
Mantener Node.js rápido: herramientas, técnicas y consejos para crear servidores Node.js de alto rendimiento
Publicado: 2022-03-10Si ha estado creando algo con Node.js durante el tiempo suficiente, entonces sin duda ha experimentado el dolor de los problemas de velocidad inesperados. JavaScript es un lenguaje asíncrono con eventos. Eso puede hacer que el razonamiento sobre el rendimiento sea complicado , como se hará evidente. La creciente popularidad de Node.js ha expuesto la necesidad de herramientas, técnicas e ideas adecuadas a las limitaciones de JavaScript del lado del servidor.
Cuando se trata de rendimiento, lo que funciona en el navegador no necesariamente se adapta a Node.js. Entonces, ¿cómo nos aseguramos de que una implementación de Node.js sea rápida y adecuada para su propósito? Veamos un ejemplo práctico.
Herramientas
Node es una plataforma muy versátil, pero una de las aplicaciones predominantes es la creación de procesos en red. Nos centraremos en perfilar los más comunes de estos: servidores web HTTP.
Necesitaremos una herramienta que pueda explotar un servidor con muchas solicitudes mientras mide el rendimiento. Por ejemplo, podemos usar AutoCannon:
npm install -g autocannonOtras buenas herramientas de evaluación comparativa de HTTP incluyen Apache Bench (ab) y wrk2, pero AutoCannon está escrito en Node, proporciona una presión de carga similar (o a veces mayor) y es muy fácil de instalar en Windows, Linux y Mac OS X.
Una vez que hayamos establecido una medición de rendimiento de referencia, si decidimos que nuestro proceso podría ser más rápido, necesitaremos alguna forma de diagnosticar los problemas con el proceso. Una gran herramienta para diagnosticar varios problemas de rendimiento es Node Clinic, que también se puede instalar con npm:
npm install -g clinicEsto realmente instala un conjunto de herramientas. Usaremos Clinic Doctor y Clinic Flame (un envoltorio alrededor de 0x) a medida que avanzamos.
Nota : para este ejemplo práctico, necesitaremos Node 8.11.2 o superior.
El código
Nuestro caso de ejemplo es un servidor REST simple con un solo recurso: una gran carga JSON expuesta como una ruta GET en /seed/v1 . El servidor es una carpeta de app que consta de un archivo package.json (según restify 7.1.0 ), un archivo index.js y un archivo util.js.
El archivo index.js para nuestro servidor se ve así:
'use strict' const restify = require('restify') const { etagger, timestamp, fetchContent } = require('./util')() const server = restify.createServer() server.use(etagger().bind(server)) server.get('/seed/v1', function (req, res, next) { fetchContent(req.url, (err, content) => { if (err) return next(err) res.send({data: content, url: req.url, ts: timestamp()}) next() }) }) server.listen(3000) Este servidor es representativo del caso común de servir contenido dinámico almacenado en caché del cliente. Esto se logra con el middleware etagger , que calcula un encabezado ETag para el estado más reciente del contenido.
El archivo util.js proporciona piezas de implementación que se usarían comúnmente en tal escenario, una función para obtener el contenido relevante de un backend, el middleware etag y una función de marca de tiempo que proporciona marcas de tiempo minuto a minuto:
'use strict' require('events').defaultMaxListeners = Infinity const crypto = require('crypto') module.exports = () => { const content = crypto.rng(5000).toString('hex') const ONE_MINUTE = 60000 var last = Date.now() function timestamp () { var now = Date.now() if (now — last >= ONE_MINUTE) last = now return last } function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } function fetchContent (url, cb) { setImmediate(() => { if (url !== '/seed/v1') cb(Object.assign(Error('Not Found'), {statusCode: 404})) else cb(null, content) }) } return { timestamp, etagger, fetchContent } }¡De ninguna manera tome este código como un ejemplo de las mejores prácticas! Hay varios olores de código en este archivo, pero los localizaremos a medida que medimos y perfilamos la aplicación.
Para obtener la fuente completa de nuestro punto de partida, el servidor lento se puede encontrar aquí.
perfilado
Para perfilar, necesitamos dos terminales, uno para iniciar la aplicación y el otro para realizar pruebas de carga.
En una terminal, dentro de la carpeta de la app , podemos ejecutar:
node index.jsEn otro terminal podemos perfilarlo así:
autocannon -c100 localhost:3000/seed/v1Esto abrirá 100 conexiones simultáneas y bombardeará el servidor con solicitudes durante diez segundos.
Los resultados deberían ser algo similar a lo siguiente (ejecutando la prueba de 10s @ https://localhost:3000/seed/v1 — 100 conexiones):
| Estadística | Promedio | Desvst. | máx. |
|---|---|---|---|
| Latencia (ms) | 3086.81 | 1725.2 | 5554 |
| Requerido/seg | 23.1 | 19.18 | sesenta y cinco |
| Bytes/seg | 237,98 KB | 197,7 KB | 688,13 KB |
Los resultados variarán dependiendo de la máquina. Sin embargo, considerando que un servidor Node.js de "Hello World" es fácilmente capaz de realizar treinta mil solicitudes por segundo en esa máquina que produjo estos resultados, 23 solicitudes por segundo con una latencia promedio superior a 3 segundos es pésimo.
Diagnóstico
Descubriendo el área del problema
Podemos diagnosticar la aplicación con un solo comando, gracias al comando –on-port de Clinic Doctor. Dentro de la carpeta de la app ejecutamos:
clinic doctor --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsEsto creará un archivo HTML que se abrirá automáticamente en nuestro navegador cuando se complete la creación de perfiles.
Los resultados deberían ser algo como lo siguiente:
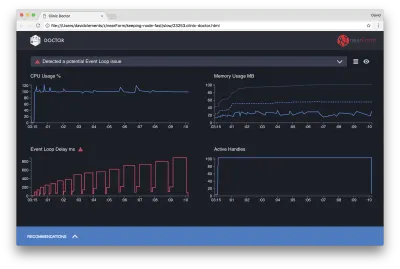
El Doctor nos dice que probablemente hayamos tenido un problema con el bucle de eventos.
Junto con el mensaje cerca de la parte superior de la interfaz de usuario, también podemos ver que el gráfico de bucle de eventos es rojo y muestra un retraso en constante aumento. Antes de profundizar en lo que esto significa, primero comprendamos el efecto que tiene el problema diagnosticado en las otras métricas.
Podemos ver que la CPU está consistentemente al 100% o más, ya que el proceso trabaja duro para procesar las solicitudes en cola. El motor de JavaScript de Node (V8) en realidad usa dos núcleos de CPU en este caso porque la máquina es multinúcleo y V8 usa dos subprocesos. Uno para Event Loop y el otro para Garbage Collection. Cuando vemos que la CPU aumenta hasta un 120 % en algunos casos, el proceso está recopilando objetos relacionados con las solicitudes gestionadas.
Vemos esto correlacionado en el gráfico de Memoria. La línea continua en el gráfico de memoria es la métrica de montón usado. Cada vez que hay un pico en la CPU, vemos una caída en la línea Montón usado, lo que muestra que la memoria se está desasignando.
Los identificadores activos no se ven afectados por el retraso del bucle de eventos. Un controlador activo es un objeto que representa E/S (como un socket o un controlador de archivo) o un temporizador (como setInterval ). Le indicamos a AutoCannon que abra 100 conexiones ( -c100 ). Los identificadores activos mantienen un recuento constante de 103. Los otros tres son identificadores para STDOUT, STDERR y el identificador para el propio servidor.
Si hacemos clic en el panel Recomendaciones en la parte inferior de la pantalla, deberíamos ver algo como lo siguiente:
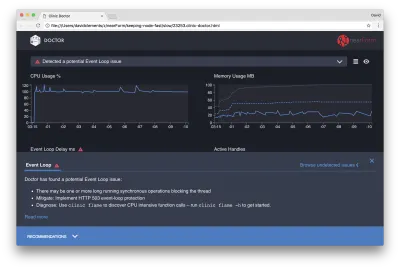
Mitigación a corto plazo
El análisis de la causa raíz de los problemas graves de rendimiento puede llevar tiempo. En el caso de un proyecto implementado en vivo, vale la pena agregar protección contra sobrecarga a los servidores o servicios. La idea de la protección de sobrecarga es monitorear el retraso del bucle de eventos (entre otras cosas) y responder con "503 Servicio no disponible" si se pasa un umbral. Esto permite que un equilibrador de carga conmute por error a otras instancias o, en el peor de los casos, significa que los usuarios tendrán que actualizar. El módulo de protección contra sobrecarga puede proporcionar esto con una sobrecarga mínima para Express, Koa y Restify. El marco Hapi tiene una opción de configuración de carga que proporciona la misma protección.
Comprender el área del problema
Como explica la breve explicación en Clinic Doctor, si el bucle de eventos se retrasa al nivel que estamos observando, es muy probable que una o más funciones estén "bloqueando" el bucle de eventos.
Es especialmente importante con Node.js reconocer esta característica principal de JavaScript: los eventos asincrónicos no pueden ocurrir hasta que se haya completado el código que se ejecuta actualmente.
Esta es la razón por la que setTimeout no puede ser preciso.
Por ejemplo, intente ejecutar lo siguiente en DevTools de un navegador o en Node REPL:
console.time('timeout') setTimeout(console.timeEnd, 100, 'timeout') let n = 1e7 while (n--) Math.random() La medida de tiempo resultante nunca será de 100 ms. Probablemente estará en el rango de 150ms a 250ms. setTimeout programó una operación asíncrona ( console.timeEnd ), pero el código que se ejecuta actualmente aún no se ha completado; hay dos líneas más. El código que se ejecuta actualmente se conoce como el "tick" actual. Para que se complete el tick, Math.random debe llamarse diez millones de veces. Si esto lleva 100 ms, entonces el tiempo total antes de que se resuelva el tiempo de espera será de 200 ms (más el tiempo que tarde la función setTimeout en poner en cola el tiempo de espera de antemano, generalmente un par de milisegundos).
En un contexto del lado del servidor, si una operación en el tick actual tarda mucho tiempo en completarse, las solicitudes no se pueden manejar y la obtención de datos no puede ocurrir porque el código asíncrono no se ejecutará hasta que se complete el tick actual. Esto significa que el código computacionalmente costoso ralentizará todas las interacciones con el servidor. Por lo tanto, se recomienda dividir el trabajo intensivo en recursos en procesos separados y llamarlos desde el servidor principal, esto evitará casos en los que una ruta raramente utilizada pero costosa ralentiza el rendimiento de otras rutas utilizadas con frecuencia pero económicas.
El servidor de ejemplo tiene un código que bloquea el bucle de eventos, por lo que el siguiente paso es localizar ese código.
analizando
Una forma de identificar rápidamente el código de bajo rendimiento es crear y analizar un gráfico de llamas. Un gráfico de llamas representa las llamadas a funciones como bloques colocados uno encima del otro, no a lo largo del tiempo sino en conjunto. La razón por la que se llama 'gráfico de llamas' es porque generalmente usa un esquema de color de naranja a rojo, donde cuanto más rojo es un bloque, más "caliente" es una función, lo que significa que es más probable que bloquee el bucle de eventos. La captura de datos para un gráfico de llamas se realiza mediante el muestreo de la CPU, lo que significa que se toma una instantánea de la función que se está ejecutando actualmente y su pila. El calor está determinado por el porcentaje de tiempo durante el perfilado que una función dada está en la parte superior de la pila (por ejemplo, la función que se está ejecutando actualmente) para cada muestra. Si no es la última función que se llama dentro de esa pila, es probable que esté bloqueando el ciclo de eventos.
Usemos clinic flame para generar un gráfico de llama de la aplicación de ejemplo:
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsEl resultado debería abrirse en nuestro navegador con algo como lo siguiente:
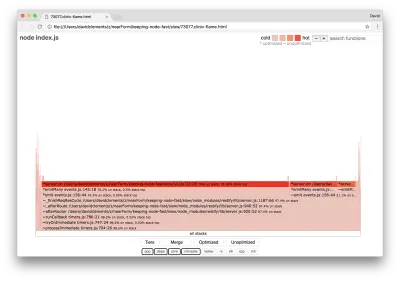
El ancho de un bloque representa cuánto tiempo pasó en la CPU en general. Se pueden observar tres pilas principales que ocupan la mayor parte del tiempo, todas ellas destacando server.on como la función más popular. En verdad, las tres pilas son iguales. Se diferencian porque durante la creación de perfiles, las funciones optimizadas y no optimizadas se tratan como tramas de llamada separadas. Las funciones con el prefijo * están optimizadas por el motor de JavaScript, y las que tienen el prefijo ~ no están optimizadas. Si el estado optimizado no es importante para nosotros, podemos simplificar aún más el gráfico presionando el botón Fusionar. Esto debería conducir a una vista similar a la siguiente:
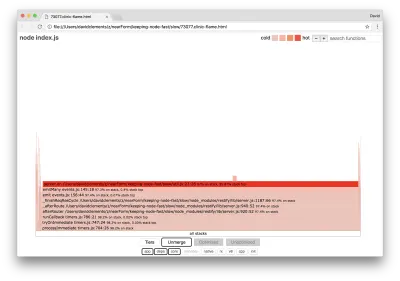
Desde el principio, podemos inferir que el código ofensivo está en el archivo util.js del código de la aplicación.
La función lenta también es un controlador de eventos: las funciones que conducen a la función son parte del módulo principal de events , y server.on es un nombre alternativo para una función anónima proporcionada como una función de manejo de eventos. También podemos ver que este código no está en el mismo tick que el código que realmente maneja la solicitud. Si lo fuera, las funciones de los módulos core http , net y stream estarían en la pila.
Tales funciones centrales se pueden encontrar expandiendo otras partes, mucho más pequeñas, del gráfico de llama. Por ejemplo, intente usar la entrada de búsqueda en la parte superior derecha de la interfaz de usuario para buscar send (el nombre de los métodos internos restify y http ). Debe estar a la derecha del gráfico (las funciones están ordenadas alfabéticamente):
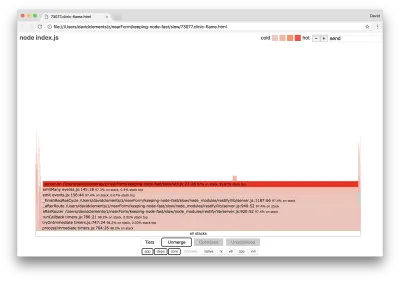
Observe cuán comparativamente pequeños son todos los bloques de manejo de HTTP reales.

Podemos hacer clic en uno de los bloques resaltados en cian que se expandirá para mostrar funciones como writeHead y write en el archivo http_outgoing.js (parte de la biblioteca http del núcleo de Node):
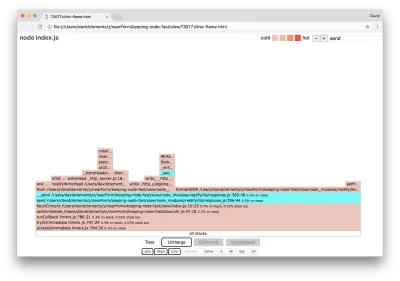
Podemos hacer clic en todas las pilas para volver a la vista principal.
El punto clave aquí es que a pesar de que la función server.on no está en el mismo tic que el código de manejo de solicitudes real, todavía está afectando el rendimiento general del servidor al retrasar la ejecución del código que de otro modo funcionaría.
depuración
Sabemos por el gráfico de llamas que la función problemática es el controlador de eventos pasado a server.on en el archivo util.js.
Vamos a ver:
server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) Es bien sabido que la criptografía tiende a ser costosa, al igual que la serialización ( JSON.stringify ), pero ¿por qué no aparecen en el gráfico de llamas? Estas operaciones están en las muestras capturadas, pero están ocultas detrás del filtro cpp . Si pulsamos el botón cpp deberíamos ver algo como lo siguiente:
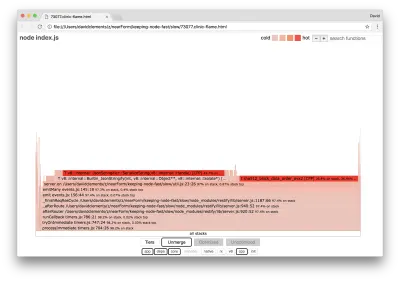
Las instrucciones internas de V8 relacionadas con la serialización y la criptografía ahora se muestran como las pilas más activas y ocupan la mayor parte del tiempo. El método JSON.stringify llama directamente al código C++; es por eso que no vemos una función de JavaScript. En el caso de la criptografía, funciones como createHash y update están en los datos, pero están en línea (lo que significa que desaparecen en la vista fusionada) o son demasiado pequeñas para representarlas.
Una vez que comenzamos a razonar sobre el código en la función etagger , rápidamente se vuelve evidente que está mal diseñado. ¿Por qué tomamos la instancia del server del contexto de la función? Hay mucho hash, ¿es necesario todo eso? Tampoco hay compatibilidad con el encabezado If-None-Match en la implementación, lo que mitigaría parte de la carga en algunos escenarios del mundo real porque los clientes solo harían una solicitud principal para determinar la actualización.
Ignoremos todos estos puntos por el momento y validemos el hallazgo de que el trabajo real que se realiza en server.on es de hecho el cuello de botella. Esto se puede lograr configurando el código server.on en una función vacía y generando un nuevo gráfico de llamas.
Modifique la función etagger a lo siguiente:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } La función de escucha de eventos pasada a server.on ahora no funciona.
Ejecutemos la clinic flame de nuevo:
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsEsto debería producir un gráfico de llama similar al siguiente:
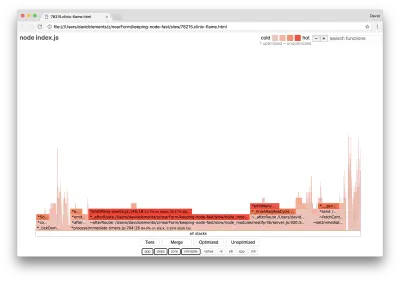
Esto se ve mejor y deberíamos haber notado un aumento en la solicitud por segundo. Pero, ¿por qué el evento que emite el código es tan caliente? Esperaríamos en este punto que el código de procesamiento HTTP ocupe la mayor parte del tiempo de la CPU, no hay nada ejecutándose en el evento server.on .
Este tipo de cuello de botella es causado por una función que se ejecuta más de lo que debería.
El siguiente código sospechoso en la parte superior de util.js puede ser una pista:
require('events').defaultMaxListeners = Infinity Eliminemos esta línea y comencemos nuestro proceso con el --trace-warnings :
node --trace-warnings index.jsSi perfilamos con AutoCannon en otro terminal, así:
autocannon -c100 localhost:3000/seed/v1Nuestro proceso generará algo similar a:
(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)
El nodo nos dice que se están adjuntando muchos eventos al objeto del servidor . Esto es extraño porque hay un valor booleano que verifica si el evento se adjuntó y luego regresa antes de tiempo, lo que esencialmente hace que attachAfterEvent no funcione después de que se adjunte el primer evento.
Echemos un vistazo a la función attachAfterEvent :
var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } ¡La verificación condicional es incorrecta! Comprueba si attachAfterEvent es verdadero en lugar de afterEventAttached . Esto significa que se adjunta un nuevo evento a la instancia del server en cada solicitud, y luego todos los eventos adjuntos anteriores se activan después de cada solicitud. ¡Vaya!
optimizando
Ahora que hemos descubierto las áreas problemáticas, veamos si podemos hacer que el servidor sea más rápido.
Fruta madura
Volvamos a colocar el código de escucha server.on (en lugar de una función vacía) y usemos el nombre booleano correcto en la verificación condicional. Nuestra función etagger tiene el siguiente aspecto:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (afterEventAttached === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } }Ahora comprobamos nuestra corrección perfilando de nuevo. Inicie el servidor en una terminal:
node index.jsLuego perfila con AutoCannon:
autocannon -c100 localhost:3000/seed/v1 Deberíamos ver resultados en algún lugar en el rango de una mejora de 200 veces (ejecutando la prueba 10s @ https://localhost:3000/seed/v1 - 100 conexiones):
| Estadística | Promedio | Desvst. | máx. |
|---|---|---|---|
| Latencia (ms) | 19.47 | 4.29 | 103 |
| Requerido/seg | 5011.11 | 506.2 | 5487 |
| Bytes/seg | 51,8 MB | 5,45 MB | 58,72 MB |
Es importante equilibrar las posibles reducciones de costos del servidor con los costos de desarrollo. Necesitamos definir, en nuestros propios contextos situacionales, hasta dónde debemos llegar para optimizar un proyecto. De lo contrario, puede ser demasiado fácil poner el 80 % del esfuerzo en el 20 % de las mejoras de velocidad. ¿Las limitaciones del proyecto lo justifican?
En algunos escenarios, podría ser apropiado lograr una mejora de 200 veces con una fruta al alcance de la mano y llamarlo un día. En otros, es posible que queramos que nuestra implementación sea lo más rápida posible. Realmente depende de las prioridades del proyecto.
Una forma de controlar el gasto de recursos es establecer una meta. Por ejemplo, 10 veces de mejora o 4000 solicitudes por segundo. Basar esto en las necesidades comerciales tiene más sentido. Por ejemplo, si los costos del servidor están 100 % por encima del presupuesto, podemos establecer una meta de mejora 2x.
Llevándolo más lejos
Si producimos un nuevo gráfico de llamas de nuestro servidor, deberíamos ver algo similar a lo siguiente:
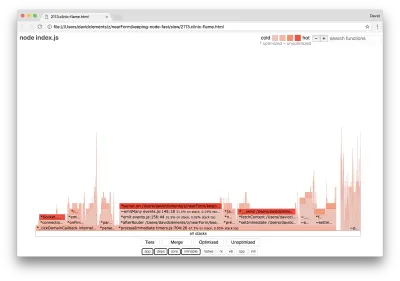
El detector de eventos sigue siendo el cuello de botella, todavía ocupa un tercio del tiempo de CPU durante la creación de perfiles (el ancho es aproximadamente un tercio del gráfico completo).
¿Qué ganancias adicionales se pueden lograr? ¿Vale la pena realizar los cambios (junto con la interrupción asociada)?
Con una implementación optimizada, que sin embargo es un poco más restringida, se pueden lograr las siguientes características de rendimiento (ejecutando 10s test @ https://localhost:3000/seed/v1 — 10 conexiones):
| Estadística | Promedio | Desvst. | máx. |
|---|---|---|---|
| Latencia (ms) | 0,64 | 0.86 | 17 |
| Requerido/seg | 8330.91 | 757.63 | 8991 |
| Bytes/seg | 84,17 MB | 7,64 MB | 92,27 MB |
Si bien una mejora de 1.6x es significativa, se puede argumentar que depende de la situación si el esfuerzo, los cambios y la interrupción del código necesarios para crear esta mejora están justificados. Especialmente cuando se compara con la mejora de 200x en la implementación original con una sola corrección de errores.
Para lograr esta mejora, se utilizó la misma técnica iterativa de perfil, generar flamegraph, analizar, depurar y optimizar para llegar al servidor optimizado final, cuyo código se puede encontrar aquí.
Los cambios finales para llegar a 8000 req/s fueron:
- No cree objetos y luego los serialice, cree una cadena de JSON directamente;
- Use algo único sobre el contenido para definir su Etag, en lugar de crear un hash;
- No haga hash de la URL, utilícela directamente como la clave.
Estos cambios son un poco más complicados, un poco más perjudiciales para la base de código y dejan el middleware de etagger un poco menos flexible porque pone la carga en la ruta para proporcionar el valor de Etag . Pero logra 3000 solicitudes adicionales por segundo en la máquina perfiladora.
Echemos un vistazo a un gráfico de llama para estas mejoras finales:
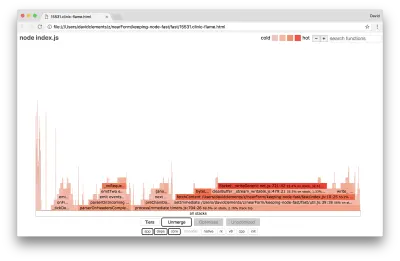
La parte más caliente del gráfico de llamas es parte del núcleo de Node, en el módulo de net . Esto es ideal.
Prevención de problemas de rendimiento
Para finalizar, aquí hay algunas sugerencias sobre formas de prevenir problemas de rendimiento antes de que se implementen.
El uso de herramientas de rendimiento como puntos de control informales durante el desarrollo puede filtrar errores de rendimiento antes de que entren en producción. Se recomienda hacer que AutoCannon y Clinic (o equivalentes) formen parte de las herramientas de desarrollo diarias.
Al comprar un marco, averigüe cuál es su política de rendimiento. Si el marco no prioriza el rendimiento, entonces es importante verificar si eso se alinea con las prácticas de infraestructura y los objetivos comerciales. Por ejemplo, Restify ha invertido claramente (desde el lanzamiento de la versión 7) en mejorar el rendimiento de la biblioteca. Sin embargo, si el bajo costo y la alta velocidad son una prioridad absoluta, considere Fastify, que ha sido medido como un 17 % más rápido por un colaborador de Restify.
Tenga cuidado con otras opciones de biblioteca de gran impacto, especialmente considere el registro. A medida que los desarrolladores corrigen problemas, pueden decidir agregar resultados de registro adicionales para ayudar a depurar problemas relacionados en el futuro. Si se utiliza un registrador de bajo rendimiento, esto puede estrangular el rendimiento con el tiempo al estilo de la fábula de la rana hirviendo. El registrador pino es el registrador JSON delimitado por saltos de línea más rápido disponible para Node.js.
Finalmente, recuerde siempre que el bucle de eventos es un recurso compartido. En última instancia, un servidor Node.js está limitado por la lógica más lenta en la ruta más activa.