
Predicción del mercado de valores mediante el aprendizaje automático [Implementación paso a paso]
Publicado: 2021-02-26Tabla de contenido
Introducción
La predicción y el análisis del mercado de valores son algunas de las tareas más complicadas de realizar. Hay varias razones para esto, como la volatilidad del mercado y tantos otros factores dependientes e independientes para decidir el valor de una acción en particular en el mercado. Estos factores hacen que sea muy difícil para cualquier analista del mercado de valores predecir el alza y la caída con altos grados de precisión.
Sin embargo, con la llegada del aprendizaje automático y sus robustos algoritmos, los últimos desarrollos de análisis de mercado y predicción del mercado de valores han comenzado a incorporar tales técnicas para comprender los datos del mercado de valores.
En resumen, muchas organizaciones utilizan ampliamente los algoritmos de aprendizaje automático para analizar y predecir valores bursátiles. Este artículo pasará por una implementación simple de análisis y predicción de valores de acciones de una tienda minorista en línea popular en todo el mundo utilizando varios algoritmos de aprendizaje automático en Python.
Planteamiento del problema
Antes de entrar en la implementación del programa para predecir los valores del mercado de valores, visualicemos los datos sobre los que trabajaremos. Aquí, analizaremos el valor de las acciones de Microsoft Corporation (MSFT) de la Asociación Nacional de Cotizaciones Automatizadas de Comerciantes de Valores (NASDAQ). Los datos del valor de las acciones se presentarán en forma de un archivo separado por comas (.csv), que se puede abrir y ver usando Excel o una hoja de cálculo.
MSFT tiene sus acciones registradas en NASDAQ y tiene sus valores actualizados durante todos los días hábiles del mercado de valores. Tenga en cuenta que el mercado no permite que se realicen transacciones los sábados y domingos; por lo tanto, hay una brecha entre las dos fechas. Para cada fecha, se anotan el valor de apertura de la acción, los valores más alto y más bajo de esa acción en los mismos días, junto con el valor de cierre al final del día.
El valor de cierre ajustado muestra el valor de la acción después de que se publiquen los dividendos (¡demasiado técnico!). Además, también se proporciona el volumen total de las acciones en el mercado. Con estos datos, depende del trabajo de un científico de datos/aprendizaje automático estudiar los datos e implementar varios algoritmos que puedan extraer patrones del historial de acciones de Microsoft Corporation. datos.

Memoria a corto plazo largo
Para desarrollar un modelo de Machine Learning para predecir los precios de las acciones de Microsoft Corporation, utilizaremos la técnica de Long Short-Term Memory (LSTM). Se utilizan para realizar pequeñas modificaciones a la información mediante multiplicaciones y sumas. Por definición, la memoria a largo plazo (LSTM) es una arquitectura de red neuronal recurrente artificial (RNN) utilizada en el aprendizaje profundo.
A diferencia de las redes neuronales de retroalimentación estándar, LSTM tiene conexiones de retroalimentación. Puede procesar puntos de datos únicos (como imágenes) y secuencias de datos completas (como voz o video). Para comprender el concepto detrás de LSTM, tomemos un ejemplo simple de una revisión de un cliente en línea de un teléfono móvil.
Supongamos que queremos comprar el Teléfono Móvil, normalmente nos remitimos a las opiniones netas de usuarios certificados. Dependiendo de sus ideas y aportes, decidimos si el móvil es bueno o malo y luego lo compramos. A medida que leemos las reseñas, buscamos palabras clave como "increíble", "buena cámara", "mejor respaldo de batería" y muchos otros términos relacionados con un teléfono móvil.
Tendemos a ignorar las palabras comunes en inglés como “it”, “gave”, “this”, etc. Así, cuando decidimos comprar el teléfono móvil o no, solo recordamos estas palabras clave definidas anteriormente. Lo más probable es que nos olvidemos de las otras palabras.
Esta es la misma forma en que funciona el Algoritmo de Memoria a Largo Corto Plazo. Solo recuerda la información relevante y la usa para hacer predicciones ignorando los datos no relevantes. De esta manera, tenemos que construir un modelo LSTM que esencialmente reconozca solo los datos esenciales sobre ese stock y omita sus valores atípicos.
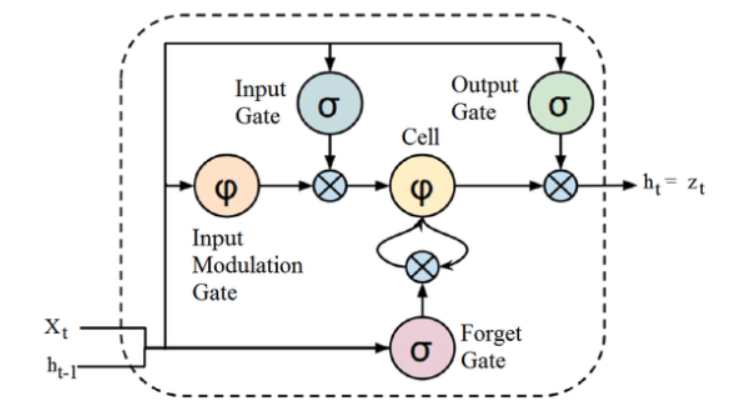
Fuente
Aunque la estructura anterior de una arquitectura LSTM puede parecer intrigante al principio, es suficiente recordar que LSTM es una versión avanzada de redes neuronales recurrentes que retiene la memoria para procesar secuencias de datos. Puede eliminar o agregar información al estado de la celda, cuidadosamente regulada por estructuras llamadas puertas.
La unidad LSTM consta de una celda, una puerta de entrada, una puerta de salida y una puerta de olvido. La celda recuerda valores en intervalos de tiempo arbitrarios, y las tres puertas regulan el flujo de información dentro y fuera de la celda.
Implementación de programa
Pasaremos a la parte donde usamos el LSTM para predecir el valor de las acciones usando Machine Learning en Python.
Paso 1: importar las bibliotecas
Como todos sabemos, el primer paso es importar las bibliotecas que son necesarias para preprocesar los datos de stock de Microsoft Corporation y las demás bibliotecas necesarias para crear y visualizar los resultados del modelo LSTM. Para ello, utilizaremos la librería Keras bajo el framework TensorFlow. Los módulos requeridos se importan de la biblioteca de Keras individualmente.
#Importación de las bibliotecas
importar pandas como PD
importar NumPy como np
% matplotlib en línea
importar matplotlib. pyplot como plt
importar matplotlib
de sklearn. Importación de preprocesamiento MinMaxScaler
de Keras. capas importar LSTM, Dense, Dropout
desde sklearn.model_selection importar TimeSeriesSplit
de sklearn.metrics importar mean_squared_error, r2_score
importar matplotlib. fechas como mandatos
de sklearn. Importación de preprocesamiento MinMaxScaler
de sklearn importar modelo_lineal
de Keras. Importación de modelos Secuencial
de Keras. Importación de capas Densa
Importar Keras. Back-end como K
de Keras. Importación de devoluciones de llamada EarlyStopping
de Keras. Los optimizadores importan Adam
de Keras. Importación de modelos load_model
de Keras. Importación de capas LSTM
de Keras. utils.vis_utils importar plot_model
Paso 2: conseguir visualizar los datos
Con la biblioteca del lector de datos de Pandas, cargaremos los datos de stock del sistema local como un archivo de valores separados por comas (.csv) y los almacenaremos en un marco de datos de pandas. Finalmente, también veremos los datos.
#Obtener el conjunto de datos
df = pd.read_csv(“MicrosoftStockData.csv”,na_values=['null'],index_col='Date',parse_dates=True,infer_datetime_format=True)
df.cabeza()
Obtenga la certificación de IA en línea de las mejores universidades del mundo: maestrías, programas ejecutivos de posgrado y programa de certificado avanzado en ML e IA para acelerar su carrera.
Paso 3: imprima la forma del marco de datos y verifique los valores nulos.
En este otro paso crucial, primero imprimimos la forma del conjunto de datos. Para asegurarnos de que no haya valores nulos en el marco de datos, los verificamos. La presencia de valores nulos en el conjunto de datos tiende a causar problemas durante el entrenamiento, ya que actúan como valores atípicos que provocan una gran variación en el proceso de entrenamiento.
#Imprimir forma de marco de datos y verificar valores nulos
imprimir ("Forma de marco de datos:", df. forma)
print(“Valor nulo presente: “, df.IsNull().values.any())
>> Forma de marco de datos: (7334, 6)
>>Valor nulo presente: Falso
| Fecha | Abierto | Elevado | Bajo | Cerrar | cerrar | Volumen |
| 1990-01-02 | 0.605903 | 0.616319 | 0.598090 | 0.616319 | 0.447268 | 53033600 |
| 1990-01-03 | 0.621528 | 0.626736 | 0.614583 | 0.619792 | 0.449788 | 113772800 |
| 1990-01-04 | 0.619792 | 0.638889 | 0.616319 | 0.638021 | 0.463017 | 125740800 |
| 1990-01-05 | 0.635417 | 0.638889 | 0.621528 | 0.622396 | 0.451678 | 69564800 |
| 1990-01-08 | 0.621528 | 0.631944 | 0.614583 | 0.631944 | 0.458607 | 58982400 |
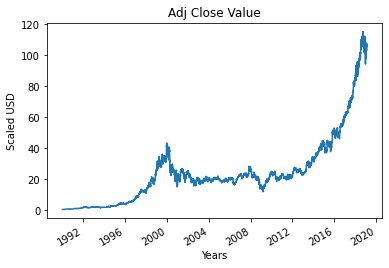
Paso 4: Trazar el verdadero valor de cierre ajustado
El valor de salida final que se va a predecir con el modelo de aprendizaje automático es el valor de cierre ajustado. Este valor representa el valor de cierre de la acción en ese día particular de negociación en el mercado de valores.
#Trazar el verdadero valor de cierre ajustado
df['Adj Cerrar'].plot()
Paso 5: configuración de la variable objetivo y selección de las características
En el siguiente paso, asignamos la columna de salida a la variable de destino. En este caso, es el valor relativo ajustado de las acciones de Microsoft. Además, también seleccionamos las características que actúan como variable independiente de la variable objetivo (variable dependiente). Para dar cuenta del propósito de la capacitación, elegimos cuatro características, que son:

- Abierto
- Elevado
- Bajo
- Volumen
#Establecer variable objetivo
output_var = PD.DataFrame(df['Adj Cerrar'])
#Selección de las funciones
características = ['Abierto', 'Alto', 'Bajo', 'Volumen']
Paso 6 – Escalado
Para reducir el costo computacional de los datos en la tabla, reduciremos los valores de stock a valores entre 0 y 1. De esta manera, todos los datos en grandes cantidades se reducen, lo que reduce el uso de memoria. Además, podemos obtener más precisión al reducir la escala, ya que los datos no se distribuyen en valores tremendos. Esto lo realiza la clase MinMaxScaler de la biblioteca sci-kit-learn.
#Escalada
escalador = MinMaxScaler()
feature_transform = scaler.fit_transform(df[características])
feature_transform= pd.DataFrame(columnas=características, data=feature_transform, index=df.index)
función_transformar.cabeza()
| Fecha | Abierto | Elevado | Bajo | Volumen |
| 1990-01-02 | 0.000129 | 0.000105 | 0.000129 | 0.064837 |
| 1990-01-03 | 0.000265 | 0.000195 | 0.000273 | 0.144673 |
| 1990-01-04 | 0.000249 | 0.000300 | 0.000288 | 0.160404 |
| 1990-01-05 | 0.000386 | 0.000300 | 0.000334 | 0.086566 |
| 1990-01-08 | 0.000265 | 0.000240 | 0.000273 | 0.072656 |
Como se mencionó anteriormente, vemos que los valores de las variables de características se reducen a valores más pequeños en comparación con los valores reales dados anteriormente.
Paso 7: división en un conjunto de entrenamiento y un conjunto de prueba.
Antes de introducir los datos en el modelo de entrenamiento, debemos dividir todo el conjunto de datos en un conjunto de entrenamiento y otro de prueba. El modelo Machine Learning LSTM se entrenará con los datos presentes en el conjunto de entrenamiento y se probará en el conjunto de prueba para determinar la precisión y la retropropagación.
Para ello, utilizaremos la clase TimeSeriesSplit de la biblioteca sci-kit-learn. Establecemos el número de divisiones en 10, lo que indica que el 10 % de los datos se usará como conjunto de prueba y el 90 % de los datos se usará para entrenar el modelo LSTM. La ventaja de usar esta división de series temporales es que las muestras de datos de series temporales divididas se observan en intervalos de tiempo fijos.
#Dividir en conjunto de entrenamiento y conjunto de prueba
timesplit= TimeSeriesSplit(n_splits=10)
para train_index, test_index en timesplit.split(feature_transform):
Tren_X, Prueba_X = transformación_característica[:len(índice_tren)], transformación_característica[len(índice_tren): (len(índice_tren)+len(índice_prueba))]
y_train, y_test = output_var[:len(train_index)].values.ravel(), output_var[len(train_index): (len(train_index)+len(test_index))].values.ravel()
Paso 8: procesamiento de datos para LSTM
Una vez que los conjuntos de entrenamiento y prueba estén listos, podemos introducir los datos en el modelo LSTM una vez que esté construido. Antes de eso, necesitamos convertir los datos del conjunto de prueba y entrenamiento en un tipo de datos que acepte el modelo LSTM. Primero convertimos los datos de entrenamiento y los datos de prueba en matrices NumPy y luego los remodelamos al formato (Número de muestras, 1, Número de características) ya que el LSTM requiere que los datos se alimenten en forma 3D. Como sabemos, el número de muestras en el conjunto de entrenamiento es el 90 % de 7334, que es 6667, y el número de características es 4, el conjunto de entrenamiento se reforma a (6667, 1, 4). De manera similar, el conjunto de prueba también se remodela.
#Procesar los datos para LSTM
trenX =np.array(X_tren)
testX =np.array(X_test)
Tren_X = trenX.reforma(tren_X.forma[0], 1, tren_X.forma[1])
X_test = testX.reshape(X_test.shape[0], 1, X_test.shape[1])
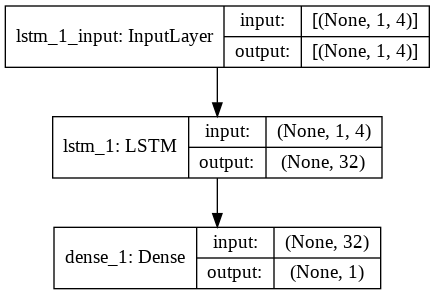
Paso 9: construcción del modelo LSTM
Finalmente, llegamos a la etapa donde construimos el Modelo LSTM. Aquí, creamos un modelo Sequential Keras con una capa LSTM. La capa LSTM tiene 32 unidades y le sigue una capa densa de 1 neurona.
Utilizamos Adam Optimizer y Mean Squared Error como la función de pérdida para compilar el modelo. Estos dos son la combinación más preferida para un modelo LSTM. Además, el modelo también se traza y se muestra a continuación.
#Construyendo el modelo LSTM
lstm = Secuencial()
lstm.add(LSTM(32, input_shape=(1, trainX.shape[1]), activación='relu', return_sequences=False))
lstm.add(Denso(1))
lstm.compile(pérdida='error_cuadrado_medio', optimizador='adam')
plot_model(lstm, show_shapes=Verdadero, show_layer_names=Verdadero)
Paso 10: entrenar el modelo
Finalmente, entrenamos el modelo LSTM diseñado anteriormente en los datos de entrenamiento para 100 épocas con un tamaño de lote de 8 usando la función de ajuste.
#Entrenamiento de modelos
history = lstm.fit(X_train, y_train, epochs=100, batch_size=8, detallado=1, shuffle=False)
Época 1/100
834/834 [==============================] – 3 s 2 ms/paso – pérdida: 67,1211
Época 2/100
834/834 [==============================] – 1 s 2 ms/paso – pérdida: 70,4911
Época 3/100
834/834 [==============================] – 1 s 2 ms/paso – pérdida: 48,8155
Época 4/100
834/834 [==============================] – 1 s 2 ms/paso – pérdida: 21,5447
Época 5/100
834/834 [==============================] – 1 s 2 ms/paso – pérdida: 6,1709
Época 6/100
834/834 [==============================] – 1 s 2 ms/paso – pérdida: 1,8726
Época 7/100
834/834 [==============================] – 1 s 2 ms/paso – pérdida: 0,9380
Época 8/100
834/834 [==============================] – 2s 2ms/paso – pérdida: 0,6566
Época 9/100
834/834 [==============================] – 1 s 2 ms/paso – pérdida: 0,5369
Época 10/100
834/834 [==============================] – 2s 2ms/paso – pérdida: 0,4761
.
.
.
.
Época 95/100
834/834 [==============================] – 1 s 2 ms/paso – pérdida: 0,4542
Época 96/100
834/834 [==============================] – 2s 2ms/paso – pérdida: 0,4553
Época 97/100
834/834 [==============================] – 1 s 2 ms/paso – pérdida: 0,4565
Época 98/100
834/834 [==============================] – 1 s 2 ms/paso – pérdida: 0,4576
Época 99/100
834/834 [==============================] – 1 s 2 ms/paso – pérdida: 0,4588
Época 100/100
834/834 [==============================] – 1 s 2 ms/paso – pérdida: 0,4599
Finalmente, vemos que el valor de pérdida ha disminuido exponencialmente con el tiempo durante el proceso de entrenamiento de 100 épocas y ha alcanzado un valor de 0.4599
Paso 11 – Predicción LSTM
Con nuestro modelo listo, es hora de usar el modelo entrenado con la red LSTM en el conjunto de prueba y predecir el valor de cierre adyacente de las acciones de Microsoft. Esto se realiza utilizando la función simple de predecir en el modelo lstm construido.
Predicción #LSTM
y_pred= lstm.predict(X_test)
Paso 12 – Valor de cierre ajustado real vs. predicho – LSTM
Finalmente, como hemos predicho los valores del conjunto de prueba, podemos trazar el gráfico para comparar los valores verdaderos de Adj Close y el valor predicho de Adj Close por el modelo de aprendizaje automático LSTM.
#Valor de cierre ajustado real vs. predicho – LSTM
plt.plot(y_test, label='Valor verdadero')
plt.plot(y_pred, label='Valor LSTM')
plt.title ("Predicción por LSTM")
plt.xlabel('Escala de tiempo')
plt.ylabel('USD escalado')
plt.leyenda()
plt.mostrar()
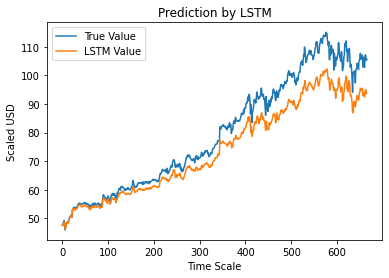
El gráfico anterior muestra que el modelo de red LSTM simple muy básico que se creó anteriormente detecta algún patrón. Al ajustar varios parámetros y agregar más capas LSTM al modelo, podemos lograr una representación más precisa del valor de las acciones de cualquier empresa.
Conclusión
Si está interesado en obtener más información sobre ejemplos de inteligencia artificial, aprendizaje automático, consulte el Programa PG Ejecutivo en Aprendizaje Automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, estado de exalumno de IIIT-B, más de 5 proyectos prácticos finales prácticos y asistencia laboral con las mejores empresas.
¿Puedes predecir el mercado de valores usando el aprendizaje automático?
Hoy en día, tenemos una serie de indicadores para ayudar a predecir las tendencias del mercado. Sin embargo, no tenemos que mirar más allá de una computadora de alta potencia para encontrar los indicadores más precisos para el mercado de valores. El mercado de valores es un sistema abierto y puede verse como una red compleja. La red está formada por las relaciones entre las acciones, las empresas, los inversores y los volúmenes comerciales. Mediante el uso de un algoritmo de minería de datos como la máquina de vectores de soporte, puede aplicar una fórmula matemática para extraer las relaciones entre estas variables. El mercado de valores ahora está más allá de la predicción humana.
¿Qué algoritmo es mejor para la predicción del mercado de valores?
Para obtener los mejores resultados, debe utilizar la regresión lineal. La regresión lineal es un enfoque estadístico que se utiliza para determinar la relación entre dos variables diferentes. En este ejemplo, las variables son precio y tiempo. En la predicción del mercado de valores, el precio es la variable independiente y el tiempo es la variable dependiente. Si se puede determinar una relación lineal entre estas dos variables, entonces es posible predecir con precisión el valor de la acción en cualquier momento en el futuro.
¿Es la predicción del mercado de valores un problema de clasificación o regresión?
Antes de responder, debemos entender qué significan las predicciones del mercado de valores. ¿Es un problema de clasificación binaria o un problema de regresión? Supongamos que queremos predecir el futuro de una acción, donde futuro significa el próximo día, semana, mes o año. Si el desempeño pasado de la acción en algún momento es la entrada y el futuro es la salida, entonces es un problema de regresión. Si el desempeño pasado de una acción y el futuro de una acción son independientes, entonces es un problema de clasificación.