
La guía definitiva para construir web scrapers escalables con Scrapy
Publicado: 2022-03-10El raspado web es una forma de obtener datos de sitios web sin necesidad de acceder a las API o la base de datos del sitio web. Solo necesita acceder a los datos del sitio; siempre que su navegador pueda acceder a los datos, podrá extraerlos.
Siendo realistas, la mayoría de las veces podría simplemente navegar por un sitio web manualmente y obtener los datos 'a mano' usando copiar y pegar, pero en muchos casos eso le llevaría muchas horas de trabajo manual, lo que podría terminar costándole un mucho más de lo que valen los datos, especialmente si ha contratado a alguien para que haga la tarea por usted. ¿Por qué contratar a alguien para que trabaje de 1 a 2 minutos por consulta cuando puede obtener un programa para realizar una consulta automáticamente cada pocos segundos?
Por ejemplo, supongamos que desea compilar una lista de los ganadores del Oscar a la mejor película, junto con su director, actores, fecha de estreno y duración. Usando Google, puede ver que hay varios sitios que enumerarán estas películas por nombre y tal vez alguna información adicional, pero generalmente tendrá que seguir con los enlaces para capturar toda la información que desea.
Obviamente, sería poco práctico y llevaría mucho tiempo revisar todos los enlaces desde 1927 hasta la actualidad e intentar encontrar manualmente la información en cada página. Con web scraping, solo necesitamos encontrar un sitio web con páginas que tengan toda esta información y luego dirigir nuestro programa en la dirección correcta con las instrucciones correctas.
En este tutorial, usaremos Wikipedia como nuestro sitio web, ya que contiene toda la información que necesitamos y luego usaremos Scrapy en Python como una herramienta para raspar nuestra información.
Algunas advertencias antes de comenzar:
La extracción de datos implica aumentar la carga del servidor para el sitio que está extrayendo, lo que significa un mayor costo para las empresas que alojan el sitio y una experiencia de menor calidad para otros usuarios de ese sitio. La calidad del servidor que ejecuta el sitio web, la cantidad de datos que intenta obtener y la velocidad a la que envía solicitudes al servidor moderarán el efecto que tiene en el servidor. Teniendo esto en cuenta, debemos asegurarnos de cumplir con algunas reglas.
La mayoría de los sitios también tienen un archivo llamado robots.txt en su directorio principal. Este archivo establece reglas para los directorios a los que los sitios no quieren que accedan los raspadores. La página de Términos y condiciones de un sitio web generalmente le informará cuál es su política sobre el raspado de datos. Por ejemplo, la página de condiciones de IMDB tiene la siguiente cláusula:
Robots y raspado de pantalla: no puede usar minería de datos, robots, raspado de pantalla o herramientas similares de recopilación y extracción de datos en este sitio, excepto con nuestro consentimiento expreso por escrito, como se indica a continuación.
Antes de intentar obtener los datos de un sitio web, siempre debemos consultar los términos del sitio web y robots.txt para asegurarnos de que estamos obteniendo datos legales. Al construir nuestros raspadores, también debemos asegurarnos de no abrumar a un servidor con solicitudes que no puede manejar.
Afortunadamente, muchos sitios web reconocen la necesidad de que los usuarios obtengan datos y los ponen a disposición a través de las API. Si están disponibles, por lo general es una experiencia mucho más fácil obtener datos a través de la API que a través del raspado.
Wikipedia permite el raspado de datos, siempre que los bots no vayan "demasiado rápido", como se especifica en su robots.txt . También proporcionan conjuntos de datos descargables para que las personas puedan procesar los datos en sus propias máquinas. Si vamos demasiado rápido, los servidores bloquearán automáticamente nuestra IP, por lo que implementaremos temporizadores para mantenernos dentro de sus reglas.
Primeros pasos, Instalación de bibliotecas relevantes usando Pip
En primer lugar, para empezar, instalemos Scrapy.
ventanas
Instale la última versión de Python desde https://www.python.org/downloads/windows/
Nota: los usuarios de Windows también necesitarán Microsoft Visual C++ 14.0, que puede obtener de "Microsoft Visual C++ Build Tools" aquí.
También querrá asegurarse de tener la última versión de pip.
En cmd.exe , escriba:
python -m pip install --upgrade pip pip install pypiwin32 pip install scrapyEsto instalará Scrapy y todas las dependencias automáticamente.
linux
Primero querrás instalar todas las dependencias:
En Terminal, ingrese:
sudo apt-get install python3 python3-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-devUna vez que esté todo instalado, simplemente escriba:
pip install --upgrade pipPara asegurarse de que pip esté actualizado, y luego:
pip install scrapyY todo está hecho.
Mac
Primero deberá asegurarse de tener un compilador c en su sistema. En Terminal, ingrese:
xcode-select --installDespués de eso, instala homebrew desde https://brew.sh/.
Actualice su variable PATH para que los paquetes homebrew se usen antes que los paquetes del sistema:
echo "export PATH=/usr/local/bin:/usr/local/sbin:$PATH" >> ~/.bashrc source ~/.bashrcInstalar Pitón:
brew install pythonY luego asegúrese de que todo esté actualizado:
brew update; brew upgrade pythonUna vez hecho esto, simplemente instale Scrapy usando pip:
pip install Scrapy > ## Descripción general de Scrapy, cómo encajan las piezas, analizadores, arañas, etc.Escribirás un script llamado 'Spider' para que lo ejecute Scrapy, pero no te preocupes, las arañas Scrapy no dan miedo en absoluto a pesar de su nombre. La única similitud que tienen las arañas Scrapy y las arañas reales es que les gusta gatear en la web.
Dentro de la araña hay una class que tú defines que le dice a Scrapy qué hacer. Por ejemplo, dónde comenzar a rastrear, los tipos de solicitudes que realiza, cómo seguir los enlaces en las páginas y cómo analiza los datos. Incluso puede agregar funciones personalizadas para procesar datos, antes de volver a enviarlos a un archivo.
Para comenzar nuestra primera araña, primero debemos crear un proyecto Scrapy. Para hacer esto, ingrese esto en su línea de comando:
scrapy startproject oscarsEsto creará una carpeta con su proyecto.
Comenzaremos con una araña básica. El siguiente código debe ingresarse en un script de python. Abra un nuevo script de python en /oscars/spiders y asígnele el nombre oscars_spider.py
Importaremos Scrapy.
import scrapyLuego comenzamos a definir nuestra clase Spider. Primero, establecemos el nombre y luego los dominios que la araña puede rastrear. Finalmente, le decimos a la araña por dónde empezar a raspar.
class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']A continuación, necesitamos una función que capture la información que queremos. Por ahora, solo tomaremos el título de la página. Usamos CSS para encontrar la etiqueta que lleva el texto del título y luego la extraemos. Finalmente, devolvemos la información a Scrapy para que se registre o se escriba en un archivo.
def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data Ahora guarda el código en /oscars/spiders/oscars_spider.py
Para ejecutar esta araña, simplemente vaya a su línea de comando y escriba:
scrapy crawl oscarsDebería ver una salida como esta:
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)
¡Felicitaciones, ha creado su primer raspador Scrapy básico!

Código completo:
import scrapy class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield dataObviamente, queremos que haga un poco más, así que veamos cómo usar Scrapy para analizar datos.
Primero, familiaricémonos con el shell de Scrapy. El shell de Scrapy puede ayudarlo a probar su código para asegurarse de que Scrapy obtenga los datos que desea.
Para acceder al shell, ingrese esto en su línea de comando:
scrapy shell “https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture”Básicamente, esto abrirá la página a la que lo ha dirigido y le permitirá ejecutar líneas de código individuales. Por ejemplo, puede ver el HTML sin formato de la página escribiendo:
print(response.text)O abra la página en su navegador predeterminado escribiendo:
view(response)Nuestro objetivo aquí es encontrar el código que contiene la información que queremos. Por ahora, tratemos de obtener solo los nombres de los títulos de las películas.
La forma más fácil de encontrar el código que necesitamos es abriendo la página en nuestro navegador e inspeccionando el código. En este ejemplo, estoy usando Chrome DevTools. Simplemente haga clic derecho en el título de cualquier película y seleccione 'inspeccionar':
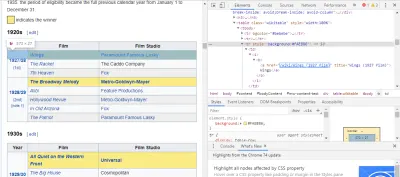
Como puedes ver, los ganadores del Oscar tienen un fondo amarillo mientras que los nominados tienen un fondo liso. También hay un enlace al artículo sobre el título de la película, y los enlaces para películas terminan en film) . Ahora que sabemos esto, podemos usar un selector de CSS para obtener los datos. En el shell de Scrapy, escriba:
response.css(r"tr[] a[href*='film)']").extract()Como puede ver, ¡ahora tiene una lista de todos los ganadores del Oscar a la Mejor Película!
> response.css(r"tr[] a[href*='film']").extract() ['<a href="/wiki/Wings_(1927_film)" title="Wings (1927 film)">Wings</a>', ... '<a href="/wiki/Green_Book_(film)" title="Green Book (film)">Green Book</a>', '<a href="/wiki/Jim_Burke_(film_producer)" title="Jim Burke (film producer)">Jim Burke</a>']Volviendo a nuestro objetivo principal, queremos una lista de los ganadores del Oscar a la mejor película, junto con su director, actores, fecha de estreno y duración. Para hacer esto, necesitamos que Scrapy tome datos de cada una de esas páginas de películas.
Tendremos que reescribir algunas cosas y agregar una nueva función, pero no se preocupe, es bastante sencillo.
Comenzaremos iniciando el raspador de la misma manera que antes.
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] Pero esta vez, dos cosas cambiarán. Primero, importaremos el time junto con scrapy porque queremos crear un temporizador para restringir la rapidez con la que raspa el bot. Además, cuando analizamos las páginas por primera vez, solo queremos obtener una lista de los enlaces a cada título, para poder obtener información de esas páginas.
def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req Aquí hacemos un bucle para buscar cada enlace en la página que termina en film) con el fondo amarillo y luego unimos esos enlaces en una lista de URL, que enviaremos a la función parse_titles para continuar. También incorporamos un temporizador para que solo solicite páginas cada 5 segundos. Recuerde, podemos usar Scrapy Shell para probar nuestros campos de respuesta.css para asegurarnos de que estamos obteniendo los datos correctos.
def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data El trabajo real se realiza en nuestra función parse_data , donde creamos un diccionario llamado data y luego completamos cada clave con la información que queremos. Nuevamente, todos estos selectores se encontraron usando Chrome DevTools como se demostró antes y luego se probaron con Scrapy Shell.
La línea final devuelve el diccionario de datos a Scrapy para almacenarlo.
Código completo:
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield dataA veces querremos usar proxies ya que los sitios web intentarán bloquear nuestros intentos de raspado.
Para hacer esto, solo necesitamos cambiar algunas cosas. Usando nuestro ejemplo, en nuestro def parse() , necesitamos cambiarlo a lo siguiente:
def parse(self, response): for href in (r"tr[] a[href*='film)']::attr(href)").extract() : url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) req.meta['proxy'] = "https://yourproxy.com:80" yield reqEsto enrutará las solicitudes a través de su servidor proxy.
Implementación y registro, muestra cómo administrar realmente una araña en producción
Ahora es el momento de ejecutar nuestra araña. Para hacer que Scrapy comience a raspar y luego generar un archivo CSV, ingrese lo siguiente en su símbolo del sistema:
scrapy crawl oscars -o oscars.csvVerá una salida grande y, después de un par de minutos, se completará y tendrá un archivo CSV en la carpeta de su proyecto.
Compilar resultados, mostrar cómo utilizar los resultados compilados en los pasos anteriores
Cuando abra el archivo CSV, verá toda la información que queríamos (ordenada por columnas con encabezados). Es realmente así de simple.
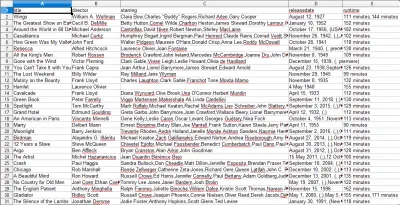
Con el raspado de datos, podemos obtener casi cualquier conjunto de datos personalizado que queramos, siempre que la información esté disponible públicamente. Lo que quieras hacer con estos datos depende de ti. Esta habilidad es extremadamente útil para realizar estudios de mercado, mantener actualizada la información de un sitio web y muchas otras cosas.
Es bastante fácil configurar su propio raspador web para obtener conjuntos de datos personalizados por su cuenta, sin embargo, recuerde siempre que puede haber otras formas de obtener los datos que necesita. Las empresas invierten mucho en proporcionar los datos que desea, por lo que es justo que respetemos sus términos y condiciones.
Recursos adicionales para obtener más información sobre Scrapy y Web Scraping en general
- El sitio web oficial de Scrapy
- Página GitHub de Scrapy
- "Las 10 mejores herramientas de raspado de datos y herramientas de raspado web", Scraper API
- "5 consejos para raspar web sin ser bloqueado o incluido en la lista negra", Scraper API
- Parsel, una biblioteca de Python para usar expresiones regulares para extraer datos de HTML.