
Uso de SSE en lugar de WebSockets para el flujo de datos unidireccional a través de HTTP/2
Publicado: 2022-03-10Al crear una aplicación web, se debe considerar qué tipo de mecanismo de entrega se va a utilizar. Digamos que tenemos una aplicación multiplataforma que funciona con datos en tiempo real; una aplicación del mercado de valores que proporciona la capacidad de comprar o vender acciones en tiempo real. Esta aplicación se compone de widgets que aportan valor diferente a los diferentes usuarios.
Cuando se trata de la entrega de datos del servidor al cliente, estamos limitados a dos enfoques generales: extracción del cliente o inserción del servidor . Como ejemplo simple con cualquier aplicación web, el cliente es el navegador web. Cuando el sitio web en su navegador solicita datos al servidor, esto se denomina extracción del cliente . Por el contrario, cuando el servidor envía actualizaciones a su sitio web de manera proactiva, se denomina servidor push .
Hoy en día, hay algunas maneras de implementarlos:
- Sondeo largo/corto (extracción del cliente)
- WebSockets (inserción del servidor)
- Eventos enviados por el servidor (servidor push).
Vamos a analizar en profundidad las tres alternativas una vez que hayamos establecido los requisitos para nuestro caso de negocios.
El caso de negocios
Para poder entregar nuevos widgets para nuestra aplicación del mercado de valores rápidamente y conectarlos y usarlos sin volver a implementar toda la plataforma, necesitamos que sean autónomos y administren su propia E/S de datos. Los widgets no están acoplados entre sí de ninguna manera. En el caso ideal, todos ellos se suscribirán a algún punto final de API y comenzarán a obtener datos de él. Además de un tiempo de comercialización más rápido de nuevas funciones, este enfoque nos brinda la capacidad de exportar contenido a sitios web de terceros, mientras que nuestros widgets brindan todo lo que necesitan por sí mismos.
El escollo principal aquí es que la cantidad de conexiones crecerá linealmente con la cantidad de widgets que tengamos y alcanzaremos el límite de los navegadores para la cantidad de solicitudes HTTP manejadas a la vez.
Los datos que van a recibir nuestros widgets se componen principalmente de números y actualizaciones de sus números: la respuesta inicial contiene diez acciones con algunos valores de mercado para ellas. Esto incluye actualizaciones de agregar/eliminar acciones y actualizaciones de los valores de mercado de las que se presentan actualmente. Transferimos pequeñas cantidades de cadenas JSON para cada actualización lo más rápido posible.
HTTP/2 proporciona la multiplexación de las solicitudes que provienen del mismo dominio, lo que significa que solo podemos obtener una conexión para múltiples respuestas. Esto parece que podría resolver nuestro problema. Comenzamos explorando las diferentes opciones para obtener los datos y ver qué podemos sacar de ellos.
- Vamos a utilizar NGINX para el equilibrio de carga y el proxy para ocultar todos nuestros puntos finales detrás del mismo dominio. Esto nos permitirá utilizar la multiplexación HTTP/2 lista para usar.
- Queremos usar la red y la batería de los dispositivos móviles de manera eficiente.
Las alternativas
Sondeo largo

Client pull es la implementación de software equivalente al molesto niño sentado en el asiento trasero de su automóvil que pregunta constantemente: "¿Ya llegamos?" En resumen, el cliente solicita datos al servidor. El servidor no tiene datos y espera un tiempo antes de enviar la respuesta:
- Si aparece algo durante la espera, el servidor lo envía y cierra la solicitud;
- Si no hay nada que enviar y se alcanza el tiempo máximo de espera, el servidor envía una respuesta de que no hay datos;
- En ambos casos, el cliente abre la siguiente solicitud de datos;
- Hacer espuma, enjuagar, repetir.
Las llamadas AJAX funcionan en el protocolo HTTP, lo que significa que las solicitudes al mismo dominio deben multiplexarse de forma predeterminada. Sin embargo, nos encontramos con múltiples problemas al tratar de hacer que eso funcione según lo requerido. Algunas de las trampas que identificamos con nuestro enfoque de widgets:
Encabezados generales
Cada solicitud y respuesta de sondeo es un mensaje HTTP completo y contiene un conjunto completo de encabezados HTTP en el marco del mensaje. En nuestro caso donde tenemos pequeños mensajes frecuentes, los encabezados en realidad representan el mayor porcentaje de los datos transmitidos. La carga útil real es mucho menor que el total de bytes transmitidos (por ejemplo, 15 KB de encabezados por 5 KB de datos).Latencia máxima
Después de que el servidor responde, ya no puede enviar datos al cliente hasta que el cliente envíe la siguiente solicitud. Mientras que la latencia promedio para un sondeo largo está cerca de un tránsito de red, la latencia máxima es de tres tránsitos de red: respuesta, solicitud, respuesta. Sin embargo, debido a la pérdida y retransmisión de paquetes, la latencia máxima para cualquier protocolo TCP/IP será de más de tres tránsitos de red (evitable con la canalización HTTP). Si bien en la conexión LAN directa esto no es un gran problema, se convierte en uno mientras uno está en movimiento y cambiando las celdas de la red. Hasta cierto punto, esto se observa con SSE y WebSockets, pero el efecto es mayor con el sondeo.Establecimiento de conexión
Aunque se puede evitar mediante el uso de una conexión HTTP persistente reutilizable para muchas solicitudes de sondeo, es complicado programar en consecuencia todos sus componentes para sondear en periodos de tiempo breves para mantener viva la conexión. Eventualmente, dependiendo de las respuestas del servidor, sus encuestas se desincronizarán.Degradación del rendimiento
Un cliente (o servidor) de sondeo largo que está bajo carga tiene una tendencia natural a degradar el rendimiento a costa de la latencia del mensaje. Cuando eso sucede, los eventos que se envían al cliente se pondrán en cola. Esto realmente depende de la implementación; en nuestro caso, necesitamos agregar todos los datos a medida que enviamos eventos de agregar/eliminar/actualizar a nuestros widgets.Tiempos de espera
Las solicitudes de sondeo largas deben permanecer pendientes hasta que el servidor tenga algo que enviar al cliente. Esto puede hacer que el servidor proxy cierre la conexión si permanece inactiva durante demasiado tiempo.multiplexación
Esto puede suceder si las respuestas ocurren al mismo tiempo a través de una conexión HTTP/2 persistente. Esto puede ser complicado de hacer, ya que las respuestas de los sondeos no pueden estar realmente sincronizadas.
Puede encontrar más información sobre problemas del mundo real que uno podría experimentar con encuestas largas aquí .
WebSockets

Como primer ejemplo del método de inserción del servidor , vamos a ver WebSockets.
Vía MDN:
WebSockets es una tecnología avanzada que permite abrir una sesión de comunicación interactiva entre el navegador del usuario y un servidor. Con esta API, puede enviar mensajes a un servidor y recibir respuestas basadas en eventos sin tener que sondear el servidor para obtener una respuesta.
Este es un protocolo de comunicaciones que proporciona canales de comunicación full-duplex a través de una única conexión TCP.
Tanto HTTP como WebSockets están ubicados en la capa de aplicación del modelo OSI y, como tales, dependen de TCP en la capa 4.
- Solicitud
- Presentación
- Sesión
- Transporte
- La red
- Enlace de datos
- Físico
RFC 6455 establece que WebSocket "está diseñado para funcionar en los puertos HTTP 80 y 443, así como para admitir servidores proxy e intermediarios HTTP", lo que lo hace compatible con el protocolo HTTP. Para lograr la compatibilidad, el protocolo de enlace WebSocket utiliza el encabezado de actualización HTTP para cambiar del protocolo HTTP al protocolo WebSocket.
También hay un artículo muy bueno que explica todo lo que necesita saber sobre WebSockets en Wikipedia. Os animo a leerlo.
Después de establecer que los enchufes realmente podrían funcionar para nosotros, comenzamos a explorar sus capacidades en nuestro caso de negocios y golpeamos pared tras pared tras pared.
Servidores proxy : en general, hay algunos problemas diferentes con WebSockets y proxies:
- El primero está relacionado con los proveedores de servicios de Internet y la forma en que manejan sus redes. Problemas con los puertos bloqueados de los proxies de radio, etc.
- El segundo tipo de problemas está relacionado con la forma en que el proxy está configurado para manejar el tráfico HTTP no seguro y las conexiones de larga duración (el impacto se reduce con HTTPS).
- El tercer problema “con WebSockets, se ve obligado a ejecutar proxies TCP en lugar de proxies HTTP. Los proxies TCP no pueden inyectar encabezados, reescribir URL o realizar muchas de las funciones que tradicionalmente dejamos que nuestros proxies HTTP se ocupen”.
Un número de conexiones : el famoso límite de conexión para solicitudes HTTP que gira en torno al número 6, no se aplica a los WebSockets. 50 enchufes = 50 conexiones. Diez pestañas del navegador por 50 sockets = 500 conexiones y así sucesivamente. Dado que WebSocket es un protocolo diferente para la entrega de datos, no se multiplexa automáticamente a través de conexiones HTTP/2 (realmente no se ejecuta sobre HTTP). La implementación de multiplexación personalizada tanto en el servidor como en el cliente es demasiado complicada para que los sockets sean útiles en el caso comercial especificado. Además, esto acopla nuestros widgets a nuestra plataforma, ya que necesitarán algún tipo de API en el cliente para suscribirse y no podemos distribuirlos sin ella.
Equilibrio de carga (sin multiplexación) : si cada usuario abre un número
nde sockets, el equilibrio de carga adecuado es muy complicado. Cuando sus servidores se sobrecargan y necesita crear nuevas instancias y terminar las antiguas según la implementación de su software, las acciones que se toman para "reconectarse" pueden desencadenar una cadena masiva de actualizaciones y nuevas solicitudes de datos que sobrecargarán su sistema. . Los WebSockets deben mantenerse tanto en el servidor como en el cliente. No es posible mover conexiones de socket a un servidor diferente si el actual experimenta una carga alta. Deben ser cerrados y reabiertos.DoS : esto generalmente lo manejan los proxies HTTP front-end que no pueden manejar los proxies TCP que se necesitan para los WebSockets. Uno puede conectarse al socket y comienza a inundar sus servidores con datos. Los WebSockets lo dejan vulnerable a este tipo de ataques.
Reinventar la rueda : con WebSockets, uno debe manejar muchos problemas que se resuelven en HTTP por sí solos.
Puede leer más sobre problemas del mundo real con WebSockets aquí.
Algunos buenos casos de uso de WebSockets son los chats y los juegos de varios jugadores en los que los beneficios superan los problemas de implementación. Dado que su principal beneficio es la comunicación dúplex, y nosotros realmente no lo necesitamos, debemos seguir adelante.
Impacto
Obtenemos mayores gastos generales operativos en términos de desarrollo, prueba y escalado; el software y su infraestructura de TI con ambos: sondeo y WebSockets.
Tenemos el mismo problema en dispositivos móviles y redes con ambos. El diseño de hardware de estos dispositivos mantiene una conexión abierta al mantener viva la antena y la conexión a la red celular. Esto conduce a una duración reducida de la batería, calor y, en algunos casos, cargos adicionales por datos.
Pero, ¿por qué seguimos teniendo problemas con los dispositivos móviles?
Consideremos cómo se conecta a Internet el dispositivo móvil predeterminado:
Una explicación sencilla de cómo funciona la red móvil: por lo general, los dispositivos móviles tienen una antena de baja potencia que puede recibir datos de una celda. De esta forma, una vez que el dispositivo recibe datos de una llamada entrante, inicia la antena full-duplex para establecer la llamada. La misma antena se utiliza cada vez que desea realizar una llamada o acceder a Internet (si no hay WiFi disponible). La antena full-duplex necesita establecer una conexión a la red celular y realizar alguna autenticación. Una vez que se establece la conexión, existe cierta comunicación entre su dispositivo y el celular para poder hacer nuestra solicitud de red. Somos redirigidos al proxy interno del proveedor de servicios móviles que maneja las solicitudes de Internet. A partir de ahí, el procedimiento ya es conocido: pregunta a un DNS dónde está realmente www.domainname.ext , recibe la URI del recurso y, finalmente, es redirigido a él.
Este proceso, como puedes imaginar, consume bastante energía de la batería. Esta es la razón por la que los proveedores de teléfonos móviles ofrecen un tiempo de espera de unos pocos días y un tiempo de conversación de solo un par de horas.
Sin WiFi, tanto los WebSockets como el sondeo requieren que la antena full-duplex funcione casi constantemente. Por lo tanto, enfrentamos un mayor consumo de datos y un mayor consumo de energía, y dependiendo del dispositivo, también calor.
Para cuando las cosas parezcan sombrías, parece que tendremos que reconsiderar los requisitos comerciales para nuestra aplicación. ¿Nos estamos perdiendo algo?

SSE
Vía MDN:
“La interfaz EventSource se utiliza para recibir eventos enviados por el servidor. Se conecta a un servidor a través de HTTP y recibe eventos en formato de flujo de eventos/texto sin cerrar la conexión”.
La principal diferencia con el sondeo es que solo obtenemos una conexión y mantenemos un flujo de eventos a través de ella. El sondeo largo crea una nueva conexión para cada extracción: ergo, los encabezados generales y otros problemas que enfrentamos allí.
A través de html5doctor.com:
Los eventos enviados por el servidor son eventos en tiempo real emitidos por el servidor y recibidos por el navegador. Son similares a WebSockets en que ocurren en tiempo real, pero son en gran medida un método de comunicación unidireccional desde el servidor.
Parece un poco extraño, pero después de considerarlo, nuestro principal flujo de datos es del servidor al cliente y, en muchas menos ocasiones, del cliente al servidor.
Parece que podemos usar esto para nuestro principal caso comercial de entrega de datos. Podemos resolver las compras de los clientes enviando una nueva solicitud ya que el protocolo es unidireccional y el cliente no puede enviar mensajes al servidor a través de él. Eventualmente, esto tendrá el tiempo de demora de la antena full-duplex para arrancar en los dispositivos móviles. Sin embargo, podemos vivir con que suceda de vez en cuando; después de todo, este retraso se mide en milisegundos.
Características unicas
- El flujo de conexión proviene del servidor y es de solo lectura.
- Usan solicitudes HTTP regulares para la conexión persistente, no un protocolo especial. Obtener multiplexación a través de HTTP/2 fuera de la caja.
- Si la conexión se interrumpe, EventSource activa un evento de error e intenta volver a conectarse automáticamente. El servidor también puede controlar el tiempo de espera antes de que el cliente intente volver a conectarse (se explica con más detalles más adelante).
- Los clientes pueden enviar una identificación única con mensajes. Cuando un cliente intenta volver a conectarse después de una conexión interrumpida, enviará la última identificación conocida. Luego, el servidor puede ver que el cliente perdió
ncantidad de mensajes y envía la acumulación de mensajes perdidos al volver a conectarse.
Ejemplo de implementación del cliente
Estos eventos son similares a los eventos ordinarios de JavaScript que ocurren en el navegador, como los eventos de clic, excepto que podemos controlar el nombre del evento y los datos asociados con él.
Veamos la vista previa del código simple para el lado del cliente:
// subscribe for messages var source = new EventSource('URL'); // handle messages source.onmessage = function(event) { // Do something with the data: event.data; };Lo que vemos en el ejemplo es que el lado del cliente es bastante simple. Se conecta a nuestra fuente y espera a recibir mensajes.
Para permitir que los servidores envíen datos a las páginas web a través de HTTP o utilizando protocolos de inserción de servidor dedicados, la especificación introduce la interfaz 'EventSource' en el cliente. El uso de esta API consiste en crear un objeto `EventSource` y registrar un detector de eventos.
La implementación del cliente para WebSockets se parece mucho a esto. La complejidad de los sockets radica en la infraestructura de TI y la implementación del servidor.
EventSource
Cada objeto EventSource tiene los siguientes miembros:
- URL: establecido durante la construcción.
- Solicitud: inicialmente es nula.
- Tiempo de reconexión: valor en ms (valor definido por el agente de usuario).
- ID del último evento: inicialmente una cadena vacía.
- Ready state: estado de la conexión.
- CONECTANDO (0)
- ABIERTO (1)
- CERRADO (2)
Aparte de la URL, todos se tratan como privados y no se puede acceder a ellos desde el exterior.
Eventos integrados:
- Abierto
- Mensaje
- Error
Manejo de caídas de conexión
El navegador restablece automáticamente la conexión si se cae. El servidor puede enviar un tiempo de espera para reintentar o cerrar la conexión de forma permanente. En tal caso, el navegador cumplirá con intentar volver a conectarse después del tiempo de espera o no intentarlo en absoluto si la conexión recibe un mensaje de finalización. Parece bastante simple, y en realidad lo es.
Ejemplo de implementación del servidor
Bueno, si el cliente es así de simple, ¿tal vez la implementación del servidor sea compleja?
Bueno, el controlador del servidor para SSE puede verse así:
function handler(response) { // setup headers for the response in order to get the persistent HTTP connection response.writeHead(200, { 'Content-Type': 'text/event-stream', 'Cache-Control': 'no-cache', 'Connection': 'keep-alive' }); // compose the message response.write('id: UniqueID\n'); response.write("data: " + data + '\n\n'); // whenever you send two new line characters the message is sent automatically }Definimos una función que va a manejar la respuesta:
- Encabezados de configuración
- Crear un mensaje
- Enviar
Tenga en cuenta que no ve una llamada al método send() o push() . Esto se debe a que el estándar define que el mensaje se enviará tan pronto como reciba dos \n\n caracteres como en el ejemplo: response.write("data: " + data + '\n\n'); . Esto enviará inmediatamente el mensaje al cliente. Tenga en cuenta que los data deben ser una cadena con escape y no tienen caracteres de nueva línea al final.
Construcción de mensajes
Como se mencionó anteriormente, el mensaje puede contener algunas propiedades:
- IDENTIFICACIÓN
Si el valor del campo no contiene U+0000 NULL, establezca el último búfer de ID de evento en el valor del campo. De lo contrario, ignore el campo. - Datos
Agregue el valor del campo al búfer de datos, luego agregue un solo carácter U+000A LINE FEED (LF) al búfer de datos. - Evento
Establezca el búfer de tipo de evento en el valor del campo. Esto lleva a queevent.typeobtenga su nombre de evento personalizado. - Rever
Si el valor del campo consta solo de dígitos ASCII, interprete el valor del campo como un número entero en base diez y establezca el tiempo de reconexión del flujo de eventos en ese número entero. De lo contrario, ignore el campo.
Cualquier otra cosa será ignorada. No podemos introducir nuestros propios campos.
Ejemplo con event agregado:
response.write('id: UniqueID\n'); response.write('event: add\n'); response.write('retry: 10000\n'); response.write("data: " + data + '\n\n'); Luego, en el cliente, esto se maneja con addEventListener como tal:
source.addEventListener("add", function(event) { // do stuff with data event.data; });Puede enviar varios mensajes separados por una nueva línea siempre que proporcione ID diferentes.
... id: 54 event: add data: "[{SOME JSON DATA}]" id: 55 event: remove data: JSON.stringify(some_data) id: 56 event: remove data: { data: "msg" : "JSON data"\n data: "field": "value"\n data: "field2": "value2"\n data: }\n\n ...Esto simplifica enormemente lo que podemos hacer con nuestros datos.
Requisitos específicos del servidor
Durante nuestra POC para el back-end, identificamos que tiene algunos detalles que deben abordarse para tener una implementación funcional de SSE. En el mejor de los casos, utilizará un servidor basado en bucle de eventos como NodeJS, Kestrel o Twisted. La idea es que con la solución basada en subprocesos tendrá un subproceso por conexión → 1000 conexiones = 1000 subprocesos. Con la solución de bucle de eventos, tendrá un hilo para 1000 conexiones.
- Solo puede aceptar solicitudes de EventSource si la solicitud HTTP dice que puede aceptar el tipo MIME de flujo de eventos;
- Debe mantener una lista de todos los usuarios conectados para poder emitir nuevos eventos;
- Debe escuchar las conexiones interrumpidas y eliminarlas de la lista de usuarios conectados;
- Opcionalmente, debe mantener un historial de mensajes para que los clientes que se vuelvan a conectar puedan ponerse al día con los mensajes perdidos.
Funciona como se esperaba y parece mágico al principio. Conseguimos todo lo que queremos para que nuestra aplicación funcione de manera eficiente. Al igual que con todas las cosas que parecen demasiado buenas para ser verdad, a veces nos enfrentamos a algunos problemas que deben abordarse. Sin embargo, no son complicados de implementar o andar por ahí:
Se sabe que los servidores proxy heredados, en ciertos casos, abandonan las conexiones HTTP después de un breve tiempo de espera. Para protegerse contra dichos servidores proxy, los autores pueden incluir una línea de comentario (una que comience con un carácter ':') cada 15 segundos más o menos.
Los autores que deseen relacionar conexiones de orígenes de eventos entre sí o con documentos específicos presentados anteriormente pueden encontrar que depender de las direcciones IP no funciona, ya que los clientes individuales pueden tener varias direcciones IP (debido a que tienen varios servidores proxy) y las direcciones IP individuales pueden tener múltiples clientes (debido a compartir un servidor proxy). Es mejor incluir un identificador único en el documento cuando se sirve y luego pasar ese identificador como parte de la URL cuando se establece la conexión.
También se advierte a los autores que la fragmentación de HTTP puede tener efectos negativos inesperados en la confiabilidad de este protocolo, en particular, si la fragmentación la realiza una capa diferente que desconoce los requisitos de tiempo. Si esto es un problema, la fragmentación se puede deshabilitar para servir flujos de eventos.
Los clientes que admiten la limitación de conexión por servidor de HTTP pueden tener problemas al abrir varias páginas de un sitio si cada página tiene un EventSource en el mismo dominio. Los autores pueden evitar esto usando el mecanismo relativamente complejo de usar nombres de dominio únicos por conexión, o permitiendo que el usuario habilite o deshabilite la funcionalidad EventSource por página, o compartiendo un solo objeto EventSource usando un trabajador compartido.
Soporte de navegador y Polyfills: Edge se está quedando atrás con respecto a esta implementación, pero hay un polyfill disponible que puede salvarlo. Sin embargo, el caso más importante para SSE se presenta para dispositivos móviles donde IE/Edge no tienen una participación de mercado viable.
Algunos de los polyfills disponibles:
- yaffle
- amvtek
- Remy
Empuje sin conexión y otras características
Los agentes de usuario que se ejecutan en entornos controlados, por ejemplo, navegadores en teléfonos móviles vinculados a operadores específicos, pueden descargar la gestión de la conexión a un proxy en la red. En tal situación, se considera que el agente de usuario para fines de conformidad incluye tanto el software del teléfono como el proxy de la red.
Por ejemplo, un navegador en un dispositivo móvil, después de haber establecido una conexión, podría detectar que está en una red compatible y solicitar que un servidor proxy en la red se haga cargo de la administración de la conexión. La línea de tiempo para tal situación podría ser la siguiente:
- El navegador se conecta a un servidor HTTP remoto y solicita el recurso especificado por el autor en el constructor EventSource.
- El servidor envía mensajes ocasionales.
- Entre dos mensajes, el navegador detecta que está inactivo, excepto por la actividad de la red involucrada en mantener activa la conexión TCP, y decide cambiar al modo de suspensión para ahorrar energía.
- El navegador se desconecta del servidor.
- El navegador se pone en contacto con un servicio en la red y solicita que el servicio, un "proxy de inserción", mantenga la conexión en su lugar.
- El servicio "push proxy" se pone en contacto con el servidor HTTP remoto y solicita el recurso especificado por el autor en el constructor EventSource (posiblemente incluyendo un encabezado HTTP
Last-Event-ID, etc.). - El navegador permite que el dispositivo móvil se vaya a dormir.
- El servidor envía otro mensaje.
- El servicio "push proxy" utiliza una tecnología como OMA push para transmitir el evento al dispositivo móvil, que se activa solo lo suficiente para procesar el evento y luego vuelve a dormir.
Esto puede reducir el uso total de datos y, por lo tanto, puede resultar en un ahorro de energía considerable.
Además de implementar la API existente y el formato de cable de flujo de eventos/texto según lo definido por la especificación y de formas más distribuidas (como se describe anteriormente), se pueden admitir formatos de marcos de eventos definidos por otras especificaciones aplicables.
Resumen
Después de largas y exhaustivas POC que incluyen implementaciones de servidor y cliente, parece que SSE es la respuesta a nuestros problemas con la entrega de datos. También hay algunas trampas, pero resultaron ser triviales de solucionar.
Así es como se ve nuestra configuración de producción al final:
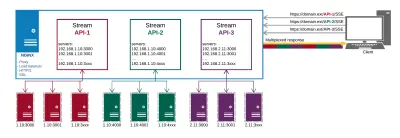
Obtenemos lo siguiente de NGINX:
- Proxy a puntos finales de API en diferentes lugares;
- HTTP/2 y todos sus beneficios como multiplexación para las conexiones;
- Balanceo de carga;
- SSL.
De esta forma, gestionamos nuestra entrega de datos y certificados en un solo lugar en lugar de hacerlo en cada punto final por separado.
Los principales beneficios que obtenemos de este enfoque son:
- Datos eficientes;
- Implementación más simple;
- Se multiplexa automáticamente sobre HTTP/2;
- Limita el número de conexiones para datos en el cliente a uno;
- Proporciona un mecanismo para ahorrar batería descargando la conexión a un proxy.
SSE no es solo una alternativa viable a los otros métodos para entregar actualizaciones rápidas; parece que está en una liga propia cuando se trata de optimizaciones para dispositivos móviles. No hay gastos generales en su implementación en comparación con las alternativas. En términos de implementación del lado del servidor, no es muy diferente al sondeo. En el cliente, es mucho más simple que sondear, ya que requiere una suscripción inicial y la asignación de controladores de eventos, muy similar a cómo se administran los WebSockets.
Consulte la demostración del código si desea obtener una implementación cliente-servidor simple.
Recursos
- "Problemas conocidos y mejores prácticas para el uso de sondeos largos y transmisión en HTTP bidireccional", IETF (PDF)
- Recomendación W3C, W3C
- "¿Sobrevivirá WebSocket a HTTP/2?", Allan Denis, InfoQ
- "Transmitir actualizaciones con eventos enviados por el servidor", Eric Bidelman, HTML5 Rocks
- "Aplicaciones de inserción de datos con HTML5 SSE", Darren Cook, O'Reilly Media