
Las 15 principales preguntas y respuestas de entrevistas de Hadoop en 2022
Publicado: 2021-01-09Con el análisis de datos ganando impulso, ha habido un aumento en la demanda de personas buenas en el manejo de Big Data. Desde analistas de datos hasta científicos de datos, Big Data está creando una variedad de perfiles de trabajo en la actualidad. Lo primero y más importante con lo que se espera que sea práctico es Hadoop.
Independientemente del rol/perfil de trabajo, probablemente estará trabajando en Hadoop de una forma u otra. Por lo tanto, siempre puede esperar que los entrevistadores le hagan algunas preguntas de Hadoop.
Para eso y más, echemos un vistazo a las 15 preguntas principales de la entrevista de Hadoop que se pueden esperar en cualquier entrevista para la que se presente.
¿Qué es Hadoop? ¿Cuáles son los componentes principales de Hadoop?
Hadoop es una infraestructura equipada con herramientas y servicios relevantes necesarios para procesar y almacenar Big Data. Para ser precisos, Hadoop es la 'solución' a todos los desafíos de Big Data. Además, el marco Hadoop también ayuda a las organizaciones a analizar Big Data y tomar mejores decisiones comerciales.
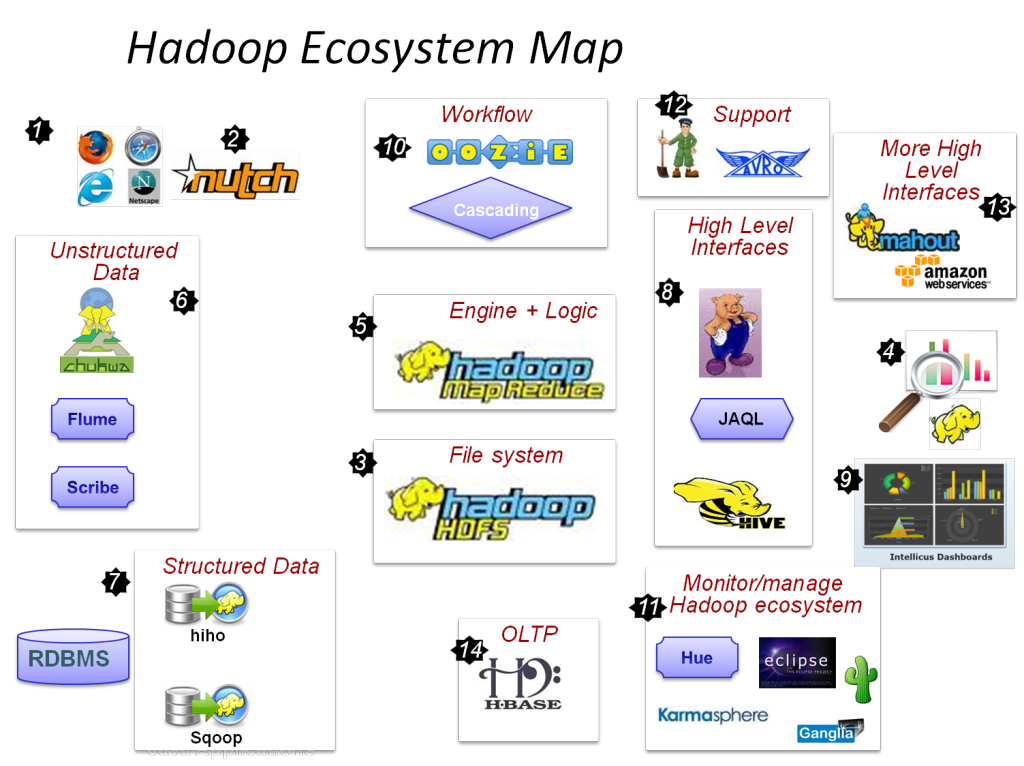
Los componentes principales de Hadoop son:
- HDFS
- Mapa de HadoopReducir
- Hadoop común
- HILO
- PIG y HIVE: los componentes de acceso a datos.
- HBase: para almacenamiento de datos
- Ambari, Oozie y ZooKeeper: componente de gestión y supervisión de datos
- Thrift y Avro: componentes de serialización de datos
- Apache Flume, Sqoop, Chukwa: los componentes de integración de datos
- Apache Mahout and Drill: componentes de inteligencia de datos
¿Cuáles son los conceptos básicos del marco Hadoop?
Hadoop se basa fundamentalmente en dos conceptos básicos. Ellos son:
- HDFS: HDFS o Hadoop Distributed File System es un sistema de archivos confiable basado en Java que se utiliza para almacenar grandes conjuntos de datos en formato de bloque. La Arquitectura Maestro-Esclavo lo impulsa.
- MapReduce: MapReduce es una estructura de programación que ayuda a procesar grandes conjuntos de datos. Esta función se divide aún más en dos partes: mientras que 'mapa' segrega los conjuntos de datos en tuplas, 'reducir' utiliza las tuplas del mapa y crea una combinación de trozos más pequeños de tuplas.
Nombre los formatos de entrada más comunes en Hadoop.
Hay tres formatos de entrada comunes en Hadoop:
- Formato de entrada de texto: este es el formato de entrada predeterminado en Hadoop.
- Formato de entrada de archivo de secuencia: este formato de entrada se utiliza para leer archivos en secuencia.
- Formato de entrada de valor clave: este se utiliza para leer archivos de texto sin formato.
¿Qué es el HILO?
YARN es la abreviatura de Yet Another Resource Negotiator. Es el marco de procesamiento de datos de Hadoop que administra los recursos de datos y crea un entorno para un procesamiento exitoso. 
¿Qué es la "conciencia de rack"?
"Rack Awareness" es un algoritmo que utiliza NameNode para determinar el patrón en el que los bloques de datos y sus réplicas se almacenan dentro del clúster de Hadoop. Esto se logra con la ayuda de definiciones de rack que reducen la congestión entre los nodos de datos contenidos en el mismo rack.

¿Qué son los NameNodes activos y pasivos?
Un sistema Hadoop de alta disponibilidad generalmente contiene dos NameNodes: Active NameNode y Passive NameNode.
El NameNode que ejecuta el clúster de Hadoop se llama Active NameNode y el NameNode en espera que almacena los datos del Active NameNode es el Passive NameNode.
El propósito de tener dos NameNodes es que si el NameNode activo falla, el NameNode pasivo puede tomar la iniciativa. Por lo tanto, NameNode siempre se ejecuta en el clúster y el sistema nunca falla.
¿Cuáles son los diferentes programadores en el marco de Hadoop?
Hay tres programadores diferentes en el marco de Hadoop:
- COSHH: COSHH ayuda a programar las decisiones al revisar el clúster y la carga de trabajo combinados con la heterogeneidad.
- Programador FIFO: FIFO alinea los trabajos en una cola en función de su hora de llegada, sin utilizar la heterogeneidad.
- Uso compartido justo: el uso compartido justo crea un grupo para usuarios individuales que contiene varios mapas y espacios reducidos en un recurso que pueden usar para ejecutar trabajos específicos.
¿Qué es la ejecución especulativa?
A menudo, en el marco de Hadoop, algunos nodos pueden ejecutarse más lentamente que el resto. Esto tiende a limitar todo el programa. Para superar esto, Hadoop primero detecta o 'especula' cuando una tarea se está ejecutando más lentamente de lo normal y luego lanza una copia de seguridad equivalente para esa tarea. Entonces, en el proceso, el nodo maestro ejecuta ambas tareas simultáneamente y la que se completa primero se acepta mientras que la otra se elimina. Esta función de copia de seguridad de Hadoop se conoce como ejecución especulativa.

Nombre los componentes principales de Apache HBase?
Apache HBase se compone de tres componentes:
- Servidor de región: después de dividir una tabla en varias regiones, los grupos de estas regiones se reenvían a los clientes a través del servidor de región.
- HMaster: Esta es una herramienta que ayuda a administrar y coordinar el servidor de la Región.
- ZooKeeper: ZooKeeper es un coordinador dentro del entorno distribuido HBase. Ayuda a mantener un estado de servidor dentro del clúster a través de la comunicación en las sesiones.
¿Qué es el "punto de control"? ¿Cuál es su beneficio?
Los puntos de control se refieren al procedimiento mediante el cual un FsImage y un registro de edición se combinan para formar un nuevo FsImage. Por lo tanto, en lugar de reproducir el registro de edición, NameNode puede cargar directamente el estado final en memoria desde FsImage. El NameNode secundario es responsable de este proceso.
El beneficio que ofrece Checkpointing es que minimiza el tiempo de inicio del NameNode, haciendo así que todo el proceso sea más eficiente.
Aplicaciones de Big Data en la cultura pop
¿Cómo depurar un código Hadoop?
Para depurar un código de Hadoop, primero debe verificar la lista de tareas de MapReduce que se están ejecutando actualmente. Luego, debe verificar si alguna tarea huérfana se está ejecutando simultáneamente. Si es así, debe encontrar la ubicación de los registros de Resource Manager siguiendo estos sencillos pasos:
Ejecute “ps –ef | grep –I ResourceManager” y en el resultado que se muestra, intente encontrar si hay un error relacionado con una identificación de trabajo específica.
Ahora, identifique el nodo trabajador que se usó para ejecutar la tarea. Inicie sesión en el nodo y ejecute “ps –ef | grep –iNodeManager.”
Por último, examine el registro del Administrador de nodos. La mayoría de los errores se generan a partir de registros de nivel de usuario para cada trabajo de reducción de mapas.
¿Cuál es el propósito de RecordReader en Hadoop?
Hadoop divide los datos en formatos de bloque. RecordReader ayuda a integrar estos bloques de datos en un solo registro legible. Por ejemplo, si los datos de entrada se dividen en dos bloques:
Fila 1 – Bienvenido a
Fila 2 - UpGrad
RecordReader leerá esto como "Bienvenido a UpG rad".
¿Cuáles son los modos en los que se puede ejecutar Hadoop?
Los modos en los que se puede ejecutar Hadoop son:
- Modo independiente: este es un modo predeterminado de Hadoop que se utiliza con fines de depuración. No es compatible con HDFS.
- Modo pseudodistribuido: este modo requería la configuración de los archivos mapred-site.xml, core-site.xml y hdfs-site.xml. Tanto el nodo maestro como el esclavo son iguales aquí.
- Modo completamente distribuido: el modo completamente distribuido es la etapa de producción de Hadoop en la que los datos se distribuyen entre varios nodos en un clúster de Hadoop. Aquí, los nodos maestro y esclavo se asignan por separado.
Nombre algunas aplicaciones prácticas de Hadoop.
Estos son algunos casos de la vida real en los que Hadoop está marcando la diferencia:
- Gestión del tráfico de la calle
- Detección y prevención de fraude
- Analice los datos de los clientes en tiempo real para mejorar el servicio al cliente
- Acceder a datos médicos no estructurados de médicos, HCP, etc., para mejorar los servicios de atención médica.
¿Cuáles son las herramientas vitales de Hadoop que pueden mejorar el rendimiento de Big Data?
Las herramientas de Hadoop que aumentan significativamente el rendimiento de Big Data son

• colmena
• HDFS
• HBase
• SQL
• No SQL
• moco
• Nubes
• Avro
• Canal
• Guardián del zoológico
Ingenieros de Big Data: Mitos vs. Realidades
Conclusión
Estas preguntas de la entrevista de Hadoop deberían serle de gran ayuda en su próxima entrevista. Si bien a veces los entrevistadores tienden a torcer algunas preguntas de la entrevista de Hadoop, no debería ser un problema para usted si tiene los conceptos básicos ordenados.
Si está interesado en saber más sobre Big Data, consulte nuestro programa PG Diploma in Software Development Specialization in Big Data, que está diseñado para profesionales que trabajan y proporciona más de 7 estudios de casos y proyectos, cubre 14 lenguajes y herramientas de programación, prácticas talleres, más de 400 horas de aprendizaje riguroso y asistencia para la colocación laboral con las mejores empresas.