
Canalización de prueba 101 para pruebas de interfaz
Publicado: 2022-03-10Imagínese esta situación: se acerca rápidamente a una fecha límite y está utilizando cada minuto libre para lograr su objetivo de finalizar esta refactorización compleja, con muchos cambios en sus archivos CSS. Incluso estás trabajando en los últimos pasos durante tu viaje en autobús. Sin embargo, sus pruebas locales parecen fallar cada vez y no puede hacer que funcionen. Su nivel de estrés está aumentando .
De hecho, hay una escena similar en una serie muy conocida: es de la tercera temporada de la serie de televisión de Netflix, “Cómo vender drogas en línea (rápido)”:
Cypress + Vue aparece *EN UN PROGRAMA DE TV DE NETFLIX*
– Jesús (@_jessicasachs) 7 de agosto de 2021
Es una comedia llamada "Cómo vender drogas (rápido)" y tiene algunas de las representaciones más realistas de webdev.
Temporada 3, episodio 1 a las 20:20 y una o dos veces antes. pic.twitter.com/ICSAwMxyFB
Bueno, al menos está usando pruebas, podrías pensar. ¿Por qué todavía está angustiado?, te preguntarás. Todavía hay mucho margen de mejora y para evitar tal situación, incluso si escribe pruebas. ¿Cómo piensas monitorear tu base de código y todos tus cambios desde el principio? Como resultado, no experimentarás sorpresas tan desagradables, ¿verdad? No es demasiado difícil incluir este tipo de rutinas de prueba automatizadas: creemos juntos esta canalización de prueba de principio a fin.
¡Vamos!
Lo primero es lo primero: términos básicos
Una rutina de construcción puede ayudarlo a tener confianza en refactorizaciones más complejas, incluso en sus pequeños proyectos paralelos. Sin embargo, eso no significa que deba ser un ingeniero de DevOps. Es esencial aprender un par de términos y estrategias, y para eso estás aquí, ¿no? ¡Afortunadamente, estás en el lugar correcto! Comencemos con los términos fundamentales que encontrará pronto cuando se trate de una canalización de prueba para su proyecto front-end.
Si busca en Google el mundo de las pruebas en general, es posible que ya se haya topado con los términos "CI/CD" como uno de los primeros términos. Es la abreviatura de "Integración continua, Entrega continua" e "Implementación continua" y describe exactamente eso: como probablemente ya haya escuchado, es un método de distribución de software utilizado por los equipos de desarrollo para implementar cambios de código con mayor frecuencia y confiabilidad. CI/CD implica dos enfoques complementarios, que dependen en gran medida de la automatización.
- Integración continua
Es un término para las medidas de automatización para implementar cambios de código pequeños y regulares y fusionarlos en un repositorio compartido. La integración continua incluye los pasos de construir y probar su código.
CD es el acrónimo de "Entrega continua" e "Implementación continua", que son conceptos similares entre sí pero que a veces se usan en contextos diferentes. La diferencia entre ambos radica en el alcance de la automatización:
- Entrega continua
Se refiere al proceso de su código que ya se estaba probando anteriormente, desde donde el equipo de operaciones ahora puede implementarlo en un entorno de producción en vivo. Sin embargo, este último paso puede ser manual. - Implementación continua
Se centra en el aspecto de "implementación", como su nombre lo indica. Es un término para el proceso de publicación completamente automatizado de los cambios del desarrollador desde el repositorio hasta la producción, donde el cliente puede usarlos directamente.
Esos procesos tienen como objetivo permitir que los desarrolladores y los equipos tengan un producto, que podrían lanzar en cualquier momento si quisieran: Tener la confianza de una aplicación continuamente monitoreada, probada e implementada.
Para lograr una estrategia de CI/CD bien diseñada, la mayoría de las personas y organizaciones utilizan procesos llamados "tuberías". “Pipeline” es una palabra que ya usamos en esta guía sin explicarla. Si piensa en tales tuberías, no es demasiado descabellado pensar en tubos que sirven como líneas de larga distancia para transportar cosas como el gas. Una tubería en el área de DevOps funciona de manera bastante similar: están "transportando" software para implementar.
Espera, eso suena como un montón de cosas para aprender y recordar, ¿verdad? ¿No hablamos de pruebas? Tiene razón en eso: Cubrir el concepto completo de una canalización de CI/CD proporcionará suficiente contenido para varios artículos, y queremos encargarnos de una canalización de prueba para pequeños proyectos front-end. O solo le falta el aspecto de prueba de sus canalizaciones, por lo que se enfoca solo en los procesos de integración continua. Entonces, en particular, nos centraremos en la parte de "Prueba" de las tuberías. Por lo tanto, crearemos una tubería de prueba "pequeña" en esta guía.
Muy bien, entonces la "parte de prueba" es nuestro enfoque principal. En este contexto, ¿qué pruebas ya conoces y te vienen a la mente a primera vista? Si pienso en probar de esta manera, estos son los tipos de pruebas en los que pienso espontáneamente:
- La prueba unitaria es un tipo de prueba en la que las partes o unidades menores comprobables de una aplicación, llamadas unidades, se prueban de forma individual e independiente para verificar su correcto funcionamiento.
- Las pruebas de integración se centran en la interacción entre componentes o sistemas. Este tipo de prueba significa que estamos comprobando la interacción de las unidades y cómo funcionan juntas.
- Pruebas de extremo a extremo , o pruebas E2E, significa que la computadora simula las interacciones reales del usuario; al hacerlo, las pruebas E2E deben incluir tantas áreas funcionales y partes de la pila de tecnología utilizada en la aplicación como sea posible.
- La prueba visual es el proceso de verificar la salida visible de una aplicación y compararla con los resultados esperados. Dicho de otra manera, ayuda a encontrar "errores visuales" en la apariencia de una página o pantalla diferente de los errores puramente funcionales.
- El análisis estático no es precisamente una prueba, pero creo que es esencial mencionarlo aquí. Puede imaginarlo funcionando como una corrección ortográfica: depura su código sin ejecutar el programa y detecta problemas de estilo de código. Esta simple medida puede prevenir muchos errores.
Para estar seguros de fusionar una refactorización masiva en nuestro proyecto único, debemos considerar usar todos estos tipos de prueba en nuestra canalización de prueba. Pero empezar con ventaja conduce rápidamente a la frustración: es posible que se sienta perdido al evaluar estos tipos de pruebas. ¿Donde debería empezar? ¿Cuántas pruebas de qué tipos son razonables?
Elaboración de estrategias: pirámides y trofeos
Necesitamos trabajar en una estrategia de prueba antes de sumergirnos en la construcción de nuestra tubería. Buscando respuestas a todas esas preguntas antes, es posible que encuentre una posible solución en algunas metáforas: en la web y en las comunidades de prueba específicamente, las personas tienden a usar analogías para darle una idea de cuántas pruebas debe usar y de qué tipo.
La primera metáfora con la que probablemente te encontrarás es la pirámide de automatización de pruebas. Mike Cohn ideó este concepto en su libro “Succeeding with Agile”, desarrollado posteriormente como “Práctica de la pirámide de prueba” por Martin Fowler. Se parece a esto:
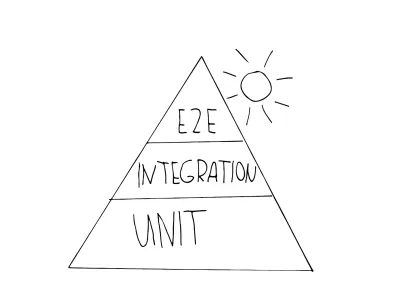
Como ves, consta de tres niveles, que corresponden a los tres niveles de prueba presentados. La pirámide pretende aclarar la combinación correcta de diferentes pruebas, para guiarlo mientras desarrolla una estrategia de prueba:
- Unidad
Estas pruebas se encuentran en la capa base de la pirámide porque son de ejecución rápida y fáciles de mantener. Esto se debe a su aislamiento y al hecho de que apuntan a las unidades más pequeñas. Vea este para ver un ejemplo de una prueba unitaria típica que prueba un producto muy pequeño. - Integración
Estos están en el medio de la pirámide, ya que aún son aceptables cuando se trata de velocidad en la ejecución, pero aún le brindan la confianza de estar más cerca del usuario que las pruebas unitarias. Un ejemplo de una prueba de tipo integración es una prueba API, también se pueden considerar pruebas de componentes de este tipo. - Pruebas E2E (también llamadas pruebas de interfaz de usuario )
Como vimos, estas pruebas simulan un usuario real y su interacción. Estas pruebas necesitan más tiempo para ejecutarse y, por lo tanto, son más costosas: se colocan en la parte superior de la pirámide. Si desea inspeccionar un ejemplo típico para una prueba E2E, diríjase a este.
Sin embargo, en los últimos años esta metáfora se sintió fuera de tiempo. Uno de sus defectos, en particular, es crucial para mí: los análisis estáticos se pasan por alto en esta estrategia. El uso de reparadores de estilo de código u otras soluciones de pelusa no se considera en esta metáfora, lo que es un gran defecto, en mi opinión. Lint y otras herramientas de análisis estático son una parte integral de la canalización en uso y no deben ignorarse.
Entonces, acortemos esto: deberíamos usar una estrategia más actualizada. Pero la falta de herramientas para eliminar pelusas no es el único defecto, incluso hay un punto más importante a considerar. En cambio, podríamos cambiar nuestro enfoque ligeramente: la siguiente cita lo resume bastante bien:
“Escribir pruebas. No muchos. Mayormente integración.”
—Guillermo Rauch
Analicemos esta cita para aprender sobre ella:
- Escribir pruebas
Se explica por sí mismo: siempre debe escribir pruebas. Las pruebas son cruciales para infundir confianza dentro de su aplicación, tanto para los usuarios como para los desarrolladores. ¡Incluso para ti mismo! - No muchos
Escribir pruebas al azar no te llevará a ninguna parte; la pirámide de pruebas sigue siendo válida en su declaración para mantener las pruebas priorizadas. - Principalmente integración
Una carta de triunfo de las pruebas más "caras" que la pirámide ignora es que la confianza en las pruebas aumenta a medida que se asciende en la pirámide. Este aumento significa que es más probable que tanto el usuario como usted como desarrollador confíen en esas pruebas.
Esto significa que debemos buscar pruebas que estén más cerca del usuario, por diseño. Como resultado, es posible que pague más, pero obtiene una gran cantidad de valor. Quizás se pregunte por qué no elegir la prueba E2E. Como están imitando a los usuarios, ¿no son los más cercanos al usuario, para empezar? Esto es cierto, pero aún son mucho más lentos de ejecutar y requieren la pila completa de aplicaciones. Por lo tanto, este retorno de la inversión se logra más tarde que con las pruebas de integración: en consecuencia, las pruebas de integración ofrecen un equilibrio justo entre la confianza por un lado y la velocidad y el esfuerzo por el otro.
Si sigues a Kent C.Dodds, estos argumentos pueden sonarte familiares, especialmente si lees este artículo de él en particular. Estos argumentos no son casualidad: ideó una nueva estrategia en su trabajo. Estoy totalmente de acuerdo con sus puntos y vinculo el más importante aquí y otros en la sección de recursos. Su enfoque sugerido se deriva de la pirámide de pruebas, pero la eleva a otro nivel al cambiar su forma para reflejar la mayor prioridad en las pruebas de integración. Se llama el "Trofeo de prueba".
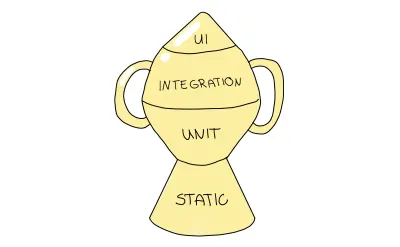
El trofeo de prueba es una metáfora que representa la granularidad de las pruebas de una manera ligeramente diferente; debe distribuir sus pruebas en los siguientes tipos de prueba:
- El análisis estático juega un papel vital en esta metáfora. De esta manera, detectará errores tipográficos, errores tipográficos y otros errores simplemente ejecutando los pasos de depuración mencionados.
- Las pruebas unitarias deben garantizar que su unidad más pequeña se pruebe adecuadamente, pero el trofeo de prueba no las enfatizará en la misma medida que la pirámide de prueba.
- La integración es el enfoque principal, ya que equilibra el costo y la mayor confianza de la mejor manera.
- Las pruebas de interfaz de usuario, incluidas las pruebas E2E y visuales, se encuentran en la parte superior del trofeo de pruebas, de forma similar a su función en la pirámide de pruebas.
Elegí esta estrategia de prueba de trofeos en la mayoría de mis proyectos, y continuaré haciéndolo en esta guía. Sin embargo, necesito dar un pequeño descargo de responsabilidad aquí: por supuesto, mi elección se basa en los proyectos en los que estoy trabajando en mi vida diaria. Por lo tanto, los beneficios y la selección de una estrategia de prueba coincidente siempre dependen del proyecto en el que esté trabajando. Así que no te sientas mal si no se ajusta a tus necesidades, agregaré recursos a otras estrategias en el párrafo correspondiente.
Alerta de spoiler menor: en cierto modo, también tendré que desviarme un poco de este concepto, como verá pronto. Sin embargo, creo que está bien, pero llegaremos a eso en un momento. Mi punto es pensar en la priorización y distribución de los tipos de prueba antes de planificar e implementar sus canalizaciones.
Cómo construir esos oleoductos en línea (rápido)
Se muestra al protagonista de la tercera temporada de la serie de televisión de Netflix "Cómo vender drogas en línea (rápido)" usando Cypress para las pruebas E2E mientras se acercaba la fecha límite, sin embargo, en realidad solo se trataba de pruebas locales. No se veía ningún CI/CD, lo que le provocaba un estrés innecesario. Debemos evitar la presión del protagonista dado en los episodios correspondientes con la teoría que aprendimos. Sin embargo, ¿cómo podemos aplicar esos aprendizajes a la realidad?
En primer lugar, necesitamos una base de código como base de prueba para empezar. Idealmente, debería ser un proyecto con el que nos encontremos muchos de nosotros, los desarrolladores front-end. Su caso de uso debería ser frecuente, siendo adecuado para un enfoque práctico y permitiéndonos implementar una canalización de prueba desde cero. ¿Qué podría ser un proyecto así?
Mi sugerencia de una canalización primaria
Lo primero que me vino a la mente fue evidente: mi sitio web, es decir, mi página de cartera, se adapta bien para ser considerado un código base de ejemplo para ser probado por nuestra tubería aspirante. Está publicado en código abierto en Github, por lo que puede verlo y usarlo libremente. Algunas palabras sobre la pila tecnológica del sitio: Básicamente, construí este sitio en Vue.js (lamentablemente todavía en la versión 2 cuando escribí este artículo) como un marco de JavaScript con Nuxt.js como un marco web adicional. Puede encontrar el ejemplo de implementación completo en su repositorio de GitHub.
Con nuestro código base de ejemplo seleccionado, debemos comenzar a aplicar nuestros aprendizajes. Dado el hecho de que queremos usar el trofeo de prueba como punto de partida para nuestra estrategia de prueba, se me ocurrió el siguiente concepto:
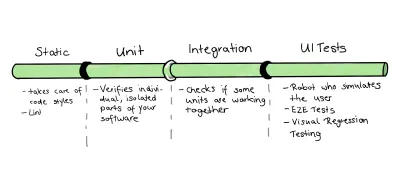
Como estamos lidiando con una base de código relativamente pequeña, fusionaré las partes de las pruebas de Unidad e Integración. Sin embargo, esa es solo una pequeña razón para hacerlo. Otras razones más importantes son las siguientes:
- La definición de una unidad es a menudo "para ser discutida": si le pide a un grupo de desarrolladores que defina una unidad, en su mayoría obtendrá varias respuestas diferentes. Como algunos se refieren a una función, clase o servicio (unidades menores), otro desarrollador contará en el componente completo.
- Además de esas luchas de definición, trazar una línea entre unidad e integración puede ser complicado, ya que es muy borroso. Esta lucha es real, especialmente para Frontend, ya que a menudo necesitamos el DOM para validar la base de prueba con éxito.
- Por lo general, es posible usar las mismas herramientas y bibliotecas para escribir ambas pruebas de integración. Entonces, podríamos ahorrar recursos fusionándolos.
Herramienta preferida: acciones de GitHub
Como sabemos lo que queremos imaginar dentro de una canalización, el siguiente paso es la elección de la plataforma de integración y entrega continuas (CI/CD). Al elegir una plataforma de este tipo para nuestro proyecto, pienso en aquellas con las que ya gané experiencia:
- GitLab, por la rutina diaria en mi lugar de trabajo,
- GitHub Actions en la mayoría de mis proyectos paralelos.
Sin embargo, hay muchas otras plataformas para elegir. Sugeriría siempre basar su elección en sus proyectos y sus requisitos específicos, teniendo en cuenta las tecnologías y los marcos utilizados, para que no se produzcan problemas de compatibilidad. Recuerde, usamos un proyecto de Vue 2 que ya se lanzó en GitHub, coincidentemente con mi experiencia anterior. Además, las acciones de GitHub mencionadas solo necesitan el repositorio de GitHub de su proyecto como punto de partida; para crear y ejecutar un flujo de trabajo de GitHub Actions específicamente para él. Como consecuencia, usaré GitHub Actions para esta guía.
Entonces, esas acciones de GitHub le brindan una plataforma para ejecutar flujos de trabajo definidos específicamente si están ocurriendo algunos eventos determinados. Esos eventos son actividades particulares en nuestro repositorio que desencadenan el flujo de trabajo, por ejemplo, enviar cambios a una rama. En esta guía, esos eventos están vinculados a CI/CD, pero dichos flujos de trabajo también pueden automatizar otros flujos de trabajo, como agregar etiquetas a las solicitudes de extracción. GitHub puede ejecutarlos en máquinas virtuales Windows, Linux y macOS.

Para visualizar dicho flujo de trabajo, se vería así:
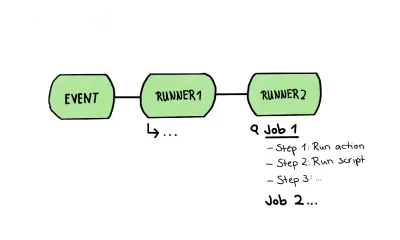
En este artículo, usaré un flujo de trabajo para representar una canalización; esto significa que un flujo de trabajo contendrá todos nuestros pasos de prueba, desde análisis estático hasta pruebas de interfaz de usuario de todo tipo. Este pipeline, o llamado “workflow” en los siguientes párrafos, consistirá en uno o más trabajos, que son un conjunto de pasos que se ejecutan en el mismo corredor.
Este flujo de trabajo es exactamente la estructura que quería esbozar en el dibujo de arriba. En él, echamos un vistazo más de cerca a un corredor de este tipo que contiene varios trabajos; Los pasos de un trabajo en sí están hechos de diferentes pasos. Esos pasos pueden ser de dos tipos:
- Un paso puede ejecutar un script simple.
- Un paso puede ser capaz de ejecutar una acción. Dicha acción es una extensión reutilizable y, a menudo, es una aplicación completa y personalizada.
Teniendo esto en cuenta, un flujo de trabajo real de una acción de GitHub se ve así:
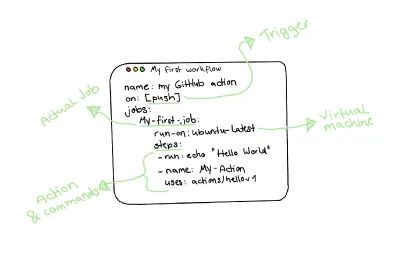
Escribiendo nuestra primera acción de GitHub
¡Finalmente, podemos escribir nuestra primera acción de Github y escribir algo de código! Comenzaremos con nuestro flujo de trabajo básico y nuestro primer resumen de los trabajos que queremos representar. Recordando nuestro trofeo de prueba, cada trabajo se parecerá a una capa en el trofeo de prueba. Los pasos serán las cosas que debemos hacer para automatizar esas capas.
Por lo tanto, primero creo el .github/workflows/ para almacenar nuestros flujos de trabajo. Crearemos un nuevo archivo llamado tests.yml para contener nuestro flujo de trabajo de prueba dentro de este directorio. Junto con la sintaxis de flujo de trabajo estándar que se ve en el dibujo anterior, procederé de la siguiente manera:
- Llamaré a nuestro flujo de trabajo
Tests CI. - Como quiero ejecutar mi flujo de trabajo en cada envío a mis sucursales remotas y proporcionar una opción manual para iniciar mi canalización, configuraré mi flujo de trabajo para que se ejecute en
pushyworkflow_dispatchde trabajo_despacho. - Por último, pero no menos importante, como se indica en el párrafo "Mi sugerencia de una canalización básica", mi flujo de trabajo contendrá tres trabajos:
-
static-eslintpara análisis estático; -
unit-integration-jestpara pruebas unitarias y de integración fusionadas en un solo trabajo; -
ui-cypresscomo etapa de interfaz de usuario, incluida la prueba E2E básica y la prueba de regresión visual.
-
- Una máquina virtual basada en Linux debería ejecutar todos los trabajos, así que
ubuntu-latest.
Ingrese la sintaxis correcta de un archivo YAML , el primer esquema de nuestro flujo de trabajo podría verse así:
name: Tests CI on: [push, workflow_dispatch] # On push and manual jobs: static-eslint: runs-on: ubuntu-latest steps: # 1 steps unit-integration-jest: runs-on: ubuntu-latest steps: # 1 step ui-cypress: runs-on: ubuntu-latest steps: # 2 steps: e2e and visualSi desea profundizar en los detalles sobre los flujos de trabajo en la acción de GitHub, no dude en consultar su documentación en cualquier momento. De cualquier manera, sin duda eres consciente de que todavía faltan los pasos. No te preocupes, yo también lo sé. Entonces, para llenar de vida este esquema de flujo de trabajo, debemos definir esos pasos y decidir qué herramientas de prueba y marcos usar para nuestro pequeño proyecto de cartera. Todos los párrafos siguientes describirán los respectivos trabajos y contendrán varios pasos para hacer posible la automatización de dichas pruebas.
Análisis estático
Como sugiere el trofeo de prueba, comenzaremos con linters y otros solucionadores de estilo de código en nuestro flujo de trabajo. En este contexto, puede elegir entre muchas herramientas, y algunos ejemplos incluyen los siguientes:
- Eslint como un fijador de estilo de código Javascript.
- Stylelint para corregir código CSS.
- Podemos considerar ir aún más lejos, por ejemplo, para analizar la complejidad del código, podría buscar herramientas como el escrutador.
Esas herramientas tienen en común que señalan errores en patrones y convenciones. Sin embargo, tenga en cuenta que algunas de esas reglas son cuestión de gustos. Depende de usted decidir qué tan estricto desea aplicarlos. Por poner un ejemplo, si vas a tolerar una sangría de dos o cuatro pestañas. Es mucho más importante centrarse en exigir un estilo de código consistente y detectar las causas de errores más críticas, como usar "==" en lugar de "===".
Para nuestro proyecto de cartera y esta guía, quiero comenzar a instalar Eslint, ya que estamos usando mucho Javascript. Lo instalaré con el siguiente comando:
npm install eslint --save-dev Por supuesto, también puedo usar un comando alternativo con el administrador de paquetes Yarn si prefiero no usar NPM. Después de la instalación, necesito crear un archivo de configuración llamado .eslintrc.json . Usemos una configuración básica por ahora, ya que este artículo no le enseñará cómo configurar Eslint en primer lugar:
{ "extends": [ "eslint:recommended", ] } Si desea obtener información detallada sobre la configuración de Eslint, diríjase a esta guía. A continuación, queremos dar nuestros primeros pasos para automatizar la ejecución de Eslint. Para empezar, quiero configurar el comando para ejecutar Eslint como un script NPM. Logro esto usando este comando en nuestro archivo package.json en la sección de secuencias de script :
"scripts": { "lint": "eslint --ext .js .", }, Luego puedo ejecutar este script recién creado en nuestro flujo de trabajo de GitHub. Sin embargo, debemos asegurarnos de que nuestro proyecto esté disponible antes de hacerlo. Por lo tanto, usamos las actions/checkout@v2 que hacen exactamente eso: verificar nuestro proyecto, para que el flujo de trabajo de su acción de GitHub pueda acceder a él. El siguiente paso sería instalar todas las dependencias de NPM que necesitamos para mi proyecto de cartera. ¡Después de eso, finalmente estamos listos para ejecutar nuestro script eslint! Nuestro trabajo final para usar pelusa se ve así ahora:
static-eslint: runs-on: ubuntu-latest steps: # Action to check out my codebase - uses: actions/checkout@v2 # install NPM dependencies - run: npm install # Run lint script - run: npm run lint Quizás se pregunte ahora: ¿Esta canalización "falla" automáticamente cuando nuestro npm run lint en una prueba fallida? Sí, esto funciona fuera de la caja. Tan pronto como terminemos de escribir nuestro flujo de trabajo, veremos las capturas de pantalla en Github.
Unidad e Integración
A continuación, quiero crear nuestro trabajo que contenga la unidad y los pasos de integración. Con respecto al marco utilizado en este artículo, me gustaría presentarle el marco Jest para las pruebas de interfaz. Por supuesto, no necesitas usar Jest si no quieres, hay muchas alternativas para elegir:
- Cypress también proporciona pruebas de componentes para que sean adecuados para las pruebas de integración.
- Jasmine es otro marco para echar un vistazo también.
- Y hay muchos más; Solo quería nombrar algunos.
Facebook proporciona Jest como código abierto. El marco acredita su enfoque en la simplicidad al tiempo que es compatible con muchos marcos y proyectos de JavaScript, incluidos Vue.js, React o Angular. También puedo usar jest junto con TypeScript. Esto hace que el marco sea muy interesante, especialmente para mi pequeño proyecto de cartera, ya que es compatible y adecuado.
Podemos comenzar a instalar Jest directamente desde esta carpeta raíz de mi proyecto de cartera ingresando el siguiente comando:
npm install --save-dev jest Después de la instalación, ya puedo comenzar a escribir pruebas. Sin embargo, este artículo se centra en la automatización de estas pruebas mediante el uso de acciones de Github. Entonces, para aprender a escribir una prueba unitaria o de integración, consulte la siguiente guía. Al configurar el trabajo en nuestro flujo de trabajo, podemos proceder de manera similar al trabajo static-eslint . Entonces, el primer paso es nuevamente crear un pequeño script NPM para usar en nuestro trabajo más adelante:
"scripts": { "test": "jest", }, Luego, definiremos el trabajo llamado unit-integration-jest manera similar a lo que ya hicimos para nuestros linters antes. Entonces, el flujo de trabajo verificará nuestro proyecto. Además de eso, usaremos dos ligeras diferencias en nuestro primer trabajo static-eslint :
- Usaremos una acción como paso para instalar Node.
- Después de eso, usaremos nuestro script npm recién creado para ejecutar nuestra prueba Jest.
De esta manera, nuestro trabajo unit-integration-jest se verá así:
unit-integration-jest: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 # Set up node - name: Run jest uses: actions/setup-node@v1 with: node-version: '12' - run: npm install # Run jest script - run: npm testPruebas de interfaz de usuario: E2E y pruebas visuales
Por último, pero no menos importante, escribiremos nuestro trabajo ui-cypress , que contendrá pruebas E2E y pruebas visuales. Es inteligente combinar esos dos en un solo trabajo, ya que usaré el marco Cypress para ambos. Por supuesto, puede considerar otros marcos como los siguientes, NightwatchJS y CodeceptJS.
Nuevamente, cubriremos solo los conceptos básicos para configurarlo en nuestro flujo de trabajo de GitHub. Si desea aprender cómo escribir pruebas de Cypress en detalle, lo cubro con otra de mis guías que aborda precisamente eso. Este artículo lo guiará a través de todo lo que necesitamos para definir nuestros pasos de prueba E2E. Muy bien, primero instalaremos Cypress, de la misma manera que hicimos con los otros marcos, usando el siguiente comando en nuestra carpeta raíz:
npm install --save-dev cypress Esta vez, no necesitamos definir un script NPM. Cypress ya nos proporciona su propia acción de GitHub para usar, cypress-io/github-action@v2 . Allí, solo necesitamos configurar algunas cosas para que funcione:
- Necesitamos asegurarnos de que nuestra aplicación esté completamente configurada y funcionando, ya que una prueba E2E necesita la pila completa de aplicaciones disponible.
- Necesitamos nombrar el navegador en el que estamos ejecutando nuestra prueba E2E.
- Necesitamos esperar a que el servidor web esté funcionando completamente, para que la computadora pueda comportarse como un usuario real.
Afortunadamente, nuestra acción Cypress nos ayuda a almacenar todas esas configuraciones con el área with . De esta manera, nuestro trabajo actual de GitHub se ve de esta manera:
steps: - name: Checkout uses: actions/checkout@v2 # Install NPM dependencies, cache them correctly # and run all Cypress tests - name: Cypress Run uses: cypress-io/github-action@v2 with: browser: chrome headless: true # Setup: Nuxt-specific things build: npm run generate start: npm run start wait-on: 'http://localhost:3000'Pruebas visuales: presta algunos ojos a tu prueba
Recuerde nuestra primera intención de escribir esta guía: tengo mi refactorización significativa con muchos cambios en los archivos SCSS; quiero agregar pruebas como parte de la rutina de compilación para asegurarme de que no rompa nada más. Con pruebas de análisis estático, unidad, integración y E2E, deberíamos estar bastante seguros, ¿verdad? Cierto, pero todavía hay algo que puedo hacer para que mi canalización sea aún más perfecta y a prueba de balas. Se podría decir que se está convirtiendo en la crema. Especialmente cuando se trata de la refactorización de CSS, una prueba E2E solo puede ser de ayuda limitada, ya que solo hace lo que dijo que hiciera al escribirlo en su prueba.
Afortunadamente, hay otra forma de detectar errores aparte de los comandos escritos y, por lo tanto, aparte del concepto. Se llama prueba visual: puede imaginar que este tipo de prueba es como un rompecabezas de encontrar las diferencias. Técnicamente hablando, la prueba visual es una comparación de capturas de pantalla que tomará capturas de pantalla de su aplicación y las comparará con el status quo, por ejemplo, de la rama principal de su proyecto. De esta forma, no pasará desapercibido ningún problema de estilo accidental, al menos en las áreas en las que utiliza las pruebas visuales. Esto puede convertir las pruebas visuales en un salvavidas para grandes refactorizaciones de CSS, al menos en mi experiencia.
Hay muchas herramientas de prueba visual para elegir y vale la pena echarle un vistazo:
- Percy.io, una herramienta de Browserstack que estoy usando para esta guía;
- Visual Regression Tracker si prefiere no usar una solución SaaS y al mismo tiempo utilizar código completamente abierto;
- Appliotools con soporte de IA. Hay una guía interesante para consultar en la revista Smashing sobre esta herramienta;
- Cromático por Storybook.
Para esta guía y básicamente para mi proyecto de cartera, fue vital reutilizar mis pruebas Cypress existentes para pruebas visuales. Como mencioné antes, usaré Percy para este ejemplo debido a su simplicidad de integración. Aunque es una solución SaaS, todavía se proporcionan muchas partes de código abierto, y hay un plan gratuito que debería ser suficiente para muchos proyectos de código abierto u otros proyectos paralelos. Sin embargo, si se siente más cómodo siendo completamente autohospedado mientras usa una herramienta de código abierto, puede darle una oportunidad al Rastreador de regresión visual.
Esta guía le brindará solo una breve descripción general de Percy, que de lo contrario proporcionaría contenido para un artículo completamente nuevo. Sin embargo, te daré la información para que comiences. Si desea profundizar en los detalles ahora, le recomiendo consultar la documentación de Percy. Entonces, ¿cómo podemos darle ojos a nuestras pruebas, por así decirlo? Supongamos que ya hemos escrito una o dos pruebas de Cypress. Imagínese que se ven así:
it('should load home page (visual)', () => { cy.get('[data-cy=Polaroid]').should('be.visible'); cy.get('[data-cy=FeaturedPosts]').should('be.visible'); });Claro, si queremos instalar Percy como nuestra solución de prueba visual, podemos hacerlo con un complemento de ciprés. Entonces, como lo hicimos un par de veces hoy, lo instalaremos en nuestra carpeta raíz usando NPM:
npm install --save-dev @percy/cli @percy/cypress Luego, solo necesita importar el paquete percy/cypress a su archivo de índice cypress/support/index.js :
import '@percy/cypress';Esta importación le permitirá usar el comando de instantánea de Percy, que tomará una instantánea de su aplicación. En este contexto, una instantánea significa una colección de capturas de pantalla tomadas de diferentes ventanas gráficas o navegadores que puede configurar.
it('should load home page (visual)', () => { cy.get('[data-cy=Polaroid]').should('be.visible'); cy.get('[data-cy=FeaturedPosts]').should('be.visible'); // Take a snapshot cy.percySnapshot('Home page'); }); Volviendo a nuestro archivo de flujo de trabajo, quiero definir la prueba de Percy como el segundo paso del trabajo. En él, ejecutaremos el script npx percy exec -- cypress run para ejecutar nuestra prueba junto con Percy. Para conectar nuestras pruebas y resultados con nuestro proyecto Percy, necesitaremos pasar nuestro token Percy, oculto por un secreto de GitHub.
steps: # Before: Checkout, NPM, and E2E steps - name: Percy Test run: npx percy exec -- cypress run env: PERCY_TOKEN: ${{ secrets.PERCY_TOKEN }}¿Por qué necesito una ficha de Percy? Es porque Percy es una solución SaaS para mantener nuestras capturas de pantalla. Mantendrá las capturas de pantalla y el status quo para comparar y nos proporcionará un flujo de trabajo de aprobación de capturas de pantalla. Allí, puede aprobar o rechazar cualquier cambio próximo:
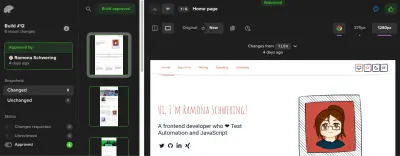
Visualización de nuestros trabajos: integración de GitHub
¡Felicidades! Estábamos construyendo con éxito nuestro primer flujo de trabajo de acción de GitHub. Echemos un vistazo final a nuestro archivo de flujo de trabajo completo en el repositorio de la página de mi cartera. ¿No te preguntas cómo se ve en el uso práctico? Puede encontrar sus acciones de trabajo de GitHub en la pestaña "Acciones" de su repositorio:
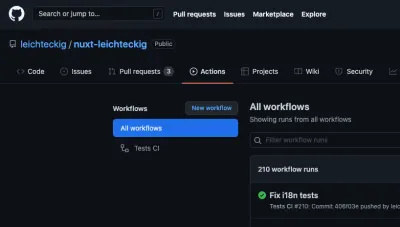
Allí puede encontrar todos los flujos de trabajo, que son equivalentes a sus archivos de flujo de trabajo. Si echa un vistazo a un flujo de trabajo, por ejemplo, mi flujo de trabajo "Pruebas de CI", puede inspeccionar todos sus trabajos:
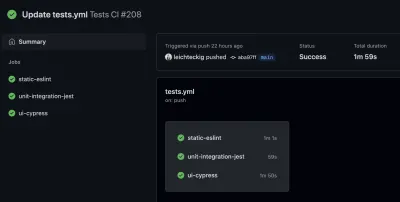
Si desea ver uno de sus trabajos, también puede seleccionarlo en la barra lateral. Allí, puede inspeccionar el registro de sus trabajos:
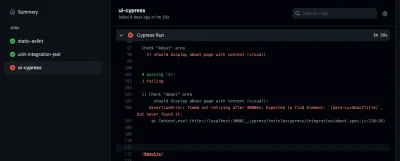
Verá, puede detectar errores si ocurren dentro de su canalización. Por cierto, la pestaña de "acción" no es el único lugar donde puede verificar los resultados de sus acciones de GitHub. También puede inspeccionarlos en sus solicitudes de extracción:
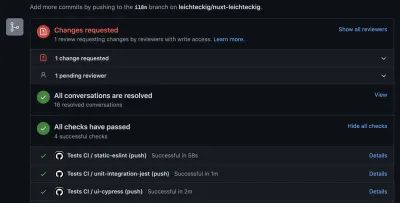
I like to configure those GitHub actions the way they need to be executed successfully: Otherwise, it's not possible to merge any pull requests into my repository.
Conclusión
CI/CD helps us perform even major refactorings — and dramatically minimizes the risk of running into nasty surprises. The testing part of CI/CD is taking care of our codebase being continuously tested and monitored. Consequently, we will notice errors very early, ideally before anyone merges them into your main branch. Plus, we will not get into the predicament of correcting our local tests on the way to work — or even worse — actual errors in our application. I think that's a great perspective, right?
To include this testing build routine, you don't need to be a full DevOps engineer: With the help of some testing frameworks and GitHub actions, you're able to implement these for your side projects as well. I hope I could give you a short kick-off and got you on the right track.
I'm looking forward to seeing more testing pipelines and GitHub action workflows out there! ️
Recursos
- An excellent guide on CI/CD by GitHub
- “The practical test pyramid”, Ham Vocke
- Articles on the testing trophy worth reading, by Kent C.Dodds:
- “Write tests. Not too many. Mostly integration”
- “The Testing Trophy and Testing Classifications”
- “Static vs Unit vs Integration vs E2E Testing for Frontend Apps”
- I referred to some examples of the Cypress real world app
- Documentation of used tools and frameworks:
- GitHub actions
- Eslint docs
- Documentación de broma
- Documentación de ciprés
- Percy documentation