
Herramientas de datos cuantitativos para diseñadores de UX
Publicado: 2022-03-10Muchos diseñadores de UX tienen un poco de miedo a los datos, ya que creen que requieren un conocimiento profundo de las estadísticas y las matemáticas. Si bien eso puede ser cierto para la ciencia de datos avanzada, no lo es para el análisis de datos de investigación básica que requieren la mayoría de los diseñadores de UX. Dado que vivimos en un mundo cada vez más basado en datos, la alfabetización básica en datos es útil para casi cualquier profesional, no solo para los diseñadores de UX.
Aaron Gitlin, diseñador de interacción en Google, argumenta que muchos diseñadores aún no se basan en datos:
“Si bien muchas empresas se promocionan a sí mismas como basadas en datos, la mayoría de los diseñadores se guían por el instinto, la colaboración y los métodos de investigación cualitativos”.
— Aaron Gitlin, "Convertirse en un diseñador consciente de los datos"
Con este artículo, me gustaría brindarles a los diseñadores de UX el conocimiento y las herramientas para incorporar datos en sus rutinas diarias.
Pero primero, algunos conceptos de datos
En este artículo hablaré sobre datos estructurados, es decir, datos que se pueden representar en una tabla, con filas y columnas. Los datos no estructurados, al ser un tema en sí mismo, son más difíciles de analizar, como señaló Devin Pickell (especialista en marketing de contenido de G2 Crowd, que escribe sobre datos y análisis) en su artículo "Datos estructurados frente a datos no estructurados: ¿cuál es la diferencia?". Si los datos estructurados se pueden representar en forma de tabla, los conceptos principales son:
conjunto de datos
Todo el conjunto de datos que pretendemos analizar. Esto podría ser, por ejemplo, una tabla de Excel. Otro formato popular para almacenar conjuntos de datos es el archivo de valores separados por comas (CSV). Los archivos CSV son archivos de texto simples que se utilizan para almacenar información similar a una tabla. Cada fila CSV corresponde a una fila en la tabla, y cada fila CSV tiene valores separados (naturalmente) por comas, que corresponden a las celdas de la tabla.
Punto de datos
Una sola fila de una tabla de conjunto de datos es un punto de datos. De esa manera, un conjunto de datos es una colección de puntos de datos.
Variable de datos
Un solo valor de una fila de puntos de datos representa una variable de datos; en pocas palabras, una celda de tabla. Podemos tener dos tipos de variables de datos: variables cualitativas y variables cuantitativas. Las variables cualitativas (también conocidas como variables categóricas) tienen un conjunto discreto de valores, como color = red/green/blue . Las variables cuantitativas tienen valores numéricos, como height = 167 . Una variable cuantitativa, a diferencia de una cualitativa, puede tomar cualquier valor.
Creando nuestro proyecto de datos
Ahora que conocemos los conceptos básicos, es hora de ensuciarse las manos y crear nuestro primer proyecto de datos. El alcance del proyecto es analizar un conjunto de datos pasando por todo el flujo de datos de importación, procesamiento y trazado de datos. Primero, elegiremos nuestro conjunto de datos, luego descargaremos e instalaremos las herramientas para analizar los datos.
Conjunto de datos de coches
A los efectos de este artículo, he elegido un conjunto de datos de automóviles porque es simple e intuitivo. El análisis de datos simplemente confirmará lo que ya sabemos sobre los autos, lo cual está bien, ya que nuestro enfoque está en el flujo de datos y las herramientas.
Podemos descargar un conjunto de datos de autos usados de Kaggle, una de las mayores fuentes de conjuntos de datos gratuitos. Tendrás que registrarte primero.
Después de descargar el archivo, ábralo y eche un vistazo. Es un archivo CSV realmente grande, pero debería entender lo esencial. Una línea en este archivo se verá así:
19500,2015,2965,Miami,FL,WBA3B1G54FNT02351,BMW,3Como puede ver, este punto de datos tiene varias variables separadas por comas. Ya que ahora tenemos el conjunto de datos, hablemos un poco sobre las herramientas.
Herramientas del oficio
Usaremos el lenguaje R y RStudio para analizar el conjunto de datos. R es un lenguaje muy popular y fácil de aprender, utilizado no solo por científicos de datos, sino también por personas en los mercados financieros, la medicina y muchas otras áreas. RStudio es el entorno donde se desarrollan los proyectos de R, y existe una versión gratuita, más que suficiente para nuestras necesidades como diseñadores de UX.
Es probable que algunos diseñadores de UX usen Excel para su flujo de trabajo de datos. Si eso significa que usted, pruebe R: es muy probable que le guste, ya que es fácil de aprender y más flexible y poderoso que Excel. Agregar R a su kit de herramientas hará la diferencia.
Instalación de las herramientas
Primero, necesitamos descargar e instalar R y RStudio. Primero debe instalar R, luego RStudio. Los procesos de instalación de R y RStudio son simples y directos.
Configuración del proyecto
Una vez que se complete la instalación, cree una carpeta de proyecto; la he llamado used-cars-prj . En esa carpeta, cree una subcarpeta llamada data y luego copie el archivo del conjunto de datos (descargado de Kaggle) en esa carpeta y cámbiele el nombre a used-cars.csv . Ahora regrese a nuestra carpeta de proyecto ( used-cars-prj ) y cree un archivo de texto sin formato llamado used-cars.r . Debería terminar con la misma estructura que en la captura de pantalla a continuación.
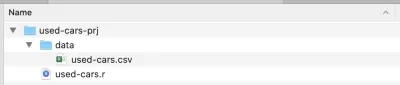
Ahora que tenemos la estructura de carpetas en su lugar, podemos abrir RStudio y crear un nuevo proyecto R. Elija Nuevo proyecto... en el menú Archivo y seleccione la segunda opción, Directorio existente . Luego seleccione el directorio del proyecto ( used-cars-prj ). Finalmente, presione el botón Crear proyecto y listo. Una vez que se crea el proyecto, abra used-cars.r en RStudio; este es el archivo donde agregaremos todo nuestro código R.
Importación de datos
Agregaremos nuestra primera línea en used-cars.r , para leer datos del archivo used-cars.csv . Recuerde que los archivos CSV son solo archivos de texto sin formato que se utilizan para almacenar datos. Nuestra primera línea de código R se verá así:
cars <- read.csv("./data/used-cars.csv", stringsAsFactors = FALSE, sep=",") Puede parecer un poco intimidante, pero en realidad no lo es; por cierto, esta es la línea más compleja de todo el artículo. Lo que tenemos aquí es la función read.csv , que toma tres parámetros.
El primer parámetro es el archivo a leer, en nuestro caso used-cars.csv , que se encuentra en la carpeta de datos . El segundo parámetro, stringsAsFactors=FALSE , se establece para asegurarse de que cadenas como "BMW" o "Audi" no se conviertan en factores (la jerga R para datos categóricos); como recordará, las variables cualitativas o categóricas solo pueden tener valores discretos como red/green/blue . Finalmente, el tercer parámetro, sep="," especifica el tipo de separador utilizado para separar los valores en el archivo CSV: una coma.
Después de leer el archivo CSV, los datos se almacenan en el objeto de marco de datos de cars . Un marco de datos es una estructura de datos bidimensional (como una tabla de Excel), que es muy útil en R para manipular datos. Después de introducir la línea y ejecutarla, se creará un marco de datos de cars para usted. Si mira en el cuadrante superior derecho en RStudio, notará el marco de datos de los cars , en la sección Datos en la pestaña Entorno . Si hace doble clic en autos , se abrirá una nueva pestaña en el cuadrante superior izquierdo de RStudio y presentará el marco de datos de cars . Como era de esperar, parece una tabla de Excel.
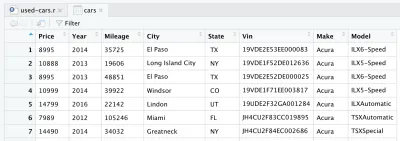
Estos son en realidad los datos sin procesar que descargamos de Kaggle. Pero como queremos realizar un análisis de datos, primero debemos procesar nuestro conjunto de datos.
Procesamiento de datos
Por procesamiento, nos referimos a eliminar, transformar o agregar información a nuestro conjunto de datos, a fin de prepararnos para el tipo de análisis que queremos realizar. Tenemos los datos en un objeto de marco de datos, por lo que ahora necesitamos instalar la biblioteca dplyr , una biblioteca poderosa para manipular datos. Para instalar la biblioteca en nuestro entorno R, debemos escribir la siguiente línea en la parte superior de nuestro archivo R.
install.packages("dplyr")Luego, para agregar la biblioteca a nuestro proyecto actual, usaremos la siguiente línea:
library(dplyr) Una vez que se ha agregado la biblioteca dplyr a nuestro proyecto, podemos comenzar a procesar los datos. Tenemos un conjunto de datos realmente grande, y solo necesitamos los datos que representan el mismo fabricante y modelo de automóvil para correlacionarlos con el precio. Usaremos el siguiente código R para mantener solo los datos relacionados con el BMW Serie 3 y eliminar el resto. Por supuesto, puede elegir cualquier otro fabricante y modelo del conjunto de datos y esperar tener las mismas características de datos.
cars <- cars %>% filter(Make == "BMW", Model == "3")Ahora tenemos un conjunto de datos más manejable, aunque aún contiene más de 11 000 puntos de datos, que se ajusta a nuestro propósito previsto: analizar las distribuciones de precio, edad y kilometraje de los automóviles, y también las correlaciones entre ellos. Para eso, debemos mantener solo las columnas "Precio", "Año" y "Millas" y eliminar el resto; esto se hace con la siguiente línea.
cars <- cars %>% select(Price, Year, Mileage)Después de eliminar otras columnas, nuestro marco de datos se verá así:

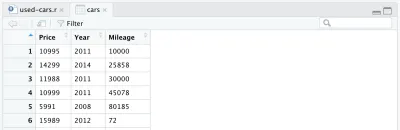
Hay un cambio más que queremos hacer en nuestro conjunto de datos: reemplazar el año de fabricación con la edad del automóvil. Podemos agregar las siguientes dos líneas, la primera para calcular la edad, la segunda para cambiar el nombre de la columna.
cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Finalmente, nuestro marco de datos procesado completo se ve así:
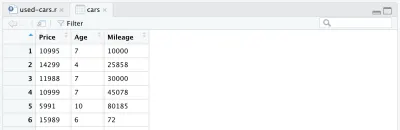
En este punto, nuestro código R se verá como el siguiente, y eso es todo para el procesamiento de datos. Ahora podemos ver lo fácil y poderoso que es el lenguaje R. Procesamos el conjunto de datos inicial de manera espectacular con solo unas pocas líneas de código.
install.packages("dplyr") library(dplyr) cars = read.csv("./data/cars.csv", stringsAsFactors = FALSE, sep=",") cars <- cars %>% filter(Make == "BMW", Model == "3") cars <- cars %>% select(Price, Year, Mileage) cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Análisis de los datos
Nuestros datos ahora están en la forma correcta, por lo que podemos ir a hacer algunos gráficos. Como ya se ha mencionado, nos centraremos en dos aspectos: la distribución de las variables individuales y las correlaciones entre ellas. La distribución variable nos ayuda a comprender qué se considera un precio medio o alto para un automóvil usado, o el porcentaje de automóviles por encima de un precio específico. Lo mismo se aplica a la edad y el kilometraje de los coches. Las correlaciones, por otro lado, son útiles para comprender cómo se relacionan entre sí variables como la edad y el kilometraje.
Dicho esto, utilizaremos dos tipos de visualización de datos: histogramas para la distribución de variables y diagramas de dispersión para las correlaciones.
Distribución de precios
Trazar el histograma de precios de automóviles en el lenguaje R es tan fácil como esto:
hist(cars$Price)Un pequeño consejo: si estás en RStudio puedes ejecutar el código línea por línea; por ejemplo, en nuestro caso, solo necesita ejecutar la línea anterior para mostrar el histograma. No es necesario volver a ejecutar todo el código ya que ya lo ejecutó una vez. El histograma debería verse así:
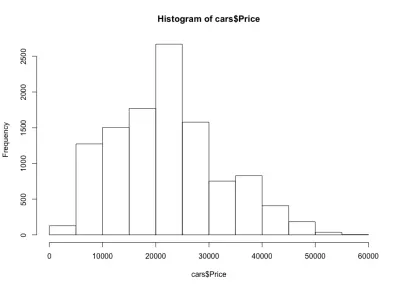
Si observamos el histograma, notamos una distribución en forma de campana de los precios de los autos, que es lo que esperábamos. La mayoría de los autos caen en el rango medio, y tenemos cada vez menos a medida que nos movemos a cada lado. Casi el 80% de los autos están entre $10,000 y $30,000 USD, y tenemos un máximo de más de 2,500 autos entre $20,000 y $25,000 USD. En el lado izquierdo tenemos probablemente alrededor de 150 autos de menos de $5,000 USD, y en el lado derecho incluso menos. Podemos ver fácilmente cuán útiles son estos gráficos para obtener información sobre los datos.
Distribución de edad
Al igual que con los precios de los autos, usaremos una línea similar para trazar el histograma de edad de los autos.
hist(cars$Age)Y aquí está el histograma:
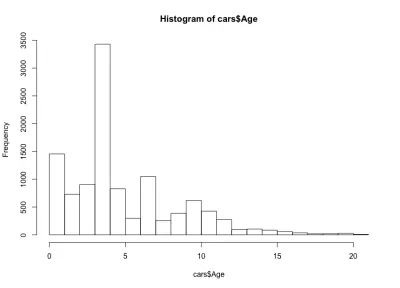
Esta vez, el histograma parece contradictorio: en lugar de una simple forma de campana, aquí tenemos cuatro campanas. Básicamente, la distribución tiene tres máximos locales y uno global, lo cual es inesperado. Sería interesante ver si esta extraña distribución de las edades de los autos se mantiene para otro fabricante y modelo de auto. A los efectos de este artículo, nos quedaremos con el conjunto de datos de la Serie 3 de BMW, pero puede profundizar en los datos si tiene curiosidad. Con respecto a la distribución de edad de nuestros autos, notamos que más del 90% de los autos tienen menos de 10 años y más del 80% menos de 7 años. Además, notamos que la mayoría de los autos tienen menos de 5 años.
Distribución de kilometraje
Ahora, ¿qué podemos decir sobre el kilometraje? Por supuesto, esperamos tener la misma forma de campana que teníamos por precio. Aquí está el código R y el histograma:
hist(cars$Mileage) 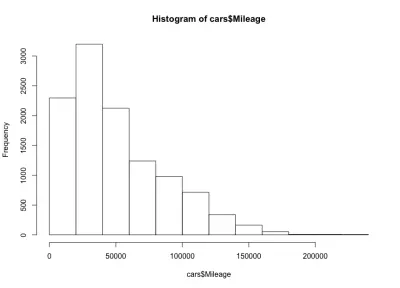
Aquí tenemos una forma de campana sesgada hacia la izquierda, lo que significa que hay más autos con menos kilometraje en el mercado. También notamos que la mayoría de los autos tienen menos de 60,000 millas, y tenemos un máximo de 20,000 a 40,000 millas.
Correlación edad-precio
Con respecto a las correlaciones, echemos un vistazo más de cerca a la correlación edad-precio de los automóviles. Podríamos esperar que el precio esté negativamente correlacionado con la edad: a medida que aumenta la edad de un automóvil, su precio bajará. Usaremos la función plot R para mostrar la correlación precio-edad de la siguiente manera:
plot(cars$Age, cars$Price)Y la trama se ve así:
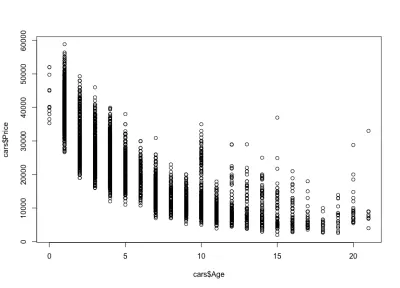
Notamos cómo los precios de los autos bajan con la edad: hay autos nuevos caros y autos viejos más baratos. También podemos ver el intervalo de variación del precio para cualquier edad específica, variación que decrece con la edad del auto. Esta variación se debe en gran medida al kilometraje, la configuración y el estado general del automóvil. Por ejemplo, en el caso de un auto de 4 años, el precio varía entre $10,000 y $40,000 USD.
Correlación entre kilometraje y edad
Teniendo en cuenta la correlación entre el kilometraje y la edad, esperaríamos que el kilometraje aumentara con la edad, lo que significa una correlación positiva. Aquí está el código:
plot(cars$Mileage, cars$Age)Y aquí está la trama:
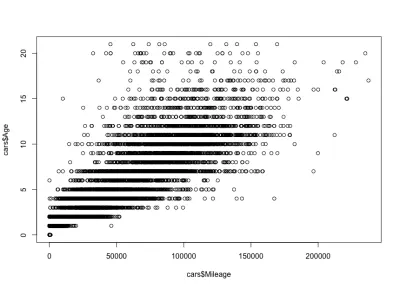
Como puede ver, la antigüedad y el kilometraje de un automóvil están correlacionados positivamente, a diferencia del precio y la antigüedad de un automóvil, que están correlacionados negativamente. También tenemos una variación de millaje esperado para una edad específica; es decir, los autos de la misma edad tienen diferentes millajes. Por ejemplo, la mayoría de los autos de 4 años tienen un kilometraje entre 10,000 y 80,000 millas. Pero también hay valores atípicos, con un mayor kilometraje.
Correlación kilometraje-precio
Como era de esperar, habrá una correlación negativa entre el kilometraje de los automóviles y el precio, lo que significa que aumentar el kilometraje reduce el precio.
plot(cars$Mileage, cars$Price)Y aquí está la trama:
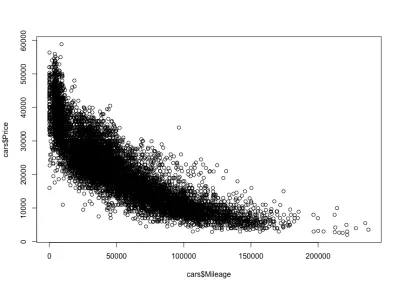
Como esperábamos, una correlación negativa. También podemos notar el intervalo de precio bruto entre $3,000 y $50,000 USD, y el kilometraje entre 0 y 150,000. Si observamos más de cerca la forma de distribución, vemos que el precio baja mucho más rápido para los autos con menos kilometraje que para los autos con más kilometraje. Hay coches con un kilometraje casi nulo, donde el precio baja drásticamente. Además, por encima del rango de 200,000 millas, porque el kilometraje es muy alto, el precio se mantiene constante.
De números a visualizaciones de datos
En este artículo, usamos dos tipos de visualización: histogramas para distribuciones de datos y diagramas de dispersión para correlaciones de datos. Los histogramas son representaciones visuales que toman los valores de una variable de datos ( números reales) y muestran cómo se distribuyen en un rango. Usamos la función R hist() para trazar un histograma.
Los diagramas de dispersión, por otro lado, toman pares de números y los representan en dos ejes. Los diagramas de dispersión utilizan la función plot() y proporcionan dos parámetros: la primera y la segunda variables de datos de la correlación que queremos investigar. Por lo tanto, las dos funciones R, hist() y plot() nos ayudan a traducir conjuntos de números en representaciones visuales significativas.
Conclusión
Habiéndonos ensuciado las manos al pasar por todo el flujo de datos de importación, procesamiento y trazado de datos, las cosas se ven mucho más claras ahora. Puede aplicar el mismo flujo de datos a cualquier conjunto de datos nuevo y brillante que encuentre. En la investigación de usuarios, por ejemplo, podría graficar el tiempo en las distribuciones de tareas o errores, y también podría trazar una correlación de tiempo en tareas versus errores.
Para obtener más información sobre el lenguaje R, Quick-R es un buen lugar para comenzar, pero también podría considerar R Bloggers. Para obtener documentación sobre paquetes de R, como dplyr , puede visitar RDocumentation. Jugar con datos puede ser divertido, pero también es extremadamente útil para cualquier diseñador de UX en un mundo basado en datos. A medida que se recopilan y utilizan más datos para informar las decisiones comerciales, existe una mayor posibilidad de que los diseñadores trabajen en la visualización de datos o productos de datos, donde la comprensión de la naturaleza de los datos es esencial.