinturón de herramientas.
Diseñando lo invisible
Para muchos, embarcarse en un proyecto de interfaz de usuario de voz (VUI) puede ser un poco como entrar en lo Desconocido. Obtenga más información sobre las lecciones aprendidas por William Merrill al diseñar para voz. Leer un artículo relacionado →
¿Qué es una interfaz conversacional?
Una interfaz conversacional (a veces abreviada como CUI) es cualquier interfaz en un lenguaje humano. Está diseñada para ser una interfaz más natural para el público en general que la GUI de la interfaz gráfica de usuario, que los desarrolladores front-end están acostumbrados a construir. Una GUI requiere humanos para aprender sus sintaxis específicas de la interfaz (botones de pensamiento, controles deslizantes y menús desplegables).
Esta diferencia clave en el uso del lenguaje humano hace que CUI sea más natural para las personas; requiere poco conocimiento y pone la carga de la comprensión en el dispositivo.
Por lo general, las CUI se presentan en dos formas: chatbots y asistentes de voz. Ambos han visto un aumento masivo en la adopción durante la última década gracias a los avances en el procesamiento del lenguaje natural (NLP).
Comprender la jerga de voz

| Palabra clave | Sentido |
|---|---|
| Habilidad/Acción | Una aplicación de voz, que puede cumplir una serie de propósitos |
| Intención | Acción prevista para que cumpla la habilidad, lo que el usuario quiere que haga la habilidad en respuesta a lo que dice. |
| Declaración | La oración que un usuario dice o pronuncia. |
| Palabra de despertar | La palabra o frase utilizada para que un asistente de voz comience a escuchar, por ejemplo, 'Hola google', 'Alexa' o 'Hola Siri' |
| Contexto | Las piezas de información contextual dentro de un enunciado, que ayudan a la habilidad a cumplir una intención, por ejemplo, 'hoy', 'ahora', 'cuando llegue a casa'. |
¿Qué es un asistente de voz?
Un asistente de voz es una pieza de software capaz de NLP (procesamiento del lenguaje natural). Recibe un comando de voz y devuelve una respuesta en formato de audio. En los últimos años, el alcance de cómo puede interactuar con un asistente se está expandiendo y evolucionando, pero el quid de la tecnología es el lenguaje natural adentro, mucha computación, lenguaje natural afuera.
Para aquellos que buscan un poco más de detalle:
- El software recibe una solicitud de audio de un usuario, procesa el sonido en fonemas, los componentes básicos del lenguaje.
- Por la magia de AI (específicamente Speech-To-Text), estos fonemas se convierten en una cadena de la solicitud aproximada, esta se guarda dentro de un archivo JSON que también contiene información adicional sobre el usuario, la solicitud y la sesión.
- Luego, el JSON se procesa (generalmente en la nube) para determinar el contexto y la intención de la solicitud.
- Según la intención, se devuelve una respuesta, nuevamente dentro de una respuesta JSON más grande, ya sea como una cadena o como SSML (más sobre esto más adelante)
- La respuesta se vuelve a procesar utilizando IA (naturalmente, al revés, texto a voz) que luego se devuelve al usuario.
Están sucediendo muchas cosas allí, la mayoría de las cuales no requieren un segundo pensamiento. Pero cada plataforma hace esto de manera diferente, y son los matices de la plataforma los que requieren un poco más de comprensión.

Dispositivos habilitados para voz
Los requisitos para que un dispositivo pueda tener un asistente de voz incorporado son bastante bajos. Requieren un micrófono, una conexión a Internet y un altavoz. Los parlantes inteligentes como Nest Mini y Echo Dot brindan este tipo de control de voz de baja fidelidad.
El siguiente en el ranking es voz + pantalla, esto se conoce como un dispositivo 'Multimodal' (más sobre esto más adelante), y son dispositivos como Nest Hub y Echo Show. Como los teléfonos inteligentes tienen esta funcionalidad, también pueden considerarse un tipo de dispositivo multimodal habilitado para voz.
Habilidades de voz
En primer lugar, cada plataforma tiene un nombre diferente para sus 'Habilidades de voz', Amazon va con habilidades, que me quedaré como un término universalmente entendido. Google opta por 'Acciones', y Samsung apuesta por 'cápsulas'.
Cada plataforma tiene sus propias habilidades integradas, como preguntar la hora, el clima y los juegos deportivos. Las habilidades creadas por desarrolladores (de terceros) se pueden invocar con una frase específica o, si a la plataforma le gusta, se pueden invocar implícitamente, sin una frase clave.
Invocación explícita : "Hola Google, habla con <nombre de la aplicación>".
Se indica explícitamente qué habilidad se solicita:
Invocación implícita : "Hola Google, ¿cómo está el clima hoy?"
El contexto de la solicitud implica qué servicio desea el usuario.
¿Qué asistentes de voz existen?
En el mercado occidental, los asistentes de voz son en gran medida una carrera de tres caballos. Apple, Google y Amazon tienen enfoques muy diferentes para sus asistentes y, como tales, atraen a diferentes tipos de desarrolladores y clientes.
Siri de Apple
Nombre del dispositivo : "Siri"
Frase de activación : "Hola Siri"
Siri tiene más de 375 millones de usuarios activos, pero en aras de la brevedad, no voy a entrar en demasiados detalles sobre Siri. Si bien puede ser bien adoptado a nivel mundial y estar integrado en la mayoría de los dispositivos de Apple, requiere que los desarrolladores ya tengan una aplicación en una de las plataformas de Apple y que esté escrita en Swift (mientras que las otras pueden estar escritas en el favorito de todos: Javascript). A menos que sea un desarrollador de aplicaciones que quiera expandir la oferta de su aplicación, actualmente puede omitir Apple hasta que abran su plataforma.
Asistente de Google
Nombres de dispositivos : "Google Home, Nest"
Frase de activación : "Hola Google"
Google tiene la mayor cantidad de dispositivos de los tres grandes, con más de mil millones en todo el mundo, esto se debe principalmente a la gran cantidad de dispositivos Android que tienen incorporado el Asistente de Google, con respecto a sus altavoces inteligentes dedicados, los números son un poco más pequeños. La misión general de Google con su asistente es deleitar a los usuarios, y siempre han sido muy buenos proporcionando interfaces ligeras e intuitivas.
Su objetivo principal en la plataforma es usar el tiempo, con la idea de convertirse en una parte habitual de la rutina diaria de los clientes. Como tales, se centran principalmente en la utilidad, la diversión familiar y las experiencias agradables.
Las habilidades desarrolladas para Google son mejores cuando se trata de juegos y piezas de participación, centrándose principalmente en la diversión familiar. Su reciente incorporación de lienzos para juegos es un testimonio de este enfoque. La plataforma de Google es mucho más estricta para el envío de habilidades y, como tal, su directorio es mucho más pequeño.
Amazon Alexa
Nombres de dispositivos : "Amazon Fire, Amazon Echo"
Frase de activación : "Alexa"
Amazon ha superado los 100 millones de dispositivos en 2019, esto proviene principalmente de las ventas de sus parlantes inteligentes y pantallas inteligentes, así como de su gama 'fuego' o tabletas y dispositivos de transmisión.
Las habilidades creadas para Amazon tienden a estar dirigidas a la compra de habilidades. Si está buscando una plataforma para expandir su servicio/comercio electrónico u ofrecer una suscripción, entonces Amazon es para usted. Dicho esto, el ISP no es un requisito para Alexa Skills, admite todo tipo de usos y está mucho más abierto a las presentaciones.
Los demás
Hay aún más asistentes de voz, como Bixby de Samsung, Cortana de Microsoft y el popular asistente de voz de código abierto Mycroft. Los tres tienen un seguimiento razonable, pero siguen siendo una minoría en comparación con los tres Goliat de Amazon, Google y Apple.
Construyendo en Amazon Alexa
Amazons Ecosystem for voice ha evolucionado para permitir a los desarrolladores desarrollar todas sus habilidades dentro de la consola de Alexa, por lo que, como ejemplo simple, voy a utilizar sus funciones integradas.
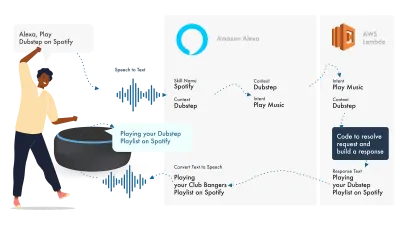
Alexa se ocupa del procesamiento del lenguaje natural y luego encuentra una intención adecuada, que se pasa a nuestra función Lambda para que se ocupe de la lógica. Esto devuelve algunos bits de conversación (SSML, texto, tarjetas, etc.) a Alexa, que convierte esos bits en audio e imágenes para mostrarlos en el dispositivo.
Trabajar en Amazon es relativamente simple, ya que le permite crear todas las partes de su habilidad dentro de la Consola para desarrolladores de Alexa. La flexibilidad está ahí para usar AWS o un punto de enlace HTTPS, pero para habilidades simples, ejecutar todo dentro de la consola de desarrollo debería ser suficiente.
Construyamos una habilidad simple de Alexa
Dirígete a la consola de Amazon Alexa, crea una cuenta si no tienes una e inicia sesión.
Haga clic en Create Skill y luego asígnele un nombre,
Elija custom como su modelo,
y elija Alexa-Hosted (Node.js) para su recurso de back-end.
Una vez que haya terminado el aprovisionamiento, tendrá una habilidad básica de Alexa, tendrá su intención construida para usted y un código de back-end para que pueda comenzar.
Si hace clic en HelloWorldIntent en sus Intents, verá algunas expresiones de muestra ya configuradas para usted, agreguemos una nueva en la parte superior. Nuestra habilidad se llama hola mundo, así que agregue Hola mundo como expresión de muestra. La idea es capturar cualquier cosa que el usuario pueda decir para desencadenar esta intención. Esto podría ser "Hola mundo", "Hola mundo", y así sucesivamente.
¿Qué está pasando en el Fulfillment JS?
Entonces, ¿qué está haciendo el código? Aquí está el código predeterminado:
const HelloWorldIntentHandler = { canHandle(handlerInput) { return Alexa.getRequestType(handlerInput.requestEnvelope) === 'IntentRequest' && Alexa.getIntentName(handlerInput.requestEnvelope) === 'HelloWorldIntent'; }, handle(handlerInput) { const speakOutput = 'Hello World!'; return handlerInput.responseBuilder .speak(speakOutput) .getResponse(); } }; Esto utiliza ask-sdk-core y esencialmente crea JSON para nosotros. canHandle le permite a ask saber que puede manejar intentos, específicamente 'HelloWorldIntent'. handle toma la entrada y construye la respuesta. Lo que esto genera se ve así:

{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }
Podemos ver que speak emite ssml en nuestro json, que es lo que el usuario escuchará cuando lo diga Alexa.
Edificio para el Asistente de Google
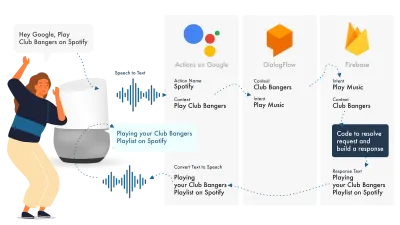
La forma más sencilla de crear acciones en Google es usar su consola AoG en combinación con Dialogflow, puede ampliar sus habilidades con firebase, pero al igual que con el tutorial de Amazon Alexa, simplifiquemos las cosas.
El Asistente de Google usa tres partes principales, AoG, que se ocupa del NLP, Dialogflow, que resuelve sus intenciones, y Firebase, que cumple con la solicitud y produce la respuesta que se enviará de vuelta a AoG.
Al igual que con Alexa, Dialogflow le permite crear sus funciones directamente dentro de la plataforma.
Construyamos una acción en Google
Hay tres plataformas para hacer malabares a la vez con la solución de Google, a las que se accede desde tres consolas diferentes, ¡así que tabula arriba!
Configuración de flujo de diálogo
Comencemos iniciando sesión en la consola de Dialogflow. Una vez que haya iniciado sesión, cree un nuevo agente desde el menú desplegable justo debajo del logotipo de Dialogflow.
Asigne un nombre a su agente y agréguelo en el 'Desplegable de proyectos de Google', mientras tiene seleccionado "Crear un nuevo proyecto de Google".
Haga clic en el botón Crear y deje que haga su magia, tomará un poco de tiempo configurar el agente, así que tenga paciencia.
Configuración de las funciones de Firebase
Bien, ahora podemos comenzar a conectar la lógica de Cumplimiento.
Dirígete a la pestaña Cumplimiento. Marque para habilitar el editor en línea y use los fragmentos JS a continuación:
índice.js
'use strict'; // So that you have access to the dialogflow and conversation object const { dialogflow } = require('actions-on-google'); // So you have access to the request response stuff >> functions.https.onRequest(app) const functions = require('firebase-functions'); // Create an instance of dialogflow for your app const app = dialogflow({debug: true}); // Build an intent to be fulfilled by firebase, // the name is the name of the intent that dialogflow passes over app.intent('Default Welcome Intent', (conv) => { // Any extra logic goes here for the intent, before returning a response for firebase to deal with return conv.ask(`Welcome to a firebase fulfillment`); }); // Finally we export as dialogflowFirebaseFulfillment so the inline editor knows to use it exports.dialogflowFirebaseFulfillment = functions.https.onRequest(app);paquete.json
{ "name": "functions", "description": "Cloud Functions for Firebase", "scripts": { "lint": "eslint .", "serve": "firebase serve --only functions", "shell": "firebase functions:shell", "start": "npm run shell", "deploy": "firebase deploy --only functions", "logs": "firebase functions:log" }, "engines": { "node": "10" }, "dependencies": { "actions-on-google": "^2.12.0", "firebase-admin": "~7.0.0", "firebase-functions": "^3.3.0" }, "devDependencies": { "eslint": "^5.12.0", "eslint-plugin-promise": "^4.0.1", "firebase-functions-test": "^0.1.6" }, "private": true }Ahora regrese a sus intentos, vaya a Intención de bienvenida predeterminada y desplácese hacia abajo hasta cumplimiento, asegúrese de que 'Habilitar llamada de webhook para este intento' esté marcado para cualquier intento que desee cumplir con javascript. Presiona Guardar.
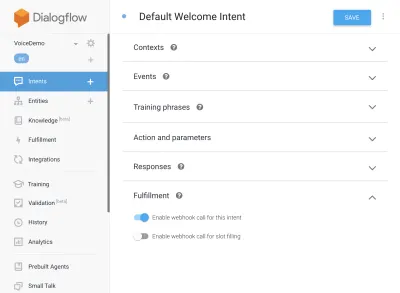
Configuración de AoG
Nos estamos acercando a la línea de meta ahora. Dirígete a la pestaña Integraciones y haz clic en Configuración de integración en la opción Asistente de Google en la parte superior. Esto abrirá un modal, así que hagamos clic en prueba, lo que integrará su Dialogflow con Google y abrirá una ventana de prueba en Acciones en Google.
En la ventana de prueba, podemos hacer clic en Hablar con mi aplicación de prueba (cambiaremos esto en un segundo), y listo, tenemos el mensaje de nuestro javascript que se muestra en una prueba del asistente de Google.
Podemos cambiar el nombre del asistente en la pestaña Desarrollar, arriba en la parte superior.
Entonces, ¿qué está pasando en el Fulfillment JS?
En primer lugar, estamos usando dos paquetes npm, actions-on-google, que proporciona todo el cumplimiento que necesitan tanto AoG como Dialogflow, y en segundo lugar, firebase-functions, que lo adivinó, contiene ayudantes para firebase.
Luego creamos la 'aplicación', que es un objeto que contiene todas nuestras intenciones.
Cada intención que se crea pasó 'conv', que es el objeto de conversación que envía Actions On Google. Podemos usar el contenido de conv para detectar información sobre interacciones previas con el usuario (como su ID e información sobre su sesión con nosotros).
Devolvemos un 'objeto conv.ask', que contiene nuestro mensaje de respuesta al usuario, listo para que responda con otra intención. Podríamos usar 'conv.close' para terminar la conversación si quisiéramos terminar la conversación allí.
Finalmente, envolvemos todo en una función HTTPS de firebase, que se ocupa de la lógica de solicitud-respuesta del lado del servidor por nosotros.
De nuevo, si nos fijamos en la respuesta que se genera:
{ "payload": { "google": { "expectUserResponse": true, "richResponse": { "items": [ { "simpleResponse": { "textToSpeech": "Welcome to a firebase fulfillment" } } ] } } } } Podemos ver que se ha inyectado el texto de conv.ask en el área textToSpeech . Si hubiéramos elegido conv.close , expectUserResponse se configuraría como false y la conversación se cerraría después de que se haya entregado el mensaje.
Constructores de voz de terceros
Al igual que la industria de las aplicaciones, a medida que la voz gana fuerza, han comenzado a aparecer herramientas de terceros en un intento de aliviar la carga de los desarrolladores, permitiéndoles construir una vez, implementar dos veces.
Jovo y Voiceflow son actualmente los dos más populares, especialmente desde la adquisición de PullString por parte de Apple. Cada plataforma ofrece un nivel diferente de abstracción, por lo que realmente solo depende de cuán simplificada sea su interfaz.
Extendiendo tu habilidad
Ahora que te has dado cuenta de cómo construir una habilidad básica de 'Hola mundo', hay muchas campanas y silbatos que se pueden agregar a tu habilidad. Estos son la guinda del pastel de los asistentes de voz y le darán a sus usuarios mucho valor adicional, lo que los llevará a repetir oportunidades comerciales personalizadas y potenciales.
SSML
SSML significa lenguaje de marcado de síntesis de voz y funciona con una sintaxis similar a HTML, la diferencia clave es que está creando una respuesta hablada, no contenido en una página web.
'SSML' como término es un poco engañoso, ¡puede hacer mucho más que síntesis de voz! Puede tener voces en paralelo, puede incluir ruidos ambientales, discursos (vale la pena escucharlos por derecho propio, piense en emojis para frases famosas) y música.
¿Cuándo debo usar SSML?
SSML es genial; hace una experiencia mucho más atractiva para el usuario, pero lo que también hace es reducir la flexibilidad de la salida de audio. Recomiendo usarlo para áreas más estáticas del habla. Puede usar variables en él para nombres, etc., pero a menos que tenga la intención de construir un generador SSML, la mayoría de los SSML serán bastante estáticos.
Comience con un discurso simple en su habilidad y, una vez que esté completo, mejore las áreas que son más estáticas con SSML, pero obtenga lo esencial antes de pasar a las campanas y silbatos. Habiendo dicho eso, un informe reciente dice que el 71% de los usuarios prefieren una voz humana (real) a una sintetizada, así que si tiene la facilidad para hacerlo, ¡salga y hágalo!

En compras de habilidades
Las compras dentro de la habilidad (o ISP) son similares al concepto de compras dentro de la aplicación. Las habilidades tienden a ser gratuitas, pero algunas permiten la compra de contenido/suscripciones 'premium' dentro de la aplicación, que pueden mejorar la experiencia de un usuario, desbloquear nuevos niveles en los juegos o permitir el acceso a contenido de pago.
multimodal
Las respuestas multimodales cubren mucho más que la voz, aquí es donde los asistentes de voz realmente pueden brillar con imágenes complementarias en los dispositivos que los admiten. La definición de experiencias multimodales es mucho más amplia y esencialmente significa múltiples entradas (teclado, mouse, pantalla táctil, voz, etc.).
Las habilidades multimodales están destinadas a complementar la experiencia de voz central, brindando información complementaria adicional para impulsar la UX. Al crear una experiencia multimodal, recuerde que la voz es el principal portador de información. Muchos dispositivos no tienen pantalla, por lo que su habilidad aún debe funcionar sin una, así que asegúrese de probar con múltiples tipos de dispositivos; ya sea de verdad o en el simulador.

Plurilingüe
Las habilidades multilingües son habilidades que funcionan en varios idiomas y abren sus habilidades a múltiples mercados.
La complejidad de hacer que su habilidad sea multilingüe depende de cuán dinámicas sean sus respuestas. Las habilidades con respuestas relativamente estáticas, por ejemplo, devolver la misma frase cada vez, o usar solo una pequeña cantidad de frases, son mucho más fáciles de hacer multilingües que las habilidades dinámicas en expansión.
El truco con multilingüe es tener un socio de traducción confiable, ya sea a través de una agencia o un traductor en Fiverr. Debe poder confiar en las traducciones proporcionadas, especialmente si no entiende el idioma al que se traduce. ¡El traductor de Google no cortará la mostaza aquí!
Conclusión
Si alguna vez hubo un momento para ingresar a la industria de la voz, sería ahora. Tanto en su mejor momento como en su infancia, así como los nueve grandes, están invirtiendo miles de millones para crecer y llevar asistentes de voz a los hogares y las rutinas diarias de todos.
Elegir qué plataforma usar puede ser complicado, pero según lo que pretenda construir, la plataforma a usar debe brillar o, en su defecto, utilizar una herramienta de terceros para cubrir sus apuestas y construir en múltiples plataformas, especialmente si su habilidad es menos complicado con menos partes móviles.
Yo, por mi parte, estoy entusiasmado con el futuro de la voz a medida que se vuelve omnipresente; la dependencia de la pantalla se reducirá y los clientes podrán interactuar naturalmente con su asistente. Pero primero, depende de nosotros desarrollar las habilidades que la gente querrá de su asistente.