
Cómo mejoramos el rendimiento de SmashingMag
Publicado: 2022-03-10Este artículo cuenta con el amable apoyo de nuestros queridos amigos de Media Temple, que ofrecen una gama completa de soluciones de alojamiento web para diseñadores, desarrolladores y sus clientes. ¡Gracias, queridos amigos!

Cada historia de rendimiento web es similar, ¿no es así? Siempre comienza con la tan esperada revisión del sitio web. Un día en el que se lanza un proyecto, completamente pulido y cuidadosamente optimizado, con una clasificación alta y muy por encima de las puntuaciones de rendimiento en Lighthouse y WebPageTest. Hay una celebración y una sensación sincera de logro que prevalece en el aire, bellamente reflejada en retweets, comentarios, boletines e hilos de Slack.
Sin embargo, a medida que pasa el tiempo, la emoción se desvanece lentamente y aparecen ajustes urgentes, funciones muy necesarias y nuevos requisitos comerciales. Y de repente, antes de que te des cuenta, el código base se vuelve un poco sobrepeso y fragmentado los scripts tienen que cargarse un poco antes, y el nuevo y brillante contenido dinámico encuentra su camino hacia el DOM a través de las puertas traseras de los scripts de terceros y sus invitados no invitados.
Hemos estado allí en Smashing también. No mucha gente lo sabe, pero somos un equipo muy pequeño de alrededor de 12 personas, muchas de las cuales trabajan a tiempo parcial y la mayoría de las cuales suelen desempeñar diferentes funciones en un día determinado. Si bien el rendimiento ha sido nuestro objetivo durante casi una década, en realidad nunca tuvimos un equipo de rendimiento dedicado.
Después del último rediseño a fines de 2017, Ilya Pukhalski estuvo en el lado de JavaScript (a tiempo parcial), Michael Riethmueller en el lado de CSS (unas pocas horas a la semana) y atentamente, jugando juegos mentales con CSS crítico. y tratando de hacer malabarismos con demasiadas cosas.
Dio la casualidad de que perdimos la noción del rendimiento en el ajetreo de la rutina diaria. Estábamos diseñando y construyendo cosas, configurando nuevos productos, refactorizando los componentes y publicando artículos. Entonces, a fines de 2020, las cosas se salieron un poco de control, con puntajes de Lighthouse rojo amarillentos apareciendo lentamente en todos los ámbitos. Tuvimos que arreglar eso.
Ahí es donde estábamos
Algunos de ustedes pueden saber que estamos ejecutando JAMStack, con todos los artículos y páginas almacenados como archivos Markdown, archivos Sass compilados en CSS, JavaScript dividido en fragmentos con Webpack y Hugo creando páginas estáticas que luego servimos directamente desde Edge CDN. En 2017 creamos todo el sitio con Preact, pero luego nos mudamos a React en 2019, y lo usamos junto con algunas API para búsqueda, comentarios, autenticación y pago.
Todo el sitio está diseñado pensando en la mejora progresiva, lo que significa que usted, querido lector, puede leer todos los artículos de Smashing en su totalidad sin necesidad de iniciar la aplicación. Tampoco es muy sorprendente: al final, un artículo publicado no cambia mucho a lo largo de los años, mientras que las piezas dinámicas, como la autenticación de membresía y el pago, necesitan que la aplicación se ejecute.
La compilación completa para implementar alrededor de 2500 artículos en vivo toma alrededor de 6 minutos en este momento. El proceso de compilación en sí también se ha convertido en una bestia con el tiempo, con inyecciones críticas de CSS, división de código de Webpack, inserciones dinámicas de publicidad y paneles de funciones, (re)generación de RSS y eventuales pruebas A/B en el borde.
A principios de 2020, comenzamos con la gran refactorización de los componentes de diseño de CSS. Nunca usamos CSS-in-JS o componentes con estilo, sino un buen sistema de módulos Sass basado en componentes que se compilaría en CSS. En 2017, todo el diseño se creó con Flexbox y se reconstruyó con CSS Grid y CSS Custom Properties a mediados de 2019. Sin embargo, algunas páginas necesitaban un tratamiento especial debido a nuevos anuncios publicitarios y nuevos paneles de productos. Entonces, mientras el diseño funcionaba, no funcionaba muy bien y era bastante difícil de mantener.
Además, el encabezado con la navegación principal tuvo que cambiar para adaptarse a más elementos que queríamos mostrar dinámicamente. Además, queríamos refactorizar algunos componentes que se usan con frecuencia en todo el sitio, y el CSS que se usa allí también necesitaba alguna revisión; el cuadro del boletín informativo es el culpable más notable. Comenzamos refactorizando algunos componentes con CSS de utilidad primero, pero nunca llegamos al punto de que se usara de manera consistente en todo el sitio.
El problema más importante fue el gran paquete de JavaScript que, como era de esperar, bloqueó el hilo principal durante cientos de milisegundos. Un gran paquete de JavaScript puede parecer fuera de lugar en una revista que simplemente publica artículos, pero en realidad, hay muchas secuencias de comandos detrás de escena.
Tenemos varios estados de componentes para clientes autenticados y no autenticados. Una vez que haya iniciado sesión, queremos mostrar todos los productos en el precio final y, a medida que agrega un libro al carrito, queremos mantener el carrito accesible con solo tocar un botón, sin importar en qué página se encuentre. La publicidad debe llegar rápidamente sin causar cambios de diseño disruptivos, y lo mismo ocurre con los paneles de productos nativos que destacan nuestros productos. Además de un trabajador de servicio que almacena en caché todos los activos estáticos y los sirve para vistas repetidas, junto con versiones en caché de artículos que un lector ya ha visitado.
Así que todo este guión tenía que suceder en algún momento, y estaba agotando la experiencia de lectura a pesar de que el guión llegaba bastante tarde. Francamente, estábamos trabajando minuciosamente en el sitio y los nuevos componentes sin vigilar de cerca el rendimiento (y teníamos algunas otras cosas que tener en cuenta para 2020). El punto de inflexión llegó inesperadamente. Harry Roberts realizó su (excelente) clase magistral de rendimiento web como un taller en línea con nosotros y, durante todo el taller, usó Smashing como ejemplo al resaltar los problemas que teníamos y sugerir soluciones a esos problemas junto con herramientas y pautas útiles.
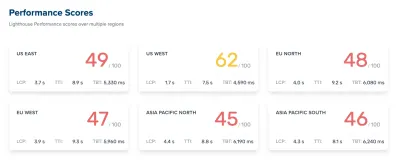
A lo largo del taller, estuve tomando notas diligentemente y revisando el código base. En el momento del taller, nuestros puntajes de Lighthouse eran de 60 a 68 en la página de inicio y de alrededor de 40 a 60 en las páginas de artículos , y obviamente peores en dispositivos móviles. Una vez terminado el taller, nos pusimos manos a la obra.
Identificando los cuellos de botella
A menudo tendemos a confiar en puntajes particulares para comprender qué tan bien nos desempeñamos, pero con demasiada frecuencia los puntajes únicos no brindan una imagen completa. Como señaló elocuentemente David East en su artículo, el rendimiento web no es un valor único; es una distribución. Incluso si una experiencia web es en gran medida un rendimiento general optimizado, no puede ser solo rápida. Puede ser rápido para algunos visitantes, pero en última instancia también será más lento (o lento) para otros.
Las razones de ello son numerosas, pero la más importante es una gran diferencia en las condiciones de la red y el hardware de los dispositivos en todo el mundo. La mayoría de las veces no podemos influir realmente en esas cosas, por lo que debemos asegurarnos de que nuestra experiencia las acomode.
En esencia, nuestro trabajo entonces es aumentar la proporción de experiencias rápidas y disminuir la proporción de experiencias lentas. Pero para eso, necesitamos obtener una imagen adecuada de cuál es realmente la distribución. Ahora, las herramientas de análisis y las herramientas de monitoreo del rendimiento proporcionarán estos datos cuando sea necesario, pero analizamos específicamente CrUX, Chrome User Experience Report. CrUX genera una descripción general de las distribuciones de rendimiento a lo largo del tiempo, con el tráfico recopilado de los usuarios de Chrome. Gran parte de estos datos están relacionados con Core Web Vitals que Google anunció en 2020, y que también contribuyen y están expuestos en Lighthouse.
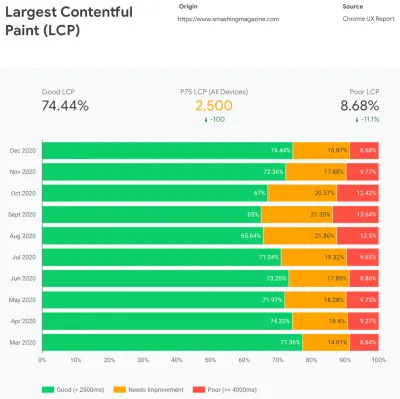
Notamos que, en general, nuestro desempeño retrocedió drásticamente a lo largo del año, con caídas particulares alrededor de agosto y septiembre. Una vez que vimos estos gráficos, pudimos mirar hacia atrás en algunas de las relaciones públicas que lanzamos en vivo en ese entonces para estudiar lo que realmente sucedió.
No me llevó mucho tiempo darme cuenta de que justo por estas fechas lanzamos una nueva barra de navegación en vivo. Esa barra de navegación, utilizada en todas las páginas, se basó en JavaScript para mostrar los elementos de navegación en un menú al tocar o al hacer clic, pero la parte de JavaScript en realidad estaba incluida en el paquete app.js. Para mejorar Time To Interactive, decidimos extraer el script de navegación del paquete y publicarlo en línea.
Casi al mismo tiempo, cambiamos de un archivo CSS crítico (obsoleto) creado manualmente a un sistema automatizado que generaba CSS crítico para cada plantilla (página de inicio, artículo, página de producto, evento, bolsa de trabajo, etc.) y CSS crítico en línea durante el tiempo de construcción. Sin embargo, no nos dimos cuenta de cuánto más pesado era el CSS crítico generado automáticamente. Tuvimos que explorarlo con más detalle.
Y también casi al mismo tiempo, estábamos ajustando la carga de fuentes web , tratando de impulsar las fuentes web de manera más agresiva con sugerencias de recursos como la precarga. Sin embargo, esto parece estar repercutiendo negativamente en nuestros esfuerzos de rendimiento, ya que las fuentes web retrasaban la representación del contenido y tenían una prioridad excesiva junto al archivo CSS completo.
Ahora, una de las razones comunes de la regresión es el alto costo de JavaScript, por lo que también analizamos Webpack Bundle Analyzer y el mapa de solicitudes de Simon Hearne para obtener una imagen visual de nuestras dependencias de JavaScript. Parecía bastante saludable al principio.
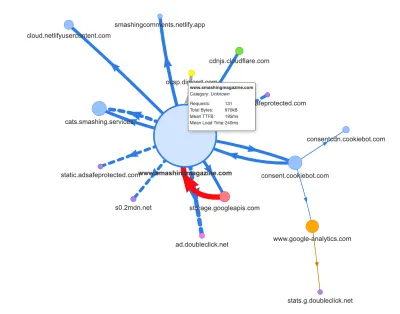
Llegaban algunas solicitudes a la CDN, un servicio de consentimiento de cookies Cookiebot, Google Analytics, además de nuestros servicios internos para servir paneles de productos y publicidad personalizada. No parecía que hubiera muchos cuellos de botella, hasta que miramos un poco más de cerca.
En el trabajo de rendimiento, es común observar el rendimiento de algunas páginas críticas, muy probablemente la página de inicio y muy probablemente algunas páginas de artículos/productos. Sin embargo, si bien solo hay una página de inicio, puede haber muchas páginas de productos diferentes, por lo que debemos elegir las que sean representativas de nuestra audiencia.
De hecho, como estamos publicando bastantes artículos con mucho código y mucho diseño en SmashingMag, a lo largo de los años hemos acumulado literalmente miles de artículos que contenían GIF pesados, fragmentos de código resaltados en sintaxis, incrustaciones de CodePen, video/audio. incrustaciones e hilos anidados de comentarios interminables.
Cuando se unieron, muchos de ellos causaron nada menos que una explosión en el tamaño del DOM junto con un trabajo excesivo del subproceso principal , lo que ralentizó la experiencia en miles de páginas. Sin mencionar que con la publicidad en su lugar, algunos elementos DOM se inyectaron tarde en el ciclo de vida de la página, lo que provocó una cascada de recálculos y repintados de estilo, también tareas costosas que pueden producir tareas largas.
Todo esto no aparecía en el mapa que generamos para una página de artículo bastante liviana en el gráfico anterior. Así que elegimos las páginas más pesadas que teníamos, la página de inicio todopoderosa, la más larga, la que tenía muchas incrustaciones de video y la que tenía muchas incrustaciones de CodePen, y decidimos optimizarlas tanto como pudimos. Después de todo, si son rápidas, las páginas con una sola inserción de CodePen también deberían ser más rápidas.
Con estas páginas en mente, el mapa se veía un poco diferente. Tenga en cuenta la enorme línea gruesa que se dirige al reproductor de Vimeo y Vimeo CDN, con 78 solicitudes provenientes de un artículo de Smashing.
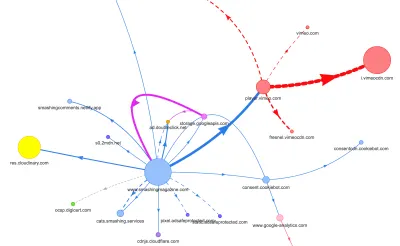
Para estudiar el impacto en el hilo principal, nos sumergimos profundamente en el panel Rendimiento en DevTools. Más específicamente, buscábamos tareas que duraran más de 50 ms (resaltadas con un rectángulo rojo en la esquina superior derecha) y tareas que contuvieran estilos de recálculo (barra morada). El primero indicaría una ejecución costosa de JavaScript, mientras que el segundo expondría invalidaciones de estilo causadas por inyecciones dinámicas de contenido en el DOM y CSS subóptimo. Esto nos dio algunos indicadores prácticos de por dónde empezar. Por ejemplo, descubrimos rápidamente que nuestra carga de fuentes web tenía un costo de repintado significativo, mientras que los fragmentos de JavaScript aún eran lo suficientemente pesados como para bloquear el hilo principal.
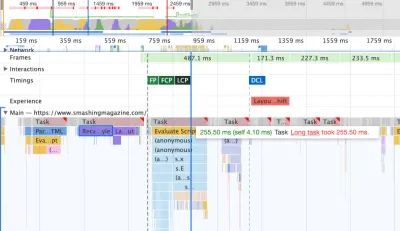
Como línea de base, observamos muy de cerca Core Web Vitals, tratando de asegurarnos de que estamos obteniendo buenos puntajes en todos ellos. Elegimos centrarnos específicamente en dispositivos móviles lentos, con 3G lento, RTT de 400 ms y velocidad de transferencia de 400 kbps, solo para estar en el lado pesimista de las cosas. Entonces, no es sorprendente que Lighthouse tampoco estuviera muy contento con nuestro sitio, brindando puntajes rojos completamente sólidos para los artículos más pesados y quejándose incansablemente sobre JavaScript, CSS, imágenes fuera de pantalla no utilizadas y sus tamaños.
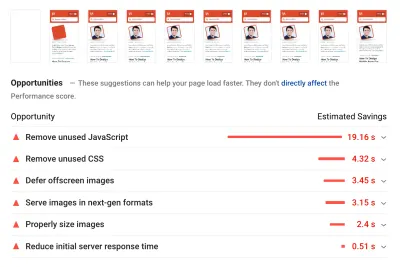
Una vez que tuviéramos algunos datos frente a nosotros, podríamos concentrarnos en optimizar las tres páginas de artículos más pesadas, con un enfoque en CSS crítico (y no crítico), paquete de JavaScript, tareas largas, carga de fuentes web, cambios de diseño y terceros. -incrustaciones. Más tarde, también revisaríamos el código base para eliminar el código heredado y usar nuevas funciones modernas del navegador. Parecía que había mucho trabajo por delante y, de hecho, estábamos bastante ocupados durante los próximos meses.
Mejorar el orden de los activos en el <head>
Irónicamente, lo primero que investigamos ni siquiera estaba estrechamente relacionado con todas las tareas que hemos identificado anteriormente. En el taller de rendimiento, Harry pasó una cantidad considerable de tiempo explicando el orden de los activos en el <head> de cada página, destacando que entregar contenido crítico rápidamente significa ser muy estratégico y estar atento a cómo se ordenan los activos en el código fuente. .
Ahora bien, no debería ser una gran revelación que el CSS crítico es beneficioso para el rendimiento web. Sin embargo, fue un poco sorprendente la diferencia que tiene el orden de todos los demás recursos (sugerencias de recursos, precarga de fuentes web, scripts sincrónicos y asincrónicos, CSS completo y metadatos).
Hemos invertido todo el <head> , colocando CSS crítico antes de todos los scripts asincrónicos y todos los activos precargados, como fuentes, imágenes, etc. Hemos desglosado los activos que estaremos preconectando o precargando por plantilla y tipo de archivo, por lo que las imágenes críticas, el resaltado de sintaxis y las incrustaciones de video se solicitarán antes solo para un determinado tipo de artículos y páginas.
En general, orquestamos cuidadosamente el orden en <head> , redujimos la cantidad de activos precargados que competían por el ancho de banda y nos enfocamos en obtener el CSS crítico correcto. Si desea profundizar en algunas de las consideraciones críticas con el orden <head> , Harry las destaca en el artículo sobre CSS y rendimiento de la red. Este cambio solo nos trajo alrededor de 3-4 puntos de puntuación de Lighthouse en todos los ámbitos.
Pasar de CSS crítico automatizado a CSS crítico manual
Sin embargo, mover las etiquetas <head> fue una parte simple de la historia. Una más difícil fue la generación y gestión de archivos CSS críticos. En 2017, creamos manualmente CSS crítico para cada plantilla, recopilando todos los estilos necesarios para representar los primeros 1000 píxeles de altura en todos los anchos de pantalla. Por supuesto, esta fue una tarea engorrosa y un poco aburrida, sin mencionar los problemas de mantenimiento para controlar toda una familia de archivos CSS críticos y un archivo CSS completo.
Así que buscamos opciones para automatizar este proceso como parte de la rutina de compilación. Realmente no había escasez de herramientas disponibles, así que probamos algunas y decidimos ejecutar algunas pruebas. Hemos logrado configurarlos y ponerlos en funcionamiento con bastante rapidez. El resultado parecía ser lo suficientemente bueno para un proceso automatizado, así que después de algunos ajustes de configuración, lo enchufamos y lo llevamos a producción. Eso sucedió alrededor de julio-agosto del año pasado, lo que se visualiza muy bien en el pico y la caída del rendimiento en los datos de CrUX anteriores. Seguimos yendo y viniendo con la configuración, a menudo teniendo problemas con cosas simples como agregar estilos particulares o eliminar otros. Por ejemplo, estilos de solicitud de consentimiento de cookies que no se incluyen realmente en una página a menos que se haya inicializado el script de cookies.
En octubre, introdujimos algunos cambios importantes en el diseño del sitio y, al examinar el CSS crítico, nos encontramos exactamente con los mismos problemas una vez más: el resultado generado era bastante detallado y no era exactamente lo que queríamos. . Entonces, como experimento a fines de octubre, todos reunimos nuestras fortalezas para revisar nuestro enfoque de CSS crítico y estudiar cuánto más pequeño sería un CSS crítico hecho a mano . Tomamos una respiración profunda y pasamos días alrededor de la herramienta de cobertura de código en páginas clave. Agrupamos las reglas de CSS manualmente y eliminamos los duplicados y el código heredado en ambos lugares: el CSS crítico y el CSS principal. De hecho, fue una limpieza muy necesaria, ya que muchos estilos que se escribieron en 2017-2018 se han vuelto obsoletos con los años.
Como resultado, terminamos con tres archivos CSS críticos hechos a mano y con tres archivos más que actualmente están en proceso:
- Critical-Homepage-manual.css (8.2 KB, Brotlified)
- manual-artículo-crítico.css (8 KB, Brotlified)
- manual-artículos-críticos.css (6 KB, Brotlified)
- manual-de-libros-criticos.css ( trabajo por hacer )
- Critical-events-manual.css ( trabajo por hacer )
- Critical-Job-Board-Manual.css ( trabajo por hacer )
Los archivos están alineados en el encabezado de cada plantilla, y en este momento están duplicados en el paquete CSS monolítico que contiene todo lo que se usó (o ya no se usó realmente) en el sitio. Por el momento, estamos analizando dividir el paquete completo de CSS en algunos paquetes de CSS, de modo que un lector de la revista no descargue estilos de la bolsa de trabajo o de las páginas del libro, pero luego, al llegar a esas páginas, obtendría un renderizado rápido. con CSS crítico y obtenga el resto del CSS para esa página de forma asincrónica, solo en esa página.
Es cierto que los archivos CSS críticos hechos a mano no eran mucho más pequeños: hemos reducido el tamaño de los archivos CSS críticos en alrededor de un 14 % . Sin embargo, incluyeron todo lo que necesitábamos en el orden correcto de arriba a abajo sin duplicados ni estilos anulados. Esto parecía ser un paso en la dirección correcta y nos dio un impulso de Lighthouse de otros 3 o 4 puntos. Estábamos haciendo progresos.
Cambiar la carga de fuentes web
Con font-display al alcance de la mano, la carga de fuentes parece ser un problema del pasado. Desafortunadamente, no es del todo correcto en nuestro caso. Ustedes, queridos lectores, parecen visitar varios artículos en Smashing Magazine. También regresa con frecuencia al sitio para leer otro artículo, tal vez unas horas o días después, o tal vez una semana después. Uno de los problemas que tuvimos con font-display utilizada en todo el sitio fue que para los lectores que se movían mucho entre artículos, notamos muchos destellos entre la fuente alternativa y la fuente web (lo que normalmente no debería suceder ya que las fuentes serían correctamente almacenado en caché).
Eso no se sintió como una experiencia de usuario decente, así que buscamos opciones. En Smashing, usamos dos tipos de letra principales : Mija para los encabezados y Elena para el cuerpo del texto. Mija viene en dos pesos (Regular y Negrita), mientras que Elena viene en tres pesos (Regular, Cursiva, Negrita). Eliminamos la cursiva negrita de Elena hace años durante el rediseño solo porque la usamos en solo unas pocas páginas. Subdividimos las otras fuentes eliminando caracteres no utilizados y rangos Unicode.
La mayoría de nuestros artículos contienen texto, por lo que hemos descubierto que la mayoría de las veces en el sitio, la pintura con contenido más grande es el primer párrafo del texto de un artículo o la foto del autor. Eso significa que debemos tener mucho cuidado de asegurarnos de que el primer párrafo aparezca rápidamente en una fuente alternativa, mientras cambia con elegancia a la fuente web con reflujos mínimos.
Eche un vistazo de cerca a la experiencia de carga inicial de la página principal (reducida tres veces):
Teníamos cuatro objetivos principales al encontrar una solución:
- En la primera visita, reproduzca el texto inmediatamente con una fuente alternativa;
- Haga coincidir las métricas de fuentes de fuentes alternativas y fuentes web para minimizar los cambios de diseño;
- Cargue todas las fuentes web de forma asincrónica y aplíquelas todas a la vez (máx. 1 reflujo);
- En visitas posteriores, reproduzca todo el texto directamente en fuentes web (sin parpadeos ni reflujos).
Inicialmente, intentamos usar font-display: swap en font-face . Esta parecía ser la opción más simple, sin embargo, como se mencionó anteriormente, algunos lectores visitarán varias páginas, por lo que terminamos con muchos parpadeos con las seis fuentes que estábamos representando en todo el sitio. Además, solo con font-display , no pudimos agrupar solicitudes o repintar.
Otra idea era representar todo en fuente alternativa en la visita inicial , luego solicitar y almacenar en caché todas las fuentes de forma asincrónica, y solo en visitas posteriores entregar fuentes web directamente desde la memoria caché. El problema con este enfoque era que una cantidad de lectores provienen de los motores de búsqueda, y al menos algunos de ellos solo verán esa página, y no queríamos mostrar un artículo solo en una fuente del sistema.
Entonces, ¿qué es entonces?
Desde 2017, hemos estado utilizando el enfoque Two-Stage-Render para la carga de fuentes web, que básicamente describe dos etapas de procesamiento: una con un subconjunto mínimo de fuentes web y la otra con una familia completa de pesos de fuentes. En el pasado, creamos subconjuntos mínimos de Mija Bold y Elena Regular, que eran los pesos más utilizados en el sitio. Ambos subconjuntos incluyen solo caracteres latinos, puntuación, números y algunos caracteres especiales. Estas fuentes ( ElenaInitial.woff2 y MijaInitial.woff2 ) eran de tamaño muy pequeño, a menudo de alrededor de 10 a 15 KB. Los servimos en la primera etapa de renderizado de fuentes, mostrando la página completa en estas dos fuentes.

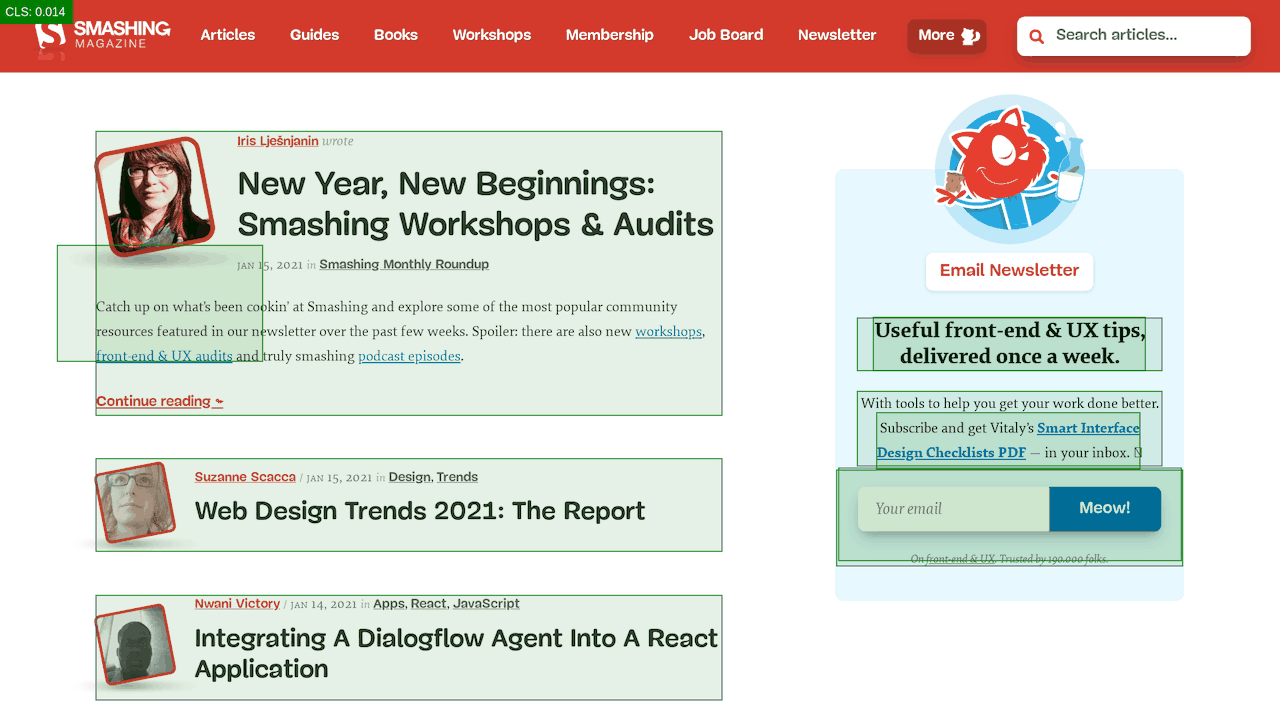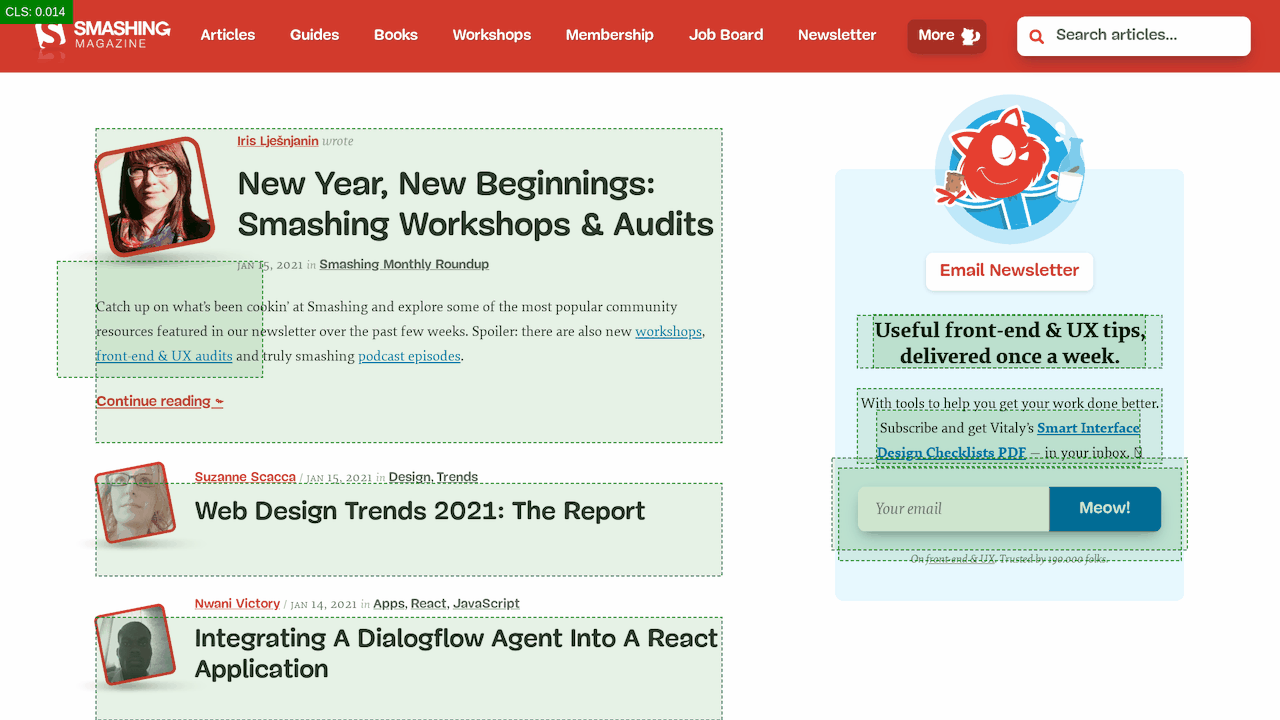
Lo hacemos con una API de carga de fuentes que nos brinda información sobre qué fuentes se han cargado correctamente y cuáles aún no. Detrás de escena, sucede al agregar una clase .wf-loaded-stage1 al cuerpo , con estilos que representan el contenido en esas fuentes:
.wf-loaded-stage1 article, .wf-loaded-stage1 promo-box, .wf-loaded-stage1 comments { font-family: ElenaInitial,sans-serif; } .wf-loaded-stage1 h1, .wf-loaded-stage1 h2, .wf-loaded-stage1 .btn { font-family: MijaInitial,sans-serif; }Debido a que los archivos de fuentes son bastante pequeños, es de esperar que pasen por la red con bastante rapidez. Luego, como el lector puede comenzar a leer un artículo, cargamos el peso completo de las fuentes de forma asincrónica y agregamos .wf-loaded-stage2 al cuerpo :
.wf-loaded-stage2 article, .wf-loaded-stage2 promo-box, .wf-loaded-stage2 comments { font-family: Elena,sans-serif; } .wf-loaded-stage2 h1, .wf-loaded-stage2 h2, .wf-loaded-stage2 .btn { font-family: Mija,sans-serif; }Entonces, al cargar una página, los lectores obtendrán rápidamente una fuente web de subconjunto pequeño primero, y luego cambiaremos a la familia de fuentes completa. Ahora, de forma predeterminada, estos cambios entre las fuentes alternativas y las fuentes web ocurren aleatoriamente, según lo que ocurra primero a través de la red. Eso puede parecer bastante disruptivo ya que ha comenzado a leer un artículo. Entonces, en lugar de dejar que el navegador decida cuándo cambiar las fuentes, agrupamos los repintados , reduciendo al mínimo el impacto del reflujo.
/* Loading web fonts with Font Loading API to avoid multiple repaints. With help by Irina Lipovaya. */ /* Credit to initial work by Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // If the Font Loading API is supported... // (If not, we stick to fallback fonts) if ("fonts" in document) { // Create new FontFace objects, one for each font let ElenaRegular = new FontFace( "Elena", "url(/fonts/ElenaWebRegular/ElenaWebRegular.woff2) format('woff2')" ); let ElenaBold = new FontFace( "Elena", "url(/fonts/ElenaWebBold/ElenaWebBold.woff2) format('woff2')", { weight: "700" } ); let ElenaItalic = new FontFace( "Elena", "url(/fonts/ElenaWebRegularItalic/ElenaWebRegularItalic.woff2) format('woff2')", { style: "italic" } ); let MijaBold = new FontFace( "Mija", "url(/fonts/MijaBold/Mija_Bold-webfont.woff2) format('woff2')", { weight: "700" } ); // Load all the fonts but render them at once // if they have successfully loaded let loadedFonts = Promise.all([ ElenaRegular.load(), ElenaBold.load(), ElenaItalic.load(), MijaBold.load() ]).then(result => { result.forEach(font => document.fonts.add(font)); document.documentElement.classList.add('wf-loaded-stage2'); // Used for repeat views sessionStorage.foutFontsStage2Loaded = true; }).catch(error => { throw new Error(`Error caught: ${error}`); }); }Sin embargo, ¿qué pasa si el primer pequeño subconjunto de fuentes no llega rápidamente a través de la red? Hemos notado que esto parece estar sucediendo con más frecuencia de lo que nos gustaría. En ese caso, después de que expire un tiempo de espera de 3 segundos, los navegadores modernos recurren a una fuente del sistema (en nuestra pila de fuentes sería Arial), luego cambian a ElenaInitial o MijaInitial , solo para cambiar a Elena o Mija completa respectivamente más tarde . Eso produjo demasiado parpadeo en nuestra degustación. Estábamos pensando en eliminar el procesamiento de la primera etapa solo para redes lentas inicialmente (a través de la API de información de red), pero luego decidimos eliminarlo por completo.
Entonces, en octubre, eliminamos los subconjuntos por completo, junto con la etapa intermedia. Siempre que el cliente descargue correctamente todos los pesos de las fuentes Elena y Mija y esté listo para aplicar, iniciamos la etapa 2 y volvemos a pintar todo a la vez. Y para que los reflujos sean aún menos perceptibles, dedicamos un poco de tiempo a hacer coincidir las fuentes alternativas y las fuentes web . Eso significó principalmente aplicar tamaños de fuente y alturas de línea ligeramente diferentes para los elementos pintados en la primera parte visible de la página.
Para eso, usamos font-style-matcher y (ejem, ejem) algunos números mágicos. Esa es también la razón por la que inicialmente elegimos -apple-system y Arial como fuentes de respaldo globales; San Francisco (renderizado a través de -apple-system ) parecía ser un poco mejor que Arial, pero si no está disponible, elegimos usar Arial solo porque está ampliamente distribuido en la mayoría de los sistemas operativos.
En CSS, se vería así:
.article__summary { font-family: -apple-system,Arial,BlinkMacSystemFont,Roboto Slab,Droid Serif,Segoe UI,Ubuntu,Cantarell,Georgia,sans-serif; font-style: italic; /* Warning: magic numbers ahead! */ /* San Francisco Italic and Arial Italic have larger x-height, compared to Elena */ font-size: 0.9213em; line-height: 1.487em; } .wf-loaded-stage2 .article__summary { font-family: Elena,sans-serif; font-size: 1em; /* Original font-size for Elena Italic */ line-height: 1.55em; /* Original line-height for Elena Italic */ }Esto funcionó bastante bien. Mostramos el texto de inmediato y las fuentes web aparecen en la pantalla agrupadas, lo que idealmente provoca exactamente un reflujo en la primera vista y ningún reflujo en las vistas posteriores.
Una vez que se han descargado las fuentes, las almacenamos en el caché de un trabajador de servicio. En visitas posteriores, primero verificamos si las fuentes ya están en el caché. Si lo son, los recuperamos de la memoria caché del trabajador del servicio y los aplicamos de inmediato. Y si no, comenzamos de nuevo con fallback-web-font-switcheroo .
Esta solución redujo la cantidad de reflujos al mínimo (uno) en conexiones relativamente rápidas, al mismo tiempo que mantuvo las fuentes de manera persistente y confiable en la memoria caché. En el futuro, esperamos sinceramente reemplazar los números mágicos con f-mods. Quizás Zach Leatherman estaría orgulloso.
Identificar y desglosar el JS monolítico
Cuando estudiamos el hilo principal en el panel Rendimiento de DevTools, sabíamos exactamente lo que teníamos que hacer. Había ocho tareas largas que tardaban entre 70 ms y 580 ms, bloqueando la interfaz y haciendo que no respondiera. En general, estos fueron los guiones que más costaron:
- uc.js , una secuencia de comandos de solicitud de cookies (70 ms)
- recálculos de estilo causados por el archivo full.css entrante (176 ms) (el CSS crítico no contiene estilos por debajo de la altura de 1000 px en todas las ventanas gráficas)
- scripts publicitarios que se ejecutan en el evento de carga para administrar paneles, carrito de compras, etc. + recálculos de estilo (276ms)
- cambio de fuente web, recálculos de estilo (290ms)
- Evaluación de app.js (580ms)
Primero nos enfocamos en los que eran más dañinos, por así decirlo, las tareas largas más largas.
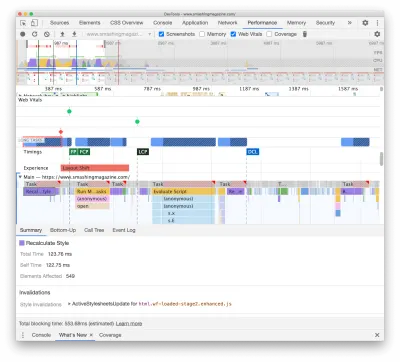
El primero estaba ocurriendo debido a los costosos recálculos de diseño causados por el cambio de las fuentes (de fuente alternativa a fuente web), lo que generaba más de 290 ms de trabajo adicional (en una computadora portátil rápida y una conexión rápida). Al eliminar la etapa uno solo de la carga de fuentes, pudimos recuperar alrededor de 80 ms. Sin embargo, no fue lo suficientemente bueno porque estaba mucho más allá del presupuesto de 50 ms. Así que empezamos a cavar más profundo.
La razón principal por la que ocurrieron los recálculos fue simplemente por las enormes diferencias entre las fuentes alternativas y las fuentes web. Al hacer coincidir la altura de línea y los tamaños de las fuentes alternativas y las fuentes web , pudimos evitar muchas situaciones en las que una línea de texto se ajustaba a una nueva línea en la fuente alternativa, pero luego se hacía un poco más pequeña y se ajustaba a la línea anterior. provocando un cambio importante en la geometría de toda la página y, en consecuencia, cambios de diseño masivos. También hemos jugado con letter-spacing word-spacing , pero no produjo buenos resultados.
Con estos cambios, pudimos reducir otros 50-80 ms, pero no pudimos reducirlo por debajo de 120 ms sin mostrar el contenido en una fuente alternativa y luego mostrar el contenido en la fuente web. Obviamente, debería afectar masivamente solo a los visitantes por primera vez, ya que las vistas de página consiguientes se representarían con las fuentes recuperadas directamente de la memoria caché del trabajador del servicio, sin reflujos costosos debido al cambio de fuente.
Por cierto, es muy importante notar que en nuestro caso, notamos que la mayoría de las tareas largas no fueron causadas por JavaScript masivo, sino por recálculos de diseño y análisis de CSS, lo que significaba que necesitábamos hacer un poco de CSS. cleaning, especially watching out for situations when styles are overwritten. In some way, it was good news because we didn't have to deal with complex JavaScript issues that much. However, it turned out not to be straightforward as we are still cleaning up the CSS this very day. We were able to remove two Long Tasks for good, but we still have a few outstanding ones and quite a way to go. Fortunately, most of the time we aren't way above the magical 50ms threshold.
The much bigger issue was the JavaScript bundle we were serving, occupying the main thread for a whopping 580ms. Most of this time was spent in booting up app.js which contains React, Redux, Lodash, and a Webpack module loader. The only way to improve performance with this massive beast was to break it down into smaller pieces. So we looked into doing just that.
With Webpack, we've split up the monolithic bundle into smaller chunks with code-splitting , about 30Kb per chunk. We did some package.json cleansing and version upgrade for all production dependencies, adjusted the browserlistrc setup to address the two latest browser versions, upgraded to Webpack and Babel to the latest versions, moved to Terser for minification, and used ES2017 (+ browserlistrc) as a target for script compilation.
We also used BabelEsmPlugin to generate modern versions of existing dependencies. Finally, we've added prefetch links to the header for all necessary script chunks and refactored the service worker, migrating to Workbox with Webpack (workbox-webpack-plugin).
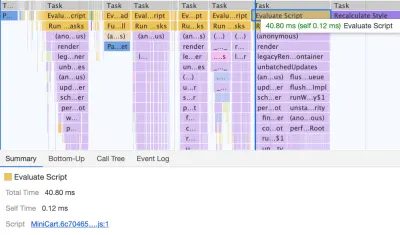
Remember when we switched to the new navigation back in mid-2020, just to see a huge performance penalty as a result? The reason for it was quite simple. While in the past the navigation was just static plain HTML and a bit of CSS, with the new navigation, we needed a bit of JavaScript to act on opening and closing of the menu on mobile and on desktop. That was causing rage clicks when you would click on the navigation menu and nothing would happen, and of course, had a penalty cost in Time-To-Interactive scores in Lighthouse.
We removed the script from the bundle and extracted it as a separate script . Additionally, we did the same thing for other standalone scripts that were used rarely — for syntax highlighting, tables, video embeds and code embeds — and removed them from the main bundle; instead, we granularly load them only when needed.
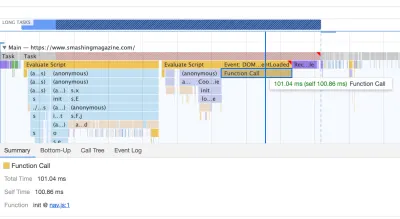
However, what we didn't notice for months was that although we removed the navigation script from the bundle, it was loading after the entire app.js bundle was evaluated, which wasn't really helping Time-To-Interactive (see image above). We fixed it by preloading nav.js and deferring it to execute in the order of appearance in the DOM, and managed to save another 100ms with that operation alone. By the end, with everything in place we were able to bring the task to around 220ms.
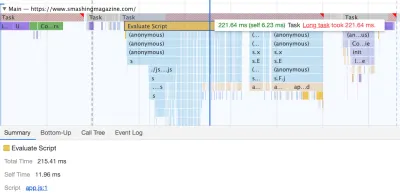
We managed to get some improvement in place, but still have quite a way to go, with further React and Webpack optimizations on our to-do list. At the moment we still have three major Long Tasks — font switch (120ms), app.js execution (220ms) and style recalculations due to the size of full CSS (140ms). For us, it means cleaning up and breaking up the monolithic CSS next.
It's worth mentioning that these results are really the best-scenario- results. On a given article page we might have a large number of code embeds and video embeds, along with other third-party scripts and customer's browser extensions that would require a separate conversation.
Dealing With 3rd-Parties
Fortunately, our third-party scripts footprint (and the impact of their friends' fourth-party-scripts) wasn't huge from the start. But when these third-party scripts accumulated, they would drive performance down significantly. This goes especially for video embedding scripts , but also syntax highlighting, advertising scripts, promo panels scripts and any external iframe embeds.
Obviously, we defer all of these scripts to start loading after the DOMContentLoaded event, but once they finally come on stage, they cause quite a bit of work on the main thread. This shows up especially on article pages, which are obviously the vast majority of content on the site.
The first thing we did was allocating proper space to all assets that are being injected into the DOM after the initial page render. It meant width and height for all advertising images and the styling of code snippets. We found out that because all the scripts were deferred, new styles were invalidating existing styles, causing massive layout shifts for every code snippet that was displayed. We fixed that by adding the necessary styles to the critical CSS on the article pages.
We've re-established a strategy for optimizing images (preferably AVIF or WebP — still work in progress though). All images below the 1000px height threshold are natively lazy-loaded (with <img loading=lazy> ), while the ones on the top are prioritized ( <img loading=eager> ). The same goes for all third-party embeds.
We replaced some dynamic parts with their static counterparts — eg while a note about an article saved for offline reading was appearing dynamically after the article was added to the service worker's cache, now it appears statically as we are, well, a bit optimistic and expect it to be happening in all modern browsers.
As of the moment of writing, we're preparing facades for code embeds and video embeds as well. Plus, all images that are offscreen will get decoding=async attribute, so the browser has a free reign over when and how it loads images offscreen, asynchronously and in parallel.
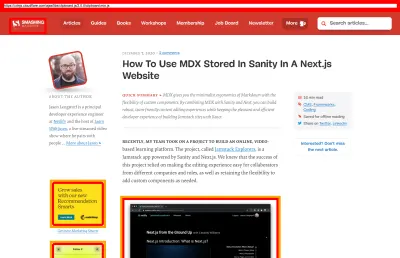
To ensure that our images always include width and height attributes, we've also modified Harry Roberts' snippet and Tim Kadlec's diagnostics CSS to highlight whenever an image isn't served properly. It's used in development and editing but obviously not in production.
One technique that we used frequently to track what exactly is happening as the page is being loaded, was slow-motion loading .
First, we've added a simple line of code to the diagnostics CSS, which provides a noticeable outline for all elements on the page.
* { outline: 3px solid red }* { outline: 3px solid red }
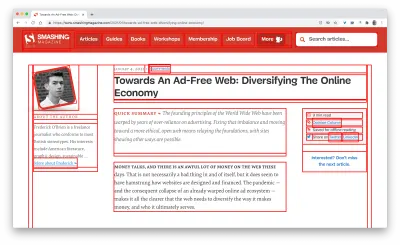
* { outline: 3px red } and observing the boxes as the browser is rendering the page. (Vista previa grande)Then we record a video of the page loaded on a slow and fast connection. Then we rewatch the video by slowing down the playback and moving back and forward to identify where massive layout shifts happen.
Here's the recording of a page being loaded on a fast connection:
And here's the recording of a recording being played to study what happens with the layout:
By auditing the layout shifts this way, we were able to quickly notice what's not quite right on the page, and where massive recalculation costs are happening. As you probably have noticed, adjusting the line-height and font-size on headings might go a long way to avoid large shifts.
With these simple changes alone, we were able to boost performance score by a whopping 25 Lighthouse points for the video-heaviest article, and gain a few points for code embeds.
Enhancing The Experience
We've tried to be quite strategic in pretty much everything from loading web fonts to serving critical CSS. However, we've done our best to use some of the new technologies that have become available last year.
We are planning on using AVIF by default to serve images on SmashingMag, but we aren't quite there yet, as many of our images are served from Cloudinary (which already has beta support for AVIF), but many are directly from our CDN yet we don't really have a logic in place just yet to generate AVIFs on the fly. That would need to be a manual process for now.
We're lazy rendering some of the offset components of the page with content-visibility: auto . For example, the footer, the comments section, as well as the panels way below the first 1000px height threshold, are all rendered later after the visible portion of each page has been rendered.
Hemos jugado un poco con el link rel="prefetch" e incluso con el link rel="prerender" (NoPush prefetch) en algunas partes de la página que es muy probable que se utilicen para una mayor navegación, por ejemplo, para obtener recursos por primera vez. artículos en la portada (aún en discusión).
También precargamos imágenes de autor para reducir la pintura con contenido más grande y algunos activos clave que se usan en cada página, como imágenes de gatos bailando (para la navegación) y sombras utilizadas para todas las imágenes de autor. Sin embargo, todos ellos están precargados solo si un lector se encuentra en una pantalla más grande (> 800 px), aunque estamos considerando usar la API de información de red para ser más precisos.
También redujimos el tamaño del CSS completo y todos los archivos CSS críticos eliminando el código heredado, refactorizando una serie de componentes y eliminando el truco de sombra de texto que estábamos usando para lograr subrayados perfectos con una combinación de text-decoration-skip -tinta y texto-decoración-grosor (¡por fin!).
trabajo por hacer
Hemos pasado una cantidad bastante significativa de tiempo trabajando en todos los cambios menores y mayores en el sitio. Hemos notado mejoras bastante significativas en el escritorio y un impulso bastante notable en el móvil. En el momento de escribir este artículo, nuestros artículos tienen una puntuación media de entre 90 y 100 en la puntuación de Lighthouse en ordenadores y entre 65 y 80 en móviles .
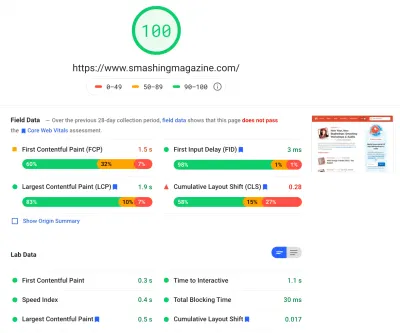
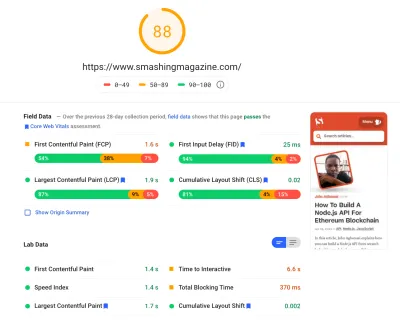
El motivo de la mala puntuación en dispositivos móviles es claramente un tiempo deficiente para interactuar y un tiempo de bloqueo total deficiente debido al arranque de la aplicación y al tamaño del archivo CSS completo. Así que todavía hay algo de trabajo por hacer allí.
En cuanto a los próximos pasos, actualmente estamos buscando reducir aún más el tamaño del CSS y dividirlo específicamente en módulos, de manera similar a JavaScript, cargando algunas partes del CSS (por ejemplo, caja o bolsa de trabajo o libros/libros electrónicos) solo cuando necesario.
También exploramos opciones de experimentación de paquetes adicionales en dispositivos móviles para reducir el impacto en el rendimiento de app.js , aunque parece no ser trivial en este momento. Finalmente, buscaremos alternativas a nuestra solución de solicitud de cookies, reconstruiremos nuestros contenedores con CSS clamp() , reemplazaremos la técnica de relación de relleno inferior con relación de aspect-ratio y buscaremos servir tantas imágenes como sea posible en AVIF.
¡Eso es, amigos!
Con suerte, este pequeño estudio de caso le será útil, y tal vez haya una o dos técnicas que pueda aplicar a su proyecto de inmediato. Al final, el rendimiento tiene que ver con la suma de todos los pequeños detalles finos que, cuando se suman, hacen o deshacen la experiencia de su cliente.
Si bien estamos muy comprometidos a mejorar el rendimiento, también trabajamos para mejorar la accesibilidad y el contenido del sitio. Entonces, si detecta algo que no está del todo bien o algo que podamos hacer para mejorar aún más Smashing Magazine, háganoslo saber en los comentarios de este artículo.
Por último, si desea mantenerse actualizado sobre artículos como este, suscríbase a nuestro boletín informativo por correo electrónico para obtener consejos amigables sobre la web, obsequios, herramientas y artículos, y una selección de temporada de Smashing cats.