
Creación de aplicaciones front-end sin servidor con Google Cloud Platform
Publicado: 2022-03-10Recientemente, el paradigma de desarrollo de aplicaciones ha comenzado a cambiar de tener que implementar, escalar y actualizar manualmente los recursos utilizados dentro de una aplicación a depender de proveedores de servicios en la nube de terceros para realizar la mayor parte de la administración de estos recursos.
Como desarrollador u organización que desea crear una aplicación adecuada para el mercado en el menor tiempo posible, su enfoque principal podría estar en brindar su servicio de aplicación central a sus usuarios mientras dedica menos tiempo a configurar, implementar y realizar pruebas de esfuerzo. su aplicación. Si este es su caso de uso, manejar la lógica comercial de su aplicación sin servidor podría ser su mejor opción. ¿Pero cómo?
Este artículo es útil para los ingenieros de front-end que desean crear ciertas funcionalidades dentro de su aplicación o para los ingenieros de back-end que desean extraer y manejar una determinada funcionalidad de un servicio de back-end existente mediante una aplicación sin servidor implementada en Google Cloud Platform.
Nota : Para beneficiarse de lo que se cubrirá aquí, debe tener experiencia trabajando con React. No se requiere experiencia previa en aplicaciones sin servidor.
Antes de comenzar, comprendamos qué son realmente las aplicaciones sin servidor y cómo se puede usar la arquitectura sin servidor al crear una aplicación en el contexto de un ingeniero front-end.
Aplicaciones sin servidor
Las aplicaciones sin servidor son aplicaciones divididas en pequeñas funciones reutilizables basadas en eventos, alojadas y administradas por proveedores de servicios en la nube externos dentro de la nube pública en nombre del autor de la aplicación. Estos son activados por ciertos eventos y se ejecutan bajo demanda. Aunque el sufijo " menos " adjunto a la palabra sin servidor indica la ausencia de un servidor, este no es el caso al 100%. Estas aplicaciones aún se ejecutan en servidores y otros recursos de hardware, pero en este caso, esos recursos no los proporciona el desarrollador, sino un proveedor de servicios en la nube externo. Por lo tanto, no tienen servidor para el autor de la aplicación, pero aún se ejecutan en servidores y son accesibles a través de Internet público.
Un ejemplo de caso de uso de una aplicación sin servidor sería enviar correos electrónicos a usuarios potenciales que visitan su página de destino y se suscriben para recibir correos electrónicos de lanzamiento de productos. En esta etapa, probablemente no tenga un servicio de back-end en ejecución y no quiera sacrificar el tiempo y los recursos necesarios para crear, implementar y administrar uno, todo porque necesita enviar correos electrónicos. Aquí, puede escribir un solo archivo que use un cliente de correo electrónico e implementarlo en cualquier proveedor de la nube que admita una aplicación sin servidor y permitirles administrar esta aplicación en su nombre mientras conecta esta aplicación sin servidor a su página de destino.
Si bien hay un montón de razones por las que podría considerar aprovechar las aplicaciones sin servidor o las funciones como servicio (FAAS), como se les llama, para su aplicación front-end, aquí hay algunas razones muy notables que debe considerar:
- Escalado automático de aplicaciones
Las aplicaciones sin servidor se escalan horizontalmente y el proveedor de la nube realiza automáticamente este " escalamiento horizontal" en función de la cantidad de invocaciones, por lo que el desarrollador no tiene que agregar o eliminar recursos manualmente cuando la aplicación tiene una gran carga. - Rentabilidad
Al estar impulsadas por eventos, las aplicaciones sin servidor se ejecutan solo cuando es necesario y esto se refleja en los cargos a medida que se facturan en función de la cantidad de tiempo invocado. - Flexibilidad
Las aplicaciones sin servidor están diseñadas para ser altamente reutilizables y esto significa que no están vinculadas a un solo proyecto o aplicación. Una funcionalidad particular puede extraerse en una aplicación sin servidor, implementarse y usarse en múltiples proyectos o aplicaciones. Las aplicaciones sin servidor también se pueden escribir en el idioma preferido del autor de la aplicación, aunque algunos proveedores de la nube solo admiten una cantidad menor de idiomas.
Al usar aplicaciones sin servidor, cada desarrollador tiene una amplia gama de proveedores de nube dentro de la nube pública para usar. En el contexto de este artículo, nos centraremos en las aplicaciones sin servidor en Google Cloud Platform: cómo se crean, administran, implementan y cómo también se integran con otros productos en Google Cloud. Para hacer esto, agregaremos nuevas funcionalidades a esta aplicación React existente mientras trabajamos en el proceso de:
- Almacenamiento y recuperación de datos de usuarios en la nube;
- Crear y administrar trabajos cron en Google Cloud;
- Implementación de Cloud Functions en Google Cloud.
Nota : las aplicaciones sin servidor no están vinculadas solo a React, siempre que su marco o biblioteca front-end preferido pueda realizar una solicitud HTTP , puede usar una aplicación sin servidor.
Funciones de la nube de Google
Google Cloud permite a los desarrolladores crear aplicaciones sin servidor usando Cloud Functions y ejecutarlas usando Functions Framework. Tal como se les llama, las funciones de la nube son funciones reutilizables impulsadas por eventos implementadas en Google Cloud para escuchar activadores específicos de los seis activadores de eventos disponibles y luego realizar la operación para la que fueron escritas.
Las funciones en la nube que son de corta duración ( con un tiempo de espera de ejecución predeterminado de 60 segundos y un máximo de 9 minutos ) pueden escribirse usando JavaScript, Python, Golang y Java y ejecutarse usando su tiempo de ejecución. En JavaScript, se pueden ejecutar usando solo algunas versiones disponibles del tiempo de ejecución de Node y se escriben en forma de módulos CommonJS usando JavaScript simple, ya que se exportan como la función principal para ejecutarse en Google Cloud.
Un ejemplo de una función en la nube es la siguiente, que es un modelo vacío para que la función maneje los datos de un usuario.
// index.js exports.firestoreFunction = function (req, res) { return res.status(200).send({ data: `Hello ${req.query.name}` }); } Arriba tenemos un módulo que exporta una función. Cuando se ejecuta, recibe los argumentos de solicitud y respuesta de forma similar a una ruta HTTP .
Nota : una función en la nube coincide con todos los protocolos HTTP cuando se realiza una solicitud. Vale la pena señalar esto cuando se esperan datos en el argumento de la solicitud, ya que los datos adjuntos al realizar una solicitud para ejecutar una función en la nube estarían presentes en el cuerpo de la solicitud para las solicitudes POST , mientras que en el cuerpo de la consulta para las solicitudes GET .
Las funciones de la nube se pueden ejecutar localmente durante el desarrollo instalando el paquete @google-cloud/functions-framework dentro de la misma carpeta donde se coloca la función escrita o realizando una instalación global para usarlo para múltiples funciones ejecutando npm i -g @google-cloud/functions-framework desde la línea de comandos. Una vez instalado, debe agregarse al script package.json con el nombre del módulo exportado similar al siguiente:
"scripts": { "start": "functions-framework --target=firestoreFunction --port=8000", } Arriba tenemos un solo comando dentro de nuestras secuencias de comandos en el archivo package.json que ejecuta el marco de funciones y también especifica firestoreFunction como la función de destino que se ejecutará localmente en el puerto 8000 .
Podemos probar el punto final de esta función haciendo una solicitud GET al puerto 8000 en localhost usando curl. Pegar el siguiente comando en una terminal hará eso y devolverá una respuesta.
curl https://localhost:8000?name="Smashing Magazine Author" El comando anterior realiza una solicitud con un método GET HTTP y responde con un código de estado 200 y un objeto de datos que contiene el nombre agregado en la consulta.
Implementación de una función en la nube
De los métodos de implementación disponibles, una forma rápida de implementar una función en la nube desde una máquina local es usar el Sdk en la nube después de instalarlo. Ejecutar el siguiente comando desde la terminal después de autenticar el SDK de gcloud con su proyecto en Google Cloud, implementaría una función creada localmente en el servicio Cloud Function.
gcloud functions deploy "demo-function" --runtime nodejs10 --trigger-http --entry-point=demo --timeout=60 --set-env-vars=[name="Developer"] --allow-unauthenticatedUsando los indicadores explicados a continuación, el comando anterior implementa una función activada por HTTP en la nube de Google con el nombre " función de demostración ".
- NOMBRE
Este es el nombre que se le da a una función de la nube cuando se implementa y es obligatorio. -
region
Esta es la región en la que se implementará la función de nube. De forma predeterminada, se implementa enus-central1. -
trigger-http
Esto selecciona HTTP como el tipo de activador de la función. -
allow-unauthenticated
Esto permite invocar la función fuera de Google Cloud a través de Internet utilizando su punto final generado sin verificar si la persona que llama está autenticada. -
source
Ruta local desde la terminal hasta el archivo que contiene la función a implementar. -
entry-point
Este es el módulo exportado específico que se implementará desde el archivo donde se escribieron las funciones. -
runtime
Este es el tiempo de ejecución de lenguaje que se usará para la función entre esta lista de tiempos de ejecución aceptados. -
timeout
Este es el tiempo máximo que una función puede ejecutarse antes de que se agote el tiempo de espera. Es de 60 segundos por defecto y se puede configurar a un máximo de 9 minutos.
Nota : Hacer que una función permita solicitudes no autenticadas significa que cualquier persona con el punto final de su función también puede realizar solicitudes sin que usted las conceda. Para mitigar esto, podemos asegurarnos de que el punto final permanezca privado usándolo a través de variables de entorno o solicitando encabezados de autorización en cada solicitud.
Ahora que nuestra función de demostración se ha implementado y tenemos el punto final, podemos probar esta función como si se estuviera usando en una aplicación del mundo real usando una instalación global de autocannon. Ejecutar autocannon -d=5 -c=300 CLOUD_FUNCTION_URL desde el terminal abierto generaría 300 solicitudes simultáneas a la función de nube dentro de una duración de 5 segundos. Esto es más que suficiente para iniciar la función de la nube y también generar algunas métricas que podemos explorar en el tablero de la función.
Nota : el punto final de una función se imprimirá en el terminal después de la implementación. Si no es el caso, ejecuta gcloud function describe FUNCTION_NAME desde la terminal para obtener los detalles sobre la función implementada, incluido el punto final.
Usando la pestaña de métricas en el tablero, podemos ver una representación visual de la última solicitud que consta de cuántas invocaciones se realizaron, cuánto duraron, la huella de memoria de la función y cuántas instancias se giraron para manejar las solicitudes realizadas.
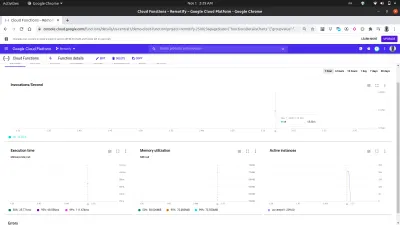
Una mirada más cercana al gráfico de instancias activas dentro de la imagen de arriba muestra la capacidad de escalado horizontal de las funciones de la nube, ya que podemos ver que se activaron 209 instancias en unos pocos segundos para manejar las solicitudes realizadas con el cañón automático.
Registros de funciones en la nube
Cada función implementada en la nube de Google tiene un registro y cada vez que se ejecuta esta función, se realiza una nueva entrada en ese registro. Desde la pestaña Registro en el tablero de la función, podemos ver una lista de todas las entradas de registros de una función en la nube.
A continuación se encuentran las entradas de registro de nuestra demo-function implementada creada como resultado de las solicitudes que hicimos usando autocannon .
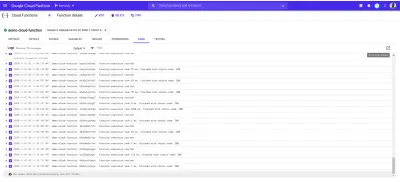
Cada una de las entradas de registro anteriores muestra exactamente cuándo se ejecutó una función, cuánto tiempo tomó la ejecución y con qué código de estado terminó. Si hay errores resultantes de una función, los detalles del error, incluida la línea en la que ocurrió, se mostrarán aquí en los registros.
El Explorador de registros en Google Cloud se puede usar para ver detalles más completos sobre los registros de una función en la nube.
Funciones en la nube con aplicaciones front-end
Las funciones de la nube son muy útiles y poderosas para los ingenieros front-end. Un ingeniero front-end sin el conocimiento de la administración de aplicaciones back-end puede extraer una funcionalidad en una función en la nube, implementarla en Google Cloud y usarla en una aplicación front-end al realizar solicitudes HTTP a la función en la nube a través de su punto final.
Para mostrar cómo se pueden usar las funciones de la nube en una aplicación front-end, agregaremos más funciones a esta aplicación React. La aplicación ya tiene un enrutamiento básico entre la autenticación y la configuración de las páginas de inicio. Lo expandiremos para usar la API React Context para administrar el estado de nuestra aplicación, ya que el uso de las funciones de la nube creadas se haría dentro de los reductores de la aplicación.
Para comenzar, creamos el contexto de nuestra aplicación usando la API createContext y también creamos un reductor para manejar las acciones dentro de nuestra aplicación.
// state/index.js import { createContext } from “react”;export const UserReducer = (acción, estado) => { switch (action.type) { case “CREATE-USER”: break; case “CARGAR-IMAGEN-DE-USUARIO”: break; case “FETCH-DATA”: romper case “LOGOUT”: romper; predeterminado: console.log(
${action.type} is not recognized) } };export const userState = { usuario: nulo, está conectado: falso };
export const UserContext = createContext(userState);
Arriba, comenzamos con la creación de una función UserReducer que contiene una declaración de cambio, lo que le permite realizar una operación basada en el tipo de acción que se le envía. La instrucción switch tiene cuatro casos y estas son las acciones que manejaremos. Por ahora no hacen nada todavía, pero cuando empecemos a integrarnos con nuestras funciones en la nube, iríamos implementando de forma incremental las acciones a realizar en ellas.
También creamos y exportamos el contexto de nuestra aplicación utilizando la API React createContext y le asignamos un valor predeterminado del objeto userState que contiene un valor de usuario actualmente que se actualizaría de nulo a los datos del usuario después de la autenticación y también un valor booleano isLoggedIn para saber si el usuario está conectado o no.
Ahora podemos proceder a consumir nuestro contexto, pero antes de hacerlo, debemos envolver todo nuestro árbol de aplicaciones con el proveedor adjunto al UserContext para que los componentes secundarios puedan suscribirse al cambio de valor de nuestro contexto.
// index.js import React from "react"; import ReactDOM from "react-dom"; import "./index.css"; import App from "./app"; import { UserContext, userState } from "./state/"; ReactDOM.render( <React.StrictMode> <UserContext.Provider value={userState}> <App /> </UserContext.Provider> </React.StrictMode>, document.getElementById("root") ); serviceWorker.unregister(); userState nuestra aplicación de entrada con el proveedor UserContext en el componente raíz y pasamos nuestro valor predeterminado de estado de usuario creado previamente en la propiedad de valor.
Ahora que tenemos el estado de nuestra aplicación completamente configurado, podemos pasar a crear el modelo de datos del usuario usando Google Cloud Firestore a través de una función en la nube.
Manejo de datos de la aplicación
Los datos de un usuario dentro de esta aplicación consisten en una identificación única, un correo electrónico, una contraseña y la URL de una imagen. Usando una función de nube, estos datos se almacenarán en la nube usando el servicio Cloud Firestore que se ofrece en Google Cloud Platform.
Google Cloud Firestore , una base de datos NoSQL flexible, se creó a partir de Firebase Realtime Database con nuevas funciones mejoradas que permiten consultas más ricas y rápidas junto con el soporte de datos sin conexión. Los datos dentro del servicio Firestore están organizados en colecciones y documentos similares a otras bases de datos NoSQL como MongoDB.
Se puede acceder visualmente a Firestore a través de Google Cloud Console. Para iniciarlo, abra el panel de navegación izquierdo y desplácese hacia abajo hasta la sección Base de datos y haga clic en Firestore. Eso mostraría la lista de colecciones para usuarios con datos existentes o solicitaría al usuario que cree una nueva colección cuando no haya una colección existente. Crearíamos una colección de usuarios para ser utilizada por nuestra aplicación.
Al igual que otros servicios en Google Cloud Platform, Cloud Firestore también tiene una biblioteca de cliente de JavaScript creada para usarse en un entorno de nodo ( se generará un error si se usa en el navegador ). Para improvisar, usamos Cloud Firestore en una función de nube usando el paquete @google-cloud/firestore .
Uso de Cloud Firestore con una función de nube
Para comenzar, cambiaremos el nombre de la primera función que creamos de demo-function a firestoreFunction y luego la expandiremos para conectarnos con Firestore y guardar datos en la colección de nuestros usuarios.
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const { SecretManagerServiceClient } = require("@google-cloud/secret-manager"); const client = new SecretManagerServiceClient(); exports.firestoreFunction = function (req, res) { return { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); console.log(document) // prints details of the collection to the function logs if (!type) { res.status(422).send("An action type was not specified"); } switch (type) { case "CREATE-USER": break case "LOGIN-USER": break; default: res.status(422).send(`${type} is not a valid function action`) } }; Para manejar más operaciones relacionadas con el almacén de incendios, hemos agregado una declaración de cambio con dos casos para manejar las necesidades de autenticación de nuestra aplicación. Nuestra declaración de cambio evalúa una expresión de type que agregamos al cuerpo de la solicitud cuando realizamos una solicitud a esta función desde nuestra aplicación y cada vez que este type de datos no está presente en nuestro cuerpo de solicitud, la solicitud se identifica como Solicitud incorrecta y un código de estado 400 junto con un mensaje para indicar que el type que falta se envía como respuesta.
Establecemos una conexión con Firestore mediante la biblioteca de Credenciales predeterminadas de la aplicación (ADC) dentro de la biblioteca cliente de Cloud Firestore. En la siguiente línea, llamamos al método de colección en otra variable y le pasamos el nombre de nuestra colección. Usaremos esto para realizar otras operaciones en la recopilación de los documentos contenidos.
Nota : las bibliotecas de clientes para servicios en Google Cloud se conectan a su servicio respectivo mediante una clave de cuenta de servicio creada que se pasa al inicializar el constructor. Cuando la clave de la cuenta de servicio no está presente, se usa de forma predeterminada las Credenciales predeterminadas de la aplicación que, a su vez, se conecta mediante los roles de IAM asignados a la función de nube.
Después de editar el código fuente de una función que se implementó localmente con el SDK de Gcloud, podemos volver a ejecutar el comando anterior desde una terminal para actualizar y volver a implementar la función en la nube.

Ahora que se ha establecido una conexión, podemos implementar el caso CREATE-USER para crear un nuevo usuario utilizando los datos del cuerpo de la solicitud.
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const path = require("path"); const { v4 : uuid } = require("uuid") const cors = require("cors")({ origin: true }); const client = new SecretManagerServiceClient(); exports.firestoreFunction = function (req, res) { return cors(req, res, () => { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); if (!type) { res.status(422).send("An action type was not specified"); } switch (type) { case "CREATE-USER": if (!email || !password) { res.status(422).send("email and password fields missing"); } const id = uuid() return bcrypt.genSalt(10, (err, salt) => { bcrypt.hash(password, salt, (err, hash) => { document.doc(id) .set({ id : id email: email, password: hash, img_uri : null }) .then((response) => res.status(200).send(response)) .catch((e) => res.status(501).send({ error : e }) ); }); }); case "LOGIN": break; default: res.status(400).send(`${type} is not a valid function action`) } }); }; Generamos un UUID utilizando el paquete uuid para ser utilizado como el ID del documento que se va a guardar pasándolo al método set en el documento y también al ID del usuario. De forma predeterminada, se genera una identificación aleatoria en cada documento insertado, pero en este caso, actualizaremos el documento cuando manejemos la carga de la imagen y el UUID es lo que se usará para actualizar un documento en particular. En lugar de almacenar la contraseña del usuario en texto sin formato, primero la salteamos usando bcryptjs y luego almacenamos el resultado hash como la contraseña del usuario.
Al integrar la función de nube firestoreFunction en la aplicación, la usamos desde el caso CREATE_USER dentro del reductor de usuarios.
Después de hacer clic en el botón Crear cuenta , se envía una acción a los reductores con un tipo CREATE_USER para realizar una solicitud POST que contiene el correo electrónico y la contraseña ingresados al extremo de la función firestoreFunction .
import { createContext } from "react"; import { navigate } from "@reach/router"; import Axios from "axios"; export const userState = { user : null, isLoggedIn: false, }; export const UserReducer = (state, action) => { switch (action.type) { case "CREATE_USER": const FIRESTORE_FUNCTION = process.env.REACT_APP_FIRESTORE_FUNCTION; const { userEmail, userPassword } = action; const data = { type: "CREATE-USER", email: userEmail, password: userPassword, }; Axios.post(`${FIRESTORE_FUNCTION}`, data) .then((res) => { navigate("/home"); return { ...state, isLoggedIn: true }; }) .catch((e) => console.log(`couldnt create user. error : ${e}`)); break; case "LOGIN-USER": break; case "UPLOAD-USER-IMAGE": break; case "FETCH-DATA" : break case "LOGOUT": navigate("/login"); return { ...state, isLoggedIn: false }; default: break; } }; export const UserContext = createContext(userState); Arriba, utilizamos Axios para realizar la solicitud a firestoreFunction y, una vez resuelta esta solicitud, configuramos el estado inicial del usuario de null a los datos devueltos por la solicitud y, por último, dirigimos al usuario a la página de inicio como un usuario autenticado. .
En este punto, un nuevo usuario puede crear una cuenta con éxito y ser redirigido a la página de inicio. Este proceso demuestra cómo usamos Firestore para realizar una creación básica de datos desde una función en la nube.
Manejo del almacenamiento de archivos
El almacenamiento y la recuperación de los archivos de un usuario en una aplicación es, en la mayoría de los casos, una característica muy necesaria dentro de una aplicación. En una aplicación conectada a un backend de node.js, Multer se usa a menudo como un middleware para manejar los datos de varias partes/formularios en los que se carga un archivo. Pero en ausencia del backend de node.js, podríamos usar un archivo en línea servicio de almacenamiento como Google Cloud Storage para almacenar activos de aplicaciones estáticas.
Google Cloud Storage es un servicio de almacenamiento de archivos disponible a nivel mundial que se utiliza para almacenar cualquier cantidad de datos como objetos para aplicaciones en depósitos. Es lo suficientemente flexible para manejar el almacenamiento de activos estáticos para aplicaciones pequeñas y grandes.
Para usar el servicio de almacenamiento en la nube dentro de una aplicación, podríamos usar los puntos finales de la API de almacenamiento disponibles o usar la biblioteca de cliente de almacenamiento del nodo oficial. Sin embargo, la biblioteca del cliente de Node Storage no funciona dentro de una ventana del navegador, por lo que podríamos usar una función de nube donde usaremos la biblioteca.
Un ejemplo de esto es la función de la nube a continuación, que conecta y carga un archivo en un cubo de la nube creado.
const cors = require("cors")({ origin: true }); const { Storage } = require("@google-cloud/storage"); const StorageClient = new Storage(); exports.Uploader = (req, res) => { const { file } = req.body; StorageClient.bucket("TEST_BUCKET") .file(file.name) .then((response) => { console.log(response); res.status(200).send(response) }) .catch((e) => res.status(422).send({error : e})); }); };Desde la función de nube anterior, estamos realizando las siguientes dos operaciones principales:
Primero, creamos una conexión con Cloud Storage dentro del
Storage constructorde Storage y utiliza la función Credenciales predeterminadas de la aplicación (ADC) en Google Cloud para autenticarse con Cloud Storage.En segundo lugar, subimos el archivo incluido en el cuerpo de la solicitud a nuestro
TEST_BUCKETllamando al método.filey pasando el nombre del archivo. Dado que se trata de una operación asíncrona, usamos una promesa para saber cuándo se ha resuelto esta acción y enviamos una respuesta200, finalizando así el ciclo de vida de la invocación.
Ahora, podemos expandir la función de Uploader en la nube de arriba para manejar la carga de la imagen de perfil de un usuario. La función en la nube recibirá la imagen de perfil de un usuario, la almacenará en el depósito en la nube de nuestra aplicación y luego actualizará los datos img_uri del usuario dentro de la colección de nuestros usuarios en el servicio Firestore.
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const cors = require("cors")({ origin: true }); const { Storage } = require("@google-cloud/storage"); const StorageClient = new Storage(); const BucketName = process.env.STORAGE_BUCKET exports.Uploader = (req, res) => { return Cors(req, res, () => { const { file , userId } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); StorageClient.bucket(BucketName) .file(file.name) .on("finish", () => { StorageClient.bucket(BucketName) .file(file.name) .makePublic() .then(() => { const img_uri = `https://storage.googleapis.com/${Bucket}/${file.path}`; document .doc(userId) .update({ img_uri, }) .then((updateResult) => res.status(200).send(updateResult)) .catch((e) => res.status(500).send(e)); }) .catch((e) => console.log(e)); }); }); };Ahora hemos ampliado la función Cargar anterior para realizar las siguientes operaciones adicionales:
- Primero, establece una nueva conexión con el servicio de Firestore para obtener nuestra colección de
usersal inicializar el constructor de Firestore y usa las Credenciales predeterminadas de la aplicación (ADC) para autenticarse con Cloud Storage. - Después de cargar el archivo agregado en el cuerpo de la solicitud, lo hacemos público para que sea accesible a través de una URL pública llamando al método
makePublicen el archivo cargado. De acuerdo con el Control de acceso predeterminado de Cloud Storage, sin hacer público un archivo, no se puede acceder a un archivo a través de Internet y poder hacerlo cuando se carga la aplicación.
Nota : hacer público un archivo significa que cualquier persona que use su aplicación puede copiar el enlace del archivo y tener acceso sin restricciones al archivo. Una forma de evitar esto es usar una URL firmada para otorgar acceso temporal a un archivo dentro de su depósito en lugar de hacerlo completamente público.
- A continuación, actualizamos los datos existentes del usuario para incluir la URL del archivo cargado. Encontramos los datos del usuario en particular usando la consulta
WHEREde Firestore y usamos eluserIdde usuario incluido en el cuerpo de la solicitud, luego configuramos el campoimg_uripara que contenga la URL de la imagen recién actualizada.
La función Upload nube anterior se puede usar dentro de cualquier aplicación que tenga usuarios registrados dentro del servicio Firestore. Todo lo que se necesita para realizar una solicitud POST al punto final, colocando el IS del usuario y una imagen en el cuerpo de la solicitud.
Un ejemplo de esto dentro de la aplicación es el caso UPLOAD-FILE que realiza una solicitud POST a la función y coloca el enlace de imagen devuelto por la solicitud en el estado de la aplicación.
# index.js import Axios from 'axios' const UPLOAD_FUNCTION = process.env.REACT_APP_UPLOAD_FUNCTION export const UserReducer = (state, action) => { switch (action.type) { case "CREATE-USER" : # .....CREATE-USER-LOGIC .... case "UPLOAD-FILE": const { file, id } = action return Axios.post(UPLOAD_FUNCTION, { file, id }, { headers: { "Content-Type": "image/png", }, }) .then((response) => {}) .catch((e) => console.log(e)); default : return console.log(`${action.type} case not recognized`) } } Desde el caso de cambio anterior, hacemos una solicitud POST usando Axios a UPLOAD_FUNCTION pasando el archivo agregado para que se incluya en el cuerpo de la solicitud y también agregamos un Content-Type imagen en el encabezado de la solicitud.
Después de una carga exitosa, la respuesta devuelta por la función de la nube contiene el documento de datos del usuario que se actualizó para contener una URL válida de la imagen cargada en el almacenamiento en la nube de Google. Luego podemos actualizar el estado del usuario para que contenga los nuevos datos y esto también actualizará el elemento src de la imagen de perfil del usuario en el componente de perfil.
Manejo de trabajos cron
Las tareas automatizadas repetitivas, como enviar correos electrónicos a los usuarios o realizar una acción interna en un momento específico, son, en la mayoría de los casos, una característica incluida en las aplicaciones. En una aplicación normal de node.js, tales tareas podrían manejarse como trabajos cron utilizando node-cron o node-schedule. Al crear aplicaciones sin servidor con Google Cloud Platform, Cloud Scheduler también está diseñado para realizar una operación cron.
Nota : aunque Cloud Scheduler funciona de manera similar a la utilidad cron de Unix en la creación de trabajos que se ejecutarán en el futuro, es importante tener en cuenta que Cloud Scheduler no ejecuta un comando como lo hace la utilidad cron. Más bien, realiza una operación utilizando un objetivo específico.
Como su nombre lo indica, Cloud Scheduler permite a los usuarios programar una operación para que se realice en un momento futuro. Cada operación se denomina trabajo y los trabajos se pueden crear, actualizar e incluso destruir visualmente desde la sección Programador de Cloud Console. Además de un campo de nombre y descripción, los trabajos en Cloud Scheduler consisten en lo siguiente:
- Frecuencia
Esto se usa para programar la ejecución del trabajo Cron. Los horarios se especifican utilizando el formato unix-cron que se usa originalmente al crear trabajos en segundo plano en la tabla cron en un entorno Linux. El formato unix-cron consta de una cadena con cinco valores, cada uno de los cuales representa un punto de tiempo. A continuación podemos ver cada una de las cinco cadenas y los valores que representan.
- - - - - - - - - - - - - - - - minute ( - 59 ) | - - - - - - - - - - - - - hour ( 0 - 23 ) | | - - - - - - - - - - - - day of month ( 1 - 31 ) | | | - - - - - - - - - month ( 1 - 12 ) | | | | - - - - - -- day of week ( 0 - 6 ) | | | | | | | | | | | | | | | | | | | | | | | | | * * * * *La herramienta generadora Crontab es útil cuando se intenta generar un valor de tiempo de frecuencia para un trabajo. Si le resulta difícil juntar los valores de tiempo, el generador Crontab tiene un menú desplegable visual donde puede seleccionar los valores que componen un horario y copiar el valor generado y usarlo como frecuencia.
- Zona horaria
La zona horaria desde donde se ejecuta el trabajo cron. Debido a la diferencia horaria entre las zonas horarias, los trabajos cron ejecutados con diferentes zonas horarias especificadas tendrán diferentes tiempos de ejecución. - Objetivo
Esto es lo que se utiliza en la ejecución del Trabajo especificado. Un objetivo podría ser un tipoHTTPen el que el trabajo realiza una solicitud en el momento especificado a la URL o un tema de Pub/Sub en el que el trabajo puede publicar mensajes o extraer mensajes y, por último, una aplicación de App Engine.
Cloud Scheduler se combina perfectamente con las funciones de nube activadas por HTTP. Cuando se crea un trabajo dentro de Cloud Scheduler con su destino establecido en HTTP, este trabajo se puede usar para ejecutar una función en la nube. Todo lo que se necesita hacer es especificar el punto final de la función de la nube, especificar el verbo HTTP de la solicitud y luego agregar los datos que se deben pasar para que funcionen en el campo del cuerpo que se muestra. Como se muestra en el siguiente ejemplo:
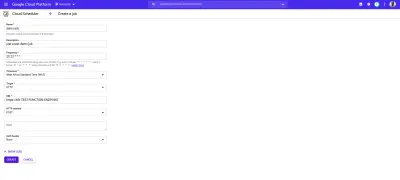
El trabajo cron en la imagen de arriba se ejecutará a las 9 a.m. todos los días haciendo una solicitud POST al punto final de muestra de una función en la nube.
Un caso de uso más realista de un trabajo cron es enviar correos electrónicos programados a los usuarios en un intervalo determinado utilizando un servicio de correo externo como Mailgun. Para ver esto en acción, crearemos una nueva función en la nube que envíe un correo electrónico HTML a una dirección de correo electrónico específica utilizando el paquete de JavaScript nodemailer para conectarse a Mailgun:
# index.js require("dotenv").config(); const nodemailer = require("nodemailer"); exports.Emailer = (req, res) => { let sender = process.env.SENDER; const { reciever, type } = req.body var transport = nodemailer.createTransport({ host: process.env.HOST, port: process.env.PORT, secure: false, auth: { user: process.env.SMTP_USERNAME, pass: process.env.SMTP_PASSWORD, }, }); if (!reciever) { res.status(400).send({ error: `Empty email address` }); } transport.verify(function (error, success) { if (error) { res .status(401) .send({ error: `failed to connect with stmp. check credentials` }); } }); switch (type) { case "statistics": return transport.sendMail( { from: sender, to: reciever, subject: "Your usage satistics of demo app", html: { path: "./welcome.html" }, }, (error, info) => { if (error) { res.status(401).send({ error : error }); } transport.close(); res.status(200).send({data : info}); } ); default: res.status(500).send({ error: "An available email template type has not been matched.", }); } };Using the cloud function above we can send an email to any user's email address specified as the receiver value in the request body. It performs the sending of emails through the following steps:
- It creates an SMTP transport for sending messages by passing the
host,userandpasswhich stands for password, all displayed on the user's Mailgun dashboard when a new account is created. - Next, it verifies if the SMTP transport has the credentials needed in order to establish a connection. If there's an error in establishing the connection, it ends the function's invocation and sends back a
401 unauthenticatedstatus code. - Next, it calls the
sendMailmethod to send the email containing the HTML file as the email's body to the receiver's email address specified in thetofield.
Note : We use a switch statement in the cloud function above to make it more reusable for sending several emails for different recipients. This way we can send different emails based on the type field included in the request body when calling this cloud function.
Now that there is a function that can send an email to a user; we are left with creating the cron job to invoke this cloud function. This time, the cron jobs are created dynamically each time a new user is created using the official Google cloud client library for the Cloud Scheduler from the initial firestoreFunction .
We expand the CREATE-USER case to create the job which sends the email to the created user at a one-day interval.
require("dotenv").config();cloc const { Firestore } = require("@google-cloud/firestore"); const scheduler = require("@google-cloud/scheduler") const cors = require("cors")({ origin: true }); const EMAILER = proccess.env.EMAILER_ENDPOINT const parent = ScheduleClient.locationPath( process.env.PROJECT_ID, process.env.LOCATION_ID ); exports.firestoreFunction = function (req, res) { return cors(req, res, () => { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); const client = new Scheduler.CloudSchedulerClient() if (!type) { res.status(422).send({ error : "An action type was not specified"}); } switch (type) { case "CREATE-USER":const job = { httpTarget: { uri: process.env.EMAIL_FUNCTION_ENDPOINT, httpMethod: "POST", body: { email: email, }, }, schedule: "*/30 */6 */5 10 4", timezone: "Africa/Lagos", }if (!email || !password) { res.status(422).send("email and password fields missing"); } return bcrypt.genSalt(10, (err, salt) => { bcrypt.hash(password, salt, (err, hash) => { document .add({ email: email, password: hash, }) .then((response) => {client.createJob({ parent : parent, job : job }).then(() => res.status(200).send(response)) .catch(e => console.log(`unable to create job : ${e}`) )}) .catch((e) => res.status(501).send(`error inserting data : ${e}`) ); }); }); default: res.status(422).send(`${type} is not a valid function action`) } }); };
From the snippet above, we can see the following:
- A connection to the Cloud Scheduler from the Scheduler constructor using the Application Default Credentials (ADC) is made.
- We create an object consisting of the following details which make up the cron job to be created:
-
uri
The endpoint of our email cloud function in which a request would be made to. -
body
This is the data containing the email address of the user to be included when the request is made. -
schedule
The unix cron format representing the time when this cron job is to be performed.
-
- After the promise from inserting the user's data document is resolved, we create the cron job by calling the
createJobmethod and passing in the job object and the parent. - The function's execution is ended with a
200status code after the promise from thecreateJoboperation has been resolved.
After the job is created, we'll see it listed on the scheduler page.
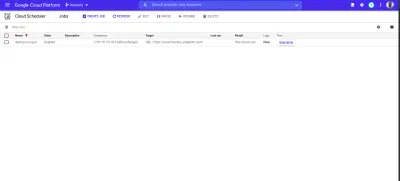
From the image above we can see the time scheduled for this job to be executed. We can decide to manually run this job or wait for it to be executed at the scheduled time.
Conclusión
Within this article, we have had a good look into serverless applications and the benefits of using them. We also had an extensive look at how developers can manage their serverless applications on the Google Cloud using Cloud Functions so you now know how the Google Cloud is supporting the use of serverless applications.
Within the next years to come, we will certainly see a large number of developers adapt to the use of serverless applications when building applications. If you are using cloud functions in a production environment, it is recommended that you read this article from a Google Cloud advocate on “6 Strategies For Scaling Your Serverless Applications”.
The source code of the created cloud functions are available within this Github repository and also the used front-end application within this Github repository. The front-end application has been deployed using Netlify and can be tested live here.
Referencias
- Nube de Google
- Cloud Functions
- Cloud Source Repositories
- Cloud Scheduler overview
- Tienda de fuego en la nube
- “6 Strategies For Scaling Your Serverless Applications,” Preston Holmes