
Comprender los genéricos de TypeScript
Publicado: 2022-03-10En este artículo, aprenderemos el concepto de genéricos en TypeScript y examinaremos cómo se pueden usar los genéricos para escribir código modular, desacoplado y reutilizable. En el camino, discutiremos brevemente cómo encajan en mejores patrones de prueba, enfoques para el manejo de errores y separación de dominio/acceso a datos.
Un ejemplo del mundo real
Quiero entrar en el mundo de los genéricos no explicando qué son, sino proporcionando un ejemplo intuitivo de por qué son útiles. Suponga que se le ha asignado la tarea de crear una lista dinámica rica en funciones. Puede llamarlo matriz, ArrayList , List , std::vector o lo que sea, dependiendo de su idioma. Quizás esta estructura de datos también deba tener sistemas de búfer incorporados o intercambiables (como una opción de inserción de búfer circular). Será un contenedor alrededor de la matriz JavaScript normal para que podamos trabajar con nuestra estructura en lugar de matrices simples.
El problema inmediato con el que se encontrará es el de las restricciones impuestas por el sistema de tipos. En este punto, no puede aceptar cualquier tipo que desee en una función o método de una manera limpia y agradable (revisaremos esta declaración más adelante).
La única solución obvia es replicar nuestra estructura de datos para todos los tipos diferentes:
const intList = IntegerList.create(); intList.add(4); const stringList = StringList.create(); stringList.add('hello'); const userList = UserList.create(); userList.add(new User('Jamie')); La sintaxis .create() aquí puede parecer arbitraria y, de hecho, new SomethingList() sería más sencilla, pero verá por qué usamos este método de fábrica estático más adelante. Internamente, el método de create llama al constructor.
Este es terrible. Tenemos mucha lógica dentro de esta estructura de colección, y la estamos duplicando descaradamente para admitir diferentes casos de uso, rompiendo por completo el principio DRY en el proceso. Cuando decidamos cambiar nuestra implementación, tendremos que propagar/reflejar manualmente esos cambios en todas las estructuras y tipos que admitimos, incluidos los tipos definidos por el usuario, como en el último ejemplo anterior. Supongamos que la estructura de la colección en sí tuviera 100 líneas de largo: sería una pesadilla mantener múltiples implementaciones diferentes donde la única diferencia entre ellas son los tipos.
Una solución inmediata que podría venir a la mente, especialmente si tiene una mentalidad orientada a objetos, es considerar un "supertipo" raíz, si lo desea. En C#, por ejemplo, existe un tipo con el nombre de object , y object es un alias para la clase System.Object . En el sistema de tipos de C#, todos los tipos, ya sean predefinidos o definidos por el usuario y sean tipos de referencia o tipos de valor, heredan directa o indirectamente de System.Object . Esto significa que se puede asignar cualquier valor a una variable de tipo object (sin entrar en la semántica de pila/montón y encajonamiento/desencajonamiento).
En este caso, nuestro problema parece resuelto. Podemos usar un tipo como any y eso nos permitirá almacenar lo que queramos dentro de nuestra colección sin tener que duplicar la estructura, y de hecho, eso es muy cierto:
const intList = AnyList.create(); intList.add(4); const stringList = AnyList.create(); stringList.add('hello'); const userList = AnyList.create(); userList.add(new User('Jamie')); Veamos la implementación real de nuestra lista usando any :
class AnyList { private values: any[] = []; private constructor (values: any[]) { this.values = values; // Some more construction work. } public add(value: any): void { this.values.push(value); } public where(predicate: (value: any) => boolean): AnyList { return AnyList.from(this.values.filter(predicate)); } public select(selector: (value: any) => any): AnyList { return AnyList.from(this.values.map(selector)); } public toArray(): any[] { return this.values; } public static from(values: any[]): AnyList { // Perhaps we perform some logic here. // ... return new AnyList(values); } public static create(values?: any[]): AnyList { return new AnyList(values ?? []); } // Other collection functions. // ... }Todos los métodos son relativamente simples, pero comenzaremos con el constructor. Su visibilidad es privada, ya que asumiremos que nuestra lista es compleja y deseamos prohibir la construcción arbitraria. También es posible que deseemos realizar la lógica antes de la construcción, por lo que, por estos motivos, y para mantener puro el constructor, delegamos estas preocupaciones en métodos estáticos de fábrica/ayuda, lo que se considera una buena práctica.
Se proporcionan los métodos estáticos from y create . El método from acepta una matriz de valores, realiza una lógica personalizada y luego los usa para construir la lista. El método estático de create toma una matriz opcional de valores en caso de que queramos sembrar nuestra lista con datos iniciales. El "operador coalescente nulo" ( ?? ) se usa para construir la lista con una matriz vacía en caso de que no se proporcione una. Si el lado izquierdo del operando es null o undefined , volveremos al lado derecho, porque en este caso, values son opcionales y, por lo tanto, pueden no estar undefined . Puede obtener más información sobre la fusión nula en la página de documentación de TypeScript correspondiente.
También agregué un método select y where . Estos métodos simplemente envuelven el map y el filter de JavaScript, respectivamente. select nos permite proyectar una matriz de elementos en una nueva forma en función de la función de selección proporcionada, y where nos permite filtrar ciertos elementos en función de la función de predicado proporcionada. El método toArray simplemente convierte la lista en una matriz devolviendo la referencia de la matriz que tenemos internamente.
Finalmente, suponga que la clase User contiene un método getName que devuelve un nombre y también acepta un nombre como su primer y único argumento constructor.
Nota: algunos lectores reconoceránWhereySelectde LINQ de C#, pero tenga en cuenta que estoy tratando de mantener esto simple, por lo que no me preocupa la pereza o la ejecución diferida. Esas son optimizaciones que podrían y deberían hacerse en la vida real.
Además, como nota interesante, quiero discutir el significado de “predicado”. En Matemática Discreta y Lógica Proposicional, tenemos el concepto de “proposición”. Una proposición es una afirmación que puede considerarse verdadera o falsa, como “cuatro es divisible por dos”. Un “predicado” es una proposición que contiene una o más variables, por lo que la veracidad de la proposición depende de la de esas variables. Puedes pensarlo como una función, comoP(x) = x is divisible by two, porque necesitamos saber el valor dexpara determinar si la declaración es verdadera o falsa. Puede obtener más información sobre la lógica de predicados aquí.
Hay algunos problemas que surgirán del uso de any . El compilador de TypeScript no sabe nada acerca de los elementos dentro de la lista/matriz interna, por lo tanto, no proporcionará ninguna ayuda dentro de where o select o al agregar elementos:
// Providing seed data. const userList = AnyList.create([new User('Jamie')]); // This is fine and expected. userList.add(new User('Tom')); userList.add(new User('Alice')); // This is an acceptable input to the TS Compiler, // but it's not what we want. We'll definitely // be surprised later to find strings in a list // of users. userList.add('Hello, World!'); // Also acceptable. We have a large tuple // at this point rather than a homogeneous array. userList.add(0); // This compiles just fine despite the spelling mistake (extra 's'): // The type of `users` is any. const users = userList.where(user => user.getNames() === 'Jamie'); // Property `ssn` doesn't even exist on a `user`, yet it compiles. users.toArray()[0].ssn = '000000000'; // `usersWithId` is, again, just `any`. const usersWithId = userList.select(user => ({ id: newUuid(), name: user.getName() })); // Oops, it's "id" not "ID", but TS doesn't help us. // We compile just fine. console.log(usersWithId.toArray()[0].ID); Dado que TypeScript solo sabe que el tipo de todos los elementos de la matriz es any , no puede ayudarnos en el momento de la compilación con las propiedades inexistentes o la función getNames que ni siquiera existe, por lo que este código generará múltiples errores de tiempo de ejecución inesperados. .
Para ser honesto, las cosas comienzan a verse bastante deprimentes. Intentamos implementar nuestra estructura de datos para cada tipo concreto que deseábamos admitir, pero rápidamente nos dimos cuenta de que eso no se podía mantener de ninguna manera. Entonces, pensamos que estábamos llegando a alguna parte usando any , que es análogo a depender de un supertipo raíz en una cadena de herencia de la que derivan todos los tipos, pero llegamos a la conclusión de que perdemos la seguridad de tipos con ese método. ¿Cuál es la solución, entonces?
Resulta que, al principio del artículo, mentí (más o menos):
"En este punto, no puede aceptar cualquier tipo que desee en una función o método de una manera agradable y limpia".
De hecho, puede, y ahí es donde entran los genéricos. Note que dije "en este punto", porque asumí que no sabíamos sobre los genéricos en ese punto del artículo.
Comenzaré mostrando la implementación completa de nuestra estructura List con Generics, y luego daremos un paso atrás, analizaremos lo que realmente son y determinaremos su sintaxis de manera más formal. Lo he llamado TypedList para diferenciarlo de nuestro AnyList anterior:
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T): void { this.values.push(value); } public where(predicate: (value: T) => boolean): TypedList<T> { return TypedList.from<T>(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U): TypedList<U> { return TypedList.from<U>(this.values.map(selector)); } public toArray(): T[] { return this.values; } public static from<U>(values: U[]): TypedList<U> { // Perhaps we perform some logic here. // ... return new TypedList<U>(values); } public static create<U>(values?: U[]): TypedList<U> { return new TypedList<U>(values ?? []); } // Other collection functions. // .. }Intentemos cometer los mismos errores que antes una vez más:
// Here's the magic. `TypedList` will operate on objects // of type `User` due to the `<User>` syntax. const userList = TypedList.create<User>([new User('Jamie')]); // The compiler expects this. userList.add(new User('Tom')); userList.add(new User('Alice')); // Argument of type '0' is not assignable to parameter // of type 'User'. ts(2345) userList.add(0); // Property 'getNames' does not exist on type 'User'. // Did you mean 'getName'? ts(2551) // Note: TypeScript infers the type of `users` to be // `TypedList<User>` const users = userList.where(user => user.getNames() === 'Jamie'); // Property 'ssn' does not exist on type 'User'. ts(2339) users.toArray()[0].ssn = '000000000'; // TypeScript infers `usersWithId` to be of type // `TypedList<`{ id: string, name: string }> const usersWithId = userList.select(user => ({ id: newUuid(), name: user.getName() })); // Property 'ID' does not exist on type '{ id: string; name: string; }'. // Did you mean 'id'? ts(2551) console.log(usersWithId.toArray()[0].ID)Como puede ver, el compilador de TypeScript nos ayuda activamente con la seguridad de tipos. Todos esos comentarios son errores que recibo del compilador cuando intento compilar este código. Los genéricos nos han permitido especificar un tipo en el que deseamos permitir que opere nuestra lista y, a partir de eso, TypeScript puede decir los tipos de todo, hasta las propiedades de los objetos individuales dentro de la matriz.
Los tipos que proporcionamos pueden ser tan simples o complejos como queramos que sean. Aquí puede ver que podemos pasar interfaces tanto primitivas como complejas. También podríamos pasar otras matrices, clases o cualquier cosa:
const numberList = TypedList.create<number>(); numberList.add(4); const stringList = TypedList.create<string>(); stringList.add('Hello, World'); // Example of a complex type interface IAircraft { apuStatus: ApuStatus; inboardOneRPM: number; altimeter: number; tcasAlert: boolean; pushBackAndStart(): Promise<void>; ilsCaptureGlidescope(): boolean; getFuelStats(): IFuelStats; getTCASHistory(): ITCASHistory; } const aircraftList = TypedList.create<IAircraft>(); aircraftList.add(/* ... */); // Aggregate and generate report: const stats = aircraftList.select(a => ({ ...a.getFuelStats(), ...a.getTCASHistory() })); Los usos peculiares de T y U y <T> y <U> en la implementación de TypedList<T> son ejemplos de genéricos en acción. Habiendo cumplido con nuestra directiva de construir una estructura de colección con seguridad de tipos, dejaremos atrás este ejemplo por ahora y volveremos a él una vez que comprendamos qué son realmente los genéricos, cómo funcionan y su sintaxis. Cuando estoy aprendiendo un nuevo concepto, siempre me gusta comenzar viendo un ejemplo complejo del concepto en uso, de modo que cuando comience a aprender los conceptos básicos, pueda establecer conexiones entre los temas básicos y el ejemplo existente que tengo en mi cabeza.
¿Qué son los genéricos?
Una forma sencilla de entender los genéricos es considerarlos relativamente análogos a los marcadores de posición o variables pero para tipos. Eso no quiere decir que pueda realizar las mismas operaciones con un marcador de posición de tipo genérico que con una variable, pero una variable de tipo genérico podría considerarse como un marcador de posición que representa un tipo concreto que se usará en el futuro. Es decir, el uso de Generics es un método para escribir programas en términos de tipos que se especificarán en un momento posterior. La razón por la que esto es útil es porque nos permite construir estructuras de datos que son reutilizables en los diferentes tipos en los que operan (o tipo agnóstico).
Esa no es particularmente la mejor de las explicaciones, así que para ponerlo en términos más simples, como hemos visto, es común en la programación que necesitemos construir una función/clase/estructura de datos que operará sobre un cierto tipo, pero es igualmente común que dicha estructura de datos también deba funcionar en una variedad de tipos diferentes. Si estuviéramos atrapados en una posición en la que tuviéramos que declarar estáticamente el tipo concreto sobre el cual operaría una estructura de datos en el momento en que diseñamos la estructura de datos (en el momento de la compilación), encontraríamos rápidamente que necesitamos reconstruir esos estructuras en casi exactamente la misma manera para cada tipo que deseamos admitir, como vimos en los ejemplos anteriores.
Los genéricos nos ayudan a resolver este problema al permitirnos diferir el requisito de un tipo concreto hasta que se conozca realmente.
Genéricos en TypeScript
Ahora tenemos una idea algo orgánica de por qué los genéricos son útiles y hemos visto un ejemplo un poco complicado de ellos en la práctica. Para la mayoría, la implementación de TypedList<T> probablemente ya tenga mucho sentido, especialmente si proviene de un entorno de lenguaje de tipado estático, pero puedo recordar que tuve dificultades para entender el concepto cuando estaba aprendiendo por primera vez, por lo que quiero desarrolle ese ejemplo comenzando con funciones simples. Los conceptos relacionados con la abstracción en el software pueden ser notoriamente difíciles de internalizar, por lo que si la noción de Genéricos aún no ha hecho clic, está completamente bien y, con suerte, para el cierre de este artículo, la idea será al menos algo intuitiva.
Para llegar a ser capaz de entender ese ejemplo, trabajemos a partir de funciones simples. Comenzaremos con la "Función de identidad", que es lo que les gusta usar a la mayoría de los artículos, incluida la documentación de TypeScript.
Una “Función de Identidad”, en matemáticas, es una función que asigna su entrada directamente a su salida, como f(x) = x . Lo que pones es lo que obtienes. Podemos representar eso, en JavaScript, como:
function identity(input) { return input; }O, más concisamente:
const identity = input => input; Intentar portar esto a TypeScript trae de vuelta los mismos problemas del sistema de tipos que vimos antes. Las soluciones son escribir con any , lo que sabemos que rara vez es una buena idea, duplicar/sobrecargar la función para cada tipo (interrumpe DRY) o usar Generics.
Con esta última opción, podemos representar la función de la siguiente manera:
// ES5 Function function identity<T>(input: T): T { return input; } // Arrow Function const identity = <T>(input: T): T => input; console.log(identity<number>(5)); // 5 console.log(identity<string>('hello')); // hello La sintaxis <T> aquí declara esta función como Genérica. Al igual que una función nos permite pasar un parámetro de entrada arbitrario a su lista de argumentos, con una función genérica también podemos pasar un parámetro de tipo arbitrario.
La parte <T> de la firma de identity<T>(input: T): T y <T>(input: T): T en ambos casos declara que la función en cuestión aceptará un parámetro de tipo genérico denominado T . Al igual que las variables pueden tener cualquier nombre, también pueden tener nuestros marcadores de posición genéricos, pero es una convención usar una letra mayúscula "T" ("T" para "Tipo") y moverse hacia abajo en el alfabeto según sea necesario. Recuerde, T es un tipo, por lo que también declaramos que aceptaremos un argumento de función de input de nombre con un tipo de T y que nuestra función devolverá un tipo de T Eso es todo lo que dice la firma. Intente dejar T = string en su cabeza: reemplace todas las T con string en esas firmas. ¿Ves cómo nada tan mágico está pasando? ¿Ves lo similar que es a la forma no genérica en que usas las funciones todos los días?
Tenga en cuenta lo que ya sabe sobre TypeScript y las firmas de funciones. Todo lo que decimos es que T es un tipo arbitrario que el usuario proporcionará al llamar a la función, al igual que input es un valor arbitrario que el usuario proporcionará al llamar a la función. En este caso, input debe ser cualquiera que sea el tipo T cuando se llame a la función en el futuro .
A continuación, en el "futuro", en las dos declaraciones de registro, "pasamos" el tipo concreto que deseamos usar, al igual que hacemos con una variable. Observe el cambio en la palabrería aquí: en la forma inicial de la <T> signature , al declarar nuestra función, es genérica, es decir, funciona en tipos genéricos o tipos que se especificarán más adelante. Esto se debe a que no sabemos qué tipo deseará usar la persona que llama cuando realmente escribamos la función. Pero, cuando la persona que llama llama a la función, sabe exactamente con qué tipo(s) quiere trabajar, que son string y number en este caso.
Puede imaginar la idea de tener una función de registro declarada de esta manera en una biblioteca de terceros: el autor de la biblioteca no tiene idea de qué tipos querrán usar los desarrolladores que usan la biblioteca, por lo que hacen que la función sea genérica, esencialmente aplazando la necesidad para tipos concretos hasta que se conocen realmente.
Quiero enfatizar que debe pensar en este proceso de manera similar a la noción de pasar una variable a una función con el fin de obtener una comprensión más intuitiva. Todo lo que estamos haciendo ahora es pasar un tipo también.
En el punto donde llamamos a la función con el parámetro number , la firma original, para todos los efectos, podría considerarse como identity(input: number): number . Y, en el punto donde llamamos a la función con el parámetro de string , nuevamente, la firma original bien podría haber sido identity(input: string): string . Puedes imaginar que, al hacer la llamada, cada T genérica se reemplaza por el tipo concreto que proporcionas en ese momento.
Explorando la sintaxis genérica
Hay diferentes sintaxis y semánticas para especificar genéricos en el contexto de funciones ES5, funciones de flecha, alias de tipo, interfaces y clases. Exploraremos esas diferencias en esta sección.
Exploración de la sintaxis genérica: funciones
Ya ha visto algunos ejemplos de funciones genéricas, pero es importante tener en cuenta que una función genérica puede aceptar más de un parámetro de tipo genérico, al igual que las variables. Puede optar por solicitar uno, dos o tres, o la cantidad de tipos que desee, todos separados por comas (nuevamente, al igual que los argumentos de entrada).
Esta función acepta tres tipos de entrada y devuelve aleatoriamente uno de ellos:
function randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V { // This is a tuple if you're not familiar. const options: [T, U, V] = [ one, two, three ]; const rndNum = getRndNumInInclusiveRange(0, 2); return options[rndNum]; } // Calling the function. // `value` has type `string | number | IAircraft` const value = randomValue< string, number, IAircraft >( myString, myNumber, myAircraft );También puede ver que la sintaxis es ligeramente diferente dependiendo de si usamos una función ES5 o una función de flecha, pero ambas declaran los parámetros de tipo en la firma:
const randomValue = <T, U, V>( one: T, two: U, three: V ): T | U | V => { // This is a tuple if you're not familiar. const options: [T, U, V] = [ one, two, three ]; const rndNum = getRndNumInInclusiveRange(0, 2); return options[rndNum]; } Tenga en cuenta que no hay una "restricción de unicidad" forzada en los tipos: puede pasar cualquier combinación que desee, como dos string y un number , por ejemplo. Además, al igual que los argumentos de entrada están "dentro del alcance" del cuerpo de la función, también lo están los parámetros de tipo genérico. El ejemplo anterior demuestra que tenemos acceso completo a T , U y V desde dentro del cuerpo de la función, y los usamos para declarar una tupla de 3 local.
Puede imaginar que estos genéricos operan en un determinado "contexto" o dentro de una determinada "vida útil", y eso depende de dónde se declaren. Los genéricos sobre funciones están dentro del alcance dentro de la firma y el cuerpo de la función (y los cierres creados por funciones anidadas), mientras que los genéricos declarados en una clase o interfaz o alias de tipo están dentro del alcance de todos los miembros de la clase o interfaz o alias de tipo.
La noción de genéricos en funciones no se limita a "funciones libres" o "funciones flotantes" (funciones no adjuntas a un objeto o clase, un término de C++), sino que también se pueden usar en funciones adjuntas a otras estructuras.
Podemos colocar ese randomValue en una clase y podemos llamarlo de la misma manera:
class Utils { public randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V { // ... } // Or, as an arrow function: public randomValue = <T, U, V>( one: T, two: U, three: V ): T | U | V => { // ... } }También podríamos colocar una definición dentro de una interfaz:
interface IUtils { randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V; }O dentro de un alias de tipo:
type Utils = { randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V; }Al igual que antes, estos parámetros de tipo genérico están "dentro del alcance" de esa función en particular: no son de clase, de interfaz o de tipo de alias. Viven sólo dentro de la función particular sobre la que se especifican. Para compartir un tipo genérico entre todos los miembros de una estructura, debe anotar el nombre de la estructura, como veremos a continuación.
Exploración de la sintaxis genérica: alias de tipo
Con Type Aliases, la sintaxis genérica se usa en el nombre del alias.
Por ejemplo, alguna función de "acción" que acepta un valor, posiblemente muta ese valor, pero devuelve void podría escribirse como:
type Action<T> = (val: T) => void;Nota : esto debería ser familiar para los desarrolladores de C# que entienden el delegado Action<T>.
O bien, una función de devolución de llamada que acepta tanto un error como un valor podría declararse como tal:
type CallbackFunction<T> = (err: Error, data: T) => void; const usersApi = { get(uri: string, cb: CallbackFunction<User>) { /// ... } }Con nuestro conocimiento de funciones genéricas, podríamos ir más allá y hacer que la función en el objeto API también sea genérica:
type CallbackFunction<T> = (err: Error, data: T) => void; const api = { // `T` is available for use within this function. get<T>(uri: string, cb: CallbackFunction<T>) { /// ... } } Ahora, estamos diciendo que la función get acepta algún parámetro de tipo genérico, y sea lo que sea, CallbackFunction lo recibe. Básicamente, hemos "aprobado" la T que entra en get como la T para CallbackFunction . Quizás esto tendría más sentido si cambiamos los nombres:
type CallbackFunction<TData> = (err: Error, data: TData) => void; const api = { get<TResponse>(uri: string, cb: CallbackFunction<TResponse>) { // ... } } El prefijo de parámetros de tipo con T es simplemente una convención, al igual que el prefijo de interfaces con I o las variables miembro con _ . Lo que puede ver aquí es que CallbackFunction acepta algún tipo ( TData ) que representa la carga útil de datos disponible para la función, mientras que get acepta un parámetro de tipo que representa el tipo/forma de datos de respuesta HTTP ( TResponse ). El cliente HTTP ( api ), similar a Axios, usa lo que TResponse sea como TData para CallbackFunction . Esto permite que la persona que llama a la API seleccione el tipo de datos que recibirá de la API (supongamos que en algún otro lugar de la canalización tenemos un middleware que analiza el JSON en un DTO).
Si quisiéramos llevar esto un poco más allá, podríamos modificar los parámetros de tipo genérico en CallbackFunction para aceptar también un tipo de error personalizado:
type CallbackFunction<TData, TError> = (err: TError, data: TData) => void;Y, al igual que puede hacer que los argumentos de función sean opcionales, también puede hacerlo con parámetros de tipo. En el caso de que el usuario no proporcione un tipo de error, lo estableceremos en el constructor de errores de forma predeterminada:
type CallbackFunction<TData, TError = Error> = (err: TError, data: TData) => void;Con esto, ahora podemos especificar un tipo de función de devolución de llamada de varias maneras:
const apiOne = { // `Error` is used by default for `CallbackFunction`. get<TResponse>(uri: string, cb: CallbackFunction<TResponse>) { // ... } }; apiOne.get<string>('uri', (err: Error, data: string) => { // ... }); const apiTwo = { // Override the default and use `HttpError` instead. get<TResponse>(uri: string, cb: CallbackFunction<TResponse, HttpError>) { // ... } }; apiTwo.get<string>('uri', (err: HttpError, data: string) => { // ... });Esta idea de parámetros predeterminados es aceptable en todas las funciones, clases, interfaces, etc., no se limita solo a los alias de tipo. En todos los ejemplos que hemos visto hasta ahora, podríamos haber asignado cualquier parámetro de tipo que quisiéramos a un valor predeterminado. Los alias de tipo, al igual que las funciones, pueden tomar tantos parámetros de tipo genérico como desee.
Exploración de la sintaxis genérica: interfaces
Como ha visto, se puede proporcionar un parámetro de tipo genérico a una función en una interfaz:
interface IUselessFunctions { // Not generic printHelloWorld(); // Generic identity<T>(t: T): T; } En este caso, T vive solo para la función de identity como su tipo de entrada y retorno.
También podemos hacer que un parámetro de tipo esté disponible para todos los miembros de una interfaz, al igual que con las clases y los alias de tipo, especificando que la propia interfaz acepta un genérico. Hablaremos sobre el patrón de repositorio un poco más adelante cuando discutamos casos de uso más complejos para genéricos, por lo que está bien si nunca ha oído hablar de él. El patrón de repositorio nos permite abstraer nuestro almacenamiento de datos para hacer que la lógica empresarial sea independiente de la persistencia. Si desea crear una interfaz de repositorio genérica que opere con tipos de entidades desconocidos, podríamos escribirla de la siguiente manera:
interface IRepository<T> { add(entity: T): Promise<void>; findById(id: string): Promise<T>; updateById(id: string, updated: T): Promise<void>; removeById(id: string): Promise<void>; }Nota : Hay muchos pensamientos diferentes sobre los repositorios, desde la definición de Martin Fowler hasta la definición de DDD Aggregate. Simplemente estoy tratando de mostrar un caso de uso para genéricos, por lo que no estoy demasiado preocupado por ser completamente correcto en cuanto a la implementación. Definitivamente hay algo que decir sobre no usar repositorios genéricos, pero hablaremos de eso más adelante.
Como puede ver aquí, IRepository es una interfaz que contiene métodos para almacenar y recuperar datos. Opera en algún parámetro de tipo genérico llamado T , y T se usa como entrada para add y updateById , así como el resultado de resolución de promesa de findById .
Tenga en cuenta que hay una gran diferencia entre aceptar un parámetro de tipo genérico en el nombre de la interfaz en lugar de permitir que cada función acepte un parámetro de tipo genérico. Lo primero, como hemos hecho aquí, asegura que cada función dentro de la interfaz opere en el mismo tipo T . Es decir, para un IRepository<User> , todos los métodos que usan T en la interfaz ahora funcionan en objetos User . Con el último método, cada función podría trabajar con cualquier tipo que desee. Sería muy peculiar solo poder agregar User al Repositorio pero poder recibir Policies u Orders , por ejemplo, que es la situación potencial en la que nos encontraríamos si no pudiéramos hacer cumplir que el tipo es uniforme en todos los métodos.
Una interfaz dada puede contener no solo un tipo compartido, sino también tipos únicos para sus miembros. Por ejemplo, si quisiéramos imitar una matriz, podríamos escribir una interfaz como esta:
interface IArray<T> { forEach(func: (elem: T, index: number) => void): this; map<U>(func: (elem: T, index: number) => U): IArray<U>; } En este caso, tanto forEach como map tienen acceso a T desde el nombre de la interfaz. Como se indicó, puede imaginar que T está dentro del alcance de todos los miembros de la interfaz. A pesar de eso, nada impide que las funciones individuales acepten también sus propios parámetros de tipo. La función map hace, con U . Ahora, el map tiene acceso tanto a T como a U Tuvimos que nombrar el parámetro con una letra diferente, como U , porque T ya está en uso y no queremos una colisión de nombres. Al igual que su nombre, map "asignará" elementos de tipo T dentro de la matriz a nuevos elementos de tipo U Asigna T s a U s. El valor de retorno de esta función es la propia interfaz, que ahora opera en el nuevo tipo U , de modo que podemos imitar un poco la sintaxis encadenable fluida de JavaScript para arreglos.
Veremos un ejemplo del poder de los genéricos y las interfaces en breve cuando implementemos el patrón de repositorio y discutamos la inyección de dependencia. Una vez más, podemos aceptar tantos parámetros genéricos como seleccionar uno o más parámetros predeterminados apilados al final de una interfaz.
Exploración de la sintaxis genérica: clases
De la misma manera que podemos pasar un parámetro de tipo genérico a un alias de tipo, función o interfaz, también podemos pasar uno o más a una clase. Al hacerlo, ese parámetro de tipo será accesible para todos los miembros de esa clase, así como para las clases base extendidas o las interfaces implementadas.
Construyamos otra clase de colección, pero un poco más simple que TypedList anterior, para que podamos ver la interoperabilidad entre tipos genéricos, interfaces y miembros. Veremos un ejemplo de cómo pasar un tipo a una clase base y herencia de interfaz un poco más adelante.
Nuestra colección simplemente admitirá funciones CRUD básicas además de un map y un método forEach .
class Collection<T> { private elements: T[] = []; constructor (elements: T[] = []) { this.elements = elements; } add(elem: T): void { this.elements.push(elem); } contains(elem: T): boolean { return this.elements.includes(elem); } remove(elem: T): void { this.elements = this.elements.filter(existing => existing !== elem); } forEach(func: (elem: T, index: number) => void): void { return this.elements.forEach(func); } map<U>(func: (elem: T, index: number) => U): Collection<U> { return new Collection<U>(this.elements.map(func)); } } const stringCollection = new Collection<string>(); stringCollection.add('Hello, World!'); const numberCollection = new Collection<number>(); numberCollection.add(3.14159); const aircraftCollection = new Collection<IAircraft>(); aircraftCollection.add(myAircraft); Vamos a discutir lo que está pasando aquí. La clase Collection acepta un parámetro de tipo genérico denominado T . Ese tipo se vuelve accesible para todos los miembros de la clase. Lo usamos para definir una matriz privada de tipo T[] , que también podríamos haber indicado en la forma Array<T> (¿Ves? Generics nuevamente para la tipificación normal de matrices TS). Además, la mayoría de las funciones miembro utilizan esa T de alguna manera, como controlar los tipos que se agregan y eliminan o verificar si la colección contiene un elemento.

Finalmente, como hemos visto antes, el método map requiere su propio parámetro de tipo genérico. We need to define in the signature of map that some type T is mapped to some type U through a callback function, thus we need a U . That U is unique to that function in particular, which means we could have another function in that class that also accepts some type named U , and that'd be fine, because those types are only “in scope” for their functions and not shared across them, thus there are no naming collisions. What we can't do is have another function that accepts a generic parameter named T , for that'd conflict with the T from the class signature.
You can see that when we call the constructor, we pass in the type we want to work with (that is, what type each element of the internal array will be). In the calling code at the bottom of the example, we work with string s, number s, and IAircraft s.
How could we make this work with an interface? What if we have different collection interfaces that we might want to swap out or inject into calling code? To get that level of reduced coupling (low coupling and high cohesion is what we should always aim for), we'll need to depend on an abstraction. Generally, that abstraction will be an interface, but it could also be an abstract class.
Our collection interface will need to be generic, so let's define it:
interface ICollection<T> { add(t: T): void; contains(t: T): boolean; remove(t: T): void; forEach(func: (elem: T, index: number) => void): void; map<U>(func: (elem: T, index: number) => U): ICollection<U>; }Now, let's suppose we have different kinds of collections. We could have an in-memory collection, one that stores data on disk, one that uses a database, and so on. By having an interface, the dependent code can depend upon the abstraction, permitting us to swap out different implementations without affecting the existing code. Here is the in-memory collection.
class InMemoryCollection<T> implements ICollection<T> { private elements: T[] = []; constructor (elements: T[] = []) { this.elements = elements; } add(elem: T): void { this.elements.push(elem); } contains(elem: T): boolean { return this.elements.includes(elem); } remove(elem: T): void { this.elements = this.elements.filter(existing => existing !== elem); } forEach(func: (elem: T, index: number) => void): void { return this.elements.forEach(func); } map<U>(func: (elem: T, index: number) => U): ICollection<U> { return new InMemoryCollection<U>(this.elements.map(func)); } } The interface describes the public-facing methods and properties that our class is required to implement, expecting you to pass in a concrete type that those methods will operate upon. However, at the time of defining the class, we still don't know what type the API caller will wish to use. Thus, we make the class generic too — that is, InMemoryCollection expects to receive some generic type T , and whatever it is, it's immediately passed to the interface, and the interface methods are implemented using that type.
Calling code can now depend on the interface:
// Using type annotation to be explicit for the purposes of the // tutorial. const userCollection: ICollection<User> = new InMemoryCollection<User>(); function manageUsers(userCollection: ICollection<User>) { userCollection.add(new User()); } With this, any kind of collection can be passed into the manageUsers function as long as it satisfies the interface. This is useful for testing scenarios — rather than dealing with over-the-top mocking libraries, in unit and integration test scenarios, I can replace my SqlServerCollection<T> (for example) with InMemoryCollection<T> instead and perform state-based assertions instead of interaction-based assertions. This setup makes my tests agnostic to implementation details, which means they are, in turn, less likely to break when refactoring the SUT.
At this point, we should have worked up to the point where we can understand that first TypedList<T> example. Here it is again:
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T): void { this.values.push(value); } public where(predicate: (value: T) => boolean): TypedList<T> { return TypedList.from<T>(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U): TypedList<U> { return TypedList.from<U>(this.values.map(selector)); } public toArray(): T[] { return this.values; } public static from<U>(values: U[]): TypedList<U> { // Perhaps we perform some logic here. // ... return new TypedList<U>(values); } public static create<U>(values?: U[]): TypedList<U> { return new TypedList<U>(values ?? []); } // Other collection functions. // .. } The class itself accepts a generic type parameter named T , and all members of the class are provided access to it. The instance method select and the two static methods from and create , which are factories, accept their own generic type parameter named U .
The create static method permits the construction of a list with optional seed data. It accepts some type named U to be the type of every element in the list as well as an optional array of U elements, typed as U[] . When it calls the list's constructor with new , it passes that type U as the generic parameter to TypedList . This creates a new list where the type of every element is U . It is exactly the same as how we could call the constructor of our collection class earlier with new Collection<SomeType>() . The only difference is that the generic type is now passing through the create method rather than being provided and used at the top-level.
I want to make sure this is really, really clear. I've stated a few times that we can think about passing around types in a similar way that we do variables. It should already be quite intuitive that we can pass a variable through as many layers of indirection as we please. Forget generics and types for a moment and think about an example of the form:
class MyClass { private constructor (t: number) {} public static create(u: number) { return new MyClass(u); } } const myClass = MyClass.create(2.17); This is very similar to what is happening with the more-involved example, the difference being that we're working on generic type parameters, not variables. Here, 2.17 becomes the u in create , which ultimately becomes the t in the private constructor.
In the case of generics:
class MyClass<T> { private constructor () {} public static create<U>() { return new MyClass<U>(); } } const myClass = MyClass.create<number>(); The U passed to create is ultimately passed in as the T for MyClass<T> . When calling create , we provided number as U , thus now U = number . We put that U (which, again, is just number ) into the T for MyClass<T> , so that MyClass<T> effectively becomes MyClass<number> . The benefit of generics is that we're opened up to be able to work with types in this abstract and high-level fashion, similar to how we can normal variables.
The from method constructs a new list that operates on an array of elements of type U . It uses that type U , just like create , to construct a new instance of the TypedList class, now passing in that type U for T .
The where instance method performs a filtering operation based upon a predicate function. There's no mapping happening, thus the types of all elements remain the same throughout. The filter method available on JavaScript's array returns a new array of values, which we pass into the from method. So, to be clear, after we filter out the values that don't satisfy the predicate function, we get an array back containing the elements that do. All those elements are still of type T , which is the original type that the caller passed to create when the list was first created. Those filtered elements get given to the from method, which in turn creates a new list containing all those values, still using that original type T . The reason why we return a new instance of the TypedList class is to be able to chain new method calls onto the return result. This adds an element of “immutability” to our list.
Hopefully, this all provides you with a more intuitive example of generics in practice, and their reason for existence. Next, we'll look at a few of the more advanced topics.
Generic Type Inference
Throughout this article, in all cases where we've used generics, we've explicitly defined the type we're operating on. It's important to note that in most cases, we do not have to explicitly define the type parameter we pass in, for TypeScript can infer the type based on usage.
If I have some function that returns a random number, and I pass the return result of that function to identity from earlier without specifying the type parameter, it will be inferred automatically as number :
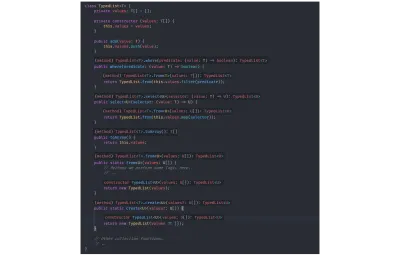
// `value` is inferred as type `number`. const value = identity(getRandomNumber()); Para demostrar la inferencia de tipos, eliminé todas las anotaciones de tipos técnicamente extrañas de nuestra estructura TypedList anteriormente, y puede ver, en las imágenes a continuación, que TSC todavía infiere todos los tipos correctamente:
TypedList sin declaraciones de tipos extraños:
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T) { this.values.push(value); } public where(predicate: (value: T) => boolean) { return TypedList.from(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U) { return TypedList.from(this.values.map(selector)); } public toArray() { return this.values; } public static from<U>(values: U[]) { // Perhaps we perform some logic here. // ... return new TypedList(values); } public static create<U>(values?: U[]) { return new TypedList(values ?? []); } // Other collection functions. // .. } En función de los valores de retorno de la función y de los tipos de entrada pasados from y el constructor, TSC comprende toda la información de tipo. En la imagen a continuación, he unido varias imágenes que muestran la extensión de lenguaje de Code TypeScript de Visual Studio (y, por lo tanto, el compilador) infiriendo todos los tipos:
Restricciones genéricas
A veces, queremos poner una restricción en torno a un tipo genérico. Tal vez no podamos admitir todos los tipos existentes, pero podemos admitir un subconjunto de ellos. Digamos que queremos construir una función que devuelva la longitud de alguna colección. Como se vio anteriormente, podríamos tener muchos tipos diferentes de matrices/colecciones, desde la Array de JavaScript predeterminada hasta las personalizadas. ¿Cómo le hacemos saber a nuestra función que algún tipo genérico tiene una propiedad de length adjunta? De manera similar, ¿cómo restringimos los tipos concretos que pasamos a la función a aquellos que contienen los datos que necesitamos? Un ejemplo como este, por ejemplo, no funcionaría:
function getLength<T>(collection: T): number { // Error. TS does not know that a type T contains a `length` property. return collection.length; }La respuesta es utilizar restricciones genéricas. Podemos definir una interfaz que describa las propiedades que necesitamos:
interface IHasLength { length: number; }Ahora, al definir nuestra función genérica, podemos restringir el tipo genérico para que amplíe esa interfaz:
function getLength<T extends IHasLength>(collection: T): number { // Restricting `collection` to be a type that contains // everything within the `IHasLength` interface. return collection.length; }Ejemplos del mundo real
En las próximas dos secciones, analizaremos algunos ejemplos del mundo real de genéricos que crean un código más elegante y fácil de razonar. Hemos visto muchos ejemplos triviales, pero quiero discutir algunos enfoques para el manejo de errores, patrones de acceso a datos y estado/props de React de front-end.
Ejemplos del mundo real: enfoques para el manejo de errores
JavaScript contiene un mecanismo de primera clase para manejar errores, al igual que la mayoría de los lenguajes de programación: try / catch . A pesar de eso, no soy muy fan de cómo se ve cuando se usa. Eso no quiere decir que no use el mecanismo, lo hago, pero tiendo a tratar de ocultarlo tanto como puedo. Al abstraer try / catch away, también puedo reutilizar la lógica de manejo de errores en operaciones con probabilidad de fallar.
Supongamos que estamos construyendo una capa de acceso a datos. Esta es una capa de la aplicación que envuelve la lógica de persistencia para manejar el método de almacenamiento de datos. Si estamos realizando operaciones de base de datos, y si esa base de datos se usa en una red, es probable que ocurran errores específicos específicos de la base de datos y excepciones transitorias. Parte del motivo de tener una capa de acceso a datos dedicada es abstraer la base de datos de la lógica empresarial. Debido a eso, no podemos tener tales errores específicos de base de datos arrojados a la pila y fuera de esta capa. Necesitamos envolverlos primero.
Veamos una implementación típica que usaría try / catch :
async function queryUser(userID: string): Promise<User> { try { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(dbUser); } catch (e) { switch (true) { case e instanceof DbErrorOne: return Promise.reject(new WrapperErrorOne()); case e instanceof DbErrorTwo: return Promise.reject(new WrapperErrorTwo()); case e instanceof NetworkError: return Promise.reject(new TransientException()); default: return Promise.reject(new UnknownError()); } } } Cambiar a true es simplemente un método para poder usar las declaraciones de cambio de case para mi lógica de verificación de errores en lugar de tener que declarar una cadena de if/else if, un truco que escuché por primera vez de @Jeffijoe.
Si tenemos múltiples funciones de este tipo, tenemos que replicar esta lógica de ajuste de errores, lo cual es una práctica muy mala. Se ve bastante bien para una función, pero será una pesadilla con muchas. Para abstraer esta lógica, podemos envolverla en una función personalizada de manejo de errores que pasará por el resultado, pero capturará y envolverá cualquier error en caso de que se produzca:
async function withErrorHandling<T>( dalOperation: () => Promise<T> ): Promise<T> { try { // This unwraps the promise and returns the type `T`. return await dalOperation(); } catch (e) { switch (true) { case e instanceof DbErrorOne: return Promise.reject(new WrapperErrorOne()); case e instanceof DbErrorTwo: return Promise.reject(new WrapperErrorTwo()); case e instanceof NetworkError: return Promise.reject(new TransientException()); default: return Promise.reject(new UnknownError()); } } } Para garantizar que esto tenga sentido, tenemos una función titulada withErrorHandling que acepta algún parámetro de tipo genérico T . Esta T representa el tipo de valor de resolución exitosa de la promesa que esperamos que devuelva la función de devolución de llamada dalOperation . Por lo general, dado que solo devolvemos el resultado de retorno de la función asíncrona dalOperation , no necesitaríamos await porque eso envolvería la función en una segunda promesa extraña, y podríamos dejar la await al código de llamada. En este caso, necesitamos detectar cualquier error, por lo que se requiere await .
Ahora podemos usar esta función para envolver nuestras operaciones DAL anteriores:
async function queryUser(userID: string) { return withErrorHandling<User>(async () => { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(dbUser); }); }Y ahí vamos. Tenemos una función de consulta de usuario con función de seguridad de tipos y de errores.
Además, como vio anteriormente, si el Compilador de TypeScript tiene suficiente información para inferir los tipos implícitamente, no tiene que pasarlos explícitamente. En este caso, TSC sabe que el resultado de retorno de la función es el tipo genérico. Por lo tanto, si mapper.toDomain(user) devolviera un tipo de User , no necesitarías pasar el tipo en absoluto:
async function queryUser(userID: string) { return withErrorHandling(async () => { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(user); }); } Otro enfoque para el manejo de errores que me suele gustar es el de los tipos monádicos. La mónada cualquiera es un tipo de datos algebraico de la forma Either<T, U> , donde T puede representar un tipo de error y U puede representar un tipo de falla. El uso de Monadic Types se basa en la programación funcional, y un beneficio importante es que los errores se vuelven seguros para los tipos: una firma de función normal no le dice nada a la persona que llama a la API sobre los errores que podría arrojar esa función. Supongamos que arrojamos un error NotFound desde dentro de queryUser . Una firma de queryUser(userID: string): Promise<User> no nos dice nada al respecto. Pero, una firma como queryUser(userID: string): Promise<Either<NotFound, User>> absolutamente lo hace. No explicaré cómo funcionan las mónadas como la mónada cualquiera en este artículo porque pueden ser bastante complejas, y hay una variedad de métodos que deben tener para ser consideradas monádicas, como mapeo/enlace. Si desea obtener más información sobre ellos, le recomiendo dos de las charlas de NDC de Scott Wlaschin, aquí y aquí, así como la charla de Daniel Chamber aquí. Este sitio y estas publicaciones de blog también pueden ser útiles.
Ejemplos del mundo real: patrón de repositorio
Echemos un vistazo a otro caso de uso en el que los genéricos podrían ser útiles. Se requiere que la mayoría de los sistemas de back-end interactúen con una base de datos de alguna manera; podría ser una base de datos relacional como PostgreSQL, una base de datos de documentos como MongoDB, o quizás incluso una base de datos de gráficos, como Neo4j.
Dado que, como desarrolladores, debemos apuntar a diseños poco acoplados y altamente cohesivos, sería un argumento justo considerar cuáles podrían ser las ramificaciones de la migración de sistemas de bases de datos. También sería justo considerar que las diferentes necesidades de acceso a datos pueden preferir diferentes enfoques de acceso a datos (esto comienza a entrar un poco en CQRS, que es un patrón para separar lecturas y escrituras. Consulte la publicación de Martin Fowler y la lista de MSDN si lo desea). para obtener más información Los libros "Implementación del diseño basado en el dominio" de Vaughn Vernon y "Patrones, principios y prácticas del diseño basado en el dominio" de Scott Millet también son buenas lecturas). También deberíamos considerar las pruebas automatizadas. La mayoría de los tutoriales que explican la construcción de sistemas back-end con Node.js entremezclan el código de acceso a datos con la lógica empresarial con enrutamiento. Es decir, tienden a usar MongoDB con Mongoose ODM, adoptan un enfoque de Active Record y no tienen una clara separación de preocupaciones. Tales técnicas están mal vistas en grandes aplicaciones; en el momento en que decide que le gustaría migrar un sistema de base de datos a otro, o en el momento en que se da cuenta de que preferiría un enfoque diferente para el acceso a los datos, tiene que eliminar ese código de acceso a datos antiguo, reemplazarlo con código nuevo, y espero que no haya introducido ningún error en el enrutamiento y la lógica comercial en el camino.
Claro, podría argumentar que las pruebas unitarias y de integración evitarán las regresiones, pero si esas pruebas se encuentran acopladas y dependen de los detalles de implementación a los que deberían ser independientes, es probable que también se rompan en el proceso.
Un enfoque común para resolver este problema es el patrón de repositorio. Dice que para llamar al código, debemos permitir que nuestra capa de acceso a datos imite una mera colección de objetos o entidades de dominio en memoria. De esta forma, podemos dejar que la empresa dirija el diseño en lugar de la base de datos (modelo de datos). Para aplicaciones grandes, se vuelve útil un patrón arquitectónico llamado diseño controlado por dominio. Los repositorios, en el Patrón de repositorio, son componentes, más comúnmente clases, que encapsulan y mantienen interna toda la lógica para acceder a las fuentes de datos. Con esto, podemos centralizar el código de acceso a datos en una sola capa, haciéndolo fácilmente comprobable y reutilizable. Además, podemos colocar una capa de mapeo en el medio, lo que nos permite mapear modelos de dominio independientes de la base de datos a una serie de mapeos de tablas uno a uno. Cada función disponible en el Repositorio podría usar opcionalmente un método de acceso a datos diferente si así lo desea.
Hay muchos enfoques y semánticas diferentes para repositorios, unidades de trabajo, transacciones de bases de datos entre tablas, etc. Dado que este es un artículo sobre genéricos, no quiero entrar demasiado en detalles, por lo tanto, ilustraré un ejemplo simple aquí, pero es importante tener en cuenta que las diferentes aplicaciones tienen diferentes necesidades. Un repositorio para agregados de DDD sería bastante diferente de lo que estamos haciendo aquí, por ejemplo. La forma en que represento las implementaciones del Repositorio aquí no es cómo las implemento en proyectos reales, ya que falta mucha funcionalidad y prácticas arquitectónicas en uso menos de lo deseado.
Supongamos que tenemos Users y Tasks como modelos de dominio. Estos podrían ser simplemente POTO: objetos TypeScript simples y antiguos. No hay una noción de una base de datos integrada en ellos, por lo tanto, no llamarías a User.save() , por ejemplo, como lo harías con Mongoose. Usando el Patrón de Repositorio, podemos conservar a un usuario o eliminar una tarea de nuestra lógica de negocios de la siguiente manera:
// Querying the DB for a User by their ID. const user: User = await userRepository.findById(userID); // Deleting a Task by its ID. await taskRepository.deleteById(taskID); // Deleting a Task by its owner's ID. await taskRepository.deleteByUserId(userID);Claramente, puede ver cómo toda la lógica de acceso a datos desordenada y transitoria se oculta detrás de esta fachada/abstracción del repositorio, lo que hace que la lógica comercial sea independiente de las preocupaciones de persistencia.
Comencemos por construir algunos modelos de dominio simples. Estos son los modelos con los que interactuará el código de la aplicación. Son anémicos aquí, pero mantendrían su propia lógica para satisfacer las invariantes comerciales en el mundo real, es decir, no serían meros paquetes de datos.
interface IHasIdentity { id: string; } class User implements IHasIdentity { public constructor ( private readonly _id: string, private readonly _username: string ) {} public get id() { return this._id; } public get username() { return this._username; } } class Task implements IHasIdentity { public constructor ( private readonly _id: string, private readonly _title: string ) {} public get id() { return this._id; } public get title() { return this._title; } } Verá en un momento por qué extraemos información de tipeo de identidad a una interfaz. Este método de definir modelos de dominio y pasar todo a través del constructor no es como lo haría en el mundo real. Además, confiar en una clase de modelo de dominio abstracto hubiera sido más preferible que la interfaz para obtener la implementación de id de forma gratuita.
Para el Repositorio, dado que, en este caso, esperamos que muchos de los mismos mecanismos de persistencia se compartan entre diferentes modelos de dominio, podemos abstraer nuestros métodos del Repositorio a una interfaz genérica:
interface IRepository<T> { add(entity: T): Promise<void>; findById(id: string): Promise<T>; updateById(id: string, updated: T): Promise<void>; deleteById(id: string): Promise<void>; existsById(id: string): Promise<boolean>; }Podríamos ir más allá y crear un repositorio genérico también para reducir la duplicación. Para abreviar, no haré eso aquí, y debo señalar que las interfaces de repositorios genéricos como esta y los repositorios genéricos, en general, tienden a estar mal vistos, ya que es posible que tenga ciertas entidades que son de solo lectura o escritura. -solo, o que no se pueden eliminar, o similar. Depende de la aplicación. Además, no tenemos una noción de "unidad de trabajo" para compartir una transacción entre tablas, una función que implementaría en el mundo real, pero, de nuevo, dado que esta es una pequeña demostración, no quiero ser demasiado técnico.
Comencemos implementando nuestro UserRepository . IUserRepository una interfaz IUserRepository que contiene métodos específicos para los usuarios, lo que permite que el código de llamada dependa de esa abstracción cuando inyectamos las implementaciones concretas:
interface IUserRepository extends IRepository<User> { existsByUsername(username: string): Promise<boolean>; } class UserRepository implements IUserRepository { // There are 6 methods to implement here all using the // concrete type of `User` - Five from IRepository<User> // and the one above. }El Repositorio de Tareas sería similar pero contendría diferentes métodos según lo estime conveniente la aplicación.
Aquí, estamos definiendo una interfaz que extiende una genérica, por lo que tenemos que pasar el tipo concreto en el que estamos trabajando. Como puede ver en ambas interfaces, tenemos la noción de que enviamos estos modelos de dominio POTO y los sacamos. El código de llamada no tiene idea de cuál es el mecanismo de persistencia subyacente, y ese es el punto.
La siguiente consideración a tener en cuenta es que dependiendo del método de acceso a datos que elijamos, tendremos que manejar errores específicos de la base de datos. Podríamos colocar Mongoose o Knex Query Builder detrás de este Repositorio, por ejemplo, y en ese caso, tendremos que manejar esos errores específicos; no queremos que se conviertan en lógica comercial porque eso rompería la separación de preocupaciones. e introducir un mayor grado de acoplamiento.
Definamos un repositorio base para los métodos de acceso a datos que deseamos usar que puedan manejar los errores por nosotros:
class BaseKnexRepository { // A constructor. /** * Wraps a likely to fail database operation within a function that handles errors by catching * them and wrapping them in a domain-safe error. * * @param dalOp The operation to perform upon the database. */ public async withErrorHandling<T>(dalOp: () => Promise<T>) { try { return await dalOp(); } catch (e) { // Use a proper logger: console.error(e); // Handle errors properly here. } } }Ahora, podemos extender esta Clase Base en el Repositorio y acceder a ese método Genérico:
interface IUserRepository extends IRepository<User> { existsByUsername(username: string): Promise<boolean>; } class UserRepository extends BaseKnexRepository implements IUserRepository { private readonly dbContext: Knex | Knex.Transaction; public constructor (private knexInstance: Knex | Knex.Transaction) { super(); this.dbContext = knexInstance; } // Example `findById` implementation: public async findById(id: string): Promise<User> { return this.withErrorHandling<User>(async () => { const dbUser = await this.dbContext<DbUser>() .select() .where({ user_id: id }) .first(); // Maps type DbUser to User return mapper.toDomain(dbUser); }); } // There are 5 methods to implement here all using the // concrete type of `User`. } Tenga en cuenta que nuestra función recupera un DbUser de la base de datos y lo asigna a un modelo de dominio de User antes de devolverlo. Este es el patrón de Data Mapper y es crucial para mantener la separación de preocupaciones. DbUser es una asignación uno a uno a la tabla de la base de datos (es el modelo de datos sobre el que opera el Repositorio) y, por lo tanto, depende en gran medida de la tecnología de almacenamiento de datos utilizada. Por esta razón, los DbUser nunca abandonarán el repositorio y se asignarán a un modelo de dominio de User antes de devolverlos. No mostré la implementación de DbUser , pero podría ser simplemente una clase o interfaz simple.
Hasta ahora, utilizando Repository Pattern, impulsado por Generics, hemos logrado abstraer los problemas de acceso a los datos en unidades pequeñas, así como mantener la seguridad de tipos y la reutilización.
Finalmente, a los efectos de las pruebas de unidad e integración, digamos que mantendremos una implementación de repositorio en memoria para que, en un entorno de prueba, podamos inyectar ese repositorio y realizar afirmaciones basadas en el estado en el disco en lugar de simular con un marco burlón. Este método obliga a que todo dependa de las interfaces públicas en lugar de permitir que las pruebas se acoplen a los detalles de implementación. Dado que las únicas diferencias entre cada repositorio son los métodos que eligen agregar en la interfaz de ISomethingRepository , podemos crear un repositorio genérico en memoria y extenderlo dentro de implementaciones específicas de tipo:
class InMemoryRepository<T extends IHasIdentity> implements IRepository<T> { protected entities: T[] = []; public findById(id: string): Promise<T> { const entityOrNone = this.entities.find(entity => entity.id === id); return entityOrNone ? Promise.resolve(entityOrNone) : Promise.reject(new NotFound()); } // Implement the rest of the IRepository<T> methods here. } El propósito de esta clase base es realizar toda la lógica para manejar el almacenamiento en memoria para que no tengamos que duplicarlo dentro de los repositorios de prueba en memoria. Debido a métodos como findById , este repositorio debe comprender que las entidades contienen un campo de id , por lo que es necesaria la restricción genérica en la interfaz IHasIdentity . Vimos esta interfaz antes: es lo que implementaron nuestros modelos de dominio.
Con esto, cuando se trata de construir el usuario en memoria o el repositorio de tareas, podemos extender esta clase y hacer que la mayoría de los métodos se implementen automáticamente:
class InMemoryUserRepository extends InMemoryRepository<User> { public async existsByUsername(username: string): Promise<boolean> { const userOrNone = this.entities.find(entity => entity.username === username); return Boolean(userOrNone); // or, return !!userOrNone; } // And that's it here. InMemoryRepository implements the rest. } Aquí, nuestro InMemoryRepository necesita saber que las entidades tienen campos como id y nombre de username , por lo que pasamos User como parámetro genérico. User ya implementa IHasIdentity , por lo que se cumple la restricción genérica y también afirmamos que también tenemos una propiedad de nombre de username .
Ahora bien, cuando deseemos utilizar estos repositorios desde la capa de lógica de negocios, es bastante simple:
class UserService { public constructor ( private readonly userRepository: IUserRepository, private readonly emailService: IEmailService ) {} public async createUser(dto: ICreateUserDTO) { // Validate the DTO: // ... // Create a User Domain Model from the DTO const user = userFactory(dto); // Persist the Entity await this.userRepository.add(user); // Send a welcome email await this.emailService.sendWelcomeEmail(user); } } (Tenga en cuenta que en una aplicación real, probablemente moveríamos la llamada a emailService a una cola de trabajo para no agregar latencia a la solicitud y con la esperanza de poder realizar reintentos idempotentes en caso de fallas (no es que el envío de correo electrónico sea particularmente idempotente en primer lugar). Además, pasar todo el objeto de usuario al servicio también es cuestionable. El otro problema a tener en cuenta es que podríamos encontrarnos en una posición aquí donde el servidor falla después de que el usuario persiste pero antes de que el correo electrónico sea Hay patrones de mitigación para evitar esto, pero a los efectos del pragmatismo, la intervención humana con el registro adecuado probablemente funcionará bien).
Y ahí vamos: usando el patrón de repositorio con el poder de Generics, hemos desacoplado completamente nuestro DAL de nuestro BLL y hemos logrado interactuar con nuestro repositorio de una manera segura. También hemos desarrollado una forma de construir rápidamente repositorios en memoria igualmente seguros para los fines de las pruebas unitarias y de integración, lo que permite verdaderas pruebas de caja negra e independientes de la implementación. Nada de esto hubiera sido posible sin los tipos genéricos.
Como descargo de responsabilidad, quiero señalar una vez más que a esta implementación del Repositorio le falta mucho. Quería mantener el ejemplo simple ya que el enfoque es la utilización de genéricos, razón por la cual no manejé la duplicación ni me preocupé por las transacciones. Las implementaciones de repositorios decentes tomarían un artículo por sí mismos para explicar completa y correctamente, y los detalles de implementación cambian dependiendo de si está haciendo N-Tier Architecture o DDD. Eso significa que si desea utilizar el patrón de repositorio, no debe ver mi implementación aquí como una mejor práctica de ninguna manera.
Ejemplos del mundo real: estado de reacción y accesorios
El estado, la referencia y el resto de los ganchos para los componentes funcionales de React también son genéricos. Si tengo una interfaz que contiene propiedades para Task y quiero tener una colección de ellas en un Componente de React, podría hacerlo de la siguiente manera:
import React, { useState } from 'react'; export const MyComponent: React.FC = () => { // An empty array of tasks as the initial state: const [tasks, setTasks] = useState<Task[]>([]); // A counter: // Notice, type of `number` is inferred automatically. const [counter, setCounter] = useState(0); return ( <div> <h3>Counter Value: {counter}</h3> <ul> { tasks.map(task => ( <li key={task.id}> <TaskItem {...task} /> </li> )) } </ul> </div> ); }; Además, si queremos pasar una serie de accesorios a nuestra función, podemos usar el tipo genérico React.FC<T> y obtener acceso a los props :
import React from 'react'; interface IProps { id: string; title: string; description: string; } export const TaskItem: React.FC<IProps> = (props) => { return ( <div> <h3>{props.title}</h3> <p>{props.description}</p> </div> ); }; El compilador de TS infiere automáticamente que el tipo de props es IProps .
Conclusión
En este artículo, hemos visto muchos ejemplos diferentes de genéricos y sus casos de uso, desde colecciones simples hasta enfoques de manejo de errores, aislamiento de la capa de acceso a datos, etc. En los términos más simples, los genéricos nos permiten construir estructuras de datos sin necesidad de saber el tiempo concreto en el que operarán en tiempo de compilación. Con suerte, esto ayuda a abrir un poco más el tema, hacer que la noción de Genéricos sea un poco más intuitiva y mostrar su verdadero poder.