
Las matemáticas detrás del aprendizaje automático: ¿Qué necesita saber?
Publicado: 2021-03-10El aprendizaje automático es una división de la IA que se centra en la creación de aplicaciones mediante el procesamiento preciso de los datos disponibles. El objetivo principal del aprendizaje automático es ayudar a las computadoras a procesar cálculos sin intervención humana. Esto es posible al permitir que una máquina aprenda a imitar la inteligencia humana a través de métodos de aprendizaje supervisados o no supervisados.
El aprendizaje automático es una combinación de muchos campos que incluyen estadísticas, probabilidad, álgebra lineal, cálculo, etc., en función de los cuales un modelo de aprendizaje automático puede crear o alimentar algoritmos para improvisar según la inteligencia humana. Cuanto más compleja sea la aplicación, más complejo será su algoritmo.
Desde asistentes digitales y dispositivos inteligentes hasta sitios web que recomiendan sus productos favoritos en función de sus actividades en línea y teléfonos móviles que le notifican el horario de su vuelo, los productos y herramientas basados en el aprendizaje automático están a nuestro alrededor. A medida que aumenta nuestra dependencia de los dispositivos y electrodomésticos inteligentes, también aumentará la necesidad de implementar el aprendizaje automático.
Con ese fin, en este artículo, exploraremos los conceptos matemáticos necesarios para escribir algoritmos de aprendizaje automático e implementarlos.
Tabla de contenido
¿Cuál es la importancia de las matemáticas en el aprendizaje automático?
Las aplicaciones de aprendizaje automático proporcionan análisis e información obtenida de los datos disponibles que contribuyen a la toma de decisiones procesables en las empresas. Dado que el aprendizaje automático gira en torno al estudio y la implementación de algoritmos, es importante reforzar sus habilidades matemáticas. Ayuda a eliminar la incertidumbre y a predecir los valores de los datos con precisión cuando se trata de características y parámetros de datos complejos. También nos ayuda a comprender mejor la compensación Sesgo-Varianza.
Dominar el aprendizaje automático requiere el conocimiento de conceptos matemáticos como álgebra lineal, cálculo vectorial, geometría analítica, descomposición de matrices, probabilidad y estadística. Una sólida comprensión de estos ayuda a crear aplicaciones intuitivas de aprendizaje automático.

Álgebra lineal
El álgebra lineal se ocupa de vectores y matrices, y en su mayoría gira en torno a la computación. Desempeña un papel integral en el aprendizaje automático y las técnicas de aprendizaje profundo. Según Skyler Speakman , son las matemáticas del siglo XXI.
Los ingenieros de aprendizaje automático y los científicos o investigadores de datos suelen utilizar el álgebra lineal para crear algoritmos lineales, regresiones logísticas, árboles de decisión y máquinas de vectores de soporte.
Cálculo
El cálculo impulsa los algoritmos de aprendizaje automático. Sin el conocimiento de sus conceptos, no sería posible predecir los resultados utilizando un conjunto de datos determinado. El cálculo ayuda a analizar la velocidad a la que cambian las cantidades y se ocupa del rendimiento óptimo de los algoritmos de aprendizaje automático. Integraciones, diferenciales, límites y derivadas son algunos conceptos de cálculo que ayudan a entrenar redes neuronales profundas.
Probabilidad
La probabilidad en el aprendizaje automático predice el conjunto de resultados, mientras que las estadísticas llevan el resultado favorable a su conclusión. El evento podría ser tan simple como lanzar una moneda. La probabilidad se puede dividir en dos categorías: probabilidad condicional y probabilidad conjunta. La probabilidad conjunta ocurre cuando los eventos son independientes entre sí, mientras que la probabilidad condicional ocurre cuando un evento reemplaza al otro.
Estadísticas
La estadística se centra en los aspectos cuantitativos y cualitativos del algoritmo. Nos ayuda a identificar objetivos y transformar los datos recopilados en observaciones precisas al presentarlos de manera concisa. Las estadísticas en el aprendizaje automático se centran en las estadísticas descriptivas y las estadísticas inferenciales.
La estadística descriptiva se ocupa de describir y resumir el pequeño conjunto de datos en el que está trabajando un modelo. Los métodos utilizados aquí son media, mediana, moda, desviación estándar y variación. Los resultados finales se presentan como representaciones pictóricas.
Las estadísticas inferenciales se ocupan de extraer información de una muestra dada mientras se trabaja con un gran conjunto de datos. Las estadísticas inferenciales permiten que las máquinas analicen datos más allá del alcance de la información proporcionada. Pruebas de hipótesis, distribuciones muestrales, análisis de varianza, son algunos aspectos de la Estadística Inferencial.
Aparte de estos, la destreza de codificación es un requisito previo crucial para el aprendizaje automático. La experiencia en lenguajes como Python y Java ayuda a comprender mejor el modelado de datos. El formateo de cadenas, la definición de funciones, los bucles con múltiples iteradores de variables, si o si no, las expresiones condicionales son algunas de sus funciones básicas.
En cuanto al modelado de datos, es el proceso a través del cual estimamos la estructura de conjuntos de datos y detectamos posibles variaciones y patrones. Para poder hacer predicciones precisas, uno debe ser consciente de las diversas propiedades de los datos colectivos.
¿Cómo se puede aprender el aprendizaje automático?
Si bien el aprendizaje automático es un campo lucrativo para ingresar, requiere mucha práctica y paciencia. Dadas sus aplicaciones en casi todas las industrias actuales, los ingenieros de aprendizaje automático tienen una gran demanda.
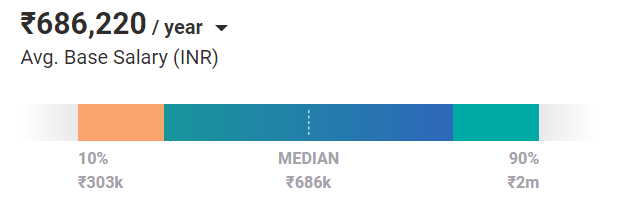
El salario promedio de un ingeniero de nivel inicial con experiencia en aprendizaje automático es de 686 000 rupias al año. Y con experiencia y capacitación, el potencial de ganar un salario más alto aumenta exponencialmente.
Hay varios cursos disponibles para alguien que desee mejorar su base de conocimientos en aprendizaje automático. Te tomaría un mínimo de 6 meses a 2 años dominar el tema.
Con un mínimo de una licenciatura y un año de experiencia laboral, mejor aún una licenciatura en Matemáticas o Estadística, puede seguir cualquiera de los siguientes cursos en upGrad para aumentar sus posibilidades de éxito en el campo.
- Programa de Certificado Avanzado en Aprendizaje Automático y Aprendizaje Profundo de IIT Bangalore (6 meses)
- Programa de Certificado Avanzado en Aprendizaje Automático y PNL de IIT Bangalore (6 meses)
- Programa ejecutivo de PG en aprendizaje automático e inteligencia artificial de IIT Bangalore (12 meses)
- Certificación avanzada en Machine Learning y Cloud de IIT Madras (12 meses)
- Maestría en Ciencias en Aprendizaje Automático e IA de LJMU e IIT Bangalore (18 meses)
Todos estos cursos ofrecen un mínimo de más de 240 horas de aprendizaje y al menos 5 estudios de casos que lo ayudarán a obtener una comprensión profunda del aprendizaje automático y sus diversos campos auxiliares. Puede cubrir temas esenciales como Python, MySQL, Tensor, NLTK, statsmodels, excel, etc., que forman la columna vertebral de la codificación. Aquí hay una descripción detallada de los diversos cursos de actualización en aprendizaje automático para que pueda elegir el más adecuado para usted.

Únase al curso de inteligencia artificial en línea de las mejores universidades del mundo: maestrías, programas ejecutivos de posgrado y programa de certificado avanzado en ML e IA para acelerar su carrera.
Aplicaciones del aprendizaje automático
El aprendizaje automático juega un papel crucial en nuestra vida diaria, tanto en el ámbito profesional como personal. Sus capacidades analíticas e intuitivas tienen el potencial de impactar drásticamente la forma en que llevamos a cabo nuestras tareas diarias. Ha demostrado ser ingenioso en el ahorro de tiempo y dinero para una organización.
Si bien el aprendizaje automático es un campo amplio con aplicaciones en casi todas las industrias, estos son algunos de los ejemplos más destacados:
- El reconocimiento de imágenes es una de las aplicaciones más utilizadas, ya que ayuda en la detección de rostros, creando así una base de datos separada para cada individuo. También se puede utilizar para identificar estilos de escritura a mano.
- El aprendizaje automático en el sector de la salud ha mejorado las capacidades de los proveedores de atención médica. Se puede utilizar en un diagnóstico médico más rápido. En muchos casos, la IA ha ayudado en el diagnóstico temprano de enfermedades, permitiendo así a los médicos sugerir tratamientos y medidas preventivas que tienen el potencial de salvar vidas.
- El aprendizaje automático tiene importantes aplicaciones en el sector financiero en lo que respecta a inversiones, fusiones y adquisiciones. Ayuda a los bancos y otras instituciones económicas a tomar decisiones inteligentes.
- Su efectividad es posiblemente más evidente en la industria de servicios y atención al cliente, ya que el aprendizaje automático agiliza las operaciones y brinda soluciones de manera más rápida y eficiente.
- El aprendizaje automático automatiza tareas que, de otro modo, tendría que realizar un ser humano en el campo. Por ejemplo, si tuviéramos que considerar los asistentes virtuales, podría ser una tarea tan simple como cambiar la contraseña o consultar su saldo bancario por la noche. Con el aprendizaje automático, ahora es posible asignar recursos humanos a tareas más apremiantes que requieren una toma de decisiones complicada o un toque humano para llevar a cabo.
Alcance futuro del aprendizaje automático
Aunque el aprendizaje automático existe desde hace décadas, su aplicación es más evidente hoy en día. La industria aún tiene que prosperar e improvisar, lo que implica que el futuro del aprendizaje automático es brillante. La mayoría de las empresas a gran escala ya están cosechando los beneficios del aprendizaje automático y escalando sus servicios y productos para impulsar el crecimiento.
Naturalmente, los ingenieros de ML tienen una gran demanda y el aprendizaje automático se presenta como una carrera lucrativa para ingresar. Ofrece a las empresas la ventaja que necesitan. AI ha generado aproximadamente 2,3 millones de oportunidades de trabajo hasta ahora. Se ha proyectado que, para fines de 2022, la industria mundial de ML crecerá a una CAGR del 42,2 % para alcanzar los 9 000 millones de USD .
Aquí hay algunas tendencias principales en el aprendizaje automático:
- Cada vez más algoritmos están aprendiendo hacia implementaciones no supervisadas. Las empresas están invirtiendo en computación cuántica basada en estos algoritmos no supervisados que tienen el potencial de transformar el aprendizaje automático. Estos contribuyen a analizar y obtener información significativa y, por lo tanto, ayudan a las empresas a lograr mejores resultados que no habrían sido posibles con las técnicas clásicas de aprendizaje automático.
- Se están implementando robots impulsados por IA para llevar a cabo operaciones comerciales. Sin embargo, estas tecnologías se encuentran en una etapa incipiente y, a medida que las empresas invierten en establecer un punto de apoyo de IA y ML, los robots pronto ayudarán a aumentar la productividad de manera exponencial. Para citar como ejemplo, tenemos drones que se presentan como poderosas herramientas comerciales en el mercado de consumo donde se utilizan para realizar operaciones comerciales y tareas simples como la entrega de bienes.
- Los algoritmos de aprendizaje automático admiten una personalización mejorada. Estos algoritmos examinan el comportamiento en línea de los clientes potenciales y envían información a las empresas. Las empresas a su vez les envían recomendaciones de productos y servicios. Estas técnicas de aprendizaje automático ayudan a identificar los gustos y disgustos de los clientes. A través del aprendizaje automático, las empresas les dan a sus clientes lo que desean y cuando lo desean, lo que aumenta la retención de clientes y atrae más negocios a la organización. La personalización mejorada es el futuro del aprendizaje automático.
- Gracias a los algoritmos de aprendizaje automático mejorados, las aplicaciones móviles y web ahora son más inteligentes que nunca. Los servicios cognitivos mejorados permiten a los desarrolladores crear bases de datos separadas para cada cliente, en función del reconocimiento visual, su habla, sonido, voz, etc.
Esto nos lleva al final del artículo. ¡Esperamos que esta información le haya resultado útil!
¿Por qué se requiere homocedasticidad en la regresión lineal?
La homocedasticidad describe cuán similares o cuán lejos se desvían los datos de la media. Esta es una suposición importante porque las pruebas estadísticas paramétricas son sensibles a las diferencias. La heterocedasticidad no induce sesgo en las estimaciones de los coeficientes, pero sí reduce su precisión. Con menor precisión, es más probable que las estimaciones del coeficiente se desvíen del valor de población correcto. Para evitar esto, la homocedasticidad es una suposición crucial para afirmar.
¿Cuáles son los dos tipos de multicolinealidad en la regresión lineal?
Los datos y la multicolinealidad estructural son los dos tipos básicos de multicolinealidad. Cuando hacemos un término modelo a partir de otros términos, obtenemos multicolinealidad estructural. En otras palabras, en lugar de estar presente en los datos en sí, es el resultado del modelo que proporcionamos. Si bien la multicolinealidad de los datos no es un artefacto de nuestro modelo, está presente en los datos mismos. La multicolinealidad de los datos es más común en las investigaciones observacionales.
¿Cuáles son los inconvenientes de usar la prueba t para pruebas independientes?
Hay problemas con la repetición de mediciones en lugar de diferencias entre diseños de grupos cuando se usan pruebas t de muestras pareadas, lo que conduce a efectos de arrastre. Debido a errores de tipo I, la prueba t no se puede utilizar para comparaciones múltiples. Será difícil rechazar la hipótesis nula al realizar una prueba t pareada en un conjunto de muestras. La obtención de los sujetos para los datos de la muestra es un aspecto del proceso de investigación que requiere mucho tiempo y es costoso.