
Estrategias para proyectos headless con sistemas de gestión de contenido estructurado
Publicado: 2022-03-10Esta es la guía que me hubiera gustado tener en los últimos años cuando ejecuté proyectos con sistemas de administración de contenido (CMS) autónomos. He sido desarrollador, consultor de experiencia de usuario y tecnología, gerente de proyectos, arquitecto de información y autor. Los diferentes sombreros me han hecho darme cuenta de que incluso si hemos tenido los llamados CMS "sin cabeza" por un tiempo, todavía hay una forma de pensar en cómo usarlos mejor.
Ahora estamos en un lugar donde muchos de nosotros confiamos en los marcos de trabajo de JavaScript para el trabajo de frontend, utilizando sistemas de diseño hechos de componentes y composiciones, en lugar de simplemente implementar diseños de página planos. Hay mucha tracción hacia las JAMstacks y las aplicaciones isomórficas/universales que se ejecutan tanto en el servidor como en el cliente. La última pieza del rompecabezas es cómo gestionamos todo el contenido.
Los CMS tradicionales están agregando API para servir contenido a través de solicitudes de red y el formato JSON. Además, han surgido CMS "sin cabeza" para servir contenido exclusivamente a través de API. Sin embargo, mi argumento en este artículo es que deberíamos pasar menos tiempo hablando de "sin cabeza" y más de "contenido estructurado" . Porque esa es la cualidad esencial de estos sistemas. Hay muchas implicaciones para nuestro oficio implícitas en estos sistemas, y todavía tenemos un camino por recorrer en términos de descubrir los buenos patrones de cómo debemos tratar con estas tecnologías.
Al llegar a la consultoría tecnológica con experiencia en humanidades, he aprendido mucho sobre cómo organizar y trabajar con proyectos web que adoptan un enfoque centrado en el contenido, tanto con los nuevos CMS basados en API como con los CMS tradicionales. He llegado a apreciar cómo comenzar temprano con contenido en vivo real de un CMS; hacerlo en un entorno interdisciplinario no solo ha hecho posible descubrir complejidades en una etapa anterior, sino que también otorga agencia a todos los involucrados y brinda oportunidades para reflexionar sobre los desafíos y las posibilidades de la tecnología y el diseño en su sentido más amplio.
WordPress sin cabeza
Todo el mundo sabe que si un sitio web es lento, los usuarios lo abandonarán. Echemos un vistazo más de cerca a los conceptos básicos para crear un WordPress desacoplado. Leer un artículo relacionado →
En este artículo, sugeriré algunas estrategias generales, con algunos ejemplos concretos del mundo real sobre cómo pensar en trabajar con contenido estructurado. En el momento de escribir este artículo, acabo de empezar a trabajar para una empresa de SaaS que proporciona un servicio de gestión de contenido de este tipo, para alojar contenido entregado a través de API. Haré referencias a él, tanto por mi experiencia pasada con él en proyectos en los que participé como consultor, como porque creo que ilustra acertadamente los puntos que quiero señalar. Así que considere esto como una especie de descargo de responsabilidad.
Dicho esto, he estado pensando en escribir este artículo durante un par de años y me he esforzado por hacerlo aplicable a cualquier plataforma que elijas. Entonces, sin más preámbulos, retrocedamos veinte años en el tiempo para comprender un poco más dónde estamos hoy.
Primeros pasos con los estándares web
A principios de la década de 2000, el movimiento de estándares web inspiró a un campo a cambiar su forma de trabajar. Desde un enfoque de "diseño primero", dirigieron nuestra atención hacia cómo el contenido de una página debe marcarse semánticamente usando HTML: el menú de un sitio web no es una <table> , es un <nav> ; Un encabezado no es un <b> , es un <h1> . Fue un paso significativo para pensar en los diferentes roles que juega el contenido web para ayudar a los usuarios a encontrarlo, identificarlo y asimilarlo.
El movimiento de estándares web introdujo el argumento de que el marcado semántico mejoró la accesibilidad, lo que también mejoró su clasificación en los resultados de búsqueda de Google. También marcó un cambio en la forma en que pensamos sobre el contenido web . Su sitio web ya no era el único lugar donde se representaba su contenido. También tenía que pensar en cómo se presentaban sus páginas web en otros contextos visuales, como en los resultados de búsqueda o lectores de pantalla. Más tarde, esto fue impulsado por las redes sociales y las vistas previas integradas de los enlaces compartidos. La mentalidad cambió de cómo debería verse el contenido a lo que debería significar . Esta también es la clave para trabajar con contenido estructurado.
Con la adopción de dispositivos de bolsillo conectados a Internet, la web de repente se convirtió en un serio competidor en las aplicaciones. La competencia, sin embargo, fue principalmente para los globos oculares del usuario final. Muchas organizaciones todavía necesitaban distribuir información sobre sus productos y servicios tanto en sus aplicaciones como en sus diferentes presencias web. Al mismo tiempo, la web maduró y JavaScript y AJAX facilitaron la conexión de diferentes fuentes de contenido a través de las API. En la actualidad, contamos con GraphQL y herramientas que simplifican la búsqueda de contenido y la administración del estado. Y así, las piezas del rompecabezas tecnológico comienzan a encajar.
“Crear una vez, publicar en todas partes”
Aunque se describe principalmente como un "cambio tecnológico", la incorporación de contenido en las cargas útiles de JSON (que viajan a lo largo de los tubos HTTP) tiene un impacto enorme en la forma en que pensamos sobre el contenido digital y los flujos de trabajo que lo rodean. De alguna manera, ya lo ha hecho. Hace casi diez años, el invitado Daniel Jacobson de National Public Radio (NPR) escribió un blog en programmableweb.com sobre su enfoque, resumido en el acrónimo COPE, que significa "Crear una vez, publicar en todas partes". En el artículo, presenta un sistema de administración de contenido que brinda contenido a múltiples interfaces digitales a través de una API, no a través de una máquina de procesamiento de HTML, como lo hicieron la mayoría de los CMS en ese momento (y posiblemente ahora).
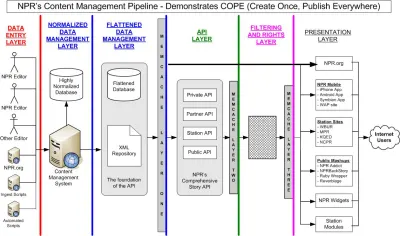
La "capa de gestión de datos" COPE de NPR es lo que se convertiría en la noción de "un CMS sin cabeza". En los inicios de COPE, se lograba estructurando el contenido en XML. Hoy en día, JSON se ha convertido en el formato de datos dominante para transferir datos a través de API, incluidos los dispositivos de Internet de las cosas y otros sistemas fuera de la web. Si desea intercambiar contenido con chatbots, interfaces de voz e incluso software para la creación de prototipos visuales, muy a menudo habla HTTP con acento JSON.
“Desacuñando” el término “CMS sin cabeza”
Según Google Trends, las búsquedas de "CMS sin cabeza" ganaron popularidad en 2015, es decir, seis años después del artículo COPE de NPR. El término "sin cabeza" (al menos en relación con la tecnología digital y no con la aristocracia francesa de finales del siglo XVIII), se ha utilizado durante bastante tiempo para hablar de sistemas que se ejecutan sin una interfaz gráfica de usuario.
Nota : se podría argumentar que una interfaz de línea de comandos es realmente "gráfica", como el software en servidores o entornos de prueba (pero dejemos eso para otro artículo).
Tengo dudas al llamar a estos nuevos CMS "sin cabeza". También podríamos llamarlos “policefálicos”, eso que tiene muchas cabezas. Son las Hidras y Cerbeuses de los CMS. “Headless” también define estos sistemas por la capacidad de la que carecen (es decir, un motor de plantillas para representar páginas web), en lugar de definirlos por su verdadera fuerza: hacer posible estructurar contenido sin las limitaciones de la web. Dicho esto, a partir de hoy, muchas de las soluciones en esta categoría también podrían llamarse "Nearly Headless Nick". Porque la interfaz de edición todavía está estrechamente unida al sistema. Su "ausencia de cabeza" surge de la falta de un motor de plantillas, es decir, la maquinaria que produce marcas a partir del contenido.
Nota : Sin embargo, casi definitivamente usaría un CMS llamado "Mimsy-Porpington" (conocido del universo de Harry Potter).
En cambio, hacen que el contenido esté disponible a través de una API, lo que le brinda más flexibilidad sobre cómo, qué y dónde desea mostrar y usar este contenido. Esto los convierte en los compañeros perfectos de los marcos frontend de JavaScript populares, como React, Angular y Vue. Y a pesar de la afirmación de poder entregar contenido a "sitios web, aplicaciones y dispositivos", la mayoría de ellos todavía están limitados por el funcionamiento del contenido web. Esto es más notable en la forma en que la mayoría maneja el texto enriquecido, almacenándolo como HTML o Markdown.
Los CMS tradicionales también han comenzado a agregar API algo genéricas además de sus sistemas de representación de plantillas y llaman a esto "desacoplado" como una forma de distinguirse de sus nuevos competidores. “¡Todo esto y las API también!”* es el reclamo. Algunos de estos CMS también son bastante agnósticos en lo que respecta al modelado de contenido. Por ejemplo, Craft CMS casi no hace suposiciones sobre su modelo de contenido cuando lo instala por primera vez. Wordpress también se está moviendo hacia el uso de API para la entrega de contenido. Sospecho que la brecha entre los jugadores antiguos en el campo de CMS y los nuevos se reducirá a medida que avancemos.
No obstante, colocar la administración de contenido detrás de las API (en lugar de un renderizador de HTML) es un paso importante hacia formas más sofisticadas de trabajar en una época en la que el texto, las imágenes, los videos y los medios de una organización se digitalizan y se exponen a usuarios y clientes internos y externos. Sin embargo, es hora de alejarse de la definición de sus capacidades de renderizado frontend deficientes, a lo que realmente pueden hacer por nosotros: brindarnos una forma de trabajar con contenido estructurado . Entonces, ¿deberíamos llamarlos "Sistemas de gestión de contenido estructurado"? Como en, “No Bob, este no es su CMS habitual. Esto es un SCMS, confía en mí, va a ser una cosa”.
No se trata de los jefes, se trata de contenido estructurado
El cambio más radical que imponen los sistemas de gestión de contenido estructurado (SCMS) es alejarse de la organización del contenido de acuerdo con una jerarquía de páginas a donde eres libre de estructurar el contenido para cualquier propósito que consideres adecuado. Evitar el contenido duplicado es una clara ventaja porque aumenta la confiabilidad y disminuye la carga administrativa (no tiene que lidiar con el contenido duplicado en múltiples canales). En otras palabras: Crear una vez, publicar en todas partes . Si solo tiene que actualizar la descripción de su producto una vez, en un sistema, y se actualiza dondequiera que su producto esté expuesto al usuario, eso es claramente una ventaja.
Si bien los proveedores de SCMS usan con frecuencia "su sitio web y una aplicación" para justificar pensar de manera diferente en la estructura de la página, no tiene que cruzar el río para obtener beneficios de una estructura de contenido estructurado. Con la popularidad de los marcos de JavaScript, es cada vez más común crear sitios web como una composición de componentes individuales, que se pueden "llenar" con diferentes contenidos según el estado y el contexto. Puede tener una tarjeta de producto que aparece en muchos contextos diferentes a lo largo de su aplicación web. Estamos viendo que el desarrollo web moderno se aleja de la configuración de documentos y páginas para componer componentes de acuerdo con una combinación de información del usuario, algoritmos y personalización.
Estas tendencias sobre cómo se crean los sistemas de diseño y cómo se nos alienta a trabajar en equipo a través de procesos de prueba, aprendizaje e iteración, hacen que el campo de la gestión de contenido esté maduro para nuevas formas de pensar. Han surgido algunos patrones, pero aún nos queda mucho camino por recorrer. Por lo tanto, en base a mi experiencia de trabajar en equipos y proyectos que han puesto el contenido al frente y al centro, y como ahora soy parte de un equipo que crea un servicio para él (y les insto a que sean conscientes de cualquier sesgo aquí), quiero presentar algunas estrategias que creo que pueden ser útiles y crear puntos para una mayor discusión.
1. Abordar el contenido en equipos multidisciplinarios
Creo que es cosa del pasado que un diseñador gráfico pueda entregar páginas obsoletas y con píxeles perfectos a un desarrollador frontend cuya responsabilidad era “implementar” el diseño. Ahora creamos sistemas de diseño que consisten en componentes más pequeños, presentados en composiciones que vienen con múltiples estados posibles listos para usar. La mayoría de las veces, estos componentes deben ser resistentes a las entradas generadas por el usuario, lo que significa que cuanto antes introduzca contenido en vivo en el proceso, mejor. La responsabilidad de un desarrollador frontend no es reproducir la visión de un diseñador gráfico ; es manejar un campo complejo de cómo los navegadores procesan HTML, CSS y JavaScript, asegurándose de que las interfaces de usuario respondan, sean accesibles y funcionen.
Cuando trabajaba como consultor de tecnología en Netlife (una consultoría especializada en experiencia de usuario), vi que se estaban dando grandes pasos hacia la colaboración entre desarrolladores, diseñadores e investigadores de usuarios. Aunque nuestros editores de contenido siempre estuvieron involucrados en el proyecto desde el principio, sus contribuciones no entraron en el flujo de trabajo de diseño principalmente debido a la fricción técnica.
El cuello de botella a menudo era un CMS heredado que no podíamos tocar, o que tomó tiempo construir la estructura del contenido porque dependía del diseño. Esto a menudo resultó en la duplicación del trabajo: Hicimos un prototipo HTML, a menudo basado en el contenido analizado de los archivos Markdown, que tuvo que volver a implementarse en la pila de CMS cuando se realizó la prueba del usuario, y todos estaban felices con píxeles perfectos. . Este fue a menudo un proceso costoso ya que las limitaciones en el CMS se descubrieron tarde en el proceso. También crea presión en todas las partes para "hacerlo bien la primera vez" y deja menos espacio para el tipo de experimentación que le gustaría en un proyecto de diseño.
El trabajo multidisciplinario requiere sistemas ágiles
Pasar a un SCMS en el que tomó minutos codificar un modelo de contenido (donde los campos y la API estaban listos al instante) cambió nuestro proceso, y para mejor. Recuerdo estar sentado con el editor de contenido del nuevo u4.no en los primeros días del proyecto. Hablando sobre cómo trabajaron y les gustaría trabajar con su contenido. Con bastante rapidez, traducimos nuestras conclusiones en objetos JavaScript simples que se transformaron instantáneamente en un entorno de edición en el navegador. Averiguar títulos y descripciones útiles para los títulos. Hablamos sobre cómo querían fragmentos de texto que pudieran reutilizar en diferentes páginas y contextos, a los que internamente llamaron "pepitas", que luego creamos allí mismo.
Permitir este tipo de exploración al principio del desarrollo del proyecto (un editor de contenido y un desarrollador hablando juntos mientras se creaba la interfaz frente a nosotros) se sintió poderoso. Sabiendo que podíamos seguir diseñando la interfaz en React mientras ella y sus colegas comenzaban a trabajar con el contenido. Y no preocuparnos por arrinconarnos, como solíamos hacer con los CMS en los que la estructura estaba estrechamente relacionada con la forma en que tenía que codificar la parte frontal.
Un sistema de contenido debe permitir la experimentación y la iteración
Aparte de los proyectos de rediseño creativo, un sistema de contenido estructurado también debería permitirle continuar mejorando, probando e iterando su contenido como parte de todo su sistema de diseño. Los diseñadores de UX deberían poder crear prototipos rápidamente con contenido real utilizando herramientas como Sketch o Framer X. Debería poder aumentar la gestión de contenido con medidas cuantitativas, ya sean escalas de legibilidad o cómo se desempeña el contenido donde se usa.
Nota : Utilicé el término "diseñadores de UX" arriba a pesar de tener la opinión de que todos deberíamos, de alguna manera, relacionarnos con el proceso de crear buenas experiencias de usuario. Todos somos diseñadores de UX en nuestras diferentes líneas de diseño.
Trabajar con contenido estructurado requiere un poco de tiempo para acostumbrarse si está acostumbrado a usar contenido WYSIWYG directamente en el diseño de su página web. Sin embargo, se presta a una conversación que está más en línea con la forma en que se mueve el campo del diseño digital. El contenido estructurado permite que un equipo de diseñadores, desarrolladores, editores de contenido, investigadores de usuarios y administradores de proyectos piensen colectivamente sobre cómo debería funcionar un sistema para satisfacer las necesidades y los objetivos estratégicos de los usuarios. Esto también requiere que pienses de manera diferente sobre cómo se estructura el contenido, lo que nos lleva a la siguiente estrategia.
2. Es posible que no necesite un orden jerárquico
Uno de los cambios más notables para muchos es que los sistemas de contenido estructurado están orientados a colecciones y listas de documentos y no a jerarquías de carpetas que reflejan las estructuras de navegación del sitio web. Estas estructuras dejan de tener sentido tan pronto como parte del contenido se va a utilizar en otros contextos, ya sean chatbots, medios impresos u otros sitios web. Los CMS tradicionales han tratado de mitigar esto al permitir bloques de contenido reutilizables, pero aún deben colocarse en diseños de página y son engorrosos para razonar a través de las API.
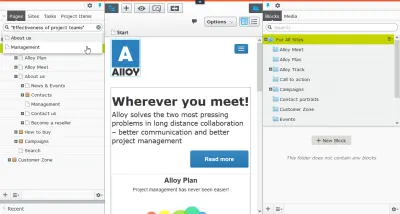
Cada página por su cuenta
Como se establece en The Core Model, cuando uno de sus principales referentes es Google o comparte en las redes sociales, debe considerar cada página como una página de destino. Y si observa la distribución de las páginas vistas, notará que algunas de sus páginas son mucho más populares que otras. A menos que sea un sitio web de noticias, esas no suelen ser las noticias, sino aquellas que permiten al usuario lograr lo que esperaba lograr en su sitio web. Ellos son donde los negocios realmente están sucediendo.

Su contenido digital debe estar al servicio de la intersección de sus propios objetivos estratégicos y los objetivos individuales de sus usuarios. Cuando la agencia digital Bengler (predecesora de sanity.io) creó el nuevo sitio web para oma.eu, no estructuró el contenido según una elaborada jerarquía de páginas. Hicieron tipos de contenido que reflejaban la realidad cotidiana de la organización, es decir, después de proyectos , personas y publicaciones . De hecho, el sitio web de OMA es casi completamente plano en términos de jerarquía de contenido, y la página principal se genera a partir de una combinación de reglas algorítmicas y editoriales.
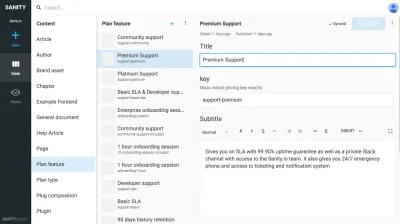
Entonces, ¿cómo hacerlo? Creo que es una combinación de pensar en su contenido como un reflejo de cómo es el modelo mental de su organización y lo que debe ser para ser útil para lo que sea que sus usuarios lo necesiten.
He aquí un ejemplo básico: al crear una página de empleados, probablemente debería comenzar con un tipo de contenido llamado persona . Una persona puede tener un nombre, información de contacto, una imagen, diferentes roles organizacionales y una breve biografía. Un documento de persona se puede reutilizar en listas de contactos, autores de artículos, interfaces de soporte de chat e insignias de acceso a edificios. ¿Quizás ya tiene un sistema interno que sabe quiénes son estas personas y que viene con una API? Genial, entonces sincroniza con eso.
No te pierdas en un agujero de conejo ontológico
Es útil volver a la forma en que Google indexa las páginas web y cómo intenta indexar la información del mundo. Por eso dedican tiempo y esfuerzo a los datos vinculados (RDFa, microformato, JSON-LD). Si anota sus páginas web con elementos JSON-LD, aparecerá más destacado en los resultados de búsqueda. También es relevante cuando los asistentes de voz deben pronunciar su información y mostrarla en una interfaz de usuario del asistente. Si tu contenido ya está estructurado y fácilmente disponible en una API, te resultará relativamente fácil implementarlo en estos microformatos.
Sin embargo, no estoy seguro de recomendar entrar en las ontologías de schema.org y varios recursos de datos vinculados, al menos no para fines de edición. Puede perderse rápidamente en una madriguera de conejo tratando de hacer estructuras platónicas perfectas donde todo encaje.
Noticia de última hora: Nunca lo hará, porque el mundo es un lugar desordenado y porque la gente piensa sobre las cosas de manera diferente.
Es más importante estructurar su contenido en un sistema que tenga sentido intuitivo y se preste a adaptarse a medida que cambien las necesidades. Por eso es importante comenzar con el modelado de contenido desde el principio del proceso de diseño y desarrollo: debe aprender cómo se debe usar.
Resumen de la realidad, no de las convenciones de CMS
Puede ser tentador simplemente seguir las convenciones con las que viene su CMS. ¿Recuerdas cómo Wordpress te dará "Publicaciones" y "Páginas", y de repente todo debe encajar en esos cuadros? Un campo de texto enriquecido WYSIWYG es flexible en el sentido de que le permite ingresar lo que sea, pero el contenido no estará estructurado ni se adaptará fácilmente: solo es flexible una vez. Pero necesita algún lugar para comenzar su mapeo de un modelo de contenido. Mi sugerencia es comenzar hablando con la gente, es decir, los autores y los lectores.
¿Cómo habla la gente sobre el contenido internamente? ¿Cómo llama la gente a las cosas diferentes? Podría ejecutar un ejercicio de listado libre, un método utilizado por los etnógrafos para mapear taxonomías populares. Por ejemplo, podría preguntar:
“Nombre los diferentes tipos de contenido en nuestra organización”.
O, en un nivel más específico:
“¿Puede nombrar los diferentes tipos de informes que tenemos en esta organización?”
El objetivo de esta encuesta es desentrañar las taxonomías internalizadas que lleva la gente, y no sus opiniones o sentimientos sobre las cosas (algo que a menudo tiende a descarrilar los procesos de diseño). No tiene que preguntar particularmente a muchos antes de tener una lista bastante exhaustiva con la que puede trabajar. Probablemente encontrará que partes de su lista provienen de convenciones en su CMS actual (es bueno saberlo si va a hacer alguna remodelación). Ahora debe hablar con su editor y tratar de precisar para qué necesitan el contenido.
Algunas preguntas que puedes hacer pueden ser las siguientes:
- ¿Necesita usar este contenido en más de un lugar? ¿Donde?
- ¿Cuáles son las diferentes relaciones entre los tipos de contenido?
- ¿Dónde necesitamos que se muestre el contenido hoy y mañana?
- ¿De qué manera necesitamos que se ordene el contenido? ¿La ordenación se puede hacer algorítmicamente, por parte del usuario, o tiene que ser manual?
- ¿Hay sistemas o bases de datos en otros sistemas con los que podamos sincronizarnos para evitar la duplicación?
- ¿Dónde queremos que viva el contenido canónico? ¿Debe el SCMS ser la fuente para ello, o simplemente aumentar el contenido existente, por ejemplo, copia de marketing para productos que viven en un sistema de gestión de productos?
Esto no significa que tenga que desechar la arquitectura de información tradicional con el agua del baño ahora tibia. Todavía tiene sentido tener artículos como un tipo de contenido, si los artículos son parte de la realidad de contenido de su organización. Pero tal vez realmente no necesite la convención abstracta de categorías , porque estos artículos tienen referencias al tipo de servicios o productos en ellos. Y esta relación permite consultar estos artículos en circunstancias en las que tiene sentido, sin requerir que alguien tenga "administración de categorías de artículos" como parte de su descripción de trabajo.
El artículo también es lo que dificulta desvincular completamente el contenido de la capa de presentación. Estamos tan acostumbrados a pensar en el diseño y el estilo del artículo, pero en una época en la que se espera que alojes tu propio contenido en tu propio dominio y luego lo distribuyas a plataformas como medium.com, ya te has dado por vencido. control sobre la presentación visual. Esto nos lleva a la siguiente estrategia.
3. Los contextos de presentación también son tipos de contenido
Esté listo para el rediseño
También desea poder adaptar y cambiar rápidamente la estructura de navegación de su sitio web, sin tener que reconstruir toda su arquitectura de contenido o luchar contra una interfaz estricta similar a una carpeta. También desea poder tener cierta jerarquía de contenido, porque a veces tiene sentido y, a veces, es más profundo que dos niveles, donde la mayoría de las interfaces en el departamento de CMS API-first no brindan mucha ayuda.
Curiosamente, los sistemas de administración de contenido para chatbots tienden a usar estructuras jerárquicas similares para organizar árboles de intención y flujos de diálogo. Esto quiere decir que las jerarquías de contenido juegan diferentes roles en diferentes canales, pero a menudo brindan formas de navegar a través del contenido. Una forma de abordar esto es crear tipos para la navegación, donde puede organizar el contenido por referencias y crear rutas para páginas web, menús o rutas para interfaces conversacionales.
Consejos de relaciones
Las referencias (o relaciones) es lo que hace posible un sistema de contenido estructurado, y es realmente el núcleo de todo lo que estamos tratando cuando se trata de contenido en la web (es la razón por la que se llama metafóricamente la web en primer lugar). Ser capaz de hacer referencias entre bits de contenido es algo muy poderoso, pero también puede ser costoso en términos de cómo los backends pueden escribir y recuperar dichos datos. Por lo tanto, es posible que tenga que pensar de manera diferente si tiene multitud de documentos, ya que la báscula rara vez es gratuita.
También vale la pena considerar que no siempre necesita una referencia explícita para unir datos; la mayoría de las veces se puede hacer por criterios que tienen que ver con el contenido, por ejemplo, “dame todas las personas y todos los edificios dentro de esta geolocalización”. No es necesario que el edificio y las personas tengan una referencia explícita entre sí, siempre que esté implícito en un campo de ubicación en ambos tipos de contenido.
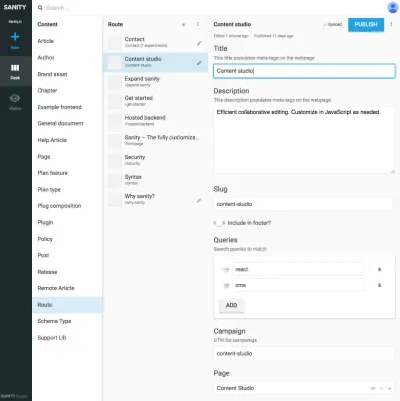
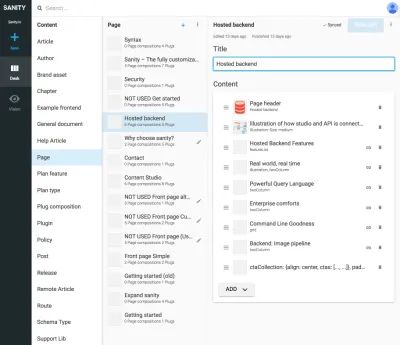
Las referencias entre los tipos de presentación y otros tipos de contenido son útiles cuando no puede dejar que un algoritmo en la capa de presentación una los datos. Puede parecer un poco engorroso dibujar explícitamente estos tipos de presentación y hacer composiciones de contenido referido, pero es una solución a un problema que a menudo encontrará con los SCMS: es difícil saber dónde se está utilizando el contenido. Al incluir tipos de navegación, vinculará explícitamente el contenido a la presentación, pero no solo a uno. Esto hace posible razonar para trabajar con estructuras de navegación independientemente del contenido al que conducen.
Por ejemplo, en las capturas de pantalla hemos vinculado Google Experiments al tipo de rutas , lo que permite agregar varias páginas compuestas por referencias al contenido, lo que significa que podemos ejecutar pruebas A/B casi sin duplicación de contenido. Dado que también recibimos una advertencia si intentamos eliminar contenido al que hacen referencia otros documentos, esta forma de estructuración evitará que eliminemos algo que no deberíamos.
Las relaciones entre tipos de contenido son un arma de doble filo. Aumenta la sostenibilidad y es clave para evitar la duplicación. Por otro lado, puede cortarse fácilmente porque crea dependencias entre el contenido, lo que (si no se hace transparente) puede generar cambios no deseados en los canales donde se muestran sus datos. Sería malo, por ejemplo, si pudiéramos eliminar una "página" utilizada por una "ruta" sin previo aviso.
Esto nos lleva a la siguiente estrategia, que (¡por supuesto!) está en parte más allá del poder del usuario normal hoy en día, ya que tiene que ver con cómo se diseñan los diferentes sistemas. Aún así, vale la pena pensarlo.
4. No coloque texto enriquecido en una esquina
El texto enriquecido es más que HTML
Puedo entender por qué HTML tiene tanta prevalencia en el contenido digital, pero sé que también proviene de algo; es un subconjunto de SGML, una forma generalizada de estructurar documentos legibles por máquina. Como señala Claire L. Evans en el maravilloso libro "Broad Band: The Untold Story of the Women who made the Internet" (2018), ya había una comunidad vibrante de personas que pensaban en documentos vinculados cuando se introdujo HTML. La propuesta de Tim Berners-Lee era mucho más simple que muchos de los otros sistemas en ese momento, pero probablemente esa es la razón por la que se dio cuenta e hizo posible, a partir de ahora, la web abierta y gratuita.
Cuando estás en un navegador en la World Wide Web, HTML es excelente. Si es un escritor que quiere publicar algo que termina en HTML simple, Markdown es excelente. Si desea que su contenido de texto enriquecido se integre fácilmente en algo que no sea un navegador o un marco de JavaScript popular que le permita aumentar HTML con JavaScript en componentes complejos (sí, estamos hablando de React y Vue.js) , tener HTML en sus respuestas API comienza a ser un poco complicado, especialmente si necesita analizarlo.
Sin embargo, casi todos lo hacen, incluso los nuevos chicos de la cuadra: revisé a todos los proveedores en headlesscms.org y examiné la documentación, y también me registré para aquellos que no lo mencionaron. Con dos excepciones, todos almacenaron texto enriquecido como HTML o Markdown. Eso está bien si todo lo que hace es usar Jekyll para representar un sitio web, o si disfruta usando peligrosamente SetInnerHTML en React. Pero, ¿qué sucede si desea reutilizar su contenido en interfaces que no están en la web? ¿O si desea más control y funcionalidad en su editor de texto enriquecido? ¿O simplemente desea que sea más fácil representar su texto enriquecido en uno de los marcos de interfaz de usuario populares y que sus componentes se encarguen de diferentes partes de su contenido de texto enriquecido? Bueno, tendrá que encontrar una manera inteligente de analizar ese descuento o HTML en lo que necesita o, más convenientemente, simplemente tenerlo almacenado de manera más sensata en primer lugar.
Por ejemplo, ¿qué sucede si desea enviar su texto enriquecido a una interfaz de voz? Sabemos que los asistentes de voz están ganando popularidad. Las plataformas más populares para estos asistentes tienen la capacidad de obtener el texto para contenido hablado a través de API. Entonces desea aprovechar algo como Speech Synthesis Markup Language. Un sistema de texto portátil adopta un enfoque más agnóstico del texto enriquecido, lo que le permite adaptar el mismo contenido para diferentes tipos de interfaces.
Lectura recomendada : Experimentando con la interfaz SpeechSynthesis
Texto portátil como modelo de texto enriquecido agnóstico
El texto portátil también es útil cuando se crea principalmente contenido para la web. ¿Qué sucede si desea tener la posibilidad de anidar y aumentar su texto con estructuras de datos, como una nota al pie de texto enriquecido o un comentario editorial en línea? ¿O una frase o redacción alternativa para los casos de prueba A/B? Markdown y HTML se quedan cortos rápidamente, y tendrá que confiar en agregar algo como etiquetas especiales de código abreviado, tal como lo resolvió Wordpress. With portable text, you have an agnostic representation of content structures, without having to marry a certain implementation. Your content ends up being more sustainable and flexible for new redesigns and implementations.
There are also other advantages to portable text, especially if you want to be able to edit content collaboratively and in real time (as you do in Google Docs); you need to store rich text in another structure than HTML. If you do, you'll also be able to take advantage of microservices and bots, such as spaCy, in order to annotate and augment your content without locking the document.
As for now, portable text isn't widely adopted, but we're seeing movements towards it. The specification isn't very complex and can be explored at portabletext.org.
5. Make Sure Your SCMS Is In Service For Your Editors, And Not The Other Way Around
Digital content isn't just used for your organization's online web page leaflets anymore. For most of us, it encapsulates and defines how your organization is understood by the world, both from those within it and those outside: From product copy, micro texts to blog posts, chatbot responses, and strategy documents. We are millions of people that have to log into some CMS every day and navigate interfaces that were imagined twenty years ago with the assumptions of people who have never made much effort to user test or challenge their interfaces. Countless hours have been wasted away trying to fit a modern frontend experience into a page layout machine. Fortunately, this is soon a thing of the past.
As a technology consultant, I had to read through pages of technical specification whenever someone thought it was time to acquire a new CMS for themselves. There were demands from which server architecture it should run on (Windows servers, of course) to their ability to render “carousels” and “being able to edit web pages in place”, despite also requesting a “modular redesign”. When editors had been allowed to contribute to these specifications, they were also often dated to the what the editors had begotten used to. They seemed not aware that they could demand better user experiences, because enterprise software has to be big, lumpy and boring.
This is partly the fault of us making these systems. We tend to communicate technology features and specifications, and less what the everyday situation working with these systems look like. Sure, for a frontend designer, something supporting GraphQL is shorthand for how conveniently she is able to work against the backend, but on a higher level, it's about the systems ability to accommodate for emerging workflows, where a content model could survive visual redesigns and design systems should be resilient to changes of its content.
Questions To Ask Of Your (S)CMS
If we are to embrace design processes, we can't know prior to solving the problem whether the user tasks are best solved by making carousels ( newsflash: most probably not ), or whether A/B-testing makes sense for your case, even though it sounds cool.
Instead, ask questions like this:
- Is it possible, and how exactly will multi-disciplinary teams work with this system?
- How easy is it to change and migrate the content model?
- How does it deal with file and image assets?
- Has the editorial interface been user tested?
- To what extent can the system be configured and customized to special workflows and needs of the editorial team?
- How easy is it to export the content in a moveable format?
- How does the system accommodate for collaboration?
- Can content models be version controlled?
- How easy is it to integrate the system with a larger ecosystem of flowing information?
The goal of these questions is to explore to what degree a content management system allows for a cross-disciplinary team to work effortlessly together, without too many bottle-necks or long deployment cycles. They also push the focus to be more about the content should be doing, and less about how things should look in a given context. Leave that for the design processes, where user testing probably will challenge assumptions one may have when looking into getting a new content system.
There are, of course, many factors in addition to this that probably have to be taken into consideration. The easiest thing to assess is the fiscal cost of software licenses and API-related costs if you are on a hosted service. The invisible cost (in time and attention spent by the team working with the system), is harder to estimate. From my experience, many of the SCMSs in combination with one of the popular frontend frameworks can significantly cut development time and allow for an agile ( there's my coin for the swear jar ) design process. With the caveat that your team is prepared to solve some of the problems that come out of the box with traditional CMSs.
Towards Structured Content
The ways we work with digital content has changed dramatically since the World Wide Web made working with interconnected documents mainstream. Organizations, businesses, and corporations have amassed gigabytes of this content, which now is stuck in rigid page hierarchies, HTML markup, and clunky user interfaces.
Using a Structured Content Management System can be a great way to free your content from a paradigm that begins to feel its age. But it isn't a trivial exercise, and success comes from being able to work multi-disciplinary and put your content model to the test. You need to get rid of some conventions you have grown used to by dealing with CMSs designed to output hierarchical websites. That means that you need to think differently about ordering content, make presentations types in order to make it easier to orchestrate content across multiple channels and to consider how you structure rich text so that it can be used outside of HTML contexts.
This article deals with some of the high-level concerns working with SCMSs. There are, of course, loads of exciting challenges when you start working with this in your team. You have to rethink stuff we've taken for granted for many years, but that's probably a good thing. Because we are forced to evaluate our content, not only from its place on a digital page but from its role in a larger system that works for whatever goals your organization and your users may have.
I believe that we can achieve content models that are more meaningful and easier to sustain in the long run, and that means saving time and expenses. It means more flexibility in terms of inventing new outputs and services, and less tie in with software vendors. Because a well-made Structured Content Management System will make it easy for you to take your content and go elsewhere. And that makes for some interesting competition. Hopefully, all in favor of the users.